Что такое база данных в информатике
Что такое база данных в информатике
Табличный процессор Excel позволяет обрабатывать табличные данные. Существуют специальные системы или приложения, которые решают иные классы задач. К ним относят программы, предназначенные для хранения информации и выдачи данных в соответствии с запросом пользователя.
Основным понятием для данного спектра задач является база данных в виде файла или группы файлов со стандартной структурой. С их помощью обеспечивается хранение данных.
База данных представляет собой комплекс массивов и файлов данных, организованный согласно определенным правилам, который предполагает применение стандартных принципов для описания, хранения и обработки данных любого типа.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
База данных является совокупностью организованной информации, имеющей отношение к конкретной предметной области. Информация хранится во внешней системной памяти компьютера и рассчитана на постоянное применение. Ключевое свойство базы данных заключается в независимости данных от программы, которая эту информацию использует. Стандартные задачи, требующие решения при работе с базой данных:
Необходимость в применении баз данных возникла по причине накопления больших объемов информации одного типа, которую требовалось оперативно использовать. Главное требование к базам данных заключается в обеспечении удобного доступа к информации, возможности получать ответ по запросу в течение короткого времени, умения оперативно использовать данные. Принципы формирования информации в базах данных:
Реляционную модель баз данных предложил Эдгар Кодд в конце 70-х годов. Она являлась набором таблиц, которые были связаны друг с другом отношениями. Такая модель отличалась простотой, гибкостью, обладала возможностями для описания сложно структурированных данных.
Основные понятия
Важным понятием, которое связано с базой данных, является программа для работы с ней. Программа для работы с базой данных должна быть способной обеспечить решение необходимого спектра задач из стандартного перечня.
Реляционные базы данных состоят из связанных таблиц.
Таблица является двумерным массивом, необходимым для хранения данных.
В таблице столбцы представляют собой поля, а строки – записи. Число полей строго определено, а количество записей может быть любым. Таблица является нефиксированным массивом записей, которые имеют одинаковую структуру полей в каждой записи. Добавление новой записи выполняется оперативно. Создание нового поля сопровождается реструктуризацией всех таблицы и сопровождается определенными трудностями.
Примеры значений полей:
Местом хранения таблиц является жесткий диск. Одной таблице соответствуют, как правило, несколько файлов, один из которых является основным, а другие – вспомогательными. Особенности организации таблиц определяются используемым форматом, например:
Ключом называют поле или комбинацию полей таблицы, значения которых однозначно определяют запись.
При наличии значений ключевых полей представляется возможным однозначно получить доступ к необходимой записи. Сохраняя значения ключа в выбранные поля подчиненной таблицы и создавая ссылку, пользователь обеспечивает связь двух записей:
Одна запись подчиненной таблицы допускает наличие нескольких ссылок на записи ключевой таблицы. Помимо связывания, ключи обеспечивают прямой доступ к записям, ускоряют работу с таблицей.
Индекс представляет собой поле, специально определенное в таблице, с данными, которые могут повторяться.
С помощью индексов ускоряют доступ к данным. Кроме того, с их помощью сортируют выборки.
Нормальными называют формы, предназначенные для автоматизации процесса создания баз данных.
При разработке баз вручную, проектировщику необходимо составить структуру, спланировать необходимые таблицы. С помощью нормальных форм можно фактически формализовать интуитивно понятные требования к организации данных, что позволяет исключить избыточное дублирование информации.
Первая нормальная форма:
Вторая нормальная форма:
Третья нормальная форма:
Способы доступа определяют, каким образом с технической точки зрения выполняются операции с записями.
Способы доступа определяет программист, разрабатывая приложения. В основе навигационного метода лежит обработка необходимых записей по одной. Как правило, такой способ применяют в случае работы с небольшими локальными таблицами. Реляционные метод базируется на одновременной обработке набора записей с помощью SQL-запросов. Такой способ целесообразно применять для больших удаленных баз данных.
Транзакции – определяют степень надежности реализации операций относительно сбоев.
Транзакция объединяет в себе последовательность действий, которая либо выполняется целиком, либо не выполняется вовсе. При возникновении сбоя результаты всех операций, включенных в транзакцию, будут отменены. Такой подход гарантирует корректность базы данных во время технических сбоев.
Бизнес-правила – такие правила, которыми определено проведение операций, являются механизмами управления базами данных.
Заданные определенные ограничения в значениях полей способствуют поддержанию корректности базы.
Признаки БД, чем отличаются от электронных таблиц
Любая база данных обладает набором стандартных признаков. Основными из них являются:
Первый признак соблюдается строго, остальные могут трактоваться по-разному и иметь неодинаковые степени оценки. Согласно общепринятой практике, к базам данных не относят файловые архивы, интернет-порталы или электронные таблицы.
Рассмотреть базу данных целесообразно на примере Access. Это специальное приложение, в котором хранятся упорядоченные данные, что допускает применение и других приложений (к примеру, Excel). В обоих случаях информация представлена в табличном виде.
Excel включает особые средства, позволяющие работать с упорядоченными данными, позволяет формировать простые базы данных. При внешнем сходстве приложения обладают рядом отличий:
Вывод: Excel целесообразно использовать для создания компактных баз данных, которые могут поместиться на одном рабочем листе. Excel обладает рядом значительных ограничений для ведения полноценной базы данных, но может успешно использоваться для анализа данных благодаря достаточному математическому аппарату.
Виды баз данных и их структура, примеры
Выделяют несколько видов баз данных. Основными из них являются:
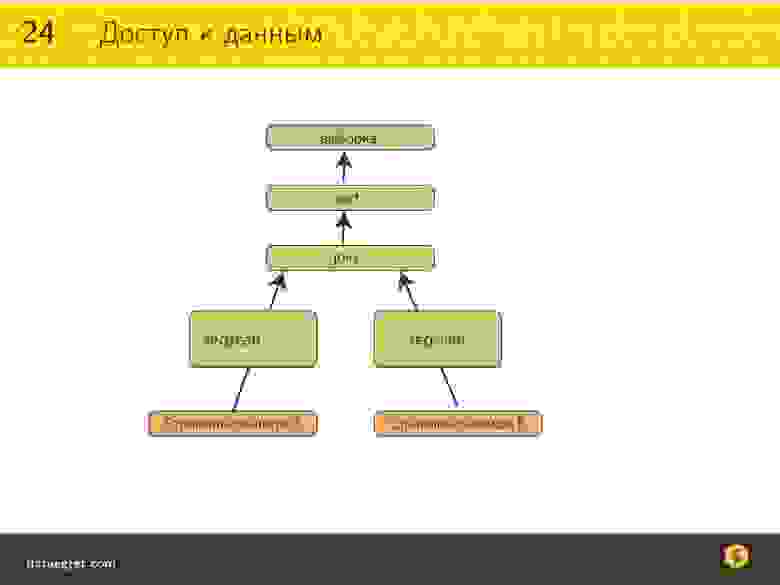
Базы данных разных систем обладают неодинаковой структурой. Для ПЭВМ характерно использование реляционных баз данных с файлами в виде таблиц, в которых столбцы являются полями, а строки – записями. В базе данных находятся данные определенного множества объектов. Для каждой записи характерна информация по одному объекту. Такую базу определяют:
В качестве примера можно привести школьную базу с данными «Ученик», «Класс», «Адрес». Также базой данных является расписание движения поездов или автобусов. В этом случае каждой строке соответствует запись с данными конкретного объекта. Возможные поля: номер рейса, маршрут, время отправления и прибытия. Классической базой данных является телефонный справочник.
Запрос к базе данных – предписание с указанием на данные, которые необходимы пользователю.
В случае некоторых запросов требуется составление сложной программы. К примеру, для выполнения запроса к базе в виде автобусного расписания необходимо вычислить разницу в среднем интервале отправления транспорта из одного города во второй и из второго пункта в третий.
Существует три звена для создания приложения, с помощью которого можно просматривать и редактировать базы данных:
В случае Access роль таких звеньев выполняют:
Приложения базы данных является нитью, которая связывает базу и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Визуальными компонентами являются:
Access характеризуется наличием следующих типов полей:
Благодаря связи с обеспечением целостности таблиц осуществляется контроль удаления и модификации данных. С помощью монопольного доступа к базам данных в них производят фундаментальные изменения.
Что такое СУБД и язык структурированных запросов SQL
Системы управления базами данных СУБД – специальные средства, включающие определенный язык программирования, предназначены для разработки программ или их систем, работающих с базами данных.
Современные системы обладают большими возможностями, а также способствуют разработке сложных программных комплексов.
SQL (SQL, Structured Query Language) — язык программирования структурированных запросов, применяемый в качестве эффективного способа сохранения данных, поиска их частей, обновления, извлечения из базы и удаления.
SQL представляет собой ключевой инструмент оптимизации и обслуживания базы данных. Возможности обработки охватывают:
SQL отличается простотой и легкостью в изучении. Его применяют:
Язык отличается универсальностью. Его структура четко определена благодаря устоявшимся стандартам. Даже в случае больших объемов данных (Big Data) обеспечивается оперативное взаимодействие с базами.
Руководство по разработке структуры и проектированию базы данных
Этапы создания базы данных
Надлежащим образом структурированная база данных:
Основные этапы разработки базы данных:
Анализ требований: определение цели базы данных
Вот несколько способов сбора информации перед созданием базы данных:
Начните со сбора существующих данных, которые будут включены в базу. Затем определите типы данных, которые нужно сохранить. А также объекты, которые описывают эти данные. Например:
Структура базы данных: построение блоков
Чтобы преобразовать списки данных в таблицы, начните с создания таблицы для каждого типа объектов, таких как товары, продажи, клиенты и заказы. Вот пример:
Каждая строка таблицы называется записью. Записи включают в себя информацию о чем-то или о ком-то, например, о конкретном клиенте. Столбцы (также называемые полями или атрибутами) содержат информацию одного типа, которая отображается для каждой записи, например, адреса всех клиентов, перечисленных в таблице.

