Статистическая значимость в экспериментах и анализе данных
Что именно имеют в виду ученые и исследователи, когда заявляют, что что-то является или не является статистически значимым? Как установить статистическую значимость и как ее интерпретировать?
Добро пожаловать в 11-ю часть серии статей о статистике в электротехнике. До сих пор мы рассматривали как высокоуровневые определения, так и конкретные примеры статистических концепций, полезных для инженера-практика. Чтобы узнать больше о том, что мы рассмотрели, ознакомьтесь со статьями, перечисленными в меню с оглавлением выше, над статьей.
Статистическая значимость: туманная концепция?
Любой, кто обычно читает исследовательские статьи, часто сталкивается со «статистической значимостью», часто сопровождаемой загадочной ссылкой на p  Рисунок 1 – Если мы предполагаем, что нулевая гипотеза верна, мы часто будем использовать гауссову кривую в качестве функции плотности вероятности, с помощью которой мы решаем, является ли результат статистически значимым.
Рисунок 1 – Если мы предполагаем, что нулевая гипотеза верна, мы часто будем использовать гауссову кривую в качестве функции плотности вероятности, с помощью которой мы решаем, является ли результат статистически значимым.
Порог вероятности
Статистическая значимость основана на вероятности получения результата при предположении, что нулевая гипотеза верна. Предположим, что в ходе нашего эксперимента мы получили число x (это может быть что угодно: артериальное давление, доход от продаж, средний балл теста).
Обращаясь к функции плотности вероятности, связанной с нулевой гипотезой, мы можем определить, будет ли вероятность получения x или какого-либо другого числа, которое более маловероятно, чем x, менее 5% (p 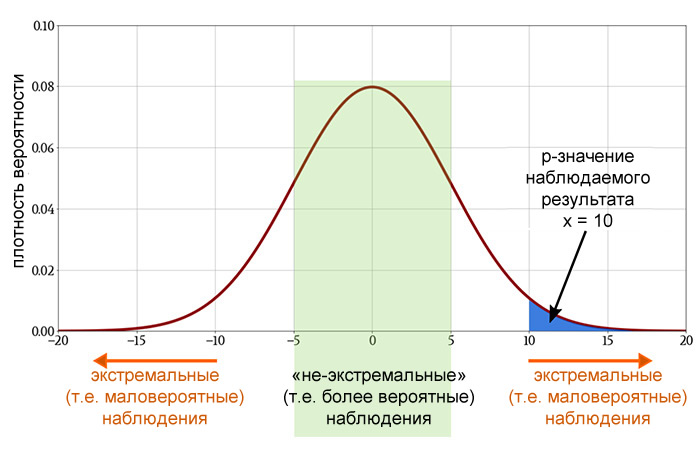 Рисунок 2 – Гауссова кривая – это функция плотности вероятности, которая соответствует распределению значений, когда нулевая гипотеза верна. Мы вычисляем p-значение наблюдаемого результата путем интегрирования части этой функции плотности вероятности.
Рисунок 2 – Гауссова кривая – это функция плотности вероятности, которая соответствует распределению значений, когда нулевая гипотеза верна. Мы вычисляем p-значение наблюдаемого результата путем интегрирования части этой функции плотности вероятности.
Если p-значение достаточно низкое, нет смысла продолжать предполагать, что между двумя переменными нет никакой связи. Таким образом, мы отвергаем нулевую гипотезу и утверждаем, что связь существует.
Интерпретация статистической значимости
Предыдущее объяснение описывает статистическую значимость способом, который я считаю наиболее простым и математически последовательным: если p-значение наблюдаемого результата меньше заранее определенного порога, который мы называем уровнем значимости, наблюдаемый результат очень маловероятен, если нулевая гипотеза верна. Поэтому, когда мы отвергаем нулевую гипотезу, это равносильно подтверждению того, что эксперимент обнаружил связь между интересующими переменными.
Это же общее сообщение можно передать другими способами, которые могут оказаться полезными:
Толкование слова «значимость»
Большая путаница в отношении статистической значимости возникает из-за использования слова «значимость», которое в данном контексте ограничивается конкретным статистическим использованием и не совпадает со словом «значимость» в обычном языке.
