Реляционные базы данных для чайников
Как правило, любое веб приложение можно разделить на 2 основные части: фронт-энд, где отображается вся информация сайта, и бэк-энд, где данная информация формируется и размещается. В этой статье мы поговорим о том, что такое реляционные базы данных, и как их проектировать.
База данных хранит записи в специально организованном виде, чтобы информацию можно было легко найти и извлечь. Любая БД состоит из одной или нескольких таблиц. Электронная таблица состоит из строк и столбцов. Все строки имеют одинаковые столбцы, а каждый столбец содержит данные. В общем, для лучшего понимания, определимся, что таблицы в БД очень похожи на те, что вы видели в Excel-е.

Табличные данные могут быть вставлены, восстановлены, обновлены и удалены. Для пакета этих операций была создана специальная аббревиатура CRUD (Create-Read-Update-Delete).
Но всё это всего лишь слова. Для того чтобы действительно понять, что такое реляционные базы данных, вам нужно больше практиковаться. Давайте же начнём и посмотрим, с какими данными нам предстоит работать.
Шаг 1. Подготовка данных
Для того чтобы нам было с чем работать, я набрал в твиттере запрос “#databases” и сформировал таблицу из 10 записей:
Таблица 1
| full_name | username | text | created_at | following_username |
|---|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 | Scootmedia, MetiersInternet |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 | klout, zillow |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 | DayJobDoc, byosko |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 | CindyCrawford, Arjantim |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 | MichaelDell, Yahoo |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 | MichaelDell, Yahoo |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 | RealSkipBayless, stephenasmith |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 | RealSkipBayless, stephenasmith |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 | dellock6, rohitkilam |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 | drsql, steam_games |
В первую очередь, давайте разберёмся с колонками:
Это реальные данные. Если хотите, вы можете их найти и обновить.
Хорошо. Теперь все наши данные находятся в одном месте. Даёт ли это нам возможность легко осуществить поиск по ним? Не совсем. Данная таблица далека от идеала. Во-первых, в некоторых столбцах у нас есть повторяющиеся записи: к примеру, в х “username” и “following_username”. Также колонка “following_username” нарушает правила реляционных моделей, т.к. её в ячейках присутствует более 1 значения (записи разделены запятыми).
К тому же у нас попадаются дубликаты и в строках.
Повторяющиеся данные действительно являются проблемой, т.к. они затрудняют процесс CRUD. К примеру, при поиске по данной таблице на обработку дубликатов будет уходить дополнительное время. К тому же, если пользователь обновит твитт, то нам нужно будет перезаписать все дубликаты.
Шаг 2. Избавляемся от дубликатов в столбцах

Поскольку @Brett_Englebert подписан на @RealSkipBayless, то в таблице “following” отобразим это следующим образом: имя @Brett_Englebert поместим в колонку “from_user”, а @RealSkipBayless в “to_user.” Давайте посмотрим, как будет выглядеть таблица “following” после разделения Таблицы 1:
Таблица 2. following
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | klout |
| GunnarSvalander | zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | CindyCrawford |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3. users
| full_name | username | text | created_at |
|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Основатель теории реляционных баз данных, Эдгар Кодд, назвал бы этот процесс (удаления повторений из столбцов таблиц) приведением БД к первой нормальной форме.
Шаг 3. Удаление повторений из строк
Теперь мы займёмся устранением других проблем, а именно, избавимся от дубликатов в строках таблицы “users”. Поскольку пользователи @AndyRyder5 и @Brett_Englebert разместили по несколько твиттов, то их имена в таблице “users” (Таблица 3) дублируются в колонке full_name. Данная проблема также решается разделением таблицы “users”.

Поскольку текст твитта и время его создания являются уникальными данными, то их мы поместим в одну и ту же таблицу. Также нам нужно указать связь между твитами и пользователями. Для этого я создал специальный столбец username.
Таблица 4. tweets
| username | text | created_at |
|---|---|---|
| _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Таблица 5. users
| full_name | username |
|---|---|
| Boris Hadjur | _DreamLead |
| Gunnar Svalander | GunnarSvalander |
| GE Software | GEsoftware |
| Adrian Burch | adrianburch |
| Andy Ryder | AndyRyder5 |
| Brett Englebert | Brett_Englebert |
| Nimbus Data Systems | NimbusData |
| SSWUG.ORG | SSWUGorg |
После разделения в таблице users (Таблица 5) у нас присутствуют уникальные (не повторяющиеся) строки.
Данный процесс удаления дубликатов из строк называется приведением ко второй нормальной форме.
Шаг 4. Объединяем таблицы на основе ключей
Итак, в результате наших действий, Таблица 1 была разбита на 3 части: following (Таблица 2), tweets (Таблица 4), users (Таблица 5). Все дубликаты устранены. Для того чтобы в дальнейшем мы могли с лёгкостью извлекать данные из этой структуры, независимые друг от друга таблицы мы должны связать специальными отношениями, которые будут давать нам информацию о том, какому пользователю принадлежит какой твит, и кто на кого подписан.
Для создания связей между записями нам необходимо ввести уникальный идентификатор, который называется первичный ключ.
Вообще говоря, в Таблице 4 и 5 мы уже это сделали. В таблице “users” первичным ключом является колонка “username”, потому что логин пользователя должен быть уникальным значением и не может повторяться. В таблице “tweets” мы используем данный ключ для обозначения связи между пользователем и твитом. Колонка “username” в таблице “tweets” называется внешним ключом.
Если вы когда-то работали с базами данных, то у вас может возникнуть вопрос: можем ли мы использовать колонку “username” в качестве первичного ключа?
С одной стороны, это может упростить процесс поиска, ведь мы не используем никаких числовых ID. С другой стороны, что если пользователь захочет поменять свой логин? Это может привести к огромному количеству проблем. Для того чтобы не попасть в подобную ситуацию, лучше воспользоваться числовыми ID. Всё зависит от вашей системы. Если вы предоставляете вашим пользователям возможность менять логины, то лучше в качестве первичного ключа использовать автоинкрементированное числовое поле ID. В противном случае, колонка “username” вполне подойдёт для этой роли. Я оставлю всё как есть.
Давайте посмотрим на таблицу tweets (Таблица 4). Первичный ключ должен быть уникальным для каждой строки. Какую колонку в данной таблице мы можем выбрать для этой роли? Колонка “created_at” не подойдёт, т.к. в принципе 2 разных пользователя могут в одно и то же время опубликовать запись. С колонкой “text” та же история: два разных пользователя могут создать твит с текстом “Hello World”. Колонка “username” в данной таблице является внешним ключом для обозначения связи между пользователем и твитом. Итак, поскольку все возможные варианты нам не подходят, то лучшим решением будет добавление колонки id, которая будет первичным ключом для данной таблицы.
Таблица 6. tweets с колонкой id
| ID | username | text | created_at |
|---|---|---|---|
| 1 | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| 2 | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| 3 | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| 4 | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| 5 | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| 6 | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| 7 | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| 8 | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| 9 | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| 10 | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
С таблицей following можем сделать то же самое, т.к. ни одна существующая колонка не подойдёт на роль первичного ключа. Колонки “from_user” и “to_user” являются внешними ключами и обозначают связь между подписками пользователей.
Итак, к этому моменту мы уже много чего сделали. Избавились от дублирующей информации в колонках и строках и выбрали для наших таблиц подходящие колонки на роль первичных и внешних ключей для обозначения зависимостей между данными. Данный процесс называется нормализацией и предназначен для приведения ваших таблиц под реляционную модель. Благодаря нормализации мы можем более простым образом реализовывать операции CRUD.
Ниже вы можете увидеть схему наших таблиц и связей между ними:

Системы Управления Базами Данных
Теперь, когда у нас есть реляционная БД, каким образом мы можем её имплементировать? Для этого мы можем воспользоваться системами управления базами данных (СУБД). Существует целый набор подобных программ, как платных, так и бесплатных. Среди платных можно выделить Oracle Database, IBM DB2 и Microsoft SQL Server. Бесплатные: MySQL, SQLite и PostgreSQL.
SQLite чаще используется при разработке приложений для iOS и Android, где хранится различного рода конфиденциальная информация. Браузер Google Chrome использует SQLite для хранения истории просмотров, кукисов, изображений.
PostgreSQL используется реже. Для неё существует полезное расширение PostGIS, которое делает данную СУБД удобной для хранения геолокационных данных. К примеру сервис OpenStreetMap исользует PostgreSQL.
Язык структурированных запросов (SQL)
После того, как вы выбрали подходящую для вас СУБД и установили её, следующим шагом было бы создание таблиц и управление данными. Для этого мы можем воспользоваться специальным языком SQL.
Создание БД development:
Создание таблицы Users:
При создании полей нам необходимо указать тип хранимой информации и её размер. Колонки “full_name” и “username” будут типа VARCHAR, который предназначен для хранения строк символов. Размер 100 символов. Список всех типов вы можете найти тут.
Извлечение всех записей пользователя _DreamLead:
SQL очень похож на человеческий язык (английский). В каждом СУБД SQL обладает рядом собственных особенностей и различий, но в целом, все разновидности SQL похожи друг на друга.
В этом уроке мы разобрали процесс создания реляционной БД, взяли набор данных и распределили их по таблицам, согласно реляционной модели. Также мы быстро пробежались по существующим СУБД и языку SQL.
Данный урок подготовлен для вас командой сайта ruseller.com
Источник урока: http://net.tutsplus.com/tutorials/tools-and-tips/relational-databases-for-dummies/
Перевел: Станислав Протасевич
Урок создан: 16 Марта 2013
Просмотров: 93095
Правила перепечатки
5 последних уроков рубрики «Разное»
Как выбрать хороший хостинг для своего сайта?
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.

Разработка веб-сайтов с помощью онлайн платформы Wrike

20 ресурсов для прототипирования
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.

Топ 10 бесплатных хостингов
Небольшая подборка провайдеров бесплатного хостинга с подробным описанием.
Особенности реляционных БД
БД используются для организации хранения данных. Структура реляционной базы данных полностью определяется перечнем названия полей с указанием их типов и свойств. Все записи имеют одинаковые поля, но в них показываются разные свойства объекта. Аналогом реляционной БД считается двумерная таблица. Характерные особенности файла БД:
Реляционная БД чаще всего не ограничивается одной таблицей. Обычно создаются несколько таблиц со связанной информацией. Это позволяет исполнять более сложные операции над данными. Таблицы реляционной БД обязаны соответствовать требованиям понятия нормализации отношений, то есть ограничениям на формирование, которые позволят избежать дублирования и обеспечат непротиворечивость хранимой информации. Пусть создана таблица «Прокат», содержащая следующие поля: Шифр Клиента, Ф. И. О., Вид устройства, Дата выдачи, Оплата, Срок возврата. Эта организация хранения информации имеет несколько недостатков:
Для устранения этих недостатков необходима нормализация с разделением данных на разные таблицы.
Связывание таблиц
Для любой таблицы реляционной БД задаётся первичный ключ (primary key) — поле или сочетание полей, которые определяют каждую запись. Внешний или вторичный ключ (foreign key) — это одно или несколько полей, ссылающихся на поле primary key другой таблицы.

Составной ключ называется так, потому что создаётся из нескольких полей. При образовании составных ключей не рекомендуется включать в них поля, значения которых точно определяют запись. Например, не следует образовывать ключ, в котором находятся вместе поля «номер паспорта» и «шифр клиента», потому что оба эти атрибута однозначно определяют запись. Поля с повторяющимися в таблице значениями тоже нельзя делать составной частью ключа. По значению ключа возможно найти только одну запись.
Ячейка — это наименьший структурный элемент, который задаёт определённое значение соответствующего поля. Таблицы связываются друг с другом, и поэтому данные могут выбираться сразу из нескольких таблиц. Связь создаётся, если в них присутствуют одинаковые поля. Типы связей:
Связи «один к одному» встречаются довольно редко. «Один ко многим» применяются чаще, например, кассир продаёт много билетов. «Многие ко многим» тоже встречаются часто. Например, студент изучает много предметов. Связи «многие ко многим» нельзя организовывать непосредственно. Для установления отношения необходимо сопоставить каждому primary key внешний ключ, который представляет собой primary key другой таблицы. Реляционные системы базируются на теории реляционной модели, которая включает в себя три аспекта:
Управление созданием и использованием БД осуществляется системами управления базами данных (СУБД).
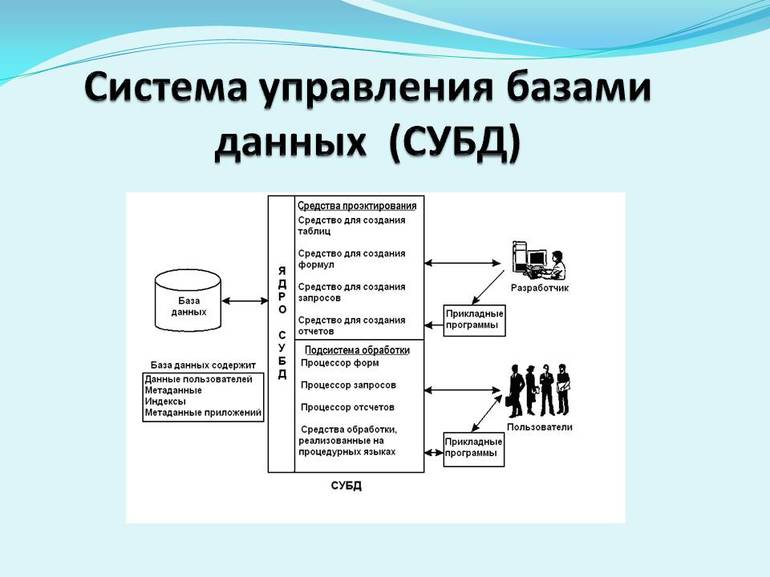
Под их руководством:
Для проведения этих операций организуются запросы. Итогом выполнения запросов будут либо изменения в таблицах, либо получение таблицы данных. При этом поддерживается принцип безопасности информации. Для реляционной БД основным языком управления является SQL.
Стадии и пример проектирования хранилища
Приступая к созданию базы, разработчик составляет для объектов манипулирования и их связей представление в терминах реляционной БД (таблицы, поля, записи). Проектирование проходит несколько стадий:

Преимущества этой модели данных состоят в том, что информация отображается в удобной для пользователя форме, а для манипуляций используется развитой математический аппарат.
Примером реляционной базы данных может послужить проект оптимизации деятельности пункта проката. Требуется автоматизировать такие процедуры: учёт клиентов; регистрацию инвентаря, выданного в прокат; отслеживание даты выдачи, сроков возврата, оплаты; получение информации по этим позициям; формирование отчёта по задолженностям. Реляционная БД может быть задана в виде трёх связанных таблиц.
Используя имеющиеся данные, следует определить отношения и объекты этих отношений. Объектами будут являться клиенты и устройства. Отношения между ними состоят в том, что каждый клиент может брать в прокат одно или несколько устройств.
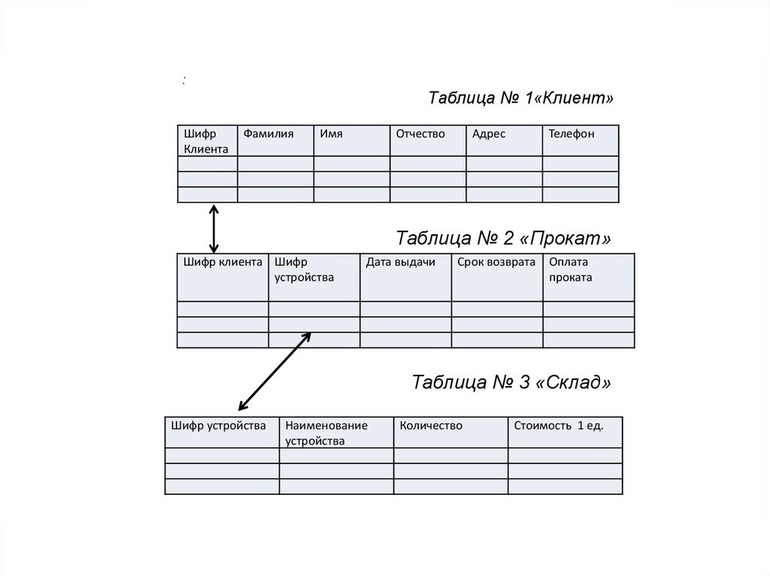
Атрибутами для сопоставления объектов друг другу должны выступать ячейки с уникальным содержимым. В таблицах есть по одному полю с уникальными данными. В № 1 «Клиент» — это шифр клиента, а в № 3 «Склад» — шифр устройства. Это и будут primary keys. Каждая строка таблицы «Прокат» будет связывать два внешних ключа между собой:
Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.

Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.



