Что такое serverless computing (бессерверные вычисления)?
Бессерверные вычисления — это метод предоставления серверных услуг на основе фактического использования сервисов. Бессерверный провайдер позволяет пользователям писать и развёртывать код, не беспокоясь о базовой инфраструктуре. Компания, которая получает бэкенд-услуги от бессерверного поставщика, платит по факту за используемые ресурсы и не должна резервировать и оплачивать фиксированную пропускную способность или количество серверов, поскольку услуга автоматически масштабируется. Конечно, для предоставления клиенту бессерверных вычислений используются физические серверы, но разработчикам нет необходимости думать об их конфигурации, производительности, ядрах, памяти и прочем.
На заре интернета любой, кто хотел создать веб-приложение, должен был физически владеть оборудованием, необходимым для запуска сервера. Это было дорого и неудобно, потому что оборудование требовало много места.
Затем пришли облачные вычисления, когда нужное количество серверов или часть серверного пространства можно было арендовать в облаке. Разработчики и компании, которые арендуют эти ресурсы, обычно приобретают мощности с некоторым запасом, чтобы гарантировать, что всплеск трафика или активности пользователей не превысит их месячные лимиты в облачной инфраструктуре и не выведет их приложение из строя. Это означает, что некоторая часть оплачиваемого серверного пространства может простаивает и не используется. Для решения этой проблемы облачные провайдеры предлагают модели автоматического масштабирования, но даже при такой модели выделения ресурсов нежелательный всплеск активности, вроде DDoS-атаки, может оказаться очень дорогостоящим.
Бессерверные вычисления позволяют разработчикам приобретать бэкенд-сервисы с оплатой по мере использования, что означает, что разработчикам нужно платить только за те услуги, которые они используют. Это похоже на переход с тарифного плана мобильного оператора с фиксированным ежемесячным лимитом на тариф, где плата взимается только за каждый фактически использованный байт данных.
Термин «бессерверный» несколько вводит в заблуждение, поскольку все ещё существуют серверы, предоставляющие эти внутренние сервисы. Но все проблемы, связанные с серверным пространством и инфраструктурой, решаются поставщиком. Бессерверный режим означает, что разработчики могут выполнять свою работу, вообще не беспокоясь о серверах.
Что такое серверные службы? В чем разница между фронтендом и бэкендом?
Разработка приложений обычно делится на две части: фронтенд и бэкенд. Фронтенд — это часть приложения, которую пользователи видят и с которой взаимодействуют, например, визуальный скелет страницы. Бэкенд — это часть, которую пользователь не видит. Она включает в себя сервер, на котором находятся файлы приложения, и базы данных, где хранятся пользовательские данные и реализована бизнес-логика.
Например, представим себе сайт, продающий билеты на концерты. Когда пользователь вводит адрес сайта в окне браузера, браузер отправляет запрос на внутренний сервер, который в ответ передаёт данные сайта. Затем пользователь видит интерфейс сайта, который может включать в себя текст, изображения и поля формы, которые пользователь должен заполнить. Пользователь может взаимодействовать с одним из полей формы на интерфейсе для поиска своего любимого музыкального исполнителя. Когда пользователь нажимает «отправить», это действие инициирует другой запрос к бэкенду. Внутренний код проверяет свою базу данных, чтобы узнать, существует ли исполнитель с таким именем, и если да, то, когда он будет выступать в следующий раз и сколько билетов доступно. Затем серверная часть передаст эти данные обратно, и интерфейс будет отображать результаты таким образом, чтобы это было понятно пользователю. Аналогичным образом происходит оплата — выполняется ещё один обмен данными между интерфейсом и сервером.
Какие серверные службы могут быть представлены бессерверными вычислениями?
Большинство бессерверных провайдеров предлагают своим клиентам услуги баз данных и хранилища, у многих есть платформы Function-as-a-Service (FaaS). FaaS позволяет разработчикам выполнять небольшие фрагменты кода на границе сети. С помощью FaaS разработчики могут создавать модульную архитектуру, делая кодовую базу более масштабируемой, не тратя ресурсы на поддержку бэкенда.
Каковы преимущества бессерверных вычислений?
Снижение затрат — бессерверные вычисления, как правило, выгодны, поскольку у многих крупных провайдеров облачных серверных услуг пользователь платит за неиспользуемое пространство или время простоя процессора.
Упрощённая масштабируемость — разработчикам, использующим бессерверную архитектуру, не нужно беспокоиться о политиках для масштабирования своего кода. Бессерверный поставщик выполняет все масштабирование по запросу.
Упрощённый внутренний код — с помощью FaaS разработчики могут создавать простые функции, которые независимо выполняют одну задачу, например, выполнение вызова API.
Более быстрый оборот — бессерверная архитектура может значительно сократить время выхода на рынок. Вместо того, чтобы требовать сложного процесса развёртывания для исправления ошибок и новых функций, разработчики могут добавлять и изменять код по частям.
В сравнении с другими моделями облачного сервиса.
Есть ещё пара технологий, которые часто путают с бессерверными вычислениями — это Backend-as-a-Service и Platform-as-a-Service. Хотя у них есть общие черты, эти модели не обязательно удовлетворяют требованиям бессерверности.
Backend-as-a-service (BaaS) — это модель обслуживания, в которой поставщик облачных услуг предлагает серверные службы (например, хранение данных), чтобы разработчики могли сосредоточиться на написании кода фронтенда. Но хотя бессерверные приложения управляются событиями и работают на периферии, приложения BaaS могут не соответствовать ни одному из этих требований.
