Бэггинг
Материал из MachineLearning.
Содержание
Идея метода
Бэггинг – технология классификации, где в отличие от бустинга все элементарные классификаторы обучаются и работают параллельно (независимо друг от друга). Идея заключается в том, что классификаторы не исправляют ошибки друг друга, а компенсируют их при голосовании. Базовые классификаторы должны быть независимыми, это могут быть классификаторы основанные на разных группах методов или же обученные на независимых наборах данных. Во втором случае можно использовать один и тот же метод.
Бэггинг на подпространствах
Этот алгоритм применяется для классификации многомерных объектов. Рассматриваемый алгоритм помогает добиться качественной классификации в условиях, когда разделить объекты на группы на всем пространстве параметров не представляется возможным. Предлагается разделить пространство характеристик на подмножества объединенных по смыслу параметров. Классификация на каждом подпространстве производится отдельно, затем результаты учитываются в голосовании. В этом случае будет учтен вклад каждой смысловой группы и много повысится вероятность того, что итоговые результаты классификации окажутся более качественными нежели без деления на подпространства, так как параметры, по которым представители разных классов неотличимы, попадут, почти наверняка, не во все группы.
Постановка задачи
Существует матрица характеристик объекта мерные столбцы с характеристиками объектов. Необходимо сопоставить каждому вектору параметров метку класса (т.е. существует некоторое отображение Y» alt= «X->Y»/>, где метки классов), на основании известных пар для объектов обучающей выборки.
Алгоритм классификации в технологии бэггинг на подпространствах
Методы принятия решений
Окончательное решение о принадлежности объекта классу может приниматься, например, одним из следующих методов:
Бэггинг на подпространствах с классификаторами на основе метода потенциальных функций
Объединение метода Бравермана потенциальных функций и технологии Бэггинг позволяет работать с небольшими выборками многомерных объектов. Подход успешно справляется с неравномерным распределением объектов внутри классов, однако выбросы в данных (особенно при небольших выборках) оказывают очень большое влияние на результаты итоговой классификации.
Ансамблевые методы машинного обучения
Поэтому я решил осветить эту тему в данной статье и показать реализацию ансамблей с помощью scikit-learn.
Что такое ансамбль?
Метод машинного обучения, где несколько моделей обучаются для решения одной и той же проблемы и объединяются для получения лучших результатов называется ансамблевым методом. Основная предпосылка заключается в том, что результат работы нескольких моделей будет более точен, чем результат только одной модели.
Когда говорится об ансамблях, то вводится понятие слабого ученика(обычные модели вроде линейной регрессии или дерева решений). Множество слабых учеников являются строительными блоками для более сложных моделей. Объединение слабых учеников для улучшения качества модели, уменьшения смещения или разброса, называется сильным учеником.
Виды ансамблевых методов
Наиболее популярными ансамблевыми методами являются: стекинг, бэггинг, бустинг.
Стекинг. Используется несколько разнородных слабых учеников. Их обучают и объединяют для построения прогноза, основанного на результатах различных слабых моделей.
Бэггинг. В этом случае однородные модели обучают на разных наборах данных и объединяют. Получают прогноз путём усреднения. Если использовать в качестве слабого ученика деревья решений, то получится случайный лес RandomForestClassifier / RandomForestRegressor.
Бустинг. При использовании данного метода несколько однородных моделей последовательно обучаются, исправляя ошибки друг друга.
Стекинг
Работа этого типа ансамблей довольно проста. На вход всех слабых прогнозаторов подаётся обучающий набор, каждый прогноз идёт к финальной модели, которая называется смеситель, мета-ученик или мета-модель, после чего та вырабатывает финальный прогноз.
 Обучение мета-модели
Обучение мета-модели
При обучении мета-модели используется приём удерживаемого набора. Сначала набор разделяется на 2 части. Слабые ученики обучаются на первой половине обучающего набора, затем на второй. Затем создаётся новый обучающий набор на основе прогнозов, сделанных на прогнозах первой и второй части набора. Таким образом, на каждый образец из входного набора приходится столько прогнозов, сколько слабых учеников в ансамбле (в примере на картинке три). Мета-модель учится прогнозировать значения на основе нового набора.
Бэггинг
Основная идея бэггинга заключается в том, чтобы обучить несколько одинаковых моделей на разных образцах. Распределение выборки неизвестно, поэтому модели получатся разными.
Если класс предсказывает большинство слабых моделей, то он получает больше голосов и данный класс является результатом предсказывания ансамбля. Это пример жёсткого голосования. При мягком голосовании рассматриваются вероятности предсказывания каждого класса, затем вероятности усредняются и результатом является класс с большой вероятностью.
Бустинг
Метод бустинга в чём то схож с методом бэггинга: берётся множество одинаковых моделей и объединяется, чтобы получить сильного ученика. Но разница заключается в том, что модели приспосабливаются к данным последовательно, то есть каждая модель будет исправлять ошибки предыдущей.
Адаптивный бустинг (AdaBoost)
Данный алгоритм сначала обучает первую базовую модель(допустим деревья решений) на тренировочном наборе. Относительный вес некорректно предсказанных значений увеличивается. На вход второй базовой модели подаются обновлённые веса и модель обучается, после чего вырабатываются прогнозы и цикл повторяется.
Adaboost обновляет веса объектов на каждой итерации. Веса хорошо классифицированных объектов уменьшаются относительно весов неправильно классифицированных объектов. Модели, которые работают лучше, имеют больший вес в окончательной модели ансамбля.
При адаптивном бустинге используется итеративный метод (добавляем слабых учеников одного за другим, просматривая каждую итерацию, чтобы найти наилучшую возможную пару (коэффициент, слабый ученик) для добавления к текущей модели ансамбля) изменения весов. Он работает быстрее, чем аналитический метод.
Градиентный бустинг
Градиентный бустинг обучает слабые модели последовательно, исправляя ошибки предыдущих. Результатом градиентного бустинга также является средневзвешенная сумма результатов моделей. Принципиальное отличие от Adaboost это способ изменения весов. Адаптивный бустинг использует итеративный метод оптимизации. Градиентный бустинг оптимизируется с помощью градиентного спуска.
Вывод
Ансамблевые модели являются мощным инструментом для анализа данных. Идея об объединении простых моделей, позволила делать лучшие прогнозы. Но всё же для построения прогнозов сначала необходимо применять более простые модели, потому что используя их можно добиться нужной точности. Если же результаты вас не устраивают, то можно применять ансамбли.
Помимо библиотеки scikit-learn в python есть библиотека XGBoost, которая предоставляет более обширный набор ансамблевых моделей с более точной реализацией.
Методы сбора ансамблей алгоритмов машинного обучения: стекинг, бэггинг, бустинг
Что такое ансамбли моделей?
Стекинг. Могут рассматриваться разнородные отдельно взятые модели. Существует мета-модель, которой на вход подаются базовые модели, а выходом является итоговый прогноз.
Бэггинг. Рассматриваются однородные модели, которые обучаются независимо и параллельно, а затем их результаты просто усредняются. Ярким представителем данного метода является случайный лес.
Бустинг. Рассматриваются однородные модели, которые обучаются последовательно, причем последующая модель должна исправлять ошибки предыдущей. Конечно, в качестве примера здесь сразу приходит на ум градиентный бустинг.
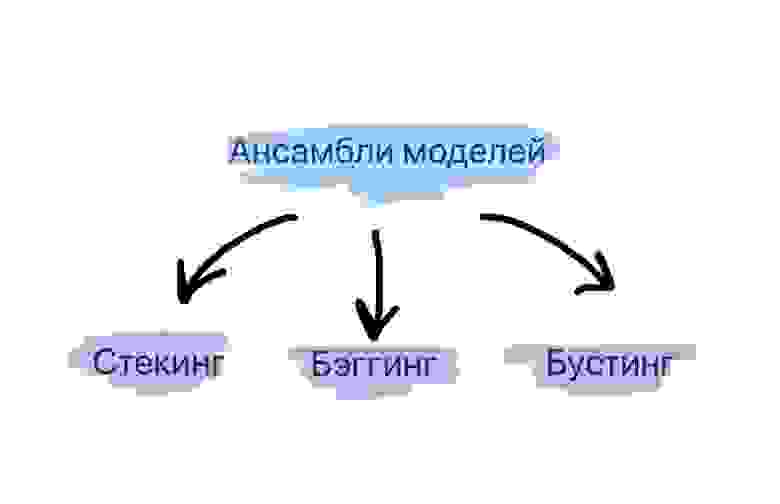 Рисунок 1
Рисунок 1
Три этих способа и будут детальнее рассмотрены далее.
Стекинг
Из трех вариантов стекинг является наименее популярным. Это можно проследить и по числу готовых реализаций данного метода в программных библиотеках. В том же sklearn.ensemble в python куда чаше используют AdaBoost, Bagging, GradientBoosting, чем тот же самый Stacking (хотя его реализация там тоже есть).
Стекинг выделяется двумя основными чертами: он может объединить в себе алгоритмы разной природы в качестве базовых. Например, взять метод опорных векторов (SVM), k-ближайших соседей (KNN) в качестве базовых и на основе их результатов обучить логистическую регрессию для классификации. Также стоит отметить непредсказуемость работы метамодели. Если в случае бэггинга и бустинга существует достаточно четкий и конкретный ансамблевый алгоритм (увидим далее), то здесь метамодель может с течением времени по-разному обучаться на входных данных.
Алгоритм обучения выглядит следующим образом (рис. 2):
Делим выборку на k фолдов (тот же смысл, что и в кросс-валидации).
Для объекта из выборки, который находится в k-ом фолде, делается предсказание слабыми алгоритмами, которые были обучены на k-1 фолдах. Этот процесс итеративен и происходит для каждого фолда.
Создается набор прогнозов слабых алгоритмов для каждого объекта выборки.
На сформированных низкоуровневыми алгоритмами прогнозах в итоге обучается метамодель.
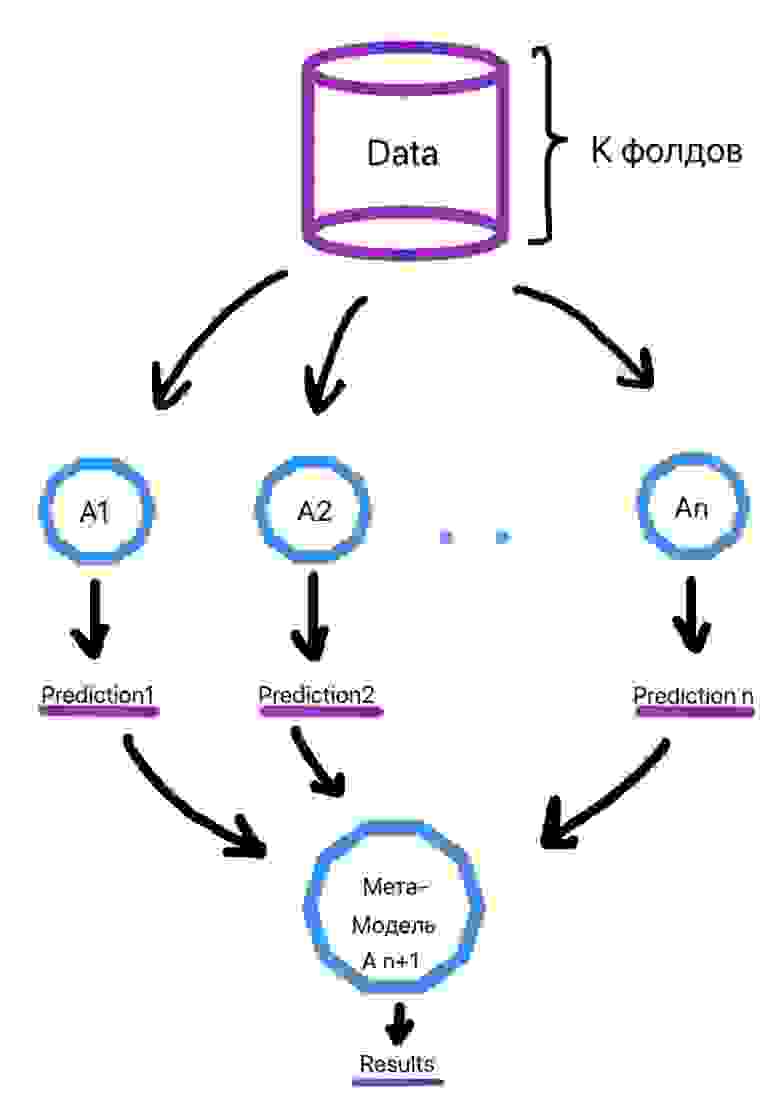 Рисунок 2
Рисунок 2
Ссылки на библиотеки для использования метода приведены ниже:
Бэггинг
Бэггинг является уже более популярным подходом и зачастую при упоминании этого термина вспоминается алгоритм построения случайного леса, как наиболее типичного его представителя.
При данном методе базовые алгоритмы являются представителями одного и того же семейства, они обучаются параллельно и почти независимо друг от друга, а финальные результаты лишь агрегируются. Нам необходимо, чтобы на вход слабым алгоритмам подавались разные данные, а не один и тот же набор, ведь тогда результат базовых моделей будет идентичен и смысла в них не будет.
0.632*n разных объектов. Таким образом, должны сформироваться m обучающих выборок для m слабых алгоритмов.
Бутстрэп выборки являются в значительной степени независимыми. Отчасти поэтому и говорят, что базовые алгоритмы обучаются на выборках независимо.
Что касается агрегации выходов базовых алгоритмов, то в случае задачи классификации зачастую просто выбирается наиболее часто встречающийся класс, а в случае задачи регрессии выходы алгоритмов усредняются (рис. 3). В формуле под ai подразумеваются выходы базовых алгоритмов.
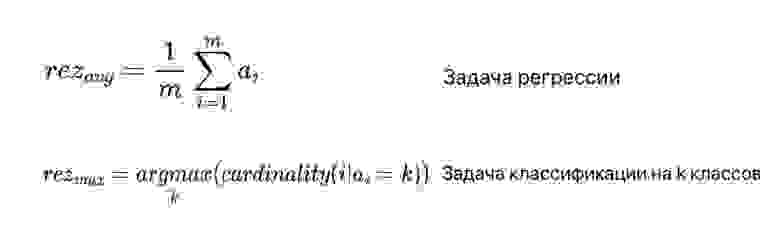 Рисунок 3
Рисунок 3
Общий процесс приведен на рисунке ниже (рис. 4):
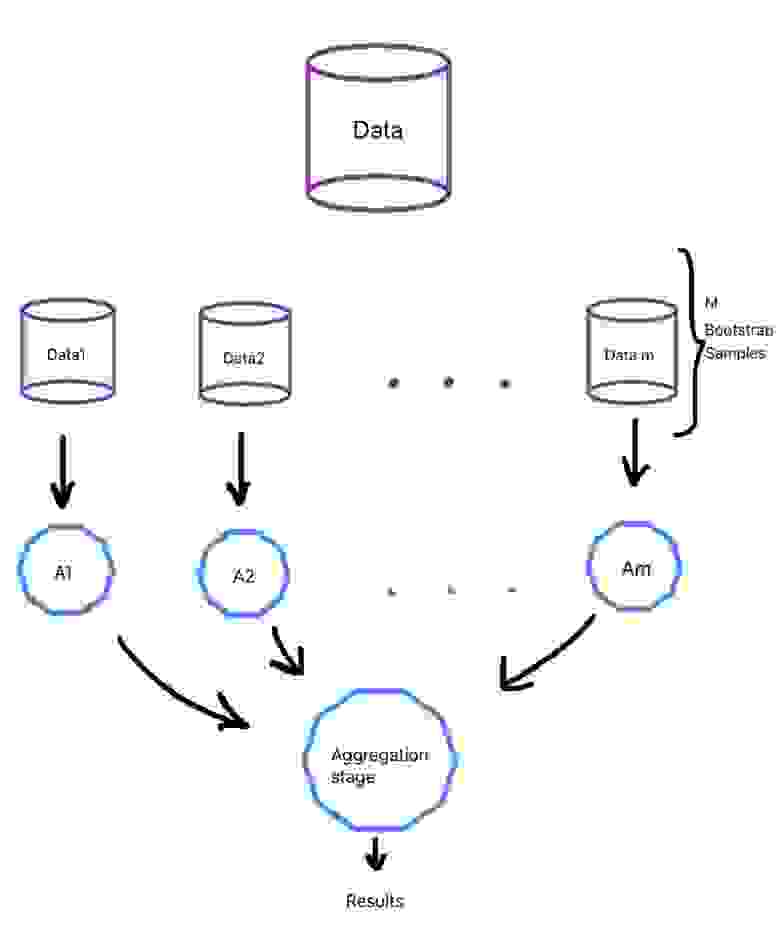 Рисунок 4
Рисунок 4
Случайный лес
 Рисунок 5
Рисунок 5
Ссылки на библиотеки для использования метода приведены ниже:
Бустинг
В данном случае, модели уже не обучаются отдельно друг от друга, а каждая следующая правит ошибки предыдущей. То есть можно сказать, что если один слабый алгоритм не смог выявить какую-либо закономерность в данных, так как это было для него сложно, то следующая модель должна сделать это. Но из данного подхода вытекает недостаток: работу алгоритма трудно распараллелить из-за зависимости предыдущего и последующего шагов.
Бустинг направлен скорее на уменьшение смещения в данных, чем на снижение разброса в них. Поэтому в качестве базовых алгоритмов могут браться модели с достаточно высоким смещением, например, неглубокие случайные деревья.
 Рисунок 6
Рисунок 6
Типичными представителями бустинга являются две модели: градиентный бустинг и AdaBoost. Обе по-разному решают одну и ту же оптимизационную задачу по поиску итоговой модели, представляющей собой взвешенную сумму слабых алгоритмов (рис. 6).
Градиентный бустинг использует типичный алгоритм градиентного спуска для решения задачи. Когда приходит время добавить новый слабый алгоритм в ансамбль делается следующее:
Находится оптимальный вектор сдвига, улучшающий предыдущий ансамбль алгоритмов.
Этот вектор сдвига является антиградиентом от функции ошибок работы предыдущего ансамбля моделей
Благодаря вектору сдвигов мы знаем, какие значения должны принимать объекты обучающей выборки
А поскольку нам надо найти очередной алгоритм в композиции, то находим тот, при использовании которого минимизируется отклонение ответов от истинных
Ссылки на библиотеки для использования метода приведены ниже:
Заключение
Таким образом, мы увидели, что для того, чтобы улучшить качество функционирования отдельно взятых моделей машинного обучения, существует ряд техник их объединения в ансамбли. Эти техники уже заложены в программные продукты и ими можно пользоваться, улучшая свое решение. Однако, с моей точки зрения, при решении задачи не стоит сразу же браться за них. Лучше сначала попробовать одну простую, отдельную модель, понять, как она функционирует на конкретных данных, а уже дальше использовать ансамбли.
Бэггинг (Bagging)

Бэггинг (Бутстрэп-агрегирование) – это алгоритм, предназначенный для улучшения стабильности и точности алгоритмов Машинного обучения (ML), используемых для задач Классификации (Classification) и Регрессии (Regression).
Прежде чем мы перейдем к основному понятию статьи, давайте кратко рассмотрим важный базовый прием Науки о данных (Data Science) – Бутстрап (Bootstrap).
Бутстрап – это мощный статистический метод оценки характеристик Признака (Feature) на основе Выборки (Sample). Мы поймем понятие, определив, является ли вычисленное Среднее арифметическое (Mean) или Стандартное отклонение (Standard Deviation) показательным с помощью этого метода.
Предположим, у нас есть выборка из массива данных на 100 значений, и мы хотим оценить, показательно ли среднее значение ее относительно Популяции (Population).
Мы можем вычислить среднее непосредственно классическим способом, разделив сумму значений на их количество:
Мы знаем, что наша выборка мала и среднее значение непоказательно. Улучшим оценку нашего среднего, используя бутстрэп:
Например, мы сформировали три выборки из популяции и получили средние значения 2.3, 4.5 и 3.3. Взяв среднее от этой троицы, получим наиболее правдивое значение 3,367. Этот прием можно использовать для оценки других величин, таких как стандартное отклонение, и даже величин, используемых в алгоритмах Машинного обучения.
Бутстрэп-агрегирование или бэггинг
Бэггинг – это простой и очень мощный ансамблевый метод, который объединяет прогнозы из нескольких методов Машинного обучения вместе, чтобы предсказывать более точно, чем любая отдельная модель.
Бутстрэп-агрегирование – это процедура, которая используется для сокращения чрезмерной дисперсии (Variance) алгоритмов – Деревьев решений (Decision Tree), таких как Алгоритм классификации и регрессии (CART).
Деревья решений чувствительны к конкретным данным, на которых обучаются. Если Тренировочные данные (Train Data) изменены (например, обучение производится на подмножестве), результирующее дерево может быть совершенно другим, и прогнозы могут быть совершенно разными для каждого такого подмножества.
Предположим, у нас есть набор из 1000 экземпляров, и мы используем алгоритм CART. Тогда бэггинг будет работать следующим образом:
Например, если бы у нас было 5 деревьев решений, которые использовали следующую выборку: синий, синий, красный, синий и красный, мы бы предсказали наиболее распространенный класс “синий”.
При бэггинге с деревьями решений мы меньше беспокоимся о том, чтобы отдельные деревья достигали Переобучения (Overfitting) обучающими данными. По этой причине и для повышения эффективности отдельные деревья решений выращиваются глубоко (например, несколько обучающих выборок в каждом листовом узле дерева), и деревья не обрезаются. Эти деревья будут иметь как высокую дисперсию, так и низкую погрешность. Это важные характеристики моделей при объединении прогнозов.
Единственные параметры при объединении деревьев решений – это количество выборок и, следовательно, количество включаемых деревьев. До тех пор, пока точность не прекратит улучшаться, можно тренировать новые и новые деревья. Большое число моделей потребует времени, но переобучения не будет.
Как и сами деревья решений, Bagging можно использовать для задач классификации и регрессии.
Случайный лес
Случайные леса (Random Forest) являются апгрейдом деревьев решений с бэггингом.
Проблема с деревьями решений, такими как CART, заключается в жадности: они выбирают, какую переменную использовать, используя “жадный” алгоритм, сводящий к минимуму ошибки. Таким образом, даже при использовании бэггинга деревья решений могут иметь много структурных сходств и, в свою очередь, иметь высокую корреляцию в своих прогнозах.
Объединение прогнозов из нескольких моделей в ансамбли способствует взрывному росту эффективности, если прогнозы из подмоделей некоррелированы или в лучшем случае слабо коррелированы.
Случайный лес изменяет алгоритм способа обучения поддеревьев, так что результирующие прогнозы из всех их имеют меньшую корреляцию.
В CART при выборе точки разделения алгоритму разрешено просматривать все переменные и их значения, чтобы выбрать наиболее оптимальную точку разделения. Алгоритм случайного леса изменяет эту процедуру таким образом, чтобы ограничиваться случайной выборкой функций, по которым выполняется поиск.
Количество признаков, которые могут быть найдены в каждой точке разделения, должно быть указано в качестве параметра алгоритма. Вы можете попробовать разные значения и настроить их с помощью Кросс-валидации (Cross Validation):
m – количество случайно выбранных объектов, которые можно искать в точке разделения,
p – количество входных переменных.
Например, если в наборе данных было 25 входных переменных для задачи классификации, то:
Расчетная производительность
Когда выборка сформирована, всегда найдутся наблюдения, не попавшие в нее. Эти записи называются Out-Of-Bag или OOB.
Производительность каждой модели на ее OOB-наблюдениях при усреднении может обеспечить некую точность бэггинг-моделей. Эту оценку производительности часто называют оценкой производительности OOB.
Эти показатели производительности представляют собой надежную оценку ошибки тестирования и хорошо коррелируют с оценками перекрестной проверки.
Бэггинг и Scikit-learn
Бэггинг легко продемонстрировать с помощью соответствующей функции Scikit-learn. Для начала импортируем необходимые библиотеки:
Сгенерируем набор данных из 100 наблюдений и 4 признаков случайным образом:
Применим Метод опорных векторов (SVM) в качестве метода оценки бэггинга:
Предскажем класс для наблюдения:
Для записи, где каждый из четырех признаков равен нулю, класс будет равен единице:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Ансамблевые методы: бэггинг, бустинг и стекинг
«Единство это сила». Эта старая поговорка довольно хорошо выражает основную идею, за которой стоят очень мощные «ансамблевые методы» в машинном обучении. Ансамблевые методы часто занимают топ рейтингов во многих соревнованиях по машинному обучению, в том числе на Kaggle. Если говорить грубо, они основаны на гипотезе о том, что объединение нескольких моделей воедино часто может привести к созданию гораздо более мощной модели.
Цель этой статьи — объяснение различных понятий ансамблевого обучения. Мы обсудим некоторые общеизвестные понятия, такие как бутстрэп, бэггинг, случайный лес, бустинг, стекинг и многие другие, которые являются основами ансамблевых методов. Чтобы сделать связь между всеми этими методами как можно более ясной, мы постараемся представить их в гораздо более широкой и логичной структуре, которую, мы надеемся, будет легче понять и запомнить.
План
В первом разделе этой статьи мы представим понятия слабых и сильных учеников и представим три основных метода обучения в ансамбле: бэггинг, бустинг и стекинг. Затем во втором разделе мы сфокусируем внимание на бэггинге и обсудим такие понятия, как бутстрэп, бэггинг и случайный лес. В третьем разделе мы представим бустинг и, в частности, два его самых популярных варианта: адаптивный бустинг (adaboost) и градиентный бустинг. Наконец, в четвертом разделе мы дадим обзор стекинга.
Что такое ансамблевые методы?
Ансамблевые методы — это парадигма машинного обучения, где несколько моделей (часто называемых «слабыми учениками») обучаются для решения одной и той же проблемы и объединяются для получения лучших результатов. Основная гипотеза состоит в том, что при правильном сочетании слабых моделей мы можем получить более точные и/или надежные модели.
Один слабый ученик
В машинном обучении, независимо от того, сталкиваемся ли мы с проблемой классификации или регрессии, выбор модели чрезвычайно важен, чтобы иметь какие-либо шансы получить хорошие результаты. Этот выбор может зависеть от многих переменных задачи: количества данных, размерности пространства, гипотезы распределения…
Слабое смещение (bias) и разброс (variance) модели, хотя они чаще всего изменяются в противоположных направлениях, являются двумя наиболее фундаментальными особенностями, ожидаемыми для модели. Действительно, чтобы иметь возможность «решить» проблему, мы хотим, чтобы в нашей модели было достаточно степеней свободы для разрешения базовой сложности данных, с которыми мы работаем, но мы также хотим, чтобы у нее было не слишком много степеней свободы, чтобы избежать ее высокого разброса и быть более устойчивой. Это хорошо известный компромисс между смещением и разбросом.
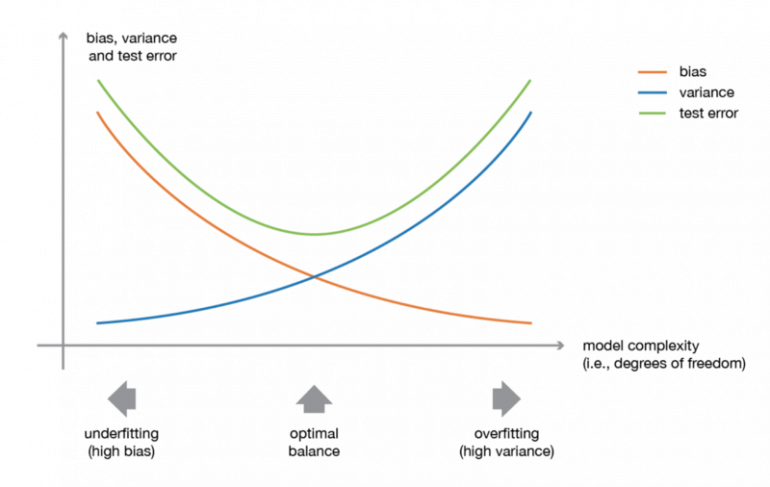
Иллюстрация компромисса между смещением и разбросом
В ансамблевой теории обучения мы вводим понятия слабых учеников (или базовых моделей), которых можно использовать в качестве строительных блоков для проектирования более сложных моделей путем объединения нескольких из них. В большинстве случаев эти базовые модели работают сами по себе не так хорошо в связи с тем, что они имеют высокое смещение (например, модели с низкой степенью свободы), либо с тем, что имеют слишком большой разброс, чтобы быть устойчивыми (например, модели с высокой степенью свободы). Тогда идея ансамблевых методов состоит в том, чтобы попытаться уменьшить смещение и/или разброс таких слабых учеников, объединяя несколько из них вместе, чтобы создать сильного ученика (или модель ансамбля), который достигает лучших результатов.
Объединение слабых учеников
Чтобы реализовать ансамблевый метод, нам сначала нужно отобрать наших слабых учеников для агрегирования. В основном (в том числе в хорошо известных методах бэггинга и бустинга) используется единственный базовый алгоритм обучения, так что у нас есть однородные слабые ученики, которые обучаются по-разному. Получаемая нами модель ансамбля называется «однородной». Тем не менее, существуют также некоторые методы, которые используют различные типы базовых алгоритмов обучения: некоторые разнородные слабые ученики затем объединяются в «разнородную ансамблевую модель».
Одним из важных моментов является то, что наш выбор слабых учеников должен быть согласован с тем, как мы агрегируем эти модели. Если мы выбираем слабых учеников с низким смещением, но высоким разбросом, это должно быть с помощью метода агрегирования, который имеет тенденцию уменьшать разброс, тогда как если мы выбираем слабых учеников с низким разбросом, но с высоким смещением, это должен быть метод агрегирования, который имеет тенденцию уменьшать смещение.
Это подводит нас к вопросу о том, как комбинировать эти модели. Мы можем упомянуть три основных типа мета-алгоритмов, которые направлены на объединение слабых учеников:
Грубо говоря, мы можем сказать, что бэггинг будет в основном сосредоточен на получении ансамблевой модели с меньшим разбросом, чем ее компоненты, в то время как бустинг и стекинг в основном будут пытаться производить сильные модели с меньшим смещением, чем их компоненты.
В следующих разделах мы подробно расскажем о бэггинге и бустинге (которые используются немного шире, чем стекинг, и позволят нам обсудить некоторые ключевые понятия ансамблевых методов), прежде чем дать краткий обзор стекинга.
