СОДЕРЖАНИЕ
Вступление
В одномерных распределениях
Если мы предположим, что популяция нормально распределена со средним значением μ и стандартным отклонением σ, и выберем индивидуумов независимо, то мы имеем
Икс ¯ знак равно Икс 1 + ⋯ + Икс п п <\ displaystyle <\ overline 
случайная величина, распределенная таким образом, что:
В статистических ошибках затем
с ожидаемыми значениями нуля, тогда как остатки равны
Замечание
Регрессии
Однако из-за поведения процесса регрессии распределения остатков в разных точках данных (входной переменной) могут различаться, даже если сами ошибки распределены одинаково. Конкретно, в линейной регрессии, где ошибки одинаково распределены, изменчивость остатков входных данных в середине области будет выше, чем изменчивость остатков на концах области: линейные регрессии подходят конечным точкам лучше, чем середина. Это также отражается в функциях влияния различных точек данных на коэффициенты регрессии : конечные точки имеют большее влияние.
Другие варианты использования слова «ошибка» в статистике
Использование термина «ошибка», как обсуждалось в разделах выше, означает отклонение значения от гипотетического ненаблюдаемого значения. По крайней мере, два других использования также встречаются в статистике, оба относятся к наблюдаемым ошибкам прогнозирования:
Анализ регрессионных остатков (пример)
Материал из MachineLearning.
Содержание
Для получения информации об адекватности построенной модели многомерной линейной регрессии используется анализ регрессионных остатков.
Постановка задачи
Задана выборка откликов и признаков. Рассматривается множество линейных регрессионных моделей вида:
. Требуется создать инструмент анализа адекватности модели используя анализ регрессионных остатков и исследовать значимость признаков и поведение остатков в случае гетероскедастичности.
Описание алгоритма
Анализ регрессионных остатков
Анализ регрессионных остатков заключается в проверке нескольких гипотез:
Для проверки первой гипотезы воспользуемся критерием знаков. Проверка второй гипотезы, по сути, является проверкой на гомоскедастичность, то есть на постоянство дисперсии, случай гетероскедастичности будет рассмотрен ниже. Для этого воспользуемся двумя статистическими тестами: тестом Ансари-Брэдли и критерием Голдфелда-Кванта. Так как тест Ансари-Брэдли фактически осуществляет проверку гипотезы, что у двух предоставленных выборок дисперсии одинаковы, а мы фактически имеем только один вектор остатков, то произведем несколько тестов, сравнивая в каждом две случайные выборки из нашего вектора остатков. Проверку нормальности распределения осуществим с помощью критерия согласия хи-квадрат, модифицированного для проверки на нормальность, то есть сравнивая данное нам распределение в остатках с нормальным распределением, имеющим моментные характеристики, вычисленные из вектора остатков. Наконец, проверку последнего условия реализуем с помощью статистики Дарбина-Уотсона.
Оценка значимости признаков
Задача состоит в проверке для каждого из признаков, дает ли нам учет этого признака в модели более хорошие результаты, нежели его отсутствие. Оценивать результаты будем с помощью коэффициента детерминации:
Гетероскедастичность
Термин гетероскедастичность применяется в ситуации, когда ошибки в различных наблюдениях некоррелированы, но их дисперсии — разные. Соответственно термин гомоскедастичность применяется в случае постоянных дисперсий.
Визуальный анализ
Одним из основных методов предварительного исследования на гетероскедастичность является визуальный анализ графика остатков. Целью данного анализа является нахождение факторов влияющих на изменение дисперсии, номер измерения или значение одного из признаков. Для сравнения приведем несколько примеров.
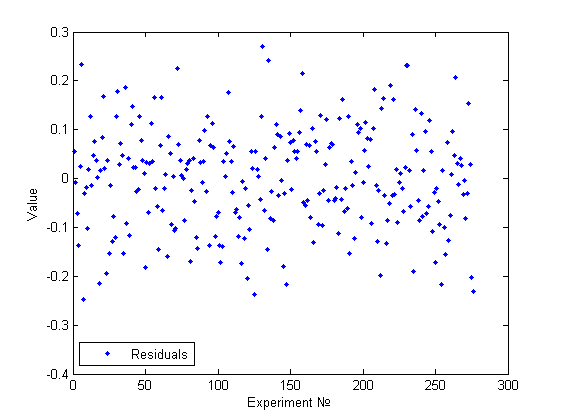
Выше представлена госмоскедастичная модель. Действительно, используя визуальный анализ, не получается найти какие-то признаки непостоянства дисперсии и тем более какие-то зависимости.
