Стори Поинты (Story Points)
Чтобы оценить объем работы над Элементом Бэклога Продукта, Скрам-команды обычно используют Стори Поинты. Это условная величина, позволяющая давать Элементам Бэклога относительные веса. Чаще всего для оценки в Стори Поинтах используются числа Фибоначчи (1, 2, 3, 5, 8, 13, …), что позволяет провести оценку достаточно быстро.
Ниже — перевод статьи Джеффа Сазерленда Story Points: Why are they better than hours? с сайта Scrum Inc.
Чем Стори Поинты лучше человеко-часов?
Стори поинты дают более точную оценку, существенно уменьшают время планирования, позволяют лучше прогнозировать дату релиза и повышают производительность команд. Традиционная оценка в человеко-часах является менее точной, приводит к лишним потерям времени на оценку, мешает Владельцу Продукта планировать релиз и не позволяет команде понять, какие из внедренных улучшений процесса действительно сработали.
Точность оценок
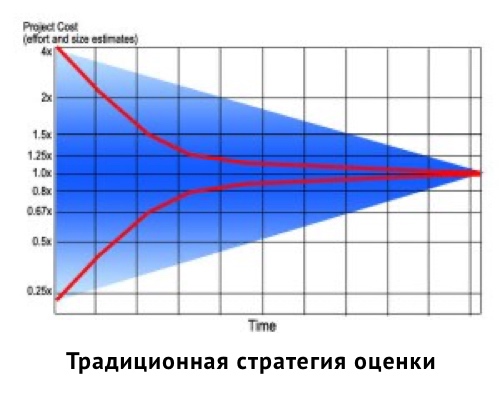
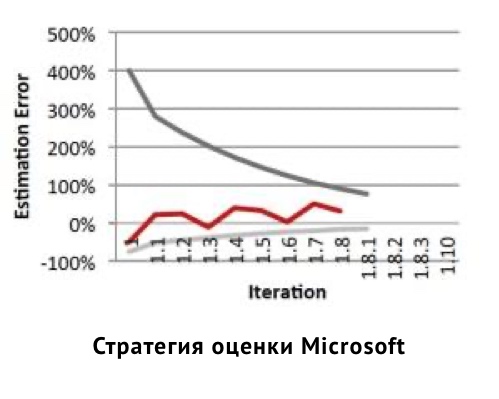
Последние исследования от Microsoft показывают, что оценка по agile демонстрирует поразительную точность в сравнении с традиционными методами оценки проектов. Подробнее об этом исследовании вы можете почитать здесь:
Scrum + Engineering Practices: Experiences of Three Microsoft Teams
Многим людям, имевшим опыт управления проектами с оценкой в часах, сложно понять, почему стори поинты работают лучше. Им также сложно принять некоторые фундаментальные факты, которые публикуются в профильной литературе уже в течение 60 лет, равно как и последние исследования, которые только подтверждают их правильность.
Успешность проектов
Давайте посмотрим на последние данные по неуспешным проектам. Глобальная финансовая система рушится, и вместе с этим растет процент провальных проектов в IT. Недавно было проведено одно интересное исследование: консалтинговая фирма Standish Group собрала данные об успешности нескольких десятков тысяч проектов, стартовавших за последние десять лет. Аналитика от Standish Group показывает, что процент успешности agile-проектов в три раза превышает успешность проектов, ведущихся традиционным образом. Джим Джонсон рекомендует использование agile-практик на всех без исключения проектах.
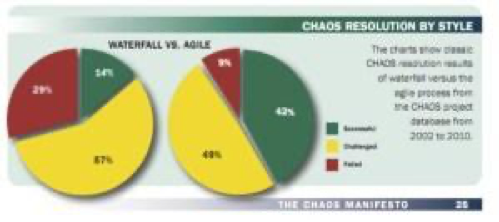
Разрыв между оценками сроков и реальностью
Венчурные капиталисты, с которыми я работаю, признаются, что никогда не видели актуальную диаграмму Ганта на встречах правления компаний. Исследуя проблему глубже, они обнаружили, что до внедрения скрама никто из руководства вообще не знал реальной производительности своих команд, и это в 100% случаев озвучивается на встречах правления как главная причина несоблюдения даты релиза.
Дело в том, что для планирования релиза критичным является постоянство пользовательских историй. Три стори поинта сегодня — это те же три стори поинта в следующем году, и для Владельца Продукта эти стори поинты являются измеримой частью релиза продукта. Тогда как количество часов для завершения истории зависит от того, кто ее делает и в какой день. Эти показатели меняются ежедневно. Диаграмма Ганта предполагает фиксированное количество часов на задачу для какого-то гипотетического человека (который зачастую не является фактическим исполнителем задачи) и заведомо известные зависимости (которые на самом деле непрерывно меняются). Исследование восьмидесяти мультимиллионных проектов, проведённое в GSI Commerce (ими сейчас владеет eBay), показало, что лучшие эксперты в компании оказались неспособными правильно оценить время выполнения проекта людьми, которые действительно его реализовывали.
Вам может показаться, что эта статистика могла бы заставить людей поменять своё поведение, но многим компаниям, похоже, проще продолжать терпеть убытки или даже банкротство вместо того, чтобы изменить свои принципы управления проектами.
Вариабельность оценок
Исследование, проведенное Rand Corporation еще в 1940х годах, очевидно продемонстрировало неспособность людей точно проводить оценку в часах, и практический опыт постоянно подтверждает этот факт. Вместо часов для оценки рекомендуется использовать метод «Дельфи», известный в разработке программного обеспечения как техника Wide Band Delphi. Аналогичная техника используется agile-командами и носит название Покер планирования.
Интересные данные по личной продуктивности разработчиков пришли из Йельского Университета. Лучшему разработчику на проекте требуется один час, чтобы сделать задачу, в то время как худшему требуется 10 часов (в рамках его проекта) или даже 25 (если проект незнакомый). Для команд эта разница еще на порядок больше. Данные, опубликованные Ларри Путнемом (Larry Putnam) показывают, что задача, на которую наиболее продуктивной команде требуется час, может превратиться в 2000 часов для наименее продуктивной команды.
Процесс оценки в стори поинтах дает лучшую точность, чем оценка в часах, за счет меньшей вариативности стори пойнтов. Одна компания 5го уровня CMMI определила, что оценка в стори поинтах сокращает время оценки на 80%, что позволяет оценивать больше фич и отслеживать их, в сравнении с каскадной моделью. Другая компания из телеком индустрии заметила, что оценка с помощью стори поинтов и Покера планирования была не только в 48 раз быстрее, чем практики каскадной оценки, но и дала более точные результаты.
Мера прогресса
Для руководства мерой прогресса является законченный функциональный элемент, поэтому важно, чтобы каждая поставка была новым шагом на этом пути. Рабочий функционал является предусловием для получения прибыли, а ведь любая компания создается для увеличения прибыли (даже если при планировании проекта неосознанно делается прямо противоположное). По крайней мере, венчурные капиталисты уверены в том, что компании работают ради денег, и для денег важны скорость производства и качественный продукт. А человеко-часы — это затраты, которые необходимо уменьшать или вообще избавляться от них везде, где это возможно.
Число потраченных часов не дает Владельцу Продукта никакой информации о том, сколько фич можно поставить и когда.
Что действительно является важной метрикой, так это количество стори поинтов, которую команда может поставить за календарный период. Число поинтов за спринт — это производительность команды (velocity). И несмотря на то что все оценки происходят в стори поинтах, Владелец Продукта делает план релизов на основании производительности команды и корректирует его, если эта производительность меняется.
Таким образом, стори поинты быстрее, лучше и дешевле часов, и высокоэффективные команды повсеместно отказываются от оценок в часах как от лишней нагрузки, которая замедляет их и тянет вниз.
Jeff Sutherland, 2013
Диаграмма Сгорания Работ Спринта визуально показывает прогресс Команды в Стори Поинтах по дням спринта. Это графическое представление того, сколько работы уже сделано и сколько еще остается сделать. Диаграмма позволяет Команде прогнозировать успех Спринта и предпринимать меры, чтобы к моменту окончанию Спринта все запланированные задачи были были завершены.
Информация, которая требуется команде для понимания и выполнения работы над Элементом Бэклога Продукта. Описание критериев готовности Элементов к разработке должно быть таким, чтобы для выполнения работы команде не требовалось дополнительных обсуждений и исследований. Такие Элементы можно принять в работу немедленно (они Immediately Actionable). Например, Элементы можно проверять на соответствие критериям I.N.V.E.S.T.