Чтобы при проектировании модели базы данных обеспечить согласованность разных записей, назначьте соответствующий тип данных для каждого столбца. К общим типам данных относятся:
В визуальном представлении БД каждая таблица будет представлена блоком на диаграмме. В заголовке каждого блока должно быть указано, что описывают данные в этой таблице, а ниже должны быть перечислены атрибуты:

При проектировании информационной базы данных необходимо решить, какие атрибуты будут служить в качестве первичного ключа для каждой таблицы, если таковые будут. Первичный ключ ( PK ) — это уникальный идентификатор для данного объекта. С его помощью вы можете выбрать данные конкретного клиента, даже если знаете только это значение.
Атрибуты, выбранные в качестве первичных ключей, должны быть уникальными, неизменяемыми и для них не может быть задано значение NULL ( они не могут быть пустыми ). По этой причине номера заказов и имена пользователей являются подходящими первичными ключами, а номера телефонов или адреса — нет. Также можно использовать в качестве первичного ключа несколько полей одновременно ( это называется составным ключом ).
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь « один-к одному » ( часто обозначается 1:1 ). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:

Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи « один- ко-многим » ( 1:M ) обозначаются так называемой «меткой ноги вороны», как в этом примере:

Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь « многие-ко-многим » ( M:N ). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:

При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи « один-ко-многим ».
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:

Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:

Два объекта могут быть взаимозависимыми ( один не может существовать без другого ).
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза. Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект « ученики » имеет прямую связь с другим объектом, называемым « учителя », но также имеет косвенные отношения с учителями через « предметы », нужно удалить связь между « учениками » и « учителями ». Так как единственный способ, которым ученикам назначают учителей — это предметы.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени ( OLTP ), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой ( OLAP ), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации ( сокращенно 1NF ) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF :

Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF :

Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу « Реквизиты продаж », которая будет соответствовать конкретным продуктам с продажами. « Продажи » будут иметь связь 1:M с « Реквизитами продаж ».
Вторая форма нормализации
Вторая форма нормализации ( 2NF ) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут « возраст » зависит от « дня рождения », который, в свою очередь, зависит от « ID студента », имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут « название товара » зависит от идентификатора продукта, но не от номера заказа:
Третья форма нормализации
Третья форма нормализации ( 3NF ) : каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.

Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:

Правила целостности данных
Правило целостности ссылок требует, чтобы каждый внешний ключ, указанный в одной таблице, сопоставлялся с одним первичным ключом в таблице, на которую он ссылается. Если первичный ключ изменяется или удаляется, эти изменения необходимо реализовать во всех объектах, на которые ссылается этот ключ в базе данных.
Правила целостности бизнес-логики обеспечивают соответствие данных определенным логическим параметрам. Например, время встречи должно быть в пределах стандартных рабочих часов.
Добавление индексов и представлений
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.
Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
Расширенные свойства
После того как схема базы данных будет готова можно уточнить БД с помощью расширенных свойств, таких как справочный текст, маски ввода и правила форматирования, которые применяются к конкретной схеме, представлению или столбцу. Преимущество этого метода заключается в том, что, поскольку эти правила хранятся в самой базе, представление данных будет согласовано между несколькими программами, которые обращаются к данным.
SQL и UML
Унифицированный язык моделирования ( UML ) — это еще один визуальный способ выражения сложных систем, созданных на объектно-ориентированном языке. Некоторые из концепций, упомянутых в этом руководстве, известны в UML под разными названиями. Например, объект в UML известен, как класс.
Сейчас UML используется не так часто. В наши дни он применяется академически и в общении между разработчиками программного обеспечения и их клиентами.
Системы управления базами данных
Проектируемая структура базы данных зависит от того, какую СУБД вы используете. Некоторые из наиболее распространенных:
Подходящую систему управления базами данных можно выбирать исходя из стоимости, установленной операционной системы, наличия различных функций и т. д.
Пожалуйста, опубликуйте свои мнения по текущей теме материала. За комментарии, дизлайки, подписки, лайки, отклики низкий вам поклон!
Пожалуйста, оставляйте свои мнения по текущей теме материала. За комментарии, подписки, отклики, лайки, дизлайки низкий вам поклон!
Как устроены базы данных
Нельзя сказать, что в этой статье вас ждут отборные потроха баз данных, но скорее рассказ про базы данных от самого начала, плюс небольшое углубление в некоторые подробности, которые Илье Космодемьянскому (@hydrobiont) кажутся важными. И есть все основания полагать, что так оно и есть.
Эта статья родилась не от хорошей жизни. Часто даже не то что начинающие разработчики, но и вполне продвинутые, не знают каких-то базовых вещей — может быть, давно учились в университете и с тех пор забыли, или им не приходилось углубляться в теорию, поскольку и так работалось нормально.
Тем не менее, теоретические знания иногда полезно освежить. Этим мы, в том числе, и займемся.

О спикере: Илья Космодемьянский CEO и консультант в компании Data Egret, специалист по базам данных PostgreSQL, Oracle, DB2. А кроме того, отвечает за продвижение Postgres-технологий, выступает на конференциях и рассказывает людям, как с ними работать.
Ниже материал по докладу Ильи на РИТ++ 2017, который не был связан с какой-то конкретной базой данных, но охватывал многие основные аспекты.
Для чeго это нужно знать?
Хранение и обработка данных — mission-critical задача любой компьютерной системы.
Даже если у вас уже 30 лет есть блог в интернете на текстовых файлах, как у некоторых создателей баз данных бывает, все равно на самом деле этот текстовый файлик — это база данных, только очень простенькая.
Все пытаются изобрести базу данных. Один из докладчиков на конференции сказал: «20 лет назад я написал свою базу данных, только не знал, что это она!» Этот тренд в мире очень развит. Все стараются так делать.
Для работы с данными база данных — это очень удобная штука. Многие базы данных — это очень старые технологии. Они разрабатываются последние полвека, в 70-х годах уже были базы данных, которые работали по схожим принципам, что и сейчас.
Эти базы очень хорошо и продуманно написаны, поэтому теперь мы можем выбрать язык программирования и использовать общий удобный интерфейс обработки данных. Таким образом можно стандартизованно обрабатывать данные, не боясь, что они будут обработаны как-то по-другому.
При этом полезно помнить, что языки программирования меняются: вчера был Python 2, сегодня Python 3, завтра все побежали писать на Go, послезавтра еще на чем-то. У вас может быть кусок кода, который эмулирует работу по манипуляции с данными, которую, по идее, должна делать база данных, а вы не будете знать, что дальше с этим делать.
В большинстве баз данных интерфейс очень консервативный. Если взять PostgreSQL или Oracle, то с некоторым бубном можно работать даже с очень старыми версиями из новых языков программирования — хорошо и здорово.
Но задача на самом деле не самая простая. Если мы начнем закапываться в глубины того, как нам не «побить» данные, как быстро, производительно и, главное так, чтобы потом можно было доверять результату, обрабатывать их, то окажется, что сложное это дело.
Если вы попробуете написать свое простенькое персистентное хранилище, все просто будет только первые 15 минут. Потом начнутся блокировки и прочие вещи, и в какой-то момент вы поймете: «Ой, зачем я все это делаю?»
Об этом и поговорим.
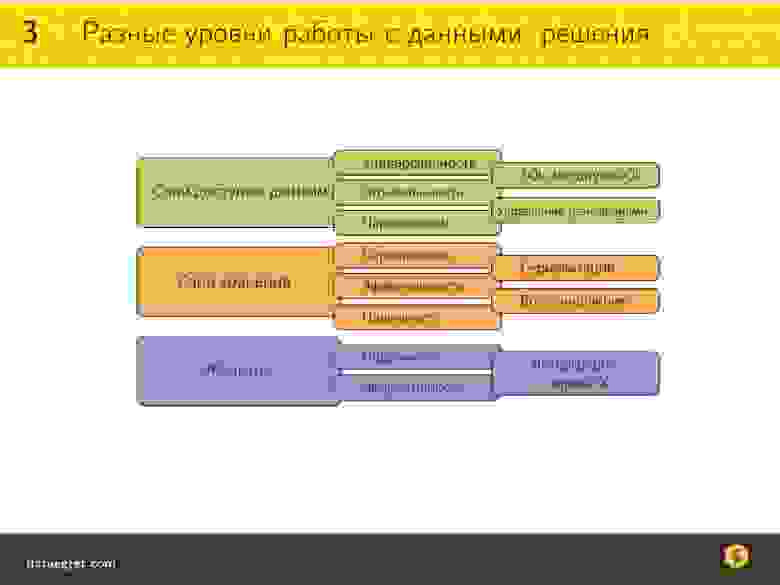
Уровни работы с данными
Итак, есть различные уровни работы с данными:
Для слоя доступа к данным есть требования, в выполнении которых мы заинтересованы, чтобы было удобно работать:
В то же время они должны быть надежно сохранены и надежно воспроизведены. То есть, если мы что-то записали в базу данных, мы должны быть уверены, что мы это получим обратно.
Если вы работали со старыми базами данных, например, FoxPro, то знаете, что там часто появляются битые данные. В новых базах данных, типа MongoDB, Cassandra и прочих, такие проблемы тоже случаются. Может быть, просто их не всегда замечают, потому что данных уж очень много и заметить сложнее.
Для «железа» на самом деле важна надежность. Это как бы допущение, поскольку мы все-таки будем говорить о теоретических вещах. В нашей модели, если что-то попало на диск, то мы считаем, что там все хорошо. Как заменить вовремя диск в RAID — это сегодня для нас забота админов. Мы не будем глубоко погружаться в этот вопрос, и практически не будем касаться того, насколько эффективно хранилище организовано физически.
Чтобы решать эти проблемы, есть некоторые подходы, которые очень похожи у разных хранилищ данных — и новых, и классических.
Прежде всего для того, чтобы обеспечить универсальный и оптимальный доступ к данным, есть язык запросов. В большинстве случаев это SQL (почему именно он, мы подискутируем дальше), но сейчас просто хочу обратить внимание на тенденцию. Сначала достаточно долгое время был SQL — конечно, были времена и до него, но, тем не менее, SQL господствовал долго. Потом стали появляться всякие Key-value-storage, которые, дескать, работают без SQL и гораздо лучше.
Многие Key-value-storage в основном делались для того, чтобы из любимого языка программирования было проще ходить за данными, а SQL не очень хорошо вяжется с любимым языком программирования. Он высокоуровневый, декларативный, а нам хочется объектов, поэтому появилась идея, что SQL не нужен.
Но большинство этих технологий сейчас на самом деле придумывают какой-то свой язык запросов. В Hibernate очень развит свой собственный язык запросов, кто-то использует Lua. Даже те, кто раньше использовал Lua, делают свои реализации SQL. То есть сейчас тенденция такая: SQL опять возвращается, потому что удобный человеко-читаемый язык работы со множествами все равно нужен.
Плюс к тому по-прежнему удобно табличное представление. В той или иной степени во многих базах данных по-прежнему имеются таблички, и это далеко не случайно — таким образом легче оптимизировать запросы. Вся математика оптимизации завязана вокруг реляционной алгебры, и когда есть SQL и таблички, работать гораздо проще.
В слое хранения возникает такое понятие, как сериализация. Когда есть параллелизм и конкурентный доступ, нам нужно обеспечить, чтобы на процессор, на диск это приезжало в более-менее предсказуемом порядке. Для этого нужны алгоритмы сериализации, которые реализуются в слое хранения.
Опять же, если что-то пошло не так и база данных упала, нам нужно ее быстро поднять.
Как вы считаете, можно ли написать 100% надежное отказоустойчивое хранилище? Наверное, вы знаете, что база данных надежно работает только тогда, когда есть механизм, чтобы ее быстро поднять, если она упала.
Для этого нужно восстановление, потому что, что ни делай, где-нибудь будет слабое звено и очень большие накладные расходы на синхронизацию. Мы можем сделать сотню копий на сотню серверов, а в результате сгорит питание или какой-то коммутатор, и будет плохо и больно.
Для «железа» на самом деле важно, чтобы база данных была хорошо интегрирована с ОС, работала производительно, вызывала правильные syscalls и поддерживала все фишки ядра по быстрой работе с данными.
Слой хранения
Начнем со слоя хранения. Понимание того, как он устроен, хорошо помогает понять, что происходит на более высоких слоях.
Слой хранения обеспечивает:
✓ Параллелизм и эффективность.
Другими словами, это конкурентный доступ. То есть, когда мы пытаемся получить пользу от параллелизма, неизбежно возникает проблема конкурентного доступа. Мы одновременно ходим за одним ресурсом, который может записаться не так, побиться при записи и, черт знает что еще, может при этом получиться.
✓ Надежность: восстановление после сбоев.
Вторая проблема — это внезапный сбой. Когда обеспечивается надежность, это означает, что мы не только максимально обеспечили катастрофоустойчивое решение, но важно и то, что мы умеем быстро восстановиться в случае чего.
Конкурентный доступ
Когда я говорю о целостности, внешних ключах и прочем, все как-то хмыкают и говорят, что все это они проверяют на уровне кода. Но как только предложишь: «А давайте пример на вашей зарплате! Вам переводят зарплату, а она не пришла», — почему-то сразу понятней становится. Не знаю почему, но сразу появляется блеск в глазах и интерес к теме внешних ключей, констрейнтов.
Ниже код на несуществующем языке программирования.
Допустим, у нас есть банковский счет с балансом в 1 000 рублей, и есть 2 функции. Как они устроены внутри, нам сейчас не важно, эти функции переводят с аккаунта a на другие банковские счета 100 и 200 рублей.
Внимание, вопрос: сколько денег окажется в результате на балансе счета a? Скорее всего, вы ответите, что 700.
Проблемы
Здесь начинаются проблемы с конкурентным доступом к данным, потому что язык у меня выдуманный, совершенно не понятно, как он реализован, одновременно ли исполняются эти функции и как они устроены внутри.
Мы, наверное, считаем, что операция send_money() — это не элементарное действие. Надо проверить баланс и куда переводится, выполнить контроль 1 и 2. Это не элементарные операции, которые занимают какое-то время. поэтому нам важен порядок выполнения элементарных операций внутри них.
В последовательности «прочитали значение на балансе», «записали на другой баланс», важен вопрос — когда мы читали этот баланс? Если мы это делаем одновременно, возникнет конфликт. Обе функции выполняются примерно параллельно: прочитали одно и то же значение баланса, перевели деньги, записали каждая свое.
Может возникнуть целое семейство конфликтов, в результате которых на балансе может оказаться 800 рублей, 700 рублей, как должно быть, или что-то побьется, и на балансе окажется null. Такое, к сожалению, бывает, если не относиться к этому с должным вниманием. Как с этим бороться, мы и поговорим.
В теории все просто — мы можем выполнить их одну за другой и все будет хорошо. На практике этих операций может быть очень много и делать их строго последовательно может быть проблематично.
Если помните, несколько лет назад была история, когда у Сбербанка упал Oracle и процессинг карточек остановился. Они тогда просили совета у общественности и примерно обозначили, сколько логов писала база данных писала. Это огромные количества и конкурентные проблемы.
Выполнять операции строго последовательно не очень хорошая идея еще и по той простой причине, что операций много, а мы ничего не выиграем от параллелизма. Можно, конечно, разбивать операции по группам, которые не будут конфликтовать друг с другом. Такие подходы тоже есть, но они не очень классические для современных баз данных.

В немецких правилах дорожного движения есть одна интересная история. Если дорога сужается, то правила предписывают доехать до конца, и только после этого перестраиваться по одному, а соседняя машина должна пропускать. Все перестраиваются строго друг за другом — такой знак об этом говорит.
Это живой пример возможной сериализации, когда общественность очень долго приучали к тому, что правила нужно соблюдать. Думаю, что все, кто ездит на машине по Москве понимают, насколько утопична эта картина.
В принципе, нам нужно то же самое сделать с данными, которые мы пишем на диск.
Как улучшить ситуацию?
● Операции должны быть независимы друг от друга — изолированость.
Чисто теоретически контролируемым образом операция должна знать, что происходит снаружи. Не может быть такого, что как только одна операция что-то изменила, результат сразу стал виден другой. Должны быть какие-то правила.
Это называется изолированностью транзакций. В самом простейшем случае транзакции вообще не знают, что происходит с соседними. Это действия сами в себе, в пределах одной функции никакого взаимодействия наружу нет, пока она не закончилась.
● Операция происходит по принципу «все или ничего» — атомарность.
То есть либо вся операция прошла, и тогда ее результат записался, либо, если что-то пошло не так, мы должны уметь вернуть статус-кво. Такая операция должна быть восстановима, а если она восстановима и изолирована, то она атомарна. Это элементарная операция, которая, как и результат, не делима. Она не может пройти наполовину, а только целиком проходит или целиком не проходит.
● Нужен механизм как проверить что все произошло правильно — консистентность.
Я спрашивал, сколько денег получилось на балансе в нашем примере, и вы почему-то сказали, что 700. Мы все знаем, что есть арифметика, здравый смысл и Уголовный Кодекс, который следит за банками и бухгалтерами, чтобы они не сделали чего-то противозаконного. Уголовный Кодекс — это одна из частных версий консистентности. Если мы говорим, о базах данных, там их гораздо больше: внешние ключи, констрейнты, все дела.
ACID-транзакция
Действия с данными, которые обладают свойствами атомарности, консистентности, изолированности и Durability — это определение ACID транзакции.
D — Durability — это та самая модель, про которую я говорил: если данные уже записали на диск, то мы считаем, что они там лежат, записались надежно и никуда не денутся. На самом деле это не так, например, данные нужно бэкапить, но для нашей модели это не важно.
Как ни печально, обеспечить эти свойства можно только с помощью блокировок. Есть 3 основных подхода к шедулингу транзакций:
Про упорядочивание TimeStamp все знают: мы смотрим время одной транзакции, время другой транзакции, кто первый встал, того и тапки. На самом деле для большинства серьезных систем этот подход имеет кучу проблем, потому что, для начала, время на сервере может идти назад, может скакать или идти неправильно — и мы приедем.
Есть разные методы усовершенствовать это, но как один-единственный метод синхронизации транзакций, он не работает. Есть еще векторные часы, Лэмпортовы часы — наверняка слышали такие термины — но у них тоже есть свои ограничения.
Оптимистические подходы подразумевают, что у нас не будет конфликтов типа того, что я описал с банковским счетом. Но в реальной жизни они не очень успешно работают, хотя есть реализации, которые помогают проводить какие-то операции с помощью оптимистичных вариантов.
Как люди, работающие с базами данных, мы на самом деле всегда пессимисты. Мы ожидаем, что программисты напишут плохой код, поставщик поставит плохое железо, Марь Иванна выдернет из розетки сервер, когда будет мыть пол — чего только может не быть!
Поэтому мы любим пессимистичный шедулинг транзакций, а именно с помощью блокировок. Это единственный гарантированный способ обеспечить целостность баз данных. Есть соответствующие теоремы, которые можно доказать и продемонстрировать это.
Нужны эффективные алгоритмы взятия и снятия блокировок, потому что, если просто блокировать все, что нам нужно, скорее всего, мы придем к очень тупой версии, когда мы выполняем все операции строго последовательно. Как мы уже знаем, это не эффективно с точки зрения утилизации параллелелизма, современных ЦПУ, количества серверов и т.д.
Семантика Эрбрана
Небольшое лирическое отступление, которое поможет понять, что будет происходить дальше. Жак Эрбран — французский математик первой половины XX века, который, кстати, изобрел рекурсию. Он придумал еще в докомпьютерные времена обозначать транзакции следующим способом:

Здесь S — от слова schedule (расписание). Расписание транзакции включает в себя операцию — r (read — чтение) или w (write — запись). Еще бывает b (begin), с (commit) и т.п.
Что удобно — у нас есть 2 транзакции (цифры 1 и 2). Одна транзакция просто читает данные из какого-то ресурса (x), а вторая транзакция его тоже читает, делает какую-то математику на основе этих двух чтений x и записывает что-то в y.
Очень удобно — транзакции состоят из элементарных действий «чтение — запись, чтение — запись». Мы можем составить итоговое расписание, проверить его, есть ли в нем конфликты, с помощью всякой хитрой математики, и таким образом гарантировать, что все будет хорошо и целостно.
Для чего все это нужно?
Two Phase Locking
Один из основополагающих алгоритмов в современных базах данных — это так называемое двухфазное блокирование или 2PL (Two Phase Locking).
Двухфазное оно, потому что было подмечено, что для оптимизации взятия и снятия блокировок в базе данных удобно сделать это в 2 присеста:
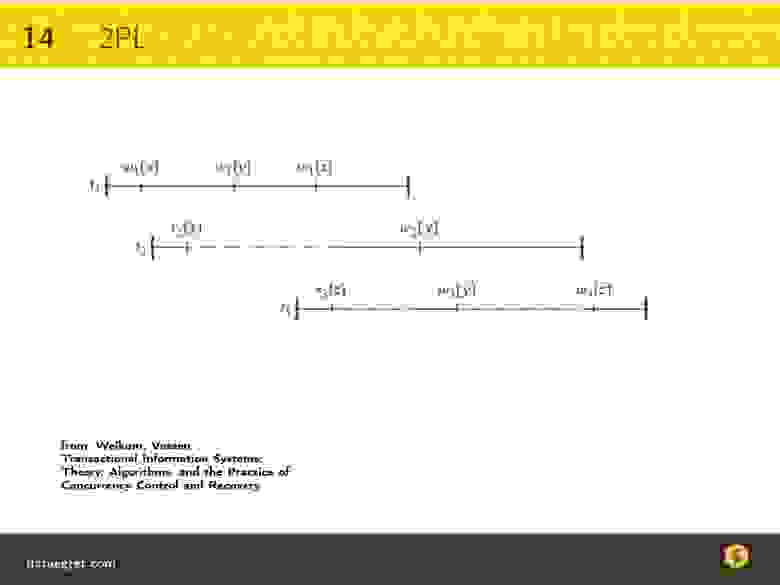
На рисунке 3 линейки обозначают транзакции и время их исполнения. Видно, что операция записи в первой транзакции ресурса x имеет ненулевое время, поскольку запись занимает какое-то время — пока диск повернется, пока странички туда уйдут и т.д.
Когда она начинается, в этой модели нет никаких других транзакций, поэтому запись началась и пишется. Но вторая транзакция тоже должна прочитать x. Эта транзакция не может взять блокировку на чтение x по той простой причине, что x в этот момент пишется другой транзакцией. Линия становится пунктирной — это означает, что транзакция ждет блокировки, которую выставила транзакция t1.
Как только транзакция t2 взяла все блокировки, которые ей были нужны для того, чтобы она выполнилась — ей еще нужна блокировка на y и блокировка на z — только тогда она может начать их отпускать. В этот момент разблокируется следующая транзакция, которая тоже выполняется до конца.
Эта идея повышает эффективность транзакций и позволяет одни и те же операции выстраивать в параллель только так, чтобы элементарные операции блокировались и ждали, только если они конфликтуют.
Рекомендую книгу «Transactional Information Systems» (Gerhard Weikum, Gottfried Vossen) — это фундаментальный учебник по теории транзакций.
Что плохо в двухфазном блокировании?
Почему нельзя так просто решить всю проблему со всеми базами данных с помощью одного простого волшебного алгоритма?
✓ Во-первых, с такими блокировками неизбежно возникают дедлоки, когда непонятно, курица или яйцо.
Одной транзакции нужен ресурс x, другой y, они его блокируют, а дальше им нужны крест-накрест те же самые ресурсы, и непонятно, кто должен первый отпускать блокировку. Для этого в базах данных имеются специальные системы контроля дедлоков и так называемого отстрела дедлоков. Дедлок нельзя разрешить мирным способом, а только откатом одной из транзакций.
Обычно математика внутри детекции дедлоков — это граф дедлоков, где на вершинах обозначены transaction ID, а направленные ребра обозначают, какая ждет блокировки от какой. На этом графе выделяются небольшие подграфы от одной из этих вершин, смотрится, например, если одну транзакцию ждет очень большое количество транзакций, то эту транзакцию прибивают.
Но есть и другие красивые математические подходы, искать которые можно по теме deadlock-detection.
✓ Второй момент, это медленно — никто не хочет ждать блокировки.
Есть такие транзакции, которые занимают ресурс надолго, например, какой-то отчет считает, заняла ресурс, и все остальные вынуждены ждать. Чтобы этого не было, придумали некоторые усовершенствования, о которых расскажу чуть позже.
✓ Зато таким образом обеспечена сериализация.
Без двухфазного блокирования никакой сериализации нет. То есть надо придумывать, как улучшать двухфазное блокирование, чтобы сократить время на ожидание.
В любой современной базе данных двухфазное блокирование — это главный способ обеспечения целостности и сериализации, даже если мы говорим о версионных базах данных.
На самом деле бывают конфликты, которые 2PL разрулить не может в принципе и тогда одна из конфликтующих транзакций откатывается. Обычно в базах данных реализован механизм, когда база данных ждет некоторое время и понимает, что некоторая транзакция ждет блокировки слишком долго, и что нельзя никак разрешить конфликт, база данных просто убивает такую транзакцию. Это достаточно редкая ситуация и следующий алгоритм позволяет решить некоторые из этих конфликтов.
MVCC — MultiVersion Concurrency Control
Версионирование данных нужно не только для того, чтобы ускорить, но еще и для того, чтобы решить некоторые разновидности конфликтов, которые могут возникнуть.
✓ Интуитивно все понятно — чтобы не ждать блокировку, берем предыдущую версию.
Если какой-то ресурс заблокирован, мы можем посмотреть его старую версию и начать с ней работать. Если, например, блокировка была такая, что та транзакция, которая блокировала, не изменила ничего на этом ресурсе, то мы можем продолжить исполнение транзакции. Если было изменение и появилась новая, более свежая версия данных, наша транзакция будет вынуждена их еще раз перечитать.
В любом случае это обычно быстрее, чем долго ждать блокировку. Если помните старый MS SQL Server и старые версии DB2, страшное дело, то там, если там пошло много блокировок, дальше началась их эскалация — все работало плохо и жить с этим было тяжело.
✓ Все современные DBMS в той или иной степени «версионники»
Oracle, PostgreSQL, MySQL — все «версионники» в честном виде. DB2 немножко оригинальнее на эту тему, там есть свой механизм — хранят только одну предыдущую версию.

Это расписание, которое я рисовал раньше, но несколько более сложное. Здесь больше транзакций (3 штуки), больше ресурсов (есть еще z) и 2 коммита. То есть обе транзакции заканчиваются коммитом.
Как говорят в таких случаях математики: «Легко заметить. » — я это очень люблю, особенно когда на половину доски формула. Действительно, тут легко заметить одну штуку. В качестве домашнего задания попробуйте понять, почему это легко заметить.
Я вам подскажу. Это расписание никогда не сериализуется по той простой причине, что операция r1(y) вызовет конфликт, возможно, даже дедлок, если не будет доступна предыдущая версия y.
То есть, если здесь будет доступна предыдущая версия y, то транзакция нормально завершится, никаких проблем не будет. Если этой версии y не будет, то операции будут конфликтовать.
Как это работает?
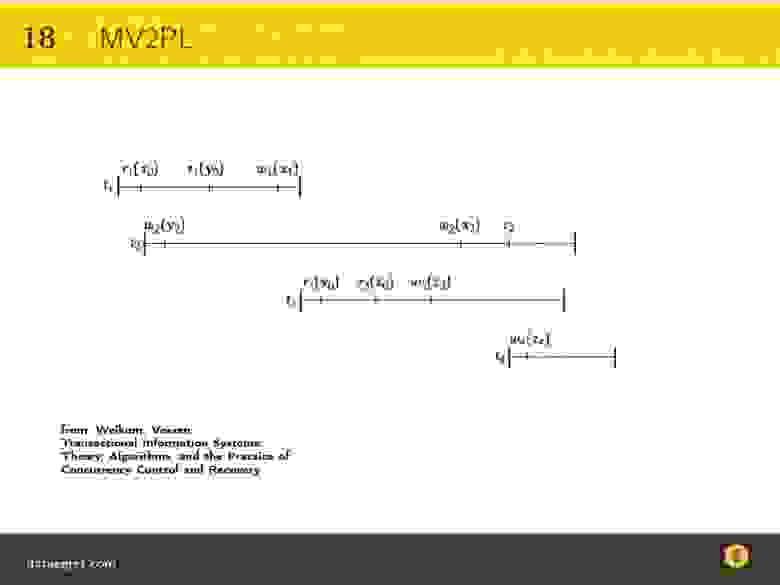
Диаграмма более-менее такая же, как с двухфазным блокированием. Это разновидность версионного шедулинга транзакций, то есть это все равно алгоритм двухфазного блокирования, только мультиверсионный.
Добавляется еще такая фишка, как нижний индекс — 0, 1, 2 — это номер версии.
В этом большой плюс MVCC. Мультиверсионность на самом деле быстрее, чем блокировка, это не просто маркетинговая фича.
А что, если в момент транзакции, которая явно имеет ненулевую длительность, произойдет сбой, например, развалится жесткий диск под базой данных или выдернут провода из сервера?
На самом деле мы к этому готовы, потому что транзакции выполняются так. Рассмотрим абстрактную базу данных:
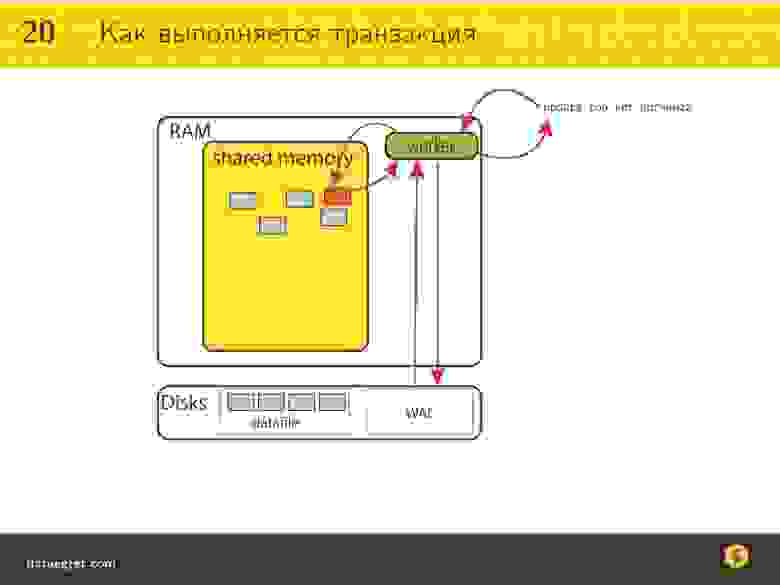
Есть некий объем памяти, который обобществлен между разными процессами или тредами, в которых обрабатываются клиентские подключения. У треда есть свой объем памяти, куда приходит SQL-запрос. В этом объеме памяти SQL запрос (или запрос на другом языке) прекомпилируется, интерпретируется, перестраивается каким-то образом.
Дальше он идет за данными, которые ему нужно прочитать и изменить. Эти данные на диске лежат специальным образом. Если заглянуть глубже в хранение, они лежат фиксированными кусками (страничками) в PostgreSQL это 8Кб, в Oracle можно разного размера использовать. В разных базах данных по-разному.
Эта страничка очень удобна тем, что в ней лежит куча разных данных (фактически в ней лежат tuple (кортежи) То есть есть табличка, а в ней строчки, эти строчки упакованы в большие странички.
Если запросу нужны данные с одной из страничек, он просто поднимает эту страничку себе в память и все воркеры, треды и процессы базы данных будут иметь к ней доступ. Если нужно много, то он поднимет несколько. Они будут закэшированы — это удобно, производительно — память быстрее, чем диски, все дела.
Если нужно поменять хотя бы одну запись хотя бы на одной страничке, вся страничка будет помечена, как так называемая «грязная». Это делается потому, что так удобнее. Мы рисовали на схеме ресурсы x и y — здесь это странички.
На самом деле база данных умеет блокировать и на более гранулярном уровне, в том числе единичную запись. Но сейчас мы рассуждаем о более теоретических вещах, а не о тонкостях глубокой реализации.
Соответственно, страничка помечена как «грязная», и у нас возникает проблема, которая заключается в том, что теперь слепок в памяти отличается от того, который на диске. Если мы сейчас упадем, память не персистентна, мы потеряем информацию о «грязных» страничках.
Поэтому нужно сделать следующую операцию: где-то на бумажке записать, какие изменения мы проделали, чтобы, когда поднимемся, прочитать эту бумажку и, используя информацию из нее, восстановить страничку до того состояния, в которое мы ее привели этим апдейтом.
Поэтому прежде, чем ответ от транзакции вернется снова к клиенту, происходит запись в так называемые Write Ahead Log. Это та самая бумажка, которая позволяет записывать быстро — запись в WAL последовательная, нам не надо искать, куда вставить в огромный data-файл это дело.
Мы записали в лог информацию о страничке и дальше вернули управление — все хорошо. Если в какой-то момент упали, то читаем назад Write Ahead Log и используя информацию об этих изменениях, можем чистые странички докатить до уровня «грязных». База данных у нас снова новая.
Это позволяет произвести то самое восстановление, которое нам нужно было обеспечить, исходя из проблем хранения данных, и позволяет восстановиться на самую последнюю транзакцию, на самое последнее действие, которое произошло перед тем, как Марь Иванна вытащила сервер из розетки.
Этот алгоритм называется ARIES и в современном виде сделан достаточно давно. Фундаментальная статья по его устройству и способе восстановления в реляционных базах данных была опубликована Моханом в 1992 году.
С тех пор теории особо не добавилось — Write Ahead Log с тех пор остался Write Ahead Log. Они все используют концепцию страничек и концепцию записей изменений в лог. Лог может по-разному называться и в разных местах располагаться:
Важный момент состоит в том, что все это было бы очень непроизводительно, если бы мы просто от начала времен писали WAL. Он бы рос и рос, а мы потом очень бы долго накатывали эти изменения в базу данных.
Checkpoint
Поэтому в последней реинкарнации этого алгоритма имеются идея так называемых Checkpoint — периодически база данных выполняет синхронизацию «грязных» страниц на диск. Когда мы будем восстанавливаться, можно просто дойти только до предыдущего Checkpoint. Все остальное уже синхронизировано, мы, так сказать, замечаем до какого момента мы восстановили.
Это как в компьютерной игре — люди, когда ее проходят, сохраняются периодически. Или как в Word сохраняют периодически свои файлы, чтобы текст не пропал никуда.
База данных это все умеет делать внутри себя. Она так устроена. Помимо всего прочего, это немножко ускоряет процесс, потому что рано или поздно эти странички должны же попасть на диск.
Доступ к данным
Эти самые странички, конечно, хорошие, но нам нужно в каком-то более человеко-читаемом виде эти данные получить. Страничная модель удобна для хранения и транзакционных алгоритмов, но не удобна для доступа. Странички читать неудобно — по битам, поэтому нужен более удобный человеку эффективный метод доступа к данным в страницах.
Есть странички на диске, относящиеся к таблице A и B. Данные на диске ничего не знают, к какой табличке они относятся. Про это знает наш оптимизатор, то есть тот engine в базе данных, который исполняет наш запрос, написанный на нашем языке запросов.
Например, если рассмотреть традиционный SQL, то обычно такая штука будет называться планом запроса. С помощью последовательного sequential scan мы будем брать странички из таблицы A и из таблицы B — иногда синхронно, иногда по очереди — в зависимости от реализации.
Дальше будем накладывать на них, например, JOIN, а с результатом делать что-нибудь еще, и потом вернем ответ клиенту.
Чем это удобно? Представьте себе альтернативу: вы из какого-нибудь Python читаете все это к себе в приложение, а эти таблички могут быть на самом деле огромными, а условие JOIN может исключать 90% этих данных. Вытаскиваете в память — там соответственно ходите по ним циклами, сортируете, возвращаете. На самом деле на каждом из этих этапов планировщик может решить, как сделать выгоднее. Например, он может выбрать метод JOIN, который может или целиком состоять из циклов, или может закэшировать одну таблицу и присоединить к ней другую и т.д. В зависимости от метода, например, можно не делать full sequential scan, то есть не читать всю табличку, а из приложения, скорее всего, вам придется прочитать данные целиком.
Здесь все придумано до вас и реализовано эффективно.
Выводы
Хранить данные удобней страницами. Есть разные базы данных: объектные, графовые, документо-ориентированные. В основном это все нишевые, неуниверсальные продукты, которые используются для своих целей. Просто поставить на такую базу огромный объем транзакций, чтобы они работали в универсальном виде, не особо получается. Шедулинг транзакций, которые мы рассматривали здесь, на объектах выглядит гораздо сложнее.
Фактически каждая транзакция представляет собой путь по графу. Граф может быть очень большим. Для нахождения конфликтов нужно заниматься очень тяжелой математикой на графах — поэтому в объектной модели возникают проблемы с шедулингом.
Неслучайно столько лет господствует база данных со страничной моделью, и поэтому все происходит так, как происходит. Хорошо ли, плохо ли, но этот метод доказал свою большую эффективность.
Транзакции, вопреки расхожему мнению, это не способ замедлить. Часто считают, что транзакции — это некий синтаксический сахар в базах данных с SQL, который просто все портит и бибикает, в смысле того, что все замедляет, потому что ждем блокировок.
На самом деле транзакции — это способ ускорения, поскольку позволяет параллельно обрабатывать больше данных без конфликтов, чтобы они не бились, чтобы получалось так, что операции выполнялись не строго одна за другой, а параллельно. Это позволяет эффективней расходовать вычислительные ресурсы и время.
Как говорил конструктор Туполев, когда его обвиняли в том, что он какую-нибудь модель самолета у кого-нибудь стянул: «Все самолеты одинаково устроены — чтобы летать, им нужно иметь крылья, фюзеляж и хвост!»
В некоторых даже, наверное, скоро появится параллелизм, и это будет большая победа сил разума.
Если посмотреть на современные Percona server, MariaDB, MySQL 8, видно, что они в значительной степени перенимают теоретические основы и сейчас гораздо больше похожи на классические базы данных по своему устройству.
Ну что, убедились, что общие теоретические аспекты нужно знать?
Но не теорией единой… и на РИТ++, который успешно завершился, и на Highload++ Siberia уже через месяц, всегда много-много реального опыта и практических кейсов.
Например, про базы данных и системы хранения есть такие потрясающие заявки:



