Что такое стек
И почему так страшен стек-оверфлоу.
Постепенно осваиваем способы организации и хранения данных. Уже было про деревья, попробуем про стеки. Это для тех, кто хочет в будущем серьёзно работать в ИТ: одна из фундаментальных концепций, которая влияет на качество вашего кода, но не касается какого-то конкретного языка программирования.
👉 Стек — это одна из структур данных. Структура данных — это то, как хранятся данные: например, связанные списки, деревья, очереди, множества, хеш-таблицы, карты и даже кучи (heap).
Как устроен стек
Стек хранит последовательность данных. Связаны данные так: каждый элемент указывает на тот, который нужно использовать следующим. Это линейная связь — данные идут друг за другом и нужно брать их по очереди. Из середины стека брать нельзя.
👉 Главный принцип работы стека — данные, которые попали в стек недавно, используются первыми. Чем раньше попал — тем позже используется. После использования элемент стека исчезает, и верхним становится следующий элемент.
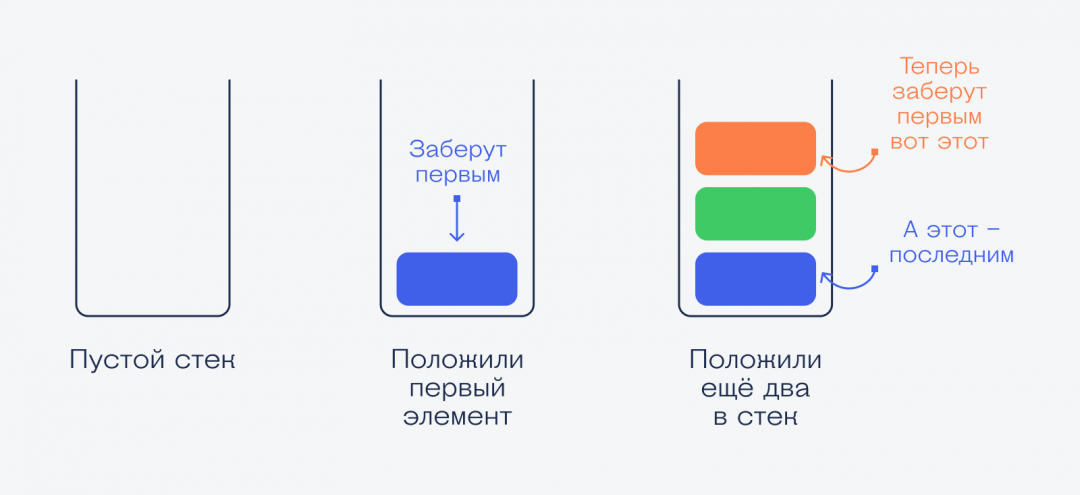
Классический способ объяснения принципов стека звучит так: представьте, что вы моете посуду и складываете одинаковые чистые тарелки стопкой друг на друга. Каждая новая тарелка — это элемент стека, а вы просто добавляете их по одной в стек.
Когда кому-то понадобится тарелка, он не будет брать её снизу или из середины — он возьмёт первую сверху, потом следующую и так далее.
🤔 Есть структура данных, похожая на стек, — называется очередь, или queue. Если в стеке кто последний пришёл, того первым заберут, то в очереди наоборот: кто раньше пришёл, тот раньше ушёл. Можно представить очередь в магазине: кто раньше её занял, тот первый дошёл до кассы. Очередь — это тоже линейный набор данных, но обрабатывается по-другому.
Стек вызовов
В программировании есть два вида стека — стек вызовов и стек данных.
Когда в программе есть подпрограммы — процедуры и функции, — то компьютеру нужно помнить, где он прервался в основном коде, чтобы выполнить подпрограмму. После выполнения он должен вернуться обратно и продолжить выполнять основной код. При этом если подпрограмма возвращает какие-то данные, то их тоже нужно запомнить и передать в основной код.
Чтобы это реализовать, компьютер использует стек вызовов — специальную область памяти, где хранит данные о точках перехода между фрагментами кода.
