HTML5 Семантические элементы
Семантика – это изучение значений слов и фраз на языке.
Семантические элементы = элементы с смыслом.
Что такое семантические элементы?
Семантический элемент четко описывает его значение как для браузера, так и для разработчика.
Примеры не семантических элементов:
Примеры семантических элементов:
HTML5 элемент
Статья должна иметь смысл самостоятельно, и она должна быть возможность читать его независимо от остальной части веб-сайта.
Примеры того, где можно использовать элемент :
Пример
What Does WWF Do?
WWF’s mission is to stop the degradation of our planet’s natural environment,
and build a future in which humans live in harmony with nature.
Вложение в или наоборот?
Элемент определяет раздел в документе.
Можем ли мы использовать определения, чтобы решить, как вкладывать эти элементы? Нет, мы не можем!
HTML5 элемент
Элемент задает заголовок для документа или раздела.
Элемент должен использоваться в качестве контейнера для вступительного содержания.
В следующем примере определяется заголовок для статьи:
Пример
What Does WWF Do?
WWF’s mission is to stop the degradation of our planet’s natural environment,
and build a future in which humans live in harmony with nature.
HTML5 элемент
Элемент указывает нижний колонтитул для документа или раздела.
Элемент должен содержать сведения о содержащем его элементе.
Нижний колонтитул обычно содержит автора документа, информацию об авторском праве, ссылки на условия использования, контактные данные и т.д.
Пример
Posted by: Hege Refsnes
HTML5
HTML5 элемент
Пример
My family and I visited The Epcot center this summer.
Epcot Center
The Epcot Center is a theme park in Disney World, Florida.
HTML5 & и элементы
Целью рисунка является добавление визуального пояснения к изображению.
В HTML5 изображение и заголовок могут быть сгруппированы вместе в элементе :
Пример
Элемент определяет изображение, элемент определяет заголовок.
Почему семантические элементы?
С HTML4, проявители использовали их собственные имена удостоверения личности/типа к элементам типа: header, top, bottom, footer, menu, navigation, main, container, content, article, sidebar, topnav, etc.
Это сделало невозможным для поисковых систем, чтобы определить правильное содержание веб-страницы.
С новыми элементами HTML5 ( ) это станет проще.
Согласно W3C, семантический Web: «позволяет обмениваться данными и повторно использовать их в различных приложениях, предприятиях и сообществах».
Семантические элементы в HTML5
Ниже приведен алфавитный список новых семантических элементов в HTML5.

Статья, в которой рассмотрим что такое семантика, а также почему так важно сделать сайт семантически верным.

Что такое семантика
Веб-страницы во всемирной паутине просматривают не только люди. Для человека нет особого труда разобраться в контенте страницы, т.е. он сразу поймёт где находится меню (навигация), заголовки, основное содержимое, дополнительный контент, контактная информация и т.д.
Процесс вложения смысла в содержимое веб-страницы с помощью элементов HTML 5 и посредством их взаимного расположения называется семантикой.
Почему так важно сделать сайт семантически верным? Да, потому что чем более понятным станет контент сайта для поисковых роботов, тем его проще будет найти пользователям.
Таким образом семантика, это очень важная часть современного web, это его сердце. При этом чем более семантически верно построен сайт, тем он является более эффективным.
Основной подход к созданию семантического сайта
При создании HTML-документа необходимо очень тщательно подходить к выбору и расположению элементов. Необходимо знать какой семантический смысл стоит за каждым из используемых элементов и как он сочетается с другими элементами. И уже только потом переходить к разметке некоторого контента.
Спецификация HTML 5 имеет ограниченное число элементов (более 100) с помощью которых автор может разметить страницу.
Основные направления, над которыми необходимо работать автору с HTML 5 документом, чтобы сделать его семантически верным:
HTML и семантика
То есть главной целью семантики в HTML является использование определенных тегов в определенных ситуациях и так, чтобы эти теги описывали текст, заключенный в них в соответствии с выполняемой им функцией. Очень много таких тегов, которые имеют определенное их названием предназначение появилось в стандарте HTML5.
Какой же выбрать для статьи? Внешне самым бросающимся в глаза является тег
Давайте посмотрим, как это выглядит в сочетании с уже рассмотренными тегами и
Давайте посмотрим, как это будет выглядеть на странице (открыть в отдельной вкладке):
, а абзацы все так же будут размещены в тегах
.
Статья увеличивается в размерах. Мы добавим ещё заголовки
, чтобы раскрыть смысл статьи и дать нашим пользователям больше информации о происхождении текста-«рыбы», начинающегося с Lorem ipsum.
Ничего особо сложного, не так ли? И термин «семантика в HTML» уже не выглядит пугающим. Наш текст имеет хоть и очень простую, но логичную структуру. Кроме того, с такой структурой ваш текст, скорей всего, понравится и поисковикам, и СЕО-шникам, т.е. специалистам по оптимизации страниц сайтов под поисковые системы. Ещё одной хорошей новостью является то, что W3C-валидатору наша разметка тоже нравится.
Валидация страницы без ошибок
Где же ложка дегтя? И есть ли она? К сожалению, есть. Наша статья абсолютно безликая. Ей не хватает выделений курсивом, жирным шрифтом, цветом. Текст, хоть и разбит на заголовки, но особого желания читать его не вызывает. Явно не хватает CSS-форматирования.
Блочные и строчные и теги
Во-первых, давайте определимся с тем, что такое блочные и строчные теги в HTML, и в чем заключается разница между ними, т.к. по началу вы можете путаться в этом вопросе.
из 4-х слов совпадает с размером абзаца со значительно большим количеством слов именно по ширине (обведенные красной рамкой цифры слева над текстом).
 Справа внизу в Инспекторе свойств вы можете видеть вложенность элементов. И
Справа внизу в Инспекторе свойств вы можете видеть вложенность элементов. И
Пример страницы с разметкой блочными тегами (открыть в отдельной вкладке):
Строчные, или линейные (от англ. inline) теги, тоже являются прямоугольными элементами, но занимают ровно столько места по ширине, сколько необходимо для отображаемого внутри них текста, причем неважно, это 4 слова или весь текст абзаца. Можно сказать, что строчные теги нужны, как правило,для дополнительного форматирования текста внутри блочных тегов.
Логическое предназначение тегов и их визуальное отображение
Здесь хотелось бы поговорить еще о строчных тегах типа или , или . И , и делают текст жирным, а и придают курсивное начертание тем словам или фразами, которые в них помещены. Зачем нам 2 разных тега, которые делают одно и то же? Какой в том смысл и в чем разница между ними?
Кстати, в примере есть вложенность элементов в , а также в . И в этом случае вы увидите текст в цвете того тега, который является наиболее глубоко вложенным. Здесь работает правило «матрешки»: первый открытый тег закрывается последним.

Теги и отступы
Следует иметь ввиду, что по умолчанию ряд тегов имеет определенные отступы либо сверху и снизу (заголовки, абзацы), либо справа (списки
- ,
- ), либо справа и слева (блочные цитаты
В примере ниже вы увидите неверное и верное применение тегов (открыть в новой вкладке).
Семантические ошибки форматирования
Мы рассматривали очень простую верстку на примере статьи с несколькими абзацами и заголовками. В ней были допущены некоторые ошибки, которые чаще всего допускают начинающие верстальщики, на которые хотелось бы обратить внимание. Они, как правило, не видны пользователю на сайте, так как браузеры стараются вывести информацию в приемлемом виде при любых ошибках форматирования. Зато их не пропустит W3C-валидатор и тот человек, который будет оценивать ваш код при приеме на работу. С поисковиками тоже спорный вопрос, т.к. они распределяют информацию по разделам своей базы данных по только им известному алгоритму, но при этом 100% обращают внимание на ряд тегов, внутри которых она размещена, особенно на заголовки 1-4-го уровней.