Платформа как услуга (PaaS) — это модель, в которой разработчики по сути арендуют все необходимые инструменты для разработки и развёртывания приложений у облачного провайдера, включая такие вещи, как операционные системы и промежуточное ПО. Однако приложения PaaS не так легко масштабируются, как бессерверные приложения. PaaS также не обязательно работает на периферии и часто имеет заметную задержку запуска, которой нет в бессерверных приложениях.
Инфраструктура как услуга (IaaS) — это общий термин для поставщиков облачных услуг, размещающих инфраструктуру от имени своих клиентов. Поставщики IaaS могут предлагать бессерверные функции, но эти термины не являются синонимами.
Развитие бессерверных технологий
Бессерверные вычисления продолжают развиваться, поскольку бессерверные провайдеры предлагают решения, позволяющие преодолеть некоторые из их недостатков. Один из таких недостатков — холодный старт.
Обычно, когда определённая бессерверная функция не вызывалась в течение некоторого времени, провайдер её отключает, чтобы сэкономить энергию и избежать избыточного выделения ресурсов. В следующий раз, когда пользователь запустит приложение, которое вызывает эту функцию, бессерверному провайдеру придётся включить его заново и снова запустить эту функцию. Это добавляет некоторую задержку, известную как «холодный старт».
Как только функция будет запущена, она будет вызываться намного быстрее при следующих запросах (тёплый старт), но если функция опять не будет запрашиваться в течение некоторого времени, она снова перейдёт в неактивное состояние. И следующий пользователь, который запросит эту функцию, столкнётся с некоторой задержкой ответа из-за холодного запуска. Холодный старт — это необходимый компромисс при использовании бессерверных функций.
По мере того как устраняются все больше и больше недостатков использования бессерверных систем, можно ожидать рост популярность подобной модели предоставления вычислений.
Что ещё интересного есть в блоге Cloud4Y
Подписывайтесь на наш Telegram-канал, чтобы не пропустить очередную статью. Пишем не чаще двух раз в неделю и только по делу.
Бессерверные вычисления (serverless computing) — что это такое и где используются

Бессерверные вычисления (их также называют serverless computing) — это набирающий популярность способ предоставления серверных услуг без аренды/покупки физического оборудования. Сервера в этом случае, разумеется, используются, но на стороне поставщика услуги. Именно он заботится о конфигурации физических серверов, их производительности, количестве CPU и RAM. Пользователь никак не взаимодействует с инфраструктурой и не обслуживает её, но при этом может писать и развёртывать код, используя готовые вычислительные ресурсы.
Оплачиваются эти ресурсы по факту потребления (модель pay-as-you-go). Резервировать и предоплачивать определённое количество серверов или пропускную способность канала не нужно. Объём потребляемых мощностей автоматически масштабируется.
Почему это востребовано? Когда интернет только начал развиваться, для запуска веб-приложения нужно было владеть оборудованием, позволяющим запустить сервер. Физическое оборудование занимало место, его нужно было обновлять и обслуживать. Это требовало много времени, денег и знаний.

С появлением облачных вычислений компании стали арендовать целые облачные сервера или часть серверного пространства. Поначалу пользователи старались брать мощности с запасом, чтобы внезапный наплыв пользователей не выводил системы из строя. Соответственно, часть облачных ресурсов оплачивалась, но не использовалась по назначению: простаивала. Чтобы решить эту проблему, поставщики облачных услуг внедрили автоматическую систему масштабирования, позволяющую эффективно справляться с внезапными пиками активности. Хотя при DDoS-атаке автоматическое масштабирование может больно ударить по кошельку. Но этот вопрос решается другими способами.
Бессерверные технологии дали разработчикам возможность использовать бэкенд-сервисы с оплатой по мере потребления. Это можно сравнить со сменой тарифного плана с абонентской платой на тариф с побайтовой (посекундной) тарификацией.
Не все правильно понимают, что значит serverless computing. Этот термин не должен вводить вас в заблуждение. Клиент действительно никак не взаимодействует с серверами, для него их нет. Он получает ресурсы этих серверов. И может заниматься тестированием и развёртыванием приложений, не беспокоясь о «железе». Однако физически серверы существуют и используются. Просто клиента это никоим образом не заботит.
Чем отличается фронтенд и бэкенд и при чём тут серверные службы
Разработку приложений можно разбить на две части: бэкенд и фронтенд. Бэкенд — это внутренняя инфраструктура. Та часть, которую пользователь не видит. Она состоит из сервера с файлами приложения и БД с пользовательскими данными. Там же реализована бизнес-логика. Фронтенд — это доступная пользователю часть приложения, которую он видит и с которой может взаимодействовать (например, интерфейс страницы).
Приведём пример. Есть сайт-агрегатор билетов на различные мероприятия. Когда пользователь вбивает в браузере нужный URL, браузер посылает запрос на внутренний сервер, получая в ответ данные этого сайта. В результате этого обмена пользователю показывается искомая страница. Допустим, там есть форма, которую нужно заполнить для поиска и покупки билета. Когда пользователь указывает в форме название мероприятия и нажимает «Отправить», формируется запрос к бэкенду. Внутренний код собирает информацию в БД, проверяя наличие мероприятия, когда оно состоится, есть ли билеты на него. Затем сервер возвращает эту информацию обратно, и фронтенд показывает результаты, трансформируя данные в понятный пользователю интерфейс. Покупка билетов выполняется по аналогичной схеме.
Какие серверные службы можно использовать как бессерверные вычисления
Как правило, провайдеры предлагают клиентам услуги баз данных и хранилища. Также существует платформа Function-as-a-Service (FaaS), благодаря которой разработчики имеют возможность формировать модульную инфраструктуру и не тратить деньги на поддержку бэкенда, что делает кодовую базу дешевле, но более масштабируемой.
Преимущества serverless computing
У бессерверных вычислений есть ряд преимуществ, которые мотивируют разработчиков активнее использовать serverless возможности. Перечислим наиболее важные.
Похожие модели облачных услуг
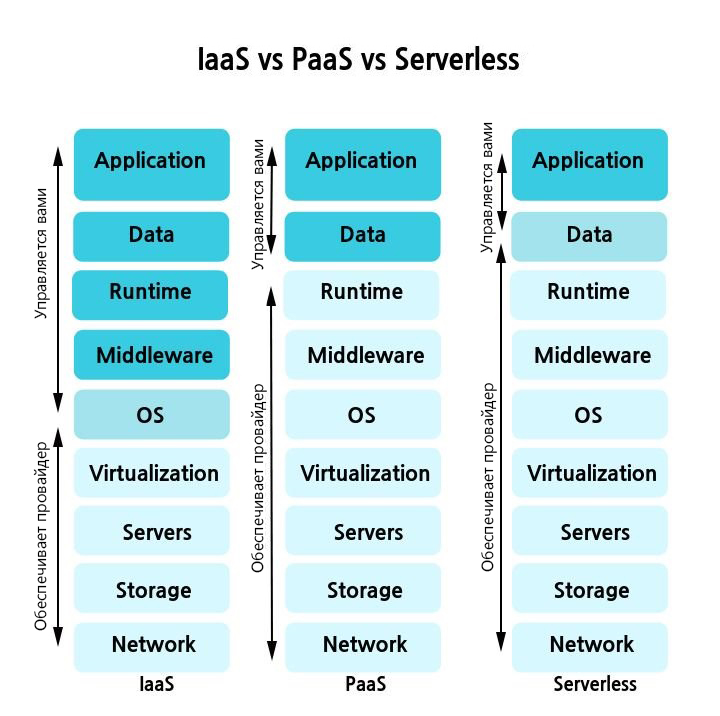
Есть несколько технологий, которые иногда путают с бессерверными: Backend-as-a-Service, Platform-as-a-Service, Infrastructure-as-a-Service. Да, у них есть схожие черты, но это разные бизнес-модели.
Backend-as-a-service (BaaS). Облачный провайдер связывает приложения с серверным облачным хранилищем и создаёт условия для того, чтобы разработчики могли сконцентрироваться на работе с кодом фронтенда. BaaS является составляющей serverless технологии, но сам по себе бессерверным называться не может.
Platform-as-a-Service (PaaS). Модель «Платформа как услуга» предполагает, что разработчики арендуют у облачного провайдера инструменты для разработки и развёртывания. Это могут быть ОС, промежуточное ПО и т.д. Однако в случае с PaaS масштабирование идёт тяжелее, платформа не всегда работает на периферии и может запускаться с заметной задержкой, которой нет у serverless-приложений
Infrastructure-as-a-Service (IaaS). Модель «Инфраструктура как услуга» включает в себя много вариантов предоставления инфраструктуры. Провайдер может предлагать бессерверные решения в рамках IaaS, но эти понятия синонимами не являются.
Что ждёт бессерверные технологии
Serverless computing будут развиваться и дальше, поскольку поставщики работают над появлением новых услуг и устраняют имеющиеся недостатки. Например, решают проблему холодного старта. Вопрос заключается в том, что когда какая-либо бессерверная функция долго не вызывается, провайдер её отключает. Это делается для снижения объёма выделяемых ресурсов. И когда функция всё же понадобится, провайдеру требуется включить её заново и затем запустить. Это вызывает небольшую задержку, которая и получила название «холодный старт».
После запуска функция начинает вызываться намного быстрее, но после долгого простоя снова может стать неактивной. И при следующем запуске пользователь опять заметит небольшую задержку ответа. Вообще, холодный старт — это важный компромисс в условиях работы с бессерверными функциями.
С развитием технологии и устранением выявленных недостатков стоит ожидать рост популярность подобной модели предоставления вычислительных мощностей.
Экономика бессерверных вычислений

Наша исходная задача заключалась в том, чтобы попытаться ответить на ряд актуальных вопросов, в частности: когда целесообразнее использовать AWS Lambda, а когда сервисы AWS EC2. А самое главное — разобраться, какие параметры играют в данном случае наибольшую роль.
Введение
Данная статья посвящена анализу тарифов на бессервисный сервис от Amazon Web Services (AWS), также известный под названием AWS Lambda. Мы сравнили применяемую тарифную стратегию этого сервиса с сервисом AWS Elastic Compute Cloud (EC2), а также подробно изучили, какие допущения необходимо сделать для адекватного сравнения этих сервисов.
Не стремясь разложить действительность на черное и белое, мы обнаружили, что оптимальный выбор сделать можно, если учесть ряд специфичных для сервисов факторов. Мы проанализировали ряд частных случаев и сделали для них адекватные выводы.
Наш подход строится на теории и результатах моделирования для типовых сервисных сценариев из реальной жизни. Они помогли нам разобраться в том, какие именно модельные переменные стоит учитывать при построении планов использования рассматриваемых технологий. Наши средства моделирования, которые мы опубликовали в виде открытого кода, могут быть чрезвычайно полезны на этапе планирования программного сервиса. Именно в этот момент очень важно понять, какие технологии нужно задействовать, чтобы сэкономить время и деньги.