Допустим, у нас есть программа, внутри которой есть три функции, причём одна из них внутри вызывает другую. Нарисуем, чтобы было понятнее:
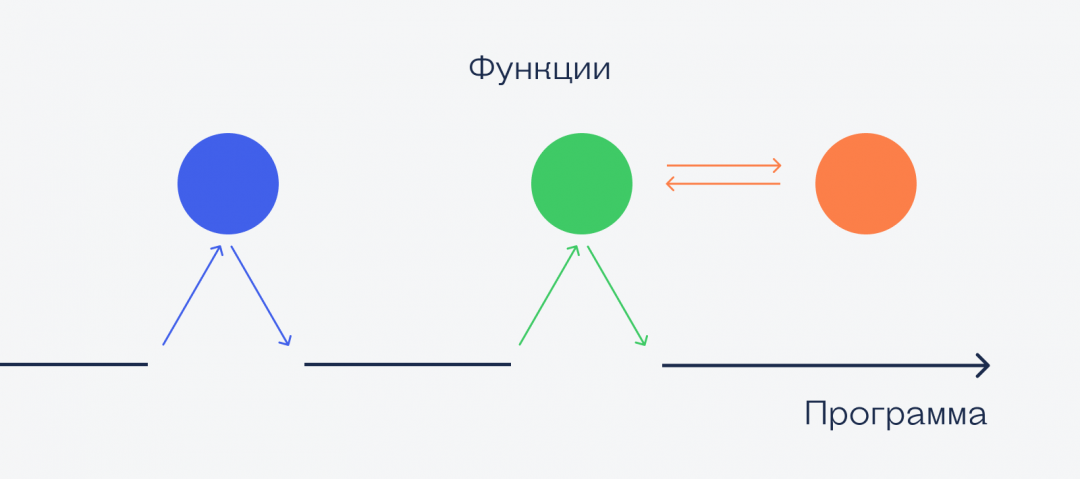
Программа запускается, потом идёт вызов синей функции. Она выполняется, и программа продолжает с того места, где остановилась. Потом выполняется зелёная функция, которая вызывает красную. Пока красная не закончит работу, все остальные ждут. Как только красная закончилась — продолжается зелёная, а после её окончания программа продолжает свою работу с того же места.
А вот как стек помогает это реализовать на практике:
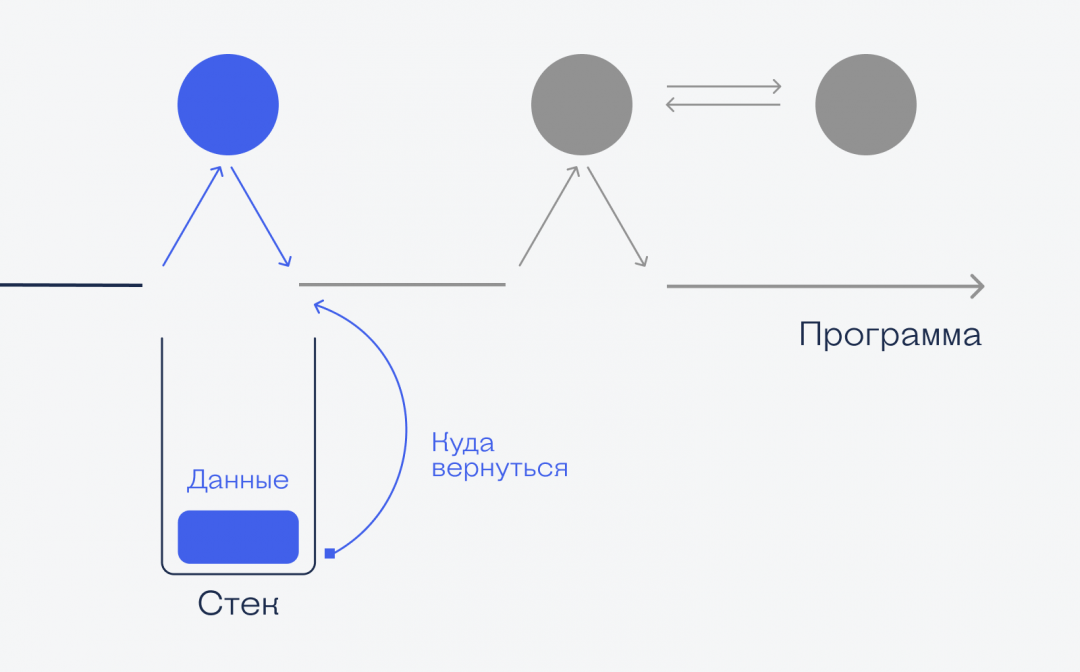
Программа дошла до синей функции, сохранила точку, куда ей вернуться после того, как закончится функция, и если функция вернёт какие-то данные, то программа тоже их получит. Когда синяя функция закончится и программа получит верхний элемент стека, он автоматически исчезнет. Стек снова пустой.
