Splunk. Введение в анализ машинных данных — часть 2. Обогащение данных из внешних справочников и работа с гео-данными

Мы продолжаем рассказывать и показывать как работает Splunk, в частности говорить о возможностях языка поисковых запросов SPL.
В этой статье на основе тестовых данных (логи веб сервера) доступных всем желающим для загрузки мы покажем:
Обогащение данных информацией из внешних справочников
Рассмотрим имеющиеся у нас данные.

Это события access лога, в которых содержится информация о действиях посетителей сайта (по легенде это сайт интернет-магазина компании, занимающейся продажей компьютерных игр). Поэтому в логах у нас есть такие поля, как (наиболее интересные для обработки и запросов):
Но! Так как в наших логах кроме productId нет больше никакой информации о продукте, мы не видим что это за товар, сколько он стоит и так далее. Поэтому было бы удобно подгрузить соответствующие поля из внешнего справочника.
В качестве справочника возьмем простой csv файл с интересующей нас информацией о названии продукта и его цене, и загрузим его в Splunk. Сразу скажу, что это самый простой ручной способ обогащения. Понятно, что Splunk может забирать данные из реляционных баз данных, делать запросы к API и прочее.
После того как Вы скачали справочник, нужно загрузить его в Splunk и разметить поля. Подробная инструкция здесь. Если Вы все сделали правильно, то должны получить следующие результаты поискового запроса:
По сути мы просто добавили табличку со справочником в Splunk, теперь давайте сделаем так, чтобы система «дописала» значения этих полей к нашим событиям. Понятно, что она никак не изменит исходные события, а просто логически подтянет поля.
Заходим во вкладку Settings → Lookups → Automatic lookups → New
Name: — любое имя
Lookup table: prices_lookup (или как вы нававли Вашу таблицу)
Sourcetype: access_combined_wcookie
Lookup input fields: productId=productId
Lookup output fields: price=price, product_name=product_name, sale_price=sale_price
После чего все сохраняем и меняем Permissions на All Apps и Read/Write everyone как предыдущей инструкции.
Если все сделано правильно, то теперь при поиске по данному sourcetype должны быть достпны добавленные нами поля (чтобы они отображались снизу каждого события нужно зайти во вкладку All fields и выбрать их в качестве Interesting fields). Заметьте, что в самих событиях этой информации нет, так как они не изменялись.
Вот теперь результаты наших запросов могут быть куда интереснее. К примеру, мы можем посчитать ту же самую аналитику только уже с привязкой к деньгам и финансовым результатам.
Понятно, что этот пример больше про BI историю. Однако, этот пример с подключением справочников тиражируем и в другие предметные области. К примеру, если говорить про информационную безопасность — мы можем подгружать по CVE коду информацию из баз данных уязвимостей.
И да, совсем забыл! Для удобного редактирования справочников у Splunk есть специальное приложение Lookup Editor, которое можно бесплатно скачать со SplunkBase.
Визуализация данных с географическими координатами
Иногда бывает очень полезно нанести результаты аналитических запросов на географическую карту. Тут ситуация разделяется на 2 случая: первый — когда в данных уже есть такие поля как широта и долгота (именно благодаря им мы можем нанести что-либо на карту), второй — когда этих полей нет. В нашем примере, то есть в наших данных, как раз второй случай (мы имеем много посетителей интернет магазина из разных мест, но данных об их широте и долготе у нас нет, зато у нас есть их ip-адрес). У Splunk есть встроенный функционал определения широты и долготы (а также города, страны и региона) на основе ip-адреса, команда iplocation.
В результате этого запроса у вас должны появится поля с широтой, долготой, названием города, страны и региона.
Теперь строим какой-нибудь аналитический запрос и наносим на карту. К примеру, посчитаем прибыль по каждому продукту и посмотрим где это покупалось. Для этого используем встроенную функцию geostats.
Также можем воспользоваться другим вариантом визуализации и посмотреть прибыльность в разрезе по странам, для этого используется команда geom.
По дефолту, есть маппинг по странам и штатам США, но вы всегда можете сделать свой, на основе широты и долготы и добавить его в Splunk. Например, это могут быть регионы Росиии, или городские округа.
Транзакции или группировка цепочки событий во времени
В том случае, когда у нас есть последовательная цепочка событий, например, процесс пересылки электронной почты, какая-нибудь финансовая операция, или как в случае с нашими данными — посещение web сайта, бывает необходимо объединить эти события в транзакции. То есть из группы отдельных событий событий явно выделить цепочку, группируя их по конкретному признаку.
В нашем случае это поле JSESSIONID — уникальный номер сессии пользователя. Для группировки используем команду transaction.
После чего получаем сгруппированные события, а также новые поля: длительность транзакции, и количество сгруппированных событий.
Теперь можно посчитать, к примеру, статистику по длительности сессий, то есть время за которое посетители решались совершить покупку.
Также можно посчитать количество конкурентных сессий в каждый период времени, для этого есть команда concurrency.
В результате, создается новое поле concurrency, которое и считает конкурентные сессии, но, к сожалению, из-за того что наши данные синтетические у нас в любой момент времени есть только одна конкурентная сессия, поэтому этот пример не очень результативен.
Заключение
Конечно, примеры очень простые, но надеюсь, репрезентативные.
На этом мы заканчиваем данную статью!
Пишите свои вопросы если что-то не заработало или не получилось =)
Еще раз сылки на загрузку данных и справочника c ценами.
Обогащение данных
В большинстве случаев хранилища данных создаются и поддерживаются для обеспечения эффективного анализа данных на предприятии.
Очевидно, что данные, собираемые для задач анализа, должны быть полными и достоверными, поскольку на основе неполных или недостоверных данных нельзя сделать правильные выводы о состоянии бизнеса и путях его совершенствования.
Неполные данные могут появиться, например, если часть сведений о продажах филиала фирмы была утеряна в процессе их переноса в ХД. Аналитик может прийти к выводу, что продажи в этом филиале катастрофически низкие, филиал работает неэффективно и его следует закрыть, хотя на самом деле деятельность филиала вполне успешна, а его сотрудники хорошо справляются со своими задачами. Недостоверные данные, которые при этом могут быть полными, содержат искаженную информацию, не позволяющую провести качественный анализ. Поэтому в процессе загрузки в ХД, а также при подготовке к анализу в аналитическом приложении данные проверяются на полноту, целостность, непротиворечивость, наличие ошибок, пропусков, аномальных значений и других факторов, которые могут привести к некорректным результатам анализа.
Данные и информация
Помимо достоверности и полноты данных, существует еще один фактор, непосредственно влияющий на эффективность их анализа, — информационная насыщенность. Вообще говоря, данные и информация не совсем одно и то же. Каждый сталкивался с ситуацией, когда, несмотря на наличие данных, извлечь из них какую-либо информацию оказывалось невозможно. Например, если вывести на экран компьютера текст с неправильной кодировкой шрифта, мы увидим вместо букв непонятные закорючки, фигурки, спецсимволы и т.д. Данные есть — информации нет. То же самое произойдет, если вы попытаетесь читать текст на иностранном языке, которого не знаете и символы которого вам неизвестны, например на китайском. При этом мы понимаем, что информация есть, но мы не можем ее распознать и осмыслить.
Для извлечения информации из данных может потребоваться их обработка — корректировка представления значений (символов), упорядочение и т.д. Примерами такой обработки служат перевод с неизвестного языка на известный, изменение кодировки символов и т.д. На практике подобная обработка с целью получить из произвольных данных информацию является очень трудоемкой, отнимающей много времени и не гарантирующей результатов. Действительно, если изначально при создании данных в них не закладывалась никакая информация, то и извлечь ее будет невозможно. Попробуйте закрыть глаза и случайно набрать на клавиатуре несколько строк, а затем отнесите набранный фрагмент криптографу, скажите, что это код, и попросите расшифровать его. Скорее всего, усилия специалиста будут напрасны. Если же ему случайно и удастся выявить некоторую закономерность и извлечь какую-то информацию, то о ее достоверности и говорить не приходится.
Таким образом, информация — это не любые данные, а только те, которые соответственным образом представлены и упорядочены, то есть имеют структурные закономерности, которые, кроме всего прочего, должны распознаваться и осмысливаться пользователем. Так, если мы видим текст на языке, символы которого нам незнакомы, мы сталкиваемся с ситуацией, когда упорядоченность данных есть, а соответствующего представления нет. Напротив, если в тексте на известном языке случайным образом переставить буквы, то получится правильное представление, но отсутствие упорядоченности. И в том и в другом случае воспользоваться этими данными мы не сможем, до тех пор пока они не будут соответствующим образом преобразованы.
Данные — понятие объективное. Они либо реально существуют как изменения некоторого физического процесса, либо нет. А информация в большинстве случаев субъективна. Если один эксперт с определенным уровнем компетентности, знаний и опыта увидит в некотором наборе данных полезную информацию, то другой эксперт с другим уровнем опыта и знаний отыщет совсем другую информацию или не найдет ее вовсе.
Ответ на первый вопрос во многом определяется происхождением набора данных. Если данные были получены из надежного источника: от подразделения предприятия, из учетной системы, органов госстатистики и т.д. — скорее всего, в том или ином виде информация в них имеется. Правда, иногда для ее извлечения требуется некоторая обработка данных — перекодировка, преобразование форматов и т.д.
Таким образом, если поставщик данных хорошо известен, то и смысл данных определен. Например, если источником данных является бухгалтерия, то они, скорее всего, содержат информацию финансового или учетного характера. Если источником является какая-либо техническая служба предприятия, то и предоставляемая ею информация в большинстве случаев носит технический характер.
Надежность и достоверность проверяются практически на всех этапах аналитического процесса: сначала на этапе загрузки данных в ХД (в процессе ETL), затем в самом ХД (автоматический контроль) и, наконец, в аналитическом приложении при подготовке данных к анализу.
Третий вопрос является самым неоднозначным. Достаточно или недостаточно информации для решения той или иной аналитической задачи, каждый аналитик определяет сам на основании весьма субъективных критериев. Один аналитик даже из минимума информации выжмет максимум полезных знаний с помощью личного опыта, навыков аналитической работы, умелого применения аналитических методов и алгоритмов. Специалисту с меньшей квалификацией, возможно, не удастся решить задачу с любым количеством данных. Кроме того, сами аналитические задачи различаются по уровню сложности и требованиям к информативности исходных данных.
Необходимость обогащения данных
Часто возникают ситуации, особенно при решении нестандартных аналитических задач, когда для анализа требуется информация, которой почему-то не оказалось в наличии. Это может произойти из-за непродуманного процесса сбора данных. Порой базы данных оказываются забиты чем угодно, только не данными, имеющими прямое отношение к основным бизнес-процессам на предприятии. Например, в регистрирующую систему заносят номер автомобиля, на котором вывозят товар, номер путевого листа, ФИО водителя и т.д. А непосредственное отношение к бизнес-процессу имеют только наименование товара, его количество и цена за единицу. Очевидно, что большая часть информации, содержащейся в БД, может заинтересовать разве что начальника охраны, но никак не аналитика по продажам. Складывается ситуация, проиллюстрированная левой частью рис. 31, когда в огромном массиве данных имеется только небольшое их подмножество, реально описывающее исследуемый процесс.
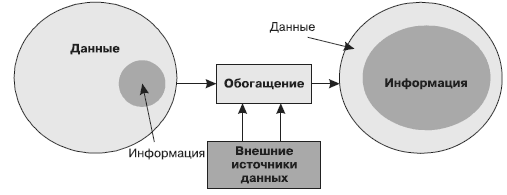
Рис. 31. Обогащение данных
Когда же наконец приходит время анализировать данные, выясняется, что анализировать, в общем-то, и нечего. В этот момент осознается необходимость обогащения данных. Оно может выполняться за счет реорганизации самих данных: введения каких-то кодировок, признаков состояний объектов, подразделения их на категории (например, товары распределяются по группам товаров) и т.д. Может привлекаться дополнительная внешняя информация, например история курсов валют на день продажи, информация о продажах конкурентов за тот же период и др. И постепенно ситуация примет вид, представленный в правой части схемы (см. рис. 31), когда полезная информация составляет большую часть имеющихся в распоряжении аналитика данных.
Обогащение данных — процесс насыщения данных новой информацией, которая позволяет сделать их более ценными и значимыми с точки зрения решения той или иной аналитической задачи.
Можно выделить два основных метода обогащения данных — внешнее обогащение и внутреннее.
Внешнее обогащение предполагает привлечение дополнительной информации из внешних источников, что позволит повысить ценность и значимость данных с точки зрения их анализа. Под повышением значимости данных подразумевается, что на основе их анализа можно будет принимать управленческие решения принципиально нового уровня. Например, обычные данные о текущей работе предприятия позволяют оптимизировать товарные потоки, работу с клиентами, политику скидок, гарантий и т.д. Уже немало, но, поскольку у конкурентов тоже созданы аналитические службы, больших конкурентных преимуществ анализ только оперативной информации не принесет.
Для поддержки успешного решения стратегических бизнес-задач необходимо использовать соответствующий уровень анализа данных. Данных из обычных OLTP или учетных систем предприятия для такого анализа, как правило, недостаточно. В этом случае следует привлекать дополнительную информацию из внешних источников. Она позволит обогатить внутренние данные, имеющиеся в распоряжении аналитиков фирмы, до уровня информативности и значимости, который позволит решать задачи стратегического анализа с соответствующим уровнем достоверности.
Источником информации для обогащения данных могут быть любые организации, которые в процессе своей деятельности собирают, структурируют и хранят информацию, необходимую им для осуществления своих целей.
Внутреннее обогащение не предполагает привлечения внешней информации. В этом случае повышение информативности и значимости данных может быть достигнуто за счет изменения их организации. Не следует путать внутреннее обогащение с обычным преобразованием данных, выполняемым в процессе их загрузки в ХД или при подготовке к анализу в аналитическом приложении. Преобразование данных изначально связано с оптимизацией занимаемого ими объема, скорости доступа к ним, удобства представления для пользователя, обеспечения целостности и непротиворечивости данных, удаления факторов, которые мешают их корректно обрабатывать, и т.д. Такая обработка не преследует цель обогатить данные информацией, а только решает определенные технические проблемы.
Внутреннее обогащение обычно связано с получением и включением в набор данных полезной информации, которая отсутствует в явном виде, но может быть тем или иным способом получена с помощью манипуляций с имеющимися данными. Затем эта информация встраивается в виде новых полей или даже таблиц в ХД и может быть использована для дальнейшего анализа. Для обогащения данных также может использоваться информация, полученная в процессе их анализа.
Рассмотрим пример внутреннего обогащения. Руководство предприятия поставило задачу выработать новую политику взаимодействия с поставщиками в зависимости от их надежности. Были разработаны критерии, в соответствии с которыми определялась степень надежности поставщиков, в результате чего все поставщики разбивались на три категории — надежные, средние и ненадежные. Степень надежности конкретного поставщика определялась как отношение общего числа дней задержки поставок за квартал к стоимости поставок. То есть поставщик, часто задерживающий мелкие поставки, но в целом соблюдающий график серьезных поставок, будет рассматриваться как надежный партнер. В то же время поставщик, который задерживает крупные поставки, пусть даже и редко, но соблюдает график мелких поставок, будет рассматриваться как потенциально ненадежный партнер. Информацию о задержках и суммах поставок можно получить из документов о поступлении товара в учетной системе. После соответствующих вычислений и сравнений в таблицу ХД, где находится информация о поставщиках, будет добавлено новое поле, в котором для каждого из них будет указана категория надежности. Дальнейший анализ в области поставок может производиться с использованием новых данных.
Таким же образом можно создавать рейтинги сотрудников для их поощрения и продвижения по службе, рейтинги популярности товаров и т.д.
Применение обогащения данных из внешних источников обычно связано со сбором информации об объектах предметной области, участвующих в исследуемом бизнес-процессе. Для предприятий и организаций это могут быть экономические показатели (прибыль, численность работников, объем продаж и др.). При исследовании клиентов — физических лиц наибольший интерес представляют признаки, позволяющие распределить их по группам, например с точки зрения их активности как покупателей или потребителей каких-либо услуг. В этом случае выясняются пол, возраст, род занятий и увлечений, наличие семьи и детей, медиапредпочтения и т.д.
Сеть магазинов, торгующих недорогой повседневной одеждой, решила провести рекламную кампанию с целью привлечения большего числа покупателей. При этом организаторы кампании посчитали, что реклама должна быть направлена на те категории населения, которые являются самыми активными клиентами. Чтобы узнать, представители каких слоев общества наиболее активно приобретают товары этой сети магазинов, были проведены следующие мероприятия. Клиентам предлагалась дисконтная карта, при получении которой нужно было заполнить анкету и указать пол, возраст, профессию, семейное положение, род занятий, увлечения, наличие детей, предпочтения в стилях одежды. Затем по номеру дисконтной карты отслеживались продажи. По итогам квартала были сопоставлены анкетные данные и собранная информация о продажах. В результате выяснилось, что более 70 % клиентов сети магазинов составляют студенты и молодые специалисты в возрасте до 25–27 лет, предпочитающие современный стиль в одежде и ведущие активный образ жизни. Поэтому рекламную кампанию было решено направить именно на эту категорию клиентов.
Обогащение — один из важнейших этапов подготовки данных к анализу. Использование этой процедуры во многих случаях позволяет поднять качество анализа на принципиально новый уровень, особенно при решении нестандартных задач, даже в условиях недостаточной информативности данных, поступающих из OLTP и учетных систем. Кроме того, обогащение данных в какой-то мере позволяет компенсировать просчеты в стратегии сбора и консолидации аналитических данных.
Билл Инмон (Bill Inmon) — автор концепции хранилищ данных, обнародованной в 1989 г., крупнейший в мире специалист в этой области. Его идея вызвала настоящий переворот в методах использования при управлении бизнесом гигантских массивов данных, накопленных компаниями. Тем самым был дан мощный толчок дальнейшему развитию технологий Business Intelligence, прежде всего построению информационных витрин. Билл Инмон — соавтор концепций корпоративной информационной фабрики (Corporate Information Factory) и ее аналога для государственных структур (Government Information Factory). В его модели атомарные данные организованы в реляционные базы и находятся в нормализованном хранилище данных.
Из-под пера Инмона вышло более 600 статей, а также 46 книг, переведенных на девять языков мира. Среди них — бестселлер Building the Data Warehouse, суммарный тираж которого уже превысил полмиллиона экземпляров.
Билл Инмон является основателем Prism Solutions — первой в мире компании, которая занялась разработкой инструментария ETL — средств извлечения, преобразования и загрузки данных.
Ральф Кимболл (Ralph Kimball) — широко известный специалист в области хранилищ данных и бизнес-аналитики. Он предложил использовать пространственную организацию баз данных (dimensional data bases) с так называемой архитектурой «звезда».
Кимболл известен как автор бестселлера «Инструменты для хранилища данных: полное руководство пространственного моделирования» (The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling) и др.
Карьера Кимболла складывалась следующим образом. В 1972 г., после окончания постдока Стэндфордского университета в области электротехники (специализация — человеко-машинное взаимодействие), он попал в исследовательский центр Xerox Palo Alto, где принял участие в разработке коммерческого программного продукта Xerox Star WorkStation. Затем Кимболл становится вице-президентом компании Metaphor Computer Systems, занимающейся разработкой систем принятия решений и консалтингом. В 1986 г. он основывает компанию Red Brick Systems и занимает пост ее генерального директора до 1992 г. Red Brick System, сейчас принадлежащая IBM, известна своими разработками в области производительной реляционной СУБД, оптимизированной под хранилища данных.
Что такое data enrichment (обогащение данных)

Обогащение данных (или data enrichment) – это один из процессов, которые улучшают и дополняют сырые данные. Эти процессы объединяют 1st party данные с другой информацией из внутренних и внешних источников.
Как происходит data enrichment?
Процесс data enrichment начинается со сбора различных данных из нескольких источников. Напомним, что типичные источники данных делятся на три типа:
Информация о клиентах, которую компания собирает напрямую от них, является 1st party данными. Часто источником является поведение пользователей вашего веб-сайта и приложения или информация из customer relationship management (CRM) платформы. 1st party данные также могут поступать из списков подписок, аналитики социальных сетей и опросов клиентов.
2nd party данные – это 1st party данные, полученные от кого-то еще. Эта информация обычно может быть объединена с вашими 1st party данными, чтобы увеличить ее масштаб и более точно ориентироваться на клиентов, похожих на вашу текущую аудиторию. 1st party данные особенно полезны, если вы ориентируетесь на новую демографическую группу, которая представляет значительную часть клиентской базы исходной компании.
3rd party данные – это агрегированные 1st party данные, собранные и скомпилированные из многих источников. Вместо того, чтобы покупать 2nd party данные прямо из источника, компания может вместо этого приобретать определенные наборы 3rd party данных у агрегаторов для увеличения масштабов своих 1st party данных. 3rd party данные наиболее часто используются для обогащения данных с целью увеличения 1st party data.
Все три типа данных могут быть эффективными для лучшего понимания вашей идеальной аудитории и нацеливания на нее. 1st party данные, как правило, являются наиболее ценными, поскольку это информация, полученная непосредственно от ваших клиентов, но не всегда она обеспечивает достаточный масштаб. Обогащение этих данных с помощью 2nd party и 3rd party данных помогает обеспечить более полное представление о вашем потребителе в масштабе. Для еще большего обогащения данных, можно применить аналитику для определения закономерностей и формирования новых параметров целевой аудитории.
Объединив данные с помощью методов обогащения данных, бренды могут глубже понять предпочтения и поведение своих клиентов. Используя обогащение данных, бренды могут использовать свои знания для принятия обоснованных решений, расширения клиентской базы и персонализации сообщений для достижения большего успеха. Вот почему все большее число компаний используют обогащение данных как источник для достижения своих долгосрочных маркетинговых целей.
Какие бывают типы data enrichment?
Обогащение данных улучшает данные с помощью различных средств. Существует столько же типов обогащения данных, сколько и источников данных, но компании часто используют несколько распространенных видов. К ним относятся:
Обогащение демографических данных
Обогащение демографических данных расширяет наборы данных о клиентах за счет применения демографической информации, такой как семейное положение, размер семьи, уровень дохода, кредитный рейтинг и многое другое. Этот тип информации обеспечивает большую персонализацию ваших критериев таргетинга, месседжей и креативов.
Обогащение географических данных
Обогащение географических данных включает добавление в профили клиентов такой информации, как почтовые индексы, картографические адреса, координаты и многое другое. Этот тип данных особенно полезен для мобильной рекламы и для определения местоположения новых магазинов. Его также можно использовать для определения локальных цен.
Обогащение поведенческих данных
Обогащение поведенческих данных применяет модели поведения клиентов к их профилям, включая их прошлые покупки и поведение при просмотре. Это часто связано с отслеживанием покупательского пути пользователя, чтобы определить ключевые области интересов каждого покупателя. Поведенческие данные необходимы компаниям для определения того, какие рекламные кампании работают лучше всего и какова будет рентабельность инвестиций (ROI) каждой кампании.
Каждый тип обогащения данных помогает компании достигать различных бизнес-целей. Прежде чем выбрать правильный метод обогащения данных для вашего бизнеса, определите, какая именно информация вам нужна.
Зачем нужно использовать data enrich?
Основное преимущество, обеспечиваемое обогащением данных, – это повышенная ценность и точность понимания клиентов компании. Компаниям нужны высококачественные данные, чтобы принимать важные бизнес-решения и делать ценные выводы. Однако при обсуждении обогащения данных возникает общий вопрос – почему бы просто не использовать 1st party данные?
1st party данные, как сообщалось выше, собираются от клиентов напрямую через CRM-платформы, веб-сайты, опросы и списки подписок. Хотя эти данные ценны, поскольку они поступают непосредственно из вашей существующей клиентской базы, они также могут быть ограничены. 1st party данные говорят компаниям о поведении их посетителей на их сайтах или в приложениях, но ничего не говорят им о жизни потребителей за пределами сферы их деятельности, например, о решениях о покупке и активности на сайте.
Даже если ваша компания собирает демографическую и географическую информацию, ваше наблюдение за каждым клиентом ограничивается тем, как они ведут себя при прямом взаимодействии с вашей компанией. Это показывает лишь небольшую часть того, кем они являются, но не дает более детального понимания. Ваш бизнес может не получить всю информацию, необходимую для точного и эффективного маркетинга.
Дополняя информацию о своей компании 2nd party и 3rd party данными, вы можете получить более полное представление о том, кто ваш клиент, чтобы вы могли более точно понять его и настроить таргетинг. Это также дает вам больше информации, к которой вы можете применить аналитику для получения все более значимых идей.
Для всего этого вам пригодится платформа для управления данными и их обогащения – dmp data enrichment. Она даст вам возможность собирать всю информацию в одном месте и подготовить ее соответствующим образом к анализу, а также передавать и использовать в рекламных платформах.

Результаты от использования обогащения данных
Кроме устранения ограничений для 1st party данных, использование data enrichment может дать значительные преимущества в различных критически важных для бизнеса областях. Ниже подробно описаны лишь некоторые из этих преимуществ:
Клиент должен чувствовать, что ваша компания понимает его потребности. Это увеличивает вероятность того, что он совершит покупку и продолжит работать с вашим бизнесом в будущем. Data enrichment может облегчить это более глубокое понимание клиентов, предоставляя больше информации для обеспечения персонализированного взаимодействия с клиентами.
Обогащенные данные позволяют адаптировать свой бизнес к потребностям широких слоев населения, вплоть до индивидуальных клиентов. И все это основано на подробной информации в вашем наборе данных. Вы можете скорректировать цены и рекламные кампании своего бизнеса так, чтобы они соответствовали целевой аудитории. Вы также можете создавать более персонализированные коммуникации на основе данных отдельного клиента.
Такой персонализированный опыт является весьма ценным для потребителей. Он способствует установлению значимых, долгосрочных отношений с клиентами, которые приводят к успеху в бизнесе. В одном из опросов Forbes 40% руководителей предприятий сообщили, что персонализация клиентов оказывает прямое положительное влияние на их продажи.
Чем больше у вас данных, тем точнее вы сможете сегментировать свою аудиторию. Сегментация, основанная на крупных и мелких факторах, помогает классифицировать людей и видеть общее у ваших клиентов. Эти знания позволяют вашей компании разрабатывать более эффективные целевые кампании. Имея больше данных, вы можете выявить новые закономерности и возможности маркетинга или продукта, которые раньше могли быть невидимы.
Подход к маркетингу, основанный на “spray-and-pray” (“отправил и молись”), может помочь общей узнаваемости бренда, но его эффективность на конверсии покупателя менее очевидна. Вместо этого большинство компаний сосредотачивают свои усилия на целевом (таргетированном) маркетинге. Однако для того, чтобы нацелить персонализированную рекламу на людей, компании должны иметь полное представление о своей аудитории.
1st party данные могут показывать только поведение потребителей при непосредственном взаимодействии с компанией. А вот дополнение этих данных 2nd party и 3rd party данными позволяет организациям получить более развернутое представление о каждом потребителе и его цифровой жизни. Это помогает компаниям определить и сосредоточить свои усилия на личностях, которые с наибольшей вероятностью превратятся в клиентов.
Оценка и анализ лидов помогает отделам продаж расставить приоритеты в своих усилиях. Только это практически невозможно сделать, когда у вас есть неполные профили клиентов. Обогащение данных может улучшить их профили с помощью качественных данных, обеспечивая надежную и значимую оценку. Качество и глубина данных также могут позволить автоматизировать оценку лидов, исключить предположения и позволить вашей команде продаж сосредоточиться на своих целях.
Процессы обогащения данных обеспечивают соблюдение вашей компанией нормативных требований, касающихся конфиденциальности данных. Многие страны на законодательном уровне устанавливают ограничения на тип клиентских данных, которые вы можете хранить, и на время их сбережения. Есть также необходимость регулярно вести «do-not-call lists», списки людей, которые отписались или запретили использовать данные о них. Если у вашей компании нет механизма, обеспечивающего соблюдение нормативных требований, вы можете столкнуться с дорогостоящими штрафами.
С другой стороны, вы можете настроить data enrichment процессы для регулярной потоковой очистки базы данных. При этом можно сохранить ценность данных и соответствие справочным требованиям.
Неточные данные могут привести к потере рекламных бюджетов, недовольству клиентов и неправильной аналитике, что дорого обходится компаниям. Многие работают с избыточными данными, потому что либо не знают о их существовании, либо не знают, какие данные следует удалить.
Инструменты обогащения данных могут устранить избыточные и неточные данные. Это происходит за счет автоматического анализа информации, объединения избыточностей и исправления ошибок при сохранении обновленных профилей. Этот метод повышает качество данных компании, поэтому они могут быть уверены, что выполняется задача работать с максимально точной и актуальной информацией.
Обогащение данных снижает затраты и оптимизирует продажи. Процессы обогащения данных экономят компании деньги за счет управления существующей информацией. Это гарантирует, что вы не тратите зря хранилище баз на данные, которые бесполезны для вашего бизнеса. Этот процесс также снижает затраты за счет минимизации штрафов из-за несоответствия данных. Одновременно с этим обогащение данных обеспечивает максимальную прибыль за счет увеличения продаж. Это происходит благодаря более эффективному маркетингу и клиентскому менеджменту. Data enrichment может определять возможности перекрестных и дополнительных продаж, продвигая при этом конструктивные отношения с клиентами.