Критерии Приемки (Acceptance Criteria)
Специфические требования и приемочные тесты, которым должны соответствовать Элементы Бэклога Продукта, чтобы работа по ним считалась завершенной с точки зрения клиента / Владельца Продукта. Определение Критериев Приемки звучит очень похоже на Критерии Готовности, но в действительности эти понятия отличаются: Критерии Приемки касаются требований клиента к конкретному Элементу Бэклога, а Критерии Готовности формируются командой и касаются многих Элементов.
Оценка (Estimation)
Оценка – это прогнозирование усилий, которые потребуются для завершения работы над Элементом Бэклога Продукта. Она обеспечивает Владельцу Продукта и Скрам-мастеру уверенность в дате релиза и является базой для расчета производительности Команды. Существует множество способов оценки усилий Скрам-командой, но при этом всегда используются относительные единицы: например, Стори Поинты. Обычно оценка проводится в рамках Уточнения (Груминга) Бэклога Продукта.
Величина, отражающая количество работы, которое Скрам-команда может выполнить за один Спринт. Является важной метрикой в Скраме. Производительность вычисляется в конце Спринта как сумма Стори Поинтов по всем полностью завершенным Элементам Бэклога Спринта.
Мы хотим, чтобы компании были крутыми, а люди в них — счастливыми
Стори поинты: как это работает
![]()
Сколько усилий нужно потратить на задачу? В условиях неопределенности и сложности ответ лучше дать не в часах. Куда удобнее относительные единицы, из которых самые известные — стори поинты. Мы перевели статью Майка Кона о том, какие факторы нужно учитывать, оценивая работу в стори поинтах, и как согласовывать эти факторы между собой. Бонус — список типичных ошибок в применении стори поинтов.
Стори поинтами измеряют усилия, которые нужны, чтобы выполнить элемент бэклога продукта или любой другой отрезок работы.
Пользуясь стори поинтами, мы присваиваем каждому элементу (работы) некое количественное значение. Сами по себе эти количественные оценки не важны. Важно то, как оценки разных элементов соотносятся друг с другом. История, которой присвоено значение 2, должна быть вдвое больше истории со значением 1 и соответствовать двум третям истории со значением 3.
Вместо единицы, двойки и тройки команда могла бы использовать цифры 100, 200 и 300. Или 1 миллион, 2 миллиона, 3 миллиона. Важно соотношение, а не цифры как таковые.
Что включают в стори поинт?
Поскольку стори поинты выражают усилия для выполнения истории, команда должна оценить все, что повлияет на эти усилия. Это может быть:
Измеряя работу стори поинтами, обязательно оцените каждый из этих факторов.
Объем работы

Чем больше работы необходимо выполнить, тем, очевидно, больше должен быть условный показатель усилий. Возьмем разработку двух веб-страниц. На одной должно быть только одно поле и просьба ввести имя. На второй странице полей для текста должно быть 100.
Вторая страница не сложнее первой. Она не предусматривает взаимодействия между полями, и заполнять их не нужно ничем, кроме текста. Ее разработка не связана ни с какими рисками. Единственное отличие двух страниц — на второй сделать нужно больше.
Второй странице стоит присвоить больше стори поинтов. Может, не в 100 раз больше, хотя на ней и во 100 раз больше полей. В конце концов, существует эффект масштаба, так что в реальности мы можем затратить на вторую страницу всего в 2, 3 или в 10 раз больше усилий, чем на первую.
Риски и неопределенность

Нужно включать в оценку и риски или неопределенные моменты в работе. Например, команде бывает нужно оценить элемент бэклога, о котором стейкхолдер не может сказать ничего конкретного. Похожая ситуация: нужно давать наценку по сложности, когда внедрение фичи требует переписать старый ненадежный код без автотестов.
Неопределенность как таковая отражена уже в самой последовательности чисел для стори поинтов, которая напоминает ряд Фибоначчи: 1, 2, 3, 5, 8, 13, 20, 40, 100. Какое бы число вы не выбрали, усредненная неопределенность уже заложена в него — если, конечно, вы используете именно такое соотношение чисел.
Сложность

Также нужно учитывать сложность. Вернемся к нашей странице со 100 полями, между которыми нет взаимодействий.
А теперь представим себе другую страницу со 100 полями. Часть из них — поля с датами и, соответственно, календарными виджетами. В другой части можно вводить только ограниченное количество символов: например, номера телефонов. Есть и поля, в которых проверяется контрольная сумма (например, с номерами банковских карт). Кроме того, есть взаимодействия между полями. Для карты Visa страница должна выдавать поле с трехзначным CVV-кодом, а для карты American Express — с четырехзначным.
Хотя на экране по-прежнему 100 полей, разработка будет сложнее, а значит, займет больше времени. Растет вероятность, что разработчик ошибется и ему придется откатить какие-то из изменений и переделать работу.
Учитывайте все эти факторы
Может показаться, что невозможно отобразить три фактора в одном числе, но это не так. Объединяющим фактором должны стать необходимые усилия. Сначала оценивающие учитывают, какими могут быть общие трудозатраты по каждому элементу бэклога.
Потом нужно оценить, как на трудозатраты повлияет риск. Для этого стоит озвучить риски и оценить их влияение. Например, больше стори поинтов стоит присвоить элементу с более высокой степенью риска, особенно если он потребует выполнить больший объем работы, а не элементу, с которым проблемы менее вероятны.
И наконец, необходимо оценить сложность. Она может потребовать больше осмысления, проб и ошибок, коммуникации с заказчиком, проверки и времени на исправление ошибок.
Обратите внимание на Definition of Done
Оценка в стори поинтах должна учитывать все, что потребуется для доведения элемента бэклога до состояния готовности. Если в определениях готового у команды указаны автотесты для проверки истории (а это хорошая мысль), то в оценке должны быть учтены и усилия на написание тестов.
Типичные ошибки
Узнайте больше на наших ближайших тренингах.
Переведено и адаптировано командой BrainRain по материалам:
Понимание относительных оценок в Agile. Даёшь Story Points!
В своей работе со Scrum-командами, я столкнулся с непониманием членов команды, как правильно оценивать задачи или user story. Из этого и родилась потребность в написании статьи, с помощью которой (я надеюсь), я смогу уложить знания в своей голове, лучше объяснять методику командам, а также помочь всем, кто будет ее читать эффективно и быстро оценивать задачи в своих проектах.
В этой части я не буду отвечать на вопрос «зачем вообще нужны оценки?», надеюсь, что на данный вопрос вы сами знаете ответ или на него уже ответил ваш руководитель, спонсор или инвестор. Я начну рассказ с сравнения относительных и абсолютных оценок.
В старой последовательной «водопадной» методологии разработки программного обеспечения и продуктов, где нельзя начать следующий этап без завершения предыдущего, существовало классическое деление на отделы: отдел разработки, отдел дизайна, отдел аналитики и т.д. Таким образом, техническое задание, пройдя через отдел архитектуры, аналитики, разработки (последовательность и наполнение зависели от организационной структуры и размера конкретной организации), обрастало деталями, дополнительными требованиями, архитектурными изысканиями и тому подобными артефактами. Финально получалась оценка в человеко-днях (или man day — md, терминология использовалась у одного из моих бывших работодателей). Считалось, а где-то до сих пор считается, что данный подход позволяет получить детальный бюджет проекта (смету) с точными абсолютными трудозатратами, на основе чего верстался портфельный бюджет и закладывался весь бюджет организации.
Однако, у данного подхода есть ряд существенных недостатков:
Как итог: у нас нет времени для детальной и точной оценки, но и ценности в этой оценке, по большому счету нет. Наша основная цель: понять сколько задач команда может взять в итерацию (спринт), для этого нам точно подойдет относительная оценка и дальше я расскажу, что же она из себя представляет применительно к гибким методологиям.
На тренингах команд я использую пример, который, на мой взгляд, хорошо иллюстрирует относительную оценку и ее применимость в современных реалиях.
Итак, для начала давайте представим себя астрофизиками, которым необходимо решить задачу по определению диаметров планет Солнечной системы:
Сможете сходу назвать диаметр такой планеты, как Уран?
Без помощи Google, ответить на этот вопрос тем из нас, у кого не было пятерки по астрономии будет сложно, задача потребует значительного времени и даже после этого совершенно точно будут разные варианты оценки.
Кто-то решит, что 22 750
Мы будем спорить и потратим очень много времени, чтобы договориться и выбирать лучший ответ, причём кто-то из команды все равно останется не довольным результатом.
Когда мы сравниваем объекты между собой, оценка становится проще и в команде возникает меньше споров и противоречий.
В этом и есть разница и проблема между абсолютной и относительной оценкой.
В приведенных мною выше примерах использовалась оценка в днях, также есть практика оценки задач в часах, что является примером абсолютной оценки. В Scrum пользовательские истории оцениваются относительно и при оценке используются Story Points.
Абсолютная оценка = Часы
Относительная оценка = Story Points
Story Pointы не имеют физических единиц оценки. Но я сталкивался с ситуациями, когда команды пытаются приравнять их ко времени, например, что 1 SP = 1 часу или дню, тем самым мы просто возвращаемся к абсолютной оценке. Важно помнить о том что мы должны оставаться в относительной шкале и задача Scrum мастера донести эту концепцию до команды и Product Ownera. Можно использовать пример с планетами, стаканом фасоли или другими сравнимыми вещами. Также, при продуктовом подходе, стоит помнить, что мы экспериментируем, мы ещё не знаем будет ли успешен наш продукт на рынке и сделаем ли мы удачный инкремент в этом спринте. Scrum Фреймворк предполагает процесс непрерывного улучшения на основе полученного опыта.
Эксперимент важен, он позволяет команде постоянно совершенствоваться и становиться эффективнее и относительная оценка помогает в этом, так как за основу оценки, мы берём задачи, которые команда уже делала. Таким образом оценка со временем становится все лучше, а результат все более прогнозируемым.
Для себя я выделяю 3 основных принципа, при которых оценка будет эффективна для команды и проекта в целом.
Методов относительной оценки множество, описание их механик тянет на отдельную статью. Я склоняюсь к самым простым, чтобы команде можно было быстро и легко начать их использовать. Далее расскажу об одном из них:
Мы, также используем размер XXL когда появляется задача с очень высоким уровнем неопределенности и такую «майку» точно необходимо декомпозировать на более мелкие.
Product Owner рассказывает команде контекст задачи, как он ее видит, после чего все члены команды «вслепую» (исключаем влияние на оценки) дают свои оценки ведущему (Scrum мастеру). Далее, слово предоставляется участнику, давшему самую высокую и самую маленькую оценку задаче. Выслушав их члены команды договариваются готовы ли они повысить или понизить свою оценку на основе услышанного, в итоге команда должна придти к единому мнению.
Не меняйте метод оценки часто, важно наблюдать за эволюцией команды, первые 1-2 спринта оценки могут не соответствовать полученным результатам, помните про эксперимент. Проводите ретро и обсуждайте с командой почему результат показал отклонение от первоначальных ожиданий, с помощью чего его можно улучшить, что необходимо предусмотреть.
Большое спасибо, что вы дочитали до конца! Я очень надеюсь, что мне удалось донести смысл оценочной системы и привести примеры ее работы. Буду рад и благодарен за любые комментарии или критику в свой адрес.
Оценка задач в Story Points
Практически каждый человек, который сталкивался с разработкой ПО знает что такое оценка задач в Story Points (SP), тем не менее периодически мне доводится рассказывать коллегам из других отделов или новичкам в команде, которые ни разу не сталкивались с таким подходом, зачем мы используем SP и почему это удобно для команды и эффективно для компании.
Цель этого текста – рассказать, что такое SP, как их использовать для оценки задач и почему эта методика получила такое широкое распространение.
Проблема
Расчет времени, необходимого на выполнение задачи одновременно и очень простая и очень рискованная задача, с которой сталкиваются команды разработки.
Неверная оценка становится одной из первых причин срыва графиков или даже провала проекта.
Проблема в том, что бизнес рассматривает оценки как обязательства. Разработчики рассматривают оценки как предположения.
Для иллюстрации я приведу в пример вымышленный диалог из книги Роберта Мартина «Идеальный программист».
Майк (Менеджер): Какова вероятность того, что ты справишься за три дня?
Питер (Разработчик): Пожалуй, справлюсь.
Майк: Можешь назвать число?
Питер: Пятьдесят или шестьдесят процентов.
Майк: Значит, есть довольно высокая вероятность, что тебе понадобится четыре дня?
Питер: Да. может понадобиться даже пять или шесть, хотя я в этом сомневаюсь.
Майк: До какой степени сомневаешься?
Питер: О, я не знаю… Я на девяносто пять процентов уверен, что работа будет сделана менее чем за шесть дней.
Майк: То есть может быть и семь?
Питер: Ну, если все пойдет наперекосяк… Черт, если ВСЕ пойдет наперекосяк, может быть десять и даже одиннадцать дней. Но ведь вероятность такого совпадения очень мала, верно?
Я думаю, что диалог выше звучит довольно знакомо для любого разработчика или менеджера проекта.
К сожалению, проблемы с оценками на этом не заканчиваются. Следует так же учитывать и другие подводные камни:
Корреляция оценки и оценивающего
Выставленная оценка справедлива только в том случае, если реализовывать задачу будет автор оценки. Ведь очевидно, что время, затраченное на задачу старшим разработчиком и интерном будет отличаться.
Идеальная оценка в неидеальном мире
Срочные встречи, рабочие письма, мессенджеры и упавший таск-менеджер еще больше запутывают и без того сложный процесс разработки, что делает идеальные часы, которые мы воображаем во время выставления оценок слабо полезными для менеджера проекта, пытающего собрать стремительно устаревающую диаграмму Ганта.
Далее мы рассмотрим подход к оценке задач в SP и то, каким образом он адресует все описанные выше сложности.
Альтернативные решения
Естественно, подход с использованием SP не первая попытка решить озвученные проблемы, хотя и, вероятно, самый популярный.
В этом блоке я расскажу еще об одной программе, включающей в себя схему оценки задач. Программы называется PERT и знакомство с ней не обязательно для достижения цели тексты, поэтому можно смело перейти к следующему блоку.
PERT или Program Evaluation and Review Technique была разработана в 50-е годы XX века в ВМС США.
Для оценки задачи по схеме представляются три числа:
O: предельно оптимистическая оценка. Задача может быть выполнена в эти сроки только если все без исключения пройдет как задумано.
N: номинальная и наиболее вероятная оценка.
P: крайне пессимистическая оценка, в которую заложены все неприятности, которые могут произойти во время выполнения задачи.
По этим трем оценкам ожидаемая продолжительность задачи описывается следующей формулой:

А среднеквадратическое отклонение, фактически являющееся мерой неопределенности задачи вычисляется по формуле:

Таким образом задачу, которую обсуждали Питер и Майк можно оценить в:

Как видим данный метод заставляет оценивающего задумываться не только о позитивных, но и негативных сценариях и даже использует элемент статистики. Но, к сожалению, не отвечает на все поставленные вопросы и к тому же весьма усложняет сам процесс оценки.
Story Points
Что же такое Story Points и как они помогают оценивать задачи? Весьма коротко и понятно об этой технике рассказывает в своем видео Майк Кон евангелист Agile и CEO компании Mountain Goat Software.
Что если вместо оценки времени, которое потребуется для выполнение задачи мы будем оценивать усилия, необходимые на решение этой задачи? Для этого мы примем шкалу оценки и расставим на ней задачи, требующие оценки.
При этом в оценку усилий следует заложить все факторы, которые могут повлиять на нее:
Хочется подчеркнуть два важных аспекта метода Story Points, которые позволяют ему решать проблемы, которые мы обсудили на предыдущей странице:
Относительность оценки
Задачи оцениваются относительно друг друга, таким образом возникает универсальная шкала оценки, не зависящая от опыта оценивающего. Даже если у задачи сменится ответственный — ее оценка останется неизменной, достаточно новые задачи оценивать относительно этой шкалы.
Замена часов на абстрактные баллы
Так мы снимаем с оценивающего необходимость оценивать задачу в часах. Вместо этого он оценивает ее в баллах, таким образом мы убираем противоречия в восприятии оценки разработчиком и менеджером. Более того, теперь отвлекающие факторы и форс-мажорные обстоятельства никак не повлияют на оценку, ведь они не меняют усилия, требующиеся для решения задачи!
