Что такое градиент фактор дайвинг

Что же такое Градиент фактор?
Последние версии прогаммного обеспечения для наиболее популярных среди технических дайверов подводных компьютеров VR 3, VR X, Liquivision X1, Shearwater Predator содержат такой изменяемый параметр как Градиент фактор. Кроме того этот параметр есть в программе Deco-planner. Например, на компьютере VR X этот параметр, по умолчанию, стоит 20/85, а в Shearwater Predator 30/85, в программе Deco-planner по умолчанию, стоит 20/85. Что же такое Градиент фактор?
О чём говорит нам эта формула?
Во-первых, формула Градиент-фактора говорит нам, что если ГФ=1.0, то давление в ТК равно Бульмановскому М-фактору. Таким образом, важно, чтобы значение ГФ не превышало ГФ=1.0. Во-вторых, если давление в тканевых компартментах будет равно внешнему давлению, то ГФ=0.0. Другой стратегией декомпрессии может быть установление предела ГФ=0.8 и всплывать так, чтобы не превышать его. В этом случае, вы знаете, что давление в тканевых ячейках не превысит внешнее больше, чем на величину в 80% от Бульмановского М-фактора. В этом случае у вас всегда будет запас безопасности в 20% от Бульмановского М-фактора. Декомпрессионные компьютеры, использующие ГФ, обычно дают возможность ввести для него два параметра. Если вы решили всплывать, используя постоянную величину ГФ=0.8, то это равносильно введению в декомпрессионный компьютер параметров 80/80.
Стратегия Эрика Бейкера
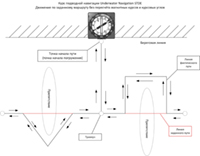
Эрик Бейкер не приветствует всплытие близкое к Бульмановскому М-фактору (ГФ=1.0). Вместо этого он предлагает начинать всплытие при низком значении ГФ, а затем медленно его увеличивать. Смотрите график.

Предположим, что вы решили начать всплытие при ГФ=0.2, а затем увеличивать его до ГФ=0.6 по мере всплытия. Это соответствует настройкам на компьютере 20/60.
Что происходит при использовании параметров ГФ 20/60?
В начале всплытия ваш декомпрессионный компьютер позволит вам всплывать до тех пор, пока один из ТК не достигнет ГФ=0.2. Это означает, что давление в ТК превышает внешнее давление на величину в 20% от Бульмановского М-фактора. Затем вы делаете остановку до тех пор, пока рассыщение ТК не позволит вам подняться до следующей остановки.
Но, поскольку верхний градиент-фактор достигается у поверхности (Depth GF Hi=0.0), то:
Таким образом, если вы достигли ГФ=0.3 на глубине 33м, то глубина GF Low=33. Перед тем, как достичь следующей остановки на 30м, вы должны дождаться, пока рассыщение ТК не позволит вам подняться к 30м с градиент-фактором, не превышающим ГФ=0.35, рассчитанным как:
MaxGF=0,85-((0,85-0,3)/33))Х30=0,35
Далее, когда ТК на глубине 30м рассытятся настолько, что позволят подняться на 27м с градиент-фактором, не превышающим ГФ=0.40, рассчитанным как:
MaxGF=0,85-((0,85-0,3)/33))x27=0,40
Градиент-фактор