Прочитав статью, вы сможете убедиться в том, что наличие глубинных знаний об особенностях работы вашего кода чрезвычайно важно для оптимизации операционных затрат и предотвращения их непропорционального роста при добавлении нового функционала. Мы также проанализируем вклад так называемого фактора пропускной способности, позволяющего определить метод для сравнения рассматриваемых архитектур.
По своей сути бессерверная архитектура (или архитектура «функция как услуга», FaaS) предоставляет вычислительные ресурсы для выполнения прикладного кода без необходимости настройки серверов или управления ими. Облачный провайдер исполняет код (который называется функцией) исключительно по мере необходимости и автоматически масштабируется для удовлетворения спроса.
В предыдущих постах мы обсуждали бессерверную архитектуру, а также крупнейших провайдеров публичных облачных услуг, предлагающих решения на базе этой архитектуры. Кроме того, мы проанализировали варианты внутреннего развертывания этой архитектуры при помощи Fission и RedHat OpenShift.
Функции, развертываемые при помощи сервиса AWS Lambda, получают дополнительные преимущества благодаря интеграции с другими сервисами облачного провайдера. Тем не менее это повышает риск зависимости от поставщика, лишая ваше приложение возможности развертывания в средах других облачных провайдеров. Важно сказать, что выполняемый код ограничен набором языков, поддерживаемых провайдером.
Достаточно просто прочитать описание сервиса, чтобы понять, что у этого облачного провайдера позиция такая: для каждой из платформ существует свой сценарий использования, и если ваша рабочая нагрузка не может быть реализована на каком-нибудь из языков, поддерживаемых AWS Lambda, либо если это бинарный файл другого разработчика, или же нагрузка сильно зависит от использования локального хранилища данных, то тогда целесообразно использовать виртуальную машину от облачных провайдеров, например AWS, Google, IBM или Microsoft. Тем не менее есть большое число приложений и рабочих нагрузок, которые могут успешно выполняться в среде AWS Lambda и использовать ее преимущества. На них мы и остановимся в этой работе.
В данном исследовании мы сосредоточились на AWS Lambda — одной из наиболее активно используемых бессерверных платформ, которая поддерживает множество языков общего назначения, включая Python, Java, Go, C# и Node.js.
Большая часть статей, которые мы обнаружили на эту тему, ориентируются исключительно на то, что бессерверные вычисления позволяют не резервировать заранее вычислительные мощности и тем самым экономят компаниям деньги. Мы считаем, что если провести углубленный анализ и рассмотреть реальные варианты рабочих нагрузок, то можно более адекватно оценить роль этой архитектуры для снижения затрат.
Бизнес-допущения
Для проведения моделирования и глубокого изучения экономического эффекта развертывания бессерверной архитектуры (AWS Lambda) по сравнению с виртуальными машинами (AWS EC2) мы должны сделать несколько допущений о возможном поведении и моделировании рассматриваемых бизнес-процессов:
Мы полагаем, что прикладной код хорошо работает на обоих сервисах — EC2 и Lambda. Это необходимо для того, чтобы сервисы можно было сравнивать. В большинстве случаев, чтобы унаследованный код можно было использовать непосредственно на бессерверной платформе, его необходимо предварительно преобразовать. Монолитные приложения или такие программы, которые требуют низкоуровневого доступа к операционной системе, не смогут нормально работать на бессерверной архитектуре без серьезного рефакторинга кода. Кроме того, провайдер бессерверной облачной инфраструктуры может запретить доступ к ряду потенциально опасных пакетов, поэтому создаваемые бессерверные функции будут ограниченно совместимы с кодом, предназначенным для обычных облачных ВМ.
Мы полагаем, что наше приложение способно автоматически масштабировать облачные виртуальные машины (ВМ) в процессе работы, добавляя новые ВМ в те моменты, когда существующий набор ВМ перестает справляться с возрастающим объемом запросов.
Сразу оговоримся, что мы не учитываем здесь экономию административных расходов при использовании модели «инфраструктура как услуга» (IaaS). Хотя именно здесь может лежать ключ к более точной оценке «точки перегиба», при которой затраты на каждый из сервисов становятся соизмеримы друг с другом. Тем не менее практически невозможно в данном случае сделать правильное допущение, поскольку стоимость трудовых ресурсов в разных странах сильно варьируется.
В наших моделях мы использовали различные варианты соотношений объемов памяти, необходимых для обработки одного запроса с использованием бессерверной архитектуры, с одной стороны, и в облачных ВМ, с другой. Чаще всего мы будем использовать коэффициент пропускной способности 1:1 — это означает, что облачная виртуальная машина сможет обработать весь объем запросов, который может уместиться в общем объеме доступной памяти, при этом на каждый запрос будет тратиться тот же объем памяти, что и в случае бессерверной функции.
Наконец мы полагаем, что наша гипотетическая организация имеет достаточный опыт в области программирования, настройки и развертывания бессерверных архитектур. Несмотря на то, что бессерверные архитектуры устраняют необходимость развертывания инфраструктур веб-серверов, IT-команды многих организаций могут и не иметь опыта развертывания приложений по-новому.
Рассмотренные типовые сценарии
Мы выделили несколько типовых сценариев, которые достаточно сильно отличаются друг от друга, и поэтому их можно рассматривать по отдельности. В большей части существующих исследований в лучшем случае был рассмотрен первый из сценариев.
Среди своих продающих моментов облачные провайдеры часто упоминают, что бессерверные архитектуры снимают необходимость в новом развертывании инфраструктуры в случае существенного роста рабочих нагрузок.
Как распределение запросов в течение суток влияет на общие затраты? Что можно сказать об общем объеме запросов? Есть ли разница между использованием исключительно локального сервиса (например, региональной вычислительной сети передачи данных) и глобального сервиса?