Числа Фибоначчи, майки и собаки
Да, да майки и собаки. Для оценки задач можно использовать любую шкалу. Самой распространенной являются числа Фибоначчи, это понятные числовые значения к тому же с приятным бонусом: элементы этой последовательности хорошо отражают рост неопределенности, который возникает с ростом сложности оцениваемой задачи.
Тем не менее некоторые команды используют альтернативную шкалу оценки. Самые распространенные это оценка в майках и собаках, когда сложность задачи указывается в размере майки (S, M, L, XL) или в породе собаки (Чихуахуа, Мопс, Дог). Таким образом команды еще больше абстрагируются от численного представления оценки, которое в некоторых случаях так и подмывает перевести в оценку временную.
 | |
Оценка в команде
Чем отличается оценка в команде от индивидуальной оценки?
Почему важно привлекать всю команду к выставлению оценок?
Одна из самых больших ошибок, которые можно допустить при оценке задач — сделать ее самостоятельно и не спросить мнения членов команды. Может быть у них есть свое мнение по этому поводу? Хотите добавить поддержку нового браузера? А что по этому поводу думают QA?
Люди — самый важный ресурс оценки. Они могут увидеть то, что не видите Вы.
Но как проводить оценку командой? Просто выкрикивать оценки не очень эффективно, к тому же услышав вашу оценку другой член команды может передумать и не станет озвучивать свою.
Покер планирования
В 2002 году Джеймс Греннинг описал метод, который впоследствии стал настолько популярным, что теперь Вы даже можете купить настоящие колоды карт для покера планирования. Или воспользоваться одним из онлайн сервисов для проведения сеанса;
Суть метода заключается в следующем: всем участникам команды раздаются карты с числами из шкалы оценки. Затем выбирается задача и обсуждаются требования к ней. После обсуждения модератор просит всех членов команды выбрать карту и положить ее «рубашкой» вверх. Затем модератор дает сигнал показать карты.
Если оценки участников согласуются – оценка фиксируется, в противном случае карты возвращаются в руку, а члены команды продолжают обсуждение задачи. Хорошая идея — спросить у выставивших разные оценки: «Какие сложности ты видишь в этой задаче?» или «Почему ты считаешь, что во время реализации не возникнет никаких проблем?».
Стоит отметить, что согласие не должно быть абсолютным. Вы можете условиться, что набор соседних оценок так же считается согласием.
Альтернативы
Как и самого метода оценки, так и у покера планирования есть альтернативы. Я вкратце расскажу о одной из них.
Этот блок можно пропустить и перейти сразу к следующей странице.
Об этом методе я узнал все из той же книги Роберта Мартина «Идеальный программист. Суть метода заключается в том, что все задачи записываются на картах без каких либо оценок. Экспертная группа стоит возле окна или стены, на которой карты распределены случайным образом. Участники не говорят между собой — они просто сортируют карты. Карты задач, требующих больше усилий, перемещаются вниз, требующих меньше усилий смещаются наверх.
Любой участник группы может в любой момент переместить любую карту, даже если она уже была перемещена другим участником. Карты перемещенные несколько раз, откладываются в сторону для обсуждения. Со временем безмолвная сортировка завершается и начинается обсуждение.
На следующем этапе между картами рисуются линии, представляющие усилия, требующиеся для реализации задач.
Стоит отметить, что подход с использованием таких категорий или „корзин“ можно использовать и в классическом покере планирования.
Планирование проекта
Сколько часов в Story Point’e и как мне построить диаграмму Ганта?
Итак, мы оценили наш бэклог задач, но на Story Point’ах план проекта не построишь. Часто у руководителя проекта возникает вопрос: „Как перевести SP в часы?“.
Короткий ответ на этот вопрос: „Никак“.
Конечно, можно с секундомером ходить за разработчиками и записывать время, которое им понадобилось на решение задачи, а затем вывести эту информация в виде графика. Тогда у вас получится классический „колокол“, как на примере в блоке ниже. Как мы видим на первом рисунке – некоторые задачи занимают чуть больше времени, некоторые чуть меньше, но в целом все значение будут соответствовать некоторому нормальному распределению.
То же самое справедливо и для задач в 2 SP и это показано на втором рисунке. Заметили, что „хвосты“ графиков пересекаются? Да, некоторые задачи оцененные в 1 SP могут потребовать больше усилие чем самые простые из оцененных в 2 SP. В конце концов ни одна команда еще не научилась оценивать идеально. Кроме того переводя SP в часы мы возвращаемся к старым граблям, то, сколько времени понадобится разработчику для решения конкретной задачи сильно зависит от самого разработчика.
| |
Но что же делать, мы не можем полностью отказаться от планирования. К счастью, для этого нам не нужно переводить каждый Story Point в часы. Что действительно важно, так это сколько SP команда разработки может „закрыть“ за спринт (итерацию, релиз).
Собирая данные о скорости команды можно получить достаточно точные данные для долгосрочного планирования проекта. К тому же не забывайте про закон больших чисел, погрешности оценок взаимно компенсируются, это касается как задач, так и итераций. Стоит отметить, что это немного оптимистично, т.к. погрешности обычно связаны с недооценкой, а не переоценкой. Но ничто не идеально.
Скорость (или Velocity) это мощный инструмент планирования и главная метрика команды разработки. Команда должна работать над постоянным улучшением, чтобы повысить свою скорость. Не стоит так же забывать, что скорость это производная величина от SP и поэтому тоже относительна. Нельзя сравнивать две команды друг с другом, команда соревнуется сама с собой.
Практика
Какие нюансы нужно знать?
Каких ошибок можно избежать?
В заключении хочется собрать несколько советов для тех, кто в первый раз решил попробовать описанные методики в своей работе.
Это ваш первый покер планирования и команда не понимает относительно чего оценивать новые задачи. Соберите несколько уже реализованных задач, в идеале хорошо всем знакомых или типовых и оцените их сложность относительно друг друга. Используйте эти задачи для оценки новых.
У вас новый проект и нет реализованных задач? Попробуйте воспользоваться афинной оценкой, которая описана выше, и распределите задачи по шкале оценок.
Не усредняйте оценки
Но, как и говорилось выше, вы всегда можете договориться о том, что близкие друг к другу оценки не будут являться поводом для дальнейшего обсуждения.
Даже если в ходе реализации вы поняли, что ошиблись при планировании, оставьте оценку неизменной. Вы будете ошибаться и в будущем, причем в обе стороны. Дайте этим ошибкам компенсировать друг друга, не вмешивайтесь в процесс.
Я сталкивался с разными подходами к оценке багов. Некоторые команды оценивают все баги, кроме тех, что возникли в ходе реализации новых задач в итерации. Некоторые не оценивают баги, обосновывая это тем, что скорость команды должна показывать новую ценность, которая добавляется в продукт, и исправление багов не должно влиять на рост этого показателя.
Какой бы подход вы выбрали оставайтесь последовательными. Информация об исторический скорости команды не должна пострадать от применения разных подходов к оценке.
Еще один вопрос, который не имеет однозначного ответа. Кто-то считает, что не бывает задач, не требующих усилий. Другие отвечают им, что назначение баллов простейшим задачкам ведет к необоснованному росту графика скорости команды.
Вы можете ввести оценку в 1/2 балла для таких задач и ретроспективно отслеживать не превышает ли доля таких задач разумные пределы. Но главный совет все тот же, оставайтесь последовательными в своих решениях.
Переоценка незаконченных задач между итерациями
Не всегда удается закончить задачу в одну итерацию, даже если это планировалось изначально. Тем не менее не стоит изменять ее оценку при планировании следующей итерации исходя из количества оставшейся работы. Учитывайте это при планировании, но оставьте оценку неизменной для истории.
Если вы еще не проводите ретроспективы – пора начать! Это отличный командный инструмент повышения скорости и слаженности команды. Впрочем это отдельная тема.
В ходе ваших ретроспектив пройдитесь по оценкам, которые были сделаны при планировании итерации и обсудите не случилось ли больших отклонений между ожиданиями и реальностью.
Можно так же достать из истории несколько задач с одинаковыми оценками и обсудить действительно ли все эти истории потребовали одинакового количества усилий.
Если ваша система управления задачами не поддерживает оценки и не считает скорость команды автоматически, значит вам придется делать это вручную. Как Вы, наверняка, уже догадались исторические данные важный инструмент совершенствования ваших оценок.



