Безопасный веб-скрейпинг: как извлекать данные с сайтов, чтобы вас не заблокировали
Авторизуйтесь
Безопасный веб-скрейпинг: как извлекать данные с сайтов, чтобы вас не заблокировали
Автор — Мария Багулина
Чтобы получить данные с сайтов, используется готовый API, однако он не всегда доступен. Тогда приходится использовать «парсер» веб-страницы — в автоматическом или полуавтоматическом режиме распознавать код и получать данные из необходимых полей. Обходом множества страниц и сайтов занимается ПО, которое обычно называется «краулер».
Процесс сбора данных с сайтов краулером называется веб-скрейпингом.
Большинство популярных сайтов активно защищают свои ресурсы от скрейпинга используя распознавание IP-адреса, проверку заголовков HTTP-запросов, CAPTCHA и другие способы. Но скрейперы не отстают от них и придумывают новые стратегии обхода. Вот несколько советов, как скрейпить без блокировок.
Задайте случайные интервалы между запросами
Ни один реальный человек не станет отправлять запросы на сайт каждую секунду в течение 24 часов — такой сбор информации очень легко обнаружить. Используйте случайные задержки (например около 2–10 секунд), чтобы избежать блокировки. И не отправляйте запросы слишком часто, иначе сканирование сайта будет походить на сетевую атаку.
Особо щепетильным стоит проверить файл robots.txt (как правило, находится на http:// /robots.txt). Иногда там можно найти параметр Crawl-delay, который говорит, сколько секунд нужно подождать между запросами, чтобы не вредить работе сервера.
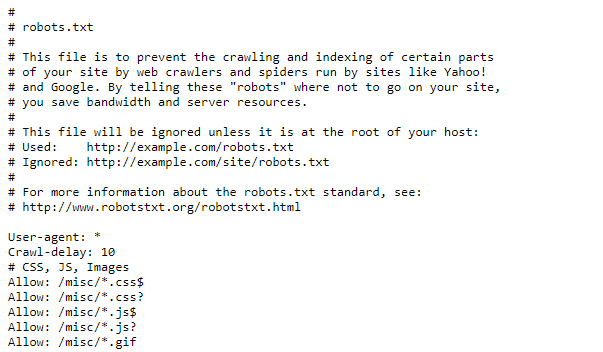
Установите адекватный User Agent
User Agent — HTTP-заголовок, который сообщает посещаемому веб-сайту информацию о вашем браузере. Если не настроить User Agent, вашего краулера будет очень легко обнаружить. Кроме того, сайты иногда блокируют запросы пользовательских агентов от неизвестных браузеров. Поэтому не забудьте установить один из популярных пользовательских агентов (например из этого списка).
Опытные скрейперы могут попробовать установить свой агент на Googlebot User Agent — поисковый робот Google. Большинство веб-сайтов, очевидно, хотят попасть в выдачу Google и пропускают Googlebot.
Хорошей практикой будет также чередование разных User Agent.
Используйте прокси
Вряд ли настоящий пользователь сможет запрашивать 20 страниц в секунду на одном и том же сайте. Чтобы «обмануть» веб-сервер, заставьте его думать, что все эти запросы приходят из разных мест. Другими словами, используйте прокси.
Тут есть множество вариантов, например сервисы SmartProxy, Luminati Network, Blazing SEO. Бесплатные прокси не всегда подойдут для таких целей: они часто медленные и ненадёжные. Также можно создать свою прокси-сеть на сервере, например с помощью Scrapoxy — API с открытым исходным кодом.
Добавьте referer
Referer — заголовок HTTP-запроса, который даёт понять, с какого сайта вы пришли. Неплохой вариант — сделать так, чтобы он показывал, будто вы перешли из Google:
Стоит менять referer для веб-сайтов в разных странах: например для России использовать https://www.google.ru/, а не https://www.google.com/. Вместо Google можно подставить адреса соцсетей: Youtube, Facebook, ВКонтакте. Referer поможет сделать так, чтобы запросы выглядели как трафик с того сайта, откуда обычно приходит больше всего посетителей.
Используйте headless-браузер
Особо хитроумные сайты могут отслеживать веб-шрифты, расширения, файлы cookie, цифровые отпечатки (фингерпринты). Иногда они даже встраивают JavaScript-код, открывающий страницу только после его запуска — так зачастую можно определить, поступает ли запрос из браузера. Для обхода таких ресурсов вам потребуется headless-браузер. Он эмулирует поведение настоящего браузера и поддерживает программное управление. Чаще всего для этих целей выбирают Chrome Headless.
Если ресурс отслеживает цифровой отпечаток браузера, то даже многократная смена IP и очистка cookie не всегда помогают, так как вас всё равно могут узнать по фингерпринту. За частую смену IP при одном и том же отпечатке вполне могут заблокировать, и одна из задач Chrome Headless — не допустить этого.
Самый простой способ работать с Chrome Headless — использовать фреймворк, который объединяет все его функции в удобный API. Наиболее известные решения можно найти тут. Но некоторые веб-ресурсы пытаются отслеживать и их: идёт постоянная гонка между сайтами, пытающимися обнаружить headless-браузеры, и headless-браузерами, которые выдают себя за настоящие.
Подключите программу для решения CAPTCHA
Существуют веб-сайты, которые систематически просят вас подтвердить, что вы не робот, с помощью капч. Обычно капчи отображаются только для подозрительных IP-адресов, и с этим помогут прокси. В остальных же случаях используйте автоматический решатель CAPTCHA — скажем, 2Captcha или AntiCaptcha.
Распознаватели чаще всего платные, потому что капчи вручную решают реальные люди. Поэтому стоит понять, оправдают ли затраты поставленную цель.
Избегайте honeypot-ловушек
«Honeypot» — это фальшивая ссылка, которая невидима для обычного пользователя, но присутствует в HTML-коде. Как только вы начнёте анализировать сайт, honeypot может перенаправить вас на пустые и бесполезные страницы-приманки. Поэтому всегда проверяйте, установлены ли для ссылки CSS-свойства «display: none», «visibility: hidden» или «color: #fff;» (в последнем случае нужно учитывать цвет фона сайта).
Если вы последуете хотя бы одному совету из этой статьи, ваши шансы быть заблокированным уменьшатся во много раз. Но для верности лучше комбинировать несколько приёмов и всегда следить, чтобы краулер не слишком нагружал чужие веб-серверы.
15 топовых веб скрапинг решений 2021 года
Веб скрапинг позволяет компаниям автоматизировать процессы сбора веб данных с помощью ботов или автоматизированных скриптов, называемых веб-сканерами и загружать эти данные в формате Excel, CSV или XML для последующей аналитики.
Представляем вашему вниманию список топ 15 инструментов для парсинга 2021 года.
Scraper API
Scraper API позволяет получить содержимое HTML с любой страницы с помощью вызова API. С Scraper API можно с легкостью работать с браузерами и прокси-серверами и обходить проверочные код CAPTCHA. Единственное на что необходимо сосредоточиться это превращение веб-сайтов в ценную информацию. С этим иснтрументом практически невозможно быть заблокированным, так как он меняет IP-адреса при каждом запросе, автоматически повторяет неудачные попытки и решает капчу за вас.
Octoparse
Octoparse это бесплатный инструмент предназначенный для веб скрапинга. Он позволяет извлекать данные с интернета без строчки кода и превращать веб-страницы в структурированные данные всего за один клик. Благодаря автоматической ротации IP-адресов для предотвращения блокировки и возможности планирования последующего скрапинга этот инструмент является одним из самых эффективных.
DataOx
DataOx— настоящий эксперт в области скрапинга веб-страниц. Инструменты предлогаемые компанией DataOx обеспечивают крупномасштабные сборы данных и предоставляют комплексные решения адаптированные к потребностям клиентов. Этой компании могут доверять как стартапы, создающие продукты на основе данных, так и большие предприятия, которые предпочитают поручать сбор собственных данных профессионалам.
ScrapingBot
Scraping-Bot.io предлагает мощный API для извлечения HTML-содержимого. Компания предлагает API-интерфейсы для сбора данных в области розничной торговли (описание продукта, цена, валюта, отзыв) и недвижимости (цена покупки или аренды, площадь, местоположение). Доступные тарифные планы, JS-рендеринг, парсинг с веб-сайтов на Angular JS, Ajax, JS, React JS, а также возможность геотаргетинга делают этот продукт незаменимым помощником для сбора данных.
Wintr
Wintr это API для парсинга веб-страниц, использующий вращающиеся резидентные прокси, позволяющий извлекать и анализировать любые данные доступные в сети. Простой в использовании и полностью настраиваемый Wintr включает множество инструментов для сбора данных даже с самых сложных веб-сайтов. Например, можно легко извлечь содержимое с общедоступной веб-страницы с помощью ротационного IP-адреса или автоматизировать аутентификацию с помощью Javascript рендеринга, а затем извлечь личные данные с помощью файлов cookie и постоянного IP-адреса.
Import.io
Webhose.io
Webhose.io это расширенный API сервис для извлечения веб данных в реальном времени. Это инструмент очень часто изпользуют для извлечения исторических данных, мониторинга СМИ, бизнес-аналитики, финансового анализа, а также для академических исследований.
ParseHub
Mozenda
Mozenda это корпоративное программное обеспечение разработанное для всех видов задач по извлечению данных. Этой компании доверяют тысячи предприятий и более 30% компаний из списка Global Fortune 500. Это один из лучших инструментов для парсинга веб-страниц, который поможет за считанные минуты создать скрапер агента. Mozenda также предлагает функции Job Sequencer and Request Blocking для сбора веб-данных в реальном времени и лучший сервис для работы с клиентами.
Diffbot
Diffbot автоматизирует извлечение веб-данных с помощью искусственного интеллекта и позволяет легко получать различные данные с любого сайта. Вам не нужно платить за дорогостоящий парсинг веб-страниц или делать это в ручную.
Этот инструмент поможет увеличить объем скрапинга до 10 000 доменов, а функция Knowledge Graph предоставит точные, полные и подробные данные с любого интернет источника.
Luminati
Luminati предлагает инструмент для сбора данных нового поколения, который позволяет получать автоматизированный и настраиваемый поток данных с помощью одной простой панели управления. Необходимо только отправить запрос, а всем остальным: IP-адресами, заголовками, файлами cookie, капча будет управлять система. С Luminati вы получите структурированные данные с любого веб-сайта, от тенденций в электронной коммерции и данных с социальных сетей до исследований рынка и конкурентной разведки.
FMiner
FMiner это программное обеспечение для парсинга веб-страниц, извлечения веб-данных, веб-сканирования и поддержки веб-макросов для Windows и Mac OS X. Этот простой в использовании инструмент извлечения данных сочетает в себе лучшие в своем классе функции от простых задач до комплексных проектов по извлечению данных, требующими ввода форм, списков прокси-серверов, обработки Ajax и многоуровневого сканирования веб страниц.
Outwit
Data streamer
Data Streamer помогает получать контент из социальных сетей. Это один из лучших веб-парсеров, который позволяет извлекать важные метаданные с помощью NLP. Встроенный полнотекстовый поиск на базе Kibana и Elasticsearch и простая в использовании и всеобъемлющая консоль администратора обеспечивает эффективный сбор необходимой информации.
Web Scraping – что это такое и зачем он нужен
Каталог товаров, спортивная статистика, цены на офферы… Что-то знакомое, правда? Эти и другие вещи собирают с помощью специальных софтов или вручную в документы. Там информация структурирована; нет необходимости разбираться что и где.
Если вас заинтересовал такой метод, подумайте о веб-скрейпинге.
Что такое веб-скрейпинг?
Web scraping – процесс сбора данных с помощью программы, то есть в автоматическом режиме. В русскоязычном пространстве этот процесс называют парсингом. А программу – парсером. Точно так же как за бугром говорят to scrape web page, у нас – парсить страницу. Так что если изучаете материал на английском, не переводите как “скрабить”, “скрабы” и так далее 🙂
Как работает веб-скрейпинг?
Запускаете программу и загружаете в нее адреса страниц. А еще наполняете софт ключевыми словами и фразами, блоками и числами, которые нужно собрать. Эта программка заходит на указанные сайты и копирует в файл все, что найдет. Это может быть файл CSV-формата или Excel-таблица.
