Директивы сегмантации в ассемблере
Физически сегмент представляет собой область памяти, занятую командами и (или) данными, адреса которых вычисляются относительно значения в соответствующем сегментном регистре.
Каждая программа содержит 3 типа сегментов:
Функциональное назначение сегмента несколько шире, чем простое разбиение программы на блоки кода, данных и стека. Сегментация является частью более общего механизма, связанного с концепцией модульного программирования. Она предполагает унификацию оформления объектных модулей, создаваемых компилятором, в том числе с разных языков программирования. Это позволяет объединять программы, написанные на разных языках. Именно для реализации различных вариантов такого объединения и предназначены директивы сегментации.
Упрощенные директивы сегментации
Для задания сегментов в тексте программы можно пользоваться упрощенными директивами:
Однако использование упрощенных директив сегментации не позволяет создать более трех сегментов для одной программы.
Стандартные директивы сегментации
Директива ENDS определяет конец сегмента.
Атрибут выравнивания сегмента (тип выравнивания) align сообщает компоновщику о том, что нужно обеспечить размещение начала сегмента на заданной границе. Это важно, поскольку при правильном выравнивании доступ к данным в процессорах, совместимых с базовым i8086, выполняется быстрее. Допустимые значения этого атрибута следующие:
Атрибут класса сегмента (тип класса) ‘class’ — это заключенная в кавычки строка, помогающая компоновщику определить соответствующий порядок следования сегментов при сборке программы из сегментов нескольких модулей. Компоновщик объединяет вместе в памяти все сегменты с одним и тем же именем класса (имя класса, в общем случае, может быть любым, но лучше, если оно будет отражать функциональное назначение сегмента). Типичным примером использования имени класса является объединение в группу всех сегментов кода программы (обычно для этого используется класс ‘code’ ). С помощью механизма типизации класса можно группировать также сегменты инициализированных и неинициализированных данных.
Что такое сегмент ассемблер
Справочная система по языку Assembler
Структура программы на ассемблере
Синтаксис ассемблера

Рис. 1. Формат предложения ассемблера

Рис. 2. Формат директив

Рис. 3. Формат команд и макрокоманд
Практически каждое предложение содержит описание объекта, над которым или при помощи которого выполняется некоторое действие. Эти объекты называются операндами.
Их можно определить так:
операнды — это объекты (некоторые значения, регистры или ячейки памяти), на которые действуют инструкции или директивы, либо это объекты, которые определяют или уточняют действие инструкций или директив.
Операнды могут комбинироваться с арифметическими, логическими, побитовыми и атрибутивными операторами для расчета некоторого значения или определения ячейки памяти, на которую будет воздействовать данная команда или директива.

Рис. 4. Синтаксис описания адресных операндов
Результатом вычисления выражения может быть адрес некоторой ячейки памяти или некоторое константное (абсолютное) значение.



Рис. 7. Синтаксис операторов сравнения
Таблица 1. Операторы сравнения


Рис. 9. Синтаксис индексного оператора
Заметим, что в литературе по ассемблеру принято следующее обозначение: когда в тексте речь идет о содержимом регистра, то его название берут в круглые скобки. Мы также будем придерживаться этого обозначения.
К примеру, в нашем случае запись в комментариях последнего фрагмента программы mas + (si) означает вычисление следующего выражения: значение смещения символического имени mas плюс содержимое регистра si.




Рис. 13. Синтаксис оператора получения смещения
Как и в языках высокого уровня, выполнение операторов ассемблера при вычислении выражений осуществляется в соответствии с их приоритетами (см. табл. 2). Операции с одинаковыми приоритетами выполняются последовательно слева направо. Изменение порядка выполнения возможно путем расстановки круглых скобок, которые имеют наивысший приоритет.
Таблица 2. Операторы и их приоритет
Директивы сегментации
Синтаксическое описание сегмента на ассемблере представляет собой конструкцию, изображенную на рис. 14:

Рис. 14. Синтаксис описания сегмента

Рис. 15. Директива ASSUME
На уроке 3 мы рассматривали пример программы с директивами сегментации. Эти директивы изначально использовались для оформления программы в трансляторах MASM и TASM. Поэтому их называют стандартными директивами сегментации.
В листинге 1 приведен пример программы с использованием упрощенных директив сегментации:
Синтаксис директивы MODEL показан на рис. 16.

Рис. 16. Синтаксис директивы MODEL
Обязательным параметром директивы MODEL является модель памяти. Этот параметр определяет модель сегментации памяти для программного модуля. Предполагается, что программный модуль может иметь только определенные типы сегментов, которые определяются упомянутыми нами ранее упрощенными директивами описания сегментов. Эти директивы приведены в табл. 3.
Таблица 3. Упрощенные директивы определения сегмента
| Формат директивы (режим MASM) | Формат директивы (режим IDEAL) | Назначение |
| .CODE [имя] | CODESEG[имя] | Начало или продолжение сегмента кода |
| .DATA | DATASEG | Начало или продолжение сегмента инициализированных данных. Также используется для определения данных типа near |
| .CONST | CONST | Начало или продолжение сегмента постоянных данных (констант) модуля |
| .DATA? | UDATASEG | Начало или продолжение сегмента неинициализированных данных. Также используется для определения данных типа near |
| .STACK [размер] | STACK [размер] | Начало или продолжение сегмента стека модуля. Параметр [размер] задает размер стека |
| .FARDATA [имя] | FARDATA [имя] | Начало или продолжение сегмента инициализированных данных типа far |
| .FARDATA? [имя] | UFARDATA [имя] | Начало или продолжение сегмента неинициализированных данных типа far |
При использовании директивы MODEL транслятор делает доступными несколько идентификаторов, к которым можно обращаться во время работы программы, с тем, чтобы получить информацию о тех или иных характеристиках данной модели памяти (см. табл. 5). Перечислим эти идентификаторы и их значения (табл. 4).
Таблица 4. Идентификаторы, создаваемые директивой MODEL
| Имя идентификатора | Значение переменной |
| @code | Физический адрес сегмента кода |
| @data | Физический адрес сегмента данных типа near |
| @fardata | Физический адрес сегмента данных типа far |
| @fardata? | Физический адрес сегмента неинициализированных данных типа far |
| @curseg | Физический адрес сегмента неинициализированных данных типа far |
| @stack | Физический адрес сегмента стека |
Таблица 5. Модели памяти
Таблица 6. Модификаторы модели памяти
| Значение модификатора | Назначение |
| use16 | Сегменты выбранной модели используются как 16-битные (если соответствующей директивой указан процессор i80386 или i80486) |
| use32 | Сегменты выбранной модели используются как 32-битные (если соответствующей директивой указан процессор i80386 или i80486) |
| dos | Программа будет работать в MS-DOS |
Описанные нами стандартные и упрощенные директивы сегментации не исключают друг друга. Стандартные директивы используются, когда программист желает получить полный контроль над размещением сегментов в памяти и их комбинированием с сегментами других модулей.
Упрощенные директивы целесообразно использовать для простых программ и программ, предназначенных для связывания с программными модулями, написанными на языках высокого уровня. Это позволяет компоновщику эффективно связывать модули разных языков за счет стандартизации связей и управления.
Assembler
понедельник, 18 мая 2009 г.
Синтаксис ассемблера. Директива SEGMENT
Стандартные Директивы Сегментации
Синтаксическое описание сегмента на ассемблере представляет собой конструкцию, изображенную на рисунке ниже:
 Важно отметить, что функциональное назначение сегмента несколько шире, чем простое разбиение программы на блоки кода, данных и стека. Сегментация является частью более общего механизма, связанного с концепцией модульного программирования. Она предполагает унификацию оформления объектных модулей, создаваемых компилятором, в том числе с разных языков программирования. Это позволяет объединять программы, написанные на разных языках. Именно для реализации различных вариантов такого объединения и предназначены операнды в директиве SEGMENT.
Важно отметить, что функциональное назначение сегмента несколько шире, чем простое разбиение программы на блоки кода, данных и стека. Сегментация является частью более общего механизма, связанного с концепцией модульного программирования. Она предполагает унификацию оформления объектных модулей, создаваемых компилятором, в том числе с разных языков программирования. Это позволяет объединять программы, написанные на разных языках. Именно для реализации различных вариантов такого объединения и предназначены операнды в директиве SEGMENT.
Рассмотрим их подробнее.
По умолчанию тип выравнивания имеет значение PARA.
По умолчанию атрибут комбинирования принимает значение PRIVATE.
Упрощенные Директивы Сегментации
Синтаксис директивы MODEL :

Модификатор модели памяти
| Значение модификатора | Назначение |
| use16 | Сегменты выбранной модели используются как 16-битные (если соответствующей директивой указан процессор i80386 или i80486) |
| use32 | Сегменты выбранной модели используются как 32-битные (если соответствующей директивой указан процессор i80386 или i80486) |
| dos | Программа будет работать в MS-DOS |
Модель памяти является обязательным параметром директивы MODEL. Этот параметр определяет модель сегментации памяти для программного модуля.
Упрощенные директивы определения сегмента
| Формат директивы (режим MASM) | Формат директивы (режим IDEAL) | Назначение |
| .CODE [имя] | CODESEG[имя] | Начало или продолжение сегмента кода |
| .DATA | DATASEG | Начало или продолжение сегмента инициализированных данных. Также используется для определения данных типа near |
| .CONST | CONST | Начало или продолжение сегмента постоянных данных (констант) модуля |
| .DATA? | UDATASEG | Начало или продолжение сегмента неинициализированных данных. Также используется для определения данных типа near |
| .STACK [размер] | STACK [размер] | Начало или продолжение сегмента стека модуля. Параметр [размер] задает размер стека |
| .FARDATA [имя] | FARDATA [имя] | Начало или продолжение сегмента инициализированных данных типа far |
| .FARDATA? [имя] | UFARDATA [имя] | Начало или продолжение сегмента неинициализированных данных типа far |
Наличие в некоторых директивах параметра [имя] говорит о том, что возможно определение нескольких сегментов этого типа. С другой стороны, наличие нескольких видов сегментов данных обусловлено требованием обеспечить совместимость с некоторыми компиляторами языков высокого уровня, которые создают разные сегменты данных для инициализированных и неинициализированных данных, а также констант.
Идентификаторы, создаваемые директивой MODEL
| Имя идентификатора | Значение переменной |
| @code | Физический адрес сегмента кода |
| @data | Физический адрес сегмента данных типа near |
| @fardata | Физический адрес сегмента данных типа far |
| @fardata? | Физический адрес сегмента неинициализированных данных типа far |
| @curseg | Физический адрес сегмента неинициализированных данных типа far |
| @stack | Физический адрес сегмента стека |
Если вы посмотрите на текст примера, то увидите пример использования одного из этих идентификаторов. Это @data – с его помощью мы получили значение физического адреса сегмента данных нашей программы.
Необязательные параметры язык и модификатор языка определяют некоторые особенности вызова процедур. Необходимость в использовании этих параметров появляется при написании и связывании программ на различных языках программирования.
_TEXT segment word public ’CODE’
для моделей TINY, SMALL и COMPACT
name_TEXT segment word public ’CODE’
STACK segment para public ’stack’
Необязательный параметр указывает размер стека. По умолчанию он равен 1 Кб.
_DATA segment word public ’DATA’
_BSS segment word public ’BSS’
Этот сегмент обычно не включается в программу, а располагается за концом памяти, так что все описанные в нем переменные на момент загрузки программы имеют неопределенные значения.
CONST segment word public ’CONST’
В некоторых операционных системах этот сегмент будет загружен так, что попытка записи в него может привести к ошибке.
имя_сегмента segment para private ’FAR_DATA’
Доступ к данным, описанным в этом сегменте, потребует загрузки сегментного регистра. Если не указан операнд, в качестве имени сегмента используется FAR_DATA.
имя_сегмента segment para private ’FAR_BSS’
Как и в случае с FARDATA, доступ к данным из этого сегмента потребует загрузки сегментного регистра. Если имя сегмента не указано, используется FAR_BSS.
Порядок загрузки сегментов
При использовании стандартных директив сегментации сегменты загружаются в память в том порядке, в котором они описываются в тексте программы.
При использовании упрощенных директив сегментации ( по умолчанию ) устанавливается порядок загрузки сегментов, существующий в MS DOS и часто требуемый для взаимодействия программ на ассемблере с программами на языках высокого уровня.
Порядок загрузки сегментов:
1. Все сегменты класса ‘CODE’.
2. Все сегменты, не принадлежащие группе DGROUP и классу ‘CODE’.
3. Группа сегментов DGROUP:
3.1. Все сегменты класса ‘BEGDATA’.
3.2. Все сегменты, кроме классов ‘BEGDATA’, ‘BSS’ и ‘STACK’.
3.3. Все сегменты класса ‘BSS’.
3.4. Все сегменты класса ‘STACK’.
Знание порядка загрузки сегментов необходимо, например, для вычисления длины программы или адреса ее конца. Для этого надо знать, какой сегмент будет загружен последним, и смещение последнего байта в нем.
Что такое сегмент ассемблер
1.4. Сегментная структура программ
;Пример 1-1. Простая программа с тремя сегментами
;Укажем соответствие сегментных регистров сегментам
assume CS:code,DS:data
;Опишем сегмент команд
code segment ;Откроем сегмент команд
begin: mov AX,data ;Настроим DS
mov DS,AX ;на сегмент данных;
Выведем на экран строку текста
mov АН,09h ;Функция DOS вывода на экран
mov DX,offset msg ;Адрес выводимой строки
int 21h ;Вызов DOS
;Завершим программу
mov AX,4C00h ;Функция DOS завершения программы
int 21h ;Вызов DOS
code ends ;Закроем сегмент команд
;Опишем сегмент данных
data segment ;Откроем сегмент данных
msg db «Программа работает!$’ ;Выводимая строка
data ends ;Закроем сегмент данных
;Опишем сегмент стека
stk segment stack ;Откроем сегмент стека
db 256 dup (?) ;Отводим под стек 256 байт
stk ends ;Закроем сегмент стека
end begin ;Конец текста с точкой входа
mov AX,data ;Настроим DS
mov DS,AX ;на сегмент данных
Ключ /z разрешает вывод на экран строк исходного текста программы, в которых ассемблер обнаружил ошибки (без этого ключа поиск ошибок пришлось бы проводить по листингу трансляции).
Ключ /zi управляет включением в объектный файл информации, не требуемой при выполнении программы, но используемой отладчиком.
Ключ /n подавляет вывод в листинг перечня символических обозначений в программе, от чего несколько уменьшается информативность
листинга, но сокращается его размер.
Стоящие далее параметры определяют имена файлов: исходного (P.ASM), объектного (P.OBJ) и листинга (P.LST). При желании можно в строке вызова транслятора указать полные имена файлов с их расширениями, однако необходимости в этом нет, так как по умолчанию транслятор использует именно указанные выше расширения.
Строка вызова компоновщика имеет следующий вид:
Ключ /х подавляет образование листинга компоновки, который обычно не нужен.
Ключ /v передает в загрузочный файл информацию, используемую отладчиком. Стоящие далее параметры обозначают имена модулей: объектного (Р.ОЫ) и загрузочного (Р.ЕХЕ).
Поскольку при изучении этой книги вам придется написать и отладить большое количество программ, целесообразно создать командный файл (с именем, например, А.ВАТ), автоматизирующий выполнение однотипных операций трансляции и компоновки. Текст командного файла в простейшем варианте может быть таким (в предположении, что путь к каталогу с пакетом TASM был указан в параметре команды PATH):
tasm /z/zi/n p,p,p
tlink /х/v р,р
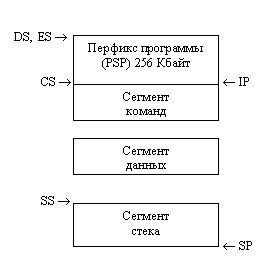
Рис. 1.9. Образ программы в памяти.
Что такое сегмент ассемблер
С этого шага мы начнем рассматривать структуру программы на Ассемблере.
Программа, написанная на языке Ассемблера, может состоять из нескольких модулей. Основной формат представления команд имеет следующий вид:
Метка (если имеется), команда и операнд (если имеется) разделяются, по крайней мере, одним пробелом. Примеры команд:
директивы SEGMENT задают информацию для компоновщика программы. Они должны кодироваться в указанной последовательности, но могут быть опущены в произвольной комбинации. Рассмотрим назначение этих параметров.
Если тип комбинации не указан, сегмент ни с чем не объединяется и рассматривается как отдельная программная единица.
В качестве класса сегмента может быть указан любой идентификатор, на который распространяются все требования и ограничения языка Ассемблера. Поскольку класс сегмента рассматривается как идентификатор, он не может быть определен где-либо еще в программе.
Если класс не указан, компоновщик копирует сегменты в исполнительный файл в той последовательности, в которой они расположены в объектном файле. Эта последовательность сохраняется до тех пор, пока компоновщик не обнаружит два или более сегмента одного класса, после чего начинается объединение сегментов. Сегменты одного класса копируются в последовательные блоки исполнительного файла.
Все сегменты имеют класс. Сегменты, для которых класс не указан, считаются принадлежащими к классу с пустым именем и копируются в последовательные блоки памяти вместе с такими же сегментами. Число сегментов, принадлежащих к одному классу, неограничено, но их суммарный объем не должен превышать 64Кб.