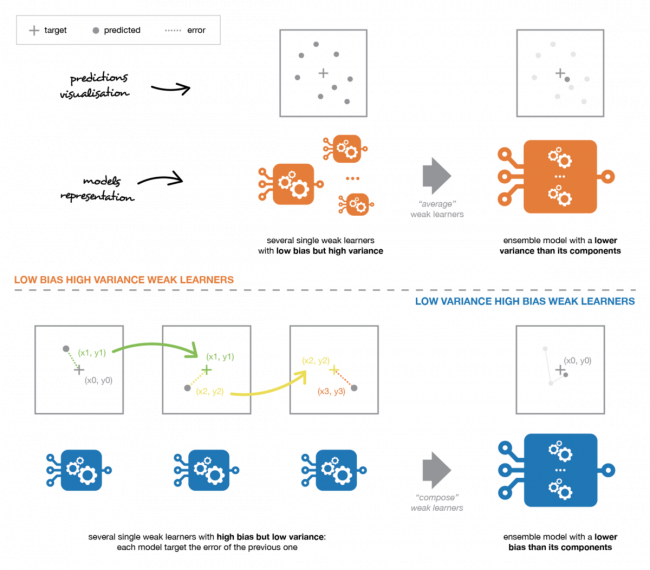
Слабых учеников можно объединить, чтобы получить модель с лучшими показателями. Способ объединения базовых моделей должен быть адаптирован к их типам. Модели с низким смещением и высоким разбросом следует объединять таким образом, чтобы сделать сильную модель более устойчивой, тогда как модели с низким разбросом и высоким смещением лучше объединять таким образом, чтобы сделать ансамблевую модель менее смещенной.
Сфокусируем внимание на бэггинге
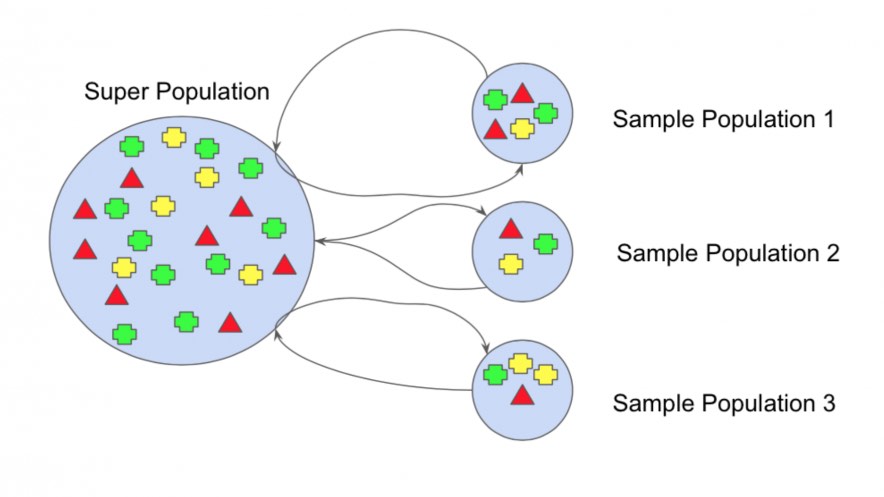
В параллельных методах мы рассматриваем разных учеников независимо друг от друга друга и, таким образом, можно обучать их одновременно. Наиболее известным из таких подходом является «бэггинг» (от «bootstrap aggregation»), целью которого является создание ансамблевой модели, которая является более надежной, чем отдельные модели, ее составляющие.
Бутстрэп
Давайте начнем с определения бутстрэпа. Этот статистический метод заключается в генерации выборок размера B (так называемых бутстрэп выборок) из исходного датасета размера N путем случайного выбора элементов с повторениями в каждом из наблюдений B.
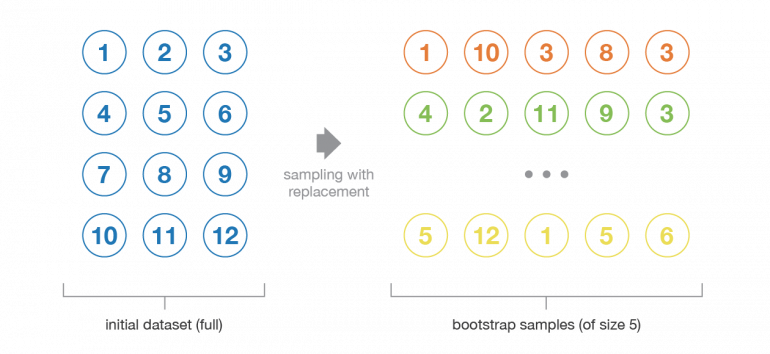 Иллюстрация процесса бустрэпа
Иллюстрация процесса бустрэпа
При некоторых допущениях эти выборки имеют довольно хорошие статистические свойства: в первом приближении их можно рассматривать как взятые непосредственно из истинного базового (и часто неизвестного) распределения данных, так и независимо друг от друга. Таким образом, их можно рассматривать как репрезентативные и независимые выборки истинного распределения данных (почти идентичные выборки). Гипотеза, которая должна быть проверена, чтобы сделать это приближение действительным, имеет две стороны. Во-первых, размер N исходного датасета должен быть достаточно большим, чтобы охватить большую часть сложности базового распределения, чтобы выборка из датасета была хорошим приближением к выборке из реального распределения (репрезентативность). Во-вторых, размер датасета N должен быть достаточно большим по сравнению с размером бутстрэп выборок B, чтобы выборки не слишком сильно коррелировали (независимость). Обратите внимание, что в дальнейшем мы иногда будем ссылаться на эти свойства (репрезентативность и независимость) бутстрэп выборок: читатель всегда должен помнить, что это только приближение.
Бутстрэп выборки часто используются, например, для оценки разброса или доверительных интервалов статистических оценок. По определению статистическая оценка является функцией некоторых наблюдений и, следовательно, случайной величины с разбросом, полученным из этих наблюдений. Чтобы оценить разброс такой оценки, нам нужно оценить его на нескольких независимых выборках, взятых из интересующего распределения. В большинстве случаев рассмотрение действительно независимых выборок потребовало бы слишком большого количества данных по сравнению с реально доступным количеством. Затем мы можем использовать бутстрэп, чтобы сгенерировать несколько бутстрэп выборок, которые можно рассматривать как «почти репрезентативные» и «почти независимые» (почти «независимые одинаково распределенные выборки»). Эти примеры бутстрэп выборок позволят нам аппроксимировать разброс оценки, оценивая его значение для каждой из них.
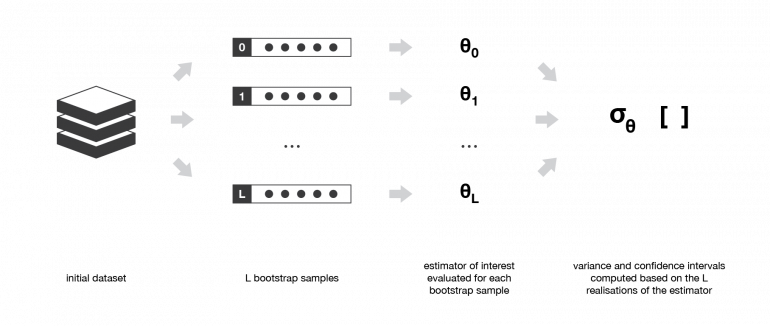 Бутстрэп часто используется для оценки разброса или доверительного интервала некоторых статистических оценок
Бутстрэп часто используется для оценки разброса или доверительного интервала некоторых статистических оценок
Бэггинг
При обучении модели, независимо от того, имеем ли мы дело с
проблемой классификации или регрессии, мы получаем функцию, которая принимает входные данные, возвращает выходные данные и определяется в отношении обучающего датасета. Из-за теоретического разброса обучающего датасета (мы напоминаем, что датасет является наблюдаемой выборкой, исходящей из истинно неизвестного базового распределения), подобранная модель также подвержена изменчивости: если бы наблюдался другой датасет, мы получили бы другую модель.
Идея бэггинга в таком случае проста: мы хотим подобрать несколько независимых моделей и «усреднить» их прогнозы, чтобы получить модель с меньшим разбросом. Однако на практике мы не можем подобрать полностью независимые модели, потому что для этого потребуется слишком много данных. Таким образом, мы полагаемся на хорошие «приблизительные свойства» бутстрэп выборок (репрезентативность и независимость) для подбора моделей, которые практически независимы.
Сначала мы генерируем несколько бутстрэп выборок так, чтобы каждая новая бутстрэп выборка выполняла роль (почти) еще одного независимого датасета, взятого из истинного распределения. Затем мы можем обучить слабого ученика для каждой из этих выборок и, наконец, агрегировать их так, чтобы мы как бы «усреднили» их результаты и, таким образом, получили модель ансамбля с разбросом меньшим, чем ее отдельные компоненты. Грубо говоря, так как бутстрэп выборки являются примерно независимыми и одинаково распределенными, то же самое касается и обученных слабых учеников. Затем «усреднение» результатов слабых учеников не изменяет ожидаемый ответ, но уменьшает его разброс (так же, как усреднение независимых одинаково распределенных случайных величин сохраняет ожидаемое значение, но уменьшает разброс).
Итак, предположим, что у нас есть L бутстрап выборок (аппроксимации L независимых датасетов) размера B. Это обозначается:
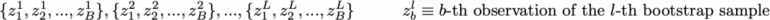
Мы можем обучить L почти независимых слабых учеников (по одному на каждый датасет):
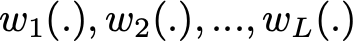
А затем объединим их некоторым процессом усреднения, чтобы получить модель ансамбля с меньшим разбросом. Например, мы можем определить нашу сильную модель так, чтобы
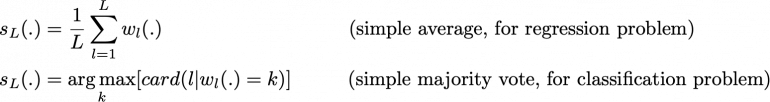
Существует несколько возможных способов объединить несколько моделей, обученных параллельно. Для задачи регрессии выходные данные отдельных моделей могут быть буквально усреднены для получения выходных данных модели ансамбля. Для задачи классификации класс, предсказываемый каждой моделью, можно рассматривать как голос, а класс, который получает большинство голосов, является ответом модели ансамбля (это называется мажоритарным голосованием). Что касается задачи классификации, мы также можем рассмотреть вероятности каждого класса, предсказываемые всеми моделями, усреднить эти вероятности и сохранить класс с самой высокой средней вероятностью (это называется мягким голосованием). Средние значения или голоса могут быть простыми или взвешенными, если будут использоваться любые соответствующие им веса.
Наконец, мы можем упомянуть, что одним из больших преимуществ бэггинга является его параллелизм. Поскольку различные модели обучаются независимо друг от друга, при необходимости могут использоваться методы интенсивного распараллеливания.
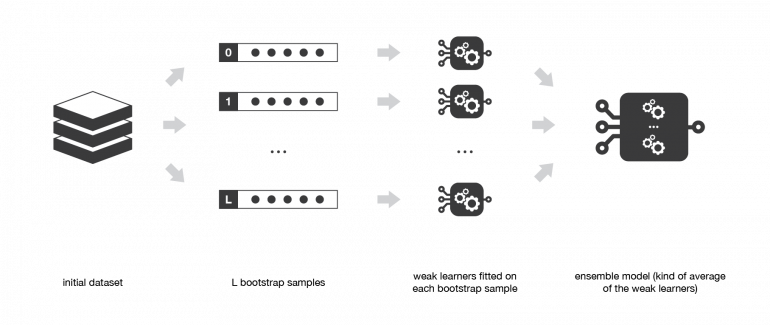 Бэггинг состоит из нескольких базовых моделей, обученных на разных бутстрэп выборках и построения ансамблевой модели, которая «усредняет» результаты этих слабых учеников
Бэггинг состоит из нескольких базовых моделей, обученных на разных бутстрэп выборках и построения ансамблевой модели, которая «усредняет» результаты этих слабых учеников
Случайные леса
Деревья решений являются очень популярными базовыми моделями для ансамблевых методов. Сильные ученики, состоящие из нескольких деревьев решений, можно назвать «лесами». Деревья, составляющие лес, могут быть выбраны либо неглубокими (глубиной в несколько узлов), либо глубокими (глубиной в множество узлов, если не в полную глубину со всеми листьями). Неглубокие деревья имеют меньший разброс, но более высокое смещение, и тогда для них лучшим выбором станут последовательные методы, которые мы опишем позже. Глубокие деревья, с другой стороны, имеют низкое смещение, но высокий разброс и, таким образом, являются подходящим выбором для бэггинга, который в основном направлен на уменьшение разброса.
Случайный лес представляет собой метод бэггинга, где глубокие деревья, обученные на бутстрап выборках, объединяются для получения результата с более низким разбросом. Тем не менее, случайные леса также используют другой прием, чтобы несколько обученных деревьев были менее коррелированными друг с другом: при построении каждого дерева вместо выбора всех признаков из датасета для генерации бутстрэпа мы выбираем и сохраняем только случайное их подмножество для построения дерева (обычно одинаковое для всех бутстрэп выборок).
Выборка по признакам действительно приводит к тому, что все деревья не смотрят на одну и ту же информацию для принятия своих решений и, таким образом, уменьшают корреляцию между различными возвращаемыми выходными данными. Другое преимущество выборки по признакам заключается в том, что она делает процесс принятия решений более устойчивым к отсутствующим данным: значения наблюдения (из обучающего датасета или нет) с отсутствующими данными можно восстанавливать с помощью регрессии или классификации на основе деревьев, которые учитывают только те признаки, где данные не отсутствуют. Таким образом, алгоритм случайного леса сочетает в себе концепции бэггинга и выбора подпространства случайных объектов для создания более устойчивых моделей.
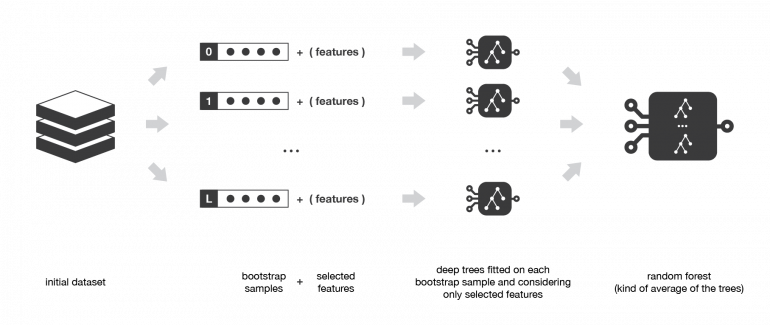 Метод случайного леса — это метод бэггинга с деревьями решений в качестве слабых учеников. Каждое дерево помещается в бутстрэп выборку, только с учетом случайного выбора подмножества признаков.
Метод случайного леса — это метод бэггинга с деревьями решений в качестве слабых учеников. Каждое дерево помещается в бутстрэп выборку, только с учетом случайного выбора подмножества признаков.
Сфокусируем внимание на бустинге
В последовательных методах различные комбинированные слабые модели больше не обучаются независимо друг от друга. Идея состоит в том, чтобы итеративно обучать модели таким образом, чтобы обучение модели на данном этапе зависело от моделей, обученных на предыдущих этапах. Бустинг является наиболее известным из этих подходов, и он создает ансамблевую модель, которая имеет меньшее смещение, чем составляющие ее слабые ученики.
Бустинг
Методы бустинга работают в том же духе, что и методы бэггинга: мы создаем семейство моделей, которые объединяются, чтобы получить сильного ученика, который лучше работает. Однако, в отличие от бэггинга, которое в основном направлено на уменьшение разброса, бустинг — это метод, который заключается в том, чтобы адаптировать последовательно нескольких слабых учеников адаптивным способом: каждая модель в последовательности подбирается, что придает большее значение объектам в датасете, которые плохо обрабатывались предыдущими моделями в последовательности. Интуитивно, каждая новая модель фокусирует свои усилия на самых сложных объектах выборки при обучении предыдущих моделей, чтобы мы получили в конце процесса сильного ученика с более низким смещением (даже если получится так, что бустинг будет при этом уменьшать разброс). Бустинг, как и бэггинг, может использоваться как для задач регрессии, так и для классификации.
Базовые модели, которые часто рассматриваются для бустинга — это модели с низким разбросом, но с высоким смещением. Например, если мы хотим использовать деревья решений в качестве наших базовых моделей, в основном мы будем выбирать неглубокие деревья решений с глубиной в несколько узлов. Другая важная причина, которая мотивирует использовать модели с низким разбросом, но с высоким смещением в качестве слабых учеников для бустинга, заключается в том, что эти модели, как правило, требуют меньших вычислительных затрат (несколько степеней свободы при подборе гиперпараметров). Действительно, поскольку вычисления для подгонки к различным моделям не могут выполняться параллельно (в отличие от бэггинга), это может стать слишком дорогостоящим для последовательного подбора нескольких сложных моделей.
После того, как слабые ученики выбраны, нам все еще нужно определить, как они будут последовательно подгоняться (какую информацию из предыдущих моделей мы учитываем при подборе текущей модели?) И как они будут агрегироваться (как мы агрегируем текущую модель к предыдущим?). Мы обсудим эти вопросы в двух следующих подразделах, более подробно описывающих два важных алгоритма бустинга: adaboost (адаптивный бустинг) и градиентный бустинг.
В двух словах, эти два мета-алгоритма отличаются тем, как они создают и объединяют слабых учеников в ходе последовательного процесса. Адаптивный бустинг обновляет веса, прикрепленные к каждому из объектов обучающего датасета, тогда как градиентный бустинг обновляет значения этих объектов. Эта разница исходит из того, что оба метода пытаются решить задачу оптимизации, заключающуюся в поиске наилучшей модели, которая может быть записана в виде взвешенной суммы слабых учащихся.
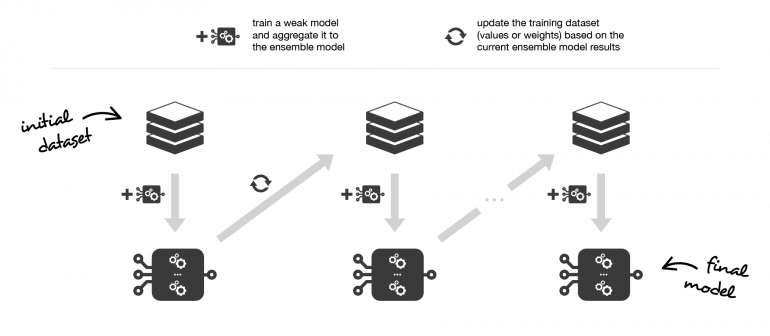 Бустинг состоит в итеративном подборе слабого ученика, агрегировании его в модель ансамбля и «обновлении» обучающего датасета для лучшего учета сильных и слабых сторон текущей модели ансамбля при подборе следующей базовой модели.
Бустинг состоит в итеративном подборе слабого ученика, агрегировании его в модель ансамбля и «обновлении» обучающего датасета для лучшего учета сильных и слабых сторон текущей модели ансамбля при подборе следующей базовой модели.
Адаптивный бустинг
При адаптивном бустинге («adaboost») мы пытаемся определить нашу ансамблевую модель как взвешенную сумму L слабых учеников.
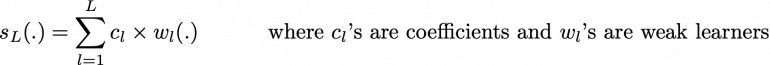
Поиск лучшей модели ансамбля с этой формой записи ансамблевой модели является сложной задачей оптимизации. Вместо того, чтобы пытаться решить ее за один раз аналитически (находя все коэффициенты и слабых учеников, которые дают лучшую общую аддитивную модель), мы используем итеративный процесс оптимизации, который гораздо более податлив, даже несмотря на то что он может привести к неоптимальному решению. В частности, мы добавляем слабых учеников одного за другим, просматривая каждую итерацию, чтобы найти наилучшую возможную пару (коэффициент, слабый ученик) для добавления к текущей модели ансамбля. Другими словами, мы итеративно определяем (s_l), как
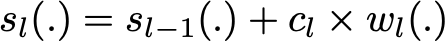
где c_l и w_l выбраны так, что s_l — это модель, которая наилучшим образом соответствует обучающим данным, и, таким образом, это наилучшее возможное улучшение по сравнению с s_(l-1). Затем мы можем определить
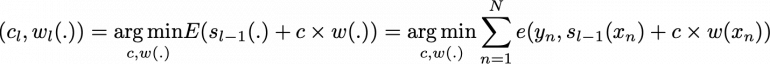
где E(.) — ошибка подгонки данной модели, а e(. ) — функция потерь/ошибок. Таким образом, вместо глобальной оптимизации по всем L-моделям в сумме, мы приближаем оптимум локальной оптимизацией путем построения и добавления слабых учеников к сильной модели по одному.
В частности, при рассмотрении бинарной классификации мы можем показать, что алгоритм adaboost может быть переписан в процесс, который выполняется следующим образом. Во-первых, он обновляет веса объектов в датасете и обучает нового слабого ученика, уделяя особое внимание наблюдениям, неправильно классифицированным текущей ансамблевой моделью. Во-вторых, он добавляет слабого ученика к взвешенной сумме в соответствии с коэффициентом обновления, который выражает эффективность этой слабой модели: чем лучше слабый ученик выполнил свою работу, тем больше он будет учтен в сильном ученике.
Итак, предположим, что мы сталкиваемся с задачей бинарной классификации с N объектами в нашем датасете, и мы хотим использовать алгоритм adaboost с данным семейством слабых моделей. В самом начале алгоритма (первая модель последовательности) все объекты имеют одинаковые веса 1 / N. Затем мы повторяем L раз (для L учеников в последовательности) следующие шаги:
Повторяя эти шаги, мы затем последовательно строим наши L моделей и объединяем их в простую линейную комбинацию, взвешенную по коэффициентам, выражающим эффективность каждого ученика. Обратите внимание, что существуют варианты исходного алгоритма adaboost, такие как LogitBoost (классификация) или L2Boost (регрессия), которые в основном различаются по своему выбору функции потерь.
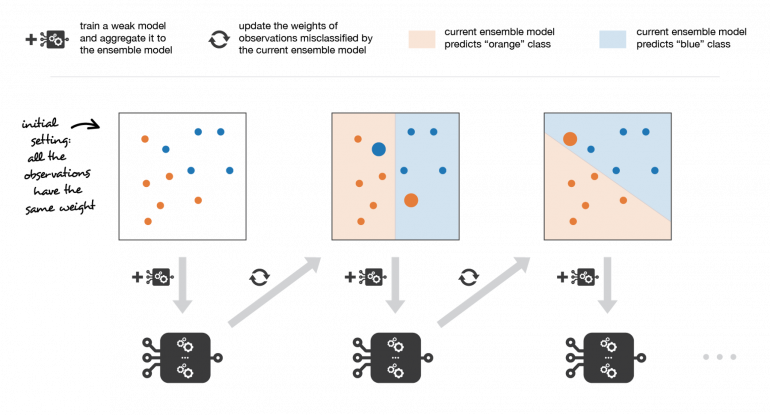
Adaboost обновляет веса объектов на каждой итерации. Веса хорошо классифицированных объектов уменьшаются относительно весов неправильно классифицированных объектов. Модели, которые работают лучше, имеют больший вес в окончательной модели ансамбля.
Градиентный бустинг
При градиентном бустинге модель ансамбля, которую мы пытаемся построить, также представляет собой взвешенную сумму слабых учеников.