Когда программа закончит работу, вы получите файл, в котором вся информация будет структурирована.
Для чего он нужен?
С помощью веб-скрейпинга собирают нужные данные. Например, у вас новостное агентство и вы хотите проанализировать тексты своих конкурентов на конкретную тематику. Какую лексику они используют? Как подают информацию? Конечно, найти такие статьи можно вручную, но проще настроить программу и поручить эту задачу ей.
Или так: вы любитель литературы и сейчас страшно хотите найти информацию о болгарских поэтах. На болгарском. В болгарском интернете информации о болгарской литературе в принципе мало, и поэтому штудировать каждый сайт – долго. В таком случае есть смысл обратиться к парсеру. Загоняете в программу ключевые слова и фразы, по которым она будет искать материал о поэтах, – и ждете, пока софт завершит работу.
То есть парсить информацию могут все, кто захочет. В основном этим занимаются те, кому нужно проанализировать контент конкурентов.
Зачем нужны прокси для веб-скрейпинга?
В web data scraping вы не обойдетесь без прокси. Есть две причины использовать промежуточные серверы.
Если обновляете страницу определенное количество раз, на ней срабатывает антифрод-система. Сайт начинает воспринимать ваши действия как DDoS-атаку. Итог – доступ к странице закрывается, вы не можете зайти на нее.
Парсер делает огромное количество запросов на сайт. Поэтому в любой момент его работу может остановить антифрод-система. Чтобы успешно собрать информацию, используйте даже несколько IP-адресов. Все зависит от того, какое количество запросов необходимо сделать.
Некоторые сайты защищаются от веб-скрейпинга как могут. А прокси помогают эту защиту обойти. Например, вы парсите информацию из буржевых сайтов, а у них стоит защита. Когда программа захочет скопировать содержимое страниц в таблицу, она сможет это сделать, но ресурс отдаст вам информацию на русском – не на английском.
Чтобы обойти такую антифрод-систему, используют прокси того же сервера, на котором расположен сайт. Например, парсить инфу с американского веб-ресурса нужно с американским IP.
Какие прокси использовать?
Покупайте платные прокси. Благодаря ним вы обойдете антифрод-системы сайтов. Бесплатные не дадут вам этого сделать: веб-ресурсы уже давно занесли бесплатные айпи в блэклисты. И если сделаете огромное количество запросов с публичного адреса, в какой-то момент произойдет следующее:
Во втором случае вы сможете спокойно скрайпить и дальше, но нужно будет при каждом новом обращении к странице вводить капчу.
Иногда достаточно одного запроса, чтобы сайт закрыл доступ или попросил ввести капчу. Так что вывод один: только платные промежуточные серверы.
Купить недорогие прокси для веб-скрейпинга вы можете на нашем сайте. Если не будет получаться настроить его или возникнут другие вопросы – пишите. Саппорт онлайн 24/7. Отвечает в течение 5 минут.
А сколько их должно быть?
Точно сказать, сколько использовать прокси для веб-скрейпинга, нельзя. У каждого сайта свои требования, а у каждого парсера в зависимости от задачи будет свое количество запросов.
300-600 запросов в час с одного айпи-адреса – вот примерные лимиты сайтов. Будет хорошо, если отыщете ограничение для ресурсов с помощью тестов. Если у вас нет такой возможности – берите среднее арифметическое: 450 запросов в час с одного IP.
К каким программам обратиться?
Инструментов для парсинга много. Они написаны на разных языках программирования: Ruby, PHP, Python. Есть программы с открытым кодом, где пользователи вносят изменения в алгоритм, если нужно.
Для вас – самые популярные программы для веб-скрейпинга:
Найдите подходящий софт для себя. А еще лучше – попробуйте несколько и выберите из них лучший.
А это законно?
Если боитесь собирать данные с сайтов, не стоит. Парсинг – это законно. Все, что находится в открытом доступе, можно собирать.
Например, вы можете спокойно спарсить электронные почты и номера телефонов. Это личная информация, но если пользователь сам публикует ее, претензий уже не может быть.
Заключение
Благодаря веб-скрапингу пользователи собирают каталоги товаров, цены на эти товары, спортивную статистику, даже целые тексты. Парсинг без блокировки – это реально: достаточно просто закупиться IP-адресами и менять их.
Веб-скрейпинг на PHP

Термин web scraping означает извлечение информации из веб-страниц в интернете. Его ещё называют web crawling или web data extraction.
PHP широко используется в качестве серверного скриптового языка для создания динамических сайтов и веб-приложений. И на нём можно написать веб-скрейпер. Но поскольку мы не хотим изобретать колесо, можно воспользоваться готовыми open-source библиотеками для веб-скрейпинга. Кстати, мы также написали отличную статью про веб-скрейпинг с помощью Node.js и с помощью Python, почитайте. А здесь мы обсудим разные инструменты и сервисы, которые можно использовать с PHP для скрейпинга веб-страниц: Guzzle, Goutte, Simple HTML DOM, Headless-браузер Symfony Panther.
Вот что нам потребуется для работы:
Выполните в терминале эти две команды для инициализации composer.json:
1. Веб-скрейпинг на PHP с использованием Guzzle, XML и XPath
Guzzle — это HTTP-клиент для PHP, позволяющий легко отправлять HTTP-запросы. Он предоставляет простой интерфейс для написания строк запросов. XML — язык разметки для представления документов в удобочитаемом для человека и компьютера формате. XPath — это язык запросов для навигации и выбора XML-узлов.
Посмотрим, как можно использовать эти инструменты для скрейпинга сайта. Начнём с установки Guzzle через Composer, выполним в терминале команду:
После установки Guzzle создадим новый PHP-файл guzzle_requests.php, в который будем добавлять код. Для примера спарсим сайт Books to Scrape, другие сайты вы сможете скрейпить действуя аналогично. Books to Scrape выглядит так:

Нам нужно извлечь названия книг и отобразить их в терминале. Первым делом нужно разобраться в HTML-макете. В этом случае его можно посмотреть, кликнув правой кнопкой над списком книг и выбрав пункт Inspect. Скриншот исходного кода страницы:
На экране должно появиться вот что:
Работает. А что если теперь нам нужно получить стоимость книг?
Если исполнить код в терминале, то получим:
Ваш код должен выглядеть так:
Конечно, это лишь базовый веб-скрейпер, его можно улучшить. Перейдём к следующей библиотеке.
2. Веб-скрейпинг на PHP с использованием Goutte
Goutte — ещё один прекрасный HTTP-клиент для PHP, созданный специально для веб-скрейпинга. Его разработал автор фреймворка Symfony, он предоставляет хороший API для извлечения данных из HTML/XML-ответов сайтов. Вот некоторые компоненты клиента для упрощений скрейпинга:
После установки создадим новый файл goutte_requests.php для кода. Ниже мы обсудим, что мы сделали с помощью библиотеки Guzzle в предыдущей главе. Извлечём с помощью Goutte названия книг с сайта Books to Scrape. Также покажем, как можно добавлять цены в переменную массива и использовать её в коде. Добавьте в файл goutte_requests.php этот код:
Выполним его с помощью команды в терминале:
Выше показан один из способов скрейпинга с помощью Goutte. Давайте рассмотрим способ с применением компонента CSSSelector из Goutte. CSS-селектор проще в использовании, чем XPath из предыдущего способа. Создадим ещё один PHP файл — goutte_css_requests.php. Добавим в него код:
И увидим аналогичный результат:
Наш веб-скрейпер с Goutte работает хорошо. Давайте теперь посмотрим, можно ли кликнуть на ссылку и перейти на другую страницу. На нашем демо-сайте Books to Scrape при клике на название книги загружается страница с описанием:
Посмотрим, можно ли кликнуть на ссылку в списке книг, перейти на страницу с описанием и извлечь его. Изучим код интересующей страницы:
Модифицируем файл goutte_css_requests.php:
Если исполнить его в терминале, то мы увидим название, цену и описание книги:
С помощью компонента Goutte CSS Selector и возможности кликать на странице вы можете легко бродить по многостраничным сайтам и извлекать сколько угодно информации.
