Алфавит (информатика)

В информатике алфавит — это множество (как правило конечное) символов или букв, например латинских букв и цифр. Примером распространённого алфавита является двоичный алфавит <0,1>. Конечная строка — это конечная последовательность букв алфавита. Например, двоичная строка — это строка из символов алфавита <0,1>. Также возможно построение бесконечных последовательностей из букв алфавита.
Пусть дан алфавит  . Тогда
. Тогда  обозначает множество всевозможных строк из символов алфавита . Здесь
обозначает множество всевозможных строк из символов алфавита . Здесь  обозначен оператор звезда Клини. Запись
обозначен оператор звезда Клини. Запись  (или иногда
(или иногда  или
или  ) обозначает множество всех бесконечных последовательностей символов из алфавита .
) обозначает множество всех бесконечных последовательностей символов из алфавита .
Например, для алфавита <0,1>строки <ε, 0, 1, 00, 01, 10, 11, 000, и так далее>составляют его замыкание Клини (где ε обозначает пустую строку).
Алфавиты играют важную роль в теории формальных языков, автоматов и полуавтоматов. В большинстве случаев для определения сущности автоматов, таких как детерминированный конечный автомат (ДКА), требуется задать алфавит, из которого составляются входные строки для автомата.
См. также

Полезное
Смотреть что такое «Алфавит (информатика)» в других словарях:
Алфавит (математика) — Эту страницу предлагается объединить с Алфавит (информатика). Пояснение причин и обсуждение на странице Википедия:К объединению/14 сентября 2012. Обсуждение длится одну неделю (или дольше, если оно идёт медленно). Дата начала обсуждения 2012 09… … Википедия
ДРАКОН — Эта статья предлагается к удалению. Пояснение причин и соответствующее обсуждение вы можете найти на странице Википедия:К удалению/28 сентября 2012. Пока процесс обсуждения не завершён, статью мож … Википедия
ДРАКОН (алгоритмический язык) — У этого термина существуют и другие значения, см. Дракон (значения). Пример блок схемы алгоритма на языке ДРАКОН дракон схемы ДРАКОН (Дружелюбный Русский Алгоритмический язык, Который Обеспечивает Наглядность) визуальный… … Википедия
Мнемоника — Содержание 1 Основной метод запоминания в современной мнемонике 2 История … Википедия
Информация — (Information) Информация это сведения о чем либо Понятие и виды информации, передача и обработка, поиск и хранение информации Содержание >>>>>>>>>>>> … Энциклопедия инвестора
ОСАНКА — привычное положение тела человека в покое и при движении. При правильной О. тело постоянно и без напряжения сохраняет выпрямленное положение, плечи слегка отведены назад, живот подобран. Такая О. делает фигуру красивой, способствует правильному… … Российская педагогическая энциклопедия
ОСНОВЫ ИНФОРМАТИКИ И ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ — (ОИВТ), уч предмет, введенный в ср у ч заведения Рос Федерации с 1985/86 у ч г. Предусматривает изучение законов и методов сбора, передачи и обработки информации с помощью электронной вычислит техники Цель обучения ОИВТ формирование «компьютерной … Российская педагогическая энциклопедия
ЗНАК — материальный объект (артефакт), выступающий в коммуникативном или трансляционном процессе аналогом другого объекта (предмета, свойства, явления, понятия, действия), замещающий его. 3. является осн. средством культуры, с его помощью… … Энциклопедия культурологии
Вертикальная черта — | ¦ Вертикальная черта Пунктуация апостроф ( … Википедия
Список терминов, относящихся к алгоритмам и структурам данных — Это служебный список статей, созданный для координации работ по развитию темы. Данное предупреждение не устанавливается на информационные списки и глоссарии … Википедия
Язык и алфавит представления информации
Вы будете перенаправлены на Автор24
Общее понятие кодирования информации
Познание окружающего мира начинается с восприятия его человеком с помощью органов чувств. Зрение, вкус, слух, обоняние, осязание доводят до нашего сознания информацию о самых разнообразных свойствах предметов, а также явлениях и процессах, происходящих вокруг нас. Эта информация поступает к нам в виде набора символов или сигналов. Однако если эти символы или сигналы никому не ясны, то информация будет бесполезной. Поэтому требуется язык общения, который будет понятен всем.
Естественные и формальные языки представления информации
Язык — это знаковая система для представления и передачи информации.
Естественный язык можно формализовать. Так для формализации музыки изобрели нотную грамоту, для формализации речи создали национальные алфавиты (например, латинский ($26$ символов), русский ($33$ символа)), кроме этого арабские цифры, азбуку Морзе и т.д.
