Дедлоки в SQL Server — часть 1: Что такое блокировки


Введение
В сложных, распределенных, высоконагруженных системах очень часто возникает проблема конкурентного доступа к данным, что приводит к использованию различного рода блокировок в запросах к БД. Кроме того, могут возникать взаимоблокировки, с которыми нужно бороться.
Мы начинаем серию публикаций, посвященную блокировкам в базах данных, в которых поделимся своим опытом, наработанном в нашей компании, по следующим вопросам:
– Какие виды блокировок использовали при разработке наших продуктов
– Какие средства диагностики и инструменты использовали при определении взаимоблокировок
– Как боролись с взаимоблокировками
В данной статье серии, мы рассмотрим блокировки, с которыми столкнулись при разработке программных продуктов.
Прежде чем приступить, кратко напомним, зачем вообще нужны блокировки.
Зачем нужны блокировки
В распределенных системах, использующих в качестве хранилища БД, могут возникать различные побочные эффекты при параллельном доступе к данным:
– Потерянное обновление (lost update) — две транзакции выполняют одновременно UPDATE для одной и той же строки, и изменения, сделанные одной транзакцией, затираются другой;
– «Грязное» чтение (dirty read) — это такое чтение, при котором могут быть считаны добавленные или изменённые данные из другой транзакции, которая впоследствии откатится;
– Неповторяющееся чтение (non-repeatable read) — проявляется, когда при повторном чтении в рамках одной транзакции, ранее прочитанные данные, оказываются изменёнными;
– Фантомное чтение (phantom reads) — можно наблюдать, когда одна транзакция в ходе своего выполнения несколько раз выбирает множество строк по одним и тем же критериям. При этом другая транзакция в интервалах между этими выборками добавляет или удаляет строки, или изменяет столбцы некоторых строк, используемых в критериях выборки первой транзакции, и успешно заканчивается. В результате получится, что одни и те же выборки в первой транзакции дают разные множества строк.
Современные СУБД имеют возможность решать подобные проблемы при помощи встроенных механизмов, например MS SQL Server делает это с помощью использования различных уровней изоляции транзакций:
Для реализации требования изолированности транзакции используется в свою очередь механизм блокировок. Таким образом, механизм блокировок предназначен решать проблемы параллелизма. Стоит также отметить, что неправильное использование блокировок может приводить к деградации производительности, взаимоблокировкам и потере данных.
Блокировки
В MS SQL Server существует много различных видов блокировок и на эту тему написано много хороших статей и технической документации. В статье мы затронем только часть из них, с которыми столкнулись на практике при разработке наших продуктов.
Задача извлечения данных из очереди
Классической задачей, при котором используется блокировка, это задача извлечения элемента из очереди, c которой одномоментно может работать ограниченное количество клиентов. Доступ к такому элементу одновременно должен получить только один клиент очереди.
В нескольких наших продуктах используется очередь, хранимая в БД, доступ к которой должен быть синхронизирован между клиентами. Рассмотрим, как решалась данная задача в наших продуктах.
Представим, что у нас есть очередь задач для клиентов, которая хранится в БД. Каждую задачу может получить одновременно максимум N клиентов. Т.е. появляется связанность задачи с ее результатами, это связь 1-N. Это привносит дополнительную сложность, т.к. извлекаемые данные находятся в двух таблицах, связанных внешним ключом. Структура таблиц выглядит примерно следующим образом:
Task — таблица с задачами
TaskResult — таблица с результатами задач.
Для решения этой задачи мы использовали блокировку обновления (UPDLOCK) записей корневой таблицы Task совместно с хинтами ROWLOCK и READPAST.

Использование блокировки UPDLOCK гарантировало нам, что к задаче не смогут получить доступ другие клиенты, хинтом ROWLOCK мы рекомендовали MS SQL серверу использовать блокировку на уровне строки, READPAST — выбирал нам только незаблокированные другими транзакциями записи. Помимо извлечения данных, мы также во все операции обновления данных, как корневой, так и дочерней таблицы, включили хинты UPDLOCK и ROWLOCK.
Таким образом мы решили задачу конкурентного доступа к задачам клиентами.
Задача извлечения данных, которые параллельно изменяются
В высоконагруженных системах, разработкой которых занимается компания ITA Labs, часто бывает необходимо мониторить данные, которые часто изменяются параллельными транзакциями. Если нам важно лишь состояние данных в конкретный момент времени, можно не ставить блокировку вообще. В таком случае есть риск прочтения неконсистентных данных в конкретный момент времени, но которые актуализируются спустя некоторое время. При этом мы увеличиваем скорость чтения отображаемых данных, вместо того, чтобы ждать освобождения блокировок. Это очень важно для своевременного отклика программы и увеличивает дружественность пользовательского интерфейса.
В одном из разрабатываемых продуктов нам необходимо было отображать историю выполненных задач конкретным оператором, а также выбирать команды, соответствующие определенным критериям, т.е. фильтровать. Из-за того, что параллельно к этим данным обращались множество клиентов с операциями обновления, таблица блокировалась и прочитать данные не всегда удавалось за необходимое время, выходил таймаут. Эту проблему мы решили чтением данных без блокировки с помощью хинта NOLOCK, но сразу отметим, что подобный метод не годится, если на основании прочитанных данных будет приниматься какое-либо решение. Пример:

Указание хинта NOLOCK указывает SQL Server-у не использовать блокировки при выполнении данной транзакции, в результате чтение данных происходит быстро. Но здесь стоит отметить один момент — на самом деле все же один тип блокировки, даже при использовании хинта NOLOCK, будет устанавливаться. Это блокировка стабилизации схемы (schema stability lock, Sch-S). Но обычно редко во время выполнения бизнес-логики, затрагивающее работу с БД, требуется менять схему БД, поэтому данная блокировка не будет оказывать никакого влияния. Но, в тех системах, в которых все же меняется схема БД параллельно с доступом к данным БД, нужно учитывать данное обстоятельство и использовать другие механизмы блокировок.
Задача синхронизации доступа к модифицируемым данным
Очень часто в распределенных системах встречается задача синхронизации доступа к данным с последующей их модификацией. В наших продуктах мы также сталкиваемся с подобным. В таких случаях необходимо использовать блокировку обновления UPDLOCK в операторе извлечения данных. Это гарантирует, что извлекаемые для последующего изменения данные блокируются до момента завершения транзакции.

Рассмотрим пример на Рис.2. Допустим, у нас есть 2 параллельно выполняющиеся транзакции, которые выбирают вторую строку из таблицы Table для последующей модификации. Для того, чтобы предотвратить одновременный доступ к этой строке для модификации мы наложили блокировку обновления UPDLOCK на оператор выборки SELECT. Таким образом, доступ ко второй строке получит транзакция, первой наложившая блокировку обновления. Вторая же транзакция будет ожидать освобождения наложенной блокировки.
Управление эскалацией блокировок
Эскалация блокировок — это процесс, который направлен на оптимизацию работы сервера, позволяющий заменять множество низкоуровневых блокировок одной или несколькими блокировками более высокого уровня.
Например, если у нас создано множество блокировок уровня строки, и все строки принадлежат одной странице, то сервер, в целях экономии ресурсов, может заменить их все одной блокировкой уровня страницы и далее до уровня всей таблицы (см. Рис. 3).

В наших продуктах мы также использовали управление опцией эскалации блокировок там, где это нужно. В одном из проектов мы столкнулись с эскалацией блокировок с уровня строк до более верхних уровней — страниц, экстентов. Эскалации возникали при высокой нагрузке на несколько связанных между собой таблиц. Транзакции блокировали друг друга и завершались по ошибке. Чтобы решить данную проблему мы запретили эскалацию блокировок для некоторых таблиц, которые ссылались на множество других таблиц.

После отключения эскалации блокировок, проблема с взаимными блокировками решилась. Общая пропускная способность системы тоже возросла за счет того, что значительно сократилось общее количество блокировок.
Также следует отметить, что нельзя злоупотреблять этой опцией и отключать эскалацию там, где это не требуется, т.к. это может негативно сказаться на производительности SQL Server и скорости выполнения SQL-инструкций.
Взаимоблокировки
Взаимоблокировка (deadlock) — это ситуация при которой, одному процессу для продолжения работы требуется ресурс, захваченный вторым процессом, а второму процессу требуется ресурс, захваченный первым процессом. В такой ситуации оба процесса оказываются в заблокированном состоянии и не могут продолжать работу.
Рассмотрим простейший пример. Допустим, у нас есть таблица Students, состоящая из 2-х строк:

Параллельно запускаются 2 транзакции:


На операторе обновления мы получим блокировку в обеих транзакциях. Что же тут происходит? Оператор SELECT в обеих транзакциях накладывает блокировку обновления на вторую и первую строки соответственно. Затем, при выполнении оператора UPDATE в первой транзакции, процесс пытается наложить эксклюзивную блокировку на первую строку, но не может этого сделать, т.к. она заблокирована второй транзакцией и остается ждать его освобождения.
Аналогично вторая транзакция при выполнении оператора UPDATE пытается наложить эксклюзивную блокировку на вторую строку, но она уже заблокирована первой транзакцией и процесс остается ждать освобождения блокировки. Это классический пример взаимной блокировки.
Обе транзакции ждут освобождения заблокированных друг другом ресурсов. Но на этом процессы не виснут. MS SQL Server с помощью встроенного менеджера блокировок определяет взаимные блокировки и разрешает их. Разрешает очень просто — жертвует одной из транзакций, т. е. попросту откатывает ее и возвращает ошибку. Вторая транзакция продолжит выполняться. Какая транзакция будет выбрана в качестве жертвы — определяет сам MS SQL Server, исходя из соображений производительности или же, определяется при помощи задания приоритета DEADLOCK_PRIORITY.
Заключение
В данной статье мы рассказали о блокировках и для чего они нужны. Если говорить вкратце — блокировки являются механизмом для реализации требования различных уровней изоляции транзакций.
Мы рассмотрели проблемы, которые приходилось решать на практике с помощью блокировок в многопользовательской конкурентной среде:
– это задача извлечения данных из очереди — когда одномоментно к данным имеет доступ только один клиент;
– это задача извлечения изменяемых данных с конкурентным доступом — когда клиенты одновременно обращаются к общим, часто изменяемым данным, но только для чтения;
– это задача синхронизации доступа к модифицируемым данным — когда необходимо получить доступ к данным с последующим изменением.
Также мы коснулись темы эскалации блокировок — когда блокировки более низкого уровня укрупняются до уровня страниц, таблиц при превышении критического значения.
Ну и на десерт, мы затронули вкратце о взаимоблокировках — ситуации, при котором 2 процесса ждут освобождения заблокированного ресурса друг у друга.
Эта тема заслуживает отдельного внимания, и в продолжении статьи мы расскажем о том, как диагностировать и бороться с взаимоблокировками.
Автор статьи: Николай Иванов, Старший Разработчик, ITA Labs
Deadlocks, Livelocks и Starvation

Продолжаем серию статей о проблемах многопоточности, параллелизме, concurrency и других интересных штуках.
В 1965 году Эдсгер Дейкстра сформулировал задачу об обедающих философах. Задача была иллюстрацией проблем синхронизации при разработке параллельных алгоритмов и техник решения этих проблем.
В задачи были рассмотренный такие проблема, как deadlock, livelock, resource starvation.

Саму задачу и возможные решения можно посмотреть на wiki.
А мы рассмотрим проблемы синхронизации в контексте современных языков программирования.
Deadlock
Что такое deadlock и как избежать таких ошибок?
Deadlock или взаимная блокировка — это ошибка, которая происходит когда процессы имеют циклическую зависимость от пары синхронизированных объектов.

Deadlock — это программа, в которой все параллельные процессы ожидают друг друга. В этом состоянии программа никогда не восстановится без вмешательства извне.
Пример


fatal error: all goroutines are asleep — deadlock!
Отладка взаимных блокировок, как и других ошибок синхронизации, усложняется тем, что для их возникновения нужны специфические условия одновременного выполнения нескольких процессов. Если бы Процесс 1 успел захватить ресурс B до Процесса 2, то ошибка не произошла бы.
Но все не так плохо, оказывается, есть несколько условий, которые должны присутствовать для возникновения взаимных блокировок, и в 1971 году Эдгар Коффман перечислил эти условия в своей статье System Deadlocks. Условия теперь известны как условия Кофмана и являются основой для методов, которые помогают обнаруживать, предотвращать и исправлять взаимные блокировки.

Условия Коффмана
Указанные условия являются необходимыми. То есть, если хоть одно из них не выполняется, то взаимных блокировок никогда не возникнет. Достаточность не имеет места быть: если выполняются все четыре условия, блокировка может и не произойти, например, если в системе нет процессов, претендующих на одновременное использование одних и тех же ресурсов.
Диаграммы Холта (Holt).
Отслеживать возникновение взаимных блокировок удобно на диаграммах Холта (Holt). Диаграмма Холта представляет собой направленный граф, имеющий два типа узлов: процессы (показываются кружочками) и ресурсы (показываются квадратиками). Тот факт, что ресурс получен процессом и в данный момент занят этим процессом, указывается ребром (стрелкой) от ресурса к процессу. Ребро, направленное от процесса, к ресурсу, означает, что процесс в данный момент блокирован и находится в состоянии ожидания доступа к соответствующему ресурсу.
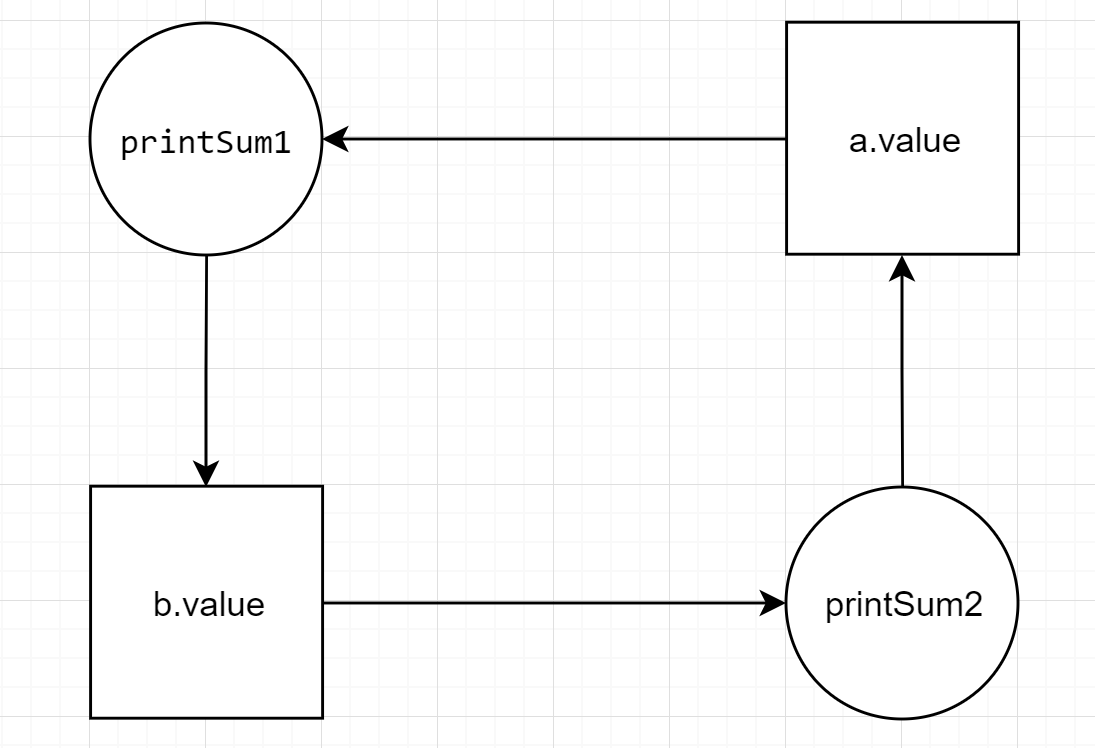
Критерий deadlock.
Livelock
Livelock— это программы, которые активно выполняют параллельные операции, но эти операции никак не влияют на продвижение состояния программы вперед.
Ситуация, в которой два или более процессов непрерывно изменяют свои состояния в ответ на изменения в других процессах без какой-либо полезной работы. Это похоже на deadlock, но разница в том, что процессы становятся “ вежливыми” и позволяют другим делать свою работу.
Выполнение алгоритмов поиска удаления взаимных блокировок может привести к livelock — взаимная блокировка образуется, сбрасывается, снова образуется, снова сбрасывается и так далее.
Жизненный пример такой ситуации:
Двое встречаются лицом к лицу. Каждый из них пытается посторониться, но они не расходятся, а несколько секунд сдвигаются в одну и ту же сторону.
Вы делаете телефонный звонок, но человек на другом конце тоже пытается вам позвонить. Вы оба повесите трубку и попробуйте снова через одно и то же время, что снова создаст такую же ситуацию. Это может продолжаться вечность.
Рассмотрим простой пример livelock, где муж и жена пытаются поужинать, но между ними только одна ложка. Каждый из супругов слишком вежлив, и передает ложку, если другой еще не ел.

Ложка у которой есть хозяин:
Процесс обеда. Ложка и партнер:
Обедаем пока не утолим голод( isHungry=false ).
Поесть этим милым людям не суждено. До третьего блока выполнение не дойдет.
На мой взгляд, обнаружить livelock труднее, чем deadlock, просто потому, что может показаться, что программа работает. Она может реагировать на сигналы, потреблять ресурсы и как то менять состояния, но выйти из цикла и завершить работу уже не в состоянии.
Livelock— это подмножество более широкого набора проблем, называемых Starvation.
Starvation

Starvation — это любая ситуация, когда параллельный процесс не может получить все ресурсы, необходимые для выполнения его работы.
При livelock все параллельные процессы одинаково “голодают”, и никакая работа не выполняется до конца.
В более широком смысле starvation обычно подразумевает наличие одного или нескольких параллельных процессов, которые несправедливо мешают одному или нескольким другим параллельным процессам выполнять работу настолько эффективно, насколько это возможно.
Пример
У нас будет два работника. Один жадный( greedyWorker ), другой вежливый( politeWorker ). Обоим дается одинаковое кол-во времени на их полезную работу — спать по 3 наносекунде.
greedyWorker жадно удерживает общий ресурс( sharedLock ) на протяжении всего цикла работы, тогда как politeWorker пытается блокировать его только тогда, когда это необходимо.
Результат их работы:
За одно и то же время, жадный работник получил почти вдвое больше возможностей выполнять свою работу и владеть общим ресурсом.
Конечно, lock\unlock медленные и в данном примере у politeWorker очень неэффективный код, но голодания может также применяться к процессору, памяти, файловым дескрипторам, соединениям с бд, к любому ресурсу, который должен использоваться совместно.
Если у вас есть параллельный процесс, который настолько жаден, что препятствует эффективно работать другим параллельным процессам, то у вас большая проблема.
Боремся с deadlock-ами: паттерн unlocked callbacks
Ситуации взаимной блокировки
В Википедии дается следующее определение взаимной блокировки: «Взаимная блокировка (англ. deadlock) — ситуация в многозадачной среде или СУБД, при которой несколько процессов находятся в состоянии бесконечного ожидания ресурсов, занятых самими этими процессами».
Взаимные блокировки носят, как правило, динамический характер: их проявление зависит от таких факторов, как действия пользователя, доступность сетевых сервисов, позиционирование головки жесткого диска, переключение задач в системе с вытесняющей многозадачностью и т.п.
Классический пример взаимной блокировки: первый поток (A) захватывает мьютекс M1 и следом мьютекс M2. Второй поток (B) захватывает мьютекс M2, а уже после этого – мьютекс M1. Взаимная блокировка этих двух потоков может произойти следующим образом: поток A захватывает M1, поток B захватывает M2, после этого оба потока «обречены»: ни поток A не может захватить M2, ни поток B не может захватить M1; попытки захвата мьютексов заблокируют оба потока.
Описанная взаимная блокировка произойдет только в том случае, если оба потока успеют захватить ровно по одному мьютексу. В противном случае потоки продолжат свое выполнение.
Данная ситуация очень распространена в сложных многопоточных системах. Как правило, мьютексы-участники расположены далеко друг от друга (в различных компонентах системы), и выявить участников взаимной блокировки оказывается достаточно сложно.
Распространенная ситуация в реальной системе
Далее предлагаются два способа решения этой проблемы.
Способ 1: изменить порядок блокировки
Способ 2: не блокировать мьютекс при передаче данных потребителям
Этот способ звучит многообещающе: если передача данных из внутреннего потока объекта Worker потребителям будет происходить при не заблокированных мьютексах, это исправит все возможные в дальнейшем взаимные блокировки при работе с объектом Worker.
Почему бы просто не делать обратный вызов при не захваченном мьютексе? Потому что поток объекта Worker должен пройтись по списку зарегистрированных потребителей и вызвать функцию интерфейса каждого потребителя. Если список не будет защищен мьютексом, и содержимое списка изменится в ходе этого цикла, вероятно зацикливание или даже аварийное завершение программы из-за некорректного обращения к памяти.
Почему бы не сделать копию списка потребителей (при создании копии захватывать мьютекс), а дальше пройти циклом по копии? Потому что нужно гарантировать потребителю, что после вызова unregisterCallback ему не будут переданы данные. Если потребитель вызывает unregisterCallback из своего деструктора, последующая передача данных в интерфейс обратного вызова этого потребителя приведет к аварийному завершению программы.
Типичные взаимные блокировки в MS SQL и способы борьбы с ними
Чаще всего deadlock описывают примерно следующим образом:
Процесс 1 блокирует ресурс А.
Процесс 2 блокирует ресурс Б.
Процесс 1 пытается получить доступ к ресурсу Б.
Процесс 2 пытается получить доступ к ресурсу А.
В итоге один из процессов должен быть прерван, чтобы другой мог продолжить выполнение.
Но это простейший вариант взаимной блокировки, в реальности приходится сталкиваться с более сложными случаями. В этой статье мы расскажем с какими взаимными блокировками в MS SQL нам приходилось встречаться и как мы с ними боремся.

Немного теории
Выбор уровня изоляции транзакции
При использовании транзакций с уровнем изоляции serializable могут происходить любые взаимные блокировки. При использовании уровня изоляции repeatable read некоторые из описанных ниже взаимных блокировок не могут произойти. У транзакций с уровнем изоляции read committed могут возникнуть только простейшие взаимные блокировки. Транзакция с уровнем изоляции read uncommitted практически не влияет на скорость работы других транзакций и в ней не могут возникнуть взаимные блокировки из-за чтения, так как она не накладывает shared блокировки (правда могут быть взаимные блокировки с транзакциями изменяющими схему БД).
Retry on deadlock
В достаточно сложной системе, насчитывающей десятки разнообразных типов бизнес транзакций, вряд ли получится спроектировать все транзакции таким образом, чтобы deadlock не мог возникнуть ни при каких условиях. Не стоит тратить время на предотвращение взаимных блокировок, вероятность возникновения которых крайне мала. Но, чтобы не портить user experience, в случае, когда операция прерывается из-за взаимной блокировки, ее нужно повторить. Для того, чтобы операцию можно было безопасно повторить, она не должна изменять входные данные и должна быть обернута в одну транзакцию (либо вместо всей операции, надо оборачивать в свой RetryOnDeadlock каждую SQL транзакцию в операции).
Вот пример функции RetryOnDeadlock на C#:
Важно понимать, что функция RetryOnDeadlock всего лишь улучшает user experience при изредка возникающих взаимных блокировках. Если они возникают очень часто, она лишь ухудшит ситуацию, в разы увеличив нагрузку на систему.
Борьба с простейшими взаимными блокировками
Если взаимная блокировка возникает из-за того, что два процесса обращаются к одним и тем же ресурсам но в разном порядке (как это описано в начале статьи), то достаточно поменять порядок блокировки ресурсов. В принципе, если в разных операциях блокируется определенный набор ресурсов, блокироваться первым всегда должен один и тот же ресурс, если это возможно. Этот совет применим не только к реляционным БД, но и вообще к любым системам, в которых возникают взаимные блокировки.
В применении к MS SQL этот совет, немного упрощая, можно выразить следующим образом: в разных транзакциях, изменяющих несколько таблиц, первой должна изменяться одна и та же таблица.
Shared->Exclusive lock escalation
Чтобы избежать такой взаимной блокировки, необходимо, чтобы из двух транзакций, собирающихся изменить запись, прочитать ее могла только одна. Специально для этого была введена update блокировка. Ее можно наложить следующим образом:
Если вы используете ORM и не можете управлять тем, как запрашивается сущность из БД, то вам придется выполнить отдельный запрос на чистом SQL для блокировки записи прежде чем запрашивать ее из БД. Важно, что накладывающий update блокировку запрос должен быть первым запросом, обращающимся к этой записи в данной транзакции, иначе будет возникать все та же взаимная блокировка, но при попытке наложить update блокировку, а не при изменении записи.
Накладывая update блокировку мы заставляем все транзакции, обращающиеся к одному ресурсу, выполняться по очереди, но обычно транзакции изменяющие один и тот же ресурс в принципе нельзя делать параллельно, так что это нормально.
Такая взаимная блокировка может возникнуть в любой транзакции, которая проверяет данные перед их изменением, но для редко изменяющихся сущностей, можно использовать RetryOnDeadlock. Подход с предварительной update блокировкой достаточно использовать только для сущностей, которые часто меняются разными процессами параллельно.
Пример
Пользователи заказывают призы за баллы. Количество призов каждого вида ограниченно. Система не должна позволить заказать больше призов, чем есть в наличии. Из-за особенностей промоакции периодически происходят набеги пользователей, желающих заказать один и тот же приз. Если использовать RetryOnDeadlock в данной ситуации, то во время набега пользователей заказ приза в большинстве случаев будет падать по web таймауту.
Большинство взаимных блокировок, описанных далее, происходят похожим образом — мы пытаемся изменить данные после того как наложили на них Shared блокировку. Но в каждом из этих случаев есть свои нюансы.
Выборки по неиндексируемым полям
Если мы в serializable транзакции ищем запись по полю не входящему ни в один индекс, то shared блокировка будет наложена на всю таблицу. По другому нельзя убедиться, что ни одна другая транзакция не сможет вставить запись с таким же значением до завершения текущей транзакции. В итоге любая транзакция делающая выборку по этому полю, а потом изменяющая эту таблицу, будет взаимно блокироваться с любой подобной же транзакцией.
Если же добавить индекс по этому полю (или индекс по нескольким полям, первым из которых является поле, по которому мы ищем), то блокироваться будет ключ в этом индексе. Так что в serializable транзакциях еще более важно задумываться есть ли индекс по колонкам, по которым вы ищете записи.
Есть еще один нюанс, о котором важно помнить: если индекс уникален, то блокировка накладывается только на запрашиваемый ключ, а если неуникален, то также блокируются cледующее за этим ключом значение. Две транзакции, запрашивающие разные записи по неуникальному индексу, а потом изменяющие их, могут взаимно блокироваться, если запрашиваются соседние значения ключей. Обычно это редкая ситуация и достаточно использовать RetryOnDeadlock, чтобы избежать проблем, но в некоторых случаях может потребоваться накладывать update блокировку при вытаскивании записей по неуникальному ключу.
Проверка на наличие перед вставкой
Пример
Нам необходимо проверить, есть ли в БД пользователь с таким Id в Facebook, перед тем как его добавлять. Так как мы работаем с одной строчкой в БД, создается ощущение, что будет блокироваться только она и вероятность взаимной блокировки невелика. Однако если в транзакции с уровнем изоляции Serializable попытаться выбрать несуществующее значение (и эта колонка входит в индекс), то будет наложена shared блокировка на все ключи между двумя ближайшими значениям, которые есть в таблице. Например, если в базе есть Id 15 и Id 1025, и нет ни одного значения между ними, то при выполнении SELECT * FROM Users WHERE FacebookId = 500 будет наложена Shared блокировка на ключи с 15 до 1025. Если до вставки другая транзакция проверит есть ли пользователь с FacebookId = 600 и попытается его вставить, то произойдёт взаимная блокировка. Если в БД уже много потребителей, у которых заполнен FacebookId, то вероятность взаимной блокировки будет невелика и нам достаточно использовать RetryOnDeadlock. Но если выполнять множество таких транзакций на почти пустой базе, то взаимные блокировки будут возникать достаточно часто, чтобы это сильно сказалось на производительности.
У нас эта проблема возникла при параллельном импорте потребителей от новых клиентов (для каждого клиента мы создаем новую пустую БД). Так как нас на данный момент устраивает скорость однопоточного импорта, мы просто отключили параллелизм. Но в принципе проблема решается также как и в выше описанном примере, надо использовать update блокировку:
В этом случае при многопоточном импорте в пустую базу по началу потоки будут простаивать, ожидая пока освободится блокировка, но по мере заполнения базы степень параллелизма будет возрастать. Хотя если импортируемые данные упорядочены по FacebookId, то параллельно импортировать их не получится. При импорте в пустую базу такого упорядочивания стоит избегать (либо не проверять наличие пользователей в БД по FacebookId при первом импорте).
Взаимные блокировки на сложных агрегатах
Если у вас в системе есть сложный агрегат, данные которого хранятся в нескольких таблицах, и есть множество транзакций изменяющих разные части этого агрегата параллельно, то необходимо выстроить все эти транзакции таким образом, чтобы в них не возникали взаимные блокировки.
Пример
В БД хранится персональные данные потребителя, его идентификаторы в соц сетях, заказы в интернет магазине, записи об отправленных ему письмах.

Транзакции, добавляющие идентификатор в соц сети, отправляющие письма и регистриующие покупки, также могут изменять технические поля в основной записи о потребителе. В любой из этих транзакций присутствует Id потребителя.
Для избежания взаимных блокировок нужно начинать любую транзакцию со следующего запроса:
В этом случае в один момент только одна транзакция сможет изменять данные, относящиеся к конкретному потребителю и взаимные блокировки не будут возникать в независимости от того насколько сложен агрегат потребителя.
Можно попробовать изменить схему хранения данных так, чтобы транзакции, отправляющие письма и регистрирующие покупки не меняли технические пометки в потребителе. Тогда информацию о заказах и отправленных письмах можно будет изменять параллельно с изменением потребителя. В этом случае мы фактически выносим эти данные за рамки агрегата «потребитель».
Взаимные блокировки на последовательно идущих записях
Подобные взаимные блокировки возникают при очень специфичных условиях, но пару раз мы с ними все-таки сталкивались, так что о них тоже стоит рассказать.
Пример