Если осознать важность проблем масштабируемости, то с этой точки зрения возможность не крутить виртуальные машины круглосуточно только ради того, чтобы выполнить запросы, поступающие с равными интервалами (как и бывает в случае интернета вещей), — вполне себе нормальный сценарий использования бессерверных вычислений: вы платите только за те запросы, которые были фактически обработаны. Но как все это будет работать при росте числа устройств? Какую роль в сравнительном анализе затрат будет играть частота запросов?
Облачные ВМ и тарифы на бессерверные вычисления: основные различия
Большинство облачных провайдеров берет деньги за время работы виртуальной машины с минимально предоплачиваемым временем в 60 секунд. Стоимость зависит от функционала ВМ (например, процессорной мощности, объема оперативной памяти, доступности или объема диска), а также предварительно резервируемого потребления ресурсов для этих ВМ. Правильный выбор типа или конфигурации ресурсов ВМ очень сильно зависит от приложения.
Функция, которая определяет ежемесячную стоимость виртуальной машины AWS Lambda зависит от трех параметров:
число выполненных запросов (назовем их n) в данном интервале;
объем памяти, выделенный виртуальной машиной;
оценочное время выполнения запросов (d) в миллисекундах.
Таким образом, общая стоимость Cλ для заданного числа запросов n может быть вычислена по следующей формуле:
Cλ – функция затрат для данного числа запросов;
cλ – фиксированная стоимость запроса;
di – длительность выполнения функции, мс;
C’λ – функция затрат для данного числа запросов;
N – общее число запросов за данный период.
С другой стороны, функция затрат для виртуальной машины EC2 зависит, в свою очередь, от времени ее работы, а также максимального числа запросов, которое она способна обработать (rmax).
CEC2 – функция затрат для данного периода T для виртуальной машины EC2;
rt – число запросов, которые необходимо обработать в секунду;
rmax – максимальное число запросов, которое виртуальная машина способна выполнить в секунду;
CEC2 – затраты за единицу времени (то есть одну секунду) для конкретной облачной ВМ;
T – временной период, за который проводится анализ затрат.
Сравнение эффективности работы бессерверных функций и облачных ВМ
Мы создали теоретическую модель, в которой попытались связать эффективность работы облачных ВМ и бессерверных функций, используя максимальное число запросов в секунду в качестве связующего параметра. В рамках этой модели мы можем выразить максимальную удельную производительность (число запросов в секунду) для облачной ВМ через объем памяти и время выполнения бессерверной функции следующим образом:
rmax – максимальное число запросов, которые облачная ВМ способна выполнить за единицу времени;
m – объем памяти облачной виртуальной машины, МБ;
S – память, выделенная на бессерверную функцию, МБ;
α – постоянный коэффициент, характеризующий относительный уровень пропускной способности.
Коэффициент α мы вводим в уравнение для того, чтобы учесть возможную разницу в производительности между обеими архитектурами. Как и с другими параметрами, которые мы уже успели обсудить в этой статье, этот коэффициент чрезвычайно сильно зависит от специфики приложения, поэтому оценивается он в каждом случае индивидуально — путем измерения фактического воздействия следующих аспектов:
объем памяти, потребляемый виртуальной машиной;
дополнительный расход памяти при создании единичного экземпляра функции, требуемой для выполнения каждого запроса (бессерверный случай) по сравнению с использованием одной уникальной ВМ, обрабатывающей множество вызовов функции (случай с облачными ВМ);
в случае функции, лимитируемой вычислениями, на время выполнения будет существенно влиять выбранная конфигурация ресурсов AWS Lambda, а с другой стороны, на выполнение функции, лимитируемой вводом-выводом, не сильно повлияет выбор Lambda-конфигурации с низкопроизводительным CPU, если эта конфигурация характеризуется еще и низким объемом оперативной памяти.
Мы можем определить коэффициент пропускной способности как количественное соотношение между объемом памяти, потребляемым бессерверной функцией и той же функцией, выполняемой как обычный код на облачной ВМ. Существует ряд аспектов, которые способствуют росту этого параметра, — например, если бессерверным функциям выделяются более низкопроизводительные CPU-ресурсы. Тем не менее есть и другие характеристики, которые снижают значение этой переменной, — например, уровень потребления оперативной памяти для облачной ВМ.
Ниже на графиках показан уровень месячных затрат в зависимости от объема запросов в секунду при разных коэффициентах пропускной способности α: 1, 5 и 10.
Технические допущения
Для того чтобы иметь возможность сравнивать цены на облачные ВМ с ценами на бессерверные функции, мы должны принять во внимание следующие допущения.
Общие инфраструктурные сервисы, используемые обеими архитектурами, здесь не учитываются, потому что их влияние в обоих случаях одинаково. В частности, затраты на API-шлюзы, передачу данных, хранение данных и другие облачные сервисы мы решили явным образом вывести за скобки настоящего исследования.
Для имитации высокой доступности бессерверных функций нашему сервису потребуется как минимум одна виртуальная машина, которая будет работать постоянно, вне зависимости от нагрузки. Именно поэтому предварительно зарезервированные виртуальные машины (с типами spot, preemptible и reserved) не учитываются в данном исследовании.
Чтобы справиться с пиковым спросом, наш сервис будет горизонтально масштабироваться при превышении определенного порога по числу запросов в секунду. Величина порога будет зависеть от типа используемой виртуальной машины: чем мощнее ВМ, тем больше запросов в секунду она сможет обработать. Таким образом, в данном исследовании нет сценария горизонтального масштабирования, при котором тип ВМ меняется в зависимости от ожидаемого роста нагрузки.
Наш сервис не применим для режима офлайн и задач пакетной обработки — запросы должны выполняться сразу после поступления, как можно быстрее.
Ценовые данные для проведения исследования мы брали из тарифов AWS EC2 и тарифов AWS Lambda по состоянию на февраль 2018 года.
Прикладная модель и ее параметры
Для моделирования приложения для обеих архитектур нужно определить значения следующих параметров:
общее число запросов за исследуемый период;
длительность выполнения запроса в миллисекундах;
уровень потребляемой памяти на каждый запрос;
распределение запросов во времени: несмотря на то, что для бессерверной архитектуры это распределение не играет роли, на динамику вычислительных ресурсов, выделяемых под облачные ВМ, оно все же влияет.
Несмотря на то, что параметры обеих архитектур одинаковы, их численные значения возможно не будут одинаковыми для конкретного исследуемого сервиса.
Общий объем памяти, необходимой для выполнения одного запроса, в бессерверной архитектуре оказывается выше, чем для облачных ВМ. Бессерверный сервис должен создать среду исполнения — и уровень потребляемой им памяти обычно оказывается заметно выше при такой архитектуре.
Именно поэтому мы не можем просто поделить общий объем оперативной памяти на виртуальной машине на число Lambda-функций и сравнить полученную величину с уровнем потребления памяти для Lambda-функций: такой подход будет несправедлив по отношению к облачным ВМ.
Как мы уже говорили, мы будем использовать коэффициент пропускной способности α для учета данного отличия между двумя архитектурами.
Но при этом мы будем считать, что время исполнения запроса в обеих архитектурах одинаковое. Тем не менее стоит упомянуть, что провайдеры (например, AWS) выделяют вдвое больше CPU-ресурсов в тот момент, когда бессерверная конфигурация удваивает свой объем памяти. В случае платформы Google Cloud Platform этого не происходит, поскольку конфигурации, представленные на этой платформе, имеют разные сочетания объемов памяти и вычислительной мощности.
Соответственно, при принятии решения о том, какую конфигурацию бессерверных ресурсов выбрать в случае AWS Lambda, стоит учитывать, что конфигурация (определенная только в терминах памяти) повлияет исключительно на время выполнения запроса Lambda-функцией, если эта функция требует интенсивных вычислений (в случае функций, требовательных к оперативной памяти и операциям ввода-вывода, ситуация иная).
Исходя из этих предпосылок, как же нам выбрать конфигурацию бессерверных ресурсов в AWS Lambda?
Сначала мы должны выбрать минимальную конфигурацию Lambda, способную выполнить наш код.
Затем выбрать какую-то одну конфигурацию бессерверной функции, способную на постоянной основе выполнять наши требования по уровню обслуживания (число запросов в секунду).
Мы должны понять, чем будет лимитироваться выполнение нашего кода: вычислениями или операциями ввода-вывода.
а) Если код лимитируется вычислениями, следует использовать самую мощную из доступных конфигураций AWS Lambda. Это позволит обеспечить максимальный уровень сервиса при той же цене.
б) Если код лимитируется операциями ввода-вывода, следует использовать минимальную из доступных конфигураций AWS Lambda. Это позволит обеспечить приемлемый уровень сервиса при минимальных затратах.
Мы рекомендуем провести оценку этих лимитирующих факторов для вашего кода. Так вы сможете оптимизировать свое приложение с точки зрения цены и гарантировать, что новый функционал или модификации кода не будут непомерно увеличивать издержки. При сборке приложений это особенно ценно — заранее знать, как любое изменение может сказаться на затратах.
Проведенное моделирование
Наша команда BBVA-Labs задалась вопросом, как организовать сравнительный анализ затрат, который бы учитывал как можно больше различных ситуаций. Мы хотели создать среду, которая, оставаясь предельно унифицированной, могла бы гибко применяться к максимальному спектру сценариев.
Отдавая себе в этом отчет, мы постарались выбрать такую среду моделирования, которая позволила бы тонко настроить сразу несколько параметров и оптимально подстроиться под ситуацию. В качестве рабочей среды мы использовали блокноты Jupyter Notebooks с Python 3.6, а также библиотеки pandas и NumPy. Помимо блокнотов мы разработали ряд пакетов Python, включающих в себя все нюансы учета и моделирования затрат.
Наконец, чтобы наиболее убедительно показать, как работает сравнение цены, мы решили использовать наиболее часто используемые типы виртуальных машин.
С учетом всего этого мы смоделировали разные сценарии использования, сделав при этом ряд допущений и изучив, как они влияют на модель, а также выделив наиболее важные переменные для этапа проектирования сервиса.
Исходный код наших Jupyter-блокнотов и пакетов Python можно скачать из нашего открытого репозитория BBVA на GitHub.
Случай 1: однородная интенсивность обработки запросов в течение всего месяца («нереалистичный сценарий»)
Сценарий
Данный сценарий включает моделирование однородно распределенных запросов в течение месяца. Мы проанализировали, каким образом растут затраты в зависимости от интенсивности обработки запросов конкретным сервисом.
Построив распределение запросов, мы смогли рассчитать затраты при использовании виртуальных машин AWS EC2 и функций AWS Lambda, установив максимальную интенсивность запросов (число запросов в секунду), при которой каждая из конфигураций EC2 еще способна справиться с задачей, но при более высокой интенсивности будет уже горизонтально масштабироваться с созданием еще одной виртуальной машины. Вместо того чтобы использовать произвольные значения для каждой конфигурации EC2, мы можем использовать коэффициент пропускной способности α, о котором мы говорили в разделе 1.4. В самом деле, здесь мы можем применять графики, полученные в результате того анализа, поскольку при построении этих графиков мы исходили из допущения о равномерном распределении запросов в течение всего месяца.
Те же самые допущения действуют и в отношении конфигурации Lambda. Давайте посмотрим, какой размер оперативной памяти и время выполнения лучше выбрать.
Для целей этого конкретного исследования мы выбрали конфигурацию со 128 МБ памяти и временем запроса 200 миллисекунд. Здесь можно использовать разные значения, но для простоты в большинстве случаев мы используем фиксированные значения для длительности запроса (d) и объема памяти. Варьирование каждого из этих параметров «подняло» бы графики по вертикали, но форма и наклон этих кривых остался бы прежним.
Мы рекомендуем вам сделать форк нашего репозитория и поиграться с нашими блокнотами — так вы сможете более тонко подстроить параметры и учесть специфичные требования вашего конкретного сервиса.
Большинство исследований экономики сервисов на этом и останавливается. Однако в реальном мире запросы не приходят стройными рядами и с однородной интенсивностью. Поэтому мы задались вопросом, как неоднородность повлияет на экономическую сторону дела.
Случай 2: более «очеловеченная» модель
Несмотря на то, что предыдущее исследование дает нам возможность грубо оценить, каким образом масштаб спроса влияет на затраты, вряд ли можно представить себе реальный сценарий, при котором постоянный объем запросов в секунду соблюдался бы в течение целого месяца.
Сценарий
Мы решили построить более приближенный к реальному миру сценарий, который позволил бы нам смоделировать трафик, создаваемый глобально распределенной базой пользователей и принимающий во внимание наличие разных временных зон и культурных привычек. Для этого мы создали модель, основанную на исторических данных о трафике (объеме визитов) на сайте Википедии, и построили для нее распределение запросов. Затем мы применили к этому распределению фактор масштабирования, чтобы достичь требуемого суммарного уровня запросов в месяц.
Для случайно выбранной недели на сайте английской Википедии распределение запросов получается таким:
Поскольку исторические данные по неделям говорят о сильном факторе сезонности, мы привели все запросы на сайте Википедии за весь год к одной среднеуникальной неделе. Затем мы построили синтетический месяц запросов к сайту Википедии, получив общий объем в 100 млн запросов в месяц, а затем нормализовали полученное распределение.
Используя полученное распределение запросов, давайте перейдем к расчету затрат, связанных с работой виртуальной машины EC2 и функций AWS Lambda.
Исходя из допущений, сделанных с точки зрения сервисных характеристик (объема используемой оперативной памяти, времени выполнения и т. д.), мы можем посмотреть на динамику затрат в бессерверной инфраструктуре по сравнению с более традиционной инфраструктурой на базе облачных ВМ.
Но как же меняются эти значения с ростом общего числа запросов в месяц (то есть при масштабировании)? Мы рассчитали, при каком уровне запросов по сравнению с общим объемом запросов в месяц будет достигнута точка равноценности этих двух инфраструктур. Для простоты восприятия мы используем среднее число запросов в секунду в течение месяца:
Используя этот последний график, мы можем визуально оценить, насколько Lambda-архитектура оказалась бы более дорогой, если бы мы начали получать больше ожидаемого числа запросов в месяц.
Инсайты
Приведенные выше цифры позволяют нам сделать следующие выводы.
Первая точка равноценности достигается для Lambda-функции с памятью 128 МБ примерно при 90 млн запросов в месяц (средняя интенсивность
35 запросов в секунду). Если использовать Lambda-функцию с памятью 256 МБ, то эта точка окажется уже в районе 52 млн запросов в месяц (средняя интенсивность
20 запросов в секунду).
Как только для конкретной конфигурации Lambda-функции и виртуальной машины EC2 будет достигнута точка равноценности, кривая начнет двигаться вверх очень быстро, и Lambda-функция окажется гораздо более затратной, чем виртуальная машина EC2. Положение этой критической точки очень чувствительно к приросту буквально на несколько тысяч запросов в месяц.
Точка равноценности, при которой виртуальные машины EC2 становятся более экономически эффективными, чем Lambda-функции, достигается при использовании всего одной виртуальной машины, поэтому горизонтальное масштабирование по числу облачных ВМ не требуется. Таким образом, вклад коэффициента пропускной способности в данном случае некритичен.
Важный вывод в данном случае такой: экономические преимущества перехода на бессерверную архитектуру быстро теряются, как только затраты на сервис превышают точку равноценности. Тем не менее, если рост числа запросов обусловлен наличием дискретных пиков в определенные моменты времени, это может быть допустимо.
Стоит тем не менее помнить, что эти значения очень чувствительны к максимальной интенсивности запросов, которую виртуальная машина способна обработать, а также к объему памяти и длительности выполнения запроса со стороны Lambda-функции.
Случай 3: живые пользователи и локализованный трафик
Проанализировав, каким образом растут затраты при масштабировании спроса с учетом глобального уровня нагрузки со стороны реальных пользователей, мы задались вопросом, как же изменятся результаты анализа затрат, если трафик будет более агрессивно распределяться в течение дня, например в случае приложения, ориентированного на конкретный регион. Пример для реализации такого сценария — локальное веб-приложение органа местного самоуправления, карта метро или схема движения общественного транспорта.
Сценарий
Для целей этого анализа мы выбрали датский язык как наиболее территориально локализованный язык Википедии. Вот как выглядит распределение трафика за одну неделю:
Исходя из этого, мы построили некий синтетический месяц, точно так же, как в предыдущем примере. Обратите внимание, насколько ситуация отличается от мировой.
В рамках данной модели мы построили синтетический месяц с целью анализа работы локализованного регионального приложения. Масштаб сервиса (то есть общий объем запросов в течение данного месяца) снова оказывается на уровне 100 млн (
38,6 запросов в секунду). Влияет ли это почасовое распределение запросов на уровень затрат по сравнению с предыдущим случаем? Ответ — нет. Точка равноценности достигается в том же диапазоне, что и в предыдущем случае.
Случай 4: сервис типа «машина-машина»
В нашем последнем эксперименте мы решили выяснить, какие факторы будут сильнее всего влиять на модели тарификации Lambda и EC2 в тех случаях, когда трафик нашего приложения генерируется совокупностью устройств, отправляющих запросы через равные промежутки времени. Этот случай соответствует приложениям интернета вещей, например распределенной сети датчиков.
Как и в случае с предыдущими экспериментами, наша задача заключалась в том, чтобы построить распределение запросов. В данном случае распределение определялось следующими параметрами.
Устройство должно отправлять запросы нашему сервису с регулярными интервалами, установленными в параметре период устройства. Все устройства обращаются к серверу именно с этой заданной частотой.
Запросы от всей совокупности устройств в течение заданного периода следуют равномерному распределению.
Эта модель позволила нам создать симулятор запросов, который использует период устройства и число устройств в качестве входных параметров. Получив на выходе распределение запросов за период времени (период моделирования), мы смогли легко рассчитать соответствующие ему затраты для EC2 и Lambda.
Затем мы получили профили затрат и для Lambda, и для различных конфигураций EC2, последовательно увеличивая число устройств.
Выборка устройств и период устройства
Чем больше у нас устройств, тем выше интенсивность запросов за один и тот же период. Как эти две величины соотносятся друг с другом?
Например, если каждое устройство делает запросы каждый час, то есть период устройства составляет 3600 секунд, целевой показатель в 100 запросов в секунду достигается при 360 000 устройств.
Как и в предыдущей модели, точка равноценности достигается для каждой конфигурации EC2 в тот момент, когда она начинает обходиться нам дешевле, чем соответствующая ей Lambda-функция. При этом также интересно заметить, что с ростом мощности виртуальных машин EC2 шанс того, что какая-нибудь из них будет недозагружена, также возрастает — это приводит к росту нецелевого использования ресурсов, а значит, и стоимости.
По нашим наблюдениям, затраты на EC2 чуть более высоки, чем в теоретической модели. Тем не менее общее соотношение между затратами остается примерно тем же, если использовать коэффициент пропускной способности, равный 1.
Lambda-функция оказывается экономически более эффективной при низкой интенсивности запросов (
В рамках настоящего анализа мы условно наложили на имеющиеся данные один большой пик в начале месяца и еще один пик с той же высотой, но более длительный по времени, в конце месяца.
Небольшой пик в стоимости виртуальных машин EC2 соответствует всплескам трафика — его можно объяснить тем, что группы автоматического масштабирования порождают больше виртуальных машин: эти ВМ нужны, чтобы обработать избыточный трафик, и поэтому временно увеличивают затраты.
Выводы
Распределение трафика действительно оказывает существенное влияние на точку равноценности, а значит, и на уровень затрат. Ранее мы рассмотрели, как можно определить точку равноценности для равномерного распределения запросов, а затем и для более реалистичного профиля трафика.
При таком профиле трафика, когда запросы приходят с периодическими интервалами, но общий объем запросов невелик, бессерверная архитектура выглядит замечательно — не только с точки зрения затрат, но и скорости передачи данных и объема трудозатрат. Поэтому, если у нашего приложения есть периоды достаточно длительной неактивности, Lambda-функция — это отличный выход.
Как только инфраструктура проходит точку равноценности и виртуальные машины EC2 становятся более экономически эффективными, чем Lambda-функции, различие по затратам начинает очень быстро расти, что делает решение AWS Lambda все менее привлекательным с позиций цены. Таким образом, крайне важно знать, будет ли ожидаемый объем трафика находиться где-то вблизи точки равноценности или нет.
Не нужно при этом недооценивать экономию в результате переноса HTTP-инфраструктуры на уровень облачного провайдера. Кроме того, благодаря удобству планирования и развертывания систем с высоким уровнем доступности точка равноценности может оказаться существенно сдвинута в большую сторону по сравнению с нашими теоретическими оценками, и тогда применение Lambda-функций окажется с экономической точки зрения весьма эффективным.
Также не следует забывать о тротлинге процессора, с которым неизбежно придется столкнуться при выборе конфигураций Lambda с низкой оперативной памятью. Если ваш код лимитируется вычислениями, выбор конфигураций с относительно небольшим объемом оперативной памяти — не самый лучший выбор, поскольку время выполнения, а значит, и задержка могут выйти за рамки предельно допустимых. С другой стороны, если ваш код лимитируется процессами ввода-вывода, тротлинг процессора не особо скажется на его исполнении.
Где именно окажется точка равноценности (если ее, конечно, удастся достигнуть), сильно зависит от специфики приложения. Соответственно, без измерения характеристик целевого прикладного кода, целевых уровней использования сервиса, уровней SLA, а также возможностей ответственной за сервис команды разработчиков, практически невозможно с уверенностью сказать, какой же из сервисов окажется удобнее в эксплуатации — Lambda или EC2.
Если вам интересна экосистема Serverless-сервисов и все, что с этим связано, заходите в наше сообщество в Telegram, где можно обсудить serverless в целом.



