«ПЕРЕВЕРНУТЫЕ» ГРАФИКИ
Технология построения графиков статистик включает в себя отображение таких статистик, которые должны быть отмечены па графике в «перевёрнутом» виде.
К этому можно подойти несколькими способами, однако, это график, который является хорошим, когда статистика, которую он отражает, падает, и является плохим, когда она растёт, и он должен строиться не так, как другие графики. Иначе по по этому графику будут назначаться неправильные состояния.
Один из способов справиться с этим — это развернуть вертикальную ось таким образом, чтобы ноль был вверху. Для этого нужно просто строить график, на котором вертикальная числовая шкала, находящаяся слева, будет «перевёрнута».
Пример: если график построен обычным способом, — когда ноль находится внизу, — то уменьшение расходов, отражённое на графике, может быть ошибочно названо «состоянием Чрезвычайного положения». Если бы был построен «перевёрнутый» график (ноль на вершине шкалы), тогда по этому графику можно было бы назначить правильные состояния. Когда такой график идёт вверх, это значит, что денег тратится меньше, а когда он идёт вниз, это значит, что денег тратится больше, и вы обнаружите, что формулы состояний применимы к этому графику.
Когда расходы на графике отображаются таким образом, можно отслеживать затраты на осуществление деятельности. Конечно же, когда затраты на осуществление деятельности снижаются, это определённо не означает, что существует состояние Чрезвычайного положения.
Вы должны посмотреть и определить, хорошо это или плохо, когда увеличивается количество или объём чело-либо.
Если бы это отобразили с помощью обычной шкалы, то это выглядело бы так:
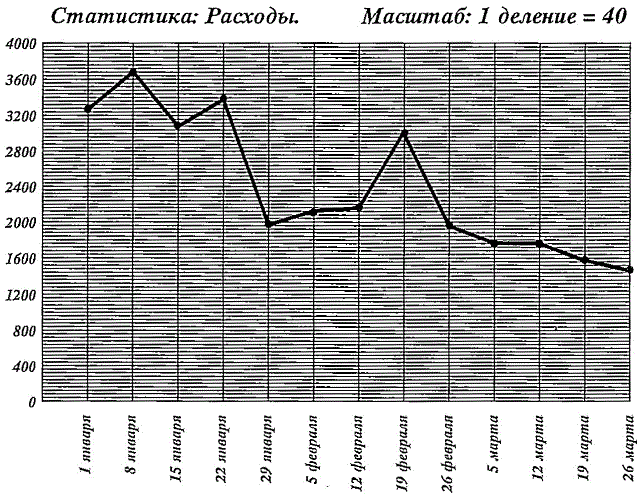
Если график построен таким способом — ноль внизу — это состояние может быть ошибочно названо «состоянием Чрезвычайного положения».
Вот этот график был построен на «перевёрнутой» шкале — ноль наверху. Это даёт точное представление и показывает, что правильное состояние — Нормальная деятельность.
Что такое перевернутая статистика


Какие фреймворки стоит освоить начинающему разработчику

Яндекс.Директ изменит логику учета корректировок в конверсионных стратегиях

Добрый день. Долго наблюдаю такую картину. Лайф показывает корявую статистику по поисковым фразам.
Например вчера не было переходов по запросу, сегодня есть.
Нажимаешь на эти просмотры, а там вообще нч. С метрикой вообще разница.
Читал как-то новость, что Яндекс что-то подмутил. Теперь верить только метрики?

Теперь только метрика показывает поисковые фразы от Яндекса
А вообще в эти цифры из лайфа можно верить, не смотря на то, что неизвестно от куда переходы.

Наберите эту фразу в поиске и посмотрите, в топе она или нет.
В метрике посмотрите, если она установлена.
mr-Lex:
Наберите эту фразу в поиске и посмотрите, в топе она или нет.
В метрике посмотрите, если она установлена.
не много понял. Лайф похоже без точной инфы, стал путать слова.
Например у меня запрос «купить пластиковые окна»
лайф показывает «пластиковые окна купить»
«Лайф» ничего не путает. Как можно путать то, о чем вообще никакой информации нет? Как может «лайф» знать, что вы ввели «купить пластиковые окна» и спутать в нем слова, если яндекс специально скрыл ваш запрос? Вообще скрыл. Совсем-совсем. Ноль информации о вашем запросе. В чем будет «лайф» путать слова, если у него ничего нет?
В связи с тем, что Гугл и Яндекс скрывают поисковые фразы, в статистике LiveInternet искусственно ставится вероятная поисковая фраза для данной страницы.
В данный момент берется наиболее популярная фраза из прошлых известных поисковых переходов на данный URL. Конкретные критерии выбора фразы могут меняться.
m@ksim:
В связи с тем, что Гугл и Яндекс скрывают поисковые фразы, в статистике LiveInternet искусственно ставится вероятная поисковая фраза для данной страницы.
Вот-вот. Это я и наблюдаю. И как раз это объяснение тому, что он путает.
Если у меня траф почти весь из Яндекса, буду смотреть только на метрику.
Что на самом деле значит перевернутая кривая доходности
Индикатор рецессии нельзя считать идеальным сигналом, но и игнорировать его тоже не стоит
Форма кривой доходности на рынке облигаций уже несколько десятилетий используется в качестве индикатора риска рецессии в США и других развитых экономиках.
На самом деле этот простой индикатор порой оказывает гипнотическое влияние на настроения инвесторов в отношении будущей экономической активности. Перевернутая кривая доходности в прошлом во многих случаях предшествовала рецессии, поэтому игнорировать ее сигналы опасно.
Политики и экономисты также обращают пристальное внимание на информацию, которую несет кривая доходности. Недавняя инверсия кривой доходности в США, которая произошла впервые с 2007 года, не сможет ускользнуть от внимания Федрезерва в рамках заседания на этой неделе. Мнения чиновников банка по этому вопросу расходятся, но большинство членов FOMC, вероятно, будут склоняться в пользу того, что последние сигналы с рынка облигаций следует воспринимать всерьез.
Надежный индикатор?
За последние 60 лет каждый раз перевернутая кривая (за исключением одного случая в конце 1960-х гг.) предшествовала рецессии. Это говорит о многом. Еще примечательнее тот факт, что кривая доходности подает сигналы о будущей экономической активности с 1850-х гг.
Несмотря на такие яркие примеры, на самом деле нет полного понимания, почему кривая переворачивается перед наступлением рецессии. Большинство экономистов указывают на тот факт, что кривая систематически выравнивается и впоследствии переворачивается в периоды ужесточения монетарной политики. Когда краткосрочные ставки растут, доходность облигаций выглядит стабильнее, отражая взгляд рынка на равновесные процентные ставки, что меняется очень медленно и плавно.
Если согласиться с тем, что кривая доходности является хорошим индикатором состояния монетарной политики, неудивительно, что она также содержит информацию об экономической активности. Это просто отражение нормального отставания между политикой и реакцией экономики, которое проявляется в большинстве макромоделей.
Федрезерв обычно использует кривую доходность для оценки вероятности рецессии в 12-месячной перспективе. Одно из ключевых моделей публикуется ФРБ Нью-Йорка и ориентируется на уклон кривой в определенный период времени.
Несмотря на то, что статистическая значимость таких методов ограничена относительно небольшим числом эпизодов рецессии, регулярность инверсии кривой перед наступлением рецессий нельзя не заметить. Последние оценки показывают, что уклон кривой в начале июня предполагает 29%-ную вероятность наступления рецессии в 12-месячной перспективе.
Впрочем, есть причины полагать, что текущие риски несколько преувеличены. Доходность долгосрочных облигаций представляет потенциальный будущий путь краткосрочных ставок плюс премию за риск. Из-за пониженных инфляционных рисков эта премия упала на 1.5% с начала 2000-х гг. Это говорит о том, что кривая демонстрирует более глубокую инверсию, чем в предыдущих случаях.
Другие методы
Федрезерв оценивает риски рецессии при помощи так называемой избыточной премии на кредитном рынке. Этот барометр настроений инвесторов не связан с риском банкротства. В рамках этой модели риск рецессии сейчас составляет всего 13%. Модель, которая существует довольно давно, пережила главное испытание в 2016 году, когда масштабное расширение кредитных спредов повысило риск рецессии до 60%. Но благодаря переходу ФРС к голубиной политике рецессии удалось избежать.
Еще один подход, который поддерживают некоторые члены FOMC, основан на влиянии кривой доходности на предложение кредита в экономике, особенно со стороны теневого банковского сектора. Исследование, опубликованное ФРБ Нью-Йорка в 2010 году, показало, что перевернутся кривая снижает маржу, заработанную на создании новых кредитов, что снижает интерес к расширению балансов через дополнительное кредитование. В свою очередь, сокращение предложения займов приводит к росту рисков рецессии.
На этой неделе заседание ФРС пройдет в условиях, когда кривая доходности и модель кредитных спредов указывают на риск рецессии в районе 13-29%, что выше нормы. Возможно, есть некоторые смягчающие факторы, связанные с необычно низкой срочной премией, которая может искажать эти сигналы. Но со стороны FOMC будет легкомысленно проигнорировать информацию, которую несет кривая доходности.
Modern Business Management, Int
+7 8482 789 757 | постановка дистанционного управления компанией
Программный комплекс StatsSoft
Программный комплекс StatsSoft разработан для централизованного сбора еженедельных статистик.
Проблемы управления, которые призван решить программный комплекс StatsSoft:
 Финансовое планирование очень тесно связано с оценкой продуктивности отдельных подразделений и сотрудников, с выявлением динамики развития компании и динамики её финансового статуса. Чтобы это было возможно, необходимо вести еженедельные графики статистик по базовым производственным и финансовым показателям, а также необходимо добиться, чтобы сотрудники подсчитывали свои собственные показатели эффективности и рисовали графики.
Финансовое планирование очень тесно связано с оценкой продуктивности отдельных подразделений и сотрудников, с выявлением динамики развития компании и динамики её финансового статуса. Чтобы это было возможно, необходимо вести еженедельные графики статистик по базовым производственным и финансовым показателям, а также необходимо добиться, чтобы сотрудники подсчитывали свои собственные показатели эффективности и рисовали графики.
Наш опыт по внедрению Финансового планирования показал, что за редким исключением руководителям не удаётся вести графиков статистик.
Обычно статистики не ведутся по ряду объективных причин:
Чтобы с этим справиться и облегчить руководителям работу, наша компания разработала собственный программный комплекс StatsSoft.
Зачем нужны статистики. Чем они отличаются от обычных способов оценки эффективности компании
При создании комплекса StatsSoft мы преследовали несколько задач:
1. Эта программа должна позволять централизованно собирать статистики.
То есть любой сотрудник с любого рабочего места (с любого компьютера) должен иметь возможность ввести свою статистику, и все цифры должны попадать в одном место.
2. Программа должна иметь удалённый доступ.
Руководитель может просмотреть все статистики в любом месте, где бы он ни находился: в своём офисе, дома, в отеле на отдыхе, в самолёте и т.п.
3. Нужно свести «человеческий фактор» к минимуму.
Программа сама должна выбирать масштаб, сама — строить графики.
4. Программа должна быть простой.
Эта программа должна содержать только самые необходимые функции, она должна быть интуитивно понятной настолько, чтобы её можно было освоить самостоятельно, без привлечения консультанта. При этом программа должна выполняла все вышеперечисленные задачи, не занимая много компьютерных ресурсов.
5. Она должна побуждать руководителей самостоятельно проводить анализ статистик.
Судя по нашим наблюдениям, руководители, в попытке облегчить себе работу, прибегают к различным автоматизированным методикам анализа статистик, таким как автоматическое определение трендов, автоматическое назначение состояний, построение различных «пирогов» и т.д. К сожалению, такие методы идут враз с технологией анализа статистик и практически в каждом случае приводят к неправильным выводам и толкают руководителей на роковые ошибки в управлении. Поэтому мы намеренно отказались от всех подобных функций в нашей программе, дабы руководители были вынуждены самостоятельно анализировать графики, назначать состояния, замечать тенденции и искать их причины. Ведь только смекалка руководителя и его понимание сути технологии управления статистиками способно привести к позитивным результатам. В чём мы убеждались раз за разом.
Все эти задачи были с успехом реализованы в программном комплексе StatsSoft.
Вот что позволяет делать StatsSoft:
Внимание! Выпущена новая версия StatsSoft:
дифференцированные права доступа | интеграция с FPSoft
Управление доступом к статистикам
В прежней версии каждый, кто имел доступ в StatsSoft, мог посматривать и изменять все статистики.
Теперь мы наладили управление доступом.
Вы можете раздавать права на просмотр и редактирование конкретных статистик. Если вы не хотите, чтобы ваш уборщик видел общие статистики по доходу и продажам, вы даёте ему доступ на внесение данных по его личной статистике и, например, просмотр общей статистики его отдела уборщиков, чтобы он видел, какой вклад вносит в общую статистику своего отдела.
Теперь у каждого сотрудника есть настраиваемый доступ.
Автоматическое ведение графика дохода
Если у вас установлена программа по финансовому планированию FPSoft, где вы делаете еженедельный финн.план, StatSoft сама получает цифры еженедельного дохода и строит для вас график дохода.
Подстатистики дохода
Более того, если вы ведёте учёт источников дохода в FPsoft, то StatsSoft автоматически формирует еженедельные графики по всем вашим источникам дохода.
Объединённый с фин.планом список пользователей
Но даже больше! Теперь, если у вас установлена FPSoft, где у вас заведены все пользователи с их логинами и паролями, этот список пользователей автоматически переносится в StatsSoft, так что вам не нужно заново заводить всех своих 200 пользователей и раздавать им логины и пароли.
Двойные графики
Некоторые статистики требуют ведения двух графиков на одном листе. Теперь StatsSoft позволяет накладывать один график на другой с соблюдением масштаба графиков.
Перевернутые графики
В некоторые статистики считаются нежелательные показатели, например долги, чем меньше которых — тем лучше. Для этого мы ввели перевернутые графики, которые теперь правильно отражают улучшения и ухудшения: график идёт вверх — негативные показатели уменьшаются, вниз — увеличиваются.
Объясняем p-значения для начинающих Data Scientist’ов
Я помню, когда я проходил свою первую зарубежную стажировку в CERN в качестве практиканта, большинство людей все еще говорили об открытии бозона Хиггса после подтверждения того, что он соответствует порогу «пять сигм» (что означает наличие p-значения 0,0000003).

Тогда я ничего не знал о p-значении, проверке гипотез или даже статистической значимости.
Я решил загуглить слово — «p-значение», и то, что я нашел в Википедии, заставило меня еще больше запутаться…
При проверке статистических гипотез p-значение или значение вероятности для данной статистической модели — это вероятность того, что при истинности нулевой гипотезы статистическая сводка (например, абсолютное значение выборочной средней разницы между двумя сравниваемыми группами) будет больше или равна фактическим наблюдаемым результатам.
— Wikipedia
Хорошая работа, Википедия.
Ладно. Я не понял, что на самом деле означает р-значение.
Углубившись в область науки о данных, я наконец начал понимать смысл p-значения и то, где его можно использовать как часть инструментов принятия решений в определенных экспериментах.
Поэтому я решил объяснить р-значение в этой статье, а также то, как его можно использовать при проверке гипотез, чтобы дать вам лучшее и интуитивное понимание р-значений.
Также мы не можем пропустить фундаментальное понимание других концепций и определение p-значения, я обещаю, что сделаю это объяснение интуитивно понятным, не подвергая вас всеми техническими терминами, с которыми я столкнулся.
Всего в этой статье четыре раздела, чтобы дать вам полную картину от построения проверки гипотезы до понимания р-значения и использования его в процессе принятия решений. Я настоятельно рекомендую вам пройтись по всем из них, чтобы получить подробное понимание р-значений:
1. Проверка гипотез

Прежде чем мы поговорим о том, что означает р-значение, давайте начнем с разбора проверки гипотез, где р-значение используется для определения статистической значимости наших результатов.
Наша конечная цель — определить статистическую значимость наших результатов.
И статистическая значимость построена на этих 3 простых идеях:
Другими словами, мы создадим утверждение (нулевая гипотеза) и используем пример данных, чтобы проверить, является ли утверждение действительным. Если утверждение не соответствует действительности, мы выберем альтернативную гипотезу. Все очень просто.
Чтобы узнать, является ли утверждение обоснованным или нет, мы будем использовать p-значение для взвешивания силы доказательств, чтобы увидеть, является ли оно статистически значимым. Если доказательства подтверждают альтернативную гипотезу, то мы отвергнем нулевую гипотезу и примем альтернативную гипотезу. Это будет объяснено в следующем разделе.
Давайте воспользуемся примером, чтобы сделать эту концепцию более ясной, и этот пример будет использоваться на протяжении всей этой статьи для других концепций.
Пример. Предположим, что в пиццерии заявлено, что время их доставки составляет в среднем 30 минут или меньше, но вы думаете, что оно больше чем заявленное. Таким образом, вы проводите проверку гипотезы и случайным образом выбираете время доставки для проверки утверждения:
Одним из распространенных способов проверки гипотез является использование Z-критерия. Здесь мы не будем вдаваться в подробности, так как хотим лучше понять, что происходит на поверхности, прежде чем погрузиться глубже.
2. Нормальное распределение
Нормальное распределение — это функция плотности вероятности, используемая для просмотра распределения данных.
Нормальное распределение имеет два параметра — среднее (μ) и стандартное отклонение, также называемое сигма (σ).
Среднее — это центральная тенденция распределения. Оно определяет местоположение пика для нормальных распределений. Стандартное отклонение — это мера изменчивости. Оно определяет, насколько далеко от среднего значения склонны падать значения.
Нормальное распределение обычно связано с правилом 68-95-99.7 (изображение выше).
Классно. Теперь вы можете задаться вопросом: «Как нормальное распределение относится к нашей предыдущей проверке гипотез?»
Поскольку мы использовали Z-тест для проверки нашей гипотезы, нам нужно вычислить Z-баллы (которые будут использоваться в нашей тестовой статистике), которые представляют собой число стандартных отклонений от среднего значения точки данных. В нашем случае каждая точка данных — это время доставки пиццы, которое мы получили.
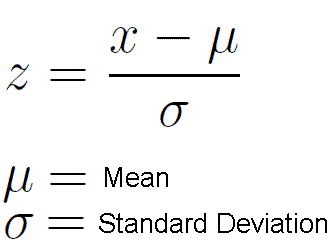
Обратите внимание, что когда мы рассчитали все Z-баллы для каждого времени доставки пиццы и построили стандартную кривую нормального распределения, как показано ниже, единица измерения на оси X изменится с минут на единицу стандартного отклонения, так как мы стандартизировали переменную, вычитая среднее и деля его на стандартное отклонение (см. формулу выше).
Изучение стандартной кривой нормального распределения полезно, потому что мы можем сравнить результаты теста с ”нормальной» популяцией со стандартизированной единицей в стандартном отклонении, особенно когда у нас есть переменная, которая поставляется с различными единицами.
Z-оценка может сказать нам, где лежат общие данные по сравнению со средней популяцией.
Мне нравится, как Уилл Кёрсен выразился: чем выше или ниже Z-показатель, тем менее вероятным будет случайный результат и тем более вероятным будет значимый результат.
Но насколько высокий (или низкий) показатель считается достаточно убедительным, чтобы количественно оценить, насколько значимы наши результаты?
Кульминация
Здесь нам нужен последний элемент для решения головоломки — p-значение, и проверить, являются ли наши результаты статистически значимыми на основе уровня значимости (также известного как альфа), который мы установили перед началом нашего эксперимента.
3. Что такое P-значение?
Наконец… Здесь мы говорим о р-значении!
Все предыдущие объяснения предназначены для того, чтобы подготовить почву и привести нас к этому P-значению. Нам нужен предыдущий контекст и шаги, чтобы понять это таинственное (на самом деле не столь таинственное) р-значение и то, как оно может привести к нашим решениям для проверки гипотезы.
Если вы зашли так далеко, продолжайте читать. Потому что этот раздел — самая захватывающая часть из всех!
Вместо того чтобы объяснять p-значения, используя определение, данное Википедией (извини Википедия), давайте объясним это в нашем контексте — время доставки пиццы!
Напомним, что мы произвольно отобрали некоторые сроки доставки пиццы, и цель состоит в том, чтобы проверить, превышает ли время доставки 30 минут. Если окончательные доказательства подтверждают утверждение пиццерии (среднее время доставки составляет 30 минут или меньше), то мы не будем отвергать нулевую гипотезу. В противном случае мы опровергаем нулевую гипотезу.
Поэтому задача p-значения — ответить на этот вопрос:
Если я живу в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), насколько неожиданными являются мои доказательства в реальной жизни?
Р-значение отвечает на этот вопрос числом — вероятностью.
Чем ниже значение p, тем более неожиданными являются доказательства, тем более нелепой выглядит наша нулевая гипотеза.
И что мы делаем, когда чувствуем себя нелепо с нашей нулевой гипотезой? Мы отвергаем ее и выбираем нашу альтернативную гипотезу.
Если р-значение ниже заданного уровня значимости (люди называют его альфа, я называю это порогом нелепости — не спрашивайте, почему, мне просто легче понять), тогда мы отвергаем нулевую гипотезу.
Теперь мы понимаем, что означает p-значение. Давайте применим это в нашем случае.
P-значение в расчете времени доставки пиццы
Теперь, когда мы собрали несколько выборочных данных о времени доставки, мы выполнили расчет и обнаружили, что среднее время доставки больше на 10 минут с p-значением 0,03.
Это означает, что в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), есть 3% шанс, что мы увидим, что среднее время доставки, по крайней мере, на 10 минут больше, из-за случайного шума.
Чем меньше p-значение, тем более значимым будет результат, потому что он с меньшей вероятностью будет вызван шумом.
В нашем случае большинство людей неправильно понимают р-значение:
Р-значение 0,03 означает, что есть 3% (вероятность в процентах), что результат обусловлен случайностью — что не соответствует действительности.
Р-значение ничего не *доказывает*. Это просто способ использовать неожиданность в качестве основы для принятия разумного решения.
— Кэсси Козырков
Вот как мы можем использовать p-значение 0,03, чтобы помочь нам принять разумное решение (ВАЖНО):
По моему мнению, p-значения используются в качестве инструмента для оспаривания нашего первоначального убеждения (нулевая гипотеза), когда результат является статистически значимым. В тот момент, когда мы чувствуем себя нелепо с нашим собственным убеждением (при условии, что р-значение показывает, что результат статистически значим), мы отбрасываем наше первоначальное убеждение (отвергаем нулевую гипотезу) и принимаем разумное решение.
4. Статистическая значимость
Наконец, это последний этап, когда мы собираем все вместе и проверяем, является ли результат статистически значимым.
Недостаточно иметь только р-значение, нам нужно установить порог (уровень значимости — альфа). Альфа всегда должна быть установлена перед экспериментом, чтобы избежать смещения. Если наблюдаемое р-значение ниже, чем альфа, то мы заключаем, что результат является статистически значимым.
Основное правило — установить альфа равным 0,05 или 0,01 (опять же, значение зависит от вашей задачи).
Как упоминалось ранее, предположим, что мы установили альфа равным 0,05, прежде чем мы начали эксперимент, полученный результат является статистически значимым, поскольку р-значение 0,03 ниже, чем альфа.
Для справки ниже приведены основные этапы всего эксперимента:
Если вы хотите узнать больше о статистической значимости, не стесняйтесь посмотреть эту статью — Объяснение статистической значимости, написанная Уиллом Керсеном.
Последующие размышления
Здесь много чего нужно переваривать, не так ли?
Я не могу отрицать, что p-значения по своей сути сбивают с толку многих людей, и мне потребовалось довольно много времени, чтобы по-настоящему понять и оценить значение p-значений и то, как они могут быть применены в рамках нашего процесса принятия решений в качестве специалистов по данным.
Но не слишком полагайтесь на p-значения, поскольку они помогают только в небольшой части всего процесса принятия решений.
Я надеюсь, что мое объяснение p-значений стало интуитивно понятным и полезным в вашем понимании того, что в действительности означают p-значения и как их можно использовать при проверке ваших гипотез.
Сам по себе расчет р-значений прост. Трудная часть возникает, когда мы хотим интерпретировать p-значения в проверке гипотез. Надеюсь, что теперь трудная часть станет для вас немного легче.
Если вы хотите узнать больше о статистике, я настоятельно рекомендую вам прочитать эту книгу (которую я сейчас читаю!) — Практическая статистика для специалистов по данным, специально написанная для data scientists, чтобы разобраться с фундаментальными концепциями статистики.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:



