Конспект курса «Основы статистики»
1. Введение

Способы формирования репрезентативной выборки:
Простая случайная выборка (simple random sample)
Стратифицированная выборка (stratified sample)
Групповая выборка (cluster sample)
Типы переменных:
непрерывные (рост в мм)
дискретные (количество публикаций у учёного)
Ранговые (успеваемость студентов)
Гистограмма частот:
Позволяет сделать первое впечатление о форме распределения некоторого количественного признака.
Описательные статистики:
Меры центральной тенденции (узкий диапазон, высокие значения признака):
(  используется для среднего значения из выборки, а для генеральной совокупности латинская буква
используется для среднего значения из выборки, а для генеральной совокупности латинская буква  )
)
Свойства среднего:

Если к каждому значению выборки прибавить определённое число, то и среднее значение увеличится на это число.

Если к каждому значению выборки прибавить определённое число, то и среднее значение увеличится на это число.

Если для каждого значения выборки, рассчитать такой показатель как его отклонение от среднего арифметического, то сумма этих отклонений будет равняться нулю.
Меры изменчивости (широкий диапазон, вариативность признака):

При добавлении сильно отличающегося значения данные меняются сильно и могут быть некорректные.
Дисперсия генеральной совокупности:

 (среднеквадратическое отклонение генеральной совокупности)
(среднеквадратическое отклонение генеральной совокупности)

 (среднеквадратическое отклонение выборки)
(среднеквадратическое отклонение выборки)
Свойства дисперсии:




Квартили распределения и график box-plot
Нормальное распределение
Отклонения наблюдений от среднего подчиняются определённому вероятностному закону.
Стандартизация




Правило «двух» и «трёх» сигм


Центральная предельная теорема
Есть признак, распределенный КАК УГОДНО* с некоторым средним и некоторым стандартным отклонением. Тогда, если выбирать из этой совокупности выборки объема n, то их средние тоже будут распределены нормально со средним равным среднему признака в ГС и стандартным отклонением  .
.

30″ alt=»SE = \frac
Доверительные интервалы для среднего
Доверительный интервал является показателем точности измерений. Это также показатель того, насколько стабильна полученная величина, то есть насколько близкую величину (к первоначальной величине) вы получите при повторении измерений (эксперимента).
Идея статистического вывода
2. Сравнение средних
T-распределение
Если число наблюдений невелико и \sigma неизвестно (почти всегда), используется распределение Стьюдента (t-distribution).
Унимодально и симметрично, но: наблюдения с большей вероятностью попадают за пределы  от
от 
«Форма» распределения определяется числом степеней свободы ( ).
).
С увеличением числа  распределение стремится к нормальному.
распределение стремится к нормальному.

t-распределение используется не потому что у нас маленькие выборки, а потому что мы не знаем стандартное отклонение в генеральной совокупности.
Сравнение двух средних; t-критерий Стьюдента
Критерий, который позволяет сравнивать средние значения двух выборок между собой, называется t-критерий Стьюдента.
Условия для корректности использования t-критерия Стьюдента:
Две независимые группы
Формула стандартной ошибки среднего:

Формула числа степеней свободы:

Формула t-критерия Стьюдента:

Переход к p-критерию:
Проверка распределения на нормальность, QQ-Plot
Однофакторный дисперсионный анализ
Часто в исследованиях необходимо сравнить несколько групп между собой. В таком случае применятся однофакторный дисперсионный анализ.
Группы:
Нулевая гипотеза:

Альтернативная гипотеза:
Среднее значение всех наблюдений:

Общая сумма квадратов (Total sum of sqares):

Показатель, который характеризует насколько высока изменчивость данных, без учёта разделения их на группы.
Число степеней свободы:

 — Межгрупповая сумма квадратов (Sum of sqares between groups)
— Межгрупповая сумма квадратов (Sum of sqares between groups)
 — Внутригрупповая сумма квадратов (Sum of sqares within groups)
— Внутригрупповая сумма квадратов (Sum of sqares within groups)





F-значение (основной статистический показатель дисперсионного анализа):

При делении значения межгрупповой суммы квадратов на число степеней свободы, полученный показатель усредняется.


