Переобучение
Переобучение (англ. overfitting) — негативное явление, возникающее, когда алгоритм обучения вырабатывает предсказания, которые слишком близко или точно соответствуют конкретному набору данных и поэтому не подходят для применения алгоритма к дополнительным данным или будущим наблюдениям.
Недообучение (англ. underfitting) — негативное явление, при котором алгоритм обучения не обеспечивает достаточно малой величины средней ошибки на обучающей выборке. Недообучение возникает при использовании недостаточно сложных моделей.
Содержание
Примеры [ править ]
На примере линейной регрессии [ править ]
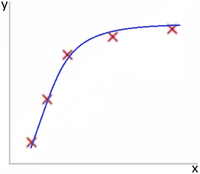
Представьте задачу линейной регрессии. Красные точки представляют исходные данные. Синие линии являются графиками полиномов различной степени M, аппроксимирующих исходные данные.
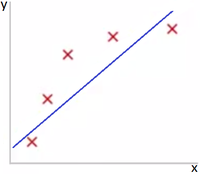

Как видно из Рис. 1, данные не поддаются линейной зависимости при небольшой степени полинома и по этой причине модель, представленная на данном рисунке, не очень хороша.
На Рис. 2 представлена ситуация, когда выбранная полиномиальная функция подходит для описания исходных данных.
Рис. 3 иллюстрирует случай, когда высокая степень полинома ведет к тому, что модель слишком заточена на данные обучающего датасета.
На примере логистической регрессии [ править ]
Представьте задачу классификации размеченных точек. Красные точки представляют данные класса 1. Голубые круглые точки — класса 2. Синие линии являются представлением различных моделей, которыми производится классификация данных.
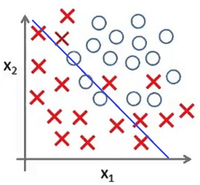
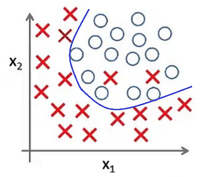
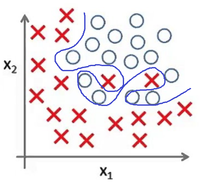
Рис. 4 показывает результат использования слишком простой модели для представленного датасета
Кривые обучения [ править ]
Кривые обучения при переобучении [ править ]
При переобучении небольшая средняя ошибка на обучающей выборке не обеспечивает такую же малую ошибку на тестовой выборке.
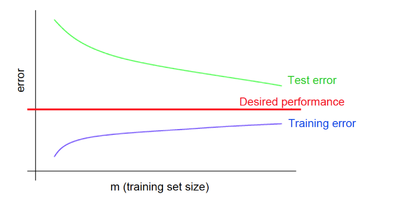
Рис. 7 демонстрирует зависимость средней ошибки для обучающей и тестовой выборок от объема датасета при переобучении.
Кривые обучения при недообучении [ править ]
При недообучении независимо от объема обучающего датасета как на обучающей выборке, так и на тестовой выборке небольшая средняя ошибка не достигается.
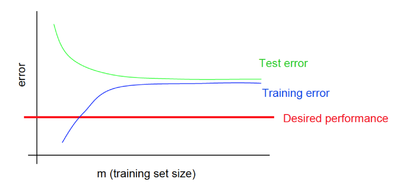
Рис. 8 демонстрирует зависимость средней ошибки для обучающей и тестовой выборок от объема датасета при недообучении.
High variance и high bias [ править ]
Bias — ошибка неверных предположений в алгоритме обучения. Высокий bias может привести к недообучению.
Variance — ошибка, вызванная большой чувствительностью к небольшим отклонениям в тренировочном наборе. Высокая дисперсия может привести к переобучению.
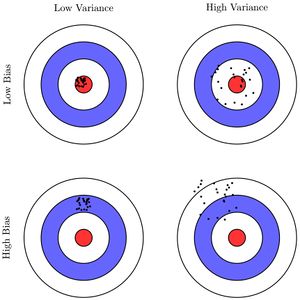
При использовании нейронных сетей variance увеличивается, а bias уменьшается с увеличением количества скрытых слоев.
Для устранения high variance и high bias можно использовать смеси и ансамбли. Например, можно составить ансамбль (boosting) из нескольких моделей с высоким bias и получить модель с небольшим bias. В другом случае при bagging соединяются несколько моделей с низким bias, а результирующая модель позволяет уменьшить variance.
Дилемма bias–variance [ править ]
Дилемма bias–variance — конфликт в попытке одновременно минимизировать bias и variance, тогда как уменьшение одного из негативных эффектов, приводит к увеличению другого. Данная дилемма проиллюстрирована на Рис 10.
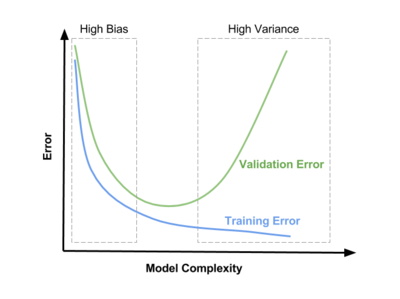
При небольшой сложности модели мы наблюдаем high bias. При усложнении модели bias уменьшается, но variance увеличится, что приводит к проблеме high variance.
Переобучение
Материал из MachineLearning.
Содержание
Обобщающая способность (generalization ability, generalization performance). Говорят, что алгоритм обучения обладает способностью к обобщению, если вероятность ошибки на тестовой выборке достаточно мала или хотя бы предсказуема, то есть не сильно отличается от ошибки на обучающей выборке. Обобщающая способность тесно связана с понятиями переобучения и недообучения.
Переобучение, переподгонка (overtraining, overfitting) — нежелательное явление, возникающее при решении задач обучения по прецедентам, когда вероятность ошибки обученного алгоритма на объектах тестовой выборки оказывается существенно выше, чем средняя ошибка на обучающей выборке. Переобучение возникает при использовании избыточно сложных моделей.
Недообучение — нежелательное явление, возникающее при решении задач обучения по прецедентам, когда алгоритм обучения не обеспечивает достаточно малой величины средней ошибки на обучающей выборке. Недообучение возникает при использовании недостаточно сложных моделей.
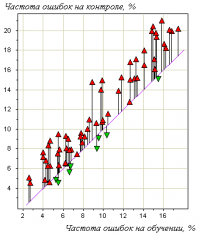
Пример. На рисунке справа показан эффект переобучения в одной задаче медицинского прогнозирования. Точки на графике соотвествуют различным методам обучения. Каждая точка получена путём усреднения по большому числу разбиений исходной выборки из 72 прецедентов на обучающую подвыборку и контрольную. Горизонтальная ось — частота ошибок на обучении; вертикальная — на контроле. Хорошо видно, что точки имеют систематическое смещение вверх относительно диагонали графика.
О природе переобучения
Эмпирическим риском называется средняя ошибка алгоритма на обучающей выборке. Метод минимизации эмпирического риска (empirical risk minimization, ERM) наиболее часто применяется для построения алгоритмов обучения. Он состоит в том, чтобы в рамках заданной модели выбрать алгоритм, имеющий минимальное значение средней ошибки на заданной обучающей выборке.
С переобучением метода ERM связано два утверждения, которые на первый взгляд могут показаться парадоксальными.
Утверждение 1. Минимизация эмпирического риска не гарантирует, что вероятность ошибки на тестовых данных будет мала. Легко строится контрпример — абсурдный алгоритм обучения, который минимизирует эмпирический риск до нуля, но при этом абсолютно не способен обучаться. Алгоритм состоит в следующем. Получив обучающую выборку, он запоминает её и строит функцию, которая сравнивает предъявляемый объект с запомненными обучающими объектами. Если предъявляемый объект в точности совпадает с одним из обучающих, то эта функция выдаёт для него запомненный правильный ответ. Иначе выдаётся произвольный ответ (например, случайный или всегда один и тот же). Эмпирический риск алгоритма равен нулю, однако он не восстанавливает зависимость и не обладает никакой способностью к обобщению.
Вывод: для успешного обучения необходимо не только запоминать, но и обобщать.
Утверждение 2. Переобучение появляется именно вследствие минимизации эмпирического риска. Пусть задано конечное множество из D алгоритмов, которые допускают ошибки независимо и с одинаковой вероятностью. Число ошибок любого из этих алгоритмов на заданной обучающей выборке подчиняется одному и тому же биномиальному распределению. Минимум эмпирического риска — это случайная величина, равная минимуму из D независимых одинаково распределённых биномиальных случайных величин. Её ожидаемое значение уменьшается с ростом D. Соотвественно, с ростом D увеличивается переобученность — разность вероятности ошибки и частоты ошибок на обучении.
