Почему стоит научиться «парсить» сайты, или как написать свой первый парсер на Python
В этой статье я постараюсь понятно рассказать о парсинге данных и его нюансах.

Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
И сделаем наш первый get-запрос.
Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
Получаем такой код.
И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
После запуска появится файл test.csv — с результатами поиска.
«Кто владеет информацией, тот владеет миром» (Н. Ротшильд).
Web Scraping с помощью python
Введение
Недавно заглянув на КиноПоиск, я обнаружила, что за долгие годы успела оставить более 1000 оценок и подумала, что было бы интересно поисследовать эти данные подробнее: менялись ли мои вкусы в кино с течением времени? есть ли годовая/недельная сезонность в активности? коррелируют ли мои оценки с рейтингом КиноПоиска, IMDb или кинокритиков?
Но прежде чем анализировать и строить красивые графики, нужно получить данные. К сожалению, многие сервисы (и КиноПоиск не исключение) не имеют публичного API, так что, приходится засучить рукава и парсить html-страницы. Именно о том, как скачать и распарсить web-cайт, я и хочу рассказать в этой статье.
В первую очередь статья предназначена для тех, кто всегда хотел разобраться с Web Scrapping, но не доходили руки или не знал с чего начать.
Off-topic: к слову, Новый Кинопоиск под капотом использует запросы, которые возвращают данные об оценках в виде JSON, так что, задача могла быть решена и другим путем.
Задача
Инструменты
Загрузка данных
Первая попытка
Приступим к выгрузке данных. Для начала, попробуем просто получить страницу по url и сохранить в локальный файл.
Открываем полученный файл и видим, что все не так просто: сайт распознал в нас робота и не спешит показывать данные. 
Разберемся, как работает браузер
Однако, у браузера отлично получается получать информацию с сайта. Посмотрим, как именно он отправляет запрос. Для этого воспользуемся панелью «Сеть» в «Инструментах разработчика» в браузере (я использую для этого Firebug), обычно нужный нам запрос — самый продолжительный.
Как мы видим, браузер также передает в headers UserAgent, cookie и еще ряд параметров. Для начала попробуем просто передать в header корректный UserAgent.
На этот раз все получилось, теперь нам отдаются нужные данные. Стоит отметить, что иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке Requests.
Скачаем все оценки
Парсинг
Немного про XPath
XPath — это язык запросов к xml и xhtml документов. Мы будем использовать XPath селекторы при работе с библиотекой lxml (документация). Рассмотрим небольшой пример работы с XPath
Подробнее про синтаксис XPath также можно почитать на W3Schools.
Вернемся к нашей задаче
Каждый фильм представлен как
. Рассмотрим, как вытащить русское название фильма и ссылку на страницу фильма (также узнаем, как получить текст и значение атрибута).
Еще небольшой хинт для debug’a: для того, чтобы посмотреть, что внутри выбранной ноды в BeautifulSoup можно просто распечатать ее, а в lxml воспользоваться функцией tostring() модуля etree.
Резюме
В результате, мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup и lxml, а также получили пригодные для дальнейшего анализа данные о просмотренных фильмах на КиноПоиске.
Полный код проекта можно найти на github’e.
Парсим на Python: Pyparsing для новичков
Парсинг (синтаксический анализ) представляет собой процесс сопоставления последовательности слов или символов — так называемой формальной грамматике. Например, для строчки кода:
имеет место следующая грамматика: сначала идёт ключевое слово import, потом название модуля или цепочка имён модулей, разделённых точкой, потом ключевое слово as, а за ним — наше название импортируемому модулю.
В результате парсинга, например, может быть необходимо прийти к следующему выражению:
Данное выражение представляет собой словарь Python, который имеет два ключа: ‘import’ и ‘as’. Значением для ключа ‘import’ является список, в котором по порядку перечислены названия импортируемых модулей.
Для парсинга как правило используют регулярные выражения. Для этого имеется модуль Python под названием re (regular expression — регулярное выражение). Если вам не доводилось работать с регулярными выражениями, их вид может вас испугать. Например, для строки кода ‘import matplotlib.pyplot as plt’ оно будет иметь вид:
К счастью, есть удобный и гибкий инструмент для парсинга, который называется Pyparsing. Главное его достоинство — он делает код более читаемым, а также позволяет проводить дополнительную обработку анализируемого текста.
В данной статье мы установим Pyparsing и создадим на нём наш первый парсер.
Вначале установим Pyparsing. Если Вы работаете в Linux, в командной строке наберите:
В Windows Вам необходимо в командной строке, запущенной с правами администратора, предварительно зайти в каталог, где лежит файл pip.exe (например, C:\Python27\Scripts\), после чего выполнить:
Другой способ — это зайти на страницу проекта Pyparsing на SourceForge, скачать там инсталлятор для Windows и установить Pyparsing как обычную программу. Полную информацию о всевозможных способах установки Pyparsing можно получить на странице проекта.
Перейдём к парсингу. Пусть s — следующая строка:
В результате парсинга мы хотим получить словарь:
Сначала необходимо импортировать Pyparsing. Запустите например Python IDLE и введите:
Звёздочка * выше означает импорт всех имён из pyparsing. В результате это может нарушить рабочее пространство имён, что приведёт к ошибкам в работе программы. В нашем случае * используется временно, потому что мы пока не знаем, какие классы из Pyparsing мы будем использовать. После того, как мы напишем парсер, мы заменим * на названия использованных нами классов.
При использовании pyparsing, парсер вначале пишется для отдельных ключевых слов, символов, коротких фраз, а потом из отдельных частей получается парсер для всего текста.
Начнём с того, что у нас в строке есть название модуля. Формальная грамматика: в общем случае название модуля — это слово, состоящее из букв и символа нижнего подчёркивания. На pyparsing:
Word — это слово, alphas — буквы. Word(alphas + ‘_’) — слово, состоящее из букв и нижнего подчёркивания. module_name переводится как название модуля. Теперь читаем всё вместе: название модуля — это слово, состоящее из букв и символа нижнего подчёркивания. Таким образом, запись на Pyparsing очень близка к естественному языку.
Полное имя модуля — это название модуля, потом точка, потом название другого модуля, потом снова точка, потом название третьего модуля и так далее, пока по цепочке не дойдём до искомого модуля. Полное имя модуля может состоять из имени одного модуля и не иметь точек. На pyparsing:
ZeroOrMore дословно переводится как «ноль или более», а это означает, что содержимое в скобках может повторяться несколько раз или отсутствовать. В итоге читаем полностью вторую строчку парсера: полное имя модуля — это название модуля, после которого ноль и более раз идут точка и название модуля.
После полного названия модуля идёт необязательная часть ‘as plt’. Она представляет собой ключевое слово ‘as’, после которого идёт имя, которое мы сами дали импортируемому модулю. На pyparsing:
Optional дословно переводится как «необязательный», а это означает, что содержимое в скобках может быть, а может отсутствовать. В сумме получаем: «необязательное выражение, состоящее из слова ‘as’ и названия модуля.
Полная инструкция импорта состоит из ключевого слова import, после которого идёт полное имя модуля, потом необязательная конструкция ‘as plt’. На pyparsing:
В итоге имеем наш первый парсер:
Теперь надо распарсить строку s:
Вывод можно улучшить, преобразовав результат в список:
Теперь будем совершенствовать парсер. Прежде всего, мы бы не хотели видеть в выводе парсера слово import и точку между названиями модулей. Для подавления вывода используется Suppress(). С учётом этого наш парсер выглядит так:
Как видно из двух строчек выше, чтобы дать результату парсинга имя, нужно выражение парсера поставить в скобки, и после этого выражения в скобках дать название результата. Давайте посмотрим, что изменилось. Для этого выполним код:
Теперь мы можем отдельно извлекать цепочку модулей для импорта искомого и наше название для него. Осталось сделать так, чтобы парсер возвращал словарь. Для этого используется так называемое ParseAction — действие в процессе парсинга:
lambda — это анонимная функция в Python, t — аргумент этой функции. Потом идёт двоеточие и выражение словаря Python, в который мы подставляем нужные нам данные. Когда мы вызываем asList(), мы получаем список. Имя модуля после as всегда одно, и список t.import_as.asList() всегда будет содержать только одно значение. Поэтому мы берём единственный элемент списка (он имеет индекс ноль) и пишем asList()[0].
Проверим парсер. Выполним parse_module.parseString(s).asList() и получим:
Мы почти достигли цели. Так как у полученного списка единственный аргумент, добавим [0] в конце строки для парсинга текста: parse_module.parseString(s).asList()[0]
Мы получили то, что хотели.
Достигнув цели, необходимо вернуться к ‘from pyparsing import *’ и поменять звёздочку на те классы, которые нам пригодились:
В итоге наш код имеет следующий вид:
Мы рассмотрели совсем простой пример и лишь небольшую часть возможностей Pyparsing. За бортом — создание рекурсивных выражений, обработка таблиц, поиск по тексту с оптимизацией, резко ускоряющей сам поиск, и многое другое.
В заключение пару слов о себе. Я аспирант и ассистент МГТУ им. Баумана (кафедра МТ-1 „Металлорежущие станки“). Увлекаюсь Python, Linux, HTML, CSS и JS. Моё хобби — автоматизация инженерной деятельности и инженерных расчётов. Считаю, что могу быть полезным Хабру, делясь своими знаниями о работе в Pyparsing, Sage и некоторыми особенностями автоматизации инженерных расчётов. Также знаю среду SageMathCloud, которая является мощной альтернативой Wolfram Alpha. SageMathCloud заточена на проведение расчётов на Python в облаке. При этом Вам доступна консоль (Ubuntu под капотом), Sage, IPython и LaTeX. Есть возможность совместной работы. Помимо кода на Python SageMathCloud поддерживает html, css, js, coffescript, go, fortran, scilab и многое другое. В настоящее время среда бесплатна (достаточно стабильная бета-версия), потом будет будет работать по системе Freemium. На текущий момент времени эта среда не освещена на Хабре, и я хотел бы восполнить этот пробел.
Благодарю Дарью Фролову и Никиту Коновалова за помощь в редактировании статьи.
Как устроен парсер Python, и как втрое уменьшить потребление им памяти
Любой, кто изучал устройство языков программирования, примерно представляет, как они работают: парсер в соответствии с формальной грамматикой ЯП превращает входной текст в некоторое древовидное представление, с которой работают последующие этапы (семантический анализ, различные трансформации, и генерация кода).

(За нижеследующим описанием работы парсера удобно было бы следить по этому листингу — например, открыв его в соседней вкладке.)
Для работы с КСД в Python есть стандартный модуль parser :
В его исходном коде ( Modules/parsermodule.c ) для проверки КСД на соответствие грамматике Python были >2000 рукописных строк, которые выглядели примерно так:
Легко догадаться, что такой однообразный код можно было бы и автоматически генерировать по формальной грамматике. Немногим сложнее догадаться, что такой код уже генерируется автоматически — именно так работают автоматы, используемые первым парсером! Выше я затем в подробностях объяснял его устройство, чтобы пояснить, каким образом я в марте этого года предложил заменить все эти простыни рукописного кода, которые нужно править каждый раз, когда меняется грамматика, — на прогон всех тех же самых автоматически сгенерированных КА, которыми пользуется сам парсер. Это к разговорам о том, нужно ли программистам знать алгоритмы.
В июне мой патч был принят, так что в Python 3.6+ вышеприведённых простыней в Modules/parsermodule.c уже нет, а зато есть несколько десятков строк моего кода.
Работать с таким громоздким и избыточным КСД, как было показано выше, довольно неудобно; и поэтому второй парсер ( Python/ast.c ), написанный целиком вручную, обходит КСД и создаёт по нему абстрактное синтаксическое дерево. Грамматика АСД описана в файле Parser/Python.asdl ; для нашей программы АСД будет таким, как показано справа.
Необходимость прохода по длинным «бамбуковым ветвям» делает код Python/ast.c просто отвратительным:
Многократно повторяющиеся на всём протяжении второго парсера if (NCH(n) == 1) n = CHILD(n, 0); — иногда, как в этой функции, внутри цикла — означают «если у текущего узла КСД всего один ребёнок, то вместо текущего узла надо рассматривать его ребёнка».
Но разве что-то мешает сразу во время создания КСД удалять «однодетные» узлы, подставляя вместо них их детей? Ведь это и сэкономит кучу памяти, и упростит второй парсер, позволяя избавиться от многократного повторения goto loop; по всему коду, от вида которого Дейкстра завращался бы волчком в своём гробу!
С другой стороны, у многих узлов в результате «сжатия ветвей» дети теперь могут быть новых типов, и поэтому во многих местах кода приходится добавлять новые условия.
С моим патчем стандартный набор бенчмарков показывает сокращение потребления памяти процессом python до 30%, при неизменившемся времени работы. На вырожденных примерах сокращение потребления памяти доходит до трёхкратного!
Но увы, за полгода с тех пор, как я предложил свой патч, никто из мейнтейнеров так и не отважился его отревьюить — настолько он большой и страшный. В сентябре же мне ответил сам Гвидо ван Россум: «Раз за всё это время никто к патчу интереса не проявил, — значит, никого другого потребление памяти парсером не заботит. Значит, нет смысла тратить время мейнтейнеров на его ревью.»
Надеюсь, эта статья объясняет, почему мой большой и страшный патч на самом деле нужный и полезный; и надеюсь, после этого объяснения у Python-сообщества дойдут руки его отревьюить.
Парсинг на Python с Beautiful Soup
Парсинг — это распространенный способ получения данных из интернета для разного типа приложений. Практически бесконечное количество информации в сети объясняет факт существования разнообразных инструментов для ее сбора. В процессе скрапинга компьютер отправляет запрос, в ответ на который получает HTML-документ. После этого начинается этап парсинга. Здесь уже можно сосредоточиться только на тех данных, которые нужны. В этом материале используем такие библиотеки, как Beautiful Soup, Ixml и Requests. Разберем их.
Установка библиотек для парсинга
Чтобы двигаться дальше, сначала выполните эти команды в терминале. Также рекомендуется использовать виртуальную среду, чтобы система «оставалась чистой».
Поиск сайта для скрапинга
Для знакомства с процессом скрапинга можно воспользоваться сайтом https://quotes.toscrape.com/, который, похоже, был создан для этих целей.
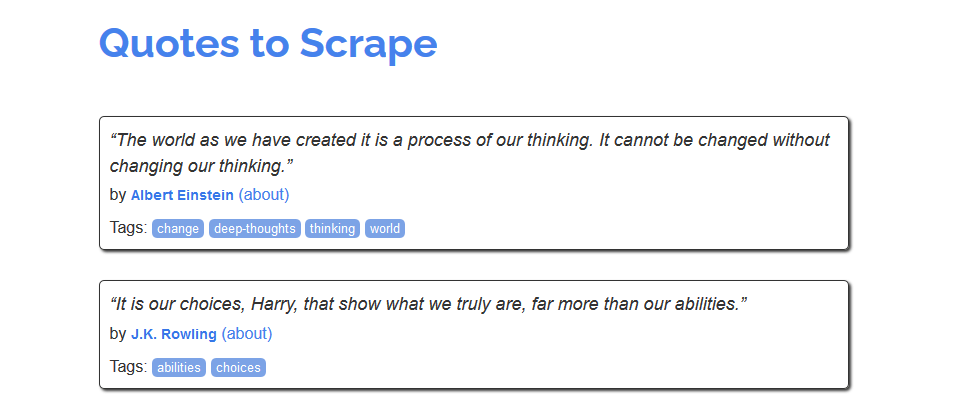
Из него можно было бы создать, например, хранилище имен авторов, тегов или самих цитат. Но как это сделать? Сперва нужно изучить исходный код страницы. Это те данные, которые возвращаются в ответ на запрос. В современных браузерах этот код можно посмотреть, кликнув правой кнопкой на странице и нажав «Просмотр кода страницы».

На экране будет выведена сырая HTML-разметка страница. Например, такая:
На этом примере можно увидеть, что разметка включает массу на первый взгляд перемешенных данных. Задача веб-скрапинга — получение доступа к тем частям страницы, которые нужны. Многие разработчики используют регулярные выражения для этого, но библиотека Beautiful Soup в Python — более дружелюбный способ извлечения необходимой информации.
Создание скрипта скрапинга
В PyCharm (или другой IDE) добавим новый файл для кода, который будет отвечать за парсинг.
Вот что происходит: ПО заходит на сайт, считывает данные, получает исходный код — все по аналогии с ручным подходом. Единственное отличие в том, что в этот раз достаточно лишь одного клика.
Прохождение по структуре HTML
Написанный скрипт уже получает данные о разметке из указанного адреса. Дальше нужно сосредоточиться на конкретных интересующих данных.

Таким образом и происходит дешифровка данных, которые требуется получить. Сперва нужно найти некий шаблон на странице, а после этого — создать код, который бы работал для него. Можете поводить мышью и увидеть, что это работает для всех элементов. Можно увидеть соотношение любой цитаты на странице с соответствующим тегом в коде.
Скрапинг же позволяет извлекать все похожие разделы HTML-документа. И это все, что нужно знать об HTML для скрапинга.



