Нулевая гипотеза в статистике: пример. Проверка нулевой гипотезы
Статистика — сложная наука об измерении и анализе различных данных. Как и во многих других дисциплинах, в этой отрасли существует понятие гипотезы. Так, гипотеза в статистике — это какое-либо положение, которое нужно принять или отвергнуть. Причём в данной отрасли есть несколько видов таких допущений, схожих между собой по определению, но отличающихся на практике. Нулевая гипотеза — сегодняшний предмет изучения.
От общего к частному: гипотезы в статистике
От основного определения предположений отходит ещё одно, не менее важное, — статистическая гипотеза есть изучение генеральной совокупности важных для науки объектов, относительно коих учёными делаются выводы. Ее можно проверить с помощью выборки (части генеральной совокупности). Приведём несколько примеров статистических гипотез:
 1. Успеваемость всего класса, возможно, зависит от уровня образования каждого учащегося.
1. Успеваемость всего класса, возможно, зависит от уровня образования каждого учащегося.
2. Начальный курс математики в равной степени усваивается как детьми, пришедшими в школу в 6 лет, так и детьми, пришедшими в 7.
Простой гипотезой в статистике называют такое предположение, которое однозначно характеризует определённый параметр величины, взятой учёным.
Сложная состоит из нескольких или бесконечного множества простых. Указывается некоторая область или нет точного ответа.
Полезно понимать несколько определений гипотез в статистике, чтобы не путать их на практике.
Концепция нулевой гипотезы
Нулевая гипотеза — это теория о том, что есть некие две совокупности, которые не различаются между собой. Однако на научном уровне нет понятия «не различаются», но есть «их сходство равно нулю». От этого определения и было образовано понятие. В статистике нулевая гипотеза обозначается как Н0. Причём крайним значением невозможного (маловероятного) считается от 0.01 до 0.05 или менее.
Лучше разобрать, что такое нулевая гипотеза, пример из жизни поможет. Педагог в университете предположил, что различный уровень подготовки учащихся двух групп к зачётной работе вызван незначительными параметрами, случайными причинами, не влияющими на общий уровень образования (разница в подготовке двух групп студентов равна нулю).
Однако встречно стоит привести пример альтернативной гипотезы — допущения, опровергающего утверждение нулевой теории (Н1). Например: директор университета предположил, что различный уровень в подготовке к зачётной работе у учащихся двух групп вызван применением педагогами разных методик обучения (разница в подготовке двух групп существенна и на то есть объяснение).
 Теперь сразу видна разница между понятиями «нулевая гипотеза» и «альтернативная гипотеза». Примеры иллюстрируют эти понятия.
Теперь сразу видна разница между понятиями «нулевая гипотеза» и «альтернативная гипотеза». Примеры иллюстрируют эти понятия.
Проверка нулевой гипотезы
Создать предположение — это ещё полбеды. Настоящей проблемой для новичков считается проверка нулевой гипотезы. Именно тут многих и ожидают трудности.
Используя метод альтернативной гипотезы, утверждающей нечто обратное нулевой теории, можно сравнить оба варианта и выбрать верный. Так действует статистика.
Пусть нулевая гипотеза Н0, а альтернативная Н1, тогда:
Здесь c — это некое среднее значение генеральной совокупности, которое предстоит найти, а c0 — данное изначально значение, по отношению к которому проверяется гипотеза. Также есть некоторое число Х — среднее значение выборки, по которому определяется c0.
«Доверительный» способ проверки
Существует наиболее действенный способ, с помощью которого нулевая статистическая гипотеза легко проверяется на практике. Он заключается в построении диапазона значений до 95% точности.
Итак, предположим ситуацию. До ремонта конвейер в день выпускал 32.1 кг конечной продукции, а после ремонта, как утверждает предприниматель, коэффициент полезного действия вырос, и конвейер, по недельной проверке, начал выпускать 39.6 кг в среднем.
 Нулевая гипотеза будет утверждать, что ремонт никак не повлиял на КПД конвейера. Альтернативная гипотеза скажет, что ремонт коренным образом изменил КПД конвейера, поэтому производительность его повысилась.
Нулевая гипотеза будет утверждать, что ремонт никак не повлиял на КПД конвейера. Альтернативная гипотеза скажет, что ремонт коренным образом изменил КПД конвейера, поэтому производительность его повысилась.
По таблице находим n=7, t = 2,447, откуда формула примет следующий вид:
39,6 – 2,447*4,2 ≤ с ≤ 39,6 + 2,447*4,2;
Разновидности отрицания
До этого рассматривался такой вариант построения гипотезы, где Н0 утверждает что-либо, а Н1 это опровергает. Откуда можно было составить подобную систему:
Но существует ещё два родственных способа опровержения. К примеру, нулевая гипотеза утверждает, что средняя оценка успеваемости класса больше 4.54, а альтернативная тогда скажет, что средняя успеваемость того же класса менее 4.54. И выглядеть в виде системы это будет так:
Объясняем p-значения для начинающих Data Scientist’ов
Я помню, когда я проходил свою первую зарубежную стажировку в CERN в качестве практиканта, большинство людей все еще говорили об открытии бозона Хиггса после подтверждения того, что он соответствует порогу «пять сигм» (что означает наличие p-значения 0,0000003).

Тогда я ничего не знал о p-значении, проверке гипотез или даже статистической значимости.
Я решил загуглить слово — «p-значение», и то, что я нашел в Википедии, заставило меня еще больше запутаться…
При проверке статистических гипотез p-значение или значение вероятности для данной статистической модели — это вероятность того, что при истинности нулевой гипотезы статистическая сводка (например, абсолютное значение выборочной средней разницы между двумя сравниваемыми группами) будет больше или равна фактическим наблюдаемым результатам.
— Wikipedia
Хорошая работа, Википедия.
Ладно. Я не понял, что на самом деле означает р-значение.
Углубившись в область науки о данных, я наконец начал понимать смысл p-значения и то, где его можно использовать как часть инструментов принятия решений в определенных экспериментах.
Поэтому я решил объяснить р-значение в этой статье, а также то, как его можно использовать при проверке гипотез, чтобы дать вам лучшее и интуитивное понимание р-значений.
Также мы не можем пропустить фундаментальное понимание других концепций и определение p-значения, я обещаю, что сделаю это объяснение интуитивно понятным, не подвергая вас всеми техническими терминами, с которыми я столкнулся.
Всего в этой статье четыре раздела, чтобы дать вам полную картину от построения проверки гипотезы до понимания р-значения и использования его в процессе принятия решений. Я настоятельно рекомендую вам пройтись по всем из них, чтобы получить подробное понимание р-значений:
1. Проверка гипотез

Прежде чем мы поговорим о том, что означает р-значение, давайте начнем с разбора проверки гипотез, где р-значение используется для определения статистической значимости наших результатов.
Наша конечная цель — определить статистическую значимость наших результатов.
И статистическая значимость построена на этих 3 простых идеях:
Другими словами, мы создадим утверждение (нулевая гипотеза) и используем пример данных, чтобы проверить, является ли утверждение действительным. Если утверждение не соответствует действительности, мы выберем альтернативную гипотезу. Все очень просто.
Чтобы узнать, является ли утверждение обоснованным или нет, мы будем использовать p-значение для взвешивания силы доказательств, чтобы увидеть, является ли оно статистически значимым. Если доказательства подтверждают альтернативную гипотезу, то мы отвергнем нулевую гипотезу и примем альтернативную гипотезу. Это будет объяснено в следующем разделе.
Давайте воспользуемся примером, чтобы сделать эту концепцию более ясной, и этот пример будет использоваться на протяжении всей этой статьи для других концепций.
Пример. Предположим, что в пиццерии заявлено, что время их доставки составляет в среднем 30 минут или меньше, но вы думаете, что оно больше чем заявленное. Таким образом, вы проводите проверку гипотезы и случайным образом выбираете время доставки для проверки утверждения:
Одним из распространенных способов проверки гипотез является использование Z-критерия. Здесь мы не будем вдаваться в подробности, так как хотим лучше понять, что происходит на поверхности, прежде чем погрузиться глубже.
2. Нормальное распределение
Нормальное распределение — это функция плотности вероятности, используемая для просмотра распределения данных.
Нормальное распределение имеет два параметра — среднее (μ) и стандартное отклонение, также называемое сигма (σ).
Среднее — это центральная тенденция распределения. Оно определяет местоположение пика для нормальных распределений. Стандартное отклонение — это мера изменчивости. Оно определяет, насколько далеко от среднего значения склонны падать значения.
Нормальное распределение обычно связано с правилом 68-95-99.7 (изображение выше).
Классно. Теперь вы можете задаться вопросом: «Как нормальное распределение относится к нашей предыдущей проверке гипотез?»
Поскольку мы использовали Z-тест для проверки нашей гипотезы, нам нужно вычислить Z-баллы (которые будут использоваться в нашей тестовой статистике), которые представляют собой число стандартных отклонений от среднего значения точки данных. В нашем случае каждая точка данных — это время доставки пиццы, которое мы получили.
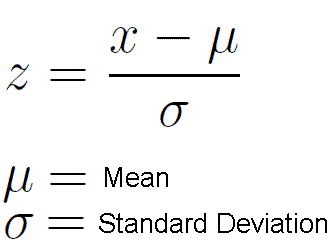
Обратите внимание, что когда мы рассчитали все Z-баллы для каждого времени доставки пиццы и построили стандартную кривую нормального распределения, как показано ниже, единица измерения на оси X изменится с минут на единицу стандартного отклонения, так как мы стандартизировали переменную, вычитая среднее и деля его на стандартное отклонение (см. формулу выше).
Изучение стандартной кривой нормального распределения полезно, потому что мы можем сравнить результаты теста с ”нормальной» популяцией со стандартизированной единицей в стандартном отклонении, особенно когда у нас есть переменная, которая поставляется с различными единицами.
Z-оценка может сказать нам, где лежат общие данные по сравнению со средней популяцией.
Мне нравится, как Уилл Кёрсен выразился: чем выше или ниже Z-показатель, тем менее вероятным будет случайный результат и тем более вероятным будет значимый результат.
Но насколько высокий (или низкий) показатель считается достаточно убедительным, чтобы количественно оценить, насколько значимы наши результаты?
Кульминация
Здесь нам нужен последний элемент для решения головоломки — p-значение, и проверить, являются ли наши результаты статистически значимыми на основе уровня значимости (также известного как альфа), который мы установили перед началом нашего эксперимента.
3. Что такое P-значение?
Наконец… Здесь мы говорим о р-значении!
Все предыдущие объяснения предназначены для того, чтобы подготовить почву и привести нас к этому P-значению. Нам нужен предыдущий контекст и шаги, чтобы понять это таинственное (на самом деле не столь таинственное) р-значение и то, как оно может привести к нашим решениям для проверки гипотезы.
Если вы зашли так далеко, продолжайте читать. Потому что этот раздел — самая захватывающая часть из всех!
Вместо того чтобы объяснять p-значения, используя определение, данное Википедией (извини Википедия), давайте объясним это в нашем контексте — время доставки пиццы!
Напомним, что мы произвольно отобрали некоторые сроки доставки пиццы, и цель состоит в том, чтобы проверить, превышает ли время доставки 30 минут. Если окончательные доказательства подтверждают утверждение пиццерии (среднее время доставки составляет 30 минут или меньше), то мы не будем отвергать нулевую гипотезу. В противном случае мы опровергаем нулевую гипотезу.
Поэтому задача p-значения — ответить на этот вопрос:
Если я живу в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), насколько неожиданными являются мои доказательства в реальной жизни?
Р-значение отвечает на этот вопрос числом — вероятностью.
Чем ниже значение p, тем более неожиданными являются доказательства, тем более нелепой выглядит наша нулевая гипотеза.
И что мы делаем, когда чувствуем себя нелепо с нашей нулевой гипотезой? Мы отвергаем ее и выбираем нашу альтернативную гипотезу.
Если р-значение ниже заданного уровня значимости (люди называют его альфа, я называю это порогом нелепости — не спрашивайте, почему, мне просто легче понять), тогда мы отвергаем нулевую гипотезу.
Теперь мы понимаем, что означает p-значение. Давайте применим это в нашем случае.
P-значение в расчете времени доставки пиццы
Теперь, когда мы собрали несколько выборочных данных о времени доставки, мы выполнили расчет и обнаружили, что среднее время доставки больше на 10 минут с p-значением 0,03.
Это означает, что в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), есть 3% шанс, что мы увидим, что среднее время доставки, по крайней мере, на 10 минут больше, из-за случайного шума.
Чем меньше p-значение, тем более значимым будет результат, потому что он с меньшей вероятностью будет вызван шумом.
В нашем случае большинство людей неправильно понимают р-значение:
Р-значение 0,03 означает, что есть 3% (вероятность в процентах), что результат обусловлен случайностью — что не соответствует действительности.
Р-значение ничего не *доказывает*. Это просто способ использовать неожиданность в качестве основы для принятия разумного решения.
— Кэсси Козырков
Вот как мы можем использовать p-значение 0,03, чтобы помочь нам принять разумное решение (ВАЖНО):
По моему мнению, p-значения используются в качестве инструмента для оспаривания нашего первоначального убеждения (нулевая гипотеза), когда результат является статистически значимым. В тот момент, когда мы чувствуем себя нелепо с нашим собственным убеждением (при условии, что р-значение показывает, что результат статистически значим), мы отбрасываем наше первоначальное убеждение (отвергаем нулевую гипотезу) и принимаем разумное решение.
4. Статистическая значимость
Наконец, это последний этап, когда мы собираем все вместе и проверяем, является ли результат статистически значимым.
Недостаточно иметь только р-значение, нам нужно установить порог (уровень значимости — альфа). Альфа всегда должна быть установлена перед экспериментом, чтобы избежать смещения. Если наблюдаемое р-значение ниже, чем альфа, то мы заключаем, что результат является статистически значимым.
Основное правило — установить альфа равным 0,05 или 0,01 (опять же, значение зависит от вашей задачи).
Как упоминалось ранее, предположим, что мы установили альфа равным 0,05, прежде чем мы начали эксперимент, полученный результат является статистически значимым, поскольку р-значение 0,03 ниже, чем альфа.
Для справки ниже приведены основные этапы всего эксперимента:
Если вы хотите узнать больше о статистической значимости, не стесняйтесь посмотреть эту статью — Объяснение статистической значимости, написанная Уиллом Керсеном.
Последующие размышления
Здесь много чего нужно переваривать, не так ли?
Я не могу отрицать, что p-значения по своей сути сбивают с толку многих людей, и мне потребовалось довольно много времени, чтобы по-настоящему понять и оценить значение p-значений и то, как они могут быть применены в рамках нашего процесса принятия решений в качестве специалистов по данным.
Но не слишком полагайтесь на p-значения, поскольку они помогают только в небольшой части всего процесса принятия решений.
Я надеюсь, что мое объяснение p-значений стало интуитивно понятным и полезным в вашем понимании того, что в действительности означают p-значения и как их можно использовать при проверке ваших гипотез.
Сам по себе расчет р-значений прост. Трудная часть возникает, когда мы хотим интерпретировать p-значения в проверке гипотез. Надеюсь, что теперь трудная часть станет для вас немного легче.
Если вы хотите узнать больше о статистике, я настоятельно рекомендую вам прочитать эту книгу (которую я сейчас читаю!) — Практическая статистика для специалистов по данным, специально написанная для data scientists, чтобы разобраться с фундаментальными концепциями статистики.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
Конспект курса «Основы статистики»
1. Введение
Способы формирования репрезентативной выборки:
Простая случайная выборка (simple random sample)
Стратифицированная выборка (stratified sample)
Групповая выборка (cluster sample)
Типы переменных:
непрерывные (рост в мм)
дискретные (количество публикаций у учёного)
Ранговые (успеваемость студентов)
Гистограмма частот:
Позволяет сделать первое впечатление о форме распределения некоторого количественного признака.
Описательные статистики:
Меры центральной тенденции (узкий диапазон, высокие значения признака):
(  используется для среднего значения из выборки, а для генеральной совокупности латинская буква
используется для среднего значения из выборки, а для генеральной совокупности латинская буква  )
)
Свойства среднего:

Если к каждому значению выборки прибавить определённое число, то и среднее значение увеличится на это число.

Если к каждому значению выборки прибавить определённое число, то и среднее значение увеличится на это число.

Если для каждого значения выборки, рассчитать такой показатель как его отклонение от среднего арифметического, то сумма этих отклонений будет равняться нулю.
Меры изменчивости (широкий диапазон, вариативность признака):

При добавлении сильно отличающегося значения данные меняются сильно и могут быть некорректные.
Дисперсия генеральной совокупности:

 (среднеквадратическое отклонение генеральной совокупности)
(среднеквадратическое отклонение генеральной совокупности)

 (среднеквадратическое отклонение выборки)
(среднеквадратическое отклонение выборки)
Свойства дисперсии:




Квартили распределения и график box-plot
Нормальное распределение
Отклонения наблюдений от среднего подчиняются определённому вероятностному закону.
Стандартизация




Правило «двух» и «трёх» сигм


Центральная предельная теорема
Есть признак, распределенный КАК УГОДНО* с некоторым средним и некоторым стандартным отклонением. Тогда, если выбирать из этой совокупности выборки объема n, то их средние тоже будут распределены нормально со средним равным среднему признака в ГС и стандартным отклонением  .
.

30″ alt=»SE = \frac
Доверительные интервалы для среднего
Доверительный интервал является показателем точности измерений. Это также показатель того, насколько стабильна полученная величина, то есть насколько близкую величину (к первоначальной величине) вы получите при повторении измерений (эксперимента).
Идея статистического вывода
2. Сравнение средних
T-распределение
Если число наблюдений невелико и \sigma неизвестно (почти всегда), используется распределение Стьюдента (t-distribution).
Унимодально и симметрично, но: наблюдения с большей вероятностью попадают за пределы  от
от 
«Форма» распределения определяется числом степеней свободы ( ).
).
С увеличением числа  распределение стремится к нормальному.
распределение стремится к нормальному.

t-распределение используется не потому что у нас маленькие выборки, а потому что мы не знаем стандартное отклонение в генеральной совокупности.
Сравнение двух средних; t-критерий Стьюдента
Критерий, который позволяет сравнивать средние значения двух выборок между собой, называется t-критерий Стьюдента.
Условия для корректности использования t-критерия Стьюдента:
Две независимые группы
Формула стандартной ошибки среднего:

Формула числа степеней свободы:

Формула t-критерия Стьюдента:

Переход к p-критерию:
Проверка распределения на нормальность, QQ-Plot
Однофакторный дисперсионный анализ
Часто в исследованиях необходимо сравнить несколько групп между собой. В таком случае применятся однофакторный дисперсионный анализ.
Группы:
Нулевая гипотеза:

Альтернативная гипотеза:
Среднее значение всех наблюдений:

Общая сумма квадратов (Total sum of sqares):

Показатель, который характеризует насколько высока изменчивость данных, без учёта разделения их на группы.
Число степеней свободы:

 — Межгрупповая сумма квадратов (Sum of sqares between groups)
— Межгрупповая сумма квадратов (Sum of sqares between groups)
 — Внутригрупповая сумма квадратов (Sum of sqares within groups)
— Внутригрупповая сумма квадратов (Sum of sqares within groups)





F-значение (основной статистический показатель дисперсионного анализа):

При делении значения межгрупповой суммы квадратов на число степеней свободы, полученный показатель усредняется.


Поэтому формула F-значения часто записывается:

Множественные сравнения в ANOVA
Проблема множественных сравнений:
Поправка Бонферрони
Самый простой (и консервативный) метод: P-значения умножаются на число выполненных сравнений.
Критерий Тьюки
Критерий Тьюки используется для проверки нулевой гипотезы  против альтернативной гипотезы
против альтернативной гипотезы  , где индексы
, где индексы  и
и  обозначают любые две сравниваемые группы.
обозначают любые две сравниваемые группы.
Указанные сравнения выполняются при помощи критерия Тьюки, который представляет собой модифицированный критерий Стьюдента:


где  — рассчитываемая в ходе дисперсионного анализа внутригрупповая дисперсия.
— рассчитываемая в ходе дисперсионного анализа внутригрупповая дисперсия.
Многофакторный ANOVA
При применении двухфакторного дисперсионного анализа исследователь проверяет влияние двух независимых переменных (факторов) на зависимую переменную. Может быть изучен также эффект взаимодействия двух переменных.
Исследуемые группы называют эффектами обработки. Схема двухфакторного дисперсионного анализа имеет несколько нулевых гипотез: одна для каждой независимой переменной и одна для взаимодействия.
Условия применения двухмерного дисперсионного анализа:
Генеральные совокупности, из которых извлечены выборки, должны быть нормально распределены.
Выборки должны быть независимыми.
Дисперсии генеральных совокупностей, из которых извлекались выборки, должны быть равными.
Группы должны иметь одинаковый объем выборки.
АБ тесты и статистика
3. Корреляция и регрессия
Понятие корреляции
Коэффициент корреляции – это статистическая мера, которая вычисляет силу связи между относительными движениями двух переменных.
Принимает значения [-1, 1]

 — показатель силы и направления взаимосвязи двух количественных переменных.
— показатель силы и направления взаимосвязи двух количественных переменных.
Знак коэффициента корреляции показывает направление взаимосвязи.
Коэффициент детерминации
 — показывает, в какой степени дисперсия одной переменной обусловлена влиянием другой переменной.
— показывает, в какой степени дисперсия одной переменной обусловлена влиянием другой переменной.
Равен квадрату коэффициента корреляции.
Принимает значения [0, 1]
Условия применения коэффициента корреляции
Для применения коэффициента корреляции Пирсона, необходимо соблюдать следующие условия:
Сравниваемые переменные должны быть получены в интервальной шкале или шкале отношений.
Распределения переменных  и
и  должны быть близки к нормальному.
должны быть близки к нормальному.
Число варьирующих признаков в сравниваемых переменных  и
и  должно быть одинаковым.
должно быть одинаковым.
Коэффициент корреляции Спирмена

Регрессия с одной независимой переменной
Уравнение прямой:

 — (intersept) отвечает за то, где прямая пересекает ось y.
— (intersept) отвечает за то, где прямая пересекает ось y.
 — (slope) отвечает за направление и угол наклона, образованный с осью x.
— (slope) отвечает за направление и угол наклона, образованный с осью x.
Метод наименьших квадратов
Формула нахождения остатка:

 — остаток
— остаток
 — реальное значение
— реальное значение
 — значение, которое предсказывает регрессионная прямая
— значение, которое предсказывает регрессионная прямая
Сумма квадратов всех остатков:

Параметры линейной регрессии:


Гипотеза о значимости взаимосвязи и коэффициент детерминации
Коэффициенты линейной регрессии
Коэффициенты регрессии (β) — это коэффициенты, которые рассчитываются в результате выполнения регрессионного анализа. Вычисляются величины для каждой независимой переменной, которые представляют силу и тип взаимосвязи независимой переменной по отношению к зависимой.
Коэффициент детерминации
 — доля дисперсии зависимой переменной (Y), объясняем регрессионной моделью.
— доля дисперсии зависимой переменной (Y), объясняем регрессионной моделью.

 — сумма квадратов остатков
— сумма квадратов остатков
 — сумма квадратов общая
— сумма квадратов общая
Условия применения линейной регрессии с одним предиктором
Линейная взаимосвязь  и
и 
Нормальное распределение остатков
Регрессионный анализ с несколькими независимыми переменными
Множественная регрессия (Multiple Regression)
Множественная регрессия позволяет исследовать влияние сразу нескольких независимых переменных на одну зависимую.
Требования к данным
линейная зависимость переменных
нормальное распределение остатков
проверка на мультиколлинеарность
нормальное распределение переменных (желательно)