В статье был сделан ряд ошибок, которые мы сейчас разберем согласно рекомендациям валидатора:

Давайте разберем все эти ошибки.
 Ошибка 5. Нельзя вкладывать теги заголовков в теги абзацев. Если можно так выразиться, заголовки «круче» абзацев, они имеют более высокий приоритет в глазах тех же поисковиков, т.к. сообщают о том, чему же собственно посвящена вся статья или какой-то блок информации. Именно поэтому заголовков не может быть много. И уж тем более вся страница не может быть сверстана исключительно на заголовках.
Ошибка 5. Нельзя вкладывать теги заголовков в теги абзацев. Если можно так выразиться, заголовки «круче» абзацев, они имеют более высокий приоритет в глазах тех же поисковиков, т.к. сообщают о том, чему же собственно посвящена вся статья или какой-то блок информации. Именно поэтому заголовков не может быть много. И уж тем более вся страница не может быть сверстана исключительно на заголовках.

Обратите внимание, что редактор кода показал красным цветом неправильно отформатированные теги.
Кстати, текст с таким форматированием и в браузере смотрится странно:

Заголовок внутри абзаца смотрится странно
«Лишнее» форматирование
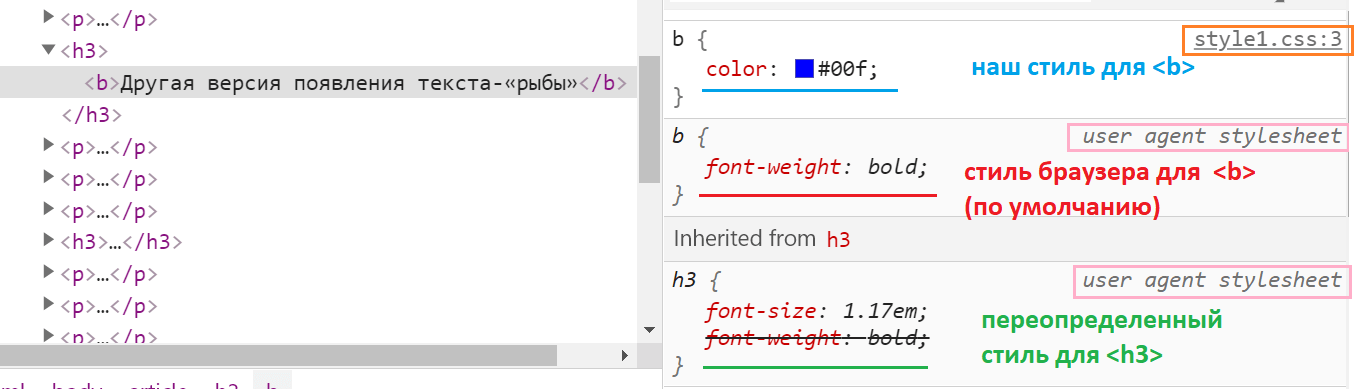
Стили по умолчанию и их переопределения
На скриншоте видно, что и у , и у
, а не добавлять в него .
Вот как это выглядит в браузере:

Тег b внутри заголовка
Устаревшие теги и атрибуты
В примере ниже собраны все возможные устаревшие теги и атрибуты (открыть в новой вкладке).
На скриншоте вы можете увидеть все ошибки, выданные относительно этого файла W3C-валидатором. Их очень много.
Семантический HTML — Основы современной вёрстки
При создании вёрстки нужно учитывать семантику, то есть смысловое (логическое) значение элементов.
Основная цель любой HTML-вёрстки — передача смысла блоков. Часто, помимо пользователей, по нашим страницам ходят и роботы. Они собирают и анализируют информацию страницы. К примеру, поисковые роботы просматривают всю страницу и определяют её полезность, а также уникальность. И если для человека достаточно просто поделить страницу на части и найти шапку, основной контент, футер, то для робота это достаточно сложная задача. Робот видит исключительно нашу вёрстку и не может «глазами» отделить части макета.
