Функциональное программирование с точки зрения EcmaScript. Рекурсия и её виды
Сегодня мы продолжим наши изыскания на тему функционального программирования в разрезе EcmaScript, на спецификации которого основан JavaScript. В предыдущих статьях цикла были рассмотрены следующие темы:
Рекурсия
Реку́рсия — определение, описание, изображение какого-либо объекта или процесса внутри самого этого объекта или процесса, то есть ситуация, когда объект является частью самого себя. Термин «рекурсия» используется в различных специальных областях знаний — от лингвистики до логики, но наиболее применение находит в математике и информатике.
Применительно к программированию под рекурсией подразумевают процессы, которые вызывают сами себя в своём теле. Рекурсивная функция имеет несколько обязательных составляющих:
Выделим характерные составляющие рекурсивной функции. Терминальное условие
и правило движения по рекурсии
Важно осознавать, что рекурсия это не какая-то специфическая фича JS, а техника очень распространённая в программировании.
Рекурсивный и итеративный процессы
Рекурсию можно организовать двумя способами: через рекурсивный процесс или через итеративный.
Рекурсивный процесс мы с вами уже видели:
Итеративное решение задачи о факториале выглядело бы так:
Оба этих варианта это рекурсия. В обоих решениях есть характерные для рекурсии черты: терминальное условие и правило движения по рекурсии. Давайте разберём их отличия.
Рекурсивный процесс на каждом шаге запоминает действие. которое надо сделать. Дойдя до термального условия, он выполняет все запомненные действия в обратном порядке. Поясним на примере. Когда рекурсивный процесс считает факториал 6, то ему нужно запомнить 5 чисел чтобы посчитать их в самом конце, когда уже никуда не деться и рекурсивно двигаться вглубь больше нельзя. Когда мы находимся в очередном вызове функции, то где-то снаружи этого вызова в памяти хранятся эти запомненные числа.
Выглядит это примерно так:
Как видите, основная идея рекурсивного процесса — откладывание вычисления до конца.
Такой процесс порождает изменяемое во времени состояние, которое хранится «где-то» снаружи текущего вызова функции.
Думаю, вы помните, что в первой статье из цикла о Функциональном программировании мы говорили о важности имутабельности и отсутствия состояния. Наличие состояния порождает много проблем, с которыми не всегда легко справится.
Итеративный процесс отличается от рекурсивного фиксированным количеством состояний. На каждом своём шаге итеративный процесс считает всё, что может посчитать, поэтому каждый шаг рекурсии существует независимо от предыдущего.
Думаю, очевидно, что итеративный процесс потребляет меньше памяти. Следовательно, всегда при создании рекурсии следует использовать его. Единственное исключение: если мы не можем посчитать значение до достижения термального условия.
Древовидная рекурсия
Многие считают, что деревья и работа с ними это что-то очень заумное, сложное и не понятное простым смертным. На самом деле это не так. Любая иерархическая структура может быть представлена в виде дерева. Даже человеческое мышление подобно дереву.
Чтобы лучше понять древовидную рекурсию разберём простой и популярный пример — числа Фибоначчи.
Чи́сла Фибона́ччи — элементы числовой последовательности 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, … (последовательность A000045 в OEIS), в которой первые два числа равны либо 1 и 1, либо 0 и 1, а каждое последующее число равно сумме двух предыдущих чисел. Названы в честь средневекового математика Леонардо Пизанского (известного как Фибоначчи).
Математически довольно просто сформулировать описание (а ведь декларативное программирование и есть описание) данной последовательности:
Теперь давайте перейдём от математики к логическим рассуждениям(нам ведь нужно программную логику написать). Для вычисления fib(5) нам придётся вычислить fib(4) и fib(3). Для вычисления fib(4) нам придётся вычислить fib(3) и fib(2). Для вычисления fib(3) нам придётся вычислить fib(2) и так до тех пор пока мы не дойдём до известных значений (1) и (2) в нашей математической модели.
На какие мысли нас должны навести наши рассуждения? Очевидно, мы должны использовать рекурсию. Термальное условие можно сформулировать как n
Рекурсия в программировании. Анализ алгоритмов
Рекурсия — это свойство объекта подражать самому себе. Объект является рекурсивным если его части выглядят также как весь объект. Рекурсия очень широко применяется в математике и программировании:
Статья посвящена анализу трудоемкости рекурсивных алгоритмов, приведены необходимые математические сведения, рассмотрены примеры. Кроме того, описана возможность замены рекурсии циклом, хвостовая рекурсия.
Содержание:
Примеры рекурсивных алгоритмов
Рекурсивный алгоритм всегда разбивает задачу на части, которые по своей структуре являются такими же как исходная задача, но более простыми. Для решения подзадач функция вызывается рекурсивно, а их результаты каким-либо образом объединяются. Разделение задачи происходит лишь тогда, когда ее не удается решить сразу (она является слишком сложной).
Например, задачу обработки массива нередко можно свести к обработке его частей. Деление на части выполняется до тех пор, пока они не станут элементарными, т.е. достаточно простыми чтобы получить результат без дальнейшего упрощения.
Поиск элемента массива
Алгоритм делит исходный массив на две части — первый элемент и массив из остальных элементов. Выделяется два простых случая, когда разделение не требуется — обработаны все элементы или первый элемент является искомым.
В алгоритме поиска разделять массив можно было бы и иначе (например пополам), но это не сказалось бы на эффективности. Если массив отсортирован — то его деление пополам целесообразно, т.к. на каждом шаге количество обрабатываемых данных можно сократить на половину.
Двоичный поиск в массиве
Двоичный поиск выполняется над отсортированным массивом. На каждом шаге искомый элемент сравнивается со значением, находящимся посередине массива. В зависимости от результатов сравнения либо левая, либо правая части могут быть «отброшены».
Вычисление чисел Фибоначчи
Числа Фибоначчи определяются рекуррентным выражением, т.е. таким, что вычисление элемента которого выражается из предыдущих элементов: \(F_0 = 0, F_1 = 1, F_n = F_
Быстрая сортировка (quick sort)
Алгоритм быстрой сортировки на каждом шаге выбирает один из элементов (опорный) и относительно него разделяет массив на две части, которые обрабатываются рекурсивно. В одну часть помещаются элементы меньше опорного, а в другую — остальные.
 Блок-схема алгоритма быстрой сортировки
Блок-схема алгоритма быстрой сортировки
Сортировка слиянием (merge sort)
В основе алгоритма сортировки слиянием лежит возможность быстрого объединения упорядоченных массивов (или списков) так, чтобы результат оказался упорядоченным. Алгоритм разделяет исходный массив на две части произвольным образом (обычно пополам), рекурсивно сортирует их и объединяет результат. Разделение происходит до тех пор, пока размер массива больше единицы, т.к. пустой массив и массив из одного элемента всегда отсортированы.
 Блок схема сортировки слиянием
Блок схема сортировки слиянием
На каждом шаге слияния из обоих списков выбирается первый необработанный элемент. Элементы сравниваются, наименьший из них добавляется к результату и помечается как обработанный. Слияние происходит до тех пор, пока один из списков не окажется пуст.
Анализ рекурсивных алгоритмов
При анализе сложности циклических алгоритмов рассчитывается трудоемкость итераций и их количество в наихудшем, наилучшем и среднем случаях [4]. Однако не получится применить такой подход к рекурсивной функции, т.к. в результате будет получено рекуррентное соотношение. Например, для функции поиска элемента в массиве:
Рекуррентные отношения не позволяют нам оценить сложность — мы не можем их просто так сравнивать, а значит, и сравнивать эффективность соответствующих алгоритмов. Необходимо получить формулу, которая опишет рекуррентное отношение — универсальным способом сделать это является подбор формулы при помощи метода подстановки, а затем доказательство соответствия формулы отношению методом математической индукции.
Метод подстановки (итераций)
Заключается в последовательной замене рекуррентной части в выражении для получения новых выражений. Замена производится до тех пор, пока не получится уловить общий принцип и выразить его в виде нерекуррентной формулы. Например для поиска элемента в массиве:
Можно предположить, что \(T^
Мы вывели формулу, однако первый шаг содержит предположение, т.е. не имеется доказательства соответствия формулы рекуррентному выражению — получить доказательство позволяет метод математической индукции.
Метод математической индукции
Позволяет доказать истинность некоторого утверждения (\(P_n\)), состоит из двух шагов:
Докажем корректность предположения, сделанного при оценки трудоемкости функции поиска (\(T^
Часто, такое доказательство — достаточно трудоемкий процесс, но еще сложнее выявить закономерность используя метод подстановки. В связи с этим применяется, так называемый, общий метод [5].
Общий (основной) метод решения рекуррентных соотношений
Общий метод не является универсальным, например с его помощью невозможно провести оценку сложности приведенного выше алгоритма вычисления чисел Фибоначчи. Однако, он применим для всех случаев использования подхода «разделяй и властвуй» [3]:
\(T_n = a\cdot T(\frac
Уравнения такого вида получаются если исходная задача разделяется на a подзадач, каждая из которых обрабатывает \(\frac
Для проведения анализа может использоваться метод подстановки или следующие рассуждения: каждый рекурсивный вызов уменьшает размерность входных данных на единицу, значит всего их будет n штук, каждый из которых имеет сложность \( \mathcal
Анализ алгоритма сортировки слиянием
Исходные данные разделяются на две части, обе из которых обрабатываются: \(a = 2, b = 2, n^ <\log_b a>= n\).
При обработке списка, разделение может потребовать выполнения \(\Theta(n)\) операций, а для массива — выполняется за постоянное время (\(\Theta(1)\)). Однако, на соединение результатов в любом случае будет затрачено \(\Theta(n)\), поэтому \(f_n = n\).
Используется второй случай теоремы: \(T^
Анализ трудоемкости быстрой сортировки
В лучшем случае исходный массив разделяется на две части, каждая из которых содержит половину исходных данных. Разделение потребует выполнения n операций. Трудоемкость компоновки результата зависит от используемых структур данных — для массива \(\mathcal
Однако, в худшем случае в качестве опорного будет постоянно выбираться минимальный или максимальный элемент массива. Тогда \(b = 1\), а значит, мы опять не можем использовать основную теорему. Однако, мы знаем, что в этом случае будет выполнено n рекурсивных вызовов, каждый из которых выполняет разделение массива на части (\(\mathcal
При анализе быстрой сортировки методом подстановки, пришлось бы также рассматривать отдельно наилучший и наихудший случаи.
Хвостовая рекурсия и цикл
Анализ трудоемкости рекурсивных функций значительно сложнее аналогичной оценки циклов, но основной причиной, по которой циклы предпочтительнее являются высокие затраты на вызов функции.
После вызова управление передается другой функции. Для передачи управления достаточно изменить значение регистра программного счетчика, в котором процессор хранит номер текущей выполняемой команды — аналогичным образом передается управление ветвям алгоритма, например, при использовании условного оператора. Однако, вызов — это не только передача управления, ведь после того, как вызванная функция завершит вычисления, она должна вернуть управление в точку, и которой осуществлялся вызов, а также восстановить значения локальных переменных, которые существовали там до вызова.
Для реализации такого поведения используется стек (стек вызовов, call stack) — в него помещаются номер команды для возврата и информация о локальных переменных. Стек не является бесконечным, поэтому рекурсивные алгоритмы могут приводить к его переполнению, в любом случае на работу с ним может уходить значительная часть времени.
В ряде случаев рекурсивную функцию достаточно легко заменить циклом, например, рассмотренные выше алгоритмы поиска и бинарного поиска [4]. В некоторых случаях требуется более творческий подход, но чаще всего такая замена оказывается возможной. Кроме того, существует особый вид рекурсии, когда рекурсивный вызов является последней операцией, выполняемой функцией. Очевидно, что в таком случае вызывающая функция не будет каким-либо образом изменять результат, а значит ей нет смысла возвращать управление. Такая рекурсия называется хвостовой — компиляторы автоматически заменяют ее циклом.
Зачастую сделать рекурсию хвостовой помогает метод накапливающего параметра [7], который заключается в добавлении функции дополнительного аргумента-аккумулятора, в котором накапливается результат. Функция выполняет вычисления с аккумулятором до рекурсивного вызова. Хорошим примером использования такой техники служит функция вычисления факториала:
\(fact_n = n \cdot fact(n-1) \\
fact_3 = 3 \cdot fact_2 = 3 \cdot (2 \cdot fact_1) = 3\cdot (2 \cdot (1 \cdot fact_0)) = 6 \\
fact_n = factTail_
\\
factTail_
factTail_ <3, 1>= factTail_ <2, 3>= factTail_ <1, 6>= factTail_ <0, 6>= 6
\)
В качестве более сложного примера рассмотрим функцию вычисления чисел Фибоначчи. Основная функция вызывает вспомогательную,использующую метод накапливающего параметра, при этом передает в качестве аргументов начальное значение итератора и два аккумулятора (два предыдущих числа Фибоначчи).
Функция с накапливающим параметром возвращает накопленный результат, если рассчитано заданное количество чисел, в противном случае — увеличивает счетчик, рассчитывает новое число Фибоначчи и производит рекурсивный вызов. Оптимизирующие компиляторы могут обнаружить, что результат вызова функции без изменений передается на выход функции и заменить его циклом. Такой прием особенно актуален в функциональных и логических языках программирования, т.к. в них программист не может явно использовать циклические конструкции.
Рекурсивное программирование

Feb 22, 2019 · 8 min read
При первом знакомстве с концепцией рекурсии, она может показаться странной и отталкивающей. Это кажется почти парадоксальным: как мы можем найти решение проблемы, используя решение той же проблемы? Несмотря на это, в большинстве проектов, рекурсию используют в программировании уже на ранних стадиях производства.
Я думаю, что тем, кто пытается постигнуть концепцию рекурс и и, следует сначала понять, что рекурсия — это больше, чем просто практика в программировании. Это философия решения проблем, которые можно решать частями, не трогая основную часть проблемы, при этом, проблема упрощается или становится меньше. Рекурсия применима не только в программировании, но и в простых повседневных задачах. Например, возьмите меня, пишущего эту статью: допустим, я хочу написать около 1000 слов, и ставлю цель писать 100 слов каждый раз, когда сажусь за работу. Получается, что в первый раз я напишу 100 слов и оставляю 900 слов на потом. В следующий раз я напишу ещё 100 слов, а оставлю 800. Я буду продолжать, пока не останется 0 слов. Каждый раз, я частично решаю проблему, а оставшаяся часть проблемы уменьшается.
Работу над статьей можно представить в виде такого кода:
Также, этот алгоритм можно реализовать итеративно:
Если рассматривать вызов функции write_words(1000) в любой из этих реализаций, вы обнаружите, одинаковое поведение. На самом деле, каждую задачу, которую можно решить с помощью рекурсии, мы также можем решить с помощью итерации (циклы for и while ). Так почему же стоит использовать именно рекурсию?

Почему рекурсия?
Хотите верьте, хотите нет, но с помощью рекурсии некоторые проблемы решить легче, чем с помощью итерации. Иногда рекурсия более эффективна, иногда более читаема, а иногда просто быстрее реализуется. Некоторые структуры данных, такие как деревья ― хорошо подходят для рекурсивных алгоритмов. Существуют языки программирования, в которых вообще нет понятия цикла — это чисто функциональные языки, такие как Haskell, они полностью зависят от рекурсии для итеративного решения задач. Я хочу сказать, что программисту не обязательно понимать рекурсию, но хороший программист, просто обязан в этом разбираться. Более того, понимание рекурсии сделает вас отличным «решателем» проблем, не только в программировании!
Суть рекурсии
В общем, рекурсивный подход подразумевает разделение сложной задачи, на один простой шаг к её решению и оставшуюся часть, которая становится упрощённой версией той же задачи. Затем этот процесс повторяется. Каждый раз вы совершаете один шаг, до тех пор, пока задача упростится до одного простейшего решения (его называют «базовым случаем»). Простейшее решение нашего базового случая с шагами, которые мы предприняли, чтобы добраться до него, образуют решение нашей первоначальной задачи.

Предположим, у нас есть фактические данные определённого типа, назовём их dₒ. Идея рекурсии состоит в том, чтобы предположить, что мы уже решили задачу или вычислили желаемую функцию f для всех форм этого типа данных. Каждая из этих форм проще общей сложности dₒ, которую нам нужно определить. Следовательно, если мы можем найти способ выражения f(dₒ), исходя из одной или нескольких частей f(d), где все эти d проще, чем dₒ, значит мы нашли решение для f(dₒ). Мы повторяем этот процесс, и рассчитываем, что в какой-то момент оставшиеся f(d) станут настолько простыми, что мы сможем легко реализовать фиксированное, окончательное решение для них. В итоге, решением исходной задачи станет поэтапное решение более простых задач.
В приведённом выше примере (про написание статьи), данными является текст, содержащийся в документе, который я должен написать, а степень сложности — это длина документа. Это немного надуманный пример, но если предположить, что я уже решил задачу f(900) (написать 900 слов), то все, что мне нужно сделать, чтобы решить f(1000), ― это написать 100 слов и выполнить решение для 900 слов, f(900).
Давайте рассмотрим пример получше: с числами Фибоначчи, где 1-е число равно 0, второе равно 1, а nᵗʰ число равно сумме двух предыдущих. Предположим, у нас есть функция Фибоначчи, которая сообщает нам nᵗʰ число:
Как будет выглядеть выполнение такой функции? Возьмём для примера fib(4) :


Рекурсивная стратегия
Рекурсивный подход — дело тонкое, и зависит от того, какую проблему вы пытаетесь решить. Тем не менее, есть некоторая общая стратегия, которая поможет вам двигаться в правильном направлении. Эта стратегия состоит из трёх шагов:
Упорядочивание данных
Этот шаг является ключевым для решения проблем рекурсивным способом, и все же его часто упускают из виду или выполняют неявно. Какие бы данные мы ни использовали, будь то числа, строки, списки, бинарные древа или люди, необходимо явно найти целесообразный порядок, который даст нам видение, как упростить задачу. Порядок полностью зависит от конкретной задачи, но для начала стоит подумать об очевидных вариантах. Например: числа можно упорядочить по величине, строки и списки можно упорядочить по длине, бинарные древа по глубине, а люди могут быть упорядочены бесконечным количеством разумных способов: рост, вес или должность в организации. Это упорядочивание должно соответствовать степени сложности задачи, которую мы пытаемся решить.

После того, как мы упорядочили данные, нам нужно подумать об этом, как о чём-то, что мы можем сократить. На самом деле, мы можем записать наш порядок в виде последовательности:
0, 1, 2, …, n для чисел (т.е. для int данных d, степень(d) = d)
Двигаясь справа налево, мы идём от общего («большая часть задачи») случая, к базовым («маленьким частям») случаям. В нашем примере с функцией reverse мы работаем со строкой, и можем взять длину строки за основу, для упорядочивания или определения степени сложности задачи.
Решаем малую часть проблемы
Переходим к общим случаям

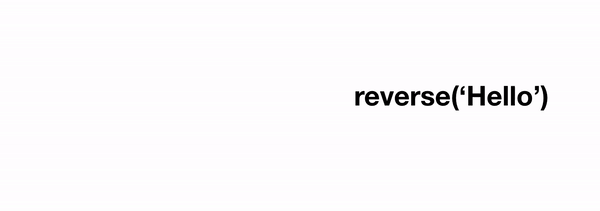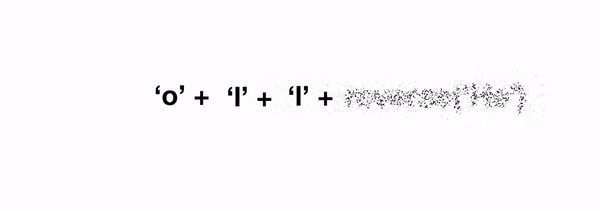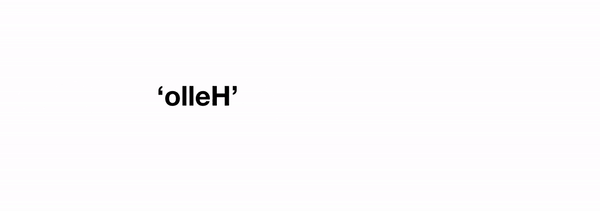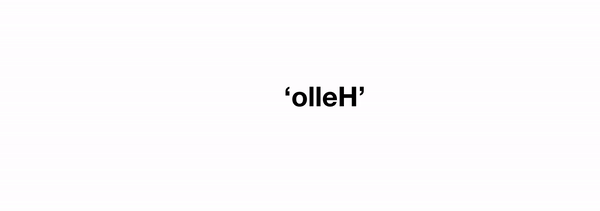
Часто бывает так, что нам нужно рассмотреть несколько рекурсивных случаев, так как данные определённого типа, могут принимать разные формы, но это полностью зависит от задачи. Например, если мы хотим сгладить список элементов, некоторые из которых сами могут быть списками, нам нужно будет различать случаи, когда элемент, который мы вытаскиваем из списка, является отдельным элементом или подсписком, что приводит по крайней мере к двум рекурсивным случаям.
Напутствие
Единственный способ улучшить свои навыки в рекурсии — это практика. В интернете можно найти тысяч примеров задач, подходящих для рекурсивного решения — испытайте себя. Однажды, вы неизбежно научитесь рекурсии, но, если у вас возникнут трудности с рекурсивным решением проблемы, попробуйте вместо этого итерацию. Рекурсия поможет вам решать проблемы не только в программировании, но и в повседневной жизни. Если проблема не подходит для рекурсии, что ж, такое бывает; со временем вы научитесь чувствовать, где следует использовать рекурсивный подход, а где итеративный.
Иногда в более сложных рекурсивных задачах, шаги 2 и 3, о которых мы говорили, принимают форму более циклического процесса. Если вы не можете быстро найти общее решение проблемы, попробуйте решить рекурсивные (большие) случаи и базовые (маленькие) случаи, которые сможете найти, а затем посмотрите, как в результате разделились разные части данных. Это должно выявить любые недостающие базовые и рекурсивные случаи или те, которые плохо взаимодействуют друг с другом и нуждаются в переосмыслении.
Наконец, помните, что выявление порядка является самым важным шагом к решению рекурсивной задачи, и ваша цель рассмотреть как правый (рекурсивный), так и левый (базовый) случаи этого порядка, чтобы решить задачу для всех данных определённого типа.
Рекурсия. Занимательные задачки
В этой статье речь пойдет о задачах на рекурсию и о том как их решать. 
Кратко о рекурсии
Рекурсия достаточно распространённое явление, которое встречается не только в областях науки, но и в повседневной жизни. Например, эффект Дросте, треугольник Серпинского и т. д. Один из вариантов увидеть рекурсию – это навести Web-камеру на экран монитора компьютера, естественно, предварительно её включив. Таким образом, камера будет записывать изображение экрана компьютера, и выводить его же на этот экран, получится что-то вроде замкнутого цикла. В итоге мы будем наблюдать нечто похожее на тоннель.
В программировании рекурсия тесно связана с функциями, точнее именно благодаря функциям в программировании существует такое понятие как рекурсия или рекурсивная функция. Простыми словами, рекурсия – определение части функции (метода) через саму себя, то есть это функция, которая вызывает саму себя, непосредственно (в своём теле) или косвенно (через другую функцию).
Задачи
При изучении рекурсии наиболее эффективным для понимания рекурсии является решение задач.
Любой алгоритм, реализованный в рекурсивной форме, может быть переписан в итерационном виде и наоборот. Останется вопрос, надо ли это, и насколько это будет это эффективно.
Для обоснования можно привести такие доводы.
Для начала можно вспомнить определение рекурсии и итерации. Рекурсия — это такой способ организации обработки данных, при котором программа вызывает сама себя непосредственно, либо с помощью других программ. Итерация — это способ организации обработки данных, при котором определенные действия повторяются многократно, не приводя при этом к рекурсивным вызовам программ.
После чего можно сделать вывод, что они взаимно заменимы, но не всегда с одинаковыми затратами по ресурсам и скорости. Для обоснования можно привести такой пример: имеется функция, в которой для организации некого алгоритма имеется цикл, выполняющий последовательность действий в зависимости от текущего значения счетчика (может от него и не зависеть). Раз имеется цикл, значит, в теле повторяется последовательность действий — итерации цикла. Можно вынести операции в отдельную подпрограмму и передавать ей значение счетчика, если таковое есть. По завершению выполнения подпрограммы мы проверяем условия выполнения цикла, и если оно верно, переходим к новому вызову подпрограммы, если ложно — завершаем выполнение. Т.к. все содержание цикла мы поместили в подпрограмму, значит, условие на выполнение цикла помещено также в подпрограмму, и получить его можно через возвращающее значение функции, параметры передающееся по ссылке или указателю в подпрограмму, а также глобальные переменные. Далее легко показать, что вызов данной подпрограммы из цикла легко переделать на вызов, или не вызов (возврата значения или просто завершения работы) подпрограммы из нее самой, руководствуясь какими-либо условиями (теми, что раньше были в условии цикла). Теперь, если посмотреть на нашу абстрактную программу, она примерно выглядит как передача значений подпрограмме и их использование, которые изменит подпрограмма по завершению, т.е. мы заменили итеративный цикл на рекурсивный вызов подпрограммы для решения данного алгоритма.
Задача по приведению рекурсии к итеративному подходу симметрична.
Подводя итог, можно выразить такие мысли: для каждого подхода существует свой класс задач, который определяется по конкретным требованиям к конкретной задаче.
Более подробно с этим можно познакомиться тут
Так же как и у перебора (цикла) у рекурсии должно быть условие остановки — Базовый случай (иначе также как и цикл рекурсия будет работать вечно — infinite). Это условие и является тем случаем к которому рекурсия идет (шаг рекурсии). При каждом шаге вызывается рекурсивная функция до тех пор пока при следующем вызове не сработает базовое условие и произойдет остановка рекурсии(а точнее возврат к последнему вызову функции). Всё решение сводится к решению базового случая. В случае, когда рекурсивная функция вызывается для решения сложной задачи (не базового случая) выполняется некоторое количество рекурсивных вызовов или шагов, с целью сведения задачи к более простой. И так до тех пор пока не получим базовое решение.
Тут Базовым условием является условие когда n=1. Так как мы знаем что 1!=1 и для вычисления 1! нам ни чего не нужно. Чтобы вычислить 2! мы можем использовать 1!, т.е. 2!=1!*2. Чтобы вычислить 3! нам нужно 2!*3… Чтобы вычислить n! нам нужно (n-1)!*n. Это и является шагом рекурсии. Иными словами, чтобы получить значение факториала от числа n, достаточно умножить на n значение факториала от предыдущего числа.
В сети при обьяснении рекурсии также даются задачи нахождения чисел Фибоначчи и Ханойская башня
Рассмотрим же теперь задачи с различным уровнем сложности.
Попробуйте их решить самостоятельно используя метод описанный выше. При решении попробуйте думать рекурсивно. Какой базовый случай в задаче? Какой Шаг рекурсии или рекурсивное условие?
Поехали! Решения задач предоставлены на языке Java.
A: От 1 до n
Дано натуральное число n. Выведите все числа от 1 до n.