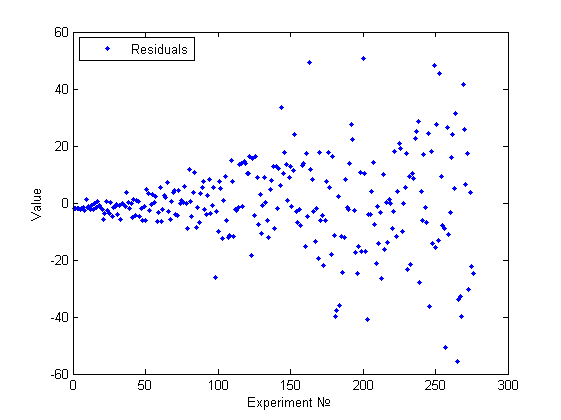
В данном случае визуально можно констатировать факт непостоянства дисперсии и даже связать это изменение с номером эксперимента (или возможно с одним из признаков, если он монотонно изменялся по номеру эксперимента).
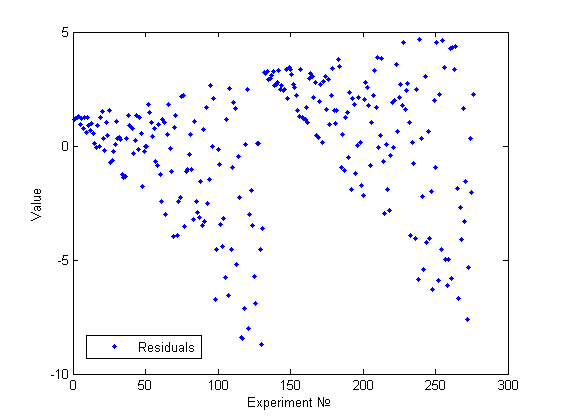
Еще один пример визуально определимой гетероскедастичности.
Статистические методы детекции
Тест Уайта
Тест Голдфелда-Кванта
Этот тест применяется, когда есть предположение о прямой зависимости дисперсии ошибок от некоторого признака. Алгоритм метода:
Тест Ансари-Брэдли
Тест получает на вход две выборки размеров и и проверяет на равенство дисперсий распределения, из которых они могли быть получены. Алгоритм метода пошагово:
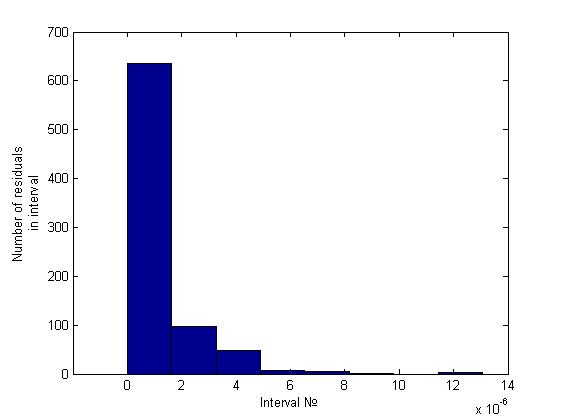
Эвристика
Вычислительный эксперимент на модельных данных
В данном отчете представлены результаты применения созданного инструмента анализа представленной модели с помощью исследования ее регрессионных остатков. Отчет состоит из трех экспериментов, демонстрирующих плюсы и минусы созданного инструмента.
Три модели
Модель №1 (хорошая)
График остатков этой модели уже был приведен выше и не представляет особого интереса.