Впервые с алгоритмом декомпрессии «градиент фактор» я столкнулся в 2008 году, когда начинал свои погружения с ребризером Эволюшн, где данный алгоритм является стандартным. На сегодняшний день большинство современных декомпрессиметров, рассчитанных на технических дайверов, используют градиент фактор в качестве рабочего алгоритма.
 Как пример это Shearwater, AV1, Сивуч, OSTC, а также практически все ребризеры. Алгоритм есть, а понимания его принципов широким кругом дайверов нет. На более старых компьютерах было понятно – чем выше уровень консерватизма, тем дольше компьютер продержит тебя в воде, прежде всего на мелких остановках. Что же делать теперь с этими двумя цифрами? Что они означают и когда какой градиент фактор нужно выбирать? На эти вопросы я и постараюсь ответить доступными словами, поскольку все объяснения, встречавшиеся мне в сети, изобилуют графиками, диаграммами, специальными терминами и т.д. До конца дочитать тяжело.
Как пример это Shearwater, AV1, Сивуч, OSTC, а также практически все ребризеры. Алгоритм есть, а понимания его принципов широким кругом дайверов нет. На более старых компьютерах было понятно – чем выше уровень консерватизма, тем дольше компьютер продержит тебя в воде, прежде всего на мелких остановках. Что же делать теперь с этими двумя цифрами? Что они означают и когда какой градиент фактор нужно выбирать? На эти вопросы я и постараюсь ответить доступными словами, поскольку все объяснения, встречавшиеся мне в сети, изобилуют графиками, диаграммами, специальными терминами и т.д. До конца дочитать тяжело.
Чтобы разобраться в алгоритме «градиент фактор», прежде всего, нужно вспомнить, что такое M-value или «значение М», а для этого, в свою очередь, вспомнить, как ведет себя инертный газ при высоком парциальном давлении, будь это азот или гелий, по отношению к тканям нашего тела. Газ проникает в ткани и его давление в них растет, стремясь к максимально возможному парциальному давлению данного газа при данном абсолютном давлении. Для примера я возьму глубокое погружение: у нас тримикс 12/50 и мы находимся на глубине 100 метров. Парциальное давление гелия, поступающего с дыхательной смесью, в этом случае равно 5,5 АТА. К этому же максимальному значению его давление стремится в наших тканях. В быстрых тканях, понятно, этот процесс происходит быстрее, в медленных – медленнее. Допустим, мы провели на 100 метрах 20 минут, и давление гелия в самой быстрой ткани достигло 4,5 АТА. Поднимаясь наверх после декомпрессионного погружения, мы обязательно достигнем глубины, на которой парциальное давление газа, поступающего для дыхания из нашего баллона, будет ниже, чем давление этого же газа, накопившегося в наших тканях. В нашем случае это все что выше 80 метров. Называется это состояние supersaturation. Очевидно, что supersaturation – это необходимое условие для рассыщения инертного газа, выхода его из тканей и успешной декомпрессии. В то же время, очевидно, что разница в давлениях должна быть небольшой, чтобы выходящий газ не начал образовывать пузыри в наших тканях, что привело бы к декомпрессионному заболеванию. Соответственно, кроме нижней границы, которую мы определили как начало supersaturation, должна быть еще и верхняя, за которую мы не должны выходить, пока давление инертного газа в наших тканях не снизится до определенного уровня. Эта верхняя граница и называется M-value, М от слова maximum. А все, что между ними является зоной рассыщения.
Какова величина этой зоны? Еще Холдейн, праотец большинства современных декомпрессионных моделей, ставя опыты над козлами (в прямом смысле этого слова), вывел безопасное, по его мнению, соотношение давлений. Эта величина 2:1. Т.е. Провели мы на 10 метрах сколько угодно времени, поднялись к поверхности и ничего. А вот проведя значительное время, скажем, на 30 метрах (давление 4 АТА), безопасно мы можем подняться только к 10 метрам (давление 2 АТА). Дальше потребуются декомпрессионные остановки. Позднее Robert Workman преобразовал эту величину в 1,58 к 1. Это и понятно, мы же говорим в данном случае об азоте. А его максимальное парциальное давление на 10 метрах при погружениях с воздухом – 1,58 АТА. В любом случае, я эти показатели сейчас использую просто для примера. Итак, если в нашем погружении рассыщение быстрых тканей начинается с 80 метров, то критическое supersaturation наступает на 9/1,58=5,7 АТА, что соответствует 47 метрам. Стоим на 79 метрах – риск заработать ДКБ в этот момент минимален, но инертный газ из быстрых тканей выходит крайне медленно, а медленные ткани продолжают довольно интенсивно его насыщать. Стоим на 48 метрах – газ покидает быстрые ткани максимально быстро, медленные ткани насыщаются гораздо медленней, а то и начали рассыщаться, но риск ДКБ в этот момент высок. Соответственно, нужна какая-то золотая середина. Для привычного Бульмановского алгоритма с остановками Пайла выглядит это примерно так:

Как же будет выглядеть профиль погружения при использовании Градиент Фактора? Алгоритм этот также основан на теории Бульмана и является ее модификацией. Обозначается следующим образом: GF 20/80. Первая цифра это низкий градиент фактор, вторая – высокий. Цифра 20 означает, что первая остановка будет на двадцати процентах теоретического расстояния от начала supersaturation до M-value. Цифра 80 означает, что компьютер не выпустит вас до тех пор, пока давление инертного газа во всех ваших тканях не будет ниже 80% от M-value. Все промежуточные остановки будут на линии, идущей от 20% к 80%. Схематически это выглядит так:

Теперь поиграемся с цифрами, поскольку градиент фактор – это величина не постоянная и пользователь может менять его значения. Если установить GF 100/100, это будет алгоритм Бульмана в чистом виде, без каких-либо глубоких остановок. Мы всплываем по M-value. GF 0/0 – время декомпрессии стремится к бесконечности. Соответственно, должно быть что-то посередине. Чем меньше первая цифра, низкий градиент фактор – тем глубже первая глубокая, или как ее еще называют, микропузырьковая остановка. Тем меньше нагрузка на быстрые ткани. Но, тем сильнее насыщение медленных, что потребует дополнительных минут на 6 и 3 метрах. Чем меньше вторая цифра, высокий градиент фактор, тем дольше компьютер продержит дайвера на мелких остановках. Высокий градиент фактор для лучшего понимания можно сравнить с привычным уровнем консерватизма как 20, 30 и т.п. Уровень консерватизма будет равен 100 минус высокий градиент фактор. Во многих компьютерах стандартными установками является GF 20/80 или GF 30/80.
«Санкт-Петербург» Школа технического дайвинга с углубленным обучением
Обучение дайвингу от начального до технического уровня!
O градиент факторе.
Последние события
 |
 |