Поэтому формула F-значения часто записывается:

Множественные сравнения в ANOVA
Проблема множественных сравнений:
Поправка Бонферрони
Самый простой (и консервативный) метод: P-значения умножаются на число выполненных сравнений.
Критерий Тьюки
Критерий Тьюки используется для проверки нулевой гипотезы  против альтернативной гипотезы
против альтернативной гипотезы  , где индексы
, где индексы  и
и  обозначают любые две сравниваемые группы.
обозначают любые две сравниваемые группы.
Указанные сравнения выполняются при помощи критерия Тьюки, который представляет собой модифицированный критерий Стьюдента:


где  — рассчитываемая в ходе дисперсионного анализа внутригрупповая дисперсия.
— рассчитываемая в ходе дисперсионного анализа внутригрупповая дисперсия.
Многофакторный ANOVA
При применении двухфакторного дисперсионного анализа исследователь проверяет влияние двух независимых переменных (факторов) на зависимую переменную. Может быть изучен также эффект взаимодействия двух переменных.
Исследуемые группы называют эффектами обработки. Схема двухфакторного дисперсионного анализа имеет несколько нулевых гипотез: одна для каждой независимой переменной и одна для взаимодействия.
Условия применения двухмерного дисперсионного анализа:
Генеральные совокупности, из которых извлечены выборки, должны быть нормально распределены.
Выборки должны быть независимыми.
Дисперсии генеральных совокупностей, из которых извлекались выборки, должны быть равными.
Группы должны иметь одинаковый объем выборки.
АБ тесты и статистика
3. Корреляция и регрессия
Понятие корреляции
Коэффициент корреляции – это статистическая мера, которая вычисляет силу связи между относительными движениями двух переменных.
Принимает значения [-1, 1]

 — показатель силы и направления взаимосвязи двух количественных переменных.
— показатель силы и направления взаимосвязи двух количественных переменных.
Знак коэффициента корреляции показывает направление взаимосвязи.
Коэффициент детерминации
 — показывает, в какой степени дисперсия одной переменной обусловлена влиянием другой переменной.
— показывает, в какой степени дисперсия одной переменной обусловлена влиянием другой переменной.
Равен квадрату коэффициента корреляции.
Принимает значения [0, 1]
Условия применения коэффициента корреляции
Для применения коэффициента корреляции Пирсона, необходимо соблюдать следующие условия:
Сравниваемые переменные должны быть получены в интервальной шкале или шкале отношений.
Распределения переменных  и
и  должны быть близки к нормальному.
должны быть близки к нормальному.
Число варьирующих признаков в сравниваемых переменных  и
и  должно быть одинаковым.
должно быть одинаковым.
Коэффициент корреляции Спирмена

Регрессия с одной независимой переменной
Уравнение прямой:

 — (intersept) отвечает за то, где прямая пересекает ось y.
— (intersept) отвечает за то, где прямая пересекает ось y.
 — (slope) отвечает за направление и угол наклона, образованный с осью x.
— (slope) отвечает за направление и угол наклона, образованный с осью x.
Метод наименьших квадратов
Формула нахождения остатка:

 — остаток
— остаток
 — реальное значение
— реальное значение
 — значение, которое предсказывает регрессионная прямая
— значение, которое предсказывает регрессионная прямая
Сумма квадратов всех остатков:

Параметры линейной регрессии:


Гипотеза о значимости взаимосвязи и коэффициент детерминации
Коэффициенты линейной регрессии
Коэффициенты регрессии (β) — это коэффициенты, которые рассчитываются в результате выполнения регрессионного анализа. Вычисляются величины для каждой независимой переменной, которые представляют силу и тип взаимосвязи независимой переменной по отношению к зависимой.
Коэффициент детерминации
 — доля дисперсии зависимой переменной (Y), объясняем регрессионной моделью.
— доля дисперсии зависимой переменной (Y), объясняем регрессионной моделью.

 — сумма квадратов остатков
— сумма квадратов остатков
 — сумма квадратов общая
— сумма квадратов общая
Условия применения линейной регрессии с одним предиктором
Линейная взаимосвязь  и
и 
Нормальное распределение остатков
Регрессионный анализ с несколькими независимыми переменными
Множественная регрессия (Multiple Regression)
Множественная регрессия позволяет исследовать влияние сразу нескольких независимых переменных на одну зависимую.
Требования к данным
линейная зависимость переменных
нормальное распределение остатков
проверка на мультиколлинеарность
нормальное распределение переменных (желательно)
Элементы статистики
Продолжаем изучать элементарные задачи по математике. Сегодня мы поговорим о статистике.
Статистика — это раздел математики в котором изучаются вопросы сбора, измерения и анализа информации, представленной в числовой форме. Происходит слово статистика от латинского слова status (состояние или положение дел).
Так, с помощью статистики мы можем узнать свое положение дел, касающихся финансов. С начала месяца можно вести дневник расходов и по окончании месяца, воспользовавшись статистикой, узнать сколько денег в среднем мы тратили каждый день или какая потраченная сумма была наибольшей в этом месяце либо узнать какую сумму мы тратили наиболее часто.
На основе этой информации можно провести анализ и сделать определенные выводы: следует ли в следующем месяце немного сбавить аппетит, чтобы тратить меньше денег, либо наоборот позволить себе не только хлеб с водой, но и колбасу.
Выборка. Объем. Размах
Что такое выборка? Если говорить простым языком, то это отобранная нами информация для исследования. Например, мы можем сформировать следующую выборку — суммы денег, потраченных в каждый из шести дней. Давайте нарисуем таблицу в которую занесем расходы за шесть дней

Выборка состоит из n-элементов. Вместо переменной n может стоять любое число. У нас имеется шесть элементов, поэтому переменная n равна 6
Элементы выборки обозначаются с помощью переменных с индексами 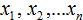 . Последний
. Последний 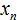 элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.
элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.

Обозначим элементы нашей выборки через переменные
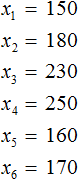
Количество элементов выборки называют объемом выборки. В нашем случае объем равен шести.
Размахом выборки называют разницу между самым большим и маленьким элементом выборки.
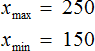
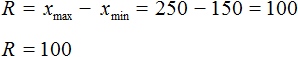
Среднее арифметическое
Понятие среднего значения часто используется в повседневной жизни.
Речь идет о среднем арифметическом — результате деления суммы элементов выборки на их количество.
Среднее арифметическое — это результат деления суммы элементов выборки на их количество.
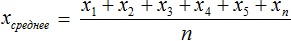
Вернемся к нашему примеру
Узнаем сколько в среднем мы тратили в каждом из шести дней:
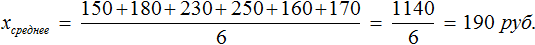
Средняя скорость движения
При изучении задач на движение мы определяли скорость движения следующим образом: делили пройденное расстояние на время. Но тогда подразумевалось, что тело движется с постоянной скоростью, которая не менялась на протяжении всего пути.
В реальности, это происходит довольно редко или не происходит совсем. Тело, как правило, движется с различной скоростью.
Когда мы ездим на автомобиле или велосипеде, наша скорость часто меняется. Когда впереди нас помехи, нам приходиться сбавлять скорость. Когда же трасса свободна, мы ускоряемся. При этом за время нашего ускорения скорость изменяется несколько раз.
Речь идет о средней скорости движения. Чтобы её определить нужно сложить скорости движения, которые были в каждом часе/минуте/секунде и результат разделить на время движения.
Задача 1. Автомобиль первые 3 часа двигался со скоростью 66,2 км/ч, а следующие 2 часа — со скоростью 78,4 км/ч. С какой средней скоростью он ехал?

Сложим скорости, которые были у автомобиля в каждом часе и разделим на время движения (5ч)
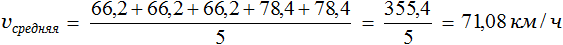
Значит автомобиль ехал со средней скоростью 71,08 км/ч.
Определять среднюю скорость можно и по другому — сначала найти расстояния, пройденные с одной скоростью, затем сложить эти расстояния и результат разделить на время. На рисунке видно, что первые три часа скорость у автомобиля не менялась. Тогда можно найти расстояние, пройденное за три часа:
Аналогично можно определить расстояние, которое было пройдено со скоростью 78,4 км/ч. В задаче сказано, что с такой скоростью автомобиль двигался 2 часа:
Сложим эти расстояния и результат разделим на 5
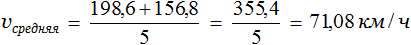
Задача 2. Велосипедист за первый час проехал 12,6 км, а в следующие 2 часа он ехал со скоростью 13,5 км/ч. Определить среднюю скорость велосипедиста.

Скорость велосипедиста в первый час составляла 12,6 км/ч. Во второй и третий час он ехал со скоростью 13,5. Определим среднюю скорость движения велосипедиста:
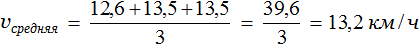
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
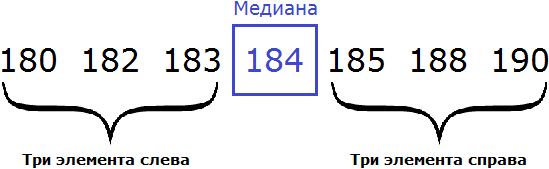
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану
Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186
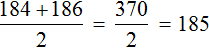
Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.
Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190
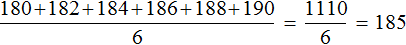
Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2
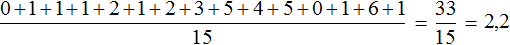
По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Частота
Частота это число, которое показывает сколько раз в выборке встречается тот или иной элемент.
Предположим, что в школе проходят соревнования по подтягиваниям. В соревнованиях участвует 36 школьников. Составим таблицу в которую будем заносить число подтягиваний, а также число участников, которые выполнили столько подтягиваний.
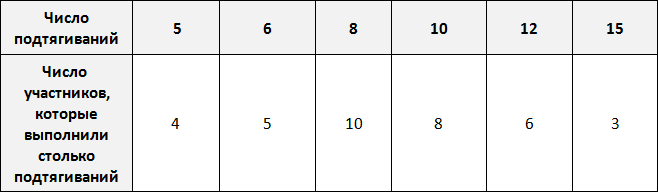
По таблице можно узнать сколько человек выполнило 5, 10 или 15 подтягиваний. Так, 5 подтягиваний выполнили четыре человека, 10 подтягиваний выполнили восемь человек, 15 подтягиваний выполнили три человека.
Количество человек, повторяющих одно и то же число подтягиваний в данном случае являются частотой. Поэтому вторую строку таблицы переименуем в название «частота»:

Такие таблицы называют таблицами частот.
Частота обладает следующим свойством: сумма частот равна общему числу данных в выборке.
Это означает, что сумма частот равна общему числу школьников, участвующих в соревнованиях, то есть тридцати шести. Проверим так ли это. Сложим частоты, приведенные в таблице:
4 + 5 + 10 + 8 + 6 + 3 = 36
Относительная частота
Относительная частота это в принципе та же самая частота, которая была рассмотрена ранее, но только выраженная в процентах.
Относительная частота равна отношению частоты на общее число элементов выборки.
Вернемся к нашей таблице:
Пять подтягиваний выполнили 4 человека из 36. Шесть подтягиваний выполнили 5 человек из 36. Восемь подтягиваний выполнили 10 человек из 36 и так далее. Давайте заполним таблицу с помощью таких отношений:

Выполним деление в этих дробях:

Выразим эти частоты в процентах. Для этого умножим их на 100. Умножение на 100 удобно выполнить передвижением запятой на две цифры вправо:

Теперь можно сказать, что пять подтягиваний выполнили 11% участников, 6 подтягиваний выполнили 14% участников, 8 подтягиваний выполнили 28% участников и так далее.
Понравился урок?
Вступай в нашу новую группу Вконтакте и начни получать уведомления о новых уроках
Возникло желание поддержать проект?
Используй кнопку ниже
42 thoughts on “Элементы статистики”
Спасибо, что вы вернулись.
Будут ли новые уроки?