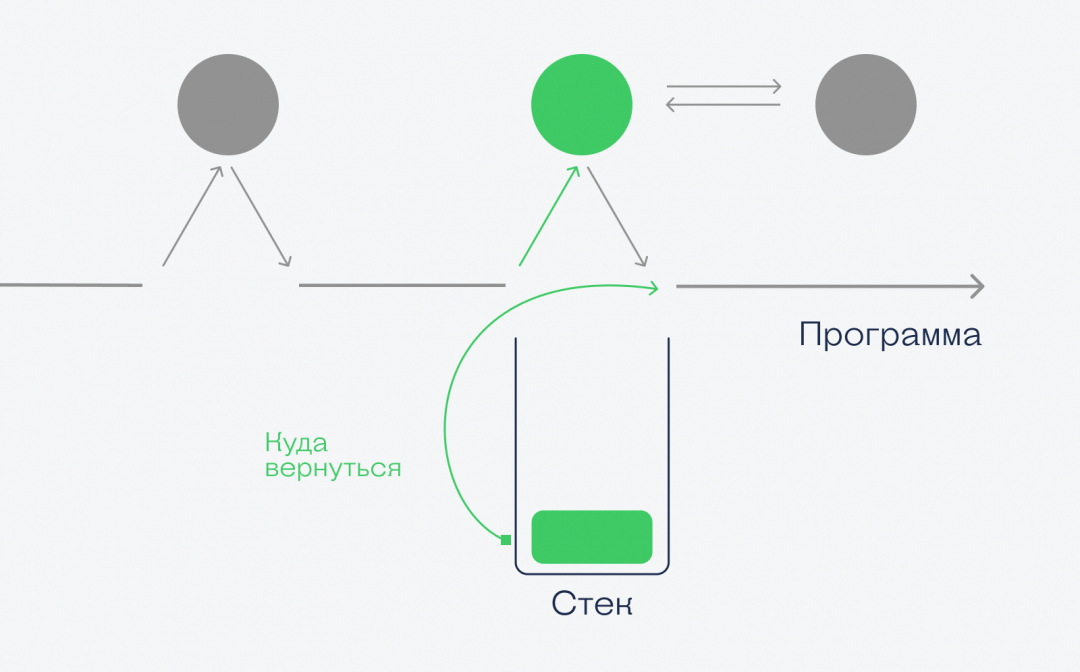
С зелёной функцией всё то же самое — в стек заносится точка возврата, и программа начинает выполнять зелёную функцию. Но внутри неё мы вызываем красную, и вот что происходит:
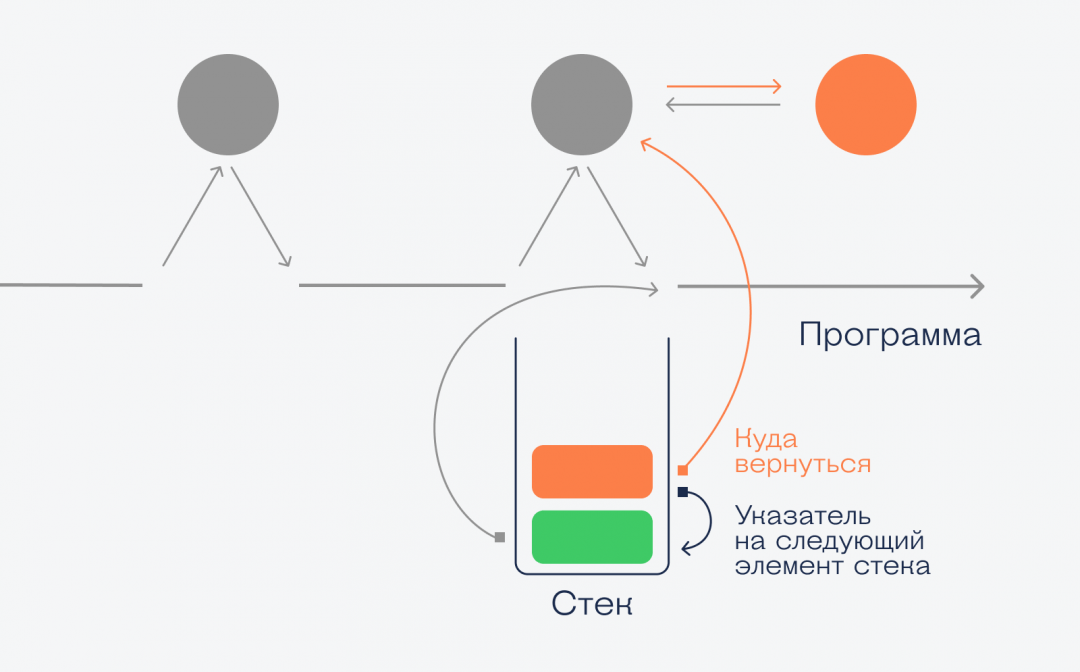
При вызове красной функции в стек помещается новый элемент с информацией о данных, точке возврата и указанием на следующий элемент. Это значит, что когда красная функция закончит работу, то компьютер возьмёт из стека адрес возврата и вернёт управление снова зелёной функции, а красный элемент исчезнет. Когда и зелёная закончит работу, то компьютер из стека возьмёт новый адрес возврата и продолжит работу со старого места.
Переполнение стека
Почти всегда стек вызовов хранится в оперативной памяти и имеет определённый размер. Если у вас будет много вложенных вызовов или рекурсия с очень большой глубиной вложенности, то может случиться такая ситуация:
Переполнение — это плохо: данные могут залезать в чужую область памяти и записывать себя вместо прежних данных. Это может привести к сбою в работе других программ или самого компьютера. Ещё таким образом можно внедрить в оперативную память вредоносный код: если программа плохо работает со стеком, можно специально вызвать переполнение и записать в память что-нибудь вредоносное.
Стек данных
Стек данных очень похож на стек вызовов: по сути, это одна большая переменная, похожая на список или массив. Его чаще всего используют для работы с другими сложными типами данных: например, быстрого обхода деревьев, поиска всех возможных маршрутов по графу, — и для анализа разветвлённых однотипных данных.
Стек данных работает по такому же принципу, как и стек вызовов — элемент, который добавили последним, должен использоваться первым.
Что дальше
А дальше поговорим про тип данных под названием «куча». Да, такой есть, и с ним тоже можно эффективно работать. Стей тюнед.
О стеке простыми словами — для студентов и просто начинающих
Привет, я студент второго курса технического университета. После пропуска нескольких пар программирования по состоянию здоровья, я столкнулся с непониманием таких тем, как «Стек» и «Очередь». Путем проб и ошибок, спустя несколько дней, до меня наконец дошло, что это такое и с чем это едят. Чтобы у вас понимание не заняло столько времени, в данной статье я расскажу о том что такое «Стек», каким образом и на каких примерах я понял что это такое. Если вам понравится, я напишу вторую часть, которая будет затрагивать уже такое понятие, как «Очередь»
Теория
На Википедии определение стека звучит так:
Стек (англ. stack — стопка; читается стэк) — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Поэтому первое, на чем бы я хотел заострить внимание, это представление стека в виде вещей из жизни. Первой на ум мне пришла интерпретация в виде стопки книг, где верхняя книга — это вершина.

На самом деле стек можно представить в виде стопки любых предметов будь то стопка листов, тетрадей, рубашек и тому подобное, но пример с книгами я думаю будет самым оптимальным.
Итак, из чего же состоит стек.
Стек состоит из ячеек(в примере — это книги), которые представлены в виде структуры, содержащей какие-либо данные и указатель типа данной структуры на следующий элемент.
Сложно? Не беда, давайте разбираться.
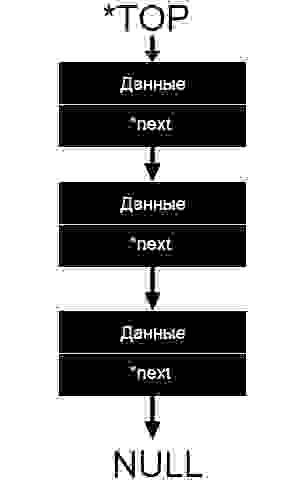
На данной картинке схематично изображен стек. Блок вида «Данные/*next» и есть наша ячейка. *next, как мы видим, указывает на следующий элемент, другими словами указатель *next хранит адрес следующей ячейки. Указатель *TOP указывает на вершину стек, то есть хранит её адрес.
С теорией закончили, перейдем к практике.
Практика
Для начала нам нужно создать структуру, которая будет являться нашей «ячейкой»
Новичкам возможно будет не понятно, зачем наш указатель — типа comp, точнее сказать указатель типа структуры comp. Объясню, для того чтобы указатель *next мог хранить структуру comp, ей нужно обозначить тип этой структуры. Другими словами указать, что будет хранить указатель.
После того как у нас задана «Ячейка», перейдем к созданию функций.
Функции
Функция создания «Стека»/добавления элемента в «Стек»
При добавлении элемента у нас возникнет две ситуации:
Разберем чуть чуть по-подробнее.
Во-первых, почему функция принимает **top, то есть указатель на указатель, для того чтобы вам было наиболее понятно, я оставлю рассмотрение этого вопроса на потом. Во-вторых, по-подробнее поговорим о q->next = *top и о том, что же означает ->.
-> означает то, что грубо говоря, мы заходим в нашу структуру и достаем оттуда элемент этой структуры. В строчке q->next = *top мы из нашей ячейки достаем указатель на следующий элемент *next и заменяем его на указатель, который указывает на вершину стека *top. Другими словами мы проводим связь, от нового элемента к вершине стека. Тут ничего сложного, все как с книгами. Новую книгу мы кладем ровно на вершину стопки, то есть проводим связь от новой книги к вершине стопки книг. После этого новая книга автоматически становится вершиной, так как стек не стопка книг, нам нужно указать, что новый элемент — вершина, для этого пишется: *top = q;.
Функция удаления элемента из «Стека» по данным
Данная функция будет удалять элемент из стека, если число Data ячейки(q->Data) будет равна числу, которое мы сами обозначим.
Здесь могут быть такие варианты:
Для лучшего понимания удаления элемента проведем аналогии с уже привычной стопкой книг. Если нам нужно убрать книгу сверху, мы её убираем, а книга под ней становится верхней. Тут то же самое, только в начале мы должны определить, что следующий элемент станет вершиной *top = q->next; и только потом удалить элемент free(q);
Если книга, которую нужно убрать находится между двумя книгами или между книгой и столом, предыдущая книга ляжет на следующую или на стол. Как мы уже поняли, книга у нас-это ячейка, а стол получается это NULL, то есть следующего элемента нет. Получается так же как с книгами, мы обозначаем, что предыдущая ячейка будет связана с последующей prev->next = q->next;, стоит отметить что prev->next может равняться как ячейке, так и нулю, в случае если q->next = NULL, то есть ячейки нет(книга ляжет на стол), после этого мы очищаем ячейку free(q).
Так же стоит отметить, что если не провести данную связь, участок ячеек, который лежит после удаленной ячейки станет недоступным, так как потеряется та самая связь, которая соединяет одну ячейку с другой и данный участок просто затеряется в памяти
Функция вывода данных стека на экран
Самая простая функция:
Здесь я думаю все понятно, хочу сказать лишь то, что q нужно воспринимать как бегунок, он бегает по всем ячейкам от вершины, куда мы его установили вначале: *q = top;, до последнего элемента.
Главная функция
Хорошо, основные функции по работе со стеком мы записали, вызываем.
Посмотрим код:
Вернемся к тому, почему же в функцию мы передавали указатель на указатель вершины. Дело в том, что если бы мы ввели в функцию только указатель на вершину, то «Стек» создавался и изменялся только внутри функции, в главной функции вершина бы как была, так и оставалась NULL. Передавая указатель на указатель мы изменяем вершину *top в главной функции. Получается если функция изменяет стек, нужно передавать в нее вершину указателем на указатель, так у нас было в функции s_push,s_delete_key. В функции s_print «Стек» не должен изменяться, поэтому мы передаем просто указатель на вершину.
Вместо цифр 1,2,3,4,5 можно так-же использовать переменные типа int.
Заключение
Полный код программы:
Так как в стек элементы постоянно добавляются на вершину, выводиться элементы будут в обратном порядке
В заключение хотелось бы поблагодарить за уделенное моей статье время, я очень надеюсь что данный материал помог некоторым начинающим программистам понять, что такое «Стек», как им пользоваться и в дальнейшем у них больше не возникнет проблем. Пишите в комментариях свое мнение, а так же о том, как мне улучшить свои статьи в будущем. Спасибо за внимание.
Разбираемся с управлением памятью в современных языках программирования
Привет, Хабр! Представляю вашему вниманию перевод статьи «Demystifying memory management in modern programming languages» за авторством Deepu K Sasidharan.
В данной серии статей мне бы хотелось развеять завесу мистики над управлением памятью в программном обеспечении (далее по тексту — ПО) и подробно рассмотреть возможности, предоставляемые современными языками программирования. Надеюсь, что мои статьи помогут читателю заглянуть под капот этих языков и узнать для себя нечто новое.
Углублённое изучение концептов управления памятью позволяет писать более эффективное ПО, потому как стиль и практики кодирования оказывают большое влияние на принципы выделения памяти для нужд программы.
Часть 1: Введение в управление памятью
Управление памятью — это целый набор механизмов, которые позволяют контролировать доступ программы к оперативной памяти компьютера. Данная тема является очень важной при разработке ПО и, при этом, вызывает затруднения или же вовсе остаётся черным ящиком для многих программистов.
Для чего используется оперативная память?
Когда программа выполняется в операционный системе компьютера, она нуждается в доступе к оперативной памяти (RAM) для того, чтобы:
Стек используется для статичного выделения памяти. Он организован по принципу «последним пришёл — первым вышел» (LIFO). Можно представить стек как стопку книг — разрешено взаимодействовать только с самой верхней книгой: прочитать её или положить на неё новую.

Использование стека в JavaScript. Объекты хранятся в куче и доступны по ссылкам, которые хранятся в стеке. Тут можно посмотреть в видеоформате
Куча используется для динамического выделения памяти, однако, в отличие от стека, данные в куче первым делом требуется найти с помощью «оглавления». Можно представить, что куча это такая большая многоуровневая библиотека, в которой, следуя определённым инструкциям, можно найти необходимую книгу.
Почему эффективное управление памятью важно?
В отличие от жёстких дисков, оперативная память весьма ограниченна (хотя и жёсткие диски, безусловно, тоже не безграничны). Если программа потребляет память не высвобождая её, то, в конечном итоге, она поглотит все доступные резервы и попытается выйти за пределы памяти. Тогда она просто упадет сама, или, что ещё драматичнее, обрушит операционную систему. Следовательно, весьма нежелательно относиться легкомысленно к манипуляциям с памятью при разработке ПО.
Различные подходы
Современные языки программирования стараются максимально упростить работу с памятью и снять с разработчиков часть головной боли. И хотя некоторые почтенные языки всё ещё требуют ручного управления, большинство всё же предоставляет более изящные автоматические подходы. Порой в языке используется сразу несколько подходов к управлению памятью, а иногда разработчику даже доступен выбор какой из вариантов будет эффективнее конкретно для его задач (хороший пример — C++). Перейдём к краткому обзору различных подходов.
Ручное управление памятью
Язык не предоставляет механизмов для автоматического управления памятью. Выделение и освобождение памяти для создаваемых объектов остаётся полностью на совести разработчика. Пример такого языка — C. Он предоставляет ряд методов (malloc, realloc, calloc и free) для управления памятью — разработчик должен использовать их для выделения и освобождения памяти в своей программе. Этот подход требует большой аккуратности и внимательности. Так же он является в особенности сложным для новичков.
Сборщик мусора
Сборка мусора — это процесс автоматического управления памятью в куче, который заключается в поиске неиспользующихся участков памяти, которые ранее были заняты под нужды программы. Это один из наиболее популярных вариантов механизма для управления памятью в современных языках программирования. Подпрограмма сборки мусора обычно запускается в заранее определённые интервалы времени и бывает, что её запуск совпадает с ресурсозатратными процессами, в результате чего происходит задержка в работе приложения. JVM (Java/Scala/Groovy/Kotlin), JavaScript, Python, C#, Golang, OCaml и Ruby — вот примеры популярных языков, в которых используется сборщик мусора.
Получение ресурса есть инициализация (RAII)
RAII — это программная идиома в ООП, смысл которой заключается в том, что выделяемая для объекта область памяти строго привязывается к его времени существования. Память выделяется в конструкторе и освобождается в деструкторе. Данный подход был впервые реализован в C++, а так же используется в Ada и Rust.
Автоматический подсчёт ссылок (ARC)
Данный подход весьма похож на сборку мусора с подсчётом ссылок, однако, вместо запуска процесса подсчёта в определённые интервалы времени, инструкции выделения и освобождения памяти вставляются на этапе компиляции прямо в байт-код. Когда же счётчик ссылок достигает нуля, память освобождается как часть нормального потока выполнения программы.
Автоматический подсчёт ссылок всё так же не позволяет обрабатывать циклические ссылки и требует от разработчика использования специальных ключевых слов для дополнительной обработки таких ситуаций. ARC является одной из особенностей транслятора Clang, поэтому присутствует в языках Objective-C и Swift. Так же автоматический подсчет ссылок доступен для использования в Rust и новых стандартах C++ при помощи умных указателей.
Владение
Это сочетание RAII с концепцией владения, когда каждое значение в памяти должно иметь только одну переменную-владельца. Когда владелец уходит из области выполнения, память сразу же освобождается. Можно сказать, что это примерно как подсчёт ссылок на этапе компиляции. Данный подход используется в Rust и при этом я не смог найти ни одного другого языка, который бы использовал подобный механизм.
В данной статье были рассмотрены основные концепции в сфере управления памятью. Каждый язык программирования использует собственные реализации этих подходов и оптимизированные для различных задач алгоритмы. В следующих частях, мы подробнее рассмотрим решения для управления памятью в популярных языках.
Читайте так же другие части серии:
Ссылки
Вы можете подписаться на автора статьи в Twitter и на LinkedIn.
Для чего нужны стеки?

Jul 3, 2019 · 4 min read
Когда я узнал, что такое стек, мне стало интересно его практическое применение. Оказалось, что чаще всего эта структура используется для имплементации операции “Отмена” ( то есть, ⌘+ Z или Ctrl+ Z).
Чтобы понять, как это работает, разберемся с определением стека.
Что такое стек?
Стек — список элементов, который может быть изменён лишь с одной стороны, называющейся вершиной стека.

Представьте приспособление для раздачи тарелок, в котором тарелки стоят в стопке. Новые тарелки можно добавлять только поверх уже имеющихся, а брать можно лишь сверху. Таким образом, чем позже тарелку положат в стопку, тем раньше её оттуда возьмут. В рамках структур данных это называется LIFO-принципом (последним пришёл — первым ушёл).
Если использовать терминологию, то стек поддерживает операции добавления ( push) и удаления ( pop) элементов на его вершине.
Зачем использовать стек для отмены?
Потому что обычно мы хотим отменить последнее действие.
Стек позволяет добавлять элементы к его вершине и удалять тот элемент, который был последним.
Что произойдёт, если ни одно действие не будет отменено? Стек ведь станет огромным!
Верно. Если не удалять элементы из стека отмены, то есть не использовать операцию отмены, то он станет очень большим. Именно поэтому такие приложения, как Adobe Photoshop, с увеличением времени работы над файлом используют всё больше и больше оперативной памяти. Стек отмены хранит все действия, произведённые над файлом, в памяти до тех пор, пока вы не сохраните и не закроете файл.
Имплементация стека
Стек можно реализовать, используя либо связные списки, либо массивы. Я приведу пример реализации стека на обеих структурах на Python и расскажу о плюсах и минусах каждой.
Стек на связном списке:
Стек на массиве:
Что лучше?
В коде я указал сложность каждой из операций, используя “О” большое. Как видите, имплементации мало чем отличаются.
Однако есть некоторые нюансы, которые стоит учесть.

Массив
Это непрерывный блок памяти. Из-за этого при маленьком размере стека массив будет занимать лишнее место. Ещё один недостаток в том, что каждый раз при увеличении размера массива придётся копировать все уже существующие элементы в новую ячейку памяти.
Связный список
Он состоит из отдельных блоков в памяти и может увеличиваться бесконечно. Поэтому, с одной стороны, имплементация стека с использованием этой структуры немного лучше с точки зрения сложности алгоритма. С другой стороны, каждый элемент должен хранить адреса предыдущего и следующего элемента, что требует больше памяти.
Заключение
Так как динамический массив увеличивается в два раза при заполнении очереди, необходимость выделить дополнительную память будет возникать всё реже и реже. Кроме того, так как указатели не занимают много места, дополнительные данные в связных списках не критичны.
Как видим, между этими двумя реализациями стека практически нет различий — используйте ту, что нравится вам.
Урок №105. Стек и Куча
На этом уроке мы рассмотрим стек и кучу в языке C++.
Сегменты
Память, которую используют программы, состоит из нескольких частей — сегментов:
Сегмент кода (или «текстовый сегмент»), где находится скомпилированная программа. Обычно доступен только для чтения.
Сегмент bss (или «неинициализированный сегмент данных»), где хранятся глобальные и статические переменные, инициализированные нулем.
Сегмент данных (или «сегмент инициализированных данных»), где хранятся инициализированные глобальные и статические переменные.
Куча, откуда выделяются динамические переменные.
Стек вызовов, где хранятся параметры функции, локальные переменные и другая информация, связанная с функциями.
Сегмент кучи (или просто «куча») отслеживает память, используемую для динамического выделения. Мы уже немного поговорили о куче на уроке о динамическом выделении памяти в языке С++.
В языке C++ при использовании оператора new динамическая память выделяется из сегмента кучи самой программы:
Адрес выделяемой памяти передается обратно оператором new и затем он может быть сохранен в указателе. О механизме хранения и выделения свободной памяти нам сейчас беспокоиться незачем. Однако стоит знать, что последовательные запросы памяти не всегда приводят к выделению последовательных адресов памяти!
При удалении динамически выделенной переменной, память возвращается обратно в кучу и затем может быть переназначена (исходя из последующих запросов). Помните, что удаление указателя не удаляет переменную, а просто приводит к возврату памяти по этому адресу обратно в операционную систему.
Куча имеет свои преимущества и недостатки:
Выделение памяти в куче сравнительно медленное.
Выделенная память остается выделенной до тех пор, пока не будет освобождена (остерегайтесь утечек памяти) или пока программа не завершит свое выполнение.
Доступ к динамически выделенной памяти осуществляется только через указатель. Разыменование указателя происходит медленнее, чем доступ к переменной напрямую.
Поскольку куча представляет собой большой резервуар памяти, то именно она используется для выделения больших массивов, структур или классов.
Стек вызовов
Стек вызовов (или просто «стек») отслеживает все активные функции (те, которые были вызваны, но еще не завершены) от начала программы и до текущей точки выполнения, и обрабатывает выделение всех параметров функции и локальных переменных.
Стек вызовов реализуется как структура данных «Стек». Поэтому, прежде чем мы поговорим о том, как работает стек вызовов, нам нужно понять, что такое стек как структура данных.
Стек как структура данных
Структура данных в программировании — это механизм организации данных для их эффективного использования. Вы уже видели несколько типов структур данных, например, массивы или структуры. Существует множество других структур данных, которые используются в программировании. Некоторые из них реализованы в Стандартной библиотеке C++, и стек как раз является одним из таковых.
Например, рассмотрим стопку (аналогия стеку) тарелок на столе. Поскольку каждая тарелка тяжелая, а они еще и сложены друг на друге, то вы можете сделать лишь что-то одно из следующего:
Посмотреть на поверхность первой тарелки (которая находится на самом верху).
Взять верхнюю тарелку из стопки (обнажая таким образом следующую тарелку, которая находится под верхней, если она вообще существует).
Положить новую тарелку поверх стопки (спрятав под ней самую верхнюю тарелку, если она вообще была).
В компьютерном программировании стек представляет собой контейнер (как структуру данных), который содержит несколько переменных (подобно массиву). Однако, в то время как массив позволяет получить доступ и изменять элементы в любом порядке (так называемый «произвольный доступ»), стек более ограничен.
В стеке вы можете:
Посмотреть на верхний элемент стека (используя функцию top() или peek() ).
Вытянуть верхний элемент стека (используя функцию pop() ).
Добавить новый элемент поверх стека (используя функцию push() ).
Стек — это структура данных типа LIFO (англ. «Last In, First Out» = «Последним пришел, первым ушел»). Последний элемент, который находится на вершине стека, первым и уйдет из него. Если положить новую тарелку поверх других тарелок, то именно эту тарелку вы первой и возьмете. По мере того, как элементы помещаются в стек — стек растет, по мере того, как элементы удаляются из стека — стек уменьшается.
Например, рассмотрим короткую последовательность, показывающую, как работает добавление и удаление в стеке:
Stack: empty
Push 1
Stack: 1
Push 2
Stack: 1 2
Push 3
Stack: 1 2 3
Push 4
Stack: 1 2 3 4
Pop
Stack: 1 2 3
Pop
Stack: 1 2
Pop
Stack: 1
Стопка тарелок довольно-таки хорошая аналогия работы стека, но есть лучшая аналогия. Например, рассмотрим несколько почтовых ящиков, которые расположены друг на друге. Каждый почтовый ящик может содержать только один элемент, и все почтовые ящики изначально пустые. Кроме того, каждый почтовый ящик прибивается гвоздем к почтовому ящику снизу, поэтому количество почтовых ящиков не может быть изменено. Если мы не можем изменить количество почтовых ящиков, то как мы получим поведение, подобное стеку?
Во-первых, мы используем наклейку для обозначения того, где находится самый нижний пустой почтовый ящик. Вначале это будет первый почтовый ящик, который находится на полу. Когда мы добавим элемент в наш стек почтовых ящиков, то мы поместим этот элемент в почтовый ящик, на котором будет наклейка (т.е. в самый первый пустой почтовый ящик на полу), а затем переместим наклейку на один почтовый ящик выше. Когда мы вытаскиваем элемент из стека, то мы перемещаем наклейку на один почтовый ящик ниже и удаляем элемент из почтового ящика. Всё, что находится ниже наклейки — находится в стеке. Всё, что находится в ящике с наклейкой и выше — находится вне стека.
Сегмент стека вызовов
Сегмент стека вызовов содержит память, используемую для стека вызовов. При запуске программы, функция main() помещается в стек вызовов операционной системой. Затем программа начинает свое выполнение.
Когда программа встречает вызов функции, то эта функция помещается в стек вызовов. При завершении выполнения функции, она удаляется из стека вызовов. Таким образом, просматривая функции, добавленные в стек, мы можем видеть все функции, которые были вызваны до текущей точки выполнения.
Наша аналогия с почтовыми ящиками — это действительно то, как работает стек вызовов. Стек вызовов имеет фиксированное количество адресов памяти (фиксированный размер). Почтовые ящики являются адресами памяти, а «элементы», которые мы добавляем или вытягиваем из стека, называются фреймами (или «кадрами») стека. Кадр стека отслеживает все данные, связанные с одним вызовом функции. «Наклейка» — это регистр (небольшая часть памяти в ЦП), который является указателем стека. Указатель стека отслеживает вершину стека вызовов.
Единственное отличие фактического стека вызовов от нашего гипотетического стека почтовых ящиков заключается в том, что, когда мы вытягиваем элемент из стека вызовов, нам не нужно очищать память (т.е. вынимать всё содержимое из почтового ящика). Мы можем просто оставить эту память для следующего элемента, который и перезапишет её. Поскольку указатель стека будет ниже этого адреса памяти, то, как мы уже знаем, эта ячейка памяти не будет находиться в стеке.
Стек вызовов на практике
Давайте рассмотрим детально, как работает стек вызовов. Ниже приведена последовательность шагов, выполняемых при вызове функции:
Программа сталкивается с вызовом функции.
Создается фрейм стека, который помещается в стек. Он состоит из:
адреса инструкции, который находится за вызовом функции (так называемый «обратный адрес»). Так процессор запоминает, куда ему возвращаться после выполнения функции;
памяти для локальных переменных;
сохраненных копий всех регистров, модифицированных функцией, которые необходимо будет восстановить после того, как функция завершит свое выполнение.
Процессор переходит к точке начала выполнения функции.
Инструкции внутри функции начинают выполняться.
После завершения функции, выполняются следующие шаги:
Регистры восстанавливаются из стека вызовов.
Фрейм стека вытягивается из стека. Освобождается память, которая была выделена для всех локальных переменных и аргументов.
Обрабатывается возвращаемое значение.
ЦП возобновляет выполнение кода (исходя из обратного адреса).
Возвращаемые значения могут обрабатываться разными способами, в зависимости от архитектуры компьютера. Некоторые архитектуры считают возвращаемое значение частью фрейма стека, другие используют регистры процессора.
Знать все детали работы стека вызовов не так уж и важно. Однако понимание того, что функции при вызове добавляются в стек, а при завершении выполнения — удаляются из стека, дает основы, необходимые для понимания рекурсии, а также некоторых других концепций, которые полезны при отладке программ.



