Правда о регистре символов, которую должны знать программисты
На конференции North Bay Python в 2018 году я делал доклад об именах пользователей. Информация из доклада по большей части была собрана мною за 12 лет поддержки django-registration. Этот опыт дал мне гораздо больше знаний, чем я планировал получить, о том, насколько сложными могут быть «простые» вещи.
В начале доклада я, правда, упомянул, что это не будет очередное разоблачение из серии «заблуждения по поводу Х, в которые верят программисты». Таких разоблачений можно найти сколько угодно. Однако мне подобные статьи не нравятся. В них перечисляются разные вещи, якобы являющиеся ложными, однако очень редко объясняется – почему это так, и что нужно делать вместо этого. Подозреваю, что люди просто прочтут такие статьи, поздравят себя с этим достижением, и потом пойдут находить новые интересные способы делать ошибки, не упомянутые в этих статьях. Всё потому, что они на самом деле не поняли проблем, порождающих этих ошибки.
Поэтому в своём докладе я постарался как можно лучше объяснить некоторые проблемы и пояснить, как их решать – такой подход мне нравится гораздо больше. Одна из тем, которой я коснулся лишь вскользь (это был всего один слайд и пара упоминаний на других слайдах) – это сложности, которые могут быть связаны с регистром символов. Для задачи, которую я обсуждал – сравнение идентификаторов без учёта регистра – есть официальный Правильный Ответ™, и в докладе я дал лучшее из известных мне решений, использующее только стандартную библиотеку Python.
Однако я кратко упомянул о более глубоких сложностях с регистром символов в Unicode, и хочу посвятить некоторое время описанию подробностей. Это интересно, и понимание этого может помочь вам принимать решения при проектировании и написании кода, обрабатывающего текст. Поэтому предлагаю вам нечто противоположное статьям «заблуждения по поводу Х, в которые верят программисты» – «правда, которую должны знать программисты».
И ещё одно: в Unicode полно терминологии. В данной статье я буду использовать в основном определения «верхний регистр» и «нижний регистр», поскольку стандарт Unicode использует эти термины. Если вам нравятся другие термины, вроде строчная/прописная буквы – всё нормально. Также я часто буду использовать термин «символ», который некоторые могут счесть некорректным. Да, в Unicode концепция «символа» не всегда совпадает с ожиданиями людей, поэтому часто лучше избегать её, используя другие термины. Однако в данной статье я буду использовать этот термин так, как он используется в Unicode – для описания абстрактной сущности, о которой можно делать заявления. Когда это важно, для уточнения я буду использовать более конкретные термины типа «кодовой позиции» [code point].
Регистров бывает больше двух
Носители европейских языков привыкли к тому, что в их языках регистр символов используется для обозначения конкретных вещей. К примеру, в английском [и русском] языках мы обычно начинаем предложения с буквы в верхнем регистре, а продолжаем чаще всего буквами в нижнем регистре. Также имена собственные начинаются с букв в верхнем регистре, и многие акронимы и аббревиатуры записываются в верхнем регистре.
И мы обычно считаем, что регистров существует всего два. Есть буква «А», и есть буква «а». Одна в верхнем, другая в нижнем регистре – не правда ли?
Однако в Unicode есть три регистра. Есть верхний, есть нижний, и есть титульный регистр [titlecase]. В английском языке так записываются названия. Например, «Avengers: Infinity War». Обычно для этого первая буква каждого слова просто пишется в верхнем регистре (и в зависимости от разных правил и стилей, некоторые слова, например, артикли, не пишутся с заглавных букв).
В стандарте Unicode дан такой пример символа в титульном регистре: U+01F2 LATIN CAPITAL LETTER D WITH SMALL Z. Выглядит он так: Dz.
Подобные символы иногда требуются для обработки негативных последствий одного из ранних решений разработки стандарта Unicode: совместимости с существующими текстовыми кодировками в обе стороны. Для Unicode было бы удобнее составлять последовательности при помощи имеющихся у стандарта возможностей по комбинированию символов. Однако во многих уже существующих системах уже были отведены места для готовых последовательностей. К примеру, в стандарте ISO-8859-1 («latin-1») у символа «é» есть готовая форма, имеющая номер 0xe9. В Unicode предпочтительнее было бы писать эту букву при помощи отдельной «е» и знака ударения. Но для обеспечения полной совместимости в обе стороны с такими существующими кодировками, как latin-1, в Unicode также назначены кодовые позиции для готовых символов. К примеру, U+00E9 LATIN SMALL LETTER E WITH ACUTE.
Хотя кодовая позиция этого символа совпадает с его байтовым значением из latin-1, полагаться на это не стоит. Вряд ли кодирование символов в Unicode сохранит эти позиции. К примеру, в UTF-8 кодовая позиция U+00E9 записана в виде байтовой последовательности 0xc3 0xa9.
И, конечно, в уже существующих кодировках есть символы, которым требовалось особое обхождение при использовании титульного регистра, из-за чего они были включены в Unicode «как есть». Если хотите посмотреть на них, поищите в своей любимой базе Unicode символы из категории Lt («Letter, titlecase»).
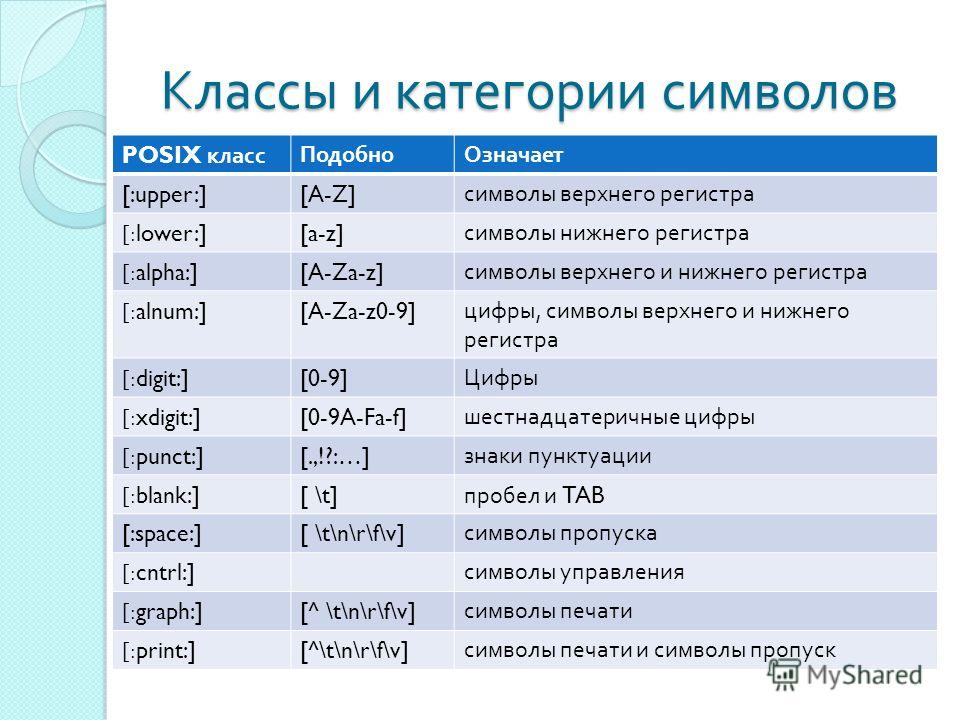
Есть несколько способов определить регистр
Если вы работаете с ограниченным подмножеством символов (конкретно, с буквами), то вам может хватить и 1-го определения. Если ваш репертуар шире – в него входят похожие на буквы символы, не являющиеся буквами, вам может подойти 2-е определение. Его рекомендует и стандарт Unicode, §4.2:
Программистам, манипулирующим строками в Unicode, стоит работать с такими строковыми функциями, как isLowerCase (и её функциональным родственником toLowerCase), если они не работают со свойствами символов напрямую.
Упомянутая здесь функция определяется в §3.13 стандарта Unicode. Формально в 3-м определении используются функции isLowerCase и isUpperCase из §3.13, определяемые в терминах фиксированных позиций в toLowerCase и toUpperCase соответственно.
Если в вашем языке программирования есть функции для проверки или преобразования регистра строк или отдельных символов, стоит изучить, какие из упомянутых определений используются в реализации. Если вам интересно, то методы isupper() и islower() в Python используют 2-е определение.
Нельзя понять регистр символа по его внешнему виду или названию
По внешнему виду многих символов можно понять, в каком они регистре. К примеру, «А» находится в верхнем регистре. Это понятно и по названию символа: «LATIN CAPITAL LETTER A». Однако иногда такой метод не работает. Возьмём кодовую позицию U+1D34. Выглядит она так: ᴴ. В Unicode ей назначено имя: MODIFIER LETTER CAPITAL H. Значит, она в верхнем регистре, так?
На самом же деле она наследует свойство Lowercase, поэтому по определению №2 она находится в нижнем регистре, несмотря на то, что визуально напоминает заглавную Н, а в названии есть слово «CAPITAL».
У некоторых символов вообще нет регистра
Символ С имеет регистр тогда и только тогда, когда у С есть свойство Lowercase или Uppercase, или значение параметра General_Category равно Titlecase_Letter.
Значит, очень много символов из Unicode – на самом деле, большая их часть – регистра не имеет. Не имеют смысла вопросы об их регистре, а изменения регистра на них не действуют. Однако мы можем получить ответ на этот вопрос по определению №3.
Некоторые символы ведут себя так, будто у них несколько регистров
Из этого следует, что если вы используете определение №3, и задаёте вопрос, находится ли символ без регистра в верхнем или нижнем регистре, вы получите ответ «да».
В стандарте Unicode даётся пример (таблица 4-1, строка 7) символа U+02BD MODIFIER LETTER REVERSED COMMA (который выглядит так: ʽ). У него нет унаследованных свойств Lowercase или Uppercase, он не принадлежит к категории Lt, поэтому регистра у него нет. При этом преобразование в верхний регистр его не меняет, и преобразование в нижний регистр его не меняет, поэтому по 3-му определению он отвечает «да» на оба вопроса: «принадлежишь ли ты к верхнему регистру?» и «принадлежишь ли ты к нижнему регистру?»
Кажется, что из-за этого может возникнуть никому не нужная путаница, однако смысл в том, что определение №3 работает с любой последовательностью символов Unicode, и позволяет упростить алгоритмы преобразования регистра (символы без регистра просто превращаются сами в себя).
Регистр зависит от контекста
Можно подумать, что если таблицы преобразования регистра в Unicode покрывают все символы, то это преобразование заключается просто в поиске нужного места в таблице. К примеру, в базе данных Unicode записано, что для символа U+0041 LATIN CAPITAL LETTER A нижним регистром будет U+0061 LATIN SMALL LETTER A. Просто, не так ли?
Один из примеров, в котором этот подход не работает – греческий язык. Символ Σ — то есть, U+03A3 GREEK CAPITAL LETTER SIGMA — сопоставлен двум разным символам при преобразовании в нижний регистр, в зависимости от того, где он находится в слове. Если он стоит на конце слова, тогда в нижнем регистре он будет ς (U+03C2 GREEK SMALL LETTER FINAL SIGMA). В любом другом месте это будет σ (U+03C3 GREEK SMALL LETTER SIGMA).
Регистр зависит от локали
В разных языках правила преобразования регистра разные. Самый популярный пример: i (U+0069 LATIN SMALL LETTER I) и I (U+0049 LATIN CAPITAL LETTER I) в большинстве локалей преобразовываются друг в друга – в большинстве, но не во всех. В локалях az и tr (тюркские языки), i в верхнем регистре будет İ (U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE), а I в нижнем регистре будет ı (U+0131 LATIN SMALL LETTER DOTLESS I). Иногда правильная запись реально означает разницу между жизнью и смертью.
Сам Unicode не обрабатывает все возможные правила преобразования регистра для всех локалей. В базе данных Unicode есть только общие правила преобразования всех символов, не зависящие от локали. Также там есть особые правила для некоторых языков и составных форм – литовского языка, тюркских языков, некоторых особенностей греческого. Всего остального там нет. §3.13 стандарта упоминает это и рекомендует при необходимости вводить правила преобразования, зависящие от локали.
Один пример будет знаком англоговорящим – это титульный регистр определённых имён. «o’brian» нужно преобразовывать в «O’Brian» (а не в «O’brian»). Однако при этом «it’s» нужно преобразовывать в «It’s», а не в «It’S». Ещё один пример, который не обрабатывается в Unicode – это голландское буквосочетание «ij», которое при преобразовании в титульный регистр должно переходить в верхний регистр целиком, если стоит в начале слова. Таким образом, большой залив в Нидерландах в титульном регистре будет «IJsselmeer», а не «Ijsselmeer». В Unicode есть символы IJ U+0132 LATIN CAPITAL LIGATURE IJ и ij U+0133 LATIN SMALL LIGATURE IJ, если они вам нужны. По умолчанию преобразование регистра преобразует их друг в друга (хотя формы нормализации Unicode, использующие эквивалентность совместимости, разделят их на два отдельных символа).
Сравнение без учёта регистра требует приведения к сложенному регистру
Возвращаясь к материалу, представленному в докладе. Сложность работы с регистром в Unicode означает, что регистронезависимое сравнение нельзя проводить при помощи стандартных функций приведения к нижнему или верхнему регистру, имеющихся во многих языках программирования. Для таких сравнений в Unicode есть концепция приведения к сложенному регистру [case folding], а в §3.13 стандарта определяются функции toCaseFold и isCaseFolded.
Можно решить, что приведение к сложенному регистру похоже на приведение к нижнему регистру – но это не так. Стандарт Unicode предупреждает, что строка в сложенном регистре не обязательно будет находиться в нижнем регистре. В качестве примера приводится язык чероки – там в строке, находящейся в сложенном регистре, будут попадаться и символы в верхнем регистре.
На одном из слайдов моего доклада рекомендации Unicode Technical Report #36 реализуются на Python настолько полно, насколько это возможно. Проводится нормализация NFKC и потом для полученной строки вызывается метод casefold() (доступный только в Python 3+). И даже при этом некоторые крайние случаи выпадают, и это не совсем то, что рекомендуется для сравнения идентификаторов. Сначала плохие новости: Python не выдаёт наружу достаточно свойств Unicode для того, чтобы отфильтровать символы, которых нет в XID_Start или XID_Continue или символы, имеющие свойство Default_Ignorable_Code_Point. Насколько мне известно, он не поддерживает отображение NFKC_Casefold. Также в нём нет простого способа использовать модифицированный NFKC UAX #31§5.1.
Хорошие новости: большинство этих крайних случаев не связано с какими-либо реальными рисками безопасности, создаваемыми рассматриваемыми символами. И складывание регистра в принципе не определяется как операция, сохраняющая нормализацию (отсюда и отображение NFKC_Casefold, которое повторно нормализуется до NFC после складывания регистра). Как правило, при сравнении вас не волнует, будут ли обе строки нормализованы после предварительной обработки. Вас заботит, не противоречива ли предварительная обработка, и гарантирует ли она, что только строки, которые «должны» отличаться впоследствии, будут отличаться впоследствии. Если вас это беспокоит, вы можете вручную выполнить повторную нормализацию после сложения регистра.
Пока достаточно
Эта статья, как и предыдущий доклад, не является исчерпывающей, и вряд ли можно уложить весь этот материал в единственный пост. Надеюсь, что это был полезный обзор сложностей, связанных с этой темой, и вы найдёте в нём достаточно отправных точек для того, чтобы искать дальнейшую информацию. Поэтому в принципе, можно остановиться и тут.
Не будет ли наивной моя надежда на то, что другие люди перестанут писать разоблачения из серии «заблуждения по поводу Х, в которые верят программисты», и начнут уже писать статьи типа «правда, которую должны знать программисты»?
Что значит Пароль должен содержать буквы верхнего и нижнего регистра?
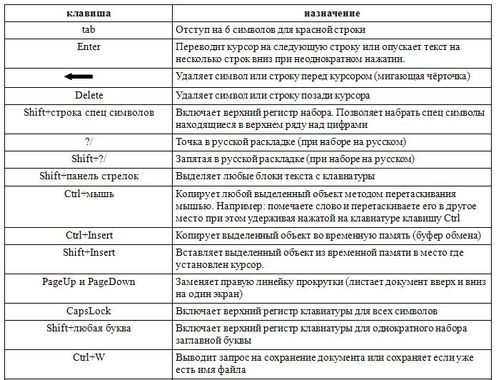
При первом знакомстве с клавиатурой у начинающих пользователей нередко возникает следующий вопрос: «Что такое верхний и нижний регистр на клавиатуре?» Оказывается, все очень просто. Верхний регистр означает, что в данный момент времени с клавиатуры вводятся заглавные буквы, а нижний, соответственно, – строчные.
Какие символы должен содержать пароль?
Помощь по единому профилю
Что за буквы верхнего регистра?
верхний регистр — Большие, прописные буквы, расположенные в верхнем регистре, такие как A, B, C (в противоположность строчным, маленьким буквам a, b, c и т. … прописные буквы (верхний регистр) — Атрибут поля, означающий, что в этом поле строчные буквы преобразуются в прописные по мере их ввода.
Что такое верхний и нижний регистр клавиатуры?
Проще говоря, если у нас включен нижний регистр клавиатуры, то печатаются строчные (маленькие) буквы. Если у нас включен верхний регистр клавиатуры, то печатаются заглавные (большие) буквы. … Нажимаем клавишу с буквой “З” – печатается заглавная (большая) буква “З”, которая находится в верхнем регистре клавиатуры.
Что не должен содержать пароль?
Пароль не должен содержать
Личную информацию, которую легко узнать. Например: имя, фамилию или дату рождения. Очевидные и простые слова, фразы, устойчивые выражения и наборы символов, которые легко подобрать. Например: password, parol, abcd, qwerty или asdfg, 1234567.
Что такое специальные символы в пароле?
Это значение указывает, что пароль не может содержать 2 или более последовательных специальных символа. Специальный символ — это символ, значение unicode которого не может быть представлено в виде буквы или цифры. Это значение указывает, что первым символом пароля не может быть специальный символ.
Как должен выглядеть пароль?
Хороший пароль – всегда комбинированный. В нем используются символы, буквы и цифры разного регистра. Длина пароля – желательно не менее 8 символов, а лучше не менее 12. Избегайте смысловых паролей: не используйте распространенные фразы или слова.
Какая клавиша используется для перевода клавиатуры в верхний регистр?
Как это символ в верхнем регистре?
Где находится верхний регистр
Если буква, которую нужно написать заглавной находится справа, то используют левую сторону. При переходе нажимают одновременно, сначала «Shift», а затем требуемый знак. А при расположении нужного символа слева – наоборот.
Как печатать в верхнем регистре?
Самым удобным способом переключения регистра, который работает во всех версиях Microsoft Word, является использование комбинации клавиш Shift + F3. Чтобы изменить регистр, необходимо выделить нужный участок текста, нажать клавишу «Shift» и, не отпуская ее, нажать клавишу «F3».
Что значит в нижнем регистре?
нижний регистр — Маленькие, строчные буквы, расположенные в нижнем регистре, такие как a, b, c (в противоположность большим, прописным буквам A, B, C и т. д.).
Как отключить заглавные буквы на клавиатуре на айфоне?
Как убрать заглавные буквы на Айфоне
Что такое регистр на компьютере?
Регистр процессора — поле заданной длины во внутрипроцессорной сверхбыстрой оперативной памяти (СОЗУ). … Используется самим процессором, может быть как доступным, так и недоступным программно.
Почему нельзя использовать пароли содержащие кириллицу?
Почему нельзя использовать
Связано с тем, в каком виде и кодировке храниться ваш пароль на том или ином ресурсе, в некоторых системах буквы русского алфавита будут сохранены некорректно и вы не сможете войти на сайт.
Как увидеть сохраненные пароли?
Чтобы посмотреть пароли, откройте страницу passwords.google.com. Там вы найдете список аккаунтов с сохраненными паролями. Примечание. Если вы используете для синхронизации кодовую фразу, вы не сможете просматривать пароли на этой странице, но увидите их в настройках Chrome.
Что такое верхний регистр В пароле?
Это означает что в пароле у тебя должно быть хотя бы одно заглавное букво, к примеру : Пароль, а не пароль. … Верхний регистр означает, что в данный момент времени с клавиатуры вводятся заглавные буквы, а нижний, соответственно, – строчные.
Что такое верхний и нижний регистр на клавиатуре?
Кратковременное переключение
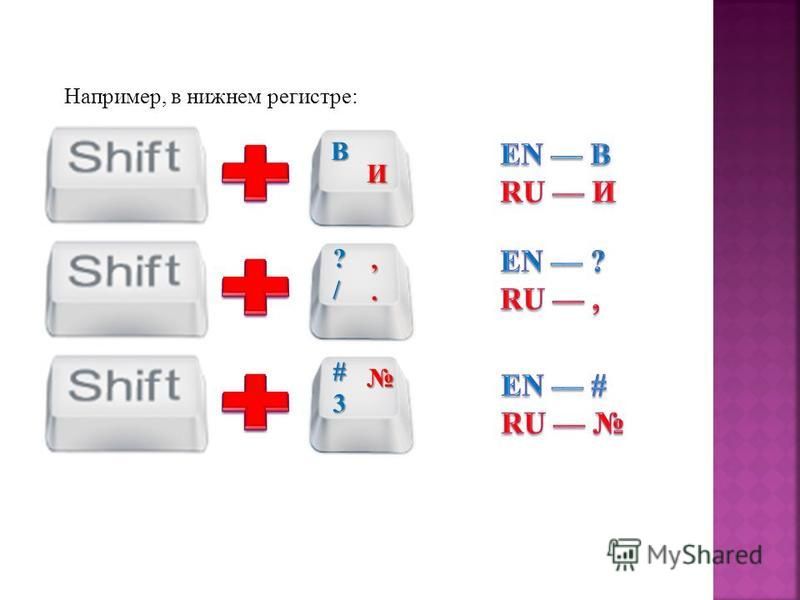
Теперь мы знаем, что такое верхний и нижний регистр на клавиатуре. Разберемся с основными способами переключения между «большими» и «маленькими» буквами. Существует кратковременное и постоянное переключение. Еще один способ программно реализован в офисном обеспечении. Он также будет рассмотрен в рамках данного материала. Начнем с кратковременного. На каждой компьютерной клавиатуре есть клавиша «Shift» (на некоторых из них вместо надписи может быть изображена стрелочка вверх). Если в данный момент времени вводятся заглавные буквы, то при нажатии этой клавиши в сочетании с любым текстовым символом появиться он в нижнем регистре, и наоборот. Этот способ удобно использовать в начале предложения. То есть ввели прописной символ, а затем все набирается уже в строчном формате.
Длительный набор
Верхний и нижний регистр клавиатуры могут быть переключены и другим методом. Для этих целей есть специальный ключ «Caps Lock». Он обычно расположен в крайнем левом ряду клавиатуры между клавишами «Tab» и «Shift». При его нажатии происходит постоянная смена регистра. Для определения текущего режима смотрим на светодиод на клавиатуре с точно такой же надписью — «Caps Lock». Если он горит, то это означает, что вводятся заглавные буквы, иначе – строчные. Для перехода из одного режима в другой нажимаем этот ключ еще раз. Этот способ лучше всего применять тогда, когда необходимо постоянно набирать текст в одном формате (например, только прописные символы), а переключение между форматом ввода если и происходит, то не настолько часто.
Что такое верхний и нижний регистр на клавиатуре
Данные понятия известны еще со времени активного использования людьми печатных машинок. При нанесении текста на бумагу, его простой шрифт, печатаемый при стандартном расположении оборудования, назывался нижним, а заглавные буквы, получаемые путем сдвига печатных штанг вверх — верхним. Точно такая же функция присутствует сегодня на клавиатуре любого современного гаджета и стационарных устройствах печати.
Используя кнопку клавиатуры «Shift» пользователь, во время набора текста может совершать переходы от строчных букв к заглавным и наоборот, а клавиши, отвечающие за нанесение цифр, переходят к нанесению различных символов и знаков препинания, порой используемых при создании документа. Другими словами, верхний регистр – это определенный режим печати, при выборе которого строчные буквы переходят в заглавные, а цифры – на определенного рода символику. Нижний же регистр представляет собой стандартные режим отображения букв и цифр. Где находится верхний регистр
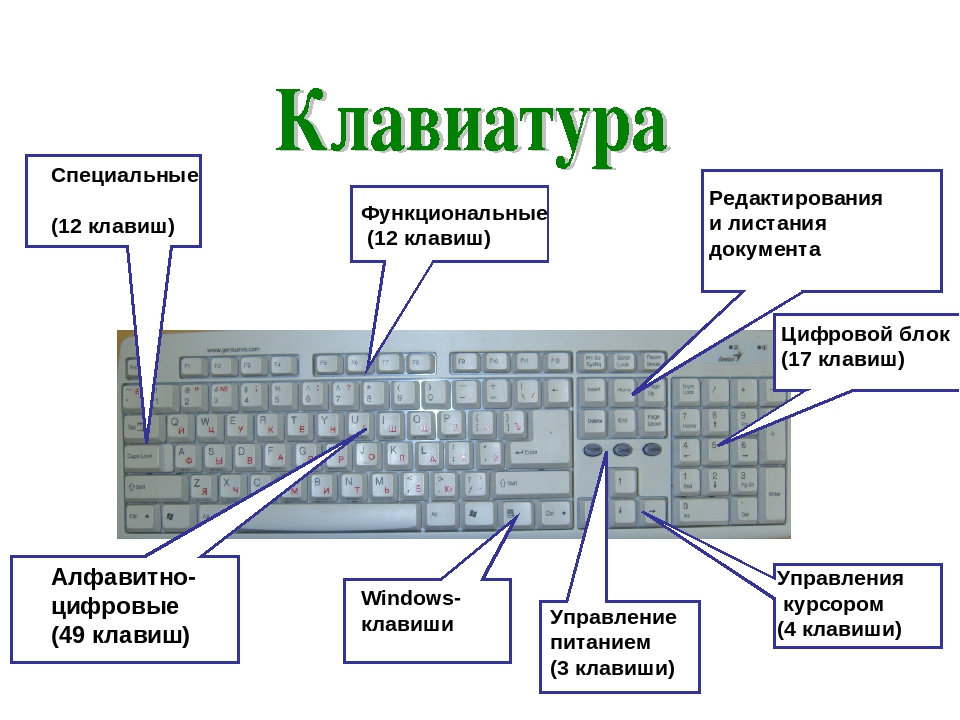

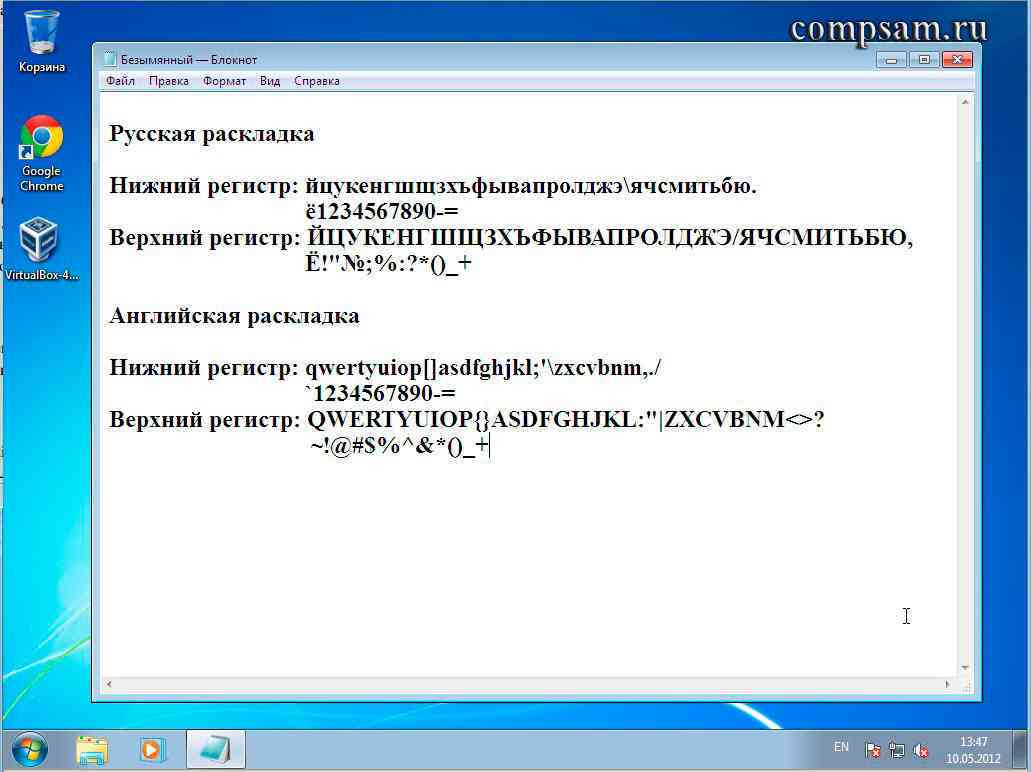






Где находится верхний регистр
Переход с одного регистра на другой можно осуществить при помощи нажатия на клавиатуре одной из клавиш «Shift», расположенных в левой и правой нижних частей клавиатуры. Использование двух клавиш удобно тем, что позволяет увеличить скорость набора текста. Так, если буква, которая должна быть заглавной, расположена в правой части клавиатуры, зажимают левый «Shift», а если в левой части, то правый. Для совершения перехода от строчной буквы к заглавной необходимо, сперва нажать на «Shift», а затем, на клавишу самой буквы. Аналогичные действия производятся для перехода от цифр к символике. Если же говорить о мобильных устройствах, то, как правило, они снабжены лишь одной клавишей «Shift» из-за своих не особо больших размеров.
Удобство использования верхнего регистра дает возможность быстрой смены функции необходимого символа из одного положения в другое. Дополнительно, с левой стороны, прямо над «Shift», имеется клавиша с надписью «Caps Lock», имеющая точно идентичное функциональное назначение, но несколько иной принцип работы.
Для офисных приложений
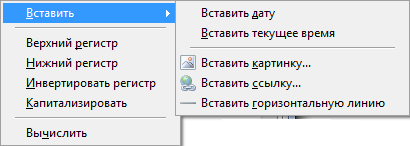
Еще один способ изменения заглавных и прописных символов реализован в офисном пакете компании «Microsoft». Наиболее часто его используют в текстовом процессоре «Ворд». В процессе ввода вы забыли случайно перейти с больших букв к маленьким или наоборот? Символы верхнего и нижнего регистров в данном случаем можно изменить следующим образом. Выделяем необходимый фрагмент текста либо с помощью левой кнопки мышки, либо с применением «Shift» и клавиш управления курсором. Далее в панели инструментов «Главная» находим подраздел «Шрифт». В нем есть кнопка для смены регистра. На ней изображены большая и маленькая буквы «а». Кликаем на ней левой кнопкой мышки один раз. Выпадет меню, в котором нужно выбрать нужный нам пункт. Например, если ввели прописные, а нужны строчные, то выбираем пункты «Изменить регистр» или «Все строчные». Независимо от выбора результат будет идентичный – все буквы в выделенном фрагменте станут «маленькими». Этот метод можно использовать только в офисном пакете компании «Микрософт», и только на тексте, который введен в компьютер.
Итоги
В рамках данной статьи дан ответ на вопрос о том, что такое верхний и нижний регистр на клавиатуре. Также приведены основные способы переключения между заглавными и прописными символами. Одним, строго определенным способом пользоваться не рекомендуется – это снизит существенно продуктивность работы. Лучше всего их комбинировать и, в зависимости от ситуации, использовать тот или иной.








верхний регистр — Большие, прописные буквы, расположенные в верхнем регистре, такие как A, B, C (в противоположность строчным, маленьким буквам a, b, c и т.д.). [http://www.morepc.ru/dict/] Тематики информационные технологии в целом EN ucupper case … Справочник технического переводчика
переход на верхний регистр — Переключение клавиатуры для ввода заглавных (прописных) букв и других символов верхнего регистра. [http://www.morepc.ru/dict/] Тематики информационные технологии в целом EN shift outSO … Справочник технического переводчика
прописные буквы (верхний регистр) — Атрибут поля, означающий, что в этом поле строчные буквы преобразуются в прописные по мере их ввода. [http://www.morepc.ru/dict/] Тематики информационные технологии в целом EN uppercase … Справочник технического переводчика
РЕГИСТР — (фр., от лат. regesta, regestum внесенное. 1) всякая общественная или частная книга, в которую записывают факты и деяния, память о которых нужно сохранить. 2) объем голоса у певцов. 3) в органах: всякий самостоятельный голос. Словарь иностранных… … Словарь иностранных слов русского языка
РЕГИСТР — РЕГИСТР, регистра, муж. (от новолат. registrum из regestum внесенное, записанное). 1. Список чего нибудь, реестр; Указатель, книга для записей (спец.). || Указатель (спец.). Регистр лиц, упомянутых в книге. 2. Степень высоты и силы голоса (муз.) … Толковый словарь Ушакова






регистр пианино — Часть музыкального диапазона пианино по высоте, отличающаяся характерной звуковой окраской. Примечание У пианино различают: басовый (нижний) регистр субконтроктава, контроктава, большая октава, теноровый (средний) регистр малая, 1 и 2 октавы,… … Справочник технического переводчика
ВЕРХНИЙ — ВЕРХНИЙ, верхняя, верхнее; ант. нижний. 1. Находящийся сверху или вверху. Верхний этаж. Верхние слои общества. 2. Близкий к истоку реки, расположенный в верховьях реки. Верхнее течение. 3. Надеваемый поверх какой нибудь одежды. Верхнее платье.… … Толковый словарь Ушакова
верхний — прил., употр. часто 1. Верхней частью какого либо многоуровневого объекта (или наслоения однородных объектов) называют ту часть, которая расположена выше других. Противоположную часть называют нижней. Верхний этаж, уровень, ярус, пласт, слой чего … Толковый словарь Дмитриева
регистр тона фонетической синтагмы — Уровень, выделяемый в связи с движением тона голоса вверх или вниз: 1) средний регистр тона – это такой уровень тона, на котором произносится большинство речевых тактов и фраз: Листья пожелтели, осыпались, завяли; 2) верхний регистр – уровень… … Словарь лингвистических терминов Т.В. Жеребило
РЕГИСТР — РЕГИСТР, а, муж. (спец.). 1. Список, указатель чего н., книга для записей. 2. Степень высоты голоса, музыкального инструмента. Бас голос низкого регистра. 3. В нек рых музыкальных инструментах: группа труб или группа язычковых одинакового тембра … Толковый словарь Ожегова






ВЕРХНИЙ — ВЕРХНИЙ, яя, ее. 1. Расположенный вверху, выше прочих. В. этаж. 2. Близкий к верховью реки. Верхнее течение. 3. Об одежде: носимый поверх другой одежды. Верхняя одежда (пальто, шуба, плащ, куртка). 4. Относящийся к верхам (в 8 знач.). В. регистр … Толковый словарь Ожегова
Верхний регистр — это заглавные буквы, нижний регистр строчные.
Разберем на примере слова — привет:— Верхний регистр — «ПРИВЕТ» — Нижний регистр — «привет»— Первая буква в верхнем регистре — «Привет» — Последняя буква в верхнем регистре — «привеТ»