Модель №2 (плохая, одномерная)
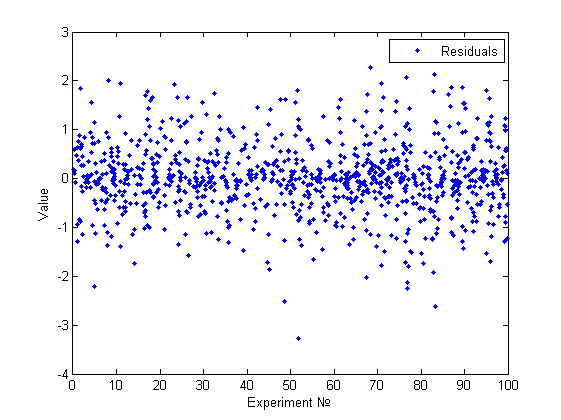
Нормальность отвергнута. Гетероскедастичность была обнаружена только эвристикой. Приведем гистограмму полученную эвристикой:
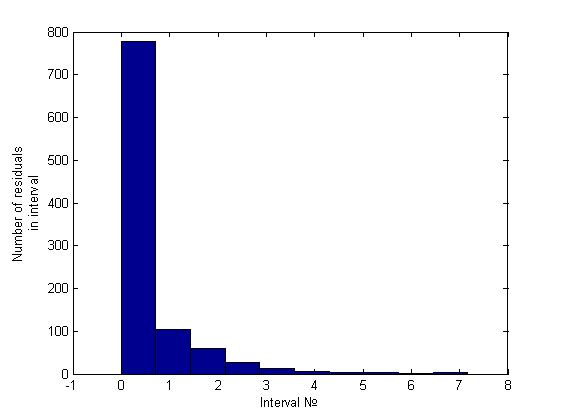
Модель №3 (плохая,многомерная)
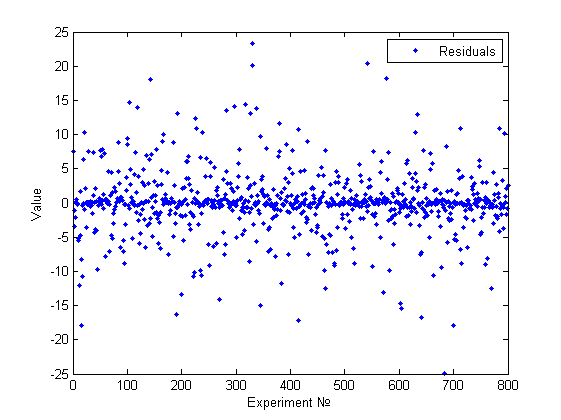
Нормальность отвергнута. Гетероскедастичность была обнаружена как эвристикой, так и тестом Голдфелда-Квандта (зависимость от первой и второй и независимость от пятой переменной). Приведем гистограмму полученную эвристикой:
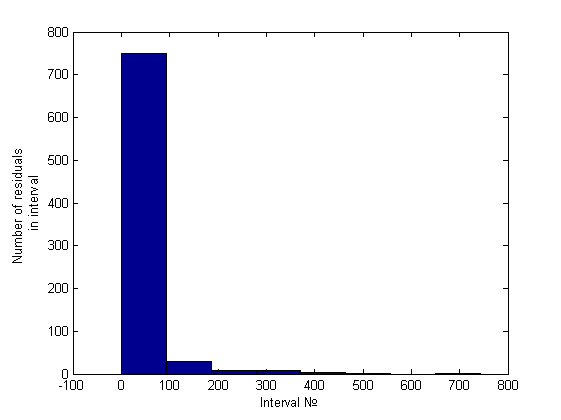
Выводы
Статистические проверки на нормальность показали себя с наилучшей стороны. Эвристика показала хорошие результаты в исследовании на гетероскедастичность. Тест Голдфелда-Квандта не сработал только в одном тесте. Тест Ансари-Брэдли (использовался для проверки на постоянство дисперсии) показал наихудшие результаты, так как с его помощью не удалось различить две существенно разные модели. Это вполне объяснимо: мы применяли этот тест для сравнения дисперсий двух случайных выборок взятых из нашего вектора остатков. Вполне очевидно что результат достаточно не предсказуем вследствие именно этой случайности выборок. В итоге мы получали одинаковые результаты для разных моделей. (причем увеличение числа экспериментов не решает данной проблемы).