Естественные языки развивались веками и служили для общения людей между собой. Формальные языки разрабатываются для специальных применений.
Коммуникативный язык несет в себе логическую информацию, именно с помощью него человек преобразует получаемую информацию в знания и передает эти знания другим людям.
Алфавиты представления информации
Первобытные люди для обозначения каждого нового предмета придумывали новые имена. Для получения необходимого разнообразия имен, названий они стали комбинировать звуки таким образом, чтобы получить в результате слова. Так в ходе эволюции человека появилась идея создания конечного алфавита, т.е. некоторого фиксированного набора знаков, из которого можно составить как угодно много слов. Комбинация знаков алфавита называется словом. Из слов можно составлять фразы, которые будут нести определенную смысловую нагрузку.
Готовые работы на аналогичную тему
Таким образом, алфавит – это упорядоченный набор символов или сигналов, который составляет основу языка.
Человек в своей практике общения использует самые разнообразные языки (например, дорожная грамота, включающая в себя знаки дорожного движения и разметки). Прежде всего, это, конечно же, языки устной и письменной речи, в том числе и иностранные.
Кроме того, человек использует ряд языков профессионального назначения. К ним относятся языки математических и химических формул, обозначений электроники (например, схема электрической цепи), языки программирования. При этом каждый язык имеет свой алфавит.
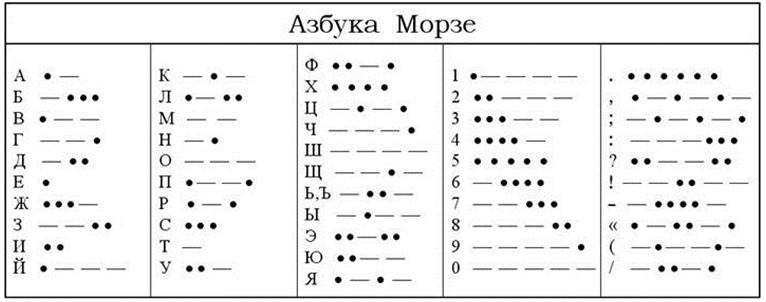
С развитием технических средств передачи информации появилась необходимость использования помимо речевых алфавитов многих других. Одним из примеров первых алфавитов, используемых в технике, является азбука Морзе, в которой каждому знаку обычного алфавита соответствует набор точек и тире.
Общее понятие кодирования информации
Воспринимая информацию, человек стал стремиться зафиксировать ее таким образом, чтобы она стала понятной для других, представляя ее в той или иной форме.
Музыкальную тему композитор может наиграть на пианино, а затем записать с помощью нот. Образы, навеянные все той же мелодией, поэт может воплотить в виде стихотворения, хореограф выразить танцем, а художник — в картине.
Люди сохраняют свои знания, записывая их на различных носителях. Благодаря чему эти знания передаются не только в пространстве, но и во времени — от одного поколения к другому.
До наших дней дошли послания предков, которые с помощью различных символов пытались изобразить себя и свои поступки в памятниках и надписях. Примером могут служить наскальные рисунки (петроглифы), которые по сей день представляют загадку для ученых. Вероятнее всего, таким образом древние люди пытались вступить в контакт с будущими поколениями и сообщить о событиях их жизни.
Каждый народ имеет свой язык, состоящий из набора символов (букв): русский, английский, японский и многие другие. Об этом уже упоминалось ранее.
Представление информации с помощью какого-либо языка часто называют кодированием.
Код — это набор символов либо условных обозначений, используемый для представления информации.
Алфавит кодирования содержит полный набор кодов.
Кодирование — это процесс представления информации с помощью кода.
Так водитель пытается передать сигнал с помощью гудка или мигания фар. В данном случае гудок (его наличие или отсутствие) – это код, а в случае световой сигнализации кодом будет являться мигание фар или его отсутствие. Пешеход встречается с кодированием информации при переходе дороги по сигналу светофора. Код определяет цвет светофора — красный, желтый, зеленый.
Естественный язык, на котором мы общаемся, тоже представляет собой код, называемый алфавитом. Во время устной речи этот код передается звуками, при письменной — буквами. Причем одну и ту же информацию можно представить различными способами. К примеру, запись разговора можно закодировать на бумажном носителе двумя способами: с помощью букв или специальных стенографических знаков.
В более узком смысле под кодированием часто понимают переход от одной формы представления информации к другой, которая более удобна при хранении, передаче или обработке.