Статистически значимые результаты не обязательно являются важными или значимыми результатами. Статистическая значимость не означает практической значимости, а также отсутствие статистической значимости не означает, что экспериментальные результаты не имеют практической ценности.
Уровень значимости
Чтобы установить статистическую значимость, мы должны сравнить p-значение с уровнем значимости, обозначенным как ⍺. Уровни значимости в некоторой степени произвольны и выбираются в соответствии с условиями заданной области. Как было указано выше, часто используются ⍺ = 0,05 и ⍺ = 0,01, хотя в некоторых случаях выбирается более высокое или гораздо более низкое значение.
Заключение
Несмотря на возможное неправильное использование статистической значимости и доказательства широко распространенной неверной интерпретации, она остается важным методом в исследованиях и экспериментах. Мы продолжим изучение этой темы в следующей статье.
Объясняем p-значения для начинающих Data Scientist’ов
Я помню, когда я проходил свою первую зарубежную стажировку в CERN в качестве практиканта, большинство людей все еще говорили об открытии бозона Хиггса после подтверждения того, что он соответствует порогу «пять сигм» (что означает наличие p-значения 0,0000003).

Тогда я ничего не знал о p-значении, проверке гипотез или даже статистической значимости.
Я решил загуглить слово — «p-значение», и то, что я нашел в Википедии, заставило меня еще больше запутаться…
При проверке статистических гипотез p-значение или значение вероятности для данной статистической модели — это вероятность того, что при истинности нулевой гипотезы статистическая сводка (например, абсолютное значение выборочной средней разницы между двумя сравниваемыми группами) будет больше или равна фактическим наблюдаемым результатам.
— Wikipedia
Хорошая работа, Википедия.
Ладно. Я не понял, что на самом деле означает р-значение.
Углубившись в область науки о данных, я наконец начал понимать смысл p-значения и то, где его можно использовать как часть инструментов принятия решений в определенных экспериментах.
Поэтому я решил объяснить р-значение в этой статье, а также то, как его можно использовать при проверке гипотез, чтобы дать вам лучшее и интуитивное понимание р-значений.
Также мы не можем пропустить фундаментальное понимание других концепций и определение p-значения, я обещаю, что сделаю это объяснение интуитивно понятным, не подвергая вас всеми техническими терминами, с которыми я столкнулся.
Всего в этой статье четыре раздела, чтобы дать вам полную картину от построения проверки гипотезы до понимания р-значения и использования его в процессе принятия решений. Я настоятельно рекомендую вам пройтись по всем из них, чтобы получить подробное понимание р-значений:
1. Проверка гипотез

Прежде чем мы поговорим о том, что означает р-значение, давайте начнем с разбора проверки гипотез, где р-значение используется для определения статистической значимости наших результатов.
Наша конечная цель — определить статистическую значимость наших результатов.
И статистическая значимость построена на этих 3 простых идеях:
Другими словами, мы создадим утверждение (нулевая гипотеза) и используем пример данных, чтобы проверить, является ли утверждение действительным. Если утверждение не соответствует действительности, мы выберем альтернативную гипотезу. Все очень просто.
Чтобы узнать, является ли утверждение обоснованным или нет, мы будем использовать p-значение для взвешивания силы доказательств, чтобы увидеть, является ли оно статистически значимым. Если доказательства подтверждают альтернативную гипотезу, то мы отвергнем нулевую гипотезу и примем альтернативную гипотезу. Это будет объяснено в следующем разделе.
Давайте воспользуемся примером, чтобы сделать эту концепцию более ясной, и этот пример будет использоваться на протяжении всей этой статьи для других концепций.
Пример. Предположим, что в пиццерии заявлено, что время их доставки составляет в среднем 30 минут или меньше, но вы думаете, что оно больше чем заявленное. Таким образом, вы проводите проверку гипотезы и случайным образом выбираете время доставки для проверки утверждения:
Одним из распространенных способов проверки гипотез является использование Z-критерия. Здесь мы не будем вдаваться в подробности, так как хотим лучше понять, что происходит на поверхности, прежде чем погрузиться глубже.
2. Нормальное распределение
Нормальное распределение — это функция плотности вероятности, используемая для просмотра распределения данных.
Нормальное распределение имеет два параметра — среднее (μ) и стандартное отклонение, также называемое сигма (σ).
Среднее — это центральная тенденция распределения. Оно определяет местоположение пика для нормальных распределений. Стандартное отклонение — это мера изменчивости. Оно определяет, насколько далеко от среднего значения склонны падать значения.
Нормальное распределение обычно связано с правилом 68-95-99.7 (изображение выше).
Классно. Теперь вы можете задаться вопросом: «Как нормальное распределение относится к нашей предыдущей проверке гипотез?»
Поскольку мы использовали Z-тест для проверки нашей гипотезы, нам нужно вычислить Z-баллы (которые будут использоваться в нашей тестовой статистике), которые представляют собой число стандартных отклонений от среднего значения точки данных. В нашем случае каждая точка данных — это время доставки пиццы, которое мы получили.
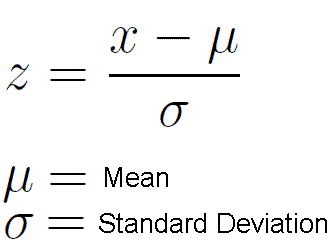
Обратите внимание, что когда мы рассчитали все Z-баллы для каждого времени доставки пиццы и построили стандартную кривую нормального распределения, как показано ниже, единица измерения на оси X изменится с минут на единицу стандартного отклонения, так как мы стандартизировали переменную, вычитая среднее и деля его на стандартное отклонение (см. формулу выше).
Изучение стандартной кривой нормального распределения полезно, потому что мы можем сравнить результаты теста с ”нормальной» популяцией со стандартизированной единицей в стандартном отклонении, особенно когда у нас есть переменная, которая поставляется с различными единицами.
Z-оценка может сказать нам, где лежат общие данные по сравнению со средней популяцией.
Мне нравится, как Уилл Кёрсен выразился: чем выше или ниже Z-показатель, тем менее вероятным будет случайный результат и тем более вероятным будет значимый результат.
Но насколько высокий (или низкий) показатель считается достаточно убедительным, чтобы количественно оценить, насколько значимы наши результаты?
Кульминация
Здесь нам нужен последний элемент для решения головоломки — p-значение, и проверить, являются ли наши результаты статистически значимыми на основе уровня значимости (также известного как альфа), который мы установили перед началом нашего эксперимента.
3. Что такое P-значение?
Наконец… Здесь мы говорим о р-значении!
Все предыдущие объяснения предназначены для того, чтобы подготовить почву и привести нас к этому P-значению. Нам нужен предыдущий контекст и шаги, чтобы понять это таинственное (на самом деле не столь таинственное) р-значение и то, как оно может привести к нашим решениям для проверки гипотезы.
Если вы зашли так далеко, продолжайте читать. Потому что этот раздел — самая захватывающая часть из всех!
Вместо того чтобы объяснять p-значения, используя определение, данное Википедией (извини Википедия), давайте объясним это в нашем контексте — время доставки пиццы!
Напомним, что мы произвольно отобрали некоторые сроки доставки пиццы, и цель состоит в том, чтобы проверить, превышает ли время доставки 30 минут. Если окончательные доказательства подтверждают утверждение пиццерии (среднее время доставки составляет 30 минут или меньше), то мы не будем отвергать нулевую гипотезу. В противном случае мы опровергаем нулевую гипотезу.
Поэтому задача p-значения — ответить на этот вопрос:
Если я живу в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), насколько неожиданными являются мои доказательства в реальной жизни?
Р-значение отвечает на этот вопрос числом — вероятностью.
Чем ниже значение p, тем более неожиданными являются доказательства, тем более нелепой выглядит наша нулевая гипотеза.
И что мы делаем, когда чувствуем себя нелепо с нашей нулевой гипотезой? Мы отвергаем ее и выбираем нашу альтернативную гипотезу.
Если р-значение ниже заданного уровня значимости (люди называют его альфа, я называю это порогом нелепости — не спрашивайте, почему, мне просто легче понять), тогда мы отвергаем нулевую гипотезу.
Теперь мы понимаем, что означает p-значение. Давайте применим это в нашем случае.
P-значение в расчете времени доставки пиццы
Теперь, когда мы собрали несколько выборочных данных о времени доставки, мы выполнили расчет и обнаружили, что среднее время доставки больше на 10 минут с p-значением 0,03.
Это означает, что в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), есть 3% шанс, что мы увидим, что среднее время доставки, по крайней мере, на 10 минут больше, из-за случайного шума.
Чем меньше p-значение, тем более значимым будет результат, потому что он с меньшей вероятностью будет вызван шумом.
В нашем случае большинство людей неправильно понимают р-значение:
Р-значение 0,03 означает, что есть 3% (вероятность в процентах), что результат обусловлен случайностью — что не соответствует действительности.
Р-значение ничего не *доказывает*. Это просто способ использовать неожиданность в качестве основы для принятия разумного решения.
— Кэсси Козырков
Вот как мы можем использовать p-значение 0,03, чтобы помочь нам принять разумное решение (ВАЖНО):
По моему мнению, p-значения используются в качестве инструмента для оспаривания нашего первоначального убеждения (нулевая гипотеза), когда результат является статистически значимым. В тот момент, когда мы чувствуем себя нелепо с нашим собственным убеждением (при условии, что р-значение показывает, что результат статистически значим), мы отбрасываем наше первоначальное убеждение (отвергаем нулевую гипотезу) и принимаем разумное решение.
4. Статистическая значимость
Наконец, это последний этап, когда мы собираем все вместе и проверяем, является ли результат статистически значимым.
Недостаточно иметь только р-значение, нам нужно установить порог (уровень значимости — альфа). Альфа всегда должна быть установлена перед экспериментом, чтобы избежать смещения. Если наблюдаемое р-значение ниже, чем альфа, то мы заключаем, что результат является статистически значимым.
Основное правило — установить альфа равным 0,05 или 0,01 (опять же, значение зависит от вашей задачи).
Как упоминалось ранее, предположим, что мы установили альфа равным 0,05, прежде чем мы начали эксперимент, полученный результат является статистически значимым, поскольку р-значение 0,03 ниже, чем альфа.
Для справки ниже приведены основные этапы всего эксперимента:
Если вы хотите узнать больше о статистической значимости, не стесняйтесь посмотреть эту статью — Объяснение статистической значимости, написанная Уиллом Керсеном.
Последующие размышления
Здесь много чего нужно переваривать, не так ли?
Я не могу отрицать, что p-значения по своей сути сбивают с толку многих людей, и мне потребовалось довольно много времени, чтобы по-настоящему понять и оценить значение p-значений и то, как они могут быть применены в рамках нашего процесса принятия решений в качестве специалистов по данным.
Но не слишком полагайтесь на p-значения, поскольку они помогают только в небольшой части всего процесса принятия решений.
Я надеюсь, что мое объяснение p-значений стало интуитивно понятным и полезным в вашем понимании того, что в действительности означают p-значения и как их можно использовать при проверке ваших гипотез.
Сам по себе расчет р-значений прост. Трудная часть возникает, когда мы хотим интерпретировать p-значения в проверке гипотез. Надеюсь, что теперь трудная часть станет для вас немного легче.
Если вы хотите узнать больше о статистике, я настоятельно рекомендую вам прочитать эту книгу (которую я сейчас читаю!) — Практическая статистика для специалистов по данным, специально написанная для data scientists, чтобы разобраться с фундаментальными концепциями статистики.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
Статистическая значимость
Статистическая значимость – что это такое и почему она так важна? Подобного рода исследования относят к ряду количественных, а не качественных. То есть в разрезе маркетинга статистика может рассказать о цифрах, но не может определить почему именно они появились. Выводы о причинах их возникновения уже ложатся на сотрудников, проводящих такие исследования.
Тем не менее эта наука является незаменимым инструментом во всех исследованиях. В сегодняшнем материале мы расскажем об азах статистической значимости и о возможностях её применения в рекламе.
Посчитать t-критерий стьюдента онлайн и понять достоверность одной из гипотез? Если эти задачи для вас слишком сложны, то этот материал для вас!
Виды гипотез
Со статистической значимостью тесно переплетается понятие «проверка гипотезы». Гипотеза – это только теория. После того, как будет разработана теория, необходимо определить порядок сбора доказательств. Различают два вида гипотез:
Нулевая гипотеза
Нулевая гипотеза не требует доказательств. Данная теория говорит о том, что при использовании каких-либо новых данных, результаты деятельности не изменятся.
Целью является не доказательство, а опровержение этой теории. Например, следователь выдвигает множество гипотез по отношению к обвиняемому. В этом случае нулевая гипотеза – это презумпция невиновности. Человека не смогут считать виноватым, пока не будет доказана его вина.
Альтернативная гипотеза
Если при нулевой гипотезе есть два объекта, которые имеют одинаковые свойства и нужно доказать, что один из них лучше, то наступает время альтернативной гипотезы. Если в нулевой гипотезе при воздействии на объект получается одинаковый эффект или таковой отсутствует в принципе, то при альтернативной гипотезе – один из эффектов лучше другого.
Теперь, когда мы имеем представление о нулевой и альтернативной гипотезах, то, как доказывать одно и опровергать другое? Существует определитель, который позволяет понять удачный был эксперимент или нет. Он называется индексом достоверности.
Что такое статистическая достоверность? Это условная величина или уровень статистической значимости, который принимается, чтобы сказать, что является «значимым», а что нет.
Виды критериев
Для оценки гипотез применяется t-критерий Стьюдента. Это метод, помогающий сравнить данные двух вариантов и сделать выводы об их различиях по статистическим параметрам.
Таблица значений критерия Стьюдента поможет установить, все ли данные находятся в установленном пределе или нет.
Этим критерием пользуются в том случае, когда отсутствует уверенность в том, что данные расположены выше или ниже нормы распределения.
Автоматический расчет t-критерия Стьюдента
В интернете есть множество сервисов для расчета критерия Стьюдента онлайн. Их принцип действия схож:
1. Выбираем вид расчета: связанные или несвязанные выборки.
2. В первую колонку вводим информацию о первой выборке, во вторую – о второй. В каждую строку заносится по одному числу. Пробелы и пропуски не допускаются. Дробная часть числа отделяется от основной части точкой.
3. Как только колонки будут заполнены, нажимаем на кнопку «Произвести расчет».
Коэффициент Стьюдента оценивает степень величин двух выборок, с учётом нормы распределения. Его достоинство заключается в том, что такой коэффициент можно применять в любой сфере бизнеса. Рассчитать критерий Стьюдента онлайн можно на сайте.
С аналогичными вводными, но по другому алгоритму работает и расчет критерия Манна-Уитни. Им также можно воспользоваться онлайн для сравнения групп данных.
Как пользоваться статистической значимостью в маркетинге: пример анализа
Статистика используется во многих областях маркетинга. Аналитики исследуют все возможные элементы бизнеса. Интернет-маркетологи проводят анализ посещаемости ресурсов и эффективности рекламных кампаний. PR-менеджеры смотрят посещаемость мероприятий перед тем как договориться о сотрудничестве с конкретной площадкой для проведения ивента. В примере далее рассмотрим наиболее точную и последовательную область маркетинга — онлайн-рекламу.
Как определить коэффициент эффективности будущего рекламного объявления? Конечно, при помощи проведения тестирования различных видов и форматов креативов.
А/B тестирование в онлайн-маркетинге – это исследование, итог которого никогда нельзя знать заранее. Можно лишь выстраивать алгоритм работы таким образом, чтобы получить максимум данных исходя из результатов тестирования. Только после этого можно прийти к выводу о том, какой из вариантов является более удачным. Также для достоверности исследования оно должно продолжаться хотя бы одну неделю, так как в разные дни конверсия может варьироваться.