В данном модельном примере легко построить доверительный интервал переобученности, так как функция распределения минимума известна. Однако в реальной ситуации алгоритмы имеют различные вероятности ошибок, не являются независимыми, а множество алгоритмов, из которого выбирается лучший, может быть бесконечным. По этим причинам вывод количественных оценок переобученности является сложной задачей, которой занимается теория вычислительного обучения. До сих пор остаётся открытой проблема сильной завышенности верхних оценок вероятности переобучения.
Утверждение 3. Переобучение связано с избыточной сложностью используемой модели. Всегда существует оптимальное значение сложности модели, при котором переобучение минимально.
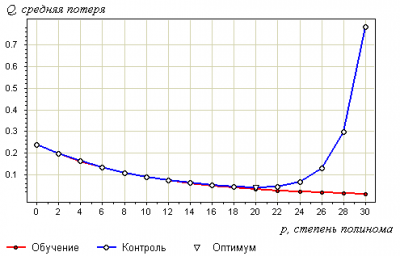
В качестве модели рассмотрим полиномы заданной степени :
В качестве метода обучения возьмём метод наименьших квадратов:
Ниже показаны графики самой выборки и аппроксимирующей функции:
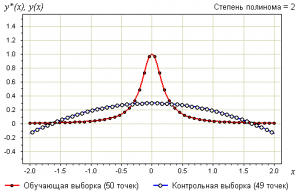
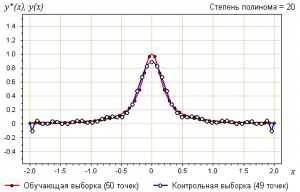
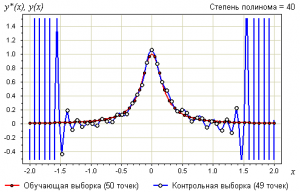
Определения
Средней потерей алгоритма на выборке называется величина
Пусть — вероятностное пространство. Ожидаемой потерей алгоритма называется величина
Не столь важно, что скрывается за термином «алгоритм». Это могут быть в частности, решающие правила в задачах классификации и распознавания образов, функции регрессии в задачах восстановления регрессии илипрогнозирования, и т. п.
Вероятность переобучения (частотное определение)
Определение. Переобученностью алгоритма относительно контрольной выборки называется разность
Определение. Вероятностью переобучения называется вероятность того, что величина переобученности превысит заданный порог  :
:
Вероятность переобучения может быть измерена эмпирически методом Монте-Карло, см. также скользящий контроль:
Вероятность переобучения (вероятностное определение)
Определение. Переобученностью алгоритма называется разность
Определение. Вероятностью переобучения называется вероятность того, что величина переобученности превысит заданный порог :
Недостатки вероятностного определения:
Теоретические верхние оценки переобученности
Сложность
Оценки, основанные на самоограничении (self-bounding)
Оценки, основанные на последовательности выборов (microchoice bounds)
Оценки, основанные на расслоении семейства алгоритмов (shell bounds)
Разделимость
Оценки, основанные на отступах (margin-based bounds)
Устойчивость
Устойчивость алгоритма обучения (algorithmic stability)
Эмпирическое измерение переобучения
См. также
Ссылки
Overfitting — статья о переобучении в англоязычной Википедии.
Переобучение
Материал из MachineLearning.
Содержание
Обобщающая способность (generalization ability, generalization performance). Говорят, что алгоритм обучения обладает способностью к обобщению, если вероятность ошибки на тестовой выборке достаточно мала или хотя бы предсказуема, то есть не сильно отличается от ошибки на обучающей выборке. Обобщающая способность тесно связана с понятиями переобучения и недообучения.
Переобучение, переподгонка (overtraining, overfitting) — нежелательное явление, возникающее при решении задач обучения по прецедентам, когда вероятность ошибки обученного алгоритма на объектах тестовой выборки оказывается существенно выше, чем средняя ошибка на обучающей выборке. Переобучение возникает при использовании избыточно сложных моделей.
Недообучение — нежелательное явление, возникающее при решении задач обучения по прецедентам, когда алгоритм обучения не обеспечивает достаточно малой величины средней ошибки на обучающей выборке. Недообучение возникает при использовании недостаточно сложных моделей.
Пример. На рисунке справа показан эффект переобучения в одной задаче медицинского прогнозирования. Точки на графике соотвествуют различным методам обучения. Каждая точка получена путём усреднения по большому числу разбиений исходной выборки из 72 прецедентов на обучающую подвыборку и контрольную. Горизонтальная ось — частота ошибок на обучении; вертикальная — на контроле. Хорошо видно, что точки имеют систематическое смещение вверх относительно диагонали графика.
О природе переобучения
Эмпирическим риском называется средняя ошибка алгоритма на обучающей выборке. Метод минимизации эмпирического риска (empirical risk minimization, ERM) наиболее часто применяется для построения алгоритмов обучения. Он состоит в том, чтобы в рамках заданной модели выбрать алгоритм, имеющий минимальное значение средней ошибки на заданной обучающей выборке.
С переобучением метода ERM связано два утверждения, которые на первый взгляд могут показаться парадоксальными.
Утверждение 1. Минимизация эмпирического риска не гарантирует, что вероятность ошибки на тестовых данных будет мала. Легко строится контрпример — абсурдный алгоритм обучения, который минимизирует эмпирический риск до нуля, но при этом абсолютно не способен обучаться. Алгоритм состоит в следующем. Получив обучающую выборку, он запоминает её и строит функцию, которая сравнивает предъявляемый объект с запомненными обучающими объектами. Если предъявляемый объект в точности совпадает с одним из обучающих, то эта функция выдаёт для него запомненный правильный ответ. Иначе выдаётся произвольный ответ (например, случайный или всегда один и тот же). Эмпирический риск алгоритма равен нулю, однако он не восстанавливает зависимость и не обладает никакой способностью к обобщению.
Вывод: для успешного обучения необходимо не только запоминать, но и обобщать.
Утверждение 2. Переобучение появляется именно вследствие минимизации эмпирического риска. Пусть задано конечное множество из D алгоритмов, которые допускают ошибки независимо и с одинаковой вероятностью. Число ошибок любого из этих алгоритмов на заданной обучающей выборке подчиняется одному и тому же биномиальному распределению. Минимум эмпирического риска — это случайная величина, равная минимуму из D независимых одинаково распределённых биномиальных случайных величин. Её ожидаемое значение уменьшается с ростом D. Соотвественно, с ростом D увеличивается переобученность — разность вероятности ошибки и частоты ошибок на обучении.
В данном модельном примере легко построить доверительный интервал переобученности, так как функция распределения минимума известна. Однако в реальной ситуации алгоритмы имеют различные вероятности ошибок, не являются независимыми, а множество алгоритмов, из которого выбирается лучший, может быть бесконечным. По этим причинам вывод количественных оценок переобученности является сложной задачей, которой занимается теория вычислительного обучения. До сих пор остаётся открытой проблема сильной завышенности верхних оценок вероятности переобучения.
Утверждение 3. Переобучение связано с избыточной сложностью используемой модели. Всегда существует оптимальное значение сложности модели, при котором переобучение минимально.
В качестве модели рассмотрим полиномы заданной степени :
В качестве метода обучения возьмём метод наименьших квадратов:
Ниже показаны графики самой выборки и аппроксимирующей функции:
Определения
Средней потерей алгоритма на выборке называется величина
Пусть — вероятностное пространство. Ожидаемой потерей алгоритма называется величина
Не столь важно, что скрывается за термином «алгоритм». Это могут быть в частности, решающие правила в задачах классификации и распознавания образов, функции регрессии в задачах восстановления регрессии илипрогнозирования, и т. п.
Вероятность переобучения (частотное определение)
Определение. Переобученностью алгоритма относительно контрольной выборки называется разность
Определение. Вероятностью переобучения называется вероятность того, что величина переобученности превысит заданный порог :
Вероятность переобучения может быть измерена эмпирически методом Монте-Карло, см. также скользящий контроль:
Вероятность переобучения (вероятностное определение)
Определение. Переобученностью алгоритма называется разность
Определение. Вероятностью переобучения называется вероятность того, что величина переобученности превысит заданный порог :
Недостатки вероятностного определения:
Теоретические верхние оценки переобученности
Сложность
Оценки, основанные на самоограничении (self-bounding)
Оценки, основанные на последовательности выборов (microchoice bounds)
Оценки, основанные на расслоении семейства алгоритмов (shell bounds)
Разделимость
Оценки, основанные на отступах (margin-based bounds)
Устойчивость
Устойчивость алгоритма обучения (algorithmic stability)
Эмпирическое измерение переобучения
См. также
Ссылки
Overfitting — статья о переобучении в англоязычной Википедии.