3. Веб-скрейпинг на PHP с использованием Simple HTML DOM
Теперь можно устанавливать библиотеку:
Затем создаём новый PHP-файл — simplehtmldom_requests.php. Мы уже рассматривали макет страницы, так что сразу перейдём к коду. Добавьте в simplehtmldom_requests.php:
Если выполнить код в терминале, получим:
4. Веб-скрейпинг на PHP с использованием Headless-браузера Symfony Panther
Headless-браузер — это браузер без графического интерфейса. Благодаря этой особенности мы можем использовать терминал для загрузки страниц в среде, аналогичной браузеру и писать код для управления навигацией, как в предыдущих примерах. Зачем это нужно? Сегодня большинство разработчиков используют для развёртывания веб-фреймворки на JavaScript. Эти фреймворки генерируют внутри браузеров HTML-код. В других случаях для динамической загрузки содержимого применяют AJAX. В предыдущих примерах мы использовали статичные HTML-страницы, поэтому и результат скрейпинга был согласованным. А в случае с динамическими страницами, в которых HTML генерируется с помощью JavaScript и AJAX, получившееся DOM-дерево может сильно отличаться, что нарушит работу скрейпера. Решить эту проблему поможет headless-браузер.
В качестве такого браузера можно использовать PHP-библиотеку Symfony Panther. Её применяют и для скрейпинга, и для прогона тестов с использованием настоящих браузеров. Кроме того, библиотека предоставляет такие же методы, как и Goutte, поэтому можно использовать Panther вместо Goutte. Возможности Panther:
Создадим новый PHP-файл panther_requests.php. Добавим в него код:
Чтобы запустить его в системе, нужно установить драйверы для Chrome или Firefox, в зависимости от клиента, используемого в вашем коде. К счастью, Composer может это сделать автоматически. Выполним в терминале команду установки и определения драйверов:
Теперь можно выполнить в терминале PHP-файл, который сделает скриншот страницы и сохранит его в текущую директорию, а потом покажет список названий книг со страницы.
Заключение
Мы рассмотрели разные open-source PHP-библиотеки, которые можно использовать для скрейпинга сайтов. С помощью этого руководства вы сможете сделать простенький скрейпер для одной-двух страниц. Хотя мы прошлись лишь по верхам, но рассмотрели большинство доступных способов использования библиотек. Теперь вы можете сделать более сложный скрейпер, способный обходить тысячи страниц. Код из статьи лежит в репозитории.
Дополнительные источники информации, которые могут быть вам полезны
Четыре проекта с веб-скрейпингом, которые позволят упростить себе жизнь

Подумайте обо всех тех вещах, которые вы делаете в течение дня. Возможно, вы читаете новости, отправляете электронные письма, находите самые выгодные цены на товары или ищете работу онлайн. Большинство этих задач можно автоматизировать при помощи веб-скрейпинга, поэтому вместо того, чтобы вы тратили часы на изучение веб-сайтов, компьютер может сделать это за вас в течение пары минут.
Веб-скрейпинг — это процесс извлечения данных с веб-сайта. Для изучения веб-скрейпинга достаточно пройти туториал о принципах работы таких библиотек Python, как Beautiful Soup, Selenium или Scrapy; однако если вы не будете применять на практике все изученные концепции, то время окажется потраченным впустую.
Именно поэтому стоит попробовать создавать проекты с веб-скрейпингом, которые не только помогут вам освоить теорию веб-скрейпинга, но и позволять разработать ботов. автоматизирующих повседневные задачи.
В этой статье я перечислю проекты, которые автоматизируют четыре задачи, ежедневно выполняемые многими людьми. Проекты изложены по возрастанию сложности, от начальных до продвинутых.
1. Автоматизируем повторяющиеся задачи
Чтобы первый проект был простым для новичков, мы используем Beautiful Soup, потому что это самая лёгкая библиотека Python для веб-скрейпинга.
Ниже перечислены некоторые другие повторяющиеся задачи, которые можно автоматизировать при помощи веб-скрейпинга. Помните, что для их автоматизации требуются начальные знания Selenium (для изучения Selenium с нуля прочитайте это руководство [en]).