Ошибки и остатки

СОДЕРЖАНИЕ
Введение [ править ]
В одномерных распределениях [ править ]
Если мы предположим нормально распределенную популяцию со средним значением μ и стандартным отклонением σ и выберем индивидуумов независимо, то мы имеем
и выборочное среднее
Икс ¯ знак равно Икс 1 + ⋯ + Икс п п <\ displaystyle <\ overline
случайная величина, распределенная таким образом, что:
В статистических ошибках затем
с ожидаемыми значениями нуля, [1] тогда как остатки равны
Замечание [ править ]
Регрессии [ править ]
Однако из-за поведения процесса регрессии распределения остатков в разных точках данных (входной переменной) могут различаться, даже если сами ошибки распределены одинаково. Конкретно, в линейной регрессии, где ошибки одинаково распределены, изменчивость остатков входных данных в середине области будет выше, чем изменчивость остатков на концах области: [6] линейные регрессии подходят для конечных точек лучше, чем середина. Это также отражается в функциях влияния различных точек данных на коэффициенты регрессии : конечные точки имеют большее влияние.
Другое использование слова «ошибка» в статистике [ править ]
Использование термина «ошибка», как обсуждалось в разделах выше, означает отклонение значения от гипотетического ненаблюдаемого значения. По крайней мере, два других использования также встречаются в статистике, оба относятся к наблюдаемым ошибкам прогнозирования:
Среднеквадратичная ошибка или среднеквадратичная ошибка (MSE) и среднеквадратичная ошибка (RMSE) относятся к тому, на сколько значения, предсказанные оценщиком, отличаются от оцениваемых величин (обычно за пределами выборки, по которой была оценена модель).
Ошибки и остатки
Если мы предположим нормально распределенную популяцию со средним значением μ и стандартным отклонением σ и выберем индивидуумов независимо, то мы
Икс ¯ знак равно Икс 1 + ⋯ + Икс п п <\ displaystyle <\ overline
случайная величина, распределенная таким образом, что:
В статистических ошибках затем
с ожидаемыми значениями нуля, [1] тогда как остатки равны
Замечание
Однако из-за поведения процесса регрессии распределения остатков в разных точках данных (входной переменной) могут различаться, даже если сами ошибки распределены одинаково. Конкретно, в линейной регрессии, где ошибки одинаково распределены, изменчивость остатков входных данных в середине области будет выше, чем изменчивость остатков на концах области: [6] линейные регрессии подходят для конечных точек лучше, чем середина. Это также отражается в функциях влияния различных точек данных на коэффициенты регрессии : конечные точки имеют большее влияние.
Использование термина «ошибка», как обсуждалось в разделах выше, означает отклонение значения от гипотетического ненаблюдаемого значения. По крайней мере, два других использования также встречаются в статистике, оба относятся к наблюдаемым ошибкам прогнозирования:
Среднеквадратичная ошибка или среднеквадратичная ошибка (MSE) и среднеквадратичная ошибка (RMSE) относятся к тому, на сколько значения, предсказанные оценщиком, отличаются от оцениваемых величин (обычно за пределами выборки, по которой была оценена модель).
Ошибки и остатки
Если мы предположим, что популяция нормально распределена со средним значением μ и стандартным отклонением σ, и выберем индивидуумов независимо, то мы имеем
Икс ¯ знак равно Икс 1 + ⋯ + Икс п п <\ displaystyle <\ overline
случайная величина, распределенная таким образом, что:
В статистических ошибках затем
с ожидаемыми значениями нуля, [1] тогда как остатки равны
Замечание
Однако из-за поведения процесса регрессии распределения остатков в разных точках данных (входной переменной) могут различаться, даже если сами ошибки распределены одинаково. Конкретно, в линейной регрессии, где ошибки одинаково распределены, изменчивость остатков входных данных в середине области будет выше, чем изменчивость остатков на концах области: [6] линейные регрессии подходят для конечных точек лучше, чем середина. Это также отражается в функциях влияния различных точек данных на коэффициенты регрессии : конечные точки имеют большее влияние.
Использование термина «ошибка», как обсуждалось в разделах выше, означает отклонение значения от гипотетического ненаблюдаемого значения. По крайней мере, два других использования также встречаются в статистике, оба относятся к наблюдаемым ошибкам прогнозирования:
Среднеквадратичная ошибка или среднеквадратичная ошибка (MSE) и среднеквадратичная ошибка (RMSE) относятся к тому, на сколько значения, предсказанные оценщиком, отличаются от оцениваемых величин (обычно за пределами выборки, по которой была оценена модель).



