Нормализация баз данных
Нормальная форма — требование, предъявляемое к отношениям в теории реляционных баз данных для устранения из базы избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных.
Содержание
Нормализация баз данных
Процесс преобразования базы данных к виду, отвечающему нормальным формам, называется нормализацией. Нормализация позволяет обезопасить базу данных от логических и структурных проблем, называемых аномалиями данных. К примеру, когда существует несколько одинаковых записей в таблице, существует риск нарушения целостности данных при обновлении таблицы. Таблица, прошедшая нормализацию, менее подвержена таким проблемам, т.к. ее структура предполагает определение связей между данными, что исключает необходимость в существовании записей с повторяющейся информацией.
Происхождение и назначение нормальных форм
Понятие нормальной формы было введено Эдгаром Коддом при создании реляционной модели БД. Основное назначение нормальных форм — приведение структуры базы данных к виду, обеспечивающему минимальную избыточность. Устранение избыточности производится за счёт декомпозиции отношений (таблиц) таким образом, чтобы в каждом отношении хранились только первичные факты (то есть факты, не выводимые из других хранимых фактов). Таким образом, нормализация не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение объёма БД. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в БД информации.
Типы нормальных форм
Нормализация может применяться к таблице, которая представляет собой правильное отношение.
Первая нормальная форма (1NF)
Таблица находится в первой нормальной форме, если каждый её атрибут атомарен. Под выражением «атрибут атомарен» понимается, что атрибут может содержать только одно значение. Таким образом, не существует 1NF таблицы, в полях которых могут храниться списки значений. Для приведения таблицы к 1NF обычно требуется разбить таблицу на несколько отдельных таблиц.
Замечание: в реляционной модели отношение всегда находится в 1 (или более высокой) нормальной форме в том смысле, что иные отношения не рассматриваются в реляционной модели. То есть само определение понятия отношение заведомо подразумевает наличие 1NF.
Вторая нормальная форма (2NF)
Таблица находится во второй нормальной форме, если она находится в первой нормальной форме, и при этом любой её атрибут, не входящий в состав первичного ключа, функционально полно зависит от первичного ключа. Функционально полная зависимость означает, что атрибут функционально зависит от всего первичного составного ключа, но при этом не находится в функциональной зависимости от какой-либо из входящих в него атрибутов(частей). Или другими словами: в 2NF нет неключевых атрибутов, зависящих от части составного ключа (+ выполняются условия 1NF).
Третья нормальная форма (3NF)
Таблица находится в третьей нормальной форме (3NF), если она находится во второй нормальной форме 2NF и при этом любой ее неключевой атрибут зависит только от первичного ключа (Primary key, PK) (иначе говоря, один факт хранится в одном месте).
При решении практических задач в большинстве случаев третья нормальная форма является достаточной. Процесс проектирования реляционной базы данных, как правило, заканчивается приведением к 3NF.
Нормальная форма Бойса — Кодда (BCNF)
Это модификация третьей нормальной формы (в некоторых источниках именно 3NF называется формой Бойса — Кодда).
Таблица находится в BCNF, если она находится в 3NF, и при этом отсутствуют функциональные зависимости атрибутов первичного ключа от неключевых атрибутов. Таблица может находиться в 3NF, но не в BCNF, только в одном случае: если она имеет, помимо первичного ключа, ещё по крайней мере один возможный ключ. Все зависимые от первичного ключа атрибуты должны быть потенциальными ключами отношения. Если это условие не выполняется, для них создаётся отдельное отношение. Чтобы сущность соответствовала BCNF, она должна находиться в третьей нормальной форме. Любая сущность с единственным возможным ключом, соответствующая требованиям третьей нормальной формы, автоматически находится в BCNF.
Четвёртая нормальная форма (4NF)
Таблица находится в 4NF, если она находится в BCNF и не содержит нетривиальных многозначных зависимостей. Многозначная зависимость не является функциональной, она существует в том случае, когда из факта, что в таблице содержится некоторая строка X, следует, что в таблице обязательно существует некоторая определённая строка Y. То есть, таблица находится в 4NF, если все ее многозначные зависимости являются функциональными.
Пятая нормальная форма (5NF)
Таблица находится в 5NF, если она находится в 4NF и любая многозначная зависимость соединения в ней является тривиальной. Пятая нормальная форма в большей степени является теоретическим исследованием и практически не применяется при реальном проектировании баз данных. Это связано со сложностью определения самого наличия зависимостей «проекции — соединения», поскольку утверждение о наличии такой зависимости должно быть сделано для всех возможных состояний БД.
Доменно-ключевая нормальная форма (DKNF)
Отношение в ДКНФ не имеет аномалий модификации. Другими словами, что бы ни менялось — ничего не потеряется, если соблюдены все ограничения относительно ключей и доменов. Формулировка слишком общая, но суть ее заключается в том, что если выполнять некоторые правила, то при любых действиях с таблицей ее целостность не пострадает и вся необходимая информация сохранится. Если рассматривать на примере, то правила действуют примерно так: нельзя просто удалить категорию из таблицы категорий, если с этой категорией связаны, например, продукты из таблицы продуктов. Прежде чем удалять категорию, необходимо выполнить предварительные действия в таблице продуктов (например, поле отвечающее за id категории этого товара нужно сделать
Шестая нормальная форма (6NF)
Таблица находится в 6NF, если она находится в 5NF и удовлетворяет требованию отсутствия нетривиальных зависимостей. Зачастую 6NF отождествляют с DKNF.
См. также
Ссылки
DDL, SELECT | INSERT | UPDATE | MERGE | DELETE | JOIN | UNION | CREATE | ALTER | DROP
Сравнение синтаксиса
Типы реализаций
Flat file | Deductive | Dimensional | Иерархическая | Объектно-ориентированная | Temporal
Полезное
Смотреть что такое «Нормализация баз данных» в других словарях:
Проектирование баз данных — процесс создания схемы базы данных и определения необходимых ограничений целостности. Содержание 1 Основные задачи проектирования баз данных … Википедия
Нормализация БД — Нормальная форма требование, предъявляемое к отношениям в теории реляционных баз данных для устранения из базы избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Содержание 1… … Википедия
Нормализация (значения) — Нормализация (франц. normalisation упорядочение, от normal правильный, положенный) Нормализация приведение чего либо в нормальное состояние; Приведение вещества или материала к однородной консистенции путём обработки, например,… … Википедия
Реляционные базы данных — Реляционная база данных база данных, основанная на реляционной модели данных. Слово «реляционный» происходит от англ. relation (отношение[1]). Для работы с реляционными БД применяют реляционные СУБД. Использование реляционных баз данных было… … Википедия
Реляционная база данных — Реляционная база данных база данных, основанная на реляционной модели данных. Слово «реляционный» происходит от англ. relation (отношение[1]). Для работы с реляционными БД применяют реляционные СУБД. Использование реляционных баз… … Википедия
Нормальные формы — Нормальная форма требование, предъявляемое к отношениям в теории реляционных баз данных для устранения из базы избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Содержание 1… … Википедия
Реляционные БД — Реляционная база данных база данных, основанная на реляционной модели. Слово «реляционный» происходит от английского «relation» (отношение[1]). Для работы с реляционными БД применяют Реляционные СУБД. Использование реляционных баз данных было… … Википедия
Нормальная форма — У этого термина существуют и другие значения, см. Нормальная форма (значения). Нормальная форма свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности, потенциально приводящей к логически ошибочным… … Википедия
Израиль — Государство Израиль, в Зап. Азии, на вост. побережье Средиземного моря. Образовано в 1948 г. на основе решения Генеральной Ассамблеи ООН от 29 ноября 1947 г. В качестве названия принято название еврейского гос ва, существовавшего примерно в этих… … Географическая энциклопедия
Нормализация базы данных и ее формы
Примечание:
Во всех статьях текущей категории уроков по SQL используются примеры и задачи, основанные на учебной базе данных.
Приступая к изучению данного материала, рекомендуется ознакомиться с описанием учебной БД.
Материал этой статьи напрямую не относиться к изучению языка SQL, так как имеет отношение к проектированию баз данных (БД), но для общего понимания взаимосвязи хранимой в системе информации она будет полезна.
По поводу того, как должна быть спроектирована база нет 100% решения, потому что конкретный вариант может удовлетворять либо не удовлетворять различным бизнес-процессам и целям. Но не принимать во внимание элементарные правила нельзя, так как их соблюдение сохранит много времени, нервов и денег при работе с данными.
Нормализация баз данных заключается в приведении структуры хранения данных к нормальным формам (NF). Всего таких форм существует 8, но часто достаточным является соблюдение первых трех. Рассмотрим их более подробно на примере учебной базы данных. Примеры будут строится по принципу «что было бы, если было иначе, чем сейчас».
Первая нормальная форма
Основным правилом первой формы является необходимость неделимости значения в каждом поле (столбце) строки – атомарность значений.
Рассмотрим таблицы сотрудников и телефонных линий.

Чтобы избавиться от связывающей таблицы «Сотрудники_Линии», мы могли бы записать идентификаторы сотрудников для каждой линии в виде перечня в дополнительном столбце:

Но подобная структура не является надежной. Представьте, что Вам необходимо поменять некоторым сотрудникам подключенные линии. Потребуется осуществить разбор составного поля, чтобы определить наличие id сотрудника в каждой записи линий, затем скорректировать перечень. Получается слишком сложный и долгий процесс для такой простой операции.
Организации структуры таблиц с применением дополнительной связывающей избавляет от подобных проблем.
Помимо атомарности к первой нормальной форме относятся следующие правила:
Вторая нормальная форма
Условием этой формы является отсутствие зависимости неключевых полей от части составного ключа.
Так как составной ключ в учебной базе наблюдается только в таблице «Сотрудники_Линии», то рассмотрим пример на ней.
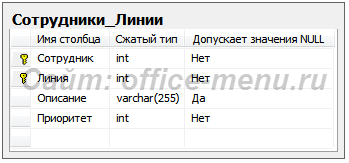
На представленной диаграмме столбцы описания и приоритета зависят от столбца «Линия», входящего в составной ключ. Это значит, что для каждой линии, подключенной разным сотрудникам, потребуется повторно указывать описание и приоритетность. Подобная структура приводит к избыточности данных.
Также велика вероятность возникновения противоречивой информации. Изменяя приоритет или описание для линии, можно по ошибке оставить некоторые строки не обработанными. В таком случае, для одного и того же идентификатора линии значения зависимых полей будут различными.
Если соблюдены правила первой нормальной формы, то создание таблицы «Линии» и перенос в нее зависимых столбцов удовлетворяет второй нормальной форме.
Третья нормальная форма
3NF схожа по логике с 2NF, но с некоторым отличием. Если 2 форма ликвидирует зависимости неключевых полей от части ключа, то третья нормальная форма исключает зависимость неключевых полей от других неключевых полей.
На приведенном примере таблицы сотрудников видно, что столбец «Супервайзер» имеет зависимость от столбца «Группа», а это значит, что при изменении значения поля группы, потребуется изменить значение поля супервайзера.
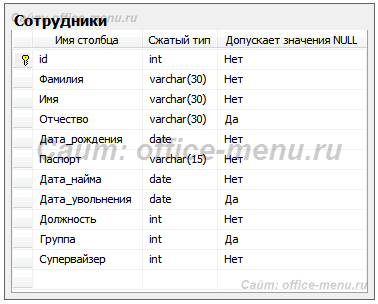
Все риски, которые были рассмотрены для 2NF, так же относятся к 3NF и устраняются переносом зависимых полей в отдельную таблицу.
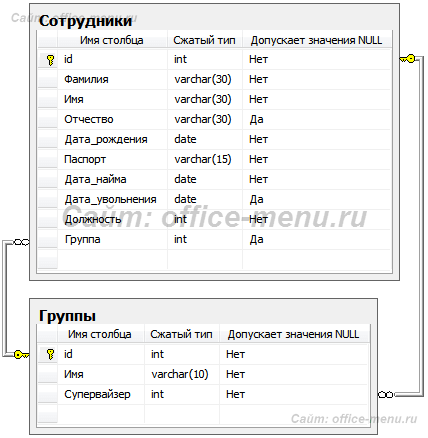
Денормализация базы данных
Теория нормальных форм не всегда применима на практике. Например, неатомарные значения не всегда являются «злом», а иногда наоборот. Связано это с необходимостью дополнительного объединения (следовательно, затрат производительности системы) при выполнении запросов, особенно когда производится обработка большого массива информации.
Для баз данных, предназначенных для аналитики, часто выполняют денормализацию, чтобы укорить выполнение запросов.
Нормализация базы данных
При построении баз данных необходимо следовать определённым правилам. Эти правила получили название нормализации баз данных. Нормализация базы данных является не обязательной, но эти правила существенно упростят работу по составлению запросов и способствуют улучшению масштабируемости.
Нормализация базы данных
Нормализация базы данных – это рекомендации по проектированию.
Преимущества нормализованной базы данных:
Как привести базу данных к нормальной форме?
Для приведения базы к нормальной форме необходимо выполнить следующие действия:
Существует 3 нормальные формы базы данных:
В одной ячейке одно значение. Исключение тип данных SET
Таблица представляет сущность которая в ней размещена (например клиенты, заказы и т.д.) Причём в каждой таблице имеется уникальное поле (первичный ключ) например id и каждая таблица состоит из наименьшего количества полей.
| id | name | languages |
| 1 | Иван | Java, C++, PHP |
| 2 | Пётр | PHP, JavaScript |
| 3 | Михаил | C#, JavaScript |
В примере №1. Представлена не удачная структура таблицы, где в поле languages указано перечисление.
| id | name | languages1 | languages2 | languages3 |
| 1 | Иван | Java | C++ | PHP |
| 2 | Пётр | PHP | JavaScript | NULL |
| 3 | Михаил | C# | JavaScript | NULL |
В примере №2 тоже не верная структура таблицы для поля languages.
Правильная структура таблиц для решения данной задачи:
| id | name | languages |
| 1 | Иван | Java, C++, PHP |
| 2 | Пётр | PHP, JavaScript |
| 3 | Михаил | C#, JavaScript |
Таблица языков программирования
| id | language |
| 1 | Java |
| 2 | PHP |
| 3 | C# |
| 4 | JavaScript |
| 5 | Java |
Таблица связей между пользователями и языками программирования
| id | language_id | user_id |
| 1 | 2 | 1 |
| 2 | 1 | 1 |
| 3 | 5 | 1 |
| 4 | 1 | 2 |
Поля с не первичным ключом не должны быть зависимы от первичного ключа.
| id | make | model |
| 1 | bmw | X5 |
| 2 | bmw | X6 |
| 3 | audi | A4 |
| 4 | audi | Q5 |
| 5 | toyota | corolla |
В примере №4 мы видим дублирование некоторых марок автомобилей (Данные избыточны). Требуется сделать разделение на несколько таблиц как в примере №3. На первый взгляд создание новых таблиц кажется более затратным чем реализация в примере №4, но это только до тех пор когда таблица состоит всего из нескольких строк.
Таблица цен и цен с НДС
| id | price | price_nds |
| 1 | 1100 | 1243 |
| 2 | 950 | 1074 |
Так как цену с НДС можно получить из поля price, то данную задачу нужно переложить на язык программирования.
Нормализация и денормализация базы данных, нормальные формы
 Нормализация схемы реляционной БД оказывает существенное влияние буквально на все аспекты взаимодействия с БД: от затрат на модификацию структур и данных до производительности запросов приложений и хранимых объёмов информации. В ряде случаев структуры могут быть сознательно денормализованы, что созвучно с другим словом «деморализованы». Однако, следует хорошо понимать, с какой целью это было сделано и полностью отдавать себе отчёт о последствиях. В общем же случае безопаснее всего придерживаться простого правила:
Нормализация схемы реляционной БД оказывает существенное влияние буквально на все аспекты взаимодействия с БД: от затрат на модификацию структур и данных до производительности запросов приложений и хранимых объёмов информации. В ряде случаев структуры могут быть сознательно денормализованы, что созвучно с другим словом «деморализованы». Однако, следует хорошо понимать, с какой целью это было сделано и полностью отдавать себе отчёт о последствиях. В общем же случае безопаснее всего придерживаться простого правила:
Нормализация — не догма, но чтобы её нарушать, нужны основания
На практике проектирования схем баз данных достижение третьей нормальной формы (3НФ) считается достаточным условием для большинства случаев.
Первая нормальная форма (1НФ) выполняется, если все значения атрибутов (читай, колонок таблицы) атомарны, то есть неделимы.
Собственные типы данных СУБД считаются атомарными, исключение могут составлять массивы, в том числе символьные (текстовые) и байтовые. Следует также понимать, что атомарность может быть относительна выбранного взгляда со стороны предметной области и контекста. Например, телефонный номер в базе данных маркетинга содержится в одной колонке, тогда как у телефонных операторов он разделяется на номера АТС, шлейфов и т.п. Колонки для хранения комментариев, подлежащих последующей обработке приложением, также отчасти нарушают принцип атомарности.
По этой же причине не стоит рассматривать отдельно целую и дробные части действительного числа или даже пару «дата-время»: дальнейшая детализация не имеет смысла с точки зрения моделируемой области, где они атомарны.
Предположим, мы нарушили 1НФ и стали хранить фамилии, имена и отчества клиентов в одной колонке. Пока операторы вносили информацию, эта ошибка проектирования особенно не мешала, Однако, на следующем этапе понадобилась отчётность, в которой ФИО клиентов выводились бы в виде фамилии и инициалов. Оказалось, что некоторые записи вместо «Сидоров Петр Иванович» содержат «Петр Иванович Сидоров», в других отчества нет вовсе, в третьих фамилия двойная и не всегда записана через тире, в четвёртых после фамилий расставлены запятые. Эту проблему пришлось решать программированием совсем нетривиальной логики с элементами распознавания по словарю. Было потрачено много времени и средств, но в отчётности нет-нет да и проскакивали непонятные значения типа «Оглы П.Б.Б.».
Следует отметить, что при добавлении к этому учёту клиентов- иностранцев, проектировщиков логической схемы БД не спасла бы и более структурированная форма из трёх колонок для раздельного хранения фамилий, имён и отчеств. Потому что это проблема уровня концептуального проектирования и соответствующих моделей: необходим синтез не привязанной к модели данных структуры, способной вмещать в себя комбинации имён людей разных стран и культур.
Вторая нормальная форма (2НФ) означает, что выполнены требования 1НФ, при этом все атрибуты целиком зависят от составного ключа и не зависят ни от какой его части.
На первый взгляд кажется, что нарушения 2НФ практически невозможны, потому что чаще всего в качестве первичных ключей используются автоинкрементные целочисленные значения или иные суррогаты для реализации ссылок. Однако, в определении говорится о ключах вообще, а не только о первичных. В отношении может быть несколько ключей, и некоторые из них могут являться составными. Такие ключи следует подвергнуть проверке в первую очередь.
Ассоциативная таблица — таблица, имеющая ключевые связи с двумя и более таблицами
Например, если каждая операция сбыта мебельной продукции в таблице продаж однозначно характеризуется колонками идентификатора товарной позиции, даты продажи и идентификатором покупателя, то нахождение в той же таблице столбца «Тип материала», зависящего непосредственно от товарной позиции, должно немедленно привлечь ваше внимание.
Аномалия в данном случае приведёт только к избыточности хранения в виде размера идентификатора, помноженного на число строк таблицы (без учёта индексов). Но если в той же таблице обнаружится ещё и колонка «Контактный телефон», присущая атрибутике покупателя, то последствия окажутся более серьёзными. Кроме избыточности хранения при ошибке ввода придётся исправлять номер телефона во всех записях о продажах данному покупателю.
Кроме приведённых примеров, при наличии в таблицах нескольких ключей необходимо, с позиций логики предметной области, определить, являются ли эти ключи присущими данной сущности или же они суть внешние ключи другой сущности, пока ещё не выделенной в процессе проектирования.
Третья нормальная форма (3НФ) означает, что выполнены требования 2НФ, при этом в между атрибутами отношения нет транзитивных зависимостей.
Что такое транзитивная зависимость легко понять на примере уже упоминавшейся выше таблицы продаж — типичного примера ассоциативной таблицы.
Предположим, что продажа каждой товарной позиции имеет своим основанием документ (заказ, счёт и т.д.), а её стоимость характеризуется ценой, количеством и валютой. В этом случае имеем следующие зависимости между атрибутами (колонками):
Эти зависимости транзитивны: каждая продажа однозначно определяет свой документ-основание и расчётную валюту, однако, валюта определяется ещё и документом.
Результатом нарушения 3НФ является избыточность хранения и необходимость обновления данных в связанной таблице. Так, если вы оставите колонку «Код валюты» в таблице продаж, то при изменении валюты документа придётся также обновлять все связанные с ним строки продаж.
Демормализация в базе данных: «звезда» и «снежинка»
Как можно понять из вышеприведённых примеров, основными целями нормализации являются:
Но список заявленных целей касается приложений транзакционных.
В приложениях интерактивной аналитической обработки приоритет меняется: на первый план выходит время отклика системы, в ущерб которому данные могут быть избыточны.
Зачем нужна денормализация?
Наиболее дорогостоящая с точки зрения вычислительных ресурсов операция между большими таблицами — соединение. Соответственно, если в одном запросе необходимо «провентилировать» несколько таблиц, состоящих из многих миллионов строк, то СУБД потратит достаточно много времени на такую обработку. Пользователь в это время может отойти выпить кофе. Интерактивность обработки практически исчезает и приближается к таковой для обработки пакетной. Даже хуже, в пакетном режиме пользователь с утра получает все запрошенные накануне данные и спокойно работает с ними, подготавливая новые запросы к вечеру.
Чтобы избежать ситуации тяжёлых соединений таблицы денормализуют. Но не абы как. Существуют некоторые правила, позволяющие считать денормализованные с точки зрения транзакционной обработки таблицы «нормализованными» согласно правилам построения таблиц для хранилищ данных.
Основных схем, считающихся «нормальными» в аналитической обработке, две: «снежинка» и «звезда». Названия хорошо отражают суть и следуют непосредственно из картинки связанных таблиц.
В обоих случаях центральным элементом схемы являются так называемые таблицы фактов, содержащие интересующие аналитика события, транзакции, документы и другие занятные вещи. Но если в транзакционной БД один документ «размазан» по нескольким таблицам (как минимум по двум: заголовки и строки-содержание), то в таблице фактов одному документу, точнее, каждой его строке или набору сгруппированных строк, соответствует одна запись. Сделать это можно денормализацией двух вышеупомянутых таблиц.
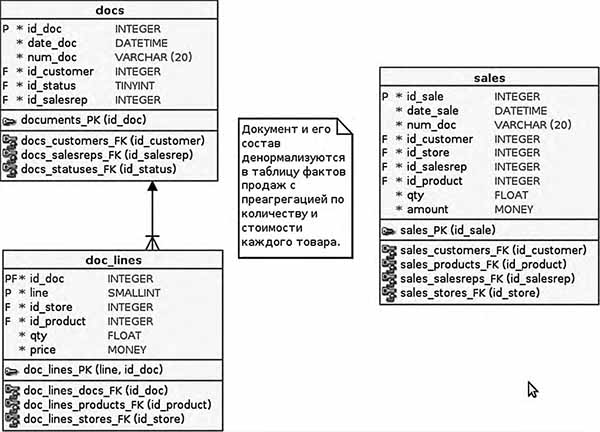
Рис. 1. Денормализация документов в таблицу фактов
Теперь можно оценить, насколько облегчится для выполнения СУБД запрос, например, следующего вида: определить объёмы продаж муки клиентам «ООО Пирожки» и «ЗАО Ватрушки» за период.
В нормализованной транзакционной БД:
В аналитической БД:
Вместо тяжёлого соединения между двумя таблицами документов и их состава с миллионами строк, СУБД достаётся прямая работа с таблицей фактов и лёгкие соединения с небольшими вспомогательными таблицами, без которых также можно обойтись, зная идентификаторы.
Вернёмся к схемам «звезда» и «снежинка». За кадром первого рисунка остались таблицы клиентов, их групп, магазинов, продавцов и, собственно, товаров. При денормализации эти таблицы, называющиеся измерениями, также соединяются с таблицей фактов. Если таблица фактов ссылается на таблицы-измерения, имеющие ссылки на другие измерения (измерения второго уровня и выше), то такая схема называется «снежинка».
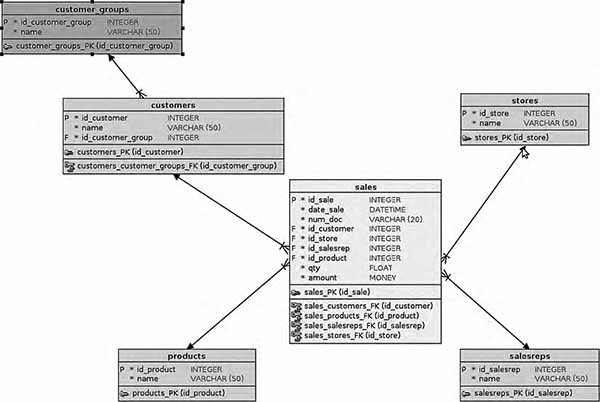
Рис. 2. Таблица фактов в схеме «снежинка»
Как можно заметить, для запросов, включающих фильтрацию по группам клиентов, приходится делать дополнительное соединение.
В таком случае денормализацию можно продолжить и опустить измерение второго уровня на первый, облегчив запросы к таблице фактов.
Схема, в которой таблица фактов ссылается только на измерения, не имеющие второго уровня, называется «звезда». Число таблиц измерений соответствует числу «лучей» в звезде.
Схема «Звезда» полностью исключает иерархию измерений и необходимость соединения соответствующих таблиц в одном запросе.
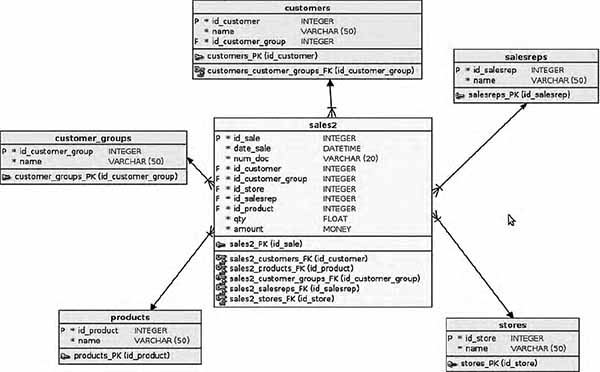
Рис. 3. Таблица фактов в схеме «звезда»
Обратной стороной денормализации всегда является избыточность, являющаяся причиной увеличения размера БД как в случае транзакционных, так и аналитических приложений. Давайте посчитаем примерную дельту на приведённом выше примере преобразования «снежинки» в «звезду».
В некоторых СУБД, например Oracle, специальные целочисленные типы на уровне определений схемы БД отсутствуют, необходимо использовать универсальный логический тип numeric(N), где N — число хранимых разрядов. Размер хранения такого числа рассчитывается по специальной формуле, приводимой в документации по физическому хранению данных, и, как правило, он превышает таковой для низкоуровневых типов вроде «16битное целое» на 1-3 байта.Положим, таблица продаж не использует компрессию данных и содержит около 500 миллионов строк, а количество групп покупателей порядка 1000. В этом случае мы можем использовать в качестве типа идентификатора id_customer_group короткое целое (shortint, smallint), занимающее 2 байта.
Будем считать, что наша СУБД поддерживает двухбайтовый целочисленный тип (например, PostgreSQL, SQL Server, Sybase и другие). Тогда добавление соответствующей колонки id_customer_group в таблицу продаж вызовет увеличение её размера как минимум на 500 000 000 * 2 = 1 000 000 000 байт