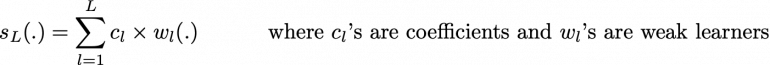
Как мы уже упоминали для adaboost, найти оптимальную модель при этой форме записи модели ансамбля слишком сложно, и требуется итерационный подход. Основное отличие от адаптивного бустинга заключается в определении процесса последовательной оптимизации. Кто бы мог подумать, градиентный бустинг сводит задачу к градиентному спуску: на каждой итерации мы подгоняем слабого ученика к антиградиенту текущей ошибки подбора по отношению к текущей модели ансамбля. Попробуем прояснить этот последний момент. Во-первых, теоретический процесс градиентного спуска по ансамблевой модели может быть записан как
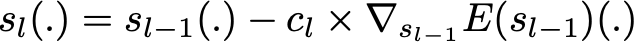
где E (.) — ошибка подгонки данной модели, c_l — коэффициент, соответствующий размеру шага, и
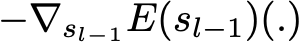
является антиградиентом ошибки подгонки относительно модели ансамбля на шаге l_1. Этот (довольно абстрактный) антиградиент является функцией, которая на практике может оцениваться только для объектов в обучающей выборке (для которой мы знаем входные и выходные данные): эти оценки называются псевдо-остатками, прикрепленными к каждому объекту. Более того, даже если мы знаем для наблюдений значения этих псевдо-остатков, мы не хотим добавлять в нашу модель ансамбля какую-либо функцию: мы хотим добавить только новый экземпляр слабой модели. Таким образом, естественная вещь, которую нужно сделать, это научитьслабого ученика псевдо-остаткам для каждого наблюдения. Наконец, коэффициент c_l вычисляется в соответствии с одномерным процессом оптимизации (линейный поиск для получения наилучшего размера шага c_l).
Итак, предположим, что мы хотим использовать градиентный бустинг с семейством слабых моделей. В самом начале алгоритма (первая модель последовательности) псевдо-остатки устанавливаются равными значениям объектов. Затем мы повторяем L раз (для L моделей последовательности) следующие шаги:
Повторяя эти шаги, мы последовательно строим наши L моделей и агрегируем их в соответствии с подходом градиентного спуска. Обратите внимание на то, что, хотя адаптивный бустинг пытается решить на каждой итерации именно «локальную» задачу оптимизации (найти лучшего слабого ученика и его коэффициент, который нужно добавить к сильной модели), градиентный бустинг использует вместо этого подход с градиентным спуском и его легче адаптировать к большому количеству функций потерь. Таким образом, градиентный бустинг можно рассматривать как обобщение adaboost для произвольных дифференцируемых функций потерь.
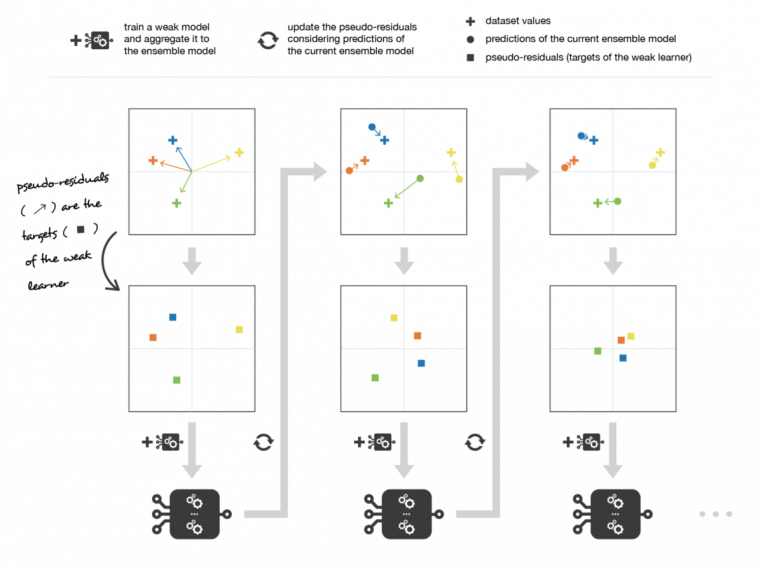 Градиентный бустинг обновляет значения наблюдений на каждой итерации. Слабых учеников обучают подгоняться под псевдо-остатки, которые указывают, в каком направлении корректировать прогнозы текущей модели ансамбля, чтобы снизить ошибку.
Градиентный бустинг обновляет значения наблюдений на каждой итерации. Слабых учеников обучают подгоняться под псевдо-остатки, которые указывают, в каком направлении корректировать прогнозы текущей модели ансамбля, чтобы снизить ошибку.
Обзор стекинга
Стекинг имеет два основных отличия от бэггинга и бустинга. Во-первых, стекинг часто учитывает разнородных слабых учеников (комбинируются разные алгоритмы обучения), тогда как бэггинг и бустинг учитывают в основном однородных слабых учеников. Во-вторых, стекинг учит объединять базовые модели с использованием метамодели, тогда как бэггинг и бустинг объединяют слабых учеников с помощью детерминистическим алгоритмам.
Стекинг
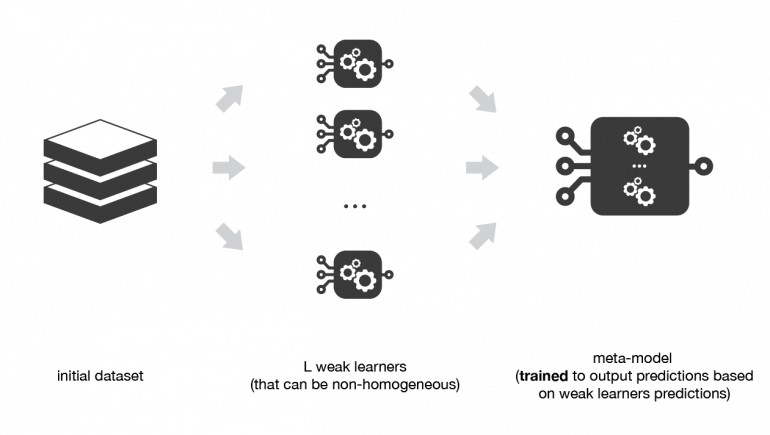
Как мы уже упоминали, идея стекинга состоит в том, чтобы выучить нескольких разных слабых учеников и объединить их, обучив метамодель для вывода предсказаний, основанных на множественных предсказаниях, возвращаемых этими слабыми моделями. Итак, нам нужно определить две вещи для построения нашей модели стека: L учеников, которых мы хотим обучить, и метамодель, которая их объединяет.
Например, для задачи классификации мы можем в качестве слабого ученика выбрать классификатор KNN, логистическую регрессию и SVM и принять решение обучить нейронную сеть в качестве метамодели. Затем нейронная сеть примет в качестве входных данных результаты трех наших слабых учеников и научится давать окончательные прогнозы на их основе.
Итак, предположим, что мы хотим обучить стековый ансамбль, составленный из L слабых учеников. Затем мы должны выполнить следующие шаги:
На предыдущих этапах мы разбили датасет на две части, потому что прогнозы данных, которые использовались для обучения слабых учеников, не имеют отношения к обучению метамодели. Таким образом, очевидным недостатком этого разделения нашего датасета на две части является то, что у нас есть только половина данных для обучения базовых моделей и половина данных для обучения метамодели. Чтобы преодолеть это ограничение, мы можем, однако, следовать некоторому подходу «k-fold кросс-обучение» (аналогичному тому, что делается в k-fold кросс-валидации), таким образом все объекты могут быть использованы для обучения мета-модели: для любого объекта предсказание слабых учеников делается на примерах этих слабых учеников, обученных на k-1 фолдах, которые не содержат рассматриваемого объекта. Другими словами, он обучается по k-1 фолдам, чтобы делать прогнозы для оставшегося фолда для объектов в любых фолдах. Таким образом, мы можем создать соответствующие прогнозы для каждого объекта нашего датасета, а затем обучить нашу метамодель всем этим прогнозам.
 Стекинг состоит в обучении метамодели для получения результатов, основанных на результатах, полученных несколькими слабыми учениками нижнего уровня
Стекинг состоит в обучении метамодели для получения результатов, основанных на результатах, полученных несколькими слабыми учениками нижнего уровня
Многоуровневый стекинг
Возможное расширение стекинга — многоуровневый стекинг. Он заключается в выполнении стекинга с несколькими слоями. В качестве примера давайте рассмотрим стекинг в 3 уровня. На первом уровне (слое) мы подходим к L слабым ученикам, которые были выбраны. Затем на втором уровне вместо обучения одной метамодели к прогнозам слабых моделей (как это было описано в предыдущем подразделе) мы обучаем М таких