Равномерные и неравномерные коды.
Дата добавления: 2015-08-14 ; просмотров: 34330 ; Нарушение авторских прав
Код называется равномерным (или кодом постоянной длины), если все его кодовые слова содержат одинаковое число букв (одинаковую длину слов). Соответственно, кодирование называется равномерным, если соответствующий ему код имеет постоянную длину. В настоящее время в информатике более употребительно равномерное кодирование, оно проще и более удобно. В компьютерах при кодировании информации в основном используются равномерные коды, соответствующие размерам компьютерных ячеек.
Другим интересным примером равномерного кода является код Трисиме, в котором знакам латинского алфавита ставятся в соответствие кодовые слова длины 3 над алфавитом из 3-х символов: <1, 2, 3>. Этот код представлен в следующей таблице :
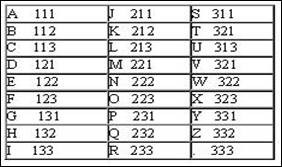
Понятно, что код Трисиме не может кодировать более чем 3 3 =27 символов.
Число букв в алфавите кода называется основанием кода, а длина кодовых слов равномерного кода называется порядком кода. Коды с основанием 2, как уже говорилось, называются двоичными, а с основанием 3 – троичными, и так далее. Так код Бодо имеет основание 2, а порядок 5, а у кода Трисиме и основание, и порядок равны 3.
Код называется неравномерным (или кодом переменной длины), если его кодовые слова имеют разное число букв (неодинаковую длину слов). Соответственно, кодирование называется неравномерным, если соответствующий ему код неравномерный.
Типичным примером неравномерного кода является телеграфный код, который принято называть азбукой Морзе. На следующей таблице представлен код азбуки Морзе для русского алфавита:
| A | • − | И | • • | P | • − • | Ш | − − − − | • − − − − | − − − − • | |
| Б | − • • • | Й | • − − − | С | • • • | Щ | − − • − | • • − − − | − − − − − | |
| В | • − − | К | − • − | Т | − | Ъ | • − − • − • | • • • − − | Точка | • • • • • • |
| Г | − − • | Л | • − • • | У | • • − | Ь | − • • − | • • • • − | Запятая | • − • − • − |
| Д | − • • | М | − − | Ф | • • − • | Ы | − • − − | • • • • • | / | − • • − • |
| Е | • | H | − • | Х | • • • • | Э | • • − • • | − • • • • | ? | • • − − • • |
| Ж | • • • − | О | − − − | Ц | − • − • | Ю | • • − − | − − • • • | ! | − − • • − − |
| З | − − • • | П | • − − • | Ч | − − − • | Я | • − • − | − − − • • | @ | • − − • − • |
Американский изобретатель телеграфа Сэмюель Морзе разработал этот код в 1838 году для передачи телеграфных сообщений в виде последовательности электрических сигналов, передаваемых от одного телеграфного аппарата по проводам к другому телеграфному аппарату. Этот код был придуман Морзе задолго до научных исследований
 |
| СэмюэлМорзе (1791-1872) |
относительной частоты появления различных букв в текстах, но, тем не менее, Морзе при составлении кода использовал принцип частоты букв. Буквам, используемым чаще, им присвоены короткие кодовые комбинации, редко используемым буквам – длинные. Морзе оценил относительную частоту букв английского языка подсчетом литер в ячейках типографской наборной машины. Наиболее часто используемой букве «Е» (в английском языке) он присвоил наиболее короткий код «точка». Следующей по количеству литер букве он присвоил код несколько большей длительности и так далее.
При составлении азбуки Морзе для букв русского алфавита учет относительной частоты букв не производился, и это повысило его избыточность. Расчеты избыточности кода Морзе на основании проведенных исследований частоты появления букв показали, что для букв английского алфавита она составляет 19%, для букв русского алфавита 22%.
Преимущество у неравномерных кодов перед равномерными как раз и состоит в том, что сообщения можно передавать более экономным способом, так как часто передаваемые кодовые слова более короткие, а значит, кодовая последовательность может иметь меньшую длину, чем для равномерных кодов. Ниже это будет показано.
Но у неравномерных кодов есть серьезный недостаток по сравнению с равномерными кодами. У равномерных кодов кодовая последовательность всегда декодируется однозначно за счет того, что кодовые слова имеют одинаковую длину (кодовая последовательность легко делится на кодовые слова). Но не для всех неравномерных кодов достигается однозначность декодирования кодовых последовательностей. Мы уже видели это, пытаясь рассматривать азбуку Морзе как двоичный код.
Этот код неравномерный (кодовые слова разной длины).
Закодируем последовательность сообщений: s7s7. Имеем F(s7s7)=B=111111. Но эта последовательность может быть декодирована и по-другому, так как: B=F(s3s3s3)= F(s1s3s7)=F(s3s7s1)=F(s1s1s1s1s1s1s1s). Как видим, способов декодирования много (подсчитайте: сколько их?). Неоднозначно декодируется и следующая последовательность:
11011011 (а сколько здесь способов декодирования?). Очевидно, что такой код практически использовать нельзя. А если мы изменим код так, чтобы он стал равномерным, например, доопределим функцию F так:
то теперь никаких проблем с декодированием не будет.
Что такое равномерное и неравномерное кодирование
Представление информации происходит в различных формах в процессе восприятия окружающей среды живыми организмами и человеком, в процессах обмена информацией между человеком и человеком, человеком и компьютером, компьютером и компьютером и так далее. Информация, поступает в виде условных знаков или сигналов самой разной физической природы.
Это свет, звук, запах, касания; это слова, значки, символы, жесты и движения.
Для того чтобы произошла передача информации, мы должны не только принять сигнал от кого-то, но и расшифровать его.
Так, услышав звонок будильника, человек понимает, что пришло время просыпаться;
телефонный звонок — кому-то нужно с нами поговорить;
школьный звонок сообщает учащимся о долгожданной перемене.
Для правильного понятия разных сигналов требуется разработка кода или кодирование.
Код — это система условных знаков для представления информации.
Кодирование — это перевод информации в удобную для передачи, обработки или хранения форму с помощью некоторого кода.
Средством кодирования служит таблица соответствия знаковых систем, которая устанавливает взаимно однозначное соответствие между знаками или группами знаков двух различных знаковых систем.
Обратное преобразование называется декодированием.
Декодирование — это процесс восстановления содержания закодированной информации.
Можно рассмотреть в качестве примера кодирования соответствие цифрового и штрихового кодов товара. Такие коды имеются на каждом товаре и позволяют полностью идентифицировать товар (страну и фирму производителя, тип товара и др.).
Существует три основных способа кодирования информации:
●Числовой способ — с помощью чисел.
●Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
●Графический способ — информация кодируется с помощью рисунков или значков.
Существует равномерное и неравномерное кодирование. При равномерном кодировании сообщение декодируется однозначно. При неравномерном кодировании для однозначного декодирования сообщения нужно, чтобы выполнялось прямое и обратное условие Фано(прямое: никакой код не должен быть началом другого кода, обратное: никакой код не должен быть концом другого кода)
Понимать, что мы можем закодировать сообщение, даже если условие Фано не выполняется, но возможно не сможем его однозначно декодировать.
Однозначно декодировать –получить один единственный точный вариант.
Двоичное кодирование информации в компьютере.
В компьютере для представления информации используется двоичное кодирование, так как удалось создать надежно работающие технические устройства, которые могут со стопроцентной надежностью сохранять и распознавать не более двух различных состояний (цифр):
· электромагнитные реле (замкнуто/разомкнуто), широко использовались в конструкциях первых ЭВМ;
· участок поверхности магнитного носителя информации (намагничен/размагничен);
· участок поверхности лазерного диска (отражает/не отражает);
· триггер, может устойчиво находиться в одном из двух состояний, широко используется в оперативной памяти компьютера.
Кодирование текстовой информации.
Текстовую информацию кодируют двоичным кодом через обозначение каждого символа алфавита определенным целым числом. С помощью восьми двоичных разрядов возможно закодировать 256 различных символов. Данного количества символов достаточно для выражения всех символов английского и русского алфавитов.
Для кодировки русского алфавита были разработаны несколько вариантов кодировок:
2) КОИ-8 (Код Обмена Информацией, восьмизначный) – другая популярная кодировка российского алфавита, распространенная в компьютерных сетях.
