Массив (программирование)
Индексный массив (в некоторых языках программирования также таблица, ряд) — именованный набор однотипных переменных, расположенных в памяти непосредственно друг за другом (в отличие от списка), доступ к которым осуществляется по индексу.
Индекс массива — целое число, либо значение типа, приводимого к целому, указывающее на конкретный элемент массива.
В ряде скриптовых языков, например PHP, ассоциативные массивы, в которых переменные не обязаны быть однотипными, и доступ к ним не обязательно осуществляется по индексу.
Содержание
Общее описание
Массив — Упорядоченный набор данных, для хранения данных одного типа, идентифицируемых с помощью одного или нескольких индексов. В простейшем случае массив имеет постоянную длину и хранит единицы данных одного и того же типа.
Количество используемых индексов массива может быть различным. Массивы с одним индексом называют одномерными, с двумя — двумерными и т. д. Одномерный массив нестрого соответствует вектору в математике, двумерный — матрице. Чаще всего применяются массивы с одним или двумя индексами, реже — с тремя, ещё большее количество индексов встречается крайне редко.
Поддержка индексных массивов (свой синтаксис объявления, функции для работы с элементами и т. д.) есть в большинстве высокоуровневых языков программирования. Максимально допустимая размерность массива, типы и диапазоны значений индексов, ограничения на типы элементов определяются языком программирования и/или конкретным транслятором.
В языках программирования, допускающих объявления программистом собственных типов, как правило, существует возможность создания типа «массив». В определении такого типа может указываться размер, тип элемента, диапазон значений и типы индексов. В дальнейшем возможно определение переменных созданного типа. Все такие переменные-массивы имеют одну структуру. Некоторые языки поддерживают для переменных-массивов операции присваивания (когда одной операцией всем элементам массива присваиваются значения соответствующих элементов другого массива).
Специфические типы массивов
Динамические массивы
Динамическим называется массив, размер которого может меняться во время исполнения программы. Для изменения размера динамического массива язык программирования, поддерживающий такие массивы, должен предоставлять встроенную функцию или оператор. Динамические массивы дают возможность более гибкой работы с данными, так как позволяют не прогнозировать хранимые объёмы данных, а регулировать размер массива в соответствии с реально необходимыми объёмами. Обычные, не динамические массивы называют ещё статическими.
Пример динамического массива на Delphi
Пример динамического массива на Си
Гетерогенные массивы
Гетерогенным называется массив, в разные элементы которого могут быть непосредственно записаны значения, относящиеся к различным типам данных. Массив, хранящий указатели на значения различных типов, не является гетерогенным, так как собственно хранящиеся в массиве данные относятся к единственному типу — типу «указатель». Гетерогенные массивы удобны как универсальная структура для хранения наборов данных произвольных типов. Отсутствие их поддержки в языке программирования приводит к необходимости реализации более сложных схем хранения данных. С другой стороны, реализация гетерогенности требует усложнения механизма поддержки массивов в трансляторе языка.
Массивы массивов
Многомерные массивы, как правило реализованные как одномерные массивы, каждый элемент которых, является ссылкой на другой одномерный массив.
Реализация
Стандартным способом реализации статических массивов с одним типом элементов является следующий:
Таким образом, адрес элемента с заданным набором индексов вычисляется, так что время доступа ко всем элементам массива одинаково.
Первый элемент массива, в зависимости от языка программирования, может иметь различный индекс. Различают три основных разновидности массивов: с отсчетом от нуля (zero-based), с отсчетом от единицы (one-based), и с отсчетом от специфического значения заданного программистом (n-based). Отсчет индекса элемента массивов с нуля более характерен для низкоуровневых ЯП, однако этот метод был популяризирован в языках более высокого уровня языком программирорования С.
Более сложные типы массивов — динамические и гетерогенные — реализуются сложнее.
Достоинства
Недостатки
См. также
Ссылки
Полезное
Смотреть что такое «Массив (программирование)» в других словарях:
Массив — У этого термина существуют и другие значения, см. Массив (значения). Эту страницу предлагается переименовать в Массив (информатика). Пояснение причин и обсуждение на странице Википедия:К переименованию/4 ноября 2012. Возможно, её … Википедия
Класс (программирование) — У этого термина существуют и другие значения, см. Класс. Класс в программировании набор методов и функций. Другие абстрактные типы данных метаклассы, интерфейсы, структуры, перечисления характеризуются какими то своими, другими… … Википедия
Коллекция (программирование) — У этого термина существуют и другие значения, см. Коллекция. Для улучшения этой статьи желательно?: Найти и оформить в виде сносок ссылки на авторитетные исто … Википедия
Интерфейс (объектно-ориентированное программирование) — У этого термина существуют и другие значения, см. Интерфейс (значения). Интерфейс (от лат. inter «между», и face «поверхность») семантическая и синтаксическая конструкция в коде программы, используемая для специфицирования… … Википедия
Полиморфизм (программирование) — У этого термина существуют и другие значения, см. Полиморфизм. Эта статья или раздел нуждается в переработке. Пожалуйста, улучшите статью … Википедия
Функциональное программирование — Парадигмы программирования Агентно ориентированная Компонентно ориентированная Конкатенативная Декларативная (контрастирует с Императивной) Ограничениями Функциональная Потоком данных Таблично ориентированная (электронные таблицы) Реактивная … Википедия
Автоматное программирование — Автоматное программирование это парадигма программирования, при использовании которой программа или её фрагмент осмысливается как модель какого либо формального автомата. В зависимости от конкретной задачи в автоматном программировании… … Википедия
Объект (программирование) — У этого термина существуют и другие значения, см. Объект (значения). Объект в программировании некоторая сущность в виртуальном пространстве, обладающая определённым состоянием и поведением, имеющая заданные значения свойств (атрибутов) и… … Википедия
Очередь (программирование) — У этого термина существуют и другие значения, см. Очередь. Очередь структура данных с дисциплиной доступа к элементам «первый пришёл первый вышел» (FIFO, First In First Out). Добавление элемента (принято обозначать словом… … Википедия
Ссылка (программирование) — В этой статье не хватает ссылок на источники информации. Информация должна быть проверяема, иначе она может быть поставлена под сомнение и удалена. Вы можете … Википедия
Основные структуры данных. Матчасть. Азы
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.
Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.

В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Основные структуры данных.
Массивы
Массив — это самая простая и широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).
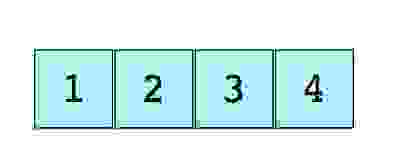
Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
Вопросы
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Это не массивы. Это очередь. Придумал Алан Тюринг.
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.
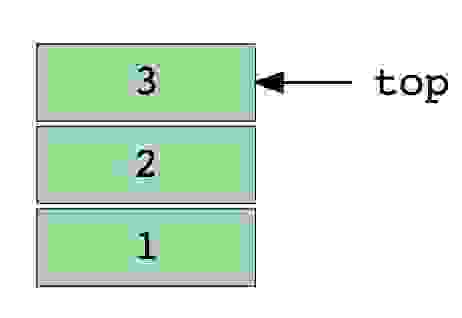
Основные операции
Вопросы
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом. Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым

Основные операции
Вопросы
Связанный список
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
Самое частое, линейный однонаправленный список. Пример – файловая система.

Основные операции
Вопросы
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).

Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
Общие алгоритмы обхода графа
Вопросы
Деревья
Дерево-это иерархическая структура данных, состоящая из узлов (вершин) и ребер (дуг). Деревья по сути связанные графы без циклов.
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
Вопросы
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».
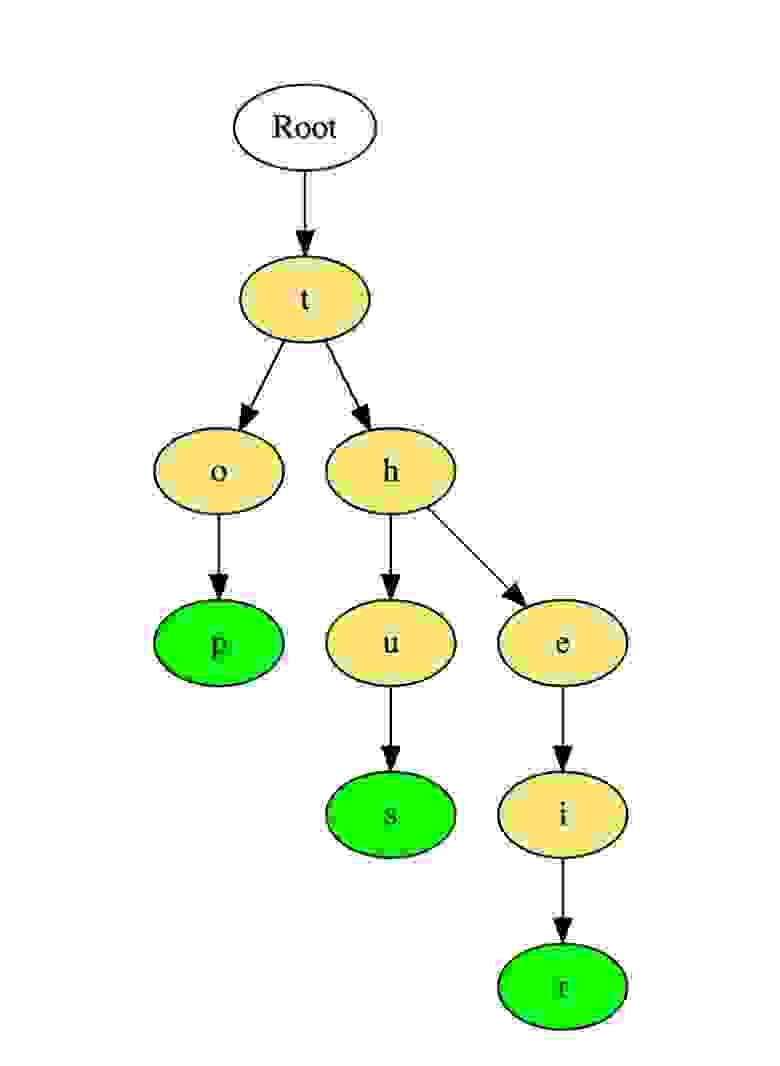
Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.
Вопросы
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от
Вопросы
Список ресурсов
Вместо заключения
Матчасть так же интересна, как и сами языки. Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
Базовый массив данных
Смотреть что такое «Базовый массив данных» в других словарях:
Массив (программирование) — Индексный массив (в некоторых языках программирования также таблица, ряд) именованный набор однотипных переменных, расположенных в памяти непосредственно друг за другом (в отличие от списка), доступ к которым осуществляется по индексу. Индекс… … Википедия
Вопрос о статусе русского языка на Украине — Николай Гоголь, русский писатель классик, уроженец Полтавщины Владимир Даль, составитель «Толкового словаря живого великорусского языка», уроженец Луганска … Википедия
Вопрос о статусе русского языка в Украине — Николай Гоголь, русский писатель классик, уроженец Полтавщины Владимир Даль, составитель «Толкового словаря живого великорусского языка», уроженец Луганска … Википедия
Дискуссия о статусе русского языка в Украине — Николай Гоголь, русский писатель классик, уроженец Полтавщины Владимир Даль, составитель «Толкового словаря живого великорусского языка», уроженец Луганска … Википедия
Положение русского языка в Украине — Николай Гоголь, русский писатель классик, уроженец Полтавщины Владимир Даль, составитель «Толкового словаря живого великорусского языка», уроженец Луганска … Википедия
Положение русского языка на Украине — Николай Гоголь, русский писатель классик, уроженец Полтавщины Владимир Даль, составитель «Толкового словаря живого великорусского языка», уроженец Луганска … Википедия
РЯнаУ — Николай Гоголь, русский писатель классик, уроженец Полтавщины Владимир Даль, составитель «Толкового словаря живого великорусского языка», уроженец Луганска … Википедия
Русский язык в Украине — Николай Гоголь, русский писатель классик, уроженец Полтавщины Владимир Даль, составитель «Толкового словаря живого великорусского языка», уроженец Луганска … Википедия
Русский язык в украинском государстве — Николай Гоголь, русский писатель классик, уроженец Полтавщины Владимир Даль, составитель «Толкового словаря живого великорусского языка», уроженец Луганска … Википедия
Русский язык на территории Украины — Николай Гоголь, русский писатель классик, уроженец Полтавщины Владимир Даль, составитель «Толкового словаря живого великорусского языка», уроженец Луганска … Википедия
Дадим формальное определение:
массив — структурированный тип данных, состоящий из некоторого числа элементов одного типа.
Для того чтобы разобраться в возможностях и особенностях обработки массивов в программах на ассемблере, нужно ответить на следующие вопросы:
· Как описать массивв программе?
· Как инициализировать массив, то есть как задать начальные значения его элементов?
· Как организовать доступк элементам массива?
· Как организовать массивыс размерностью более одной?
· Как организовать выполнениетиповых операций с массивами?
Описание и инициализация массива в программе
Специальных средств описания массивов в программах ассемблера, конечно, нет. При необходимости использовать массив в программе его нужно моделировать одним из следующих способов:
1. Перечислением элементов массива в поле операндов одной из директив описания данных. При перечислении элементы разделяются запятыми. К примеру:
;массив из 5 элементов.Размер каждого элемента 4 байта:
2. Используя оператор повторения dup. К примеру:
;массив из 5 нулевых элементов.
;Размер каждого элемента 2 байта:
Такой способ определения используется для резервирования памяти с целью размещения и инициализации элементов массива.
3. Используя директивы labelиrept. Пара этих директив может облегчить описание больших массивов в памяти и повысить наглядность такого описания. Директиваreptотносится к макросредствам языка ассемблера и вызывает повторение указанное число раз строк, заключенных между директивой и строкой endm. К примеру, определим массив байт в области памяти, обозначенной идентификаторомmas_b. В данном случае директиваlabelопределяет символическое имяmas_b, аналогично тому, как это делают директивы резервирования и инициализации памяти. Достоинство директивыlabelв том, что она не резервирует память, а лишь определяет характеристики объекта. В данном случае объект — это ячейка памяти. Используя несколько директивlabel, записанных одна за другой, можно присвоить одной и той же области памяти разные имена и разный тип, что и сделано в следующем фрагменте:
В результате в памяти будет создана последовательность из четырех слов f1f0. Эту последовательность можно трактовать как массив байт или слов в зависимости от того, какое имя области мы будем использовать в программе —mas_bилиmas_w.
4. Использование цикла для инициализации значениями области памяти, которую можно будет впоследствии трактовать как массив.
5. Посмотрим на примере листинга 2, каким образом это делается.
Листинг 2 Инициализация массива в цикле
mes db 0ah,0dh,’Массив- ‘,’$’
mas db 10 dup (?) ;исходный массив
xor ax,ax ;обнуление ax
mov cx,10 ;значение счетчика цикла в cx
mov si,0 ;индекс начального элемента в cx
go: ;цикл инициализации
mov mas[si],bh ;запись в массив i
inc si ;продвижение к следующему элементу массива
loop go ;повторить цикл
;вывод на экран получившегося массива
mov ah,02h ;функция вывода значения из al на экран
add dl,30h ;преобразование числа в символ
mov ax,4c00h ;стандартный выход
end main ;конец программы
Доступ к элементам массива
При работе с массивами необходимо четко представлять себе, что все элементы массива располагаются в памяти компьютера последовательно.
Само по себе такое расположение ничего не говорит о назначении и порядке использования этих элементов. И только лишь программист с помощью составленного им алгоритма обработки определяет, как нужно трактовать эту последовательность байт, составляющих массив. Так, одну и ту же область памяти можно трактовать как одномерный массив, и одновременно те же самые данные могут трактоваться как двухмерный массив. Все зависит только от алгоритма обработки этих данных в конкретной программе. Сами по себе данные не несут никакой информации о своем “смысловом”, или логическом, типе. Помните об этом принципиальном моменте.
Эти же соображения можно распространить и на индексы элементов массива. Ассемблер не подозревает об их существовании и ему абсолютно все равно, каковы их численные смысловые значения.
Для того чтобы локализовать определенный элемент массива, к его имени нужно добавить индекс. Так как мы моделируем массив, то должны позаботиться и о моделировании индекса. В языке ассемблера индексы массивов — это обычные адреса, но с ними работают особым образом. Другими словами, когда при программировании на ассемблере мы говорим об индексе, то скорее подразумеваем под этим не номер элемента в массиве, а некоторый адрес.
Давайте еще раз обратимся к описанию массива. К примеру, в программе статически определена последовательность данных:
Пусть эта последовательность чисел трактуется как одномерный массив. Размерность каждого элемента определяется директивой dw, то есть она равна2байта. Чтобы получить доступ к третьему элементу, нужно к адресу массива прибавить6. Нумерация элементов массива в ассемблере начинается с нуля.
То есть в нашем случае речь, фактически, идет о 4-м элементе массива — 3, но об этом знает только программист; микропроцессору в данном случае все равно — ему нужен только адрес.
В общем случае для получения адреса элемента в массиве необходимо начальный (базовый) адрес массива сложить с произведением индекса (номер элемента минус единица) этого элемента на размер элемента массива:
база + (индекс*размер элемента)
Архитектура микропроцессора предоставляет достаточно удобные программно-аппаратные средства для работы с массивами. К ним относятся базовые и индексные регистры, позволяющие реализовать несколько режимов адресации данных. Используя данные режимы адресации, можно организовать эффективную работу с массивами в памяти. Вспомним эти режимы:
· индексная адресация со смещением — режим адресации, при котором эффективный адрес формируется из двух компонентов:
o постоянного (базового)— указанием прямого адреса массива в виде имени идентификатора, обозначающего начало массива;
o переменного (индексного)— указанием имени индексного регистра.
;поместить 3-й элемент массива mas в регистр ax:
· базовая индексная адресация со смещением — режим адресации, при котором эффективный адрес формируется максимум из трех компонентов:
o постоянного(необязательный компонент), в качестве которой может выступать прямой адрес массива в виде имени идентификатора, обозначающего начало массива, или непосредственное значение;
o переменного (базового)— указанием имени базового регистра;
o переменного (индексного)— указанием имени индексного регистра.
Этот вид адресации удобно использовать при обработке двухмерных массивов. Пример использования этой адресации мы рассмотрим далее при изучении особенностей работы с двухмерными массивами.
Напомним, что в качестве базового регистра может использоваться любой из восьми регистров общего назначения. В качестве индексного регистра также можно использовать любой регистр общего назначения, за исключением esp/sp.
Микропроцессор позволяет масштабировать индекс. Это означает, что если указать после имени индексного регистра знак умножения “*” с последующей цифрой 2, 4 или 8, то содержимое индексного регистра будет умножаться на 2, 4 или 8, то есть масштабироваться.
Применение масштабирования облегчает работу с массивами, которые имеют размер элементов, равный 2, 4 или 8 байт, так как микропроцессор сам производит коррекцию индекса для получения адреса очередного элемента массива. Нам нужно лишь загрузить в индексный регистр значение требуемого индекса (считая от 0). Кстати сказать, возможность масштабирования появилась в микропроцессорах Intel, начиная с модели i486. По этой причине в рассматриваемом здесь примере программы стоит директива .486. Ее назначение, как и ранее использовавшейся директивы.386, в том, чтобы указать ассемблеру при формировании машинных команд на необходимость учета и использования дополнительных возможностей системы команд новых моделей микропроцессоров.
В качестве примера использования масштабирования рассмотрим листинг 3, в котором просматривается массив, состоящий из слов, и производится сравнение этих элементов с нулем. Выводится соответствующее сообщение.
Листинг 3. Просмотр массива слов с использованием
.data ;начало сегмента данных
mes1 db ‘не равен 0!$’,0ah,0dh
mes2 db ‘равен 0!$’,0ah,0dh
mas dw 2,7,0,0,1,9,3,6,0,8 ;исходный массив
.486 ;это обязательно
mov ds,ax ;связка ds с сегментом данных
xor ax,ax ;обнуление ax
mov cx,10 ;значение счетчика цикла в cx
mov esi,0 ;индекс в esi
mov dx,mas[esi*2] ;первый элемент массива в dx
cmp dx,0 ;сравнение dx c 0
je equal ;переход, если равно
not_equal: ;не равно
mov ah,09h ;вывод сообщения на экран
mov ah,02h ;вывод номера элемента массива на экран
inc esi ;на следующий элемент
dec cx ;условие для выхода из цикла
jcxz exit ;cx=0? Если да — на выход
jmp compare ;нет — повторить цикл
mov ah,09h ;вывод сообщения mes3 на экран
mov ah,09h ;вывод сообщения mes2 на экран
inc esi ;на следующий элемент
dec cx ;все элементы обработаны?
mov ax,4c00h ;стандартный выход
end main ;конец программы
Еще несколько слов о соглашениях:
· Если для описания адреса используется только один регистр, то речь идет о базовой адресациии этот регистр рассматривается какбазовый:
;переслать байт из области данных, адрес
которой находится в регистре ebx:
· Если для задания адреса в команде используется прямая адресация(в виде идентификатора) в сочетании с одним регистром, то речь идет обиндексной адресации. Регистр считаетсяиндексным, и поэтому можно использовать масштабирование для получения адреса нужного элемента массива:
;сложить содержимое eax с двойным словом в памяти
;по адресу mas + (ebx)*4
· Если для описания адреса используются два регистра, то речь идет о базово-индексной адресации. Левый регистр рассматривается как базовый, а правый — как индексный. В общем случае это не принципиально, но если мы используем масштабирование с одним из регистров, то он всегда являетсяиндексным. Но лучше придерживаться определенных соглашений.
· Помните, что применение регистров ebp/bpиesp/spпо умолчанию подразумевает, что сегментная составляющая адреса находится в регистреss.
Заметим, что базово-индексную адресацию не возбраняется сочетать с прямой адресацией или указанием непосредственного значения. Адрес тогда будет формироваться как сумма всех компонентов.
;адрес операнда равен [mas+(ebx)+(ecx)*2]
;адрес операнда равен [(ebx)+8+(ecx)*4]
Но имейте в виду, что масштабирование эффективно лишь тогда, когда размерность элементов массива равна 2, 4 или 8 байт. Если же размерность элементов другая, то организовывать обращение к элементам массива нужно обычным способом, как описано ранее.
Рассмотрим пример работы с массивом из пяти трехбайтовых элементов (листинг 4). Младший байт в каждом из этих элементов представляет собой некий счетчик, а старшие два байта — что-то еще, для нас не имеющее никакого значения. Необходимо последовательно обработать элементы данного массива, увеличив значения счетчиков на единицу.
Листинг 4. Обработка массива элементов с нечетной длиной
MODEL small ;модель памяти
STACK 256 ;размер стека
.data ;начало сегмента данных
N=5 ;количество элементов массива
mas db 5 dup (3 dup (0))
main: ;точка входа в программу
xor ax,ax ;обнуление ax
mov dl,mas[si] ;первый байт поля в dl
inc dl ;увеличение dl на 1 (по условию)
mov mas[si],dl ;заслать обратно в массив
add si,3 ;сдвиг на следующий элемент массива