В процессе развития технических средств появлялись новые способы кодирования информации. Так во второй половине XIX века американский изобретатель Сэмюэль Морзе придумал удивительно простой код, который применяется до сих пор. Используя этот код, информацию можно представить в виде: длинного сигнала (тире), короткого сигнала (точки) и отсутствия сигнала (паузы) для разделения букв. Таким образом, принцип кодирования сводился к использованию набора символов, расположенных в строго определенном порядке.
Люди во все времена пытались найти способы быстрого обмена сообщениями. Для этого существовали гонцы, использовались почтовые голуби. Разные народы использовали различные способы оповещения о надвигающейся опасности: это и барабанный бой, и дым костров, и набат колокола, и флаги определенных цветов и пр. Однако при передаче таким способом информации требовалась предварительная договоренность, чтобы принимаемые сообщения были поняты.
Знаменитый немецкий ученый Готфрид Вильгельм Лейбниц предложил еще в XVII веке уникальную по своей простоте систему представления чисел, основанную на использовании вычислений с помощью двоек.
Способ кодирования информации зависит от цели, которая при этом должна быть достигнута. Целью может являться сокращение записи, засекречивание (шифровка) информации, или, напротив, достижение взаимопонимания. Например, система дорожных знаков, флажковая азбука на флоте, специальные научные языки и символы ― химические, математические, медицинские и др., предназначены для того, чтобы люди могли общаться и понимать друг друга. От того, как представлена информация, зависит способ ее обработки, хранения, передачи и т.д.
Информатика. 7 класс
Конспект урока
Единицы измерения информации
Перечень вопросов, рассматриваемых в теме:
Каждый символ информационного сообщения несёт фиксированное количество информации.
Единицей измерения количества информации является бит – это наименьшаяединица.
1 Кб (килобайт) = 1024 байта= 2 10 байтов
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Формулы, которые используются при решении типовых задач:
Информационный объём сообщения определяется по формуле:
I – объём информации в сообщении;
К – количество символов в сообщении;
i – информационный вес одного символа.
Теоретический материал для самостоятельного изучения.
Любое сообщение несёт некоторое количество информации. Как же его измерить?
Одним из способов измерения информации является алфавитный подход, который говорит о том, что каждый символ любого сообщения имеет определённый информационный вес, то есть несёт фиксированное количество информации.
Сегодня на уроке мы узнаем, чему равен информационный вес одного символа и научимся определять информационный объём сообщения.
Что же такое символ в компьютере? Символом в компьютере является любая буква, цифра, знак препинания, специальный символ и прочее, что можно ввести с помощью клавиатуры. Но компьютер не понимает человеческий язык, он каждый символ кодирует. Вся информация в компьютере представляется в виде нулей и единичек. И вот эти нули и единички называются битом.
Информационный вес символа двоичного алфавита принят за минимальную единицу измерения информации и называется один бит.
Эту формулу можно применять для вычисления информационного веса одного символа любого произвольного алфавита.
Алфавит древнего племени содержит 16 символов. Определите информационный вес одного символа этого алфавита.
Составим краткую запись условия задачи и решим её:
Информационный вес одного символа этого алфавита составляет 4 бита.
Сообщение состоит из множества символов, каждый из которых имеет свой информационный вес. Поэтому, чтобы вычислить объём информации всего сообщения, нужно количество символов, имеющихся в сообщении, умножить на информационный вес одного символа.
Математически это произведение записывается так: I = К · i.
Например: сообщение, записанное буквами 32-символьного алфавита, содержит 180 символов. Какое количество информации оно несёт?
I = 180 · 5 = 900 бит.
Итак, информационный вес всего сообщения равен 900 бит.
В алфавитном подходе не учитывается содержание самого сообщения. Чтобы вычислить объём содержания в сообщении, нужно знать количество символов в сообщении, информационный вес одного символа и мощность алфавита. То есть, чтобы определить информационный вес сообщения: «сегодня хорошая погода», нужно сосчитать количество символов в этом сообщении и умножить это число на восемь.
I = 23 · 8 = 184 бита.
Значит, сообщение весит 184 бита.
Как и в математике, в информатике тоже есть кратные единицы измерения информации. Так, величина равная восьми битам, называется байтом.
Бит и байт – это мелкие единицы измерения. На практике для измерения информационных объёмов используют более крупные единицы: килобайт, мегабайт, гигабайт и другие.
1 Кб (килобайт) = 1024 байта= 2 10 байтов
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Итак, сегодня мы узнали, что собой представляет алфавитный подход к измерению информации, выяснили, в каких единицах измеряется информация и научились определять информационный вес одного символа и информационный объём сообщения.
Материал для углубленного изучения темы.
Как текстовая информация выглядит в памяти компьютера.
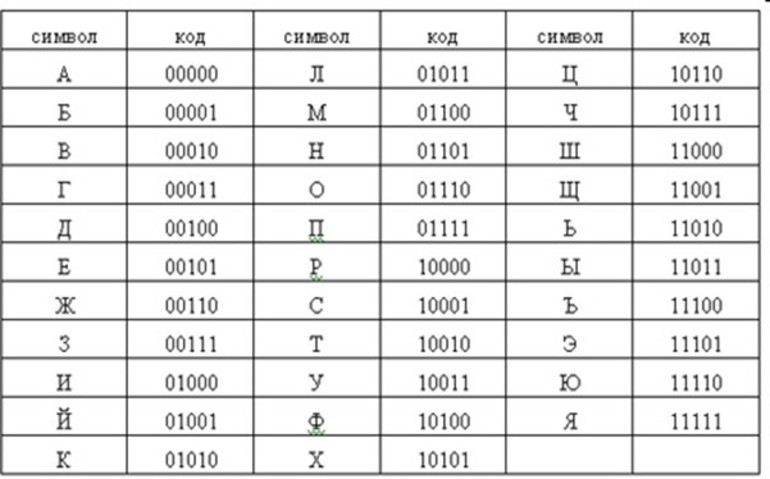
Набирая текст на клавиатуре, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111. Теперь возникает вопрос, какой именно восьмизначный двоичный код поставить в соответствие каждому символу?
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код ‑ просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.Таблица для кодировки – это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для разных типов компьютеров используются различные таблицы кодировки.
Таблица ASCII (или Аски), стала международным стандартом для персональных компьютеров. Она имеет две части.

В этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуем решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.

Вывод: все тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные для нас буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти же компьютера текст может быть выведен на экран или на печать в символьной форме.
Сейчас используют целых пять систем кодировок русского алфавита (КОИ8-Р, Windows, MS-DOS, Macintosh и ISO). Из-за количества систем кодировок и отсутствия одного стандарта, очень часто возникают недоразумения с переносом русского текста в компьютерный его вид. Поэтому, всегда нужно уточнять, какая система кодирования установлена на компьютере.
Разбор решения заданий тренировочного модуля
№1. Определите информационный вес символа в сообщении, если мощность алфавита равна 32?
№2. Выразите в килобайтах 2 16 байтов.
2 6 = 64, а 2 10 байт – это 1 Кб. Значит, 64 · 1 = 64 Кб.
№3. Тип задания: выделение цветом
8 х = 32 Кб, найдите х.
ГИА и ЕГЭ по информатике
Блог для учеников и учителей информатики. Задания и решения ГИА
Популярные сообщения
Словарь терминов по информатике
СЛОВАРЬ ТЕРМИНОВ ПО ИНФОРМАТИКЕ
Абзац – фрагмент текста, заканчивающийся нажатием клавиши Enter.
Алгоритм – точное и понятное указание исполнителю совершить конечную последовательность действий, направленных на достижение указанной цели или на решение поставленной задачи.
Алгоритмизация – разработка алгоритма решения задачи.
Алфавит – конечное множество объектов, называемых буквами или символами.
Аппаратный интерфейс – устройство, обеспечивающее согласование между отдельными блоками вычислительной системы.
Арифметическо-логическое устройство – часть процессора, предназначенная для выполнения арифметических и логических операций.
Архивация данныхорганизация хранения данных в удобной и легкодоступной форме, снижающей затраты на хранение и повышающей общую надежность информационного процесса.
Архитектура ЭВМ – общее описание структуры и функций ЭВМ на уровне, достаточном для понимания принципов работы и системы команд ЭВМ. Архитектура не включает в себя описание деталей технического и физического устройства компьютера.
База данных – хранящаяся во внешней памяти ЭВМ совокупность взаимосвязанных данных, организованных по определенным правилам, предусматривающим общие принципы их описания, хранения и обработки.
Базовая аппаратная конфигурация – типовой набор устройств, входящих в вычислительную систему. Включает в себя системный блок, клавиатуру, мышь и монитор.
Базовое программное обеспечение – совокупность программ, обеспечивающих взаимодействие компьютера с базовыми аппаратными средствами.
Байт – 1. восьмиразрядное двоичное число; 2. элемент памяти, позволяющий хранить восьмиразрядное двоичное число.
Буфер обмена – область оперативной памяти, к которой имеют доступ все приложения и в которую они могут записывать данные или считывать их.
Векторный редактор – графический редактор, использующий в качестве элемента изображения линию, являющуюся кривой третьего порядка. Используется, когда форма линии важнее информации о цвете.
Видеопамять – участок оперативной памяти компьютера, в котором хранится код изображения, выводимого на дисплей.
Внедрение – включение объекта в документ, созданный другим приложением.
Внешняя память – память большого объема, служащая для долговременного хранения программ и данных.
Вычислительная сеть (компьютерная сеть) – соединение двух и более компьютеров с помощью линий связи с целью объединения их ресурсов.
Базовое программное обеспечение – совокупность программ, обеспечивающих взаимодействие компьютера с базовыми аппаратными средствами.
Гибкий магнитный диск – устройство, предназначенное для переноса документов и программ с одного компьютера на другой, хранения архивных копий программ и данных, не используемых постоянно на компьютере.
Графический редактор – программа, предназначенная для создания и обработки графических изображений.
Данные – зарегистрированные сигналы.
Диаграмма – любой видов графического представления данных в электронной таблице.
Диалоговое окно – разновидностью окна, позволяющая пользователю вводить в компьютер информацию.
Диалоговый режим – режим работы операционной системы, в котором она находится в ожидании команды пользователя, получив её, приступает к исполнению, а после завершения возвращает отклик и ждёт очередной команды.
Диапазон – совокупность ячеек электронной таблицы, образующихся на пересечении группы последовательно идущих строк и столбцов.
Диспетчер файлов (файловый менеджер) – программа, выполняющая операции по обслуживанию файловой системы.
Документ Windows– любой файл, обрабатываемый с помощью приложений, работающих под управлением операционной системы Windows.
Драйвер – программа, обеспечивающая взаимодействие компьютера с внешним устройством.
Жесткий магнитный диск (ЖМД) – внешняя память компьютера, предназначенная для постоянного хранения данных, программ операционной системы и часто используемых пакетов программ.
Запрос – объект, служащий для извлечения данных из таблиц и предоставления их пользователю в удобном виде.
Интерфейс – набор правил, с помощью которых осуществляется взаимодействие элементов систем
Информатика – наука, изучающая закономерности получения, хранения, передачи и обработки информации в природе и человеческом обществе.
Информационная система – система, способная воспринимать и обрабатывать информацию.
Мощность алфавита в информатике

Описание термина
Понятие мощности алфавита находится в основании изучения информатики. Алфавитом принято называть набор многочисленных символов. Сумма всех их в определённом языке и есть алфавитная мощность. Иными словами, это количество всех символов, входящих в конкретно взятый язык. Сюда входят не только буквы, но и прочие обозначения, в частности:

Это определение считается обобщённым и не принимает во внимание вычисления информационной составляющей сообщения. Она может содержать в себе числа, знаки препинания и прочее. В этом случае прибегают к использованию другого способа. Его суть основывается на том, что любая буква, цифра или знак обладают собственным информационным объемом данных. Компьютер работает с этим информационным кодом и распознает то, что было написано.
Основным постулатом в информатике является тот факт, что устройство разбирает введённую информацию исключительно в двоичном коде в форме нуля и единицы. В итоге получается, что абсолютно любой символ алфавита может быть успешно закодирован при помощи соответствующего подбора этих двух цифровых символов. Самая маленькая последовательность, применяемая при обозначении какой-либо цифры, буквы или другого знака, состоит из двух элементов.
Информационная масса отдельно взятого символа обычно изображается в форме информационной стандартной измерительной единицы, которая называется «бит». Восемь битов становятся равны одному байту.
Отображение символов в двоичном коде
Алфавитная мощность может быть использована на практике только при наличии двоичного кода. В качестве примера можно использовать упрощённый алфавит, состоящий всего из четырёх символов. В этом случае разрядность их и информационное представление описываются следующим образом:
Из этого списка можно сделать вывод о том, что если алфавитная мощность равняется 4, то масса отдельного единичного символа будет составлять 2 бита. Если же есть алфавит, состоящий из 8 символов, то при подборе двоичного трёхзначного кода для него комбинационное количество будет следующим:
Иными словами, если алфавитная мощность равна 8, то вес отдельно взятого символа для двоичного трёхзначного кода составит 3 бита.
Вычисление мощности алфавита

Эта формула была изобретена американским инженером Ральфом Хартли более сотни лет тому назад. Она применяется для работы с равновероятными событиями и используется для определения мощности конкретного буквенного набора, которая обозначается буквой N (информационная масса или объём). n означает численность бит в словесной единице, иными словами, количество знаков внутри двоичного кода. Так, если n равен 1, то N тоже равен 1, при n = 2 N = 4, при n = 3 N = 8, при n = 4 N = 16.
Чтобы сформулировать теорию о численности информации в набранном словосочетании, пользуются формулой I=K*i. В этом случае К обозначает численность всех символов в предложении, а i — это информационная масса символа.
При ответе на вопрос, как найти мощность алфавита, нужно сказать, что в русском языке 33 буквы, поэтому это можно выразить как N = 33. Для сравнения, аналогичный показатель в английском, немецком и французском языках равняется 26, в испанском — 27. Венгерский язык, например, является 40-символьным.
Существует также и клавиатурный язык, куда входят не только буквы, но и дополнительные знаки. Так, в русском языке есть ещё 10 цифр и 11 символов, а также пробел и пара скобок. Их мощность прибавляется к аналогичному буквенному показателю, и на выходе получается N = 33+10+11+1+2=57. В некоторых случаях букву «ё» не выделяют в качестве отдельного самостоятельного символа, и в таком случае полная мощность русского алфавита становится равна 56.
Определение информационного объёма в тексте
Почти всегда при наборе текста на компьютерах и других электронных устройствах приходится сталкиваться с написанием различных символов. К ним следует отнести:
По всем расчётам получается, что мощность компьютерного алфавита составляет 256 различных символов и вариантов. В соответствии с формулой Хартли, N = 256, а i — масса любого из значков в клавиатурном алфавите соответствует одному байту, или восьми битам.

Размер любой напечатанной фразы может быть вычислен по формуле V=K ⋅ log2N. В этом случае N обозначает количество всех символов в алфавите, а K — это численность знаков непосредственно в напечатанной фразе. Так, например, имеется произвольный текст объёмом в 25 листов. На каждом из них расположено по 45 строчек текста, содержащих по 58 символов.
Исходя из этого, на любой отдельной странице будет 45*58 = 2610 байт информации. В целом же по всему тексту этот объём будет равен 2610*25 = 65250 байт. Для обозначения мощности алфавита в информатике общепринятым вариантом является буква N из формулы Хартли. Именно ее чаще всего указывают в большинстве учебников и профессиональной литературе.
В кодовой таблице ASCII используют восьмибитную кодировку текстовых сообщений. Она позволяет полностью вместить основной набор символов кириллического и латинского алфавитов как в строчном, так и в прописном вариантах. Также с её помощью можно отобразить знаки препинания, цифры и прочие базовые знаки. Часто пользователям приходится иметь дело с более крупными объёмами, состоящими из триллионов байтов.
Для удобства их всегда переводят в увеличенные величины — кило-, мега-, гигабайты и прочее. Для их упрощённого обозначения используются специальные сокращения: Кб, Мб, Гб и так далее. 1 Кб равняется 1024 байтам (2 байта в десятой степени), 1 Мб составляет 1024 Кб (2 Кб в десятой степени) и так далее. Исходя из этого, 65250 байт будут составлять 63,72 килобайта.
Поскольку один отдельный символ состоит из 8 битов, то устанавливать их кодировку целиком не представляется возможным. Вместо этого предпочтительнее образовать кодировку трёхбитовых комбинаций. Расчёт этого действия проводится по формуле Хартли, где n-ная степень будет равняться трём. В результате получается N, равная 8.
При определении мощности чаще всего используют алфавитный подход. Он говорит о том, что объём информации, заложенной в тексте, зависит исключительно от мощности самого алфавита и размера сообщения (то есть количества символов, содержащихся в нём). Этот показатель не имеет никакой связи со смысловым наполнением для человека.
Примеры расчёта мощности

От пользователей или обучающихся в задачах часто требуют научиться определять информационный объём какого-либо сообщения, приняв информационный вес символа за один байт. Так, в отрывке из поэмы Н. Н. Некрасова «Крестьянские дети»:
Я из лесу вышел; был сильный мороз»
будет 67 символов вместе с пробелами, то есть, в соответствии с условиями задания, 67 байт. Их количество умножают на 8 (количество битов в байте), и на выходе получается 536 битов.
Таким образом, зная в теории суть мощности, можно без проблем определять информационный объем различных сообщений.