Вторая важная причина необходимости создания семантической вёрстки — использование страниц людьми с ограниченными возможностями. Слабовидящие пользователи используют «скринридеры» — устройства или приложения, воспроизводящие голосом элементы страницы. Чтобы скринридер мог правильно понять, где содержится основная информация, меню, поясняющие блоки и так далее, мы должны правильно разметить страницу. Это поможет устройствам правильно разбить страницу на логические блоки и дать возможность посетителям корректно перемещаться по странице. Такая концепция называется «Доступный WEB».
Запомните: минимальная доступность лучше, чем её отсутствие.
Для решения этих вопросов в стандарте HTML5 появилось множество семантических тегов, которыми вы можете пользоваться. В этом уроке изучим базовые семантические теги и разметим целую HTML-страницу.
Шапка сайта
Верхняя область макета зачастую называется «шапкой» сайта. Она содержит название компании, основное меню, контактную информацию. Эта область очень важна для быстрой навигации по сайту, так как обычно содержит меню с основными разделами сайта.
Чтобы создать шапку сайта, используется парный тег header, внутри которого мы и располагаем необходимую информацию.
Один из примеров шапки сайта:
По своему поведению тег header работает так же, как и простой div. Почти все семантические элементы являются блочными и не имеют стилей по умолчанию. Это позволяет очень быстро добавить семантику в уже существующие проекты. Если стили в этих проектах не завязаны на тегах, то достаточно просто сменить название с div на header, и мы получим уже семантичную шапку сайта.
Навигация
Попробуйте взглянуть на шапку сайта из примера выше глазами компьютера. Что он там видит?
Если вы ещё не сверстали пару своих макетов, то по такому набору можете и не понять, что набор ссылок не что иное, как основное меню сайта. Вот и роботам не всегда просто это сделать. Конечно, они уже достаточно обучены, чтобы в таком простом наборе найти меню, но меню обычно может быть не одно и быть контекстно-зависимым. Тогда робот может принять за основное меню не то, что бы мы хотели.
Как же нам ему помочь? Для этого в стандарте HTML5 появился тег nav. Он обозначает навигационную область. Причём помочь отделить основное меню от меню раздела можно с помощью других тегов, речь о которых пойдёт ниже.
Заменим простой блочный элемент div на его семантичного брата nav:
Главной особенностью использования nav является то, что не обязательно оборачивать все меню на странице. Обычно достаточно обернуть только главное меню и, например, не оборачивать меню в футере. При этом не запрещается иметь сразу несколько элементов nav на странице. Выделяйте ими главные меню на странице.
Уникальный контент
Основной смысл каждой страницы — уникальный контент. Это самое главное, что должно быть на вашей странице. Пользователь вполне справится без меню или футера, но если на странице нет своего уникального контента, то страница бесполезна.
Для разметки уникального контента в стандарте HTML5 появился специальный тег main. Именно он поможет обозначить область с самым важным контентом на странице. Старайтесь в нём держать только контент. Обычно меню, боковые панели и футер в эту область не входят. Исключением может быть только ситуация, если эти блоки действительно уникальны для данной страницы. Например, меню может вести по разделам страницы. В таком случае оно на полных правах может быть включено в область уникального контента.
Добавим такую область в нашу вёрстку:
Наличие тега main также очень важно для мобильных браузеров. Вы могли видеть, что многие из них имеют функцию «Режим чтения». При его включении браузер автоматически удалит всё оформление и все ненужные блоки, оставив только главный контент. Этим контентом и будет являться область, заключённая в тег main. Такой режим отлично подходит для людей, у которых, в настоящий момент, слабое подключение к интернету.
Так как внутри main содержится уникальный контент страницы, то разрешено использовать только один такой тег на странице.
Секции
Контент на странице не является однородным. Обычно это цепочка логических областей, каждая из которых описывает что-то конкретное. Например, на странице могут присутствовать область с описанием преимуществ, цены, формы и так далее. Их хочется как-то выделить. И на это есть несколько причин:
Для таких самостоятельных логических единиц существует специальный тег section, который внутри себя может содержать одну конкретную секцию. Добавим её в наш пример:
Заметьте, как легко стало искать преимущества в коде, ведь они находятся в отдельной секции. Также вы могли обратить внимание на заголовок внутри секции. Так как секция — это самостоятельная единица, то почти всегда она имеет свой заголовок. Хоть это и не всегда так, и стандарт не обязывает нас включать заголовок в секцию, но старайтесь придерживаться этого правила.
Как быстро определить, стоит ли включать участок контента в отдельную секцию? Всё очень просто: если вы можете описать участок контента в одном или двух словах (преимущества, цены, форма заказа, каталог, контакты и так далее), то с большой вероятностью этот участок является самостоятельной секцией.
Независимые секции
Другим способом выделить логический участок текста является использование тега article. Может показаться, что какой смысл иметь два различных тега для выделения одного и того же?
Между section и article есть одна существенная разница: article является независимой секцией, то есть её можно перенести на любую страницу сайта или даже на другой сайт, и при этом она не потеряет своего контекста.
Представьте себе блог и отдельную статью в нём. Можем ли мы понять статью, если она вдруг окажется не в блоге, а, например, на странице с услугами? Конечно! Ведь статья — это законченный текст. Следовательно, такую статью можно обернуть в тег article.
Добавим колонку новостей в наш пример вёрстки. Сразу подумаем, как она может быть разделена. Сами по себе новости являются достаточно уникальным элементом, ведь даже если их перенести на другую страницу, то они не потеряют свою актуальность. В этом случае каждую новость можно обернуть в article. А что делать с обёрткой блока? Она объединяет по смыслу несколько различных новостей, её можно спокойно назвать одним словом, и она точно будет иметь свой заголовок. Следовательно, ей подойдёт тег section.
Дополняющие секции
Ещё одним крупным контейнером для нашего контента служит тег aside. Это область с дополнительной информацией. Она может быть как связана с текущей страницей, так и не очень. Подобные секции вы можете встречать в виде боковых панелей на сайтах. Там содержится дополнительное меню, баннеры, реклама и другая информация.
Обратите внимание, что aside не обязан являться боковой панелью по внешнему виду. Это может быть даже дополнительная информация внутри статьи. Но чаще всего внешнее оформление у такого тега именно в виде боковой панели.
Давайте добавим такую информацию в нашу вёрстку. Внутри этой дополнительной секции будет находиться ещё одно меню, которое не будем оборачивать в nav, так как оно не является основным.
Самостоятельная работа
Создайте файл index.html на своём компьютере и создайте собственное резюме. Используйте изученные в этом уроке теги.

Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты.
Нашли опечатку или неточность?
Выделите текст, нажмите ctrl + enter и отправьте его нам. В течение нескольких дней мы исправим ошибку или улучшим формулировку.
Что-то не получается или материал кажется сложным?
Загляните в раздел «Обсуждение»:
Об обучении на Хекслете
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно.
Наши выпускники работают в компаниях:
С нуля до разработчика. Возвращаем деньги, если не удалось найти работу.
Семантика в HTML 5
Я собираюсь сделать смелый прогноз. Еще долго после вас и меня HTML будет вокруг. Не только в миллиардах архивных страниц нашей эры, а как живые дыхательные органы. Слишком много сил, энергии и инвестиций пошло на разработку web-инструментов, протоколов и платформ, что бы все это было легко брошено.
Остановимся, что бы рассмотреть нашу ответственность. К несчастью, в истории мы связаны с разработкой важного инструмента нашей цивилизации, который будет использоваться для общения в течении десятилетий. И так когда мы направляем свои умы, праздно или всерьез, на улучшение HTML мы должны понимать на сколько далеко идущими могут быть последствия наших решений.
HTML 5, W3C недавно удвоило усилия по формированию нового поколения HTML, за прошедший год или около того набрал значительные темпы. Это огромны проект, который охватывает не только структуру HTML, но и разбор моделей, модели обработки ошибок, DOM, алгоритмы для извлечения ресурсов, медиа-котента, 2D графики, шаблоны данных, модели безопасности, модели загрузки страницы, хранение данных на стороне клиента и многое другое.
Так же существуют изменения в структуре, синтаксисе и семантике HTML, некоторые из них описал Lachlan Hunt в статье «Обзор HTML 5» (перевод на хабре).
Но в этой статье давайте рассмотрим исключительно семантику HTML. Это то, чем я был заинтересован в течении многих лет и я считаю, что это очень важно для будущего HTML.
BBC недавно объявила о том, что они будут снижать долю микроформата hCalendar в своей программе телепередач, в пользу доступности и удобства abbr design pattern. Это свидетельствует о том, что мы, вне всяких сомнений, вытолкнули семантические возможности HTML далеко за те пределы, которые когда-либо предназначались, и действительно это возможно для языка. Мы просто исчерпали элементы и атрибуты HTML, которые способны повысить семантику документа. Если мы будем и далее хитрить с существующими конструкциями HTML, то будет возникать все больше таких проблем. Потому что HTML страдает от фундаментального деффекта, как семантический язык разметки — его семантика фиксирована и не расширяема.
Это не просто теоретическая проблема. Сотни тысяч разработчиков используют class и id для создания более семантической разметки (они так же используют их в качестве «крючков» для CSS стилей, но это другой вопрос). Почти всегда эти разработчики используют специальные словари, значения которых они сами составляют, а не значения существующих схем. Это псевдосемантическая разметка — в лучшем случае.
Многие страницы по всему интернету используют микроформаты, что бы добавить более структурированной семантики, чем при помощи обнищавшего набора элементов и атрибутов HTML. В этом случае значения использованные для атрибута class согласованы со словарями, иногда взяты из других стандартов, такие как vCard, иногда из недавно созданных словарей, где нет жесткого существующего стандарта (как в случае с hReview).
Расширяемая семантика
Существует очень серьезная проблема, которую необходимо решить здесь. Нам нужны механизмы в HTML, которые четко и однозначно позволят разработчикам добавлять более выразительной семантики, а не псевдосемантики в их разметку. Это, пожалуй, является самой насущной задачей для HTML 5 проектов.
Но это не так просто, придумать механизм для создания большей семантики в HTML контенте: Существуют значительные ограничения, на любое решение. Возможно, самое большое из них — обратная совместимость. Решение, не может нарушить сотни миллионов устройств для просмотра использующихся сегодня, которые будут использоваться в ближайшие годы. Любое решение, которое не совместимо, не будет широко принято разработчиками, опасаясь потери читателей. Оно будет быстро засыхать на корню.
Решение должно быть так же вперед-совместимым. Не в том смысле, что оно должно работать в будущих броузерах — это задача разработчиков броузеров, но оно должно быть расширяемым. Мы не можем ожидать какого-либо единого решения, которое мы сейчас разработаем, что бы решить все вообразимые и невообразимые потребности семантики в будущем. Мы можем разработать решения, которые могут быть расширены для удовлетворения будущих потребностей, по мере их возникновения.
эти трудности, в совокупности представляют огромную проблему. Но в контексте языка, основные итерации которого проходят в десятилетние промежутки и важность которого, как глобальная платформа для коммуникаций имеет первостепенное значение, это проблема, которая должна быть решена.
Итак, как HTML 5 решит этот вопрос? HTML 5 вводит ряд новых элементов. Некоторые я назвал «структурные» — section, nav, aside, header и footer. Элемент dialog который по типу и содержанию схож с blockquote. Есть так же целый ряд элементов данных, как например meter, который представляет собой «скалярное измерение в пределах известного диапазона или дробное значение, например использование диска»; и элемент time
Хоть эти элементы и могут быть полезными и, как выяснилось, вызвали определенный интерес, смогут ли они действительно решить эту проблему, мы определим с ограничениями совместимости снизу вверх и обратной совместимости.
Рассмотрим каждое препятствие
Обратная совместимость
h1 > Top Level Heading h1 >
section >
h1 > Second Level Heading h1 >
p > this is text in a section element p >
section >
h1 > Third Level Heading h1 >
section >
section >
В начале это выглядит прекрасно. Но когда мы пытаемся задать стили CSS, например, для элемента section, который выглядит следующим образом:
… Большинству из упомянутых броузеров это удается, но IE7 (и тем более 6) нет.
Поэтому у нас есть проблема обратной совместимости с 75% броузеров, использующихся в настоящее время. Учитывая, период полураспад Internet Explorer, мы можем прогнозировать, что большинство пользователей будут использовать IE6 и IE7, даже через несколько лет.
Если HTML 5 вводит новые элементы, какова вероятность, что они будут использоваться подавляющим большинством разработчиков — учитывая то, что они не совместимы с большинством используемых броузеров?
Давайте обратимся к совместимости снизу вверх, это следующая проблема.
Совместимость снизу вверх
Сначала мы поставим вопрос: «Зачем мы изобретать эти новые элементы?». Разумным ответом будет: «Потому что не хватает семантики в HTML, а добавление этих элементов мы увеличим семантику HTML, что не может быть плохим, или может?».
Добавляя эти элементы, мы рассматриваем необходимость повышения потенциала семантики HTML, но только в рамках узкой сферы. Независимо от того сколько элементов введем, мы всегда будем думать о добавлении большей семантике HTML. И добавив столько элементов, сколько нам хочется, мы не решим проблему. Нам не нужно добавлять определенные термины в словарь HTML, мы должны добавить механизм, позволяющий расширять семантику документа по мере необходимости. В технических терминах, мы должны сделать HTML расширяемым. HTML 5 не предлагает механизма расширяемости.
Таким образом HTML 5 выполняет функцию, которая убьет значительный процент современных броузеров и не позволяет добавить семантики языка вообще.
Остаюнся несколько вопросов о новых элементах. Откуда взяты названия новых элементов? Как было решено, что элемент навигации нужно называть «nav»? Зачем в навигации применяются термины page-level, site-level и meta-site-level?
Почему бы не принять существующий словарь, такой как DocBook? Его словарь структуры документа более богат, он был разработан путем публикаций экспертов, на протяжении многих лет. Это не является аргументом в пользу DocBook, а дело в том, что чрезвычайно важная задача подготовки механизма обеспечения семантикой HTML проходит путь, уделяя малое внимание практике в работе которая началась более 30 лет назад. (Оригинал работы по GML начался в начале 1970-х годов)
Некоторые идеи решения
И так, имее чрезвычайно важное значение нынешних усилий, у меня есть некоторые практические рекомендации, как решить эту проблему. Ну, я начал с одного.
Если добавление новых элементов не обсуждается, по крайней мере в этой дискуссии, атрибуты — другая логическая область HTML, сконцентрируемся на ней. В конце концов, мы на протяжении, почти, десяти лет использовали атрибуты class и id, как механизмы расширения семантики HTML. Многие разработчики уже знакомы с этим и чувствуют себя комфортно. Проект microformats показал, что существующих атрибутов не достаточно, для использования их как механизм расширения семантики HTML. Так что, если мы хотим использовать атрибуты для решения проблемы, мы должны ввести один или более новых атрибутов. Пред тем, как перейти к механики, того как это может работать, справедливо подвергнуть это предложение тем же требованиям, как и новые элементы в HTML 5. Самое главное во внедрении новых атрибутов — это будет ли обратная совместимость HTML. Если да, то обеспечивает ли это работоспособный механизм расширения семантики в HTML?
Давайте изобретем новый атрибут. Назовем его «structure», но название не важно. Мы можем использовать его так:
Давайте посмотрим, как наши броузеры это оценят.
Конечно, все наши броузеры обработают следующий элемент CSS.
А как насчет этого:
На самом деле, почти все броузеры, включая IE7, обработают стиль div с атрибутом structure, даже если нет такого атрибута. К сожалению, наше счастье изчезает, потому что IE6 нет. Но мы можем использовать этот атрибут в HTML и все существующие броузеры распознают его. Мы даже можем использовать стили CSS для нашего HTML, с использованием атрибута во всех современных броузерах. И если мы хотим обойти старые броузеры, мы можем добавить class, со значением стиля. В сравнении с HTML 5 решением, которое добавляет новые элементы, не работающие в Internet Explorer 6 или 7, мы видим, что это, безусловно, более обратно совместимое решение.
Расширяемость через атрибуты
Вместо новых элементов, HTML 5 должна принять ряд новых атрибутов. Каждый из этих атрибутов будет относиться к категории или типу семантики. Например, как я уже подробно изложил в другой статье, HTML включает в себя: структурную семантику, риторическую семантику, ролевую семантику (принятую из XHTML) и другие классы и категории семантики.
Эти новые атрибуты, могут быть использованы как атрибут class: для придания элементу семантики, описывать характер элемента или для метаданных элемента.
Это не отличается от ролей атрибута в XHTML, где мы имеем один атрибут для всех элементов семантики, мы должны определить различные типы семантики элемента и разделить их.
Например XHTML атрибут role работает следующим образом:
ul role =»navigation sitemap» >
li href =»downloads» > Downloads li >
li href =»docs» > Documentation li >
li href =»news» > News li >
ul >
Значение атрибута role является разделенное пространство списка из слов определенного стандартным словарем или заданным словарем.
Почему бы не принять атрибут role, как есть? Ведь существуют другие виды семантики, для которых определение роли не применимо. Например:
Это демонстрирует теоретический тип семантики — «риторический», который может быть использован для разметки документа риторического характера. Этот элемент явно не играет роли иронии в документе. Наоборот, содержит в себе элементы иронии.
Вот еще один пример. Все более очевидно, что в HTML не хватает представления машино-читаемого значения понятным для человека, например даты. Это лежит в основе проблемы BBC с микроформатом hCalendar, о ней мы говорили ранее. Хотя May Day next year действительно не имеет смысла, зато по аналогии May Day next year будет.
Опять же, когда мы используем конкретный термин «equivalent» в качестве атрибута или какой либо другой для обозначения такого рода семантики, это не является проблемой. Важно отметить, что это не так просто, как использование атрибута class или role, где в один элемент помещается целый набор элементов семантики информации. Для, должным образом, расширяемого решения, которое обеспечит обратную совместимость и достаточную гибкость, стоит исследовать в этом направлении.
Я назвал этот раздел «Некоторые идеи решения», поскольку значительный объем работы необходимо сделать, для того, что бы создать действительно работоспособное решение. Открытые вопросы включают в себя следующее.
Вместо того, что бы торопится с ответом на эти вопросы, я выдвинул на свет вопросы которые необходимо решить и начать диалог. Разветвление и размах решений сделаных в HTML 5, слишком велик для принятия этих решений, необходимо внести осведомленность о лингвистике, семантике, семиотике и смежных областях.
Надеюсь понятно, что просто внесение новых элементов в HTML не является решением проблемы расширения семантики в HTML.
Давайте не спешить с легким решением — с изменением «климата» все это обременит наших внуков проблемой, как и сейчас. По крайней, мере давайте оставим им максимально хороший HTML, на сколько возможно.



