Что такое репликация баз данных
Репликация (replication) — механизм синхронизации содержимого нескольких копий объекта (например, содержимого базы данных). Репликация — это процесс, под которым понимается копирование данных из одного источника на множество других и наоборот. При репликации изменения, сделанные в одной копии объекта, могут быть распространены в другие копии.
Рассмотрим кратко проблему согласованности (или, скорее, несогласованности). Дело в том, что реплики могут становиться несовместимыми в результате ситуаций, которые трудно (или даже невозможно) избежать и последствия которых трудно исправить. В частности, конфликты могут возникать по поводу того, в каком порядке должны применяться обновления. Например, предположим, что в результате выполнения транзакции А происходит вставка строки в реплику X, после чего транзакция B удаляет эту строку, а также допустим, что Y — реплика X. Если обновления распространяются на Y, но вводятся в реплику Y в обратном порядке (например, из-за разных задержек при передаче), то транзакция B не находит в Y строку, подлежащую удалению, и не выполняет своё действие, после чего транзакция А вставляет эту строку. Суммарный эффект состоит в том, что реплика Y содержит указанную строку, а реплика X — нет. В целом задачи устранения конфликтных ситуаций и обеспечения согласованности реплик являются весьма сложными. Следует отметить, что, по крайней мере, в сообществе пользователей коммерческих баз данных термин репликация стал означать преимущественно (или даже исключительно) асинхронную репликацию.
Шардинг и репликация



Масштабирование баз данных — самая сложная задача во время роста проекта. 90% всех усилий обычно приходится как раз на работу, связанную с ростом объема данных и операций с ними. Классическая схема работы приложения с базой данных выглядит так: 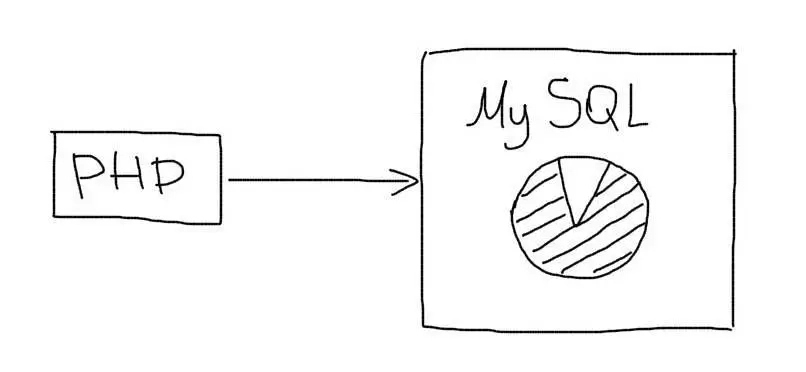
Один сервер базы данных в какой-то момент перестает справляться с нагрузкой. В этот момент и следует применять описанные тут техники масштабирования.
Перед тем, как приступать к масштабированию, необходимо провести анализ медленных запросов и убедиться, что сервер MySQL настроен оптимально.
Стратегии
В основе масштабирования данных лежит тот же принцип, что и в основе масштабирования Web приложений. Это разделение данных на группы и выделение их на отдельные сервера. Существует две основные стратегии — репликация и шардинг.
Репликация
Репликация позволяет создать полный дубликат базы данных. Так, вместо одного сервера у Вас их будет несколько: 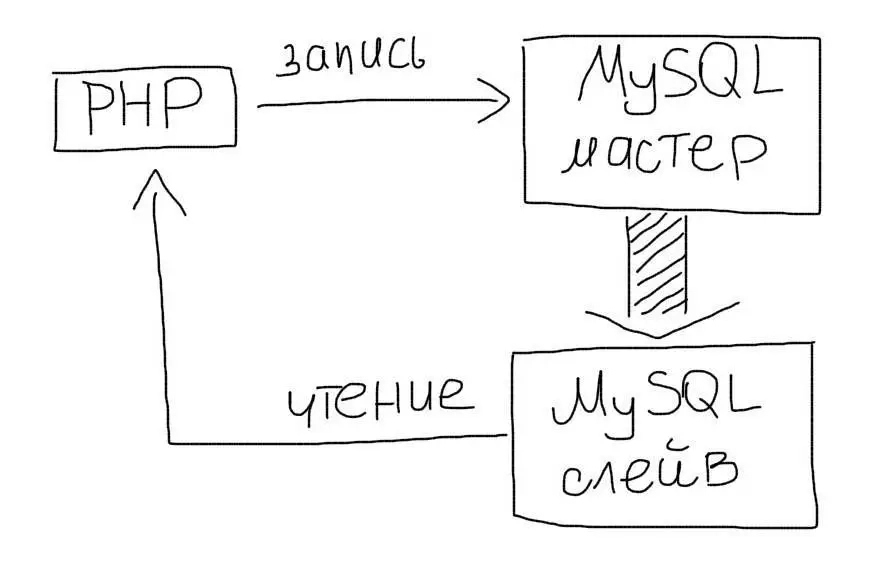
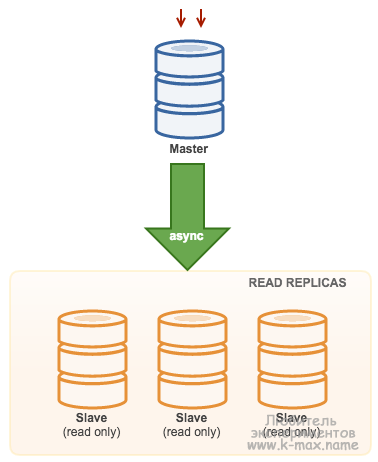
Master-slave
Чаще всего используют схему master-slave:
Репликация позволяет использовать два или больше одинаковых серверов вместо одного. Операций чтения (SELECT) данных часто намного больше, чем операций изменения данных (INSERT/UPDATE). Поэтому, репликация позволяет разгрузить основной сервер за счет переноса операций чтения на слейв.
Работа из приложения
В приложении у Вас будет два соединения с базой данных. Одно — для мастера и одно для слейва:
При выполнении запросов необходимо использовать соответствующее соединение
Репликация обычно поддерживается самой СУБД (например, MySQL) и настраивается независимо от приложения.
Читайте детальнее про настройку, использование и типы репликации данных на примере MySQL.
Следует отметить, что репликация сама по себе не очень удобный механизм масштабирования. Причиной тому — рассинхронизация данных и задержки в копировании с мастера на слейв. Зато это отличное средство для обеспечения отказоустойчивости. Вы всегда можете переключиться на слейв, если мастер ломается и наоборот. Чаще всего репликация используется совместно с шардингом именно из соображений надежности.
Шардинг (sharding)
Шардинг (иногда шардирование) — это другая техника масштабирования работы с данными. Суть его в разделении (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер. Этот процесс зависит от структуры Вашей базы данных и выполняется прямо в приложении в отличие от репликации: 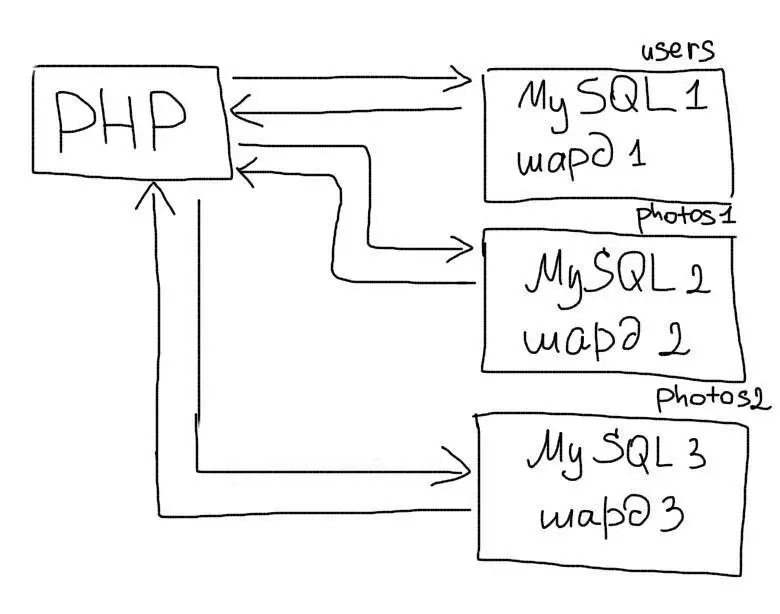
Вертикальный шардинг
Вертикальный шардинг — это выделение таблицы или группы таблиц на отдельный сервер. Например, в приложении есть такие таблицы:
Таблицу users Вы оставляете на одном сервере, а таблицы photos и albums переносите на другой. В таком случае в приложении Вам необходимо будет использовать соответствующее соединение для работы с каждой таблицей:
Для каждой таблицы или группы таблиц будет отдельное соединение
В отличие от репликации, мы используем разные соединения для любых операций, но с определенными таблицами. Читайте подробнее об использовании вертикального шардинга на практике.
Горизонтальный шардинг
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере. Разделение таблицы на куски делается по такому принципу:
Допустим, наше приложение работает с огромной таблицей, которая хранит фотографии пользователей. Мы подготовили два сервера (обычно они называются шардами) для этой таблицы. Для нечетных пользователей мы будем работать с первыми сервером, а для четных — со вторым. Таким образом, на каждом из серверов будет только часть всех данных о фотках пользователей. Это будет выглядеть так:
Перед обращением к таблице, мы выбираем нужное нам соединение
Горизонтальный шардинг — это очень мощный инструмент масштабирования данных. Но в то же время и очень нетривиальный. Читайте детально об использовании горизонтального шардинга на практике.
Не следует применять технику шардинга ко всем таблицам. Правильный подход — это поэтапный процесс разделения растущих таблиц. Следует задумываться о горизонтальном шардинге, когда количество записей в одной таблице переходит за пределы от нескольких десятков миллионов до сотен миллионов.
Совместное использование
Шардинг и репликация часто используются совместно. В нашем примере, мы могли бы использовать по два сервера на каждый шард таблицы:
Тогда в приложении работа с этой табличкой может выглядеть так:
Читаем данные со слейвов, а записываем на мастер-сервера
Такая схема часто используется не для масштабирования, а для обеспечения отказоустойчивости. Так, при выходе из строя одного из серверов шарда, всегда будет запасной.
Key-value базы данных
Следует отметить, что большинство [p165 Key-value баз данных] поддерживает шардинг на уровне платформы. Например, Memcache. В таком случае, Вы просто указываете набор серверов для соединения, а платформа сделает все остальное:
Мемкеш сам умеет определять нужный сервер для каждого ключа
Самое важное
Шардинг и репликация — это популярные и мощные техники масштабирования систем работы с данными. Несмотря на примеры для MySQL, эти подходы универсальны и могут применяться для любой технологии.
Помните, процесс масштабирования данных — это архитектурное решение, оно не связано с конкретной технологией. Не делайте ошибок наших отцов — не переезжайте с известной Вам технологии на новую из-за поддержки или не поддержки шардинга. Проблемы обычно связаны с архитектурой, а не конкретной базой данных.
Этот текст был написан несколько лет назад. С тех пор упомянутые здесь инструменты и софт могли получить обновления. Пожалуйста, проверяйте их актуальность.
Что такое индексы в Mysql и как их использовать для оптимизации запросов
Как исправить ошибку доступа к базе 1045 Access denied for user
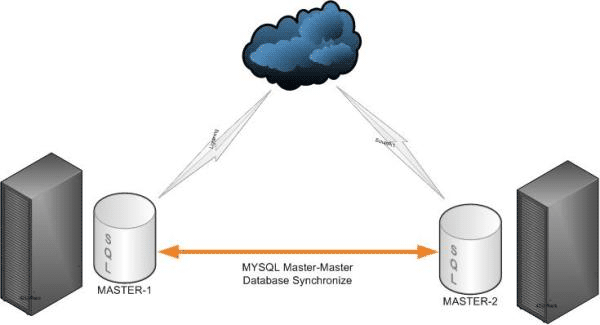
Настройка Master-Master репликации на MySQL за 6 шагов
Примеры ad-hoc запросов и технологии для их исполнения
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Как создать и использовать составной индекс в Mysql
Типы и способы применения репликации на примере MySQL
Синтаксис и оптимизация Mysql LIMIT
Настройка Master-Slave репликации на MySQL за 6 простых шагов
Правильная настройка Mysql под нагрузки и не только. Обновлено.
И как правильно работать с длительными соединениями в MySQL
Check-unused-keys для определения неиспользуемых индексов в базе данных
Запрос для определения версии Mysql: SELECT version()
3 примера установки индексов в JOIN запросах
Анализ медленных запросов с помощью EXPLAIN
Что значит и как это починить
Описание, рекомендации и значение параметра query_cache_size
Быстрый подсчет уникальных значений за разные периоды времени
Использование партиций для ускорения сложных удалений
Правила выбора типов данных для максимальной производительности в Mysql
Включение и использование логов ошибок, запросов и медленных запросов, бинарного лога для проверки работы MySQL
Блог о системном администрировании. Статьи о Linux, Windows, СХД NetApp и виртуализации.

Всем привет. Давненько я не писал. Сегодня будет лонгрид. Некоторое время назад стояла задача развернуть несколько серверов Mysql в конфигурации с репликацией базы данных и описать весь процесс. Данная инсталляция легла в основу статьи. Статья написана на основе официальной документации Mysql. По большей части, является структурированным переводом. Любые дополнения приветствуются. Поехали.
Введение в репликацию Mysql
Репликация позволяет копировать данные Вашей базы данных с одного сервера MySQL (источника) на другой сервер MySQL (реплику). По умолчанию, в MySQL репликация асинхронная. Это позволяет не держать постоянное подключение к серверу-источнику. В зависимости от конфигурации, реплицировать можно как все базы данных, так и выбранные, либо даже просто таблицы БД.
MySQL поддерживает различные методы репликации:
MySQL умеет различные типы/схемы синхронизации между источником и репликой:
Существуют три основных типа формата реплицируемых событий (переменная binlog_format ):
Каждый из данных форматов имеет свои особенности, недостатки и достоинства. Эта тема для отдельной статьи.
Обзор репликации бинарного лога (Binary Log File Position Based Replication)
При данном методе репликации, экземпляр MySQL, как источник (он же source он же master) (на котором происходит изменение базы данных), записывает обновления/изменения БД (запросы) в бинарный лог. Обычно, этот лог размещен в том же каталоге, что и базы данных. А серверы-реплики (slave серверы) настроены таким образом, что читают бинарный лог с мастера и выполняют на своей базе данных те же самые запросы, которые выполнились на мастере.
Каждая реплика получает полную копию бинарного лога и именно реплика отвечает за то, чтобы выполнить все (или не все, а только не/отфильтрованные или только для заданных таблиц/БД) запросы из полученного лог-файла.
Slave-сервер понимает откуда начать читать лог, исходя из заданных координат при настройке репликации:
Т.к. реплика хранит/сдвигает эти координаты в процессе прохождения по логу, реплика в любой момент может быть отключена от мастера и подключена снова. При этом, обработка лога продолжится с места на котором произошла остановка.
Резюмируя вышесказанное, а именно, наличие координат и возможность фильтровать/задавать таблицы и БД для чтения лога, позволяет подключить различные slave серверы к одному master и обрабатывать различные части исходной БД. Важно учитывать, что разработчики и приложения должны учитывать данные особенности, чтобы обеспечить консистентность данных/индексов/пр.
Обзор репликации с Глобальными Идентификаторами транзакции (Global transaction identifier (GTID) Based Replication)
стоит знать, что в новых версиях MySQL/MariaDB формат GTID изменился и упростился
Допущения в статье
Т.к. статья сконцентрирована на репликации MySQL, я опустил некоторые моменты, чтобы сделать основную тему более понятной:
Топология репликации
Настройка репликации бинарного лога (aka Master-slave)
1. Редактирование конфигов на мастер сервере и репликах
ОБЯЗАТЕЛЬНЫЕ НАСТРОЙКИ
ОПЦИОНАЛЬНЫЕ НАСТРОЙКИ
На самом деле, есть еще одна опция, которая влияет на работу источника:
2. Создание пользователя для репликации
Пример настройки сервера mysql master-slave
master1(Master/Source/10.0.2.2)
slave1(Slave/Replica/10.0.2.4)
3. Получение координат бинарного лога с Мастер сервера
Получите текущих координат бинарного лога на мастер-сервере:
Пояснения к выводу команды: поле File показывает имя файла бинарного лога (обычно, в каталоге /var/lib/mysql/), Position показывает позицию в файле. Именно эти данные нужны для реплики.
Следующие шаги зависят от того, имеете ли Вы данные в БД на сервере-источнике:
4. Перенос данных MySQL с Мастер-сервера на реплику
Итак, если сервер-источник содержит данные, их можно перенести несколькими способами:
Создание копии данных MySQL с помощью mysqldump
Создание копии данных MySQL с помощью сырых файлов
Итак, данный способ должен учитывать соблюдение дополнительных требований:
Следующие файлы не нужны для репликации и могут бы исключены:
Передача файлов на реплику
Настройка slave сервера MySQL, когда на источнике нет данных (чистый)
Повторюсь еще раз, этот метод приемлем только, если Вы устанавливаете репликацию с нового (чистого) MySQL сервера. И после запуска репликации Вы можете импортировать данные дампов в мастер. Таким образом, т.к. импорт будет осуществляться при установленной репликации, импортированные дампы будут скопированы (реплицированы) на реплику автоматически.
Список шагов следующий:
slave1(Slave/Replica/10.0.2.4)
Указывать координаты, когда настраивается репликация с чистого мастера не нужно.
master1(Master/Source/10.0.2.2)
Проверить статус репликации можно в выводе команд SHOW REPLICA STATUS\G (mysql новее 8.X) или SHOW SLAVE STATUS\G (старые версии mysql) в значениях SQL thread and replication I/O thread.
Настройка slave сервера MySQL, при существующих данных в БД
Список шагов следующий:
На что нужно обратить внимание:
slave1(Slave/Replica/10.0.2.4)
После проделанных шагов, slave сервер подключится к master серверу и начнет реплицировать любые обновления произошедшие на сервере-источнике с момента создания снапшота. ошибки репликации так же можно отслеживать в error.log MySQL сервера.
Снапшот, который мы получили с мастера может быть применен к любому количеству реплик. То есть можно настроить репликацию один-ко-многим с использованием единого дампа MySQl, просто повторив шаги данного раздела.
Добавление Slave сервера в существующее окружение репликации
Можно легко добавить новую реплику в существующую топологию репликации без остановки мастер-сервера. Для этого можно просто остановить существующую реплику, скопировать каталог данных MySQL на новый сервер и задать новый ID и UUID сервера.
Добавление нового Slave сервера в существующее окружение репликации Mysql по шагам:
Multi-source репликация MySQL/MariaDB
При настройке репликации MySQL из нескольких источников (т.н. FAN-IN репликация), Slave сервер может быть настроен несколькими способами:
Я опишу второй путь, т.к. первый не отличается от настройки обычной репликации. Итак, вспомним, что в нашей топологии есть 3 ключевых сервера:
Итак, шаги настройки такие:
slave2(Second Slave/Replica/10.0.2.5)
Репликация мастер-мастер (или круговая репликация)
master1(Master/Source/10.0.2.2)
master2(Master/Source/10.0.2.3)
Переключение сервера MySQL из режима репликации в отдельный сервер (отключение репликации MySQL)
Если установить server ID в ноль, то бинарный лог продолжит работать, но в режиме server_id = 0 сервер MySQL отбрасывает любые подключения от реплик. так же, реплика с server_id = 0 не пытается установить соединения с мастером. Стоит помнить, что этот параметр может быть изменен на работающем сервере, но изменения будут приняты только после рестарта MySQL!
Переключение мастер-сервера при отказах мастер-сервера (переключение на новый источник репликации)
Ок. Давайте посмотрим на исходную топологию репликации:
Предположим, что мастер сервер умер и недоступен. Давайте сделаем нашу реплику1 новым мастером и получим следующую топологию репликации:
Итак, давайте пройдемся по шагам:
| Действие | Replica1 | Replica2,3 |
|---|---|---|
| Убедиться, что все реплики завершили все запросы, которые получили со старого мастера | STOP REPLICA | SLAVE IO_THREAD | STOP REPLICA | SLAVE IO_THREAD |
| Проверить вывод команд на наличие сообщения Has read all relay log | SHOW PROCESSLIST | SHOW PROCESSLIST |
| Настроить новый сервер быть мастером | STOP REPLICA | SLAVE and RESET MASTER | |
| Направить реплики на нового мастера Replica1 | STOP REPLICA | SLAVE and CHANGE REPLICATION SOURCE TO SOURCE_HOST=’Replica1′ | |
| нет необходимости указывать координаты, т.к. реплики помнят, где закончилось чтение. | ||
| Запустить потоки репликации | `START REPLICA |
Рекомендации по резервному копированию в режиме MySQL репликации
Копию базы данных возможно получать как с мастер-сервера, так и с реплики. Поэтому очень часто репликацию используют для аккумулирования всех баз на одном slave сервере и в едином месте делают логические копии и архивацию.
Диагностика репликации MySQL
Полезные команды для траблшутинга MySQL
Типичные ошибки репликации (и способы устранения)
Ошибка Last_IO_Error equal MySQL server UUIDs
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
Ошибка MY-010604
Лекция 26: Репликация в Microsoft SQL Server: обзор типов репликации и репликация моментальных снимков
Технология репликации баз данных Microsoft SQL Server предназначена для того, чтобы помочь вам в распространении данных и хранимых процедур по серверам вашей компании. Репликация позволяет вам конфигурировать системы для автоматического копирования данных в другие системы. Используя репликацию баз данных, вы можете копировать столько данных, сколько вам нужно и можете размещать данные в любом количестве систем. Поскольку процесс репликации выполняется автоматически и поскольку во время репликации в базе данных сохраняется информация о состоянии репликации и реплицированных данных, то не существует никакой опасности потери данных. Если процедура репликации прервана (например, из-за отказа источника питания), то она возобновится с точки отказа, как только системы снова будут работать в обычном режиме.
Что такое репликация базы данных?
Репликация базы данных – это процесс копирования (реплицирования) данных из одной таблицы или базы данных в другую таблицу или базу данных. Используя эту технологию, вы можете распространять копии всей базы данных в несколько систем вашей компании или распространять выбранные части базы данных. При использовании технологии репликации SQL Server происходит автоматизация задачи копирования и распространения данных. После задания параметров и конфигурирования репликации никакого вмешательства пользователя уже не требуется. Поскольку репликация и обработка данных выполняется из базы данных SQL Server, это обеспечивает более высокий уровень стабильности и восстанавливаемости. Если во время репликации происходит сбой (или выполняется другая транзакция SQL Server), то после устранения соответствующей проблемы операции возобновляются с точки, где произошел сбой. В связи с этим многие люди предпочитают репликацию другим методам перемещения данных между системами.
Имеется много возможностей для конфигурирования репликации в вашей сети. Например, вы можете указывать, сколько данных будет реплицироваться. Вы можете задавать допустимый тип доступа к реплицированным копиям – только по чтению или с разрешением модифицирования. И вы можете задавать, насколько часто должны реплицироваться данные. Мы рассмотрим эти и другие параметры в разделе «Конфигурирование репликации моментальных снимков» далее и в аналогичных разделах следующих двух лекций.
Понятия репликации
В этом разделе вы узнаете о базовых понятиях репликации баз данных. Мы рассмотрим такие понятия, как метафора «опубликовать-и-подписаться» (publish-and-subscribe), три типа репликации, данные репликации, распространение данных и агенты репликации.
Компоненты репликации
Репликация в Microsoft SQL Server 2000 основывается на метафоре «опубликовать-и-подписаться», впервые использованной для репликации в SQL Server 6. Эта метафора базируется на трех основных понятиях: издатели, дистрибьюторы и подписчики. Издатель – это система базы данных, которая предоставляет данные для репликации. Дистрибьютор (распространитель) – это система базы данных, которая содержит дистрибутивную базу данных (или псевдоданные), используемую для поддержки и управления репликацией. Подписчик – это система базы данных, которая получает реплицированные данные и сохраняет их в реплицированной базе данных.
Издатели
Издатель – система Microsoft Windows 2000, содержащая базу данных SQL Server. Эта база данных содержит данные, которые должны реплицироваться в другие системы. Кроме того, база данных SQL Server следит за тем, какие данные изменились, чтобы их можно было эффективно реплицировать. Издатель также поддерживает информацию о том, какие данные сконфигурированы для репликации. В зависимости от выбранного типа репликации издатель выполняет больший или меньший объем работы во время процесса репликации. Это описывается более подробно далее.
Среда репликации может содержать несколько подписчиков, но любой заданный набор данных, сконфигурированных для репликации (этот набор называется статьей), может иметь только одного издателя. (Статьи описываются более подробно в разделе «Данные репликации» ниже в этой лекции.) То, что для определенного набора данных имеется только один издатель, не означает, что этот издатель является единственным компонентом, который может модифицировать данные: подписчик тоже может модифицировать и даже повторно публиковать данные. Однако это может потребовать некоторых усилий, как вы увидите из этой лекции и следующих двух лекций.
Дистрибьюторы
Серверы, действующие как дистрибьюторы, кроме дистрибутивной базы данных хранят также метаданные, данные журнала (истории) репликации и другую информацию. Во многих случаях дистрибьютор также управляет распространением данных репликации подписчикам. Издатель и дистрибьютор не обязательно должны быть на одном сервере. На самом деле вы, скорее всего, будете использовать для дистрибьютора выделенный сервер. Для каждого издателя при его создании должен быть задан дистрибьютор, и каждый издатель может иметь только одного дистрибьютора. (Более подробно см. в разделе «Конфигурирование публикования и распространения» далее.)
Подписчики
Как уже говорилось, подписчики – это серверы баз данных, которые хранят реплицированные данные и получают информацию об изменениях. Подписчики также могут вносить изменения и являться издателями для других систем. Чтобы подписчик получал реплицированные данные, он должен подписаться на эти данные. Подписка на репликацию подразумевает конфигурирование подписчика для получения этих данных. Подписка – это информация базы данных, на которую вы подписываетесь. (Более подробно о связях между этими компонентами см. в разделе «Конфигурирование репликации моментальных снимков» далее.)
Типы репликации
В SQL Server используется три типа репликации: репликация моментальных снимков, репликация транзакций и репликация слиянием. Эти типы репликации поддерживают различные уровни согласованности данных в реплицированной базе данных, и они налагают различные уровни нагрузки на серверы.
Репликация моментальных снимков
Репликация моментальных снимков (или просто репликация снимков) – это наиболее простой тип репликации. При использовании репликации снимков периодически создается снимок (картина) базы данных, который распространяется подписчикам. Главным преимуществом репликации снимков является то, что она не налагает непрерывной нагрузки на издателей и подписчиков. Это означает, что она не требует, чтобы издатели непрерывно следили за изменениями данных, а также не требует непрерывной передачи данных подписчикам. Главным недостатком является то, что база данных у подписчика соответствует только последнему снимку базы данных издателя.
Во многих случаях, как вы увидите позже в этой лекции, репликация снимков является вполне достаточной, например, когда источник данных модифицируется лишь время от времени. С такой информацией, как списки телефонов, списки цен и описание товаров, можно вполне справляться с помощью репликации снимков. Эти списки можно обновлять раз в день в нерабочее время.
Репликация транзакций
Репликацию транзакций можно использовать для репликации изменений, вносимых в базу данных. При использовании репликации транзакций любые изменения, вносимые в статьи (наборы данных, сконфигурированные для репликации) немедленно считываются из журнала транзакций и распространяются дистрибьюторам. Используя репликацию транзакций, вы можете поддерживать издателя и его подписчиков почти всегда в одинаковом состоянии (в зависимости от того, как вы сконфигурировали репликацию).
Репликация слиянием
Данные репликации
Вы группируете данные, подлежащие репликации, в виде объекта, который называется публикацией. Публикация состоит из одной или нескольких статей. Рассмотрим более подробно статьи и публикации.
Статьи
Как уже говорилось, статья – это отдельный набор данных, который подлежит репликации. Статья может быть целой таблицей, подмножеством таблицы, состоящим из определенных колонок или строк, или хранимой процедурой. Вы создаете эти подмножества с помощью фильтров. Фильтр, используемый для создания подмножества, состоящего из строк, называется горизонтальным фильтром. Фильтр, используемый для создания подмножества, состоящего из колонок, называется вертикальным фильтром. Более подробное описание горизонтальных и вертикальных фильтров приводится ниже в этой лекции.