2. Скрейпинг футбольных данных: автоматизируем спортивную аналитику
Если вам нравится спорт, то после каждого матча вы, вероятно, заходите на веб-сайты со свободно доступной статистикой, например, со счётом игры и показателями игроков. Разве не здорово было бы получать эти данные после каждого нового матча? Или даже лучше — представьте, что вы сможете использовать эти данные для создания отчёта, чтобы сделать интересные открытия о своей любимой команде или лиге.
И это задача второго проекта — выполнить скрейпинг веб-сайта, содержащего статистику вашего любимого вида спорта. Чаще всего подобные данные находятся внутри таблицы, поэтому экспортируйте эти данные в формат CSV, чтобы потом считать их при помощи библиотеки Pandas. Чтобы представить, как выглядит проект, посмотрите gif. В этом демо я извлекаю результаты матчей в нескольких футбольных лигах за последние три года.
Большинство сайтов со спортивными данными использует JavaScript для динамического обновления этих данных. Это значит, что мы не сможем использовать для этого проекта библиотеку Beautiful Soup. Вместо этого мы используем Selenium для нажатия на кнопки, выбора элементов раскрывающихся меню и извлечения нужных нам данных.
Код для реализации этого проекта выложен на моём Github. Можно усложнить этот проект, находя команды, которые обычно забивают больше голов в матче. После этого можно будет создать отчёт, из которого можно понять, в каких матчах есть тенденция к большему количеству голов. Это поможет вам принимать более правильные решения при анализе футбольного матча. По ссылке ниже можно найти руководство по созданию этой последней части проекта.
3. Скрейпинг доски объявлений с вакансиями: автоматизируем поиск работы
Поиск работы благодаря веб-скрейпингу становится проще. Такие задачи, как просмотр нескольких страниц в поисках новых вакансий, проверка требований к кандидату и диапазона зарплат может ежедневно занимать примерно по двадцать минут, если делать это вручную. К счастью, всё это можно автоматизировать при помощи кода.
В этом проекте мы создаём бота, занимающегося скрейпингом портала вакансий для получения требований к кандидату по конкретной работе и предлагаемой зарплате. Для этого проекта можно использовать Beautiful Soup или Selenium, но решения при этом будут различаться.
Если вы пользуетесь Beautiful Soup, то учитывайте только те страницы, на которых есть те данные, которые нужно скрейпить. Чтобы освоиться с проектом, можно посмотреть этот видео-туториал.
Несмотря на это, я бы рекомендовал использовать Selenium, так как он позволяет производить больше действий на веб-сайте. Лучше всего то, что можно запускать код после каждого действия и наблюдать в браузере за шагами, которые выполняет бот. Чтобы решить эту задачу в Selenium, задумайтесь о всех шагах, которые вы обычно выполняете, чтобы получить данные с портала вакансий. Например, вы заходите на веб-сайт, вводите название должности, нажимаете на кнопку поиска и просматриваете каждую вакансию, чтобы извлечь всю важную информацию. После этого воспроизведите эти шаги на Python с помощью библиотеки Selenium.
4. Скрейпинг цен на товары: находим лучшую цену
Если вы стараетесь найти лучшую цену на конкретный товар, шоппинг может занимать очень много времени. Поиск лучшей цены машины, телевизора или одежды на нескольких сайтах может занимать многие часы; к счастью, благодаря нашему новому проекту веб-скрейпинга на это будет тратиться пара минут.
Это самый сложный проект в этой статье и он разделён на две части. Во-первых, зайдите в любимый онлайн-магазин и соберите данные о продуктах, например, название, цену, скидку и ссылки на них, чтобы можно было отслеживать их в дальнейшем. Если вы планируете скрейпить множество страниц, то рекомендую использовать для этого проекта библиотеку Scrapy, потому что это самая быстрая библиотека для веб-скрейпинга на Python. Чтобы начать работу над проектом, можно изучить этот туториал.
Во второй части проекта нам нужно отслеживать извлечённые цены, чтобы когда цена на конкретный продукт значительно снижалась, мы получали бы уведомление.
Помните, что последний проект можно адаптировать и под другие интересующие вас области. Например:
На правах рекламы
Устанавливайте любые операционные системы и выполняйте разнообразные задачи на наших облачных серверах с процессорами Intel Xeon Gold. Сервер готов к работе через минуту после оплаты!



