Предметная область информационной системы
Лекция 4 Системный анализ предметной области
Содержание лекции:вопросы анализа моделируемой части реального мира.
Цель лекции:изучить подходы системного анализа моделируемой предметной области.
Каждая информационная система в зависимости от ее назначения имеет дело с той или иной частью реального мира, который принято называть предметной областью.
Существует этап, предшествующий этапу проектирования базы данных. Модель этого этапа должна выражать информацию о предметной области в виде, независимом от используемой СУБД.
Итак, на первом этапе проектирования необходимо выполнитьcистемный анализ предметной области
С точки зрения проектирования базы данных в рамках системного анализа, необходимо провести подробное словесное описание объектов предметной области и реальных связей, которые присутствуют между описываемыми объектами. Желательно, чтобы данное описание позволяло корректно определить все взаимосвязи между объектами предметной области.
В общем случае существуют два подхода к выбору состава и структуры предметной области:
— функциональный подход — он реализует принцип движения «от задач» и применяется тогда, когда заранее известны функции некоторой группы лиц и комплексов задач, для обслуживания информационных потребностей которых создается рассматриваемая база данных. В этом случае мы можем четко выделить минимальный необходимый набор объектов предметной области, которые должны быть описаны;
— предметный подход — когда информационные потребности будущих пользователей базы данных жестко не фиксируются. Они могут быть многоаспектными и весьма динамичными. Мы не можем точно выделить минимальный набор объектов предметной области, которые необходимо описывать. В описание предметной области в этом случае включаются такие объекты и взаимосвязи, которые наиболее характерны и наиболее существенны для нее. База данных, конструируемая при этом, называется предметной, то есть она может быть использована при решении множества разнообразных, заранее не определенных задач.
Конструирование предметной базы данных в некотором смысле кажется гораздо более заманчивым, однако трудность всеобщего охвата предметной области с невозможностью конкретизации потребностей пользователей может привести к избыточно сложной схеме базы данных, которая для конкретных задач будет неэффективной.
Чаще всего па практике рекомендуется использовать некоторый компромиссный вариант, который, с одной стороны, ориентирован на конкретные задачи или функциональные потребности пользователей, а с другой стороны, учитывает возможность наращивания новых приложений.
Системный анализ должен заканчиваться:
— подробным описанием информации об объектах предметной области, которая требуется для решения конкретных задач и которая должна храниться в базе данных;
— формулировкой конкретных задач, которые будут решаться с использованием данной базы;
— описанием входных документов, которые служат основанием для заполнения данными базы данных;
— кратким описанием алгоритмов решения задач;
— описанием выходных документов, которые должны генерироваться в системе.
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Предметная область информационной системы




![]()
![]()
Предметная область (ПО) информационной системы рассматривается как совокупность реальных процессов и объектов (сущностей), пред-ставляющих интерес для её пользователей [7]. Каждая из сущностей ПО обладает определённым набором свойств (атрибутов), среди которых можно выделить существенные и малозначительные. Признание какого-либо свойства существенным носит относительный характер. Например, атрибут Должность для сотрудника является существенным, а для читателя библиотеки – малозначительным.
Примечание. В данном учебном пособии наименования сущностей, атрибутов и связей вы-деляются курсивом и подчёркиванием. Кроме того:
Для упрощения процедуры формализации ПО в большинстве случаев прибегают к определению типов сущностей. Тип позволяет выделить из всего множества сущностей ПО группу сущностей, однородных по структуре и поведению (относительно рамок рассматриваемой ПО). Например, для ПО «Институт» в качестве типов сущностей могут рассматриваться студенты, преподаватели, дисциплины и т.п. Данные предметной области представляются экземплярами сущностей (студент Иванов, преподаватель Сидоров, дисциплина «Базы данных»). Экземпляры сущностей одного типа обладают одинаковыми наборами атрибутов, но должны отличаться значением хотя бы одного атрибута для того, чтобы быть узнаваемыми (например, студенты могут иметь одинаковые ФИО, но должны иметь разные номера зачётных книжек).
Между сущностями ПО могут существовать связи, имеющие различный содержательный смысл (семантику). Например, студент учится в группе, врач лечит пациента, клиент имеет вклад в банке. Связи могут быть факультативными или обязательными. Если вновь порождённая сущность одного из типов оказывается по необходимости связанной с сущностью другого типа, то между этими типами сущностей есть обязательная связь. Иначе связь является факультативной. Примеры обязательной и факультативной связей приведены на рис. 1.3. Здесь связь замещает является обязательной (изображается двойной линией), потому что каждый сотрудник должен работать на определённой должности, а связь замещается является факультативной, т.к. должность может быть вакантна.

Рис.1.3. Примеры обязательной и факультативной связей
Для удобства каждую связь между сущностями можно изображать одним ромбом (рис. 1.4). Выделяют также показатель кардинальности связи: «один к одному» (1:1), «один ко многим» (1:n) и «многие ко многим» (m:n) (рис. 1.4).

Рис.1.4. Примеры различной кардинальности связей
Связи, приведённые на рис. 1.4, с учётом семантики означают следующее:
Обратите внимание: необязательная связь имеет модификатор «может», а у обязательной связи его нет.
Степень связи – это количество сущностей, которые входят в связь. Различают унарные (рис. 1.5,а), бинарные (рис. 1.5,б) и тернарные (рис.1.5,в) связи. (На практике связи с большей степенью редко используют-ся). Унарная связь означает, что одни экземпляры сущности связаны с другими экземплярами этой же сущности (например, одни сотрудники руководят другими, а деталь может являться частью механизма)
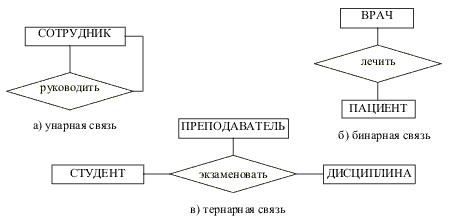
Рис.1.5. Примеры связей различной степени
Различают тип связи и экземпляр связи. Тип связи определяется её име-нем, обязательностью, степенью и кардинальностью, например, бинарная связь учится между сущностями ГРУППА и СТУДЕНТ, обязательная для студента, кардинальностью 1:n. А экземпляр связи – это конкретная связь между студентом Сидоровым и группой Н-11, в которой он учится.
Совокупность типов сущностей и типов связей между ними характеризует структуру предметной области. Собственно данные представлены экземплярами сущностей и связей между ними. Данные экземпляров сущностей и связей хранятся в базе данных информационной системы, а описание типов сущностей и связей является метаданными.

Множества экземпляров сущностей, значения атрибутов сущностей и экземпляры связей между ними могут изменяться во времени. Поэтому каждому моменту времени можно сопоставить некоторое состояние предметной области. Состояния ПО должны подчиняться совокупности правил, которые характеризуют семантику предметной области. В базе данных эти правила могут быть заданы с помощью так называемых ограничений целостности, которые накладываются на атрибуты сущностей, типы сущностей, типы связей и/или их экземпляры. Фактически, ограничения целостности – это правила, которым должны удовлетворять значения данных в БД. Например, для библиотеки можно привести такие ограничения целостности: количество экземпляров книги не может быть отрицательным; номер паспорта читателя должен быть уникальным; каждая книга относится к определённому разделу рубрикатора ББК – библиотечно-библиографической классификации и т.д.
Для того чтобы обеспечить соответствие базы данных текущему состоянию предметной области, база данных динамически обновляется (периодически или в режиме реального времени). Это обновление называется актуализацией данных. Актуализация может проводиться:
Правильность обновлений может контролироваться программно, но правильнее контролировать их автоматически с помощью ограничений целостности БД.
База данных является информационной моделью внешнего мира, некоторой предметной области. Во внешнем мире сущности ПО взаимосвязаны, поэтому в БД эти связи должны быть отражены. Если связи между данными в БД отсутствуют, то имеет смысл говорить о нескольких независимых БД и хранить их раздельно.
Предметная область базы данных и ее модели
Понятие предметной области
Понятие предметной области базы данных является одним из базовых понятий информатики и не имеет точного определения. Его использование в контексте ИС предполагает существование устойчивой во времени соотнесенности между именами, понятиями и определенными реалиями внешнего мира, не зависящей от самой ИС и ее круга пользователей. Таким образом, введение в рассмотрение понятия предметной области базы данных ограничивает и делает обозримым пространство информационного поиска в ИС и позволяет выполнять запросы за конечное время.
Методы математической логики позволяют формализовать эти утверждения и представить их в виде, пригодном для анализа.
Пример. Рассмотрим высказывание: Студент Иванов А.А, родился в 1982 году. Оно выражает следующие свойства объекта «Иванов А.А.»:
ЯВЛЯЕТСЯ СТУДЕНТОМ (Иванов А.А.)

Различают статические и динамические ситуации. Примерами статических ситуаций являются такие ситуации, как иметь цвет, иметь возраст. Примерами динамических ситуаций являются такие ситуации, как создать утюг, выпечь хлеб.
Понятие предметной области было введено в начале 80-х годов прошлого века, когда учеными в области ИС была осознана необходимость использовать семантические модели для представления информации в компьютерных системах. Так же как требования к компьютерной системе формируются средствами естественного языка, так и информация в компьютерных системах представляется средствами особого языка с определенной семантикой. Такой подход впервые был представлен П. Ченом в 1976 году.
Научная электронная библиотека

1.1. Предметная область, информация, данные
Охарактеризуем некоторые основные понятия теории баз данных [1, 4–6], которыми будем пользоваться в дальнейшем.
Предметная область – это часть реального мира, которая подлежит изучению с целью автоматизации организации управления.
Предметной областью информационной системы является совокупность объектов, свойства которых и отношения между которыми представляют интерес для пользователей ИС.
Любая предметная область может быть разбита на фрагменты. Каждый фрагмент оперирует со своими объектами и с множеством пользователей, которые имеют свои взгляды на предметную область, поэтому выявление предметной области и ее анализ является неотъемлемой частью разработки любой информационной системы.
В компьютерных системах описание некоторого формального объекта определяется посредством установления разнообразных по своим свойствам отношений этого объекта с другими объектами такого же рода.
Информация (Федеральный Закон) – сведения о предметах, лицах, событиях фактах, процессах и явлениях независимо от формы их представления.
Информация – это совокупность знаний (фактических данных) об объектах предметной области и зависимостях между ними.
Информация является одним из видов ресурсов, которые используются человеком в быту и профессиональной деятельности. К ресурсам относятся время, сырье, персонал и финансы. Каждый из видов ресурсов обладает такими свойствами как полезность и стоимость.
Полезность информации подтверждается тем, что любое предприятие при управлении другими ресурсами зависит от обеспеченности информацией. Отсутствие своевременной и достоверной информации усложняет деятельность любого предприятия. В условиях конкуренции данные становятся товаром и, следовательно, обладают стоимостью.
Информация бывает трех видов:
Оперативная информация извлекается из оперативных данных (ведомости, данные инженерных расчетов и т.п.). Тактическая информация представляет собой информацию, полученную после обработки оперативной информации (например, квартальные отчеты). Стратегическая информация – это результаты прогнозирования.
Данные – термин, который связан с представлением информации. Иными словами, сведения, зафиксированные на каком-либо материальном носителе, принято называть данными.
Данные – информация, представленная в виде пригодном для обработки ИС.
Возросший объем данных приводит к необходимости управления данными, т.е. приводит к базам данных.
БД – это системы хранения информации, обращение к которым может осуществляться через средства управления базами данных (СУБД).
Основное предназначение БД – предоставление пользователю необходимой информации в нужном месте и в нужное время. Индустрия СУБД [6, 7] в настоящее время вполне состоялась. Условия на рынке БД в настоящее время определяют такие фирмы как Oracle, IBM и Microsoft.
Необходимо выделить следующие формы деятельности БД.
Во-первых, оперативная обработка информации. Приложения с такими БД используются для поддержания ежедневной активности предприятия. Такие приложения требуют быстрой реакции и жесточайшего контроля над целостностью и безопасностью данных. Примерами таких приложений являются системы учета отработанного времени работниками предприятия; системы учета на складе; система учета книг в библиотеке и т.п.
Во-вторых, системы поддержки принятия решений. Они используются с целью анализа данных. Пользователям в таких приложениях должна быть предоставлена возможность конструирования запросов к БД различной сложности, осуществления поиска зависимостей, вывода данных в графических формах и передачи данных в другие приложения, например, текстовые редакторы или статистические пакеты.
С другой стороны приложения в зависимости от области применения подразделяются на два типа:
● офисные БД, предназначенные для поддержания деятельности средних и небольших фирм, не связанных с производственной деятельностью;
● БД для промышленной автоматизации.
С точки зрения организации информации производственная автоматизация несколько запаздывает по сравнению с офисной. Это связано с тем, что традиционные БД зачастую неприменимы для систем промышленной автоматизации.
Вот некоторые ограничения:
1. Генерация данных в производственных процессах происходит с большой скоростью и для хранения производственного архива с 7000 переменных в БД каждую секунду необходимо вставлять 7000 строк. Офисные БД не обладают таким быстродействием.
2. Заводской архив с таким количеством характеристик (7000) требует под размещение БД примерно 1 Терабайт дисковой памяти. Сегодняшние БД такими объемами манипулировать не могут.
Что такое предметная область информационной системы
1.1. Информация, данные, знания. Терминология *
1.2. Автоматизированная информационная система *
1.3. Предметная область информационной системы *
1.4. Назначение и основные компоненты системы баз данных *
1.5. Уровни представления данных *
2. ОСНОВНЫЕ МОДЕЛИ ДАННЫХ *
2.1. Понятие модели данных *
2.1.1. Типы структур данных *
2.1.2. Операции над данными *
2.1.3. Ограничения целостности *
2.2. Сетевая модель данных (СМД) *
2.3. Иерархическая модель данных (ИМД) *
2.4. Реляционная модель данных (РМД) *
2.4.1. Понятие отношения *
2.4.2. Свойства отношений *
2.4.3. Достоинства и недостатки РМД *
2.4.4. Операции реляционной алгебры *
2.4.5. Преобразования операций реляционной алгебры *
2.5. Другие модели данных *
2.5.1. Объектно-реляционные модели данных *
2.5.2. Объектно-ориентированные модели данных *
3.1. Инфологическое проектирование
3.2. Определение требований к операционной обстановке
3.3. Выбор СУБД и инструментальных программных средств
3.4. Логическое проектирование БД
3.5. Физическое проектирование БД
3.6. Автоматизация проектирования БД
3.7. Особенности проектирования реляционных БД
3.7.1. Аномалии модификации данных
3.7.2. Нормализация отношений
4. СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ
4.1. Классификация СУБД
4.2. Основные функции СУБД
4.3. Логическая и физическая целостность БД
4.4. Администрирование БД
4.5. Словари-справочники данных
5.1. Механизмы среды хранения и архитектура СУБД
5.2. Пространство памяти и размещение хранимых данных
5.3. Структура хранимых данных
5.4. Виды адресации хранимых записей
5.5. Организация связей между хранимыми записями
6. МЕХАНИЗМЫ РАЗМЕЩЕНИЯ ДАННЫХ И ДОСТУПА К ДАННЫМ
6.1. Способы доступа к записям
6.2. Индексирование данных
6.2.1. Способы организации индексов
6.2.2. Многоуровневые индексы на основе В-дерева
6.2.3. Использование индексов
6.3.1. Методы хеширования
6.3.2. Разрешение коллизий
6.3.2. Использование хеширования
6.4. Кластеризация данных
6.4.1. Принцип организации кластеров
6.4.2. Использование кластеров
7. ОРГАНИЗАЦИЯ ПАРАЛЛЕЛЬНОГО ДОСТУПА К ДАННЫМ
7.1. Механизм транзакций
7.2. Взаимовлияние транзакций
7.3. Уровни изоляции транзакций
8. СПЕЦИАЛЬНАЯ ОБРАБОТКА БАЗЫ ДАННЫХ
8.1. Обеспечение целостности данных
8.2. Обеспечение защиты данных
8.2.1. Безопасность данных (обеспечение физической защиты)
8.2.2. Защита от несанкционированного доступа
8.2.3. Управление доступом к базе данных
9. ПЕРСПЕКТИВЫ РАЗВИТИЯ ТЕХНОЛОГИИ БАЗ ДАННЫХ
Список используемых сокращений
1. ВВЕДЕНИЕ
Развитие средств вычислительной техники обеспечило возможности для создания и широкого использования автоматизированных систем обработки данных (СОД) разнообразного назначения. Разрабатываются информационные системы управления хозяйственными и техническими объектами, модельные комплексы для научных исследований, системы автоматизации проектирования и производства, всевозможные тренажеры и обучающие системы.
Существуют две основные предпосылки создания таких систем:
1. Разработка методов конструирования систем, предназначенных для коллективного пользования.
2. Возможность собирать, хранить и обрабатывать большое количество данных о реальных объектах и явлениях, то есть оснащение этих систем «памятью». Массив данных общего пользования в подобных системах называется
базой данных. Концепция баз данных стала определяющим фактором при создании эффективных автоматизированных СОД.
Основным принципом организации базы данных является совместное хранение данных и их описаний.
Эти описания обычно называют метаданными. С помощью данного принципа обеспечивается независимость данных от программ обработки, что позволяет запрашивать и модифицировать данные без написания дополнительных программ.
Информация – любые сведения о каком-либо событии, сущности, процессе и т.п., являющиеся объектом некоторых операций: восприятия, передачи, преобразования, хранения или использования.
Данные – это информация, зафиксированная в некоторой форме, пригодной для последующей обработки, передачи и хранения, например, находящаяся в памяти ЭВМ или подготовленная для ввода в ЭВМ.
Знания – в системах обработки информации знания понимают как сложноорганизованные данные, содержащие фактографическую и семантическую информацию (т.е. регистрация некоторого факта и его смысловое содержание).
Подготовка информации состоит в её формализации, сборе и перенесении на машинные носители.
Обработка данных – это совокупность задач, осуществляющих преобразование массивов данных. Обработка данных включает в себя ввод данных в ЭВМ, отбор данных по каким-либо критериям, преобразование структуры данных, перемещение данных на внешней памяти ЭВМ, вывод данных, являющихся результатом решения задач, в табличном или в каком-либо ином удобном для пользователя виде.
Система обработки данных (СОД) – это набор аппаратных и программных средств, осуществляющих выполнение задач по управлению данными.
Управление данными – весь круг операций с данными, которые необходимы для успешного функционирования СОД.
Предметная область (ПО) – часть реального мира, подлежащая изучению с целью организации управления и, в конечном итоге, автоматизации. ПО представляется множеством фрагментов, которые характеризуются множеством объектов, множеством процессов, использующих объекты, а также множеством пользователей, характеризуемых единым взглядом на предметную область.
База данных (БД) – совокупность структурированных взаимосвязанных данных, относящихся к определённой предметной области и организованных таким образом, что эти данные могут быть использованы для решения многих задач многими пользователями.
В дальнейшем речь пойдёт только об электронных базах данных, т.е. таких, которые хранятся и используются с помощью ЭВМ.
Автоматизированная информационная система (АИС) – это аппаратно-программный комплекс, функционирующий на основе вычислительной техники и обеспечивающий сбор, хранение, актуализацию и обработку данных в целях информационной поддержки какого-либо вида деятельности.
Банк данных (БнД) – это автоматизированная информационная система, включающая в свой состав комплекс специальных методов и средств (математических, информационных, программных, языковых, организационных и технических) для поддержания динамической информационной модели предметной области с целью обеспечения информационных запросов пользователей.
Информационная система (ИС), основанная на базе данных, служит для сбора, накопления, хранения информации, а также её эффективного использования для разнообразных целей. Информация представляется в виде данных, хранимых в памяти ЭВМ. При проектировании АИС, с одной стороны, решается вопрос о том, какие сведения и для каких целей будут содержаться в системе, с другой – как соответствующие данные будут организованы в памяти ЭВМ, как они будут поддерживаться и обрабатываться при эксплуатации АИС.
По сферам применения различают два основных класса АИС: информационно-поисковые (ИПС) и системы обработки данных (СОД). ИПС ориентированы, как правило, на извлечение подмножества хранимых данных, удовлетворяющих некоторому поисковому критерию. Пользователя ИПС интересует, в основном, извлекаемые из базы данных сведения, а не результаты их обработки (пример ИПС – справочные службы).
Обращения пользователя к СОД чаще всего приводят к обновлению данных. Вывод данных может вовсе отсутствовать или представлять собой результат программной обработки хранимых сведений. Пример СОД – банковские системы, осуществляющие открытие/закрытие счетов, пересчёт вкладов в зависимости от процентов, приём/снятие сумм и т.п.
В зависимости от характера информационных ресурсов, с которыми имеют дело АИС, их подразделяют на документальные и фактографические. На практике используются также и системы комбинированного типа.
В документальной системе объект хранения – документ, который содержит информацию, относящуюся к определённой предметной области. Это могут быть графические изображения (например, географические карты); информация на естественном языке (монографии, тексты законодательных актов, научные отчёты и т.п.); звуковая информация (например, мелодии для системы, хранящей фонотеку) и т.д. Для обработки информации не важно, какие сведения хранятся в документах. Обычно документальные АИС реализуются в виде информационно-поисковых систем.
Основные компоненты ИПС – это программные средства, поисковый массив документов, средства поддержки информационного языка системы. Программные средства ИПС служат для организации управления данными (ввода, хранения, защиты, поиска и выдачи). Поисковый массив документов в ИПС обычно называется базой данных. Он представляет собой набор ссылок на документы (или их описаний), хранящий основную информацию о документах и организованный так, чтобы обеспечить быстрый поиск документов. Описание документа зависит от предметной области и состоит из значений атрибутов, характеризующих содержание документа. Например, для БД географических карт это могут быть координаты и масштаб, а для БД законодательных актов – тип документа (закон, постановление и т.д.), дата его принятия, область действия и т.п.
Информационный язык системы предназначен для того, чтобы пользователь мог сформулировать запрос к системе. Системными средствами запрос преобразуется в формализованное поисковое предписание – поисковый образ запроса, которое далее сопоставляется с поисковыми образами документов, хранимыми в системе, по критерию смыслового соответствия. Информационный язык системы может быть основан на подмножестве естественного языка, которое относится к обслуживаемой ПО. Но чаще поиск документа осуществляется с помощью шаблонов – экранных форм, включающих поля описания документа.
Фактографические АИС хранят сведения об объектах предметной области, их свойствах и взаимосвязях. Сведения о каждом объекте могут поступать в систему из множества различных источников. Кроме поиска и модификации данных, фактографические системы поддерживают статистические функции (нахождение суммы, минимума, максимума и т.п.).
Мы будем основное внимание обращать на фактографические АИС, имея в виду, что ИПС создаются с помощью те же программных средств и на тех же принципах, что и СОД, а специфические моменты обработки данных реализуются через приложения (программы, внешние по отношению к ядру СОД).
Разработка любой информационной системы начинается с определения предметной области.
Предметная область (ПО) информационной системы рассматривается как совокупность реальных процессов и объектов (сущностей), представляющих интерес для её пользователей.
Каждый из объектов обладает определённым набором свойств (атрибутов), среди которых можно выделить существенные и малозначительные. Признание какого-либо свойства существенным носит относительный характер. Для упрощения процедуры формализации ПО в большинстве случаев прибегают к разбиению всего множества объектов ПО на группы объектов, однородных по структуре и поведению (относительно рамок рассматриваемой ПО), называемых типами объектов. Данные ПО представлены экземплярами объектов. Экземпляры объектов одного типа обладают одинаковыми наборами атрибутов, но должны отличаться значением хотя бы одного атрибута для того, чтобы быть узнаваемыми.
Для каждого объекта определяется идентификатор – ключевой атрибут или комбинация атрибутов. Такой идентификатор называется первичным ключом, его значение является уникальным и обязательным.
Между объектами ПО могут существовать связи, имеющие различный содержательный смысл (семантику). Эти связи могут быть факультативными или обязательными (рис.1.1). Если вновь порождённый объект одного из типов оказывается по необходимости связанным с объектом другого типа, то между этими типами объектов существует обязательная связь. Иначе связь является факультативной.
Рис.1.1. Примеры обязательной и факультативной связей
Различают типы множественных связей: «один к одному» (1:1), «один ко многим» (1:n) и «многие ко многим» (m:n) (рис. 1.2).
Рис.1.2. Примеры типов множественных связей
Совокупность типов сущностей и типов связей между ними характеризует структуру предметной области. Собственно данные представлены экземплярами объектов и связей между ними.
Множества типов объектов ПО и экземпляров объектов, значения атрибутов объектов и связи между ними могут изменяться во времени. Поэтому каждому моменту времени можно сопоставить некоторое состояние ПО. Состояния ПО обладают совокупностью свойств (правил), которые характеризуют семантику ПО. Эти правила могут быть заданы с помощью так называемых ограничений целостности, которые накладываются на типы объектов, типы связей и/или их экземпляры.
Система БД включает два основных компонента: собственно базу данных и систему управления (рис. 1.3). Большинство СОД включают также программы обработки данных, которые обращаются к данным через систему управления.
Рис.1.3. Компоненты системы баз данных
В соответствии с рис. 1.3. система управления базами данных (СУБД) обеспечивает выполнение двух групп функций: предоставление доступа к базе данных пользователям (или прикладному программному обеспечению, ППО) и управление хранением и обработкой данных в БД.
БД является информационной моделью внешнего мира, некоторой предметной области. В ней, как правило, хранятся данные об объектах, их свойствах и характеристиках. Во внешнем мире объекты взаимосвязаны, поэтому в БД эти связи должны быть отражены. Если связи между данными в БД отсутствуют, то имеет смысл говорить о нескольких независимых БД, имеющих раздельное хранение.
В памяти ЭВМ создаётся динамически обновляемая модель предметной области, что обеспечивает соответствие базы данных текущему состоянию ПО (периодически или в режиме реального времени). Одни и те же данные БД могут быть использованы для решения многих прикладных задач. Этим база данных принципиально отличается от любой другой совокупности данных внешней памяти ЭВМ.
Концепции многоуровневой архитектуры СУБД служат основой современной технологии БД. Эти идеи впервые были сформулированы в отчёте рабочей группы по базам данных Комитета по планированию стандартов Американского национального института стандартов (ANSI/X3/SPARC), опубликованному в 1975 г. В нем была предложена обобщенная трехуровневая модель архитектуры СУБД, включающая концептуальный, внешний и внутренний уровни (рис. 1.4).
Рис.1.4. Уровни представления данных
Концептуальный уровень архитектуры ANSI/SPARC служит для поддержки единого взгляда на базу данных, общего для всех её приложений и независимого от них. Концептуальный уровень представляет собой формализованную информационно-логическую модель ПО. Описание этого представления называется концептуальной схемой.
Внутренний уровень архитектуры поддерживает представление БД в среде хранения – хранимую базу данных. На этом архитектурном уровне БД представлена в полностью “материализованном” виде, тогда как на других уровнях идёт работа на уровне отдельных экземпляров или множества экземпляров записей. Описание БД на внутреннем уровне называется внутренней схемой или схемой хранения.
Внешний уровень архитектуры БД предназначен для различных групп пользователей. Описания таких представлений называются внешними схемами. В системе БД могут одновременно поддерживаться несколько внешних схем для различных групп пользователей или задач.
Совокупность схем всех уровней называется схемой базы данных.
Каждый из этих уровней может считаться управляемым, если он обладает внешним интерфейсом, который поддерживает возможности определения данных. В этом случае становится возможными формирование и системная поддержка независимого взгляда на БД для какой-либо группы персонала или пользователей, взаимодействующих с БД через интерфейс данного уровня.
В архитектурной модели ANSI/SPARC предполагается наличие в СУБД механизмов, обеспечивающих междууровневое отображение данных “внешний – концептуальный” и “концептуальный – внутренний”. Функциональные возможности этих механизмов обеспечивают абстракцию данных и определяют степень независимости данных на всех уровнях.
2. ОСНОВНЫЕ МОДЕЛИ ДАННЫХ
2.1. Понятие модели данных
Модель данных – это математическое средство абстракции, позволяющее отделить факты от их интерпретации и вместе с тем обеспечить развитые возможности представления соотношения данных.
Модель данных – это комбинация трех составляющих:
1. Набора типов структур данных.
2. Набора операторов или правил вывода, которые могут быть применены к любым правильным примерам типов данных, перечисленных в (1), чтобы находить, выводить или преобразовывать информацию, содержащуюся в любых частях этих структур в любых комбинациях.
3. Набора общих правил целостности, которые прямо или косвенно определяют множество непротиворечивых состояний БД и/или множество изменений её состояния.
2.1.1. Типы структур данных
Структуризация данных базируется на использовании концепций «агрегации» и «обобщения». Первый вариант структуризации данных был предложен Ассоциацией по языкам обработки данных (Conference on Data Systems Languages, CODASYL) (рис.2.1).
Рис.2.1. Композиция структур данных по версии CODASYL
Элемент данных – наименьшая поименованная единица данных, к которой СУБД может обращаться непосредственно и с помощью которой выполняется построение всех остальных структур. Для каждого элемента данных должен быть определён его тип.
Агрегат данных – поименованная совокупность элементов данных внутри записи, которую можно рассматривать как единое целое. Агрегат может быть простым (включающим только элементы данных, рис.2.2,а) и составным (включающим наряду с элементами данных и другие агрегаты, рис.2.2,б).
Рис.2.2. Примеры агрегатов: а) простой и б) составной агрегат
Запись – поименованная совокупность элементов данных или элементов данных и агрегатов. Запись – это агрегат, не входящий в состав никакого другого агрегата; она может иметь сложную иерархическую структуру, поскольку допускается многократное применение агрегации. Различают тип записи (её структуру) и экземпляр записи, т.е. запись с конкретными значениями элементов данных. Одна запись описывает свойства одного объекта ПО (экземпляра).
Среди элементов данных (полей) выделяются одно или несколько ключевых полей. Значения ключевых полей позволяют классифицировать объект, к которому относится конкретная запись. Ключи с уникальными значениями называются потенциальными. Каждый ключ может представлять собой агрегат данных. Один из ключей является первичным, остальные – вторичными. Первичный ключ идентифицирует экземпляр записи и его значение должно быть уникальным в пределах записей одного типа.
Иногда термин «запись» заменяют термином «группа».
Набор (или групповое отношение) – поименованная совокупность записей, образующих двухуровневую иерархическую структуру. Каждый тип набора представляет собой отношение (связь) между двумя или несколькими типами записей. Для каждого типа набора один тип записи может быть объявлен владельцем набора, остальные типы записи объявляются членами набора. Каждый экземпляр набора должен содержать только один экземпляр записи типа владельца и столько экземпляров записей типа членов набора, сколько их связано с владельцем. Для группового отношения также различают тип и экземпляр.
Групповые отношения удобно изображать с помощью диаграммы Бахмана (названа по имени одного из разработчиков сетевой модели данных). Диаграмма Бахмана представляет собой ориентированный граф, в котором вершины соответствуют группам (типам записей), а дуги – иерархическим групповым отношениям (рис. 2.3).
Рис. 2.3. Пример диаграммы Бахмана для фрагмента БД «Город»
Здесь запись типа ПОЛИКЛИНИКА является владельцем записей типа ЖИТЕЛЬ и они связаны групповым отношением диспансеризация. Запись типа ОРГАНИЗАЦИЯ также является владельцем записей типа ЖИТЕЛЬ и они связаны групповым отношением работают. Записи типа РЭУ и типа ЖИТЕЛЬ являются владельцами записей типа КВАРТИРА с отношениями соответственно обслуживают и проживают. Таким образом, запись одного и того же типа может быть членом одного отношения и владельцем другого.
База данных – поименованная совокупность экземпляров групп и групповых отношений.
2.1.2. Операции над данными
Модель данных определяет множество действий, которые допустимо производить над некоторой реализацией БД для её перевода из одного состояния в другое. Это множество соотносят с языком манипулирования данными (Data Manipulation Language, DML).
Любая операция над данными включает в себя селекцию данных (select), то есть выделение из всей совокупности именно тех данных, над которыми должна быть выполнена требуемая операция, и действие над выбранными данными, которое определяет характер операции. Условие селекции – это некоторый критерий отбора данных, в котором могут быть использованы логическая позиция элемента данных, его значение и связи между данными.
По типу производимых действий различают следующие операции:
Обработка данных в БД осуществляется с помощью процедур базы данных – транзакций. Транзакция – это последовательность операций над данными, которая является логически неделимой, то есть рассматривается как единая макрооперация. Транзакция либо выполняется полностью, либо не выполняется совсем. Никакая другая процедура или операция не могут обратиться к данным, которые обрабатываются стартовавшей процедурой, до тех пор, пока последняя не закончит свою работу.
2.1.3. Ограничения целостности
Ограничения целостности обеспечивают непротиворечивость данных при переводе системы БД из одного состояния в другое и позволяют адекватно отражать ПО данными, хранимыми в БД. Ограничения делятся на явные и неявные.
Неявные ограничения определяются самой структурой данных. Например, тот факт, что записи типа СОТРУДНИК являются обязательными членами какого-либо экземпляра набора данных ПОДРАЗДЕЛЕНИЕ, служит, по существу, ограничением целостности, означающим, что каждый сотрудник организации непременно должен быть в штате некоторого подразделения.
Явные ограничения задаются в схеме базы данных с помощью средств языка описания данных (DDL, Data Definition Language). В качестве явных ограничений чаще всего выступают условия, накладываемые на значения данных. Например, заработная плата не может быть отрицательной, а дата приема сотрудника на работу обязательно будет меньше, чем дата его перевода на другую работу. За выполнением этих ограничений следит СУБД в процессе своего функционирования.
Также различают статические и динамические ограничения целостности. Статические ограничения присущи всем состояниям ПО, а динамические определяют возможность перехода ПО из одного состояния в другое. Примерами статических ограничений целостности могут служить требования уникальности номера паспорта или ограничения на дату рождения, которая не может быть больше текущей даты. В качестве примера динамического ограничения целостности можно привести ограничение банковской системы, в соответствии с которым нельзя удалить сведения о клиенте, пока у него не закрыт счёт.
В настоящее время разработано много различных моделей данных. Основные – это сетевая, иерархическая и реляционная модели.
Сетевая модель позволяет организовывать БД, структура которых представляется графом общего вида (пример СМД – на рис. 2.3). Организация данных в сетевой модели соответствует структуризации данных по версии CODASYL. Каждая вершина графа хранит экземпляры сущностей (записи) и сведения о групповых отношениях с сущностями других типов. Каждая запись может хранить произвольное количество значений атрибутов (элементов данных и агрегатов), соответствующих экземпляру сущности.
Групповые отношения характеризуют следующие признаки:
1. Способ упорядочения подчинённых записей.
Поддерживаются три способа упорядочения:
2. Режим включения подчинённых записей.
Режим включения бывает автоматический и ручной.
При автоматическом режиме подчиненная запись связана с записью-владельцем обязательной связью, поэтому она включается в групповое отношение и прикрепляется к записи-владельцу в момент внесения в БД. (Из этого следует, что запись-владелец должна быть внесена в БД до внесения первого экземпляра подчиненной записи.)
При ручном режиме включения подчиненная запись может находиться в БД и не быть прикрепленной к записи-владельцу. Она вручную включается в групповое отношение тогда, когда это отношение (связь) возникает.
3. Режим исключения подчинённых записей.
Режим исключения определяется классом членства. Различают три класса членства: фиксированный, обязательный и необязательный. Записи с фиксированным членством удаляются вместе с записью–владельцем. Записи с обязательным членством должны быть удалены до удаления записи–владельца: владелец, к которому прикреплена хотя бы одна запись с обязательным членством, не может быть удален. Записи с необязательным членством при удалении записи–владельца останутся в БД.
В СМД применяются следующие операции над данными:
Связи между записями в СМД обычно выполнены в виде указателей (т.е. каждая запись хранит ссылки на другие однотипные записи и записи, связанные с ней групповыми отношениями). Подробнее об этом рассказано в разделе 5.5.»Организация связей между хранимыми записями».
В сетевой модели данных предусмотрены специальные способы навигации и манипулирования данными. Аппарат навигации в графовых моделях служит для установления тех объектов данных, к которым будет применяться очередная операция манипулирования данными. Такие объекты называются текущими. В СМД возможны переходы:
Наиболее распространенной и стандартизованной из реализаций СМД является модель CODASYL. В соответствии с ней описание схемы БД осуществляется на языке COBOL, а манипулирование данными – с помощью включающего языка программирования высокого уровня.
Иерархическая модель позволяет строить БД с иерархической древовидной структурой. Структура ИМД описывается в терминах, аналогичных терминам сетевой модели данных.
Дерево – это связный неориентированный граф, который не содержит циклов. Обычно при работе с деревом выделяют какую-то конкретную вершину, определяют её как корень дерева и рассматривают особо – в эту вершину не заходит ни одно ребро. В этом случае дерево становится ориентированным. Ориентация определяется от корня. Дерево как ориентированный граф можно определить следующим образом:
Конечные вершины, то есть вершины, из которых не выходит ни одной дуги, называются листьями дерева.
В иерархических моделях данных используется ориентация древовидной структуры от корня к листьям. Графическая диаграмма схемы базы данных называется деревом определения. Пример иерархической базы данных приведён на рис.2.4.
Рис.2.4. Пример иерархической базы данных
Каждая некорневая вершина связана с родительской записью иерархическим групповым отношением. Каждая вершина дерева соответствует сущности ПО, которая характеризуется произвольным количеством атрибутов, связанных с ней отношением 1:1. Атрибуты, связанные с сущностью отношением 1:n, образуют отдельную сущность и переносятся на следующий уровень иерархии. Тип вершины определяется типом сущности и набором её атрибутов. Каждая вершина дерева хранит экземпляры сущностей – записи. Следствием внутренних ограничений иерархической модели является то, что каждому экземпляру зависимой группы в БД соответствует уникальное множество экземпляров родительских групп – по одному экземпляру каждого типа вершин вышестоящих уровней.
В ИМД также предусмотрены специальные способы навигации. Передвижение по дереву всегда начинается с корневой вершины, от которой можно прейти на конкретный экземпляр записи любой вершины следующего уровня. Эта вершина становится текущей вершиной, а экземпляр – текущим экземпляром (записью). От этой записи можно перейти к другой записи данной вершины, к экземпляру записи родительской вершины или к экземпляру записи подчиненной вершины.
Корневая запись дерева должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальные значения только в экземплярах групповых отношений, т.е. на одном и том же уровне иерархии в разных ветвях дерева могут быть экземпляры записей с одинаковыми ключами. Это объясняется тем, что каждая запись идентифицируется полным сцепленным ключом, который образуется путём конкатенации всех ключей экземпляров родительских записей (групп). Таким образом, попасть в любую вершину можно, только проделав полный путь по дереву от корня.
Связи между записями в ИМД обычно выполнены в виде ссылок (т.е. хранятся адреса связанных записей). Подробнее об этом рассказано в разделе 5.5.»Организация связей между хранимыми записями».
Основным недостатком ИМД является дублирование данных. Оно вызвано тем, что каждая сущность (атрибут) может подчиняться (принадлежать) только одной родительской сущности. Таким образом, если надо сохранить, например, данные о детях сотрудника, а на предприятии трудится и отец, и мать ребенка, то информацию о детях придётся хранить дважды. Это может вызвать нарушение логической целостности БД при внесении изменений в данные о детях.
Если данные имеют естественную древовидную структуризацию, то использование иерархической модели данных не вызывает проблем. Но на практике часто требуется реализовать структуры данных, отличные от иерархической. Для решения этих задач конкретные СУБД, основанные на ИМД, включают дополнительные средства, облегчающие представление произвольно организованных данных.
Реляционная модель данных была предложена математиком Э.Ф. Коддом (Codd E.F.) в 1970 г. РМД является наиболее широко распространенной моделью данных и единственной из трех основных моделей данных, для которой разработан теоретический базис с использованием теории множеств.
В основе РМД лежит понятие отношения, представляющего собой подмножество декартова произведения доменов. Домен – это множество значений, которое может принимать элемент (например, множество целых чисел, множество комбинаций символов длиной N и т.п.).
Таким образом, декартово произведение позволяет получить все возможные комбинации элементов исходных множеств.
Пример. Для доменов D1 = (1,2), D2 = (A,B,C) декартово произведение D будет таким:
Подмножество декартова произведения доменов называется отношением.
Элементы отношения называют кортежами. Элементы кортежа принято называть атрибутами. Количество атрибутов кортежа определяет арность отношения. Отношения арности 1 называют унарными, арности 2 – бинарными, арности n – n-арными.
Отношение содержит информацию о сущностях одного типа. Каждый кортеж отношения соответствует одному экземпляру сущности.
Отношение обладает двумя основными свойствами:
1. в отношении не должно быть одинаковых кортежей, т.к. это множество;
2. порядок кортежей в отношении несущественен.
Отношение удобно представлять как таблицу, где строка является кортежем, столбец соответствует домену (рис. 2.5, отношение СТУДЕНТЫ).