Возможные проблемы при проведении А/B тестирования
Наиболее наглядно продемонстрировать проблему тестирования поможет следующий пример. Предположим, в исследовании №1 человек в кроссовках фирмы Nike подкинул монетку вверх 30 раз, и она упала стороной орла ему на ладонь 25 раз. В исследовании №2 человек в кроссовках фирмы Adidas проделал тоже самое количество подкидываний, но получил орла на ладони целых 28 раз. Разве из этого исследования очевидно, что кроссовки Adidas приводят к такому положению монетки?
В данном случае речь именно о нулевой гипотезе, определение которой мы описывали выше. Статистически значимые различия тут вовсе не кроссовки, они являются лишь переменной, не влияющей на ход событий. Именно это предстоит доказать при проведении тестирования с монеткой.
С подобными проблемами может столкнуться и интернет-маркетолог в ходе проведения А/B тестирования. Зачастую сложно понять, нажал ли пользователь на креатив из-за того, что в нём увеличен заголовок. Или он просто на него нажал, а заголовок в объявлении является аналогом кроссовок из предыдущего примера.
Ещё одна сложность А/B тестирований в том, что они указывают на статистику, но не объясняют почему именно так произошло.
Справиться с проблемами таких исследований в области интернет-маркетинга поможет увеличение выборки эксперимента, а также вариантов аудиторий/объявлений, с которыми проводятся сравнение.
На что мы обращаем внимание при расчете статистической значимости A/B-теста
В Учи.ру мы стараемся даже небольшие улучшения выкатывать A/B-тестом, только за этот учебный год их было больше 250. A/B-тест — мощнейший инструмент тестирования изменений, без которого сложно представить нормальное развитие интернет-продукта. В то же время, несмотря на кажущуюся простоту, при проведении A/B-теста можно допустить серьёзные ошибки как на этапе дизайна эксперимента, так и при подведении итогов. В этой статье я расскажу о некоторых технических моментах проведения теста: как мы определяем срок тестирования, подводим итоги и как избегаем ошибочных результатов при досрочном завершении тестов и при тестировании сразу нескольких гипотез.
Типичная схема A/B-тестирования у нас (да и у многих) выглядит так:
Статистическая значимость, критерии и ошибки
В любом A/B-тесте присутствует элемент случайности: метрики групп зависят не только от их функционала, но и от того, какие пользователи в них попали и как они себя ведут. Чтобы достоверно сделать выводы о превосходстве какой-то группы, нужно набрать достаточно наблюдений в тесте, но даже тогда вы не застрахованы от ошибок. Их различают два типа:
Самый распространенный параметрический тест — критерий Стьюдента. Для двух независимых выборок (случай A/B-теста) его иногда называют критерием Уэлча. Этот критерий работает корректно, если исследуемые величины распределены нормально. Может показаться, что на реальных данных это требование почти никогда не удовлетворяется, однако на самом деле тест требует нормального распределения выборочных средних, а не самих выборок. На практике это означает, что критерий можно применять, если у вас в тесте достаточно много наблюдений (десятки-сотни) и в распределениях нет совсем уж длинных хвостов. При этом характер распределения исходных наблюдений неважен. Читатель самостоятельно может убедиться, что критерий Стьюдента работает корректно даже на выборках, сгенерированных из распределений Бернулли или экспоненциального.
Из непараметрических критериев популярен критерий Манна — Уитни. Его стоит применять, если ваши выборки очень малого размера или есть большие выбросы (метод сравнивает медианы, поэтому устойчив к выбросам). Также для корректной работы критерия в выборках должно быть мало совпадающих значений. На практике нам ни разу не приходилось применять непараметрические критерии, в своих тестах всегда пользуемся критерием Стьюдента.
Проблема множественного тестирования гипотез

Например, для трёх экспериментальных групп получим 14.3% вместо ожидаемых 5%. Решается проблема поправкой Бонферрони на множественную проверку гипотез: нужно просто поделить уровень значимости на количество сравнений (то есть групп) и работать с ним. Для примера выше уровень значимости с учётом поправки составит 0.05/3 = 0.0167 и вероятность хотя бы одной ошибки первого рода составит приемлемые 4.9%.

P-value первой гипотезы сравнивается с уровнем статистический значимости  . Если гипотеза принимается, то переходим ко второй и сравниваем её p-value с уровнем статистической значимости
. Если гипотеза принимается, то переходим ко второй и сравниваем её p-value с уровнем статистической значимости  , и так далее. Как только какая-то гипотеза отвергается, процесс останавливается и все оставшиеся гипотезы так же отвергаются. Самое жёсткое требование (и такое же, как в поправке Бонферрони) накладывается на гипотезу с наименьшим p-value, а большая мощность достигается за счёт менее жёстких условий для последующих гипотез. Цель A/B-теста — выбрать одного единственного победителя, поэтому методы Бонферрони и Холма — Бонферрони абсолютно идентичны в этом приложении.
, и так далее. Как только какая-то гипотеза отвергается, процесс останавливается и все оставшиеся гипотезы так же отвергаются. Самое жёсткое требование (и такое же, как в поправке Бонферрони) накладывается на гипотезу с наименьшим p-value, а большая мощность достигается за счёт менее жёстких условий для последующих гипотез. Цель A/B-теста — выбрать одного единственного победителя, поэтому методы Бонферрони и Холма — Бонферрони абсолютно идентичны в этом приложении.
Строго говоря, сравнения групп по разным метрикам или срезам аудитории тоже подвержены проблеме множественного тестирования. Формально учесть все проверки довольно сложно, потому что их количество сложно спрогнозировать заранее и подчас они не являются независимыми (особенно если речь идёт про разные метрики, а не срезы). Универсального рецепта нет, полагайтесь на здравый смысл и помните, что если проверить достаточно много срезов по разным метрикам, то в любом тесте можно увидеть якобы статистически значимый результат. А значит, надо с осторожностью относиться, например, к значимому приросту ретеншена пятого дня новых мобильных пользователей из крупных городов.
Проблема подглядывания
Частный случай множественного тестирования гипотез — проблема подглядывания (peeking problem). Смысл в том, что значение p-value по ходу теста может случайно опускаться ниже принятого уровня значимости. Если внимательно следить за экспериментом, то можно поймать такой момент и ошибочно сделать вывод о статистической значимости.
Предположим, что мы отошли от описанной в начале поста схемы проведения тестов и решили подводить итоги на уровне значимости 5% каждый день (или просто больше одного раза за время теста). Под подведением итогов я понимаю признание теста положительным, если p-value ниже 0.05, и его продолжение в противном случае. При такой стратегии доля ложноположительных результатов будет пропорциональна количеству проверок и уже за первый месяц достигнет 28%. Такая огромная разница кажется контринтуитивной, поэтому обратимся к методике A/A-тестов, незаменимой для разработки схем A/B-тестирования.
Идея A/A-теста проста: симулировать на исторических данных много A/B-тестов со случайным разбиением на группы. Разницы между группами заведомо нет, поэтому можно точно оценить долю ошибок первого рода в своей схеме A/B-тестирования. На гифке ниже показано, как изменяются значения p-value по дням для четырёх таких тестов. Равный 0.05 уровень значимости обозначен пунктирной линией. Когда p-value опускается ниже, мы окрашиваем график теста в красный. Если бы в этом время подводились итоги теста, он был бы признан успешным.
Рассчитаем аналогично 10 тысяч A/A-тестов продолжительностью в один месяц и сравним доли ложноположительных результатов в схеме с подведением итогов в конце срока и каждый день. Для наглядности приведём графики блуждания p-value по дням для первых 100 симуляций. Каждая линия — p-value одного теста, красным выделены траектории тестов, в итоге ошибочно признанных удачными (чем меньше, тем лучше), пунктирная линия — требуемое значение p-value для признания теста успешным.
На графике можно насчитать 7 ложноположительных тестов, а всего среди 10 тысяч их было 502, или 5%. Хочется отметить, что p-value многих тестов по ходу наблюдений опускались ниже 0.05, но к концу наблюдений выходили за пределы уровня значимости. Теперь оценим схему тестирования с подведением итогов каждый день:
Красных линий настолько много, что уже ничего не понятно. Перерисуем, обрывая линии тестов, как только их p-value достигнут критического значения:
Всего будет 2813 ложноположительных тестов из 10 тысяч, или 28%. Понятно, что такая схема нежизнеспособна.
Хоть проблема подглядывания — это частный случай множественного тестирования, применять стандартные поправки (Бонферрони и другие) здесь не стоит, потому что они окажутся излишне консервативными. На графике ниже — доля ложноположительных результатов в зависимости от количества тестируемых групп (красная линия) и количества подглядываний (зелёная линия).
Хотя на бесконечности и в подглядываниях мы вплотную приблизимся к 1, доля ошибок растёт гораздо медленнее. Это объясняется тем, что сравнения в этом случае независимыми уже не являются.
Методы досрочного завершения теста
Есть варианты тестирования, позволяющие досрочно принять тест. Расскажу о двух из них: с постоянным уровнем значимости (поправка Pocock’a) и зависимым от номера подглядывания (поправка O’Brien-Fleming’a). Строго говоря, для обеих поправок нужно заранее знать максимальный срок теста и количество проверок между запуском и окончанием теста. Причём проверки должны происходить примерно через равные промежутки времени (или через равные количества наблюдений).
Pocock
Метод заключается в том, что мы подводим итоги тестов каждый день, но при сниженном (более строгом) уровне значимости. Например, если мы знаем, что сделаем не больше 30 проверок, то уровень значимости надо выставить равным 0.006 (подбирается в зависимости от количества подглядываний методом Монте-Карло, то есть эмпирически). На нашей симуляции получим 4% ложноположительных исходов — видимо, порог можно было увеличить.
Несмотря на кажущуюся наивность, некоторые крупные компании пользуются именно этим способом. Он очень прост и надёжен, если вы принимаете решения по чувствительным метрикам и на большом трафике. Например, в «Авито» по умолчанию уровень значимости принят за 0.005.
O’Brien-Fleming

Соответствующие уровни значимости вычисляются через перцентиль  стандартного распределения, соответствующий значению статистики Стьюдента
стандартного распределения, соответствующий значению статистики Стьюдента  :
:
На тех же симуляциях это выглядит так:
Ложноположительных результатов получилось 501 из 10 тысяч, или ожидаемые 5%. Обратите внимание, что уровень значимости не достигает значения в 5% даже в конце, так как эти 5% должны «размазаться» по всем проверкам. В компании мы пользуемся именно этой поправкой, если запускаем тест с возможностью ранней остановки. Прочитать про эти же и другие поправки можно по ссылке.
Калькулятор A/B-тестов
Специфика нашего продукта такова, что распределение любой метрики очень сильно меняется в зависимости от аудитории теста (например, номера класса) и времени года. Поэтому не получится принять за дату окончания теста правила в духе «тест закончится, когда в каждой группе наберётся 1 млн пользователей» или «тест закончится, когда количество решённых заданий достигнет 100 млн». То есть получится, но на практике для этого надо будет учесть слишком много факторов:
Все метрики у нас рассчитываются на уровне объектов теста. Если метрика — количество решённых задач, то в тесте на уровне учителей это будет сумма решённых задач его учениками. Так как мы пользуемся критерием Стьюдента, можно заранее рассчитать нужные калькулятору агрегаты по всем возможным срезам. Для каждого дня со старта теста нужно знать количество людей в тесте  , среднее значение метрики
, среднее значение метрики  и её дисперсию
и её дисперсию  . Зафиксировав доли контрольной группы
. Зафиксировав доли контрольной группы  , экспериментальной группы
, экспериментальной группы  и ожидаемый прирост от теста
и ожидаемый прирост от теста  в процентах, можно рассчитать ожидаемые значения статистики Стьюдента
в процентах, можно рассчитать ожидаемые значения статистики Стьюдента  и соответствующее p-value на каждый день теста:
и соответствующее p-value на каждый день теста:

Далее легко получить значения p-value на каждый день:
Зная p-value и уровень значимости с учетом всех поправок на каждый день теста, для любой продолжительности теста можно рассчитать минимальный аплифт, который можно задетектировать (в англоязычной литературе — MDE, minimal detectable effect). После этого легко решить обратную задачу — определить количество дней, необходимое для выявления ожидаемого аплифта.
Заключение
В качестве заключения хочу напомнить основные посылы статьи:



