Репрезентативная выборка

Репрезентативная выборка — это группа людей, товаров, объектов, которая имеет все необходимые характеристики, которые важны для исследований.
Она представляет собой часть генеральной совокупности, при этом важные параметры выборки не должны отличаться от характеристик генеральной совокупности.
Рассмотрим на примере торта, он представляет собой генеральную совокупность, то есть весь комплекс, целое. Если мы отрежем кусок торта для исследований, то такая выборка является репрезентативной, потому что свойства этого куска точно такие же, как у всего остального торта и по нему можно определить, какими свойствами обладает все целое.
Если целевая аудитория — это генеральная совокупность, то часть людей, отдельная подгруппа будет представлять собой репрезентативную выборку. Чаще всего репрезентативная выборка формируется путем простого случайного отбора респондентов. Это позволяет получить объективные данные. Другими словами, репрезентативная выборка представляет собой уменьшенный вариант генеральной совокупности.
Случайный отбор происходит по-разному. К примеру, чтобы опросить жителей определенного населенного пункта может быть взята база телефонных номеров. Компьютер случайно выбирает с помощью генерирования чисел представителей, которым будет сделан звонок. Специалисты обзванивает, к примеру, каждого 10 человека.
Иногда сформировать репрезентативную выборку случайным методом удается с трудом, например, если компьютер непреднамеренно выберет номера телефонов молодёжи, то при этом будут не учтены характеристики людей более старшего возраста.
Или, если продолжать проводить аналогию с едой, как с тортом, то выбрать часть, полностью соответствующую характеристикам целого иногда сложно. Возьмем, к примеру, суп. Если оценивать характеристики всего содержимого кастрюли по случайно взятому половнику — можно зачерпнуть больше бульона или только овощи. Поэтому в некоторых случаях нужен другой подход: формирование нескольких репрезентативных выборок, валидная исследовательская методика.
Иначе будет нарушена репрезентативность выборки, а значит, получены недостоверные результаты исследования, потерян бюджет или нанесены финансовые убытки в результате использования неправильных данных.
Статьи о маркетинге, автоматизации и интеграциях в нашем Блоге
Настроить интеграцию без программистов ApiX-Drive
Репрезентативная выборка в контексте: определяем эффективность кампании на этапе тестирования
Как рассчитать выборку и получить значимые результаты
Перед запуском рекламной кампании принято проводить A/B-тестирование. Однако не всякий тест может считаться показательным. И первая ошибка – неверно определена репрезентативная выборка. Следствие такой ошибки – впустую потраченные деньги на запуск неэффективной рекламы.
Что такое репрезентативная выборка и как ее правильно посчитать, рассказываем ниже.
Что такое репрезентативная выборка
С понятиями «генеральная совокупность» и «репрезентативная выборка» сталкиваются все, кто запускают A/B-тесты и хотят получить статистически значимые результаты. Ведь чаще всего провальные тесты случаются по двум причинам: маленькая выборка и недостаточный объем данных.
Для расчета репрезентативной выборки сейчас совсем не нужно знать сложные формулы и рассчитывать их вручную. Для этого есть удобные онлайн-калькуляторы (Optimizely, Mindbox, VWO) и методика SurveyMonkey.
Для работы со всеми перечисленными инструментами надо знать правила проведения тестов, оперировать основными понятиями и понимать, как работают инструменты расчета репрезентативной выборки.
Вот основные понятия, которые нужно знать для расчета выборки:
Каждый их перечисленных онлайн-калькуляторов имеет свою специфику. Об этом мы расскажем ниже.
Выборка в тестах: зачем считать и что еще влияет на результаты
Перед запуском рекламной кампании принято запускать тестирование. Это позволяет определить наиболее эффективный вариант объявления. В объявлении может тестироваться любой элемент: заголовки, креативы, описания, расширения, CTA-кнопки и т. д.
Тестирование разных вариантов объявлений может проводиться для повышения кликабельности объявления, увеличения коэффициента конверсии. Однако, по данным AppSumo, значимые результаты дают только 1 из 8 тестов.
Правильное определение репрезентативной выборки для тестовых групп обеспечивает достоверные результаты по тестам. Ниже рассмотрим причины, по которым тест может не дать значимых результатов.
1. Недостаточно данных
Допустим, мы запустили тестирование двух вариантов объявлений с разными заголовками. Вечером получаем такие результаты:

По результатам первого дня может показаться, что текущее объявление работает более эффективно.
В этом случае у рекламодателя возникают такие вопросы:
Нельзя делать выводы об эффективности кампании по нескольким десяткам переходов и паре кликов. Для принятия решения необходимо собрать достаточное количество аналитических данных.
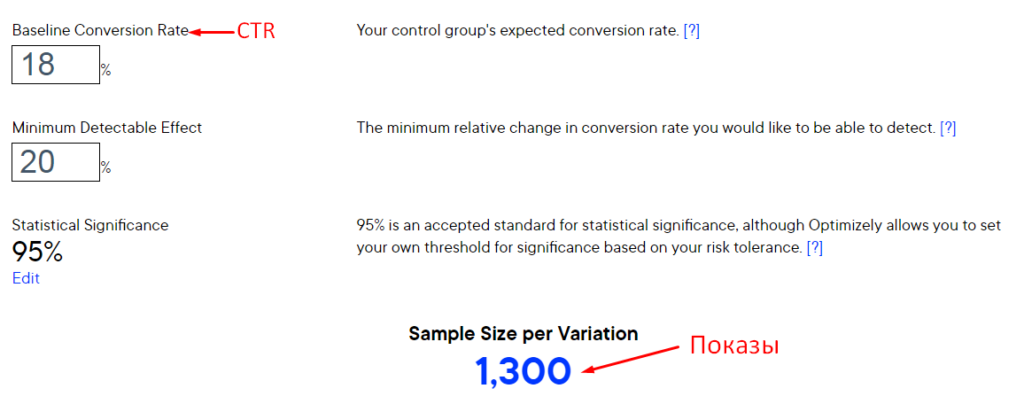
Для определения размера нашей выборки воспользуемся онлайн-калькулятором Optimizely.
Проводим такие действия:
Расчеты показывают, что для получения статистически значимых данных выборка для тестируемой группы должна состоять из 1300 человек.
2. Неправильно поставлена гипотеза
Это еще одна распространенная причина получения непоказательных результатов тестирования.
Например, в ходе теста была выдвинута гипотеза, что новое описание в объявлении принесет больше трафика на целевую страницу и мы получим более высокую конверсию. Но в результате тестирования трех вариантов описания не было обнаружено значительной разницы.
В таких ситуациях возникает вопрос о том, как сделать тест показательным и улучшить результаты. Один из способов — заинтересовать целевую аудиторию. Для этого может быть недостаточно просто изменить описание в объявлении или заголовок. Нужны более значимые изменения. Можно поменять креатив или изменить торговое предложение (увеличить скидку, изменить цену, предложить покупателям рассрочку).
3. Выбрана не та метрика
Для получения значимых результатов важно выбрать только один показатель, который надо улучшить. Например, цель – повысить коэффициент конверсии к покупке для новых посетителей. Именно с учетом этого показателя и рассчитывают выборку большинство онлайн-калькуляторов.
Однако если данных по конверсиям недостаточно, то нужно ориентироваться на другие метрики. Например, на рост CTR. В таких случаях расчет выборки можно провести с помощью онлайн-калькулятора Mindbox.
С помощью Mindbox можно определить размер выборки для 2–5 вариантов тестирования по таким показателям:
Размер выборки напрямую зависит от выбранного тестируемого показателя и количества тестируемых вариантов.
Например, посмотрим, какой размер выборки понадобится нам при тестировании показателя Open Rate. При таких условиях: средний Open Rate – 15%, ожидаемый прирост показателя – 30%.

Получается, размер выборки для каждого варианта объявления составляет 2 224 человека.
А вот скольким людям надо показать объявление при тестировании показателя конверсия в заказы при средней конверсии по истории 5%:

Размер выборки для каждой тестируемой группы составляет 29 827 человек.
Вывод: чем ближе к деньгам, тем более показательны результаты. Поэтому все A/B-тесты измерялись бы по Conversion Rate. Но проблема в том, что чем ниже по этой воронке продаж, тем больше людей потребуется для проведения теста. Для расширения охвата и получения достоверных данных в этом случае надо ориентироваться на повышение показателя Click Rate или Open Rate.
Как определить размер выборки
Метод SurveyMonkey
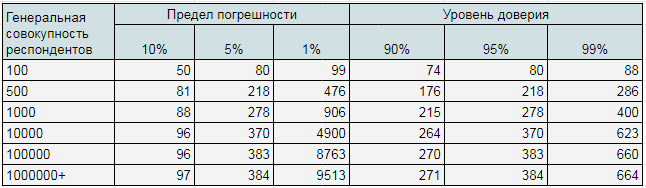
Компания SurveyMonkey предложила метод определения репрезентативной выборки с учетом предела погрешности и уровня доверия.
Сделать это можно с помощью такой таблицы:
Методика расчета репрезентативной выборки состоит из пяти этапов. Показываем, как это сделать на примере интернет-магазина электроинструментов.
Исходные данные: магазин находится в Курске и хочет запустить рекламу для привлечения новых клиентов на сайт.
Перед запуском кампания проводит A/B-тест и тестирует два объявления с разными вариантами заголовков. Выдвигается гипотеза, что второй вариант объявления понравится целевой аудитории больше и по нему будет больше кликов и конверсий.
1 этап – определяем генеральную совокупность. Интернет-магазин собрал достаточно данных о покупателях. И знает, что их целевая аудитория – это мужчины в возрасте от 25 до 70 лет, которые живут в Курске и интересуются ремонтом, строительством, обустройством дома.
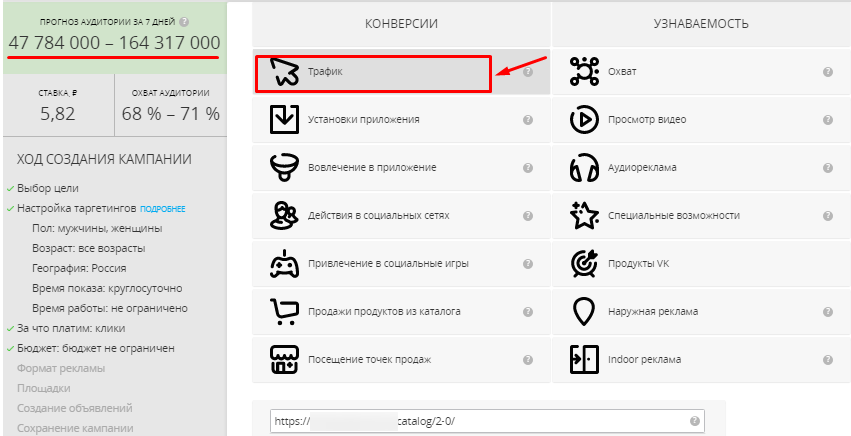
Для оценки приблизительного размера целевой аудитории воспользуемся myTarget. Эта платформа предоставляет гибкие настройки таргетинга и позволяет приблизительно определить рекламный охват, который мы и примем как генеральную совокупность.
В примере мы не будем запускать кампанию через myTarget, а просто используем его для определения размера ЦА. Подробнее о том, как запустить рекламу в системе, читайте в пошаговом гайде «Как настроить рекламу в myTarget».
Заходим в профиль myTarget. Выбираем цель – «Конверсии» – «Трафик», ниже указываем URL. Слева появится прогноз аудитории за 7 дней. По мере настройки таргетинга рекламный охват будет сокращаться.
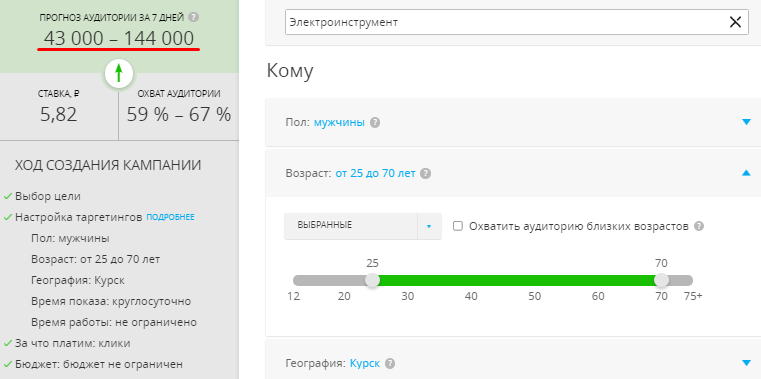
Сократим рекламный охват. Для этого указываем такие настройки:
Уже после этих настроек размер аудитории сократится до 43 000 – 144 000 человек:
Указываем интересы. Потенциальные покупатели интересуются автомобилями, ремонтными и строительными работами, благоустройством дома:
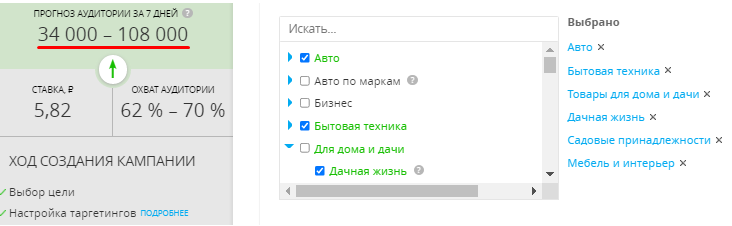
Таким образом размер нашей целевой аудитории находится в пределах 34 000 – 108 000 человек.
2. Определяем точность теста. Для получения статистически значимых результатов рекомендуется устанавливать предел погрешности в районе 1–5%, а уровень доверия – 95–99%.
Например, мы поставили гипотезу, что пользователи чаще будут кликать по второму объявлению. Уровень погрешности принимаем 1%, значит, уровень доверия составляет 99%. Это означает, что фактически 98–100% пользователям второй вариант объявления понравится больше, чем первый.
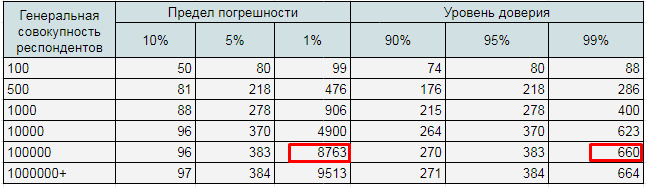
3. Определяем размер выборки с помощью таблицы. Приблизительно наша генеральная совокупность составляет 100 000 человек. Подходящая нам выборка составляет – от 383 до 8763 человек. Для получения максимально значимых данных устанавливаем уровень доверия на уровне 99%. Поэтому остановимся на 660.
4. Прикидываем ожидаемую конверсию по объявлению. Средний показатель по предыдущим кампаниям составлял 12%. Поэтому принимаем CR = 12%.
5. Узнаем, скольким людям надо показать наши объявления, чтобы получить статистически значимые результаты:
То есть выборка для одного тестовой группы составляет 5500 человек. Мы тестируем два варианта объявления. Поэтому и второе объявление (при распределении аудитории 50/50) должно увидеть 5500 пользователей.
Optimizely
Сравним, насколько размер выборки, полученный методом SurveyMonkey, будет отличаться от результатов онлайн-калькуляторов.
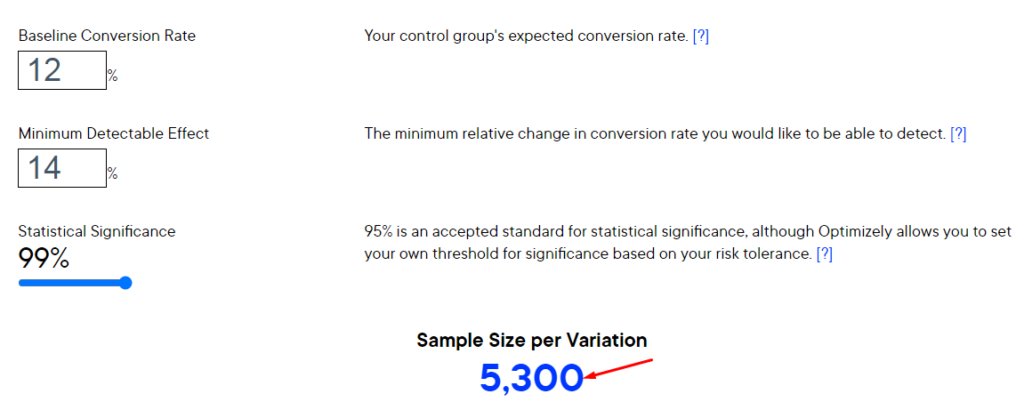
Заходим в онлайн-калькулятор и задаем там такие значения:
Вводим все эти значения и получаем, что контрольная группа должна состоять из 5300 человек.
В результате мы получили почти такие же числа, как и методом SurveyMonkey. Только во втором расчете контрольная группа должна состоять из 5300 человек, а не 5500 человек.
Mindbox
Посмотрим, какой размер тестируемой выборки для нашего примера получится с помощью калькулятора Mindbox.
Вносим свои показатели в калькулятор:
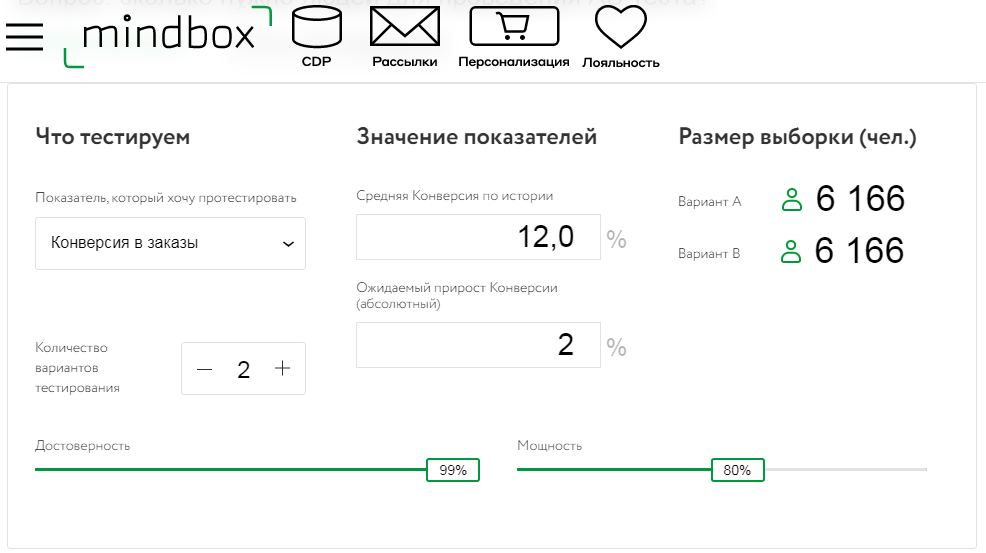
По результатам Mindbox размер выборки для каждой тестируемой группы должен составлять 6 166 человек. Это больше, чем мы получили по методу SurveyMonkey (5500 человек в контрольной группе) или с помощью калькулятора Optimezely (5300 человек). Однако цифры вполне сопоставимы.
По настройке Mindbox отличается от Optimezely следующими моментами:
Таким образом, на примере мы показали как тремя способами посчитать размер репрезентативной выборки для тестовых кампаний.
Основные сложности в тестах при расчете выборки
Недостаточное количество просмотров
Зачастую для получения статистически значимых результатов размер выборки должен составлять от 2000–3000 человек. И это большая проблема в том случае, если за неделю было всего несколько сотен переходов.
Один из вариантов сократить размер выборки – понизить уровень доверия в настройках онлайн-калькулятора до приемлемых величин (не ниже 80%). А если репрезентативная выборка определяется калькулятором Mindbox, то можно уменьшить еще и показатель мощности. В этом случае данные будут менее достоверными, но все еще не утратят своей статистической значимости.
Например, в Mindbox задаем уровень доверия 99% и мощность 98%. В результате размер выборки для одной тестируемой группы составляет 5 030 человек:

Понижаем уровень достоверности до 85%, а мощность до 80%. Остальные данные оставляем без изменений.
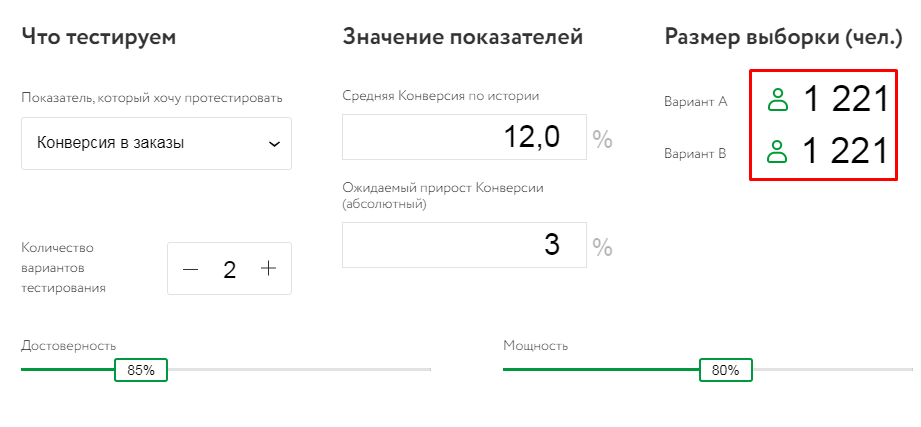
В результате требуемый размер выборки уменьшился почти в 5 раз. Это очень ощутимое сокращения с учетом низкого трафика по рекламе.
Узкая тематика
Основная проблема узкой тематики заключается в том, что всего несколькими десятками ключевых фраз можно описать все запросы, по которым пользователи ищут услугу. Отсюда и низкий трафик.
Решить проблему можно так:
Например, при средней конверсии по истории 3% размер выборки составит 18 273 человека:
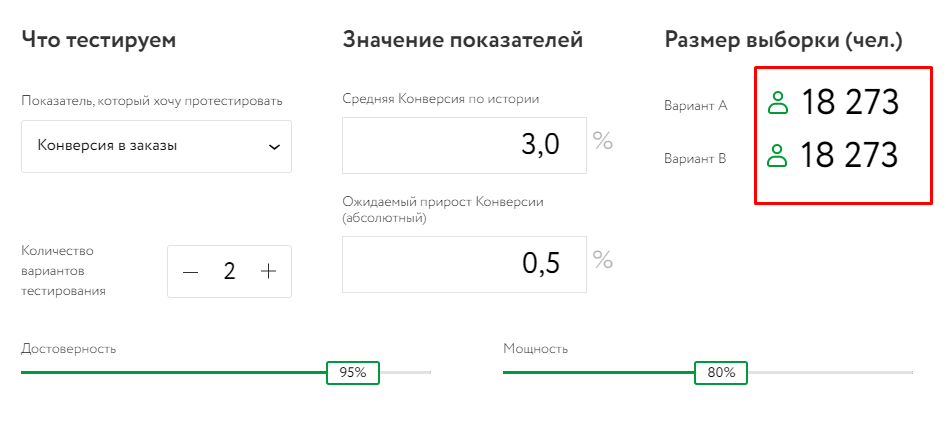
Оставляем тот же уровень достоверности и мощности. В показателях выбираем Click Rate. Устанавливаем средний по истории показатель и ожидаемый абсолютный прирост:
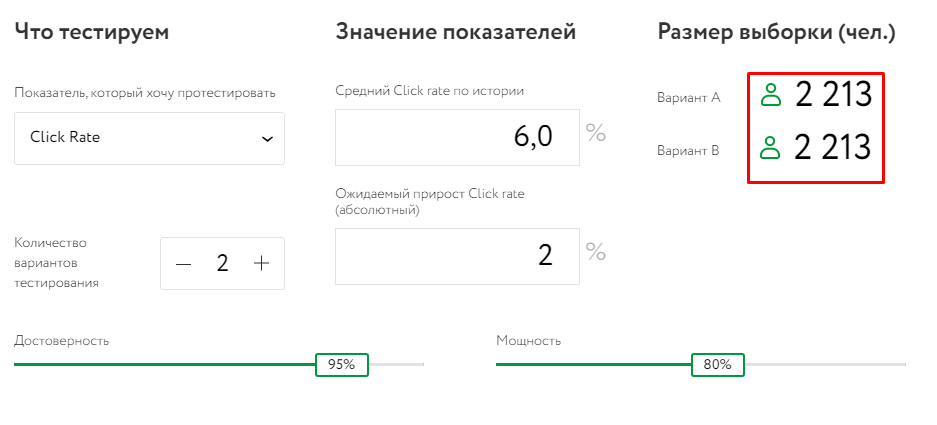
Получаем, что выборка для одной тестируемой группы составляет 2213 человек. Это все равно очень много для узкой тематики. Поэтому понижаем достоверность и мощность:
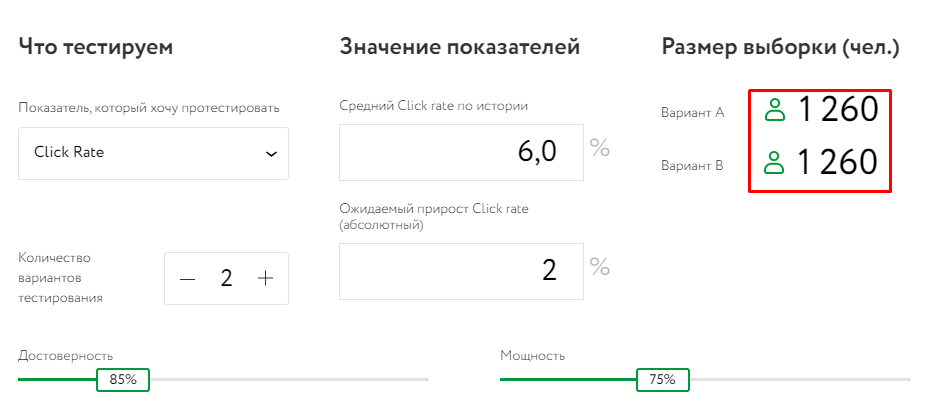
Таким образом, изменение тестируемой метрики и уменьшение показателей достоверности позволило нам сократить размер выборки с 18 273 до 1200 человек.
Рекламироваться в узкой тематике сложно, но есть способы, позволяющие увеличить трафик по объявлениям. Подробнее об этом читайте в нашей статье «Реклама в узкой тематике: 9 советов по повышению эффективности».
Низкий бюджет
В условиях ограниченного бюджета у рекламодателя нет возможности тестировать каждый заголовок, креатив или текст объявления.
Вот советы, которые помогут сэкономить бюджет:
1. Сравнивайте разные объявления. На поступательное тестирование сначала заголовков, потом текстов объявлений, креативов и других элементов потребуется время и немалые бюджеты. Поэтому в условиях ограниченных средств лучше кардинально менять заголовки, тесты, креативы и сравнивать радикально разные варианты объявлений;
2. Используйте системы автоматизации. Если стоит цель сэкономить, то можно создать тестовые объявления самостоятельно, а не платить деньги специалистам. Это позволит высвободить дополнительный ресурс на тестирование большей выборки. Быстро составить объявления можно с помощью систем автоматизации.
Например, для составления объявлений по ключевым словам можно воспользоваться инструментом медиапланирования Click.ru. Он собирает семантику исходя из контента вашего сайта, слов конкурентов или данных счетчиков статистики. А потом на основании отобранных слов составляет объявления:
Вам остается только отредактировать их и запустить тестовые кампании.
Еще один вариант – использовать генератор объявлений из YML. Этот инструмент подходит интернет-магазинам, которые используют выгрузку товаров/услуг в XML.
Высокий бюджет
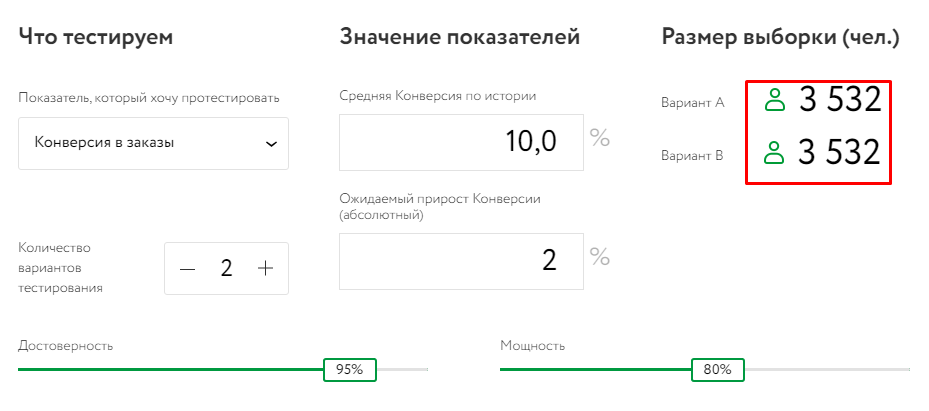
При высоком бюджете открываются дополнительные возможности: можно тестировать отдельно разные элементы объявления, запускать больше тестов, настраивать не две, а три и более тестовых групп – в этом случае размер выборки увеличивается.
Вот какой размер выборки может быть при двух тестовых группах:
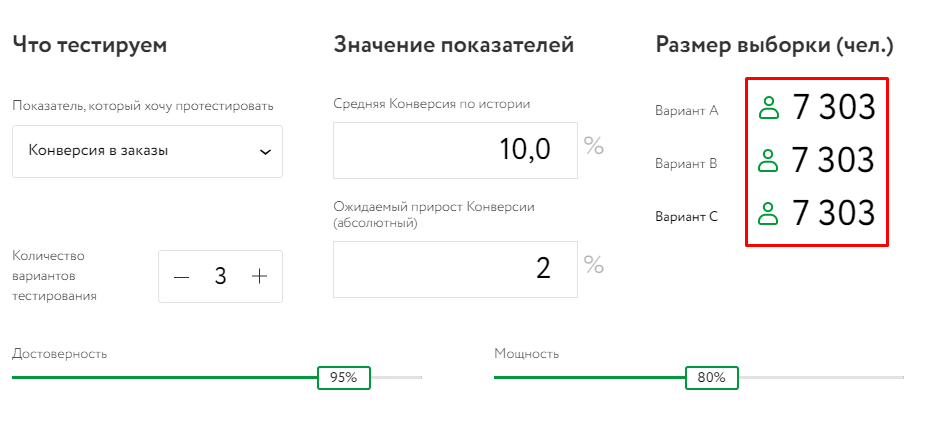
А вот размер выборки при тестировании трех групп (при этом остальные настройки остаются неизменными же):
Но при высоком бюджете важно помнить об эффективности мероприятий. Нельзя допускать того, чтобы затраты превосходили ожидаемый эффект от тестирования. Дополнительные средства можно перенаправить на SEO или другие каналы привлечения клиентов.
Советы по расчету выборки
Вот несколько рекомендаций, которые помогут правильно рассчитать репрезентативную выборку и получить показательное тестирование.
Репрезентативность выборочных данных

Репрезентативность — важнейшее свойство данных, используемых для построения аналитических моделей. Независимо от того, в какой предметной области и какими методами производятся выборочные исследования, отсутствие репрезентативности выборки приводит к некорректным результатам. В статье рассказываем подробнее об этом важном свойстве.
Репрезентативность — важнейшее свойство данных, используемых для построения аналитических моделей. Оно отражает способность данных представлять зависимости и закономерности исследуемой предметной области, которые должна обнаружить и научиться воспроизводить построенная модель. Иными словами, репрезентативность показывает, содержат ли анализируемые данные достаточно информации для построения качественной модели, а так же, может ли эта информация быть использована алгоритмом построения модели.
Репрезентативность генеральной совокупности отражает способность совокупности описывать существенные свойства, зависимости и закономерности объектов, процессов и явлений предметной области. Она достигается за счёт правильной организации сбора и консолидации первичных данных.
Репрезентативность выборки описывает способность выборочных данных отражать структурные свойства совокупности, из которой они были извлечены. Т.е. даёт ответ на вопрос: можно ли в исследовании заменить совокупность на выборку без значимого ухудшения результатов анализа. Репрезентативность выборки достигается с помощью правильного выбора метода сэмплинга.
Таким образом, репрезентативность выборки касается только воспроизведения характеристик совокупности. Если сама исходная совокупность плохо представляет предметную область, то, даже если полученная из неё выборка будет репрезентативной, построить на её основе корректную с точки зрения предметной области модель будут невозможно.
Например, пусть компания собирается вывести на рынок новый продукт. При этом она хочет провести маркетинговые исследования в виде опроса клиентов о желаемых характеристиках и параметрах продукта. Число клиентов компании насчитывает сотни тысяч человек (генеральная совокупность), поэтому опросить их всех не представляется возможным физически, не является целесообразным экономически.
Поэтому компания формирует выборку клиентов для проведения опроса. Если мнение клиентов из выборки отражает мнение большинства клиентов и может быть использовано для принятия решений о параметрах и характеристиках нового продукта, то такая выборка будет репрезентативной.
Независимо от того, в какой предметной области и какими методами производятся выборочные исследования, отсутствие репрезентативности выборки приводит к некорректным результатам. Поэтому в процессе анализа необходимо убедиться, что сформированная выборка репрезентативна.
Таким образом, репрезентативная выборка — это такая выборка, в которой представлены все подгруппы, важные для исследования. Помимо этого, характер распределения рассматриваемых параметров в выборке должен быть таким же, как в генеральной совокупности.
Особенно важным является обеспечение репрезентативности в машинном обучении, для построения моделей классификации и регрессии используется несколько выборок: обучающая, тестовая и валидационная, которые тем или иным способом отбираются из исходного набора данных. И все эти выборки должны быть репрезентативными.
Обеспечение репрезентативности
В основе построения репрезентативной выборки лежит правильный выбор используемого алгоритма сэмплинга. При этом размер выборки, хотя и является важным, сам по себе не гарантирует ее репрезентативности. Например, интернет-опрос может показать, что 100% людей пользуется интернетом, хотя это не соответствует действительности (т.е. репрезентативность нарушена).
Выделяют качественную (структурную) и количественную репрезентативность.

Рисунок 1. Количественная и качественная репрезентативность
Качественная репрезентативность
Качественная репрезентативность показывает, что все группы, присутствующие в совокупности, будут представлены и в выборке. Для этого каждый элемент совокупности должен иметь равную вероятность, быть выбранным, а сама выборка должна производиться из однородных групп.
Наиболее оптимальным способом формирования репрезентативной выборки является простой случайный сэмплинг, поскольку в этом случае у любого представителя генеральной совокупности будет одинаковая вероятность попасть в выборку.
Например, при формировании выборки клиентов для опроса, в нее попадут люди из различных социальных групп пропорционально их долям в генеральной совокупности. В результате, выборка будет представлять собой уменьшенную копию генеральной совокупности.
Случайность отбора респондентов в выборку может обеспечивается различными методами. Например, для опроса клиентов берутся номера клиентских карт, которые случайным образом отбираются компьютерной программой с использованием генератора случайных чисел.
Однако, на практике применить простой случайный сэмплинг не всегда представляется возможным. Это связано с тем, что генеральная совокупность может быть неоднородной и будет содержать группы объектов.
Например, если опрос будет проводиться по телефону, то большинство откликов будет получено от пенсионеров, как людей менее занятых и более склонных идти на контакт. Очевидно, что если опрос проводится о продукте, ориентированном на молодёжь, то ценность мнения пенсионеров вряд ли будет высокой.
Чтобы решить эту проблему, можно использовать случайный стратифицированный сэмплинг, когда исходная совокупность сначала разделяется на слои (страты) по некоторому признаку. Например, клиенты могут быть стратифицированы по возрасту. Тогда страты могут быть сформированы пропорционально доле объектов в группах, что позволит уменьшить или увеличить долю той или иной группы, сохранив репрезентативность.
Другой вариант — использовать кластерный (групповой) сэмплинг, когда клиенты предварительно разбиваются на качественно однородные группы — кластеры, и отбор производится из каждого кластера независимо. При этом вероятность отбора может быть одинаковой для всех кластеров, или различной. Можно некоторые кластеры вообще исключить из отбора. В нашем примере клиенты могут быть разбиты на кластеры по социальному статусу — студенты, работающие, пенсионеры, военнослужащие и т.д. Таким образом, долю, пенсионеров в выборке, можно уменьшить или совсем исключить.
Количественная репрезентативность
Количественная репрезентативность показывает, является ли достаточным число элементов выборки для представления характеристик генеральной совокупности с заданной погрешностью. Например, при неизвестной величине генеральной совокупности, когда результат отражается в виде показателя относительной доли, число элементов выборки, обеспечивающее количественную репрезентативность, может быть вычислено по формуле:
где t — доверительный коэффициент, показывающий, какова вероятность того, что размеры показателя не будут выходить за границы предельной ошибки, p — доля единиц наблюдения, обладающих изучаемым признаком, q=1−p — доля единиц наблюдения, не обладающих изучаемым признаков, Δ — допустимая ошибка выборки.
n=\frac<2^<2>\cdot 0,25\cdot 0,75><0,05^<2>>=300 заёмщиков.
Если же показатель — не относительная средняя величина просроченной задолженности по всем клиентам, то число наблюдений будет:
Если используется выборка без возврата и размер генеральной совокупности известен, то для определения необходимого размера случайной выборки при использования относительных величин (долей) применяется формула:
n=\frac
где N — число наблюдений генеральной совокупности. Для средних значений исследуемой величины формула примет вид:
n=\frac<2^<2>\cdot 0,25\cdot 0,75\cdot 500><0,05^<2>\cdot 500+2^<2>\cdot 0,25\cdot 0,75>\approx 188 клиентов.
Таким образом, необходимый объем выборки при безвозвратном отборе меньше, чем при возвратном (соответственнo, 188 и 300).
В целом, число наблюдений, требуемое для получения репрезентативной выборки, изменяется обратно пропорционально квадрату допустимой ошибки.
Методы оценки репрезентативности
Формально, выборку называют репрезентативной, когда результат оценки определенного параметра по данной выборке совпадает с результатом, оцененным по генеральной совокупности с учетом допустимой погрешности (ошибки репрезентативности). Если выборочная оценка отличается от оценки по генеральной совокупности более, чем на заданный уровень погрешности, то такая выборка считается нерепрезентативной.
Репрезентативность оценивается по отдельным параметрам выборки и совокупности. При этом выборка может оказаться репрезентативной по одним параметрам и нерепрезентативной по другим. Поэтому говорить о репрезентативности как о дихотомическом свойстве выборки (репрезентативна или нерепрезентативна) было бы не верно: выборка может одни параметры генеральной совокупности воспроизводить более точно, а другие — менее. Поэтому правильнее говорить о мере репрезентативности определённой выборки по конкретным параметрам.
Основным моментом в определении репрезентативности выборки является обоснование погрешности, в пределах которой выборка признается репрезентативной. Одна и та же выборка может быть достаточно репрезентативной для одной задачи и недостаточно для другой. Кроме этого, нужно проверять репрезентативность выборки по параметрам, имеющим существенное значение для предметной области исследования. Например, в маркетинговых исследованиях для анализа клиентов важны пол, возрасту, образование и пр.
Следует отметить, что далеко не все задачи бизнес-аналитики требуют строгого статистического подтверждения репрезентативности выборок. Как правило, это задачи точного прогнозирования. Что касается обычных задач, связанных, например, с определением предпочтений действующих и потенциальных клиентов, то они решаются охватом типичной клиентуры, которую можно найти непосредственно в торговых центрах.
Статистические методы
Данные, полученные в результате выборочных обследований, являются реализациями случайных величин (возраст, стаж работы, доход и т.д.). Обычно, на практике считают, что выборка является репрезентативной, если её статистические параметры (среднее значение, дисперсия, среднеквадратичное отклонение и т.д.) отличаются от параметров совокупности не более, чем на 5%.
Однако, данный подход применим только при условии, что вся генеральная совокупность известна и для неё можно вычислить статистические характеристики. Но на практике такое встречается редко, поскольку часть потенциально интересных для исследования объектов оказывается недоступной для наблюдения.
В этом случае прибегают к формированию двух независимых выборок, вычисляют и сравнивают их характеристики, и если они совпадают (не различаются значимо), то выборки считаются репрезентативными. В теоретическом плане такой подход является достаточно привлекательным, однако, на практике сложно реализуем. Во-первых, формирование нескольких выборок ведёт к дополнительным затратам, а во-вторых, если параметры выборок значимо различаются, то невозможно сказать, какая из них репрезентативна.
Нестатистические методы
Статистические методы оценки репрезентативности выборочных данных, хотя и являются строго обоснованными, но довольно сложны в использовании (особенно для пользователей, не имеющих достаточной математической подготовки). Кроме этого они могут иметь ограничения (например, независимость выборок), удовлетворить которым достаточно сложно.
Статистические подходы к оценке репрезентативности выборок имеет смысл использовать, если для анализа данных используются статистические методы. Методы машинного обучения, которые является эвристическими и в большинстве случаев не обеспечивают точного и единственного решения, вообще говоря, не нуждаются в точной оценке репрезентативности обучающих выборок. Поэтому в них используются свои техники для определения того, насколько обучающая или тестовая выборка хорошо представляют исходную совокупность.
Ещё одной особенностью выборок, используемых в машинном обучении, является то, что объём исходной совокупности, из которой формируются обучающее, тестовое, а при необходимости, и валидационное множество, известен, поскольку данные содержатся в консолидированных таблицах источника данных.
Затем вычислим величину:
где D_<_
Тогда индекс ближайшего соседа будет:
Если значение данного показателя близко к 1, то точки выборки имеют равномерное пространственное распределение. Если меньше 1, то пространственное распределение точек неоднородно. Если NNI больше 1, то имеет место значительная дисперсия значений внутри выборки.
Очевидно, что наилучшим вариантом с точки зрения репрезентативности будет первый случай, когда пространственное распределение точек данных в совокупности и выборке примерно одинаковое. Второй случай показывает, что внутри выборки могут присутствовать некоторое локальные особенности, нехарактерные для всей совокупности.
В литературе можно найти больше количество разнообразных алгоритмов и методов оценки репрезентативности выборок для машинного обучения, разработанных для различных предметных областей исследования и типов задач анализа. Большинство их них являются эвристическими и не гарантируют получения наилучшего результата. Поэтому самым надёжным критерием репрезентативности выборки, на основе которой строилась определённая обучаемая модель, является точность и обобщающая способность самой модели.
Ремонт выборки
Возникает вопрос: а что делать в ситуации, когда аналитику доступна только выборка «как есть», а её репрезентативность неудовлетворительная? При этом доступ к генеральной совокупности для формирования более репрезентативной выборки у него отсутствует (например, из-за проблем с сетью, невозможности повторных исследований из-за высоких затрат и т.д.). В этом случае улучшить ситуацию может специальная процедура, которая называется «ремонт выборки».
Все действия аналитика, связанные с репрезентативностью, можно разделить на два этапа: контроль и ремонт.
Контроль и ремонт выборки рассматриваются как обязательные этапы любого выборочного исследования. Хотя, некоторые авторы не разделяют эти два этапа, а включают ремонт в общую процедуру контроля выборки. Ряд вопросов, связанных с контролем выборки был рассмотрен выше.
Основной целью ремонта является повышение качества выборки в смысле отражения ею зависимостей и закономерностей исследуемых процессов и явлений, которые требуется обнаружить в процессе анализа. При этом не следует путать ремонт выборки с повышением качества данных вообще.
Ремонт выборки, обычно, включает следующие задачи:
Следует отметить, что единого, строго обоснованного подхода к ремонту выборок, вообще говоря, не существует, хотя в литературе можно встретить некоторые общие рекомендации. В большинстве практических случаев аналитику приходится самостоятельно выбирать, какие преобразования следует применить к выборке для повышения её репрезентативности.



