Краеугольный камень псевдослучайности: с чего начинается поиск чисел

(с)
Случайные числа постоянно генерируются каждой машиной, которая может обмениваться данными. И даже если она не обменивается данными, каждый компьютер нуждается в случайности для распределения программ в памяти. При этом, конечно, компьютер, как детерминированная система, не может создавать истинные случайные числа.
Когда речь заходит о генераторах случайных (или псевдослучайных) чисел, рассказ всегда строится вокруг поиска истинной случайности. Пока серьезные математики десятилетиями ведут дискуссии о том, что считать случайностью, в практическом отношении мы давно научились использовать «правильную» энтропию. Впрочем, «шум» — это лишь вершина айсберга.
С чего начать, если мы хотим распутать клубок самых сильных алгоритмов PRNG и TRNG? На самом деле, с какими бы алгоритмами вы не имели дело, все сводится к трем китам: seed, таблица предопределенных констант и математические формулы.
Каким бы ни был seed, еще есть алгоритмы, участвующие в генераторах истинных случайных чисел, и такие алгоритмы никогда не бывают случайными.
Что такое случайность
Первое подходящее определение случайной последовательности дал в 1966 году шведский статистик Пер Мартин-Лёф, ученик одного из крупнейших математиков XX века Андрея Колмогорова. Ранее исследователи пытались определить случайную последовательность как последовательность, которая проходила все тесты на случайность.
Основная идея Мартина-Лёфа заключалась в том, чтобы использовать теорию вычислимости для формального определения понятия теста случайности. Это контрастирует с идеей случайности в вероятности; в этой теории ни один конкретный элемент пространства выборки не может быть назван случайным.
«Случайная последовательность» в представлениях Мартина-Лёфа должна быть типичной, т.е. не должна обладать индивидуальными отличительными особенностями.
Было показано, что случайность Мартина-Лёфа допускает много эквивалентных характеристик, каждая из которых удовлетворяет нашему интуитивному представлению о свойствах, которые должны иметь случайные последовательности:
Существование множественных определений рандомизации Мартина-Лёфа и устойчивость этих определений при разных моделях вычислений свидетельствуют о том, что случайность Мартина-Лёфа является фундаментальным свойством математики.
Seed: основа псевдослучайных алгоритмов
Первые алгоритмы формирования случайных чисел выполняли ряд основных арифметических действий: умножить, разделить, добавить, вычесть, взять средние числа и т.д. Сегодня такие мощные алгоритмы, как Fortuna и Yarrow (используется в FreeBSD, AIX, Mac OS X, NetBSD) выглядят как генераторы случайных чисел для параноиков. Fortuna, например, это криптографический генератор, в котором для защиты от дискредитации после выполнения каждого запроса на случайные данные в размере 220 байт генерируются еще 256 бит псевдослучайных данных и используются в качестве нового ключа шифрования — старый ключ при этом каждый раз уничтожается.
Прошли годы, прежде чем простейшие алгоритмы эволюционировали до криптографически стойких генераторов псевдослучайных чисел. Частично этот процесс можно проследить на примере работы одной математической функции в языке С.
Функция rand () является простейшей из функций генерации случайных чисел в C.
В этом примере рандома используется вложенный цикл для отображения 100 случайных значений. Функция rand () хороша при создании множества случайных значений, но они являются предсказуемыми. Чтобы сделать вывод менее предсказуемым, вам нужно добавить seed в генератор случайных чисел — это делается с помощью функции srand ().
Seed — это стартовое число, точка, с которой начинается последовательность псевдослучайных чисел. Генератор псевдослучайных чисел использует единственное начальное значение, откуда и следует его псевдослучайность. Генератор истинных случайных чисел всегда имеет в начале высококачественную случайную величину, предоставленную различными источниками энтропии.
srand() принимает число и ставит его в качестве отправной точки. Если seed не выставить, то при каждом запуске программы мы будем получать одинаковые случайные числа.
Вот пример простой формулы случайного числа из «классики» — книги «Язык программирования C» Кернигана и Ричи, первое издание которой вышло аж в 1978 году:
Эта формула предполагает существование переменной, называемой random_seed, изначально заданной некоторым числом. Переменная random_seed умножается на 1 103 535 245, а затем 12 345 добавляется к результату; random_seed затем заменяется этим новым значением. Это на самом деле довольно хороший генератор псевдослучайных чисел. Если вы используете его для создания случайных чисел от 0 до 9, то первые 20 значений, которые он вернет при seed = 10, будут такими:
Если у вас есть 10 000 значений от 0 до 9, то распределение будет следующим:
0 — 10151 — 10242 — 10483 — 9964 — 9885 — 10016 — 9967 — 10068 — 9659 — 961
Любая формула псевдослучайных чисел зависит от начального значения. Если вы предоставите функции rand() seed 10 на одном компьютере, и посмотрите на поток чисел, которые она производит, то результат будет идентичен «случайной последовательности», созданной на любом другом компьютере с seed 10.
К сожалению, у генератора случайных чисел есть и другая слабость: вы всегда можете предсказать, что будет дальше, основываясь на том, что было раньше. Чтобы получить следующее число в последовательности, мы должны всегда помнить последнее внутреннее состояние генератора — так называемый state. Без state мы будем снова делать одну и ту же математическую операцию с одинаковыми числами, чтобы получить тот же ответ.
Как сделать seed уникальным для каждого случая? Самое очевидное решение — добавить в вычисления текущее системное время. Сделать это можно с помощью функции time().
Функция time() возвращает информацию о текущем времени суток, значение, которое постоянно изменяется. При этом метод typecasting гарантирует, что значение, возвращаемое функцией time(), является целым числом.
Итак, в результате добавления «случайного» системного времени функция rand() генерирует значения, которые являются более случайными, чем мы получили в первом примере.
Однако в этом случае seed можно угадать, зная системное время или время запуска приложения. Как правило, для приложений, где случайные числа являются абсолютно критичными, лучше всего найти альтернативное решение.
Но опять же, все эти числа не случайны.
Лучшее, что вы можете сделать с детерминированными генераторами псевдослучайных чисел — добавить энтропию физических явлений.
Период (цикл) генератора
Одними из наиболее часто используемых методов генерации псевдослучайных чисел являются различные модификации линейного конгруэнтного метода, схема которого была предложена Дерриком Лемером еще в 1949 году:
Рассмотрим случай, когда seed равен 1, а период — 100 (на языке Haskell):
В результате мы получим следующий ответ:
Это лишь пример и подобную структуру в реальной жизни не используют. В Haskell, если вы хотите построить случайную последовательность, можно воспользоваться следующим кодом:
Выбор случайного Int дает вам обратно Int и новый StdGen, который вы можете использовать для получения более псевдослучайных чисел. Многие языки программирования, включая Haskell, имеют генераторы случайных чисел, которые автоматически запоминают свое состояние (в Haskell это randomIO).
Чем больше величина периода, тем выше надежность создания хороших случайных значений, однако даже с миллиардами циклов крайне важно использовать надежный seed. Реальные генераторы случайных чисел обычно используют атмосферный шум (поставьте сюда любое физическое явление — от движения мыши пользователя до радиоактивного распада), но мы можем и схитрить программным методом, добавив в seed асинхронные потоки различного мусора, будь то длины интервалов между последними heartbeat потоками или временем ожидания mutual exclusion (а лучше добавить все вместе).
Истинная случайность бит
Итак, получив seed с примесью данных от реальных физических явлений (либо максимально усложнив жизнь будущему взломщику самым большим набором потоков программного мусора, который только сможем придумать), установив state для защиты от ошибки повтора значений и добавив криптографических алгоритмов (или сложных математических задач), мы получим некоторый набор данных, который будем считать случайной последовательностью. Что дальше?
Дальше мы возвращаемся к самому началу, к одному из фундаментальных требований — тестам.
Национальный институт стандартов и технологий США вложил в «Пакет статистических тестов для случайных и псевдослучайных генераторов чисел для криптографических приложений» 15 базовых проверок. Ими можно и ограничиться, но этот пакет вовсе не является «вершиной» проверки случайности.
Одни из самых строгих статистических тестов предложил профессор Джордж Марсалья из Университета штата Флорида. «Тесты diehard» включают 17 различных проверок, некоторые из них требуют очень длинных последовательностей: минимум 268 мегабайт.
Случайность можно проверить с помощью библиотеки TestU01, представленной Пьером Л’Экуйе и Ричардом Симардом из Монреальского университета, включающей классические тесты и некоторые оригинальные, а также посредством общедоступной библиотеки SPRNG.
Еще один полезный сервис для количественного измерения случайности.
Краткая история случайных чисел
«Когда я задался целью получить действительно случайное число, то не нашел для этого ничего лучшего, чем обычная игральная кость» — писал в 1890 году Фрэнсис Гальтон в журнале Nature. «После того, как кости встряхивают и бросают в корзинку, они ударяются друг о друга и о стенки корзинки столь непредсказуемым образом, что даже после легкого броска становится совершенно невозможным предопределить его результат».

(Игральные кости времён Римской Империи)
Как мы можем сгенерировать равномерную последовательность случайных чисел? Случайность, столь прекрасная в своём многообразии, часто встречается в живой природе, но её не всегда легко было извлечь искусственным путём. Самые древние из игральных костей были найдены на Среднем Востоке, и они датируются примерно 24 столетием до нашей эры. Другим примером может быть Китай, где ещё в 11 столетии до нашей эры применялось разбивание ударом черепашьего панциря, с дальнейшей интерпретацией размера полученных случайных частей. Столетиями позже люди разрубали несколько раз стебли растений и сравнивали размеры полученных частей.
Но к середине 40-ых годов ХХ столетия человечеству понадобилось значительно больше случайных чисел, чем можно было получить от бросков костей или разрезания стеблей. Американский аналитический центр RAND создал машину, которая была способна генерировать случайные числа с помощью использования случайного генератора импульсов (что-то вроде электронной рулетки). Они запустили её и через какое-то время получили достаточное количество случайных чисел, которые опубликовали в виде книги «Один миллион случайных чисел и сто тысяч нормальных отклонений».
 Книгу можно почитать онлайн или купить бумажное переиздание 2001 года на Amazon. То, что сегодня может показаться абсурдным арт-проектом, в то время было серьёзным прорывом. Впервые учёным стала доступна действительно большая последовательность действительно случайных чисел.
Книгу можно почитать онлайн или купить бумажное переиздание 2001 года на Amazon. То, что сегодня может показаться абсурдным арт-проектом, в то время было серьёзным прорывом. Впервые учёным стала доступна действительно большая последовательность действительно случайных чисел.
Другая похожая машина, ERNIE, построенная в знаменитом сегодня Блетчли-парке в 40-ых годах ХХ века, использовалась для генерации случайных чисел в британской лотерее Premium Bond. Для того, чтобы развеять страхи по поводу случайности и честности результатов, была даже снята документальная лента «The Importance of Being E.R.N.I.E.». Сегодня её можно посмотреть на Youtube:
В 1951 году случайность наконец была формализована и воплощена в реальном компьютере Ferranti Mark 1, который поставлялся со встроенным генератором случайных данных на основе дробовых шумов и инструкцией, позволяющей получить 20 случайных бит. Этот функционал был разработан Аланом Тьюрингом. Его коллега Кристофер Стрэчи применил его для создания «генератора любовных писем». Вот пример текста, который был сгенерирован данной программой:
Но генератор случайных чисел Тьюринга не делал программистов тех лет счастливыми, поскольку привносил в и так новые и нестабильные компьютерные системы фактор ещё большей нестабильности. Желая добиться стабильной работы некоторой программы — без отладчиков и со случайными данными — никогда нельзя было достичь повторяемости результатов. Тогда возникла следующая мысль: «А что, если генератор случайных чисел может быть представлен в виде некоторой детерминированной функции?» Тогда получилось бы, что, с одной стороны, генерируемые числа имели бы признаки случайных, но с другой стороны, при одинаковой инициализации генератора данные последовательности были бы каждый раз одни и те же. Так появились генераторы псевдослучайных чисел (ГПСЧ).
Джон фон Нейман разработал ГПСЧ в 1946 году. Его идеей было начать с некоторого числа, взять его квадрат, отбросить цифры из середины результата, снова взять квадрат и отбросить середину, и т.д. Полученная последовательность, по его мнению, обладала теми же свойствами, что и случайные числа. Теория фон Неймана не выдержала испытания временем, поскольку какое бы начальное число вы не выбрали, сгенерированная таким образом последовательность вырождалась в короткий цикл повторяющихся значений, вроде 8100, 6100, 4100, 8100, 6100, 4100,…
Полностью избежать циклов невозможно, когда мы работаем с детерминированной функцией, чьи последующие значения основаны на предыдущих. Но что, если период цикла будет столь большим, что на практике это уже не будет иметь значения?
Математик Деррик Генри Лемер развил эту идею в 1949 году с изобретением линейного конгруэнтного метода. Вот генератор псевдослучайных чисел, основанный на подходе Лемера и написанный на Javascript:
Вы можете заметить в коде ряд «магических констант». Эти числа (как правило, простые) выбирались таким образом, чтобы максимизировать период цикла до повторения последовательности результатов. Данный генератор использует в качестве начального значения текущее время и имеет период около 2^31. Он стал популярным с выходом JavaScript 1.0, поскольку он тогда ещё не имел встроенной функции Math.random(), а все ведь хотели, чтобы их рекламные баннеры сменялись случайным образом. «Я не использовал бы этот алгоритм для чего-то связанного с безопасностью, но для многих применений его достаточно», — писал автор вышеуказанного кода Paul Houle.
Но Интернет как раз требовал чего-то, связанного с безопасностью. SSL появился в 1995 году и его реализация требовала высококачественного генератора псевдослучайных чисел. Это привело к серии достаточно диких экспериментов в данной области. Если вы посмотрите на патенты, связанные с генерацией случайных чисел, выданные в те времена, то получите ощущение, будто смотрите на осовремененные попытки построения первого самолёта.
Большинство популярных процессоров в 90-ых годах не имели специальной инструкции для генерации случайных чисел, так что выбор хорошего начального значения для генератора псевдослучайных чисел имел очень важное значение. Это вылилось в проблемы с безопасностью, когда Phillip Hallam-Baker обнаружил, что в браузере Netscape (доминирующем в то время) реализация SSL использовала для инициализации ГПСЧ комбинацию текущего времени и ID своего процесса. Он показал, как хакер может легко подобрать это значение и расшифровать SSL-трафик. Угадывание начального значения алгоритма генерации псевдослучайных чисел — до сих пор популярная атака, хотя с годами она стала слегка сложнее. Вот пример удачной атаки, опубликованный на Hacker News в 2009 году.
В 1997 году программисты были ограничены в способах получения по-настоящему случайных чисел, так что команда SGI создала LavaRand, который состоял из вебкамеры, направленной на пару лава-ламп, стоявших рядом на столе. Картинка с этой камеры была отличным источником энтропии — Настоящим Генератором Случайных Чисел, таким же, как у Тьюринга. Но в этот раз получалось генерировать 165 Кб случайных чисел в секунду. Изобретение было тут же запатентовано.
Большинство экспериментов в этой области не выдержали испытания временем, но один ГПСЧ, названный Вихрем Мерсенна и разработанный в 1997 году Макото Мацумото и Такудзи Нисимура, смог удержать пальму первенства. В нём сочетались производительность и качество результатов, что позволило ему быстро распространиться на многие языки и фреймворки. Вихрь Мерсенна является витковым регистром сдвига с обобщённой отдачей и генерирует детерминированную последовательность с огромным периодом цикла. В текущей реализации период равен 2¹⁹⁹³⁷− 1 и именно эта реализация входит сегодня в большинство языков программирования.
В 1999 году Intel добавил аппаратный генератор случайных чисел в чипсет i810. Это было хорошо, поскольку данная реализация давала по-настоящему случайные числа (на основе температурных шумов), но работало не настолько же быстро, как программные ГПСЧ, так что большинство криптоприложений всё ещё используют ГПСЧ, которые теперь, по крайней мере, можно инициализировать начальным значением от аппаратного генератора случайных чисел.
Это приводит нас к понятию криптографически-безопасного генератора псевдослучайных чисел (КБГПСЧ). (Ох уж эти аббревиатуры! Не удивительно, что компьютерные науки кажутся некоторым людям скучными.) КБГПСЧ стали очень популярными в эпоху SSL. Каким требованиям должен удовлетворять КБГПСЧ? Ну вот вам 131-страничный документ с этими требованиями, развлекайтесь. Как вы уже понимаете, требований не мало. Например, тот же Вихрь Мерсенна им не удовлетворяет, поскольку, имея достаточно большую последовательность сгенерированных им чисел, можно угадать следующее число.
В 2012 году INTEL добавил в свои чипы инструкции RDRAND и RDSEED, позволяющие получить настоящие случайные числа на основе тех же колебаний температуры, но теперь уже на скорости до 500 Мб/с, что должно бы сделать применение программных ГПСЧ ненужным. Но в обществе бродят слухи и сомнения в честности этих инструкций. Нет ли в них специально сделанной закладки для NSA? Никто не может сказать этого точно. Вернее, кто-то, наверное, может, но он точно не напишет об этом в Твиттере.

(Случайные данные полученные от аппаратного генератора случайных чисел Redoubler)
В последние годы начали появляться также аппаратные генераторы случайных чисел от сторонних производителей и даже полностью открытые (как в плане софта, так и аппаратной части). Сила этих продуктов именно в открытости: можно изучить их самостоятельно и даже построить дома самому из общедоступных компонентов. Примерами могут быть REDOUBLER и Infinite Noise TRNG.
Сегодня люди всё ещё ведут дискуссии о том, какой именно генератор случайных чисел стоит использовать в той или иной системе, ядре ОС, языке программирования, криптографической библиотеке и т.д. Есть много вариантов алгоритмов, заточенных на скорость, экономию памяти, безопасность. И каждый из них постоянно подвергается атакам хакеров и специалистов по безопасности. Но для ежедневных задач, не связанных с безопасностью, вы вполне можете положиться на данные из /dev/random или функции rand(), доступных на большинстве платформ. Это даст вам достаточно большую и случайную последовательность данных, которая бы сделала в своё время счастливым Алана Тьюринга.
Как компьютер генерирует случайные числа
Что такое случайность в компьютере? Как происходит генерация случайных чисел? В этой статье мы постарались дать простые ответы на эти вопросы.
В программном обеспечении, да и в технике в целом существует необходимость в воспроизводимой случайности: числа и картинки, которые кажутся случайными, на самом деле сгенерированы определённым алгоритмом. Это называется псевдослучайностью, и мы рассмотрим простые способы создания псевдослучайных чисел. В конце статьи мы сформулируем простую теорему для создания этих, казалось бы, случайных чисел.
Определение того, что именно является случайностью, может быть довольно сложной задачей. Существуют тесты (например, колмогоровская сложность), которые могут дать вам точное значение того, насколько случайна та или иная последовательность. Но мы не будем заморачиваться, а просто попробуем создать последовательность чисел, которые будут казаться несвязанными между собой.
Часто требуется не просто одно число, а несколько случайных чисел, генерируюемых непрерывно. Следовательно, учитывая начальное значение, нам нужно создать другие случайные числа. Это начальное значение называется семенем, и позже мы увидим, как его получить. А пока давайте сконцентрируемся на создании других случайных значений.
Создание случайных чисел из семени
Один из подходов может заключаться в том, чтобы применить какую-то безумную математическую формулу к семени, а затем исказить её настолько, что число на выходе будет казаться непредсказуемым, а после взять его как семя для следующей итерации. Вопрос только в том, как должна выглядеть эта функция искажения.
Давайте поэкспериментируем с этой идеей и посмотрим, куда она нас приведёт.
Функция искажения будет принимать одно значение, а возвращать другое. Назовём её R.
Числовой круг
Посмотрим на циферблат часов: наш ряд начинается с 1 и идёт по кругу до 12. Но поскольку мы работаем с компьютером, пусть вместо 12 будет 0.
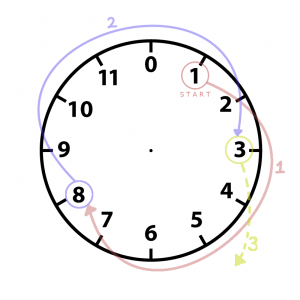
Теперь начиная с 1 снова будем прибавлять 7. Прогресс! Мы видим, что после 12 наш ряд начинает повторяться, независимо от того, с какого числа начать.
Здесь мы получаем очень важно свойство: если наш цикл состоит из n элементов, то максимальное число элементов, которые мы можем получить перед тем, как они начнут повторяться это n.
Теперь давайте переделаем функцию R так, чтобы она соответствовала нашей логике. Ограничить длину цикла можно с помощью оператора модуля или оператора остатка от деления.
Если вы попробуете несколько разных значений, то сможете увидеть одно свойство: m и с должны быть взаимно простыми.
До сих пор мы делали «прыжки» за счёт добавления, но что если использовать умножение? Умножим х на константу a.
Свойства, которым должно подчиняться а, чтобы образовался полный цикл, немного более специфичны. Чтобы создать верный цикл:
Эти свойства вместе с правилом, что m и с должны быть взаимно простыми составляют теорему Халла-Добелла. Мы не будем рассматривать её доказательство, но если бы вы взяли кучу разных значений для разных констант, то могли бы прийти к тому же выводу.
Выбор семени
Настало время поговорить о самом интересном: выборе первоначального семени. Мы могли бы сделать его константой. Это может пригодиться в тех случаях, когда вам нужны случайные числа, но при этом нужно, чтобы при каждом запуске программы они были одинаковые. Например, создание одинаковой карты для каждой игры.
Конечный результат
Когда мы применяем функцию к её результату несколько раз, мы получаем рекуррентное соотношение. Давайте запишем нашу формулу с использованием рекурсии:
То, что мы сделали, называется линейным конгруэнтным методом. Он очень часто используется, потому что он прост в реализации и вычисления выполняются быстро.
В разных языках программирования реализация линейного конгруэнтного метода отличается, то есть меняются значения констант. Например, функция случайных чисел в libc (стандартная библиотека С для Linux) использует m = 2 ^ 32, a = 1664525 и c = 1013904223. Такие компиляторы, как gcc, обычно используют эти значения.
Заключительные замечания
Существуют и другие алгоритмы генерации случайных чисел, но линейный конгруэнтный метод считается классическим и лёгким для понимания. Если вы хотите глубже изучить данную тему, то обратите внимание на книгу Random Numbers Generators, в которой приведены элегантные доказательства линейного конгруэнтного метода.
Генерация случайных чисел имеет множество приложений в области информатики и особенно важна для криптографии.
9.5 – Генерирование случайных чисел
Возможность генерировать случайные числа может быть полезна в определенных видах программ, особенно в играх, программах статистического моделирования и научных симуляторах, которые должны моделировать случайные события. Возьмем, к примеру, игры – без случайных событий монстры всегда будут атаковать вас одинаково, вы всегда найдете одно и то же сокровище, расположение подземелий никогда не изменится и т.д. И это не сделает игру очень хорошей.
Так как же нам генерировать случайные числа? В реальной жизни мы часто получаем случайные результаты, например, подбрасывая монету, бросая кости или тасуя колоду карт. Эти события включают в себя так много физических переменных (например, гравитацию, трение, сопротивление воздуха, импульс и т.д.), что их почти невозможно предсказать или контролировать, и они дают результаты, которые во всех смыслах случайны.
Однако компьютеры не предназначены для использования преимуществ физических переменных – ваш компьютер не может подбрасывать монету, бросать кости или тасовать реальные карты. Компьютеры живут в управляемом электрическом мире, где всё двоично (ложь или истина) и нет промежуточного состояния. По самой своей природе компьютеры предназначены для получения максимально предсказуемых результатов. Когда вы говорите компьютеру вычислить 2 + 2, вы всегда хотите, чтобы ответ был 4. А не 3 или 5 в отдельных случаях.
Следовательно, компьютеры обычно не способны генерировать случайные числа. Вместо этого они должны моделировать случайность, что чаще всего делается с помощью генераторов псевдослучайных чисел.
Генератор псевдослучайных чисел (ГПСЧ или PRNG, pseudo-random number generator) – это программа, которая принимает начальное число (англ. seed) и выполняет над ним математические операции, чтобы преобразовать его в какое-то другое число, которое, кажется, не связано с начальным числом. Затем он берет это сгенерированное число и выполняет с ним ту же математическую операцию, чтобы преобразовать его в новое число, не связанное с числом, из которого оно было сгенерировано. Постоянно применяя алгоритм к последнему сгенерированному числу, он может генерировать последовательность новых чисел, которые будут казаться случайными, если алгоритм достаточно сложен.
Лучшая практика
Предоставить начальное значение своему генератору случайных чисел вы должны только один раз. Если ввести его более одного раза, результаты будут менее случайными или совсем не случайными.
На самом деле написать ГПСЧ довольно просто. Вот короткая программа, которая генерирует 100 псевдослучайных чисел:
Результат этой программы:
Каждое число кажется довольно случайным по сравнению с предыдущим. Как оказалось, наш алгоритм на самом деле не очень хорош по причинам, которые мы обсудим позже. Но он эффективно иллюстрирует принцип генерации значений генератором псевдослучайных чисел.
Генерация случайных чисел в C++
C (и, как следствие, C++) поставляется со встроенным генератором псевдослучайных чисел. Он реализован как две отдельные функции, которые находятся в заголовке cstdlib :
Вот пример программы, использующей эти функции:
Вот результат этой программы:
Последовательности ГПСЧ и заполнение
Если вы запустите приведенный выше пример программы с std::rand() несколько раз, вы заметите, что она каждый раз выводит один и тот же результат! Это означает, что хотя каждое число в последовательности кажется случайным по сравнению с предыдущими, вся последовательность вовсе не случайна! А это означает, что наша программа оказывается полностью предсказуемой (одни и те же входные данные всегда приводят к одним и тем же выходным данным). Бывают случаи, когда это может быть полезно или даже желательно (например, вы хотите, чтобы научное моделирование повторялось, или вы пытаетесь выяснить, почему ваш генератор случайных подземелий дает сбой).
Но часто это не то, что нужно. Если вы пишете игру «hi-lo» (высоко-низко) (где у пользователя есть 10 попыток угадать число, а компьютер сообщает ему, является ли его предположение слишком высоким или слишком низким), вы не хотите, чтобы программа каждый раз выбирала одни и те же числа. Итак, давайте подробнее посмотрим, почему это происходит, и как мы можем это исправить.
Помните, что каждое число в последовательности ГПСЧ определенным образом генерируется из предыдущего числа. Таким образом, при любом одном и том же начальном числе ГПСЧ всегда будут генерировать одну и ту же последовательность чисел! Мы получаем ту же последовательность, потому что наше начальное число всегда 5323.
Чтобы сделать всю нашу последовательность случайной, нам нужен способ выбрать начальное число, которое не является фиксированным значением. Первый ответ, который, вероятно, приходит в голову, – нам нужно случайное число! Это хорошая мысль, но если нам нужно случайное число для генерации случайных чисел, тогда мы попадаем в уловку-22. Оказывается, нам на самом деле не нужно, чтобы наше начальное число было случайным – нам просто нужно выбирать что-то, что меняется при каждом запуске программы. Затем мы можем использовать наш ГПСЧ для генерации уникальной последовательности псевдослучайных чисел из этого начального числа.
Общепринятым методом для этого является использование системных часов. Каждый раз, когда пользователь запускает программу, время будет другим. Если мы используем это значение времени в качестве начального числа, тогда наша программа при каждом запуске будет генерировать другую последовательность чисел!
Вот та же программа, что и выше, но с вызовом time() в качестве начального числа:
Теперь наша программа будет каждый раз генерировать новую последовательность случайных чисел! Запустите ее пару раз и убедитесь сами.
Генерация случайных чисел между двумя произвольными значениями
Вот короткая функция, которая преобразует результат rand() в нужный диапазон:
Дополнительный материал: как работает предыдущая функция?
Функция getRandomNumber() может показаться немного сложной, но всё не так уж плохо.
Мы делаем это в пять этапов:
Дополнительный материал: почему в предыдущей функции мы не используем оператор остатка от деления ( % )?
Один из наиболее частых вопросов, которые задают читатели, – почему мы используем деление в приведенной выше функции вместо взятия остатка от деления ( % ). Короткий ответ заключается в том, что метод с остатком от деления имеет тенденцию смещаться в пользу малых чисел.
Давайте посмотрим, что бы произошло, если бы вместо этого приведенная выше функция выглядела так:
Теперь давайте посчитаем все возможные исходы:
Посмотрите на распределение результатов. Результаты с 0 по 2 появляются дважды, а с 3 по 6 – только один раз. Этот метод имеет явный уклон в сторону низких результатов. Экстраполируя это: большинство случаев, связанных с этим алгоритмом, будут вести себя аналогичным образом.
Расчет всех возможных исходов:
Здесь всё еще есть небольшое смещение в сторону меньших чисел (0, 2 и 4 появляются дважды, тогда как 1, 3, 5 и 6 появляются один раз), но результаты распределены гораздо более равномерно.
Несмотря на то, что getRandomNumber() немного сложнее для понимания, чем альтернатива с остатком от деления, мы выступаем за метод с делением, потому что он дает менее предсказуемый результат.
Что такое хороший генератор псевдослучайных чисел?
Как я уже упоминал выше, ГПСЧ, который мы написали, не очень хороший. В этом разделе мы обсудим причины, почему. Это дополнительный материал, потому что он не имеет прямого отношения к C или C++, но если вам нравится программировать, вам, вероятно, всё равно будет интересно.
Чтобы быть хорошим, ГПСЧ должен обладать рядом свойств:
Во-первых, ГПСЧ должен генерировать каждое число примерно с одинаковой вероятностью. Это называется равномерностью распределения. Если одни числа генерируются чаще других, результат программы, использующей ГПСЧ, будет искажен!
Например, предположим, вы пытаетесь написать генератор случайных предметов для игры. Вы выбираете случайное число от 1 до 10, и если результат равен 10, с монстра выпадет мощный предмет вместо обычного. Вы ожидаете, что это произойдет с вероятностью 1 из 10. Но если результаты простого ГПСЧ распределены неравномерно, и он генерирует намного больше десяток, чем должен, ваши игроки в конечном итоге получат больше редких предметов, чем вы предполагали, что, возможно, упростит вашу игру.
Создание ГПСЧ, дающих равномерно распределенные результаты, является сложной задачей, и это одна из основных причин, по которой ГПСЧ, который мы написали в начале этого урока, не очень хороший.
В-третьих, ГПСЧ должен иметь хорошее пространственное распределение чисел. Это означает, что он должен возвращать низкие, средние и высокие значения, казалось бы, случайным образом. ГПСЧ, который вернул все низкие значения, а затем все высокие значения, может быть равномерно распределенным и непредсказуемыми, но он всё равно приведет к смещенным результатам, особенно если количество случайных чисел, которые вы реально используете, невелико.
В-четвертых, все ГПСЧ являются периодическими, что означает, что в какой-то момент сгенерированная последовательность чисел начнет повторяться. Длина последовательности до того, как ГПСЧ начинает повторяться, называется периодом.
Например, вот первые 100 чисел, сгенерированных из ГПСЧ с плохой периодичностью:
Вы можете заметить, что он сгенерировал 9 как второе число и снова 9 как 16-е число. ГПСЧ застревает, постоянно генерируя последовательность между этими двумя девятками: 9-130-97-64-31-152-119-86-53-20-141-108-75-42- (повтор).
Это происходит потому, что ГПСЧ детерминированы – при некотором наборе входных значений они каждый раз будут выдавать одно и то же выходное значение. Это означает, что как только ГПСЧ встречает набор входных данных, которые он использовал ранее, он начинает производить ту же последовательность выходных данных, которую он создавал раньше, что приводит к циклу.
Хороший ГПСЧ должен иметь длительный период для всех начальных значений. Разработка алгоритма, отвечающего этому свойству, может быть чрезвычайно сложной задачей – большинство ГПСЧ будут иметь длительные периоды для одних начальных значений и короткие периоды для других. Если пользователь выберет начальное число с коротким периодом, тогда ГПСЧ не будет работать хорошо.
Несмотря на сложность разработки алгоритмов, отвечающих всем этим критериям, в этой области было проведено множество исследований из-за ее важности для научных вычислений.
std::rand() – посредственный ГПСЧ
Одним из основных недостатков rand() является то, что RAND_MAX обычно устанавливается равным 32767 (по сути, 15 бит). Это означает, что если вы хотите генерировать числа в большем диапазоне (например, 32-битные целые числа), rand() не подходит. Кроме того, rand() не подходит, если вы хотите генерировать случайные числа с плавающей запятой (например, от 0,0 до 1,0), что часто бывает полезно при статистическом моделировании. Наконец, rand() имеет относительно короткий период по сравнению с другими алгоритмами.
Тем не менее, rand() идеально подходит для обучения программированию и для программ, в которых высококачественный ГПСЧ не является необходимостью.
Для приложений, где полезен высококачественный ГПСЧ, я бы порекомендовал вихрь Мерсенна (Mersenne Twister) (или один из его вариантов), который дает отличные результаты и относительно прост в использовании. Вихрь Мерсенна был введен в C++11, и мы покажем, как его использовать позже в этом уроке.
Отладка программ, использующих случайные числа
Программы, использующие случайные числа, может быть трудно отлаживать, потому что программа при каждом запуске может вести себя по-разному. Иногда это может сработать, а иногда нет. При отладке полезно следить за тем, чтобы ваша программа каждый раз выполняла один и тот же (неправильный) путь. Таким образом, вы можете запускать программу столько раз, сколько необходимо, чтобы определить причину ошибки.
По этой причине при отладке полезно установить случайное начальное число (через std::srand ) на определенное значение (например, 0), которое вызывает ошибочное поведение. Это гарантирует, что ваша программа каждый раз будет генерировать одни и те же результаты, что упростит отладку. Как только вы обнаружите ошибку, вы можете снова использовать системные часы, чтобы снова начать генерировать рандомизированные результаты.
Получение лучших случайных чисел с помощью вихря Мерсенна
Вот небольшой пример, показывающий, как сгенерировать случайные числа в C++11 с помощью вихря Мерсенна:
Примечание автора
До C++17 вам нужно было после типа добавить пустые скобки для создания die
std::uniform_int_distribution<> die
Вы можете заметить, что вихрь Мерсенна генерирует случайные 32-битные целочисленные значения без знака (а не 15-битные целочисленные значения, как std::rand() ), что дает гораздо больший диапазон. Также существует версия ( std::mt19937_64 ) для генерации 64-битных целочисленных значений без знака.
Случайные числа в нескольких функциях
В приведенном выше примере генератор псевдослучайных чисел создается для использования в одной функции. Что произойдет, если мы захотим использовать генератор случайных чисел в нескольких функциях?
Хотя вы можете создать статическую локальную переменную std::mt19937 в каждой функции, которая в ней нуждается (статическая, чтобы она была инициализирована только один раз); но это немного излишне – чтобы каждая функция получала начальное значение для генератора случайных чисел и поддерживала свой собственный локальный генератор. В большинстве случаев лучшим вариантом является создание глобального генератора случайных чисел (внутри пространства имен!). Помните, как мы говорили вам избегать неконстантных глобальных переменных? Это исключение (также обратите внимание: std::rand() и std::srand() обращаются к глобальному объекту, поэтому для этого есть прецедент).
Использование библиотеки генерирования случайных чисел
Вот приведенная выше программа, модифицированная под использование библиотеки Effolkronium:
Помогите! Мой генератор случайных чисел генерирует одну и ту же последовательность случайных чисел!
Если ваш генератор случайных чисел при каждом запуске вашей программы генерирует одну и ту же последовательность случайных чисел, вы, вероятно, неправильно его инициализировали. Убедитесь, что вы инициализируете его значением, которое изменяется при каждом запуске программы (например, std::time(nullptr) ).
Помогите! Мой генератор случайных чисел всегда генерирует одно и то же первое число!
Реализация rand() в Visual Studio и некоторых других компиляторах имеет недостаток – первое сгенерированное случайное число не сильно меняется для похожих начальных значений. Это означает, что при использовании std::time(nullptr) для инициализации вашего генератора случайных чисел первый результат rand() не сильно изменится при последующих запусках. Однако на результаты последующих вызовов rand() это не повлияет, и они будут достаточно рандомизированы.
Решение здесь, и хорошее практическое правило в целом, – отбросить первое число, сгенерированное генератором случайных чисел.
Помогите! Мой генератор случайных чисел вообще не генерирует случайные числа!
Если ваш генератор случайных чисел генерирует одно и то же число каждый раз, когда вы запрашиваете случайное число, то вы, вероятно, либо повторно инициализируете генератор случайных чисел перед генерацией случайного числа, либо создаете новый генератор случайных чисел для каждого получения случайного числа.
Вот две функции, которые показывают проблему:
В обоих случаях генератор случайных чисел инициализируется перед каждой генерацией случайного числа. Это приведет к тому, что каждый раз будет генерироваться одно и то же число.
В верхнем случае std::srand() повторно инициализирует встроенный генератор случайных чисел перед вызовом rand() (с помощью getRandomNumber() ).
В нижнем случае мы создаем новый вихрь Мерсенна, инициализируем его, генерируем одно случайное число и затем уничтожаем его.
Для получения случайных результатов вы должны инициализировать генератор случайных чисел только один раз (обычно при инициализации программы для std::srand() или в точке создания для других генераторов случайных чисел), а затем использовать тот же генератор случайных чисел для каждого последующего генерируемого случайного числа.
Предупреждение
Пример getOtherRandomNumber() – одна из самых распространенных ошибок, которые допускаются в тестах. Вы не заметите, что getOtherRandomNumber() не работает, пока вы не начнете вызывать его чаще, чем один раз в секунду (поскольку начальное число изменяется только один раз в секунду). Не забудьте сделать генератор случайных чисел статическим или объявить его вне функции.