3) ISO (InternationalStandardOrganization – Международный институт стандартизации) – международный стандарт кодирования символов русского языка. На практике эта кодировка используется редко.
Ограниченный набор кодов (256) создает трудности для разработчиков единой системы кодирования текстовой информации. Вследствие этого было предложено кодировать символы не 8-разрядными двоичными числами, а числами с большим разрядом, что вызвало расширение диапазона возможных значений кодов. Система 16-разрядного кодирования символов называется универсальной – UNICODE.
Кодирование графической информации.
Существует несколько способов кодирования графической информации.
поэтому способ растрового кодирования базируется на использовании двоичного кода представления графических данных. Общеизвестным стандартом считается приведение черно-белых иллюстраций в форме комбинации точек с 256 градациями серого цвета, т. е. для кодирования яркости любой точки необходимы 8-разрядные двоичные числа.
В основу кодирования цветных графических изображений положен принцип разложения произвольного цвета на основные составляющие, в качестве которых применяются три основных цвета: красный (Red), зеленый (Green) и синий (Blue). На практике принимается, что любой цвет, который воспринимает человеческий глаз, можно получить с помощью механической комбинации этих трех цветов. Такая система кодирования называется RGB. При применении 24 двоичных разрядов для кодирования цветной графики такой режим носит название полноцветного (TrueColor).
Для любого из основных цветов дополнительным будет являться цвет, который образован суммой пары остальных основных цветов. Соответственно среди дополнительных цветов можно выделить голубой (Cyan), пурпурный (Magenta) и желтый (Yellow). Принцип разложения произвольного цвета на составляющие компоненты используется не только для основных цветов, но и для дополнительных. Этот метод кодирования цвета применяется в полиграфии, но там используется еще и четвертая краска – черная (Black), поэтому эта система кодирования обозначается четырьмя буквами – CMYK. Для представления цветной графики в этой системе применяется 32 двоичных разряда. Данный режим также носит название полноцветного.
Кодирование звуковой информации.
В настоящий момент не существует единой стандартной системы кодирования звуковой информации, так как приемы и методы работы со звуковой информацией начали развиваться по сравнению с методами работы с другими видами информации самыми последними. Поэтому множество различных компаний, которые работают в области кодирования информации, создали свои собственные корпоративные стандарты для звуковой информации. Но среди этих корпоративных стандартов выделяются два основных направления.
В основе метода FM (FrequencyModulation) положено утверждение о том, что теоретически любой сложный звук может быть представлен в виде разложения на последовательность простейших гармонических сигналов разных частот. Каждый из этих гармонических сигналов представляет собой правильную синусоиду и поэтому может быть описан числовыми параметрами или закодирован. Звуковые сигналы образуют непрерывный спектр. Обратное преобразование, которое необходимо для воспроизведения звука, закодированного числовым кодом, производится с помощью цифроаналоговых преобразователей (ЦАП). Из-за таких преобразований звуковых сигналов возникают потери информации, которые связаны с методом кодирования, поэтому качество звукозаписи с помощью метода FM обычно получается недостаточно удовлетворительным. Этот метод широко использовался в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
Основная идея метода таблично-волнового синтеза (Wave-Table) состоит в том, что в заранее подготовленных таблицах находятся образцы звуков для множества различных музыкальных инструментов. Данные звуковые образцы носят название сэмплов. Числовые коды, которые заложены в сэмпле, выражают такие его характеристики, как тип инструмента, номер его модели, высоту тона и тд. Поскольку для образцов применяются реальные звуки, то качество закодированной звуковой информации получается очень высоким и приближается к звучанию реальных музыкальных инструментов, что в большей степени соответствует нынешнему уровню развития современной компьютерной техники.
Множество кодов очень прочно вошло в нашу жизнь.
●числовая информация кодируется арабскими, римскими цифрами и др.
●для общения и письма мы используем код — русский язык, в Китае — китайский и т.д.
●с помощью нотных знаков кодируется любое музыкальное произведение, а на экране проигрывателя вы можете увидеть громкий или тихий звук, закодированный с помощью графика.
●часто бывает так, что информацию надо сжать и представить в краткой, но понятной форме. Тогда применяют пиктограммы, например, на двери магазина, на столбах в парке, на дороге.
Для передачи информации, людьми были придуманы специальные коды, к ним относятся:
Универсальное двоичное кодирование. Равномерные и неравномерные коды.
Урок 9. Информатика 7 класс (ФГОС)

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности



Конспект урока «Универсальное двоичное кодирование. Равномерные и неравномерные коды.»
На прошлом уроке мы узнали:
· Для удобства хранения и передачи информации её часто переводят из непрерывной формы в дискретную. Такой процесс называется дискретизацией.
· В процессе дискретизации информация записывается на одном из языков.
· Алфавитом языка называются все существующие символы, которые используются для представления информации на этом языке.
· Алфавит характеризуется своей мощностью, это количество символов, которые в него входят.
· Двоичный алфавит состоит из двух символов. Запись информации с помощью такого алфавита называется двоичным кодированием.
· Двоичный код – это код информации, получившийся в результате её двоичного кодирования.
· Любой алфавит можно привести к двоичному.
· Двоичное кодирование звука.
· Двоичное кодирование изображения.
· Равномерный и неравномерный коды.
· Двоичное кодирование текстовых сообщений методом Хаффмана.
Итак, на прошлом уроке мы узнали, что любой алфавит можно представить в виде двоичного, для этого каждому символу исходного алфавита присваивается его двоичный код. Записывая подряд двоичные коды всех символов, мы можем кодировать текстовые сообщения. Ещё мы узнали, что двоичный алфавит легко реализовать технически, с помощью наличия или отсутствия электрического сигнала на некотором участке электрической цепи. Именно поэтому любая информация на компьютере представлена в виде двоичного кода. Однако мы знаем, что на компьютере может храниться любая информация, а не только текстовая или числовая. Как же её представить в виде двоичного кода? Например звук и изображение. Как мы знаем, они представляются в виде непрерывных сигналов, разберёмся как же представить эти два вида информации в дискретной форме.
Начнём с изображения. Вполне логично, что любое изображение можно разделить на некоторые участки, каждый из которых имеет свой цвет. Именно так происходит при представлении изображений на компьютере. Изображение разбивается на маленькие фрагменты, которые можно назвать точками. Каждое изображение имеет своё разрешение. Оно состоит из двух цифр, которые разделяются крестиком или двоеточием. Число слева, означает, на сколько точек делится изображение по горизонтали, а справа – на сколько по вертикали. Таким образом изображение на компьютере представляется в виде последовательности точек, каждая из которых имеет свой цвет. То есть изображение на компьютере можно представить, последовательно записав цвета всех точек, которые в него входят.
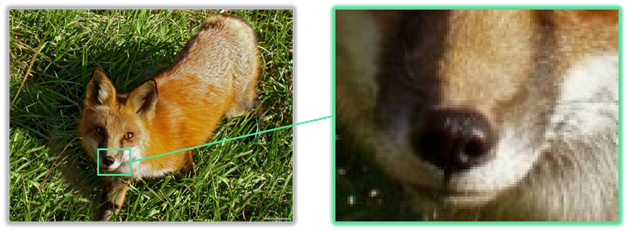
Но как же представить цвет в виде двоичных кодов? Любой цвет на мониторе компьютера изображается смешиванием в разных количествах трёх основных цветов: красного, зелёного и синего. Такое представление цветов называется их RGB-моделью. По первым буквам названий основных цветов на английском языке, то есть «Rad», «Green» и «Blue». Так, как остальные цвета – это смеси трёх основных цветов в разных количествах, их можно представить в виде трёх чисел, количеств основных цветов. Эти числа можно заменить двоичными кодами одинаковой разрядности. Записав эти коды последовательно, мы получим двоичный код цвета точки. Таким образом изображение на компьютере представляется в виде списка двоичных кодов одинаковой разрядности, каждый из которых обозначает цвет одной из точек изображения.
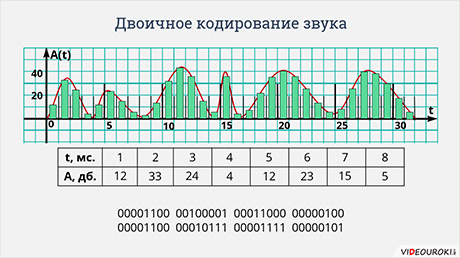
Немного иначе происходит двоичное кодирование звука. Позже из курса физики вы узнаете, что любой звук можно представить в виде непрерывной волны. Эту волну можно описать, зависимостью её амплитуды, то есть громкости звука от времени. Такую зависимость легко изобразить в виде графика. Чтобы представить звук в виде дискретных сигналов, время, в течение которого продолжается звук, делится на равные небольшие промежутки. И на каждом из промежутков заново определяется амплитуда волны, то есть громкость звука.
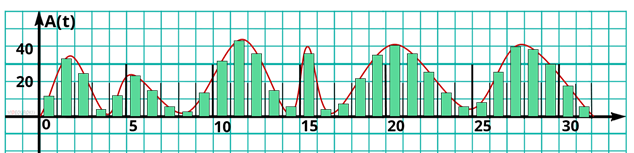
То, есть звук можно представить в виде списка чисел, каждое из которых означает амплитуду волны, в течение небольшого промежутка времени. Эти числа можно представить в виде двоичных кодов с одинаковым количеством разрядов. Таким образом звук на компьютере представляется в виде списка двоичных кодов одинаковой разрядности, каждый из которых обозначает амплитуду звуковой волны на некотором небольшом промежутке времени.
Мы знаем, что с помощью двоичного кодирования в виде последовательности единиц и нулей можно представить любую информацию на естественном или формальном языке, в том числе изображение и звук. То есть информацию из любой формы можно представить в виде двоичного кода, что означает универсальность двоичного кодирования. Это и есть его главное преимущество. Главный недостаток двоичного кодирования – это большой размер двоичного кода. Так при кодировании текстового сообщения одному символу текста может соответствовать несколько символов двоичного кода.
Давайте подумаем, как можно уменьшить размер двоичного кода, и вообще любого кода. До этого все двоичные коды, которые мы рассматривали, были равномерными. Равномерным называется код, который состоит из равных по количеству разрядов кодовых комбинаций. Так например при кодировании алфавита для каждой буквы мы использовали двоичные коды с одинаковым количеством разрядов. Однако не все символы алфавита в текстовом сообщении, встречаются одинаково часто. Поэтому, для того, чтобы сократить длину двоичного кода мы можем присвоить разным сигналам коды разной длины. Коды с меньшей разрядностью можно присвоить сигналам, которые в сообщении встречаются чаще, а коды с большей разрядностью – сигналам, которые встречаются в сообщении реже. Такой код называется неравномерным, то есть он состоит из комбинаций различной длины.
Пример неравномерного кода – азбука Морзе. В ней разным буквам алфавита, соответствует разное количество сигналов, длинных и коротких. Например буква «А» обозначается всего двумя сигналами: одним коротким и одним длинным. А твёрдый знак кодируется пятью сигналами: двумя длинными, одним коротким и двумя длинными.
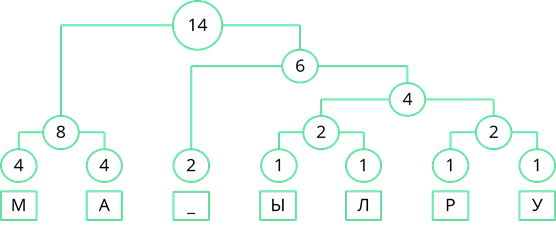
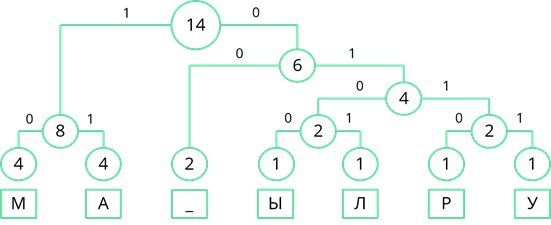
Рассмотрим один из методов неравномерного кодирования текстовых сообщений. Он называется методом Хаффмана. Посмотрим, как работает этот метод, закодировав с его помощью сообщение: «МАМА МЫЛА РАМУ». Сначала выпишем все символы алфавита, который используется в сообщении. В данном сообщении используются символы: «М», «А», пробел, «Ы», «Л», «Р» и «У». Затем нужно записать, как часто в сообщении встречается каждый из символов. Буквы «М» и «А» повторяются по четыре раза. Пробел повторяется дважды. Буквы «Ы», «Л», «Р» и «У» в сообщении встречаются по одному разу. Затем символы сообщения записываются в порядке убывания частоты появления. У нас они так и записаны.
Теперь строится дерево частоты появления символов в сообщении. В начале берутся два символа, которые встречаются в сообщении реже всех. У нас таких символа четыре, возьмём два правых, буквы «Р» и «У», соединяем их линией, и складываем их частоту появления в сообщении. 1 + 1 = 2.

Теперь повторим то же действие. Реже всех у нас появлялись буквы «Ы» и «Л». Соединим их линиями сложив частоту появления получим 2.
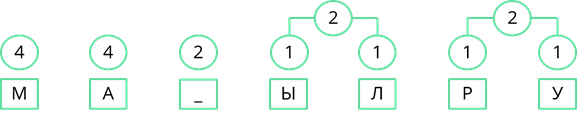
Теперь снова смотрим где у нас самая маленькая частота появления. Таких частот у нас три. Пробел появлялся дважды, двум равны и общие частоты появления символов «Ы» и «Л», и символов «Р» и «У». Возьмём две правые частоты и объединим их. Их суммарная частота равна 4.
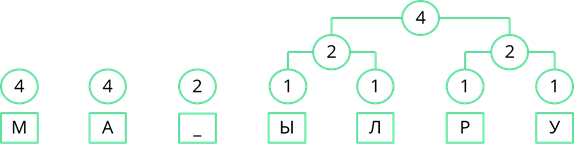
Снова ищем минимальные частоты появления. Возьмём две правые частоты и объединим их. Их сумма равна 6.
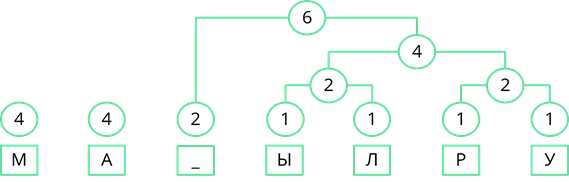
Теперь объединим две левые частоты. Их сумма равна 8.
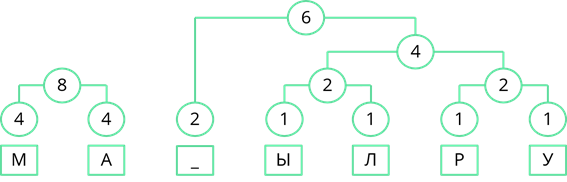
Объединим две оставшиеся частоты. Их сумма равна 14. Именно четырнадцати равна длина кодируемого сообщения.
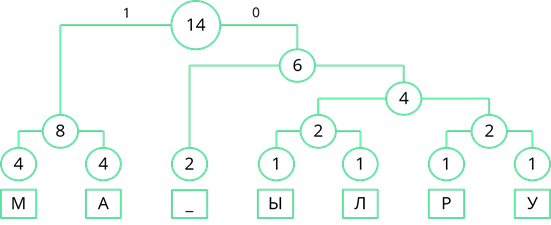
Теперь двигаясь, сверху вниз присвоим ветвям дерева значения 0 и 1. Ветви, с большей частотой будем присваивать 1, а ветви с меньшей частотой – 0. Так левой ветви верхнего узла присвоим 1, а правой – 0.
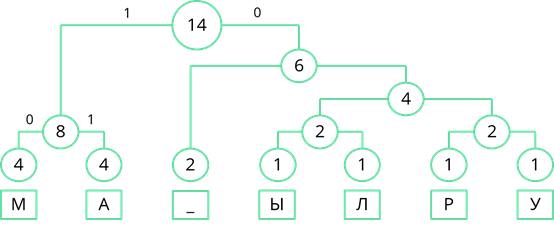
Затем рассмотрим левый узел. Там две частоты равны. Поэтому левой ветви присвоим 0, а правой – 1.
Рассмотрим узел, частота которого равна 6. Частота появления пробела меньше суммарной частоты правой ветви. Поэтому левой ветви присвоим 0, а правой ветви – 1.
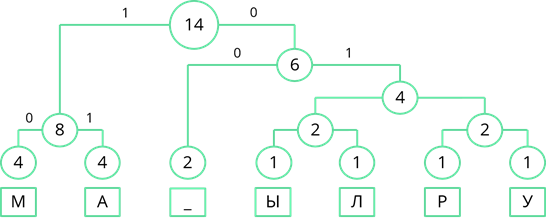
По такому же принципу пронумеруем оставшиеся ветви дерева.
Теперь, двигаясь по получившемуся дереву сверху вниз, мы можем записать двоичный код каждого символа. Так у буквы «М» будет код 10, у буквы «А» – 11, у пробела – 00 и т. д…
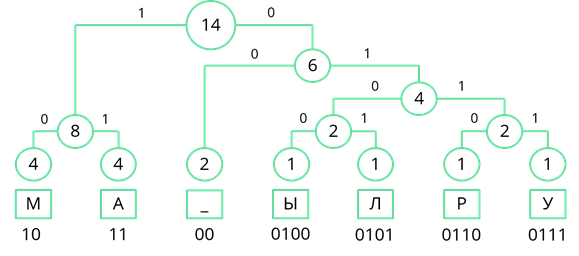
Теперь нам остаётся лишь заменить все символы в сообщении их двоичными кодами. В итоге двоичный код нашего сообщения будет 101110110010010001011100011011100111. Всего в нём 36 разрядов.
У некоторых из вас может возникнуть вопрос, а как же расшифровать такое сообщение, ведь в отличии от равномерного кода мы не знаем точно сколько разрядов занимает каждый символ. При неравномерном кодировании достаточно, чтобы код никакого из символов не начинался с кода другого символа. Давайте попробуем расшифровать первые символы нашего сообщения.
Итак, сообщение начинается с единицы. С единицы у нас начинаются двоичные коды букв «М» и «А», посмотрев на следующий символ 0, мы можем точно определить, что первый символ – это буква «М». По такому же принципу мы можем определить, что, следующий символ буква «А» и до конца расшифровать слово «МАМА».
Следующая цифра – 0. С нуля у нас начинаются коды пяти символов. После него идёт так же 0. С 00 у нас начинается код пробела. Далее идёт буква «М». Следующая цифра – 0. С нуля у нас начинаются коды 5 символов. Возьмём следующую цифру. С 01 начинаются коды четырёх символов. Следующая цифра – 0. С 010 начинаются коды двух символов. Следующий символ – снова 0. И мы можем однозначно определить, что это буква «Ы». Так же расшифровывается и остальное сообщение.
Давайте посмотрим, двоичный код из скольких разрядов получился бы при использовании равномерного двоичного кодирования. Как мы помним сообщение записано с помощью алфавита мощностью 7 символов. Определим, разрядность двоичного кода, необходимую для кодирования одного символа такого алфавита. Как мы помним, для этого необходимо определить, в какую степень возвести цифру 2, чтобы получить 7. Но цифру семь мы так получить не можем, поэтому результат необходимо округлить в большую сторону. Мы можем так получить 8, для этого двойку нужно возвести в 3 степень. То есть для кодирования одного символа нам потребуется 3-разрядный двоичный код. Определим, какой код потребуется для кодирования всего сообщения, для этого нужно разрядность кода одного символа, то есть 3 умножить на длину всего сообщения, то есть 14. 3 × 14 = 42. То есть при кодировании сообщения нам потребовался бы 42-разрядный равномерный двоичный код. При использовании неравномерного кода нам потребовалось всего 36 разрядов, то есть на 6 разрядов меньше.
Сокращение длины двоичного кода заметно даже при небольшой длине сообщения. Если длина сообщения будет больше, например десятки тысяч символов, разница между длинами равномерного и неравномерного кода тоже увеличится. Когда длина двоичного кода составляет миллиарды разрядов – разница между равномерным и неравномерным кодом просто огромна.
· Универсальность двоичного кодирования означает, что его можно применять для кодирования информации на любом формальном или неформальном языке, а также изображений и звука.
· Все коды можно разделить на равномерные и неравномерные, где равномерный код состоит из комбинаций равной длины, а неравномерный код состоит из комбинаций разной длины.
· Использование неравномерного кодирования позволяет сократить длину кода.



