Записная книжка
Компьютерное зрение, машинное обучение, нейронные сети и т.п.
Batch Normalization. Основы.
Главные наблюдаемые достоинства batch normalization это ускорение тренировки (в смысле уменьшения количества итераций для получения нужного качества) и некая допускаемая вольность в подборе параметров: и инициализации весов сети, и learning rate и других метапараметров обучения. Таким образом ценность batch Normalization для нейронных сетей сложно преувеличить, а значит есть смысл разобраться: что это такое и откуда проистекает польза при применении.
И вот тут начинается самое интересное. Ответ на первый вопрос “что это такое?” в целом не вызывает особой сложности (если подойти к делу формально и определить какие же преобразования добавляются в сетку), а вот про “откуда проистекает польза?” идут жаркие споры. Объяснение, авторов методики подвергается серьёзной критике.
Мне понравилось как это сформулировано в [3]:
“The practical success of BatchNorm is indisputable. By now, it is used by default in most deep learning models, both in research (more than 6,000 citations) and real-world settings. Somewhat shockingly, however, despite its prominence, we still have a poor understanding of what the effectiveness of BatchNorm is stemming from. In fact, there are now a number of works that provide alternatives to BatchNorm, but none of them seem to bring us any closer to understanding this issue.”
Правда, стоит отметить, что у нас всё глубокое обучение и нейронные сети во многом можно описать теми же словами. Оно вроде работает и мы даже, в принципе, понимаем какие рычаги жать, чтобы ехало в примерно нужном направлении, но многие моменты так до конца и не объясняются.
Заканчивая лирику переходим к конкретике. Начнем разбираться с самого начала, а именно классической статьи [1] где методика BN и была впервые описана.
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Авторы уже в заголовке статьи [1] анонсируют, что ускорение тренировки связано с тем, что применение BN позволяет уменьшить internal covariate shift. Следовательно, есть смысл разобраться, что такое covariate shift (отложив пока в сторону, что значит internal), а для этого надо обратиться к статье [2] на которую ссылаются авторы [1].
Covariate shift
Рассмотрим следующий пример (который взят из той же [2]).
Пример
Коэффициенты определим методом наименьших квадратов (МНК), т.е. решив задачу оптимизации:
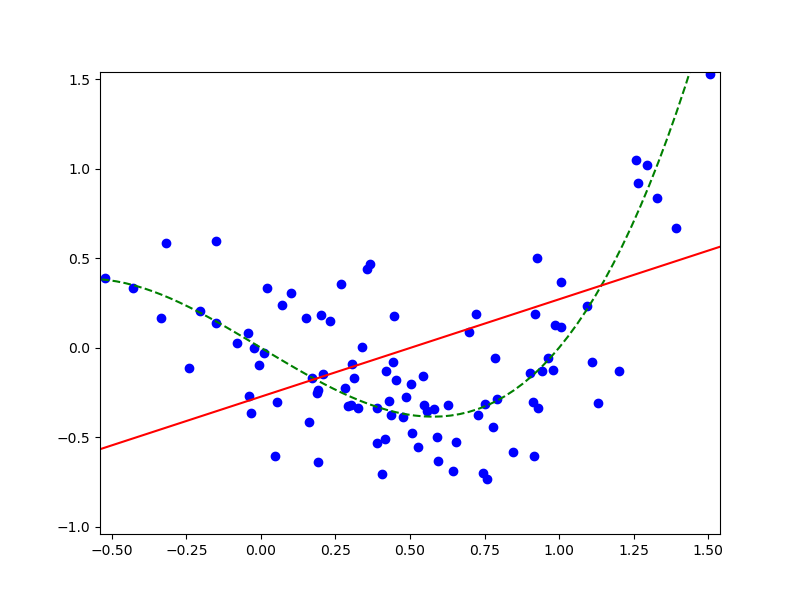
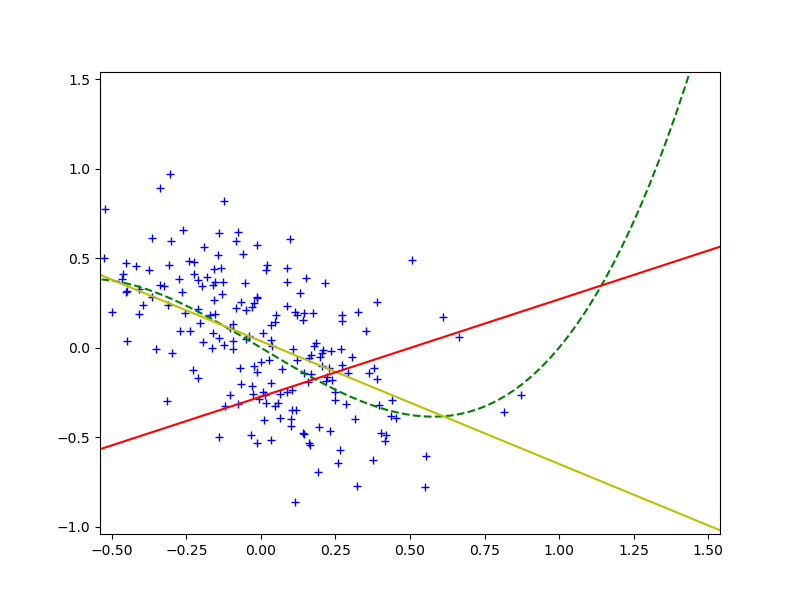
Очевидно, раз красная и желтая линии существенно не совпадают, то модель “наученная” по тренировочному набору для проверочного набора даёт плохой результат. В [2] предлагается, для того, чтобы погасить влияние covariate shift вместо МНК использовать взвешенный МНК, и оптимизировать функцию:
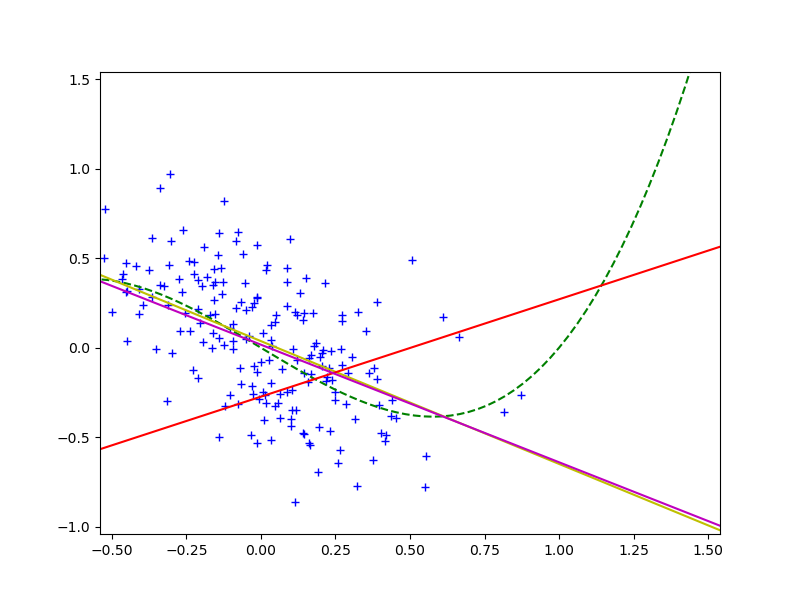
видно, что она практически совпадает с желтой, а значит мы действительно побороли covariate shift и улучшили предсказательную силу модели на проверочном наборе.
Batch Normalization. Определение.
Мы сейчас не будем углубляться в то, насколько действительно ICS оказывает влияние на скорость тренировки, и борется ли BN с ICS. Позже мы разберем статьи, которые к идеи с ICS относятся с большим скептицизмом и объясняют успех BN совсем другим. Но то, что BN отлично работает подтверждается на практике, поэтому переходим к его описанию
Если теоретическое обоснование BN выглядит “притянутым за уши” (во всяком случае в статье нет каких-то внятных экспериментов, которые бы указывали на то, что до добавления BN сеть страдала от ICS и вот вам статистика, а после перестала, и вот вам другая статистика), то какие практические соображения лежат в основе метода, авторы описывают весьма четко и понятно.
Пример.
Сегенерируем некоторое количество векторов, подчиняющихся этому распределению и отрисуем их на плоскости:
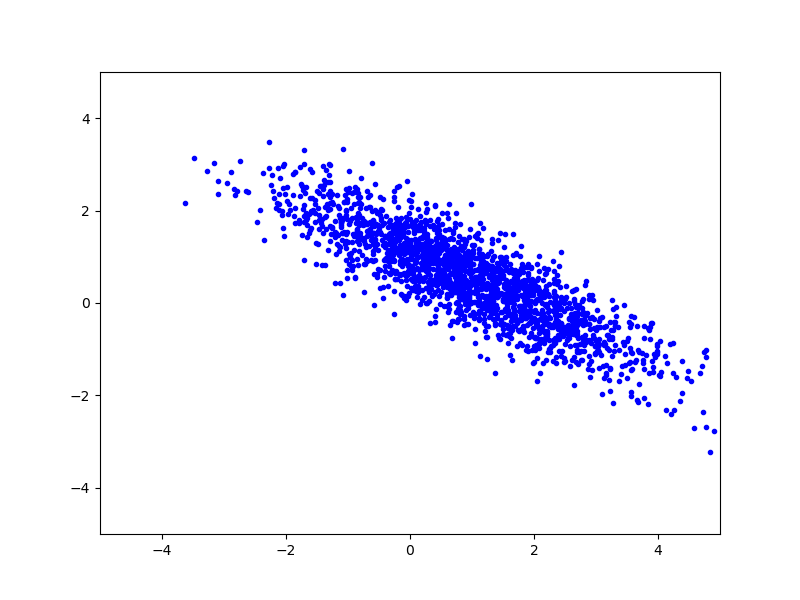
Теперь найдем собственные числа и собственные вектора для матрицы ковариации (если бы мы не знали матрицу ковариации и среднее, то могли бы вычислить приближенное значение из набора векторов):
$\lambda_2 = 0.2, e_2 = (e_<21>, e_<22>) = (0.5547002, 0.83205029)$
и определим линейное преобразование:
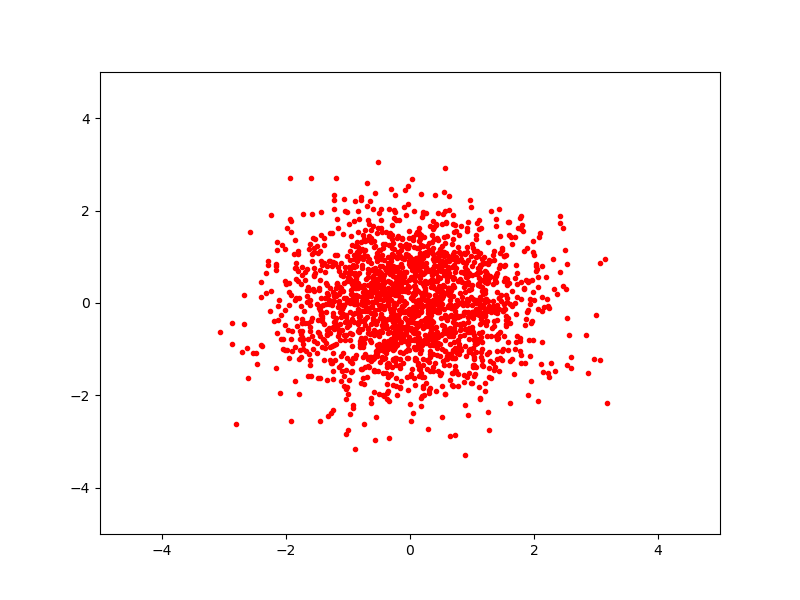
Покончили с примером, смысл того, что предполагается сделать с данными понятен.
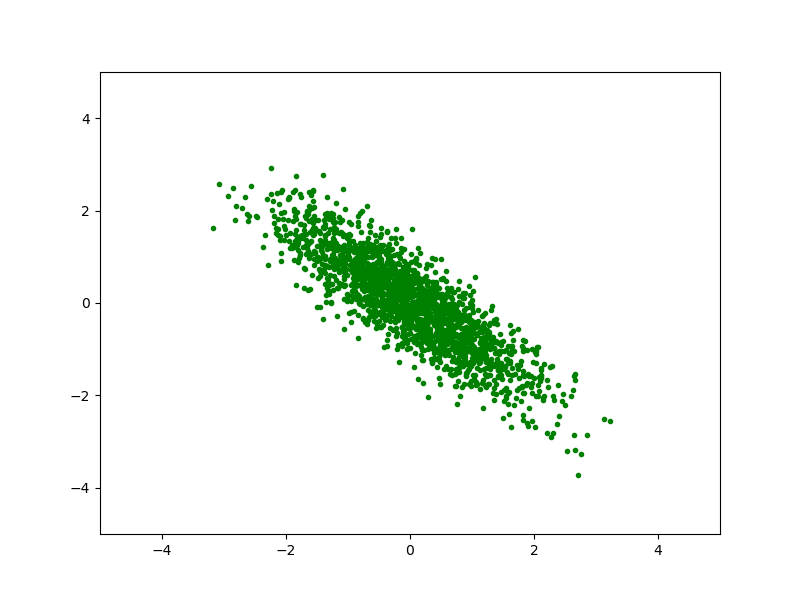
Второе, когда сеть используется для вывода, обычно у нас нет ни батчей ни даже минибатчей, поэтому среднее и дисперсию мы сохраняем из тренировки, для этого для каждой компоненты вектора входа каждого слоя мы запоминаем аппроксимированые математическое ожидание и дисперсию, считая скользящую среднюю математического ожидания и дисперсии по минибатчам в процессе тренировки.
Batch Normalization. Практика.
Итак, что такое BN мы определили, разберёмся как её применять. Обычно и полносвязный, и свёрточный слой можно представить в виде:
\[z = g(\textrm
Чтобы получить максимальный эффект от использования BN в статье [1] предлагается еще несколько изменений в процессе тренировки сети:
Увеличить learning rate. Когда в сеть внедрена BN можно увеличить learning rate и таким образом ускорить процесс оптимизации нейронной сети, при этом избежать расходимости. В сетях без BN при применении больших learning rate за счет увеличения амплитуды градиентов возникает расходимость.
Ускорить убывание learning rate. Поскольку при добавлении в сеть BN скорость сходимости увеличивается, то можно уменьшать learning rate быстрее. (Обычно используется либо экспоненциальное уменьшение веса, либо ступенчатое, и то и другое регулируется двумя параметрами: во сколько раз и через сколько итераций уменьшить learning rate, при применении BN можно сократить число итераций)
Более тщательно перемешивать тренировочные данные, чтобы минибатчи не собирались из одних и тех же примеров.
Резюмируя. Авторы статьи [1] предложили методику ускорения сходимости нейронной сети. Эта методика доказала свою эффективность, кроме того она позволяет применять более широкий интервал метапараметров тренировки (например, больший learning rate) и с меньшей аккуратностью подходить к инициализации весов сети. Объяснение данной методики основывается на понятии ICS, однако, каких-то существенных подтверждений того, что данный метод действительно позволяет погасить ICS и именно за счет этого улучшить процесс тренировки в статье я не нашел (возможно плохо искал). Есть только некие теоретические рассуждения, которые не выглядят (на мой взгляд) достаточно убедительно.
Литература
S. Ioffe, Ch. Szegedy, “Batch Normali;zation: Accelerating Deep Network Training by Reducing Internal Covariate Shift”, arXiv:1502.03167v3, 2015
H. Shimodaira, “Improving predictive inference under covariate shift by weighting the log-likelihood function.”, Journal of Statistical Planning and Inference, 90(2):227–244, October 2000.
Sh. Santurkar, D. Tsipras, A. Ilyas, A. Madry, “How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)”, arXiv:1805.11604v5, 2019
В чем разница между партией и эпохой в нейронной сети?
Дата публикации 2018-07-20
В этом посте вы обнаружите разницу между партиями и эпохами в стохастическом градиентном спуске.
Прочитав этот пост, вы узнаете:

обзор
Этот пост разделен на пять частей; они есть:
Стохастический градиентный спуск
Задача алгоритма состоит в том, чтобы найти набор внутренних параметров модели, которые хорошо работают против некоторого показателя производительности, такого как логарифмическая потеря или среднеквадратическая ошибка.
Алгоритм является итеративным. Это означает, что процесс поиска происходит в несколько отдельных этапов, каждый шаг, мы надеемся, немного улучшает параметры модели.
Каждый шаг включает использование модели с текущим набором внутренних параметров для прогнозирования некоторых выборок, сравнение прогнозов с реальными ожидаемыми результатами, вычисление ошибки и использование ошибки для обновления внутренних параметров модели.
Эта процедура обновления отличается для разных алгоритмов, но в случае искусственных нейронных сетейобратное распространениеалгоритм обновления используется.
Прежде чем мы погрузимся в партии и эпохи, давайте взглянем на то, что мы подразумеваем под образцом.
Узнайте больше о градиентном спуске здесь:
Что такое образец?
Образец представляет собой одну строку данных.
Он содержит входные данные, которые вводятся в алгоритм, и выходные данные, которые используются для сравнения с прогнозом и вычисления ошибки.
Обучающий набор данных состоит из множества строк данных, например, много образцов. Образец также может называться экземпляром, наблюдением, входным вектором или вектором признаков.
Теперь, когда мы знаем, что такое образец, давайте определим партию.
Что такое партия?
Думайте о пакете как о цикле for, повторяющем одну или несколько выборок и делающем прогнозы. В конце пакета прогнозы сравниваются с ожидаемыми выходными переменными, и вычисляется ошибка. Исходя из этой ошибки, алгоритм обновления используется для улучшения модели, например, двигаться вниз по градиенту ошибки.
Набор обучающих данных может быть разделен на одну или несколько партий.
Когда все обучающие образцы используются для создания одной партии, алгоритм обучения называется спуском градиента партии. Когда размер пакета составляет одну выборку, алгоритм обучения называется стохастическим градиентным спуском. Когда размер пакета больше, чем одна выборка и меньше, чем размер обучающего набора данных, алгоритм обучения называется спуском градиента мини-пакета.
В случае мини-пакетного градиентного спуска популярные размеры партии включают 32, 64 и 128 образцов. Вы можете увидеть эти значения, используемые в моделях в литературе и учебниках.
Что если набор данных не делится равномерно по размеру пакета?
Это может случаться и часто случается при обучении модели. Это просто означает, что в последней партии меньше образцов, чем в других партиях.
Кроме того, вы можете удалить некоторые выборки из набора данных или изменить размер пакета так, чтобы количество выборок в наборе данных делилось равномерно на размер пакета.
Подробнее о различиях между этими вариациями градиентного спуска читайте в посте:
Пакет включает обновление модели с использованием образцов; Далее, давайте посмотрим на эпоху.
Что такое эпоха?
Одна эпоха означает, что у каждой выборки в наборе обучающих данных была возможность обновить внутренние параметры модели. Эпоха состоит из одной или нескольких партий. Например, как указано выше, эпоха, в которой есть одна партия, называется алгоритмом обучения пакетного градиентного спуска.
Вы можете придумать цикл for для числа эпох, где каждый цикл проходит через набор обучающих данных. В этом цикле for находится еще один вложенный цикл for, который выполняет итерацию для каждой партии выборок, где одна партия имеет указанное количество выборок «размера партии».
Количество эпох традиционно велико, часто сотни или тысячи, что позволяет алгоритму обучения работать до тех пор, пока ошибка модели не будет сведена к минимуму. Вы можете увидеть примеры количества эпох в литературе и в учебных пособиях 10, 100, 500, 1000 и более.
Обычно создаются линейные графики, которые показывают эпохи вдоль оси X как время и ошибку или навык модели на оси Y. Эти графики иногда называют кривыми обучения. Эти графики могут помочь диагностировать, является ли модель переученной, недостаточно изученной или подходит ли она для набора данных обучения.
Подробнее о диагностике с помощью кривых обучения в сетях LSTM см. Пост:
Если это все еще не ясно, давайте посмотрим на различия между партиями и эпохами.
В чем разница между партией и эпохой?
Размер партии должен быть больше или равен одному и меньше или равен количеству выборок в наборе обучающих данных.
Количество эпох может быть установлено в целочисленное значение от одного до бесконечности. Вы можете запускать алгоритм сколько угодно и даже останавливать его, используя другие критерии, помимо фиксированного количества эпох, таких как изменение (или отсутствие изменения) ошибки модели со временем.
Они оба являются целочисленными значениями и являются гиперпараметрами для алгоритма обучения, например параметры для процесса обучения, а не внутренние параметры модели, найденные в процессе обучения.
Вы должны указать размер пакета и количество эпох для алгоритма обучения.
Не существует волшебных правил для настройки этих параметров. Вы должны попробовать разные значения и посмотреть, что лучше всего подходит для вашей проблемы.
Работал Пример
Наконец, давайте сделаем это с небольшим примером.
Предположим, у вас есть набор данных с 200 выборками (строками данных), и вы выбираете размер пакета 5 и 1000 эпох.
Это означает, что набор данных будет разделен на 40 партий, каждая с пятью выборками. Вес модели будет обновляться после каждой партии из пяти образцов.
Это также означает, что одна эпоха будет включать 40 партий или 40 обновлений модели.
При 1000 эпохах модель будет экспонироваться или проходить через весь набор данных 1000 раз. Это всего 40 000 партий за весь учебный процесс.
Дальнейшее чтение
Этот раздел предоставляет больше ресурсов по теме, если вы хотите углубиться.
Резюме
В этом посте вы обнаружили разницу между партиями и эпохами в стохастическом градиентном спуске.
В частности, вы узнали:
У вас есть вопросы?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.
Batch Normalization (батч-нормализация) что это такое?
Вам что-нибудь говорит термин внутренний ковариационный сдвиг:
internal covariance shift
Звучит очень умно, не так ли? И не удивительно. Это понятие в 2015-м году ввели два сотрудника корпорации Google:
Sergey Ioffe и Christian Szegedy (Иоффе и Сегеди)
решая проблему ускорения процесса обучения НС. И мы сейчас посмотрим, что же они предложили, как это работает и, наконец, что же это за ковариационный сдвиг. Как раз с последнего я и начну.
Давайте предположим, что мы обучаем НС распознавать машины (неважно какие, главное чтобы сеть на выходе выдавала признак: машина или не машина). Но, при обучении мы используем автомобили только черного цвета. После этого, сеть переходит в режим эксплуатации и ей предъявляются машины уже разных цветов:
Как вы понимаете, это не лучшим образом скажется на качестве ее работы. Так вот, на языке математики этот эффект можно выразить так. Начальное распределение цветов (пусть это будут градации серого) обучающей выборки можно описать с помощью вот такой плотности распределения вероятностей (зеленый график):
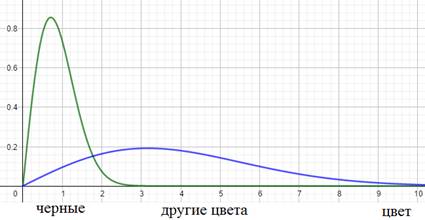
А распределение всего множества цветов машин, встречающихся в тестовой выборке в виде синего графика. Как видите эти графики имеют различные МО и дисперсии. Эта разница статистических характеристик и приводит к ковариационному сдвигу. И теперь мы понимаем: если такой сдвиг имеет место быть, то это негативно сказывается на работе НС.
Но это пример внешнего ковариационного сдвига. Его легко исправить, поместив в обучающую выборку нужное количество машин с разными цветами. Есть еще внутренний ковариационный сдвиг – это когда статистическая картина меняется внутри сети от слоя к слою:
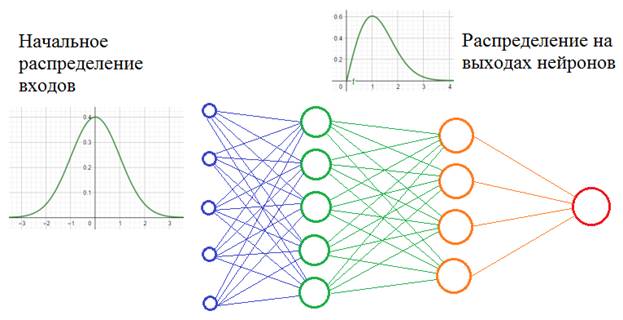
Само по себе такое изменение статистик не несет каких-либо проблем. Проблемы проявляются в процессе обучения, когда при изменении весов связей предыдущего слоя статистическое распределение выходных значений нейронов текущего слоя становится заметно другим. И этот измененный сигнал идет на вход следующего слоя. Это похоже на то, словно на вход скрытого слоя поступают то машины черного цвета, то машины красного цвета или какого другого. То есть, весовые коэффициенты в пределах мини-батча только адаптировались к черным автомобилям, как в следующем мини-батче им приходится адаптироваться к другому распределению – красным машинам и так постоянно. В ряде случаев это может существенно снижать скорость обучения и, кроме того, для адаптации в таких условиях приходится устанавливать малое значение шага сходимости, чтобы весовые коэффициенты имели возможность подстраиваться под разные статистические распределения.
Это описание проблемы, которую, как раз, и выявили сотрудники Гугла, изучая особенности обучения многослойных НС. Решение кажется здесь очевидным: если проблема в изменении статистических характеристик распределения на выходах нейронов, то давайте их стандартизировать, нормализовывать – приводить к единому виду. Именно это и делается при помощи предложенного алгоритма
Осталось выяснить: какие характеристики и как следует нормировать. Из теории вероятностей мы знаем, что самые значимые из них – первые две: МО и дисперсия. Так вот, в алгоритме batch normalization их приводят к значениям 0 и 1, то есть, формируют распределение с нулевым МО и единичной дисперсией. Чуть позже я подробнее поясню как это делается, а пока ответим на второй вопрос: для каких величин и в какой момент производится эта нормировка? Разработчики этого метода рекомендовали располагать нормировку для величин 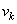 перед функцией активации:
перед функцией активации:
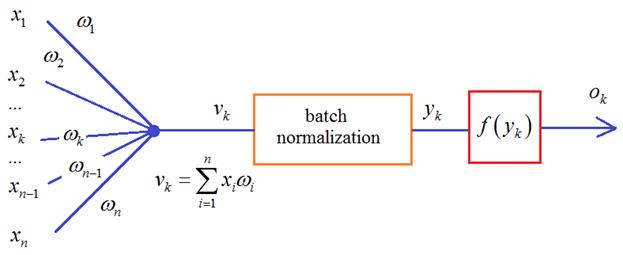
Но сейчас уже имеются результаты исследований, которые показывают, что этот блок может давать хорошие результаты и после функции активации.
Что же из себя представляет batch normalization и где тут статистики? Давайте вспомним, что НС обучается пакетами наблюдений – батчами. И для каждого наблюдения из batch на входе каждого нейрона получается свое значение суммы:
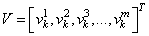
Здесь m – это размер пакета, число наблюдений в батче. Так вот статистики вычисляются для величин V в пределах одного batch:
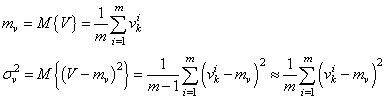
И, далее, чтобы вектор V имел нулевое среднее и единичную дисперсию, каждое значение преобразовывают по очевидной формуле:
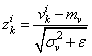
здесь 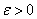 — небольшое положительное число, исключающее деление на ноль, если дисперсия будет близка к нулевым значениям. В итоге, вектор
— небольшое положительное число, исключающее деление на ноль, если дисперсия будет близка к нулевым значениям. В итоге, вектор
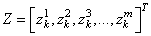
будет иметь нулевое МО и почти единичную дисперсию. Но этого недостаточно. Если оставить как есть, то будут теряться естественные статистические характеристики наблюдений между батчами: небольшие изменения в средних значениях и дисперсиях, т.е. будет уменьшена репрезентативность выборки:
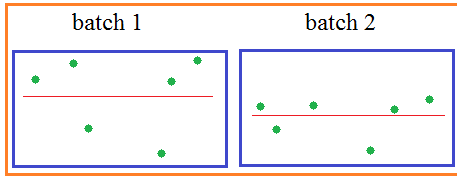
Кроме того, сигмоидальная функция активации вблизи нуля имеет практически линейную зависимость, а значит, простая нормировка значений x лишит НС ее нелинейного характера, что приведет к ухудшению ее работы:
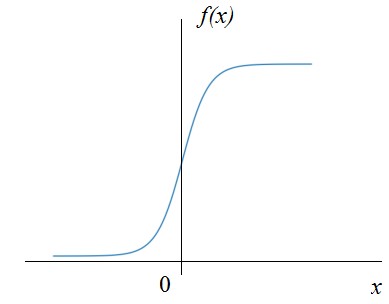
Поэтому нормированные величины 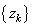 дополнительно масштабируются и смещаются в соответствии с формулой:
дополнительно масштабируются и смещаются в соответствии с формулой:

Параметры 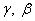 с начальными значениями 1 и 0 также подбираются в процессе обучения НС с помощью того же алгоритма градиентного спуска. То есть, у сети появляются дополнительные настраиваемые переменные, помимо весовых коэффициентов.
с начальными значениями 1 и 0 также подбираются в процессе обучения НС с помощью того же алгоритма градиентного спуска. То есть, у сети появляются дополнительные настраиваемые переменные, помимо весовых коэффициентов.
Но это лишь возможные эффекты – они могут и не проявиться или даже, наоборот, применение этого алгоритма ухудшит обучаемость НС. Рекомендация здесь такая:
Изначально строить нейронные сети без batch normalization (или dropout) и если наблюдается медленное обучение или эффект переобучения, то можно попробовать добавить batch normalization или dropout, но не оба вместе.
Реализация batch normalization в Keras
Давайте теперь посмотрим как можно реализовать данный алгоритм в пакете Keras. Для этого существует класс специального слоя, который так и называется:
Он применяется к выходам предыдущего слоя, после которого указан в модели НС, например:
Здесь нормализация применяется к выходам скрытого слоя, состоящего из 300 нейронов. Правда в такой простой НС нормализация, скорее, негативно сказывается на обучении. Этот метод обычно помогает при большом числе слоев, то есть, при deep learning.
Видео по теме

Нейронные сети: краткая история триумфа

Структура и принцип работы полносвязных нейронных сетей | #1 нейросети на Python



Ускорение обучения, начальные веса, стандартизация, подготовка выборки | #4 нейросети на Python


Функции активации, критерии качества работы НС | #6 нейросети на Python



Как нейронная сеть распознает цифры | #9 нейросети на Python

Оптимизаторы в Keras, формирование выборки валидации | #10 нейросети на Python


Batch Normalization (батч-нормализация) что это такое? | #12 нейросети на Python

Как работают сверточные нейронные сети | #13 нейросети на Python

Делаем сверточную нейронную сеть в Keras | #14 нейросети на Python

Примеры архитектур сверточных сетей VGG-16 и VGG-19 | #15 нейросети на Python

Теория стилизации изображений (Neural Style Transfer) | #16 нейросети на Python

Делаем перенос стилей изображений с помощью Keras и Tensorflow | #17 нейросети на Python

Как нейронная сеть раскрашивает изображения | #18 нейросети на Python

Введение в рекуррентные нейронные сети | #19 нейросети на Python

Как рекуррентная нейронная сеть прогнозирует символы | #20 нейросети на Python

Делаем прогноз слов рекуррентной сетью Embedding слой | #21 нейросети на Python

Как работают RNN. Глубокие рекуррентные нейросети | #22 нейросети на Python


Как делать сентимент-анализ рекуррентной LSTM сетью | #24 нейросети на Python

Рекуррентные блоки GRU. Пример их реализации в задаче сентимент-анализа | #25 нейросети на Python

Двунаправленные (bidirectional) рекуррентные нейронные сети | #26 нейросети на Python

Автоэнкодеры. Что это и как работают | #27 нейросети на Python

Вариационные автоэнкодеры (VAE). Что это такое? | #28 нейросети на Python

Делаем вариационный автоэнкодер (VAE) в Keras | #29 нейросети на Python

Расширенный вариационный автоэнкодер (CVAE) | #30 нейросети на Python

Что такое генеративно-состязательные сети (GAN) | #31 нейросети на Python

Делаем генеративно-состязательную сеть в Keras и Tensorflow | #32 нейросети на Python
© 2021 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта



