Руководство по парсингу XML Python: чтение XML-файла
Дата публикации: 2019-07-18

От автора: что такое XML? XML расшифровывается как расширяемый язык разметки. Он был разработан для хранения и передачи небольших и средних объемов данных и широко используется для обмена структурированной информацией.
Python позволяет парсировать и изменять XML-документ. Для парсинга XML-документа вам необходимо иметь в памяти весь XML-документ. В этом руководстве мы рассмотрим, как в Python использовать класс XML minidom для загрузки и парсинга XML-файла.
Как парсить XML с помощью minidom
Как создать XML-узел

Бесплатный курс «Python. Быстрый старт»
Получите курс и узнайте, как создать программу для перевода текстов на Python
Как парсить XML с помощью ElementTree
Как парсить XML с помощью minidom
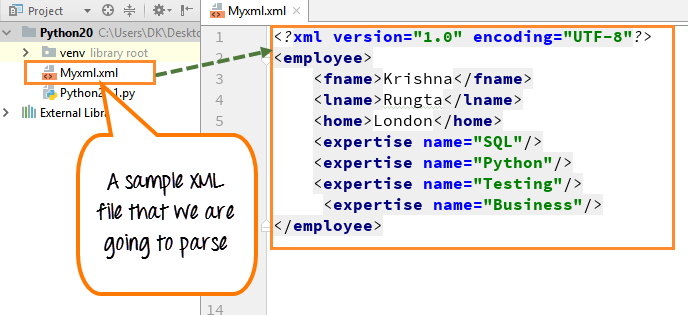
Мы создали образец XML-файла, который мы собираемся парсить.
Шаг 1) Внутри файла мы видим имя, фамилию, дом и навыки (SQL, Python, Testing и Business)
Шаг 2) После того, как мы спарсим документ, мы выведем «имя узла» корня документа и «первый дочерний тэг». Tagname и nodename являются стандартными свойствами файла XML.

Импортируйте модуль xml.dom.minidom и объявите файл для парсинга (myxml.xml)
Этот файл содержит основную информацию о сотруднике, такую как имя, фамилия, адрес, навыки и т. д.
Мы используем функцию parse в minidom XML для загрузки и парсинга файла XML
У нас есть переменная doc, doc получает результат функции parse
Мы хотим вывести имя файла и дочерний тэг, поэтому объявляем это в функции print
Запустите код. Он выведет имя узла (#document) из файла XML и первый дочерний тэг (employee) из файла XML.
Примечание: Nodename и tagname являются стандартными именами или свойствами XML dom. В случае, если вы не знакомы с этим типом именования.
Шаг 3) Мы также можем вызвать список тегов XML из документа XML и вывести его. Здесь мы вывели набор навыков, таких как SQL, Python, Testing и Business.

Объявление переменной expertise, из которой мы будем извлекать всю информацию сотрудника
Используем стандартную функцию dom с именем «getElementsByTagName»
Она получит все элементы с именем skill
Объявляем цикл для каждого из тегов skill
Как создать XML-узел
Мы можем создать новый атрибут с помощью функции «createElement», а затем добавить этот новый атрибут или тег к существующим тегам XML. Мы добавили новый тег «BigData» в XML-файл.
Вам нужно написать код, чтобы добавить новый атрибут (BigData) в существующий тег XML
Затем вам нужно вывести тег XML с новыми атрибутами, добавленными к существующему тегу XML.

Чтобы добавить новый XML и вставить его в документ, мы используем код «doc.create elements»
Бесплатный курс «Python. Быстрый старт»
Получите курс и узнайте, как создать программу для перевода текстов на Python
Этот код создаст новый тег skill для нашего нового атрибута «Big-data»
Добавьте этот тег в first child документа (employee)
Парсинг (разбор) XML документов с помощью CSS селекторов
Привет. Заметил что постов посвященных Symfony 2.0 все еще не много. Постараюсь это исправить в ближайшее время топиками и переводами про компоненты фреймворка. Сейчас же представляю вашему вниманию перевод статьи с блога Фабьена (Fabien Potencier) который всегда интересно читать. Перевод, возможно не всегда дословный, но смысл я старался передавать четко. Итак начнем.
— HTML и XML документы это как хлеб и масло для веб-разработчиков. День за днем вы, скорее всего, создаете множество HTML документов. И наверняка вам приходится парсить некоторые из них время от времени: потому что вы используете веб службы и хотите извлечь некоторую информацию, или потому, что вы хотите получить данные с нужных веб страниц, или просто потому, что хотите написать функциональные тесты для веб сайта. Получить содержимое достаточно просто, но как его разобрать, чтобы выделить нужную информацию?
PHP уже поставляется с большим количеством инструментов для парсинга XML документов: например, SimpleXML, DOM и XMLReader. Но как только вам нужно извлечь информацию глубоко зашитую в структуру документа, все не так легко, как и должно быть. Конечно же, XPath ваш лучший друг если вам нужно выбрать элементы, но кривая изучения очень крутая. Даже выражения, которые должны быть простыми, оказываются громоздкими. Для примера, вот XPath выражение для нахождения всех тегов h1 с классом «foo»:
Выражение получилось сложным, так как у тега может быть несколько классов:
h1 class =»foo» > Foo h1 >
h1 class =»foo bar» > Foo h1 >
h1 class =»foobar bar» > Foo h1 >
Выражение должно выбирать первые два тега h1, но не третий.
Конечно же, все знают что сделать то же на css проще простого:
Для функциональных тестов в Symfony 2, я искал путь увеличения мощи и выразительности CSS селекторов при помощи средств, которые уже есть в PHP. Первая идея которая пришла мне на ум, это конвертировать CSS селектор в его XPath эквивалент. Но возможно ли это? Ответ скорее «Да».
John Resig написал в своем посте почти на ту же тему: «Самое главное понять, что CSS селекторы, часто, очень коротки, но крайне неэффективны по сравнению с XPath».
Написание «токенайзера», парсера, и компоновщика, способного преобразовывать CSS селекторы в XPath эквиваленты — не тривиальная задача. Поэтому, вместо изобретения колеса, я просмотрел существующие библиотеки. Уже очень скоро я наткнулся на lxml, библиотеку Python. Модуль lxml.cssselect библиотеки lxml делает то что нужно. Поэтому я потратил время на трансляцию кода с Python на язык PHP, добавил некоторые модульные тесты, и вуаля — родился компонент CSS селекторов для Symfony 2.
Для справки: в symfony 1 есть класс sfDomCssSelector, но он не конвертирует CSS селекторы в XPath. Он делает роботу хорошо, но ограничен очень простыми CSS селекторами и не может быть использован совместно со стандартными XML инструментами.
Компонент Symfony 2 CSS Selector делает только одну вещь, и пытается делать ее хорошо: конвертировать CSS селекторы в выражения XPath. Его использование очень простое:
Давайте приведем пример, как вы можете использовать компонент. Допустим вы хотите получить все названия постов и URL-ы моего блога (информация доступна по адресу fabien.potencier.org/articles).
$document = new \DOMDocument();
$document->loadHTMLFile( ‘http://fabien.potencier.org/articles’ );
Код очень простой, и вместо использования выражения XPath, мы позволим классу парсера преобразовать для нас CSS селекторы в выражение XPath.
Помните, что если вы работаете с XML документами, вам нужно объявить используемые пространства имен. Давайте используем SimpleXMLElement, который понимает только правильно сформированные XML документы:
Как вы могли заметить, CSS селекторы поддерживают пространства имен (xhtml|div).
Этот новый CSS Selector компонент будет использоваться в Symfony 2 для функциональных тестов (но как вы увидите в ближайшие несколько недель, совсем иначе чем было с symfony 1).
Парсеры PHP XML
В этом уроке вы узнаете, как получить ограниченное количество записей из таблицы базы данных MySQL с помощью условия LIMIT.
Что такое XML?
XML (eXtensible Markup Language, расширяемый язык разметки) используется для структурирования, хранения и передачи данных из одной системы в другую.
Он очень похож на HTML, только в XML разрешены свои собственные теги и атрибуты.
Примером совместно используемых xmls являются RSS-каналы.
Что такое DOM?
DOM — это аббревиатура от Document Object Model (Объектная Модель Документа).
Объектная Модель Документа (DOM) – это программный интерфейс (API) для HTML и XML документов.
XML-документы имеют иерархию информационных единиц, называемых узлами. DOM — это способ описания этих узлов и отношений между ними.
Документ DOM — это набор узлов или фрагментов информации, организованных в иерархию. Эта иерархия позволяет разработчику перемещаться по дереву в поисках конкретной информации. Поскольку она основана на иерархии информации, модель DOM называется древовидной.
XML DOM, с другой стороны, также предоставляет API, который позволяет разработчику добавлять, редактировать, перемещать или удалять узлы в дереве в любой момент для создания приложения.
Что такое API? Это набор функций, с помощью которых мы можем сделать запрос сайту и получать нужный ответ. Вот этот ответ чаще всего приходит в формате XML.
Что такое CDATA?
Термин CDATA означает символьные данные. CDATA определяется как блоки текста, которые не анализируются анализатором, но в остальном распознаются как разметка.
Предопределенные объекты, такие как & lt ;, & gt; и & amp; требуют набора текста и, как правило, плохо читаются в разметке. В таких случаях можно использовать раздел CDATA. Используя раздел CDATA, вы даете команду синтаксическому анализатору, чтобы конкретный раздел документа не содержал разметки и обрабатывался как обычный текст.
Что такое парсер XML?
Парсер XML — это программа, которая переводит документ XML в объект объектной модели документа XML (DOM).
Затем объектом XML DOM можно управлять с помощью JavaScript, Python, PHP и т.д.
XML-парсер нам понадобится для чтения и обновления, создания и управления XML-документом.
И хотя в последнее время все большее число веб-сервисов возвращают данные в формате JSON, все же большинство, на данный момент, использует XML, поэтому важно изучить парсинг XML, если вы хотите использовать весь спектр доступных интерфейсов API.
В PHP есть два основных типа парсеров XML:
Древовидные парсеры
Древовидные парсеры (DOM) обеспечивают представление XML, ориентированное на документы. При синтаксическом анализе на основе дерева парсеры хранят весь документ в памяти и преобразуют XML-документ в древовидную структуру, что для больших документов требует очень больших затрат памяти.
Все элементы и атрибуты доступны сразу, но не раньше, чем будет проанализирован весь документ. Этот метод полезен, если вам нужно перемещаться по документу и, возможно, изменять различные фрагменты документа, именно поэтому он полезен для объектной модели документа (DOM), целью которой является управление документами с помощью языков сценариев или Java.
Этот тип синтаксического парсера является лучшим вариантом только для небольших XML-документов, поскольку он вызывает серьезные проблемы с производительностью при обработке больших XML-документов.
К древовидным парсерам относятся:
Парсеры на основе событий
Парсеры на основе событий (SAX) обеспечивают представление XML, ориентированное на данные.
Вместо того, чтобы PHP анализировал XML-файл, сохраняя его все в своей памяти и считывая сразу несколько узлов, анализатор на основе событий считывает один узел всякий раз, когда это требуется. При переходе на другой узел старый удаляется.
Вот два наиболее популярных анализатора XML на основе событий:
Пишем свой XML-парсер
 Решив запустить небольшой сервис на подаренном мне хостинге, оказалось, что там нету ни одного xml-парсера: ни SimpleXML, ни DOMXML, а только libxml и xml-rpc. Недолго думая, я решил написать свой. Мне требовался разбор не сложных rss-лент, поэтому хватило достаточно просто класса xml => array. [1]
Решив запустить небольшой сервис на подаренном мне хостинге, оказалось, что там нету ни одного xml-парсера: ни SimpleXML, ни DOMXML, а только libxml и xml-rpc. Недолго думая, я решил написать свой. Мне требовался разбор не сложных rss-лент, поэтому хватило достаточно просто класса xml => array. [1]
Но для интересной статьи этого было явно не достаточно, поэтому сейчас мы напишем свою замену для SimpleXML. А заодно пробежимся по многим интересным возможностям PHP 5.
Постановка задачи
Немного магии?
XML и expat
Указатели
Кодинг
public function __toString ()
public function count ()
public function getIterator ()
public function getParent ()
throw new Exception ( «UFO steals [$name]!» );
throw new Exception ( «Holy cow! There is’nt [$offset] attribute!» );
public function getIterator () <
Все. Парсер готов к работе. Дабы не раздувать статью еще больше, полностью исходный код с комментариями я загрузил на Google Docs и пример использования тоже. [6]
Что дальше?
Это все еще не полная замена для SimpleXML, наш парсер до сих пор не умеет создавать xml-документ из данных, находящихся в нем. Добавление нужных функций не сложная задача, поэтому я ее оставлю, для тех, кому это интересно, как домашнее задание 🙂
Xml парсер
Почему нужны xml парсеры?

В первую очередь потому что сам по себе формат xml популярный среди компьютерных стандартов. XML файл выглядит так:
т.е. по сути есть теги, есть какие-то правила какие теги должны следовать друг за другом.
Причина популярности xml файлов заключается в том, что он хорошо читаем человеком. И то, что его относительно легко обрабатывать в программах.
Минусы xml-файлов.

Как пишутся XML парсеры?
Глобально есть 2 разных подхода как парсить xml файлы.
Однако программировать по поточному варианту сложно. Сложность при достаточно серьезном извлечении вырастает в разы, что соответственно сказывается и на сроках и на бюджете.
Валидность xml файлов и парсеров.

Как создавать xml парсеры (первый вариант)

Есть такой язык запросов к XML данным как Xpath. Язык этот имеет две редакции, углубляться не будем в особенности каждой версии. Лучше представление про этот язык покажут примеры того как использовать его для извлечения данных. Например.



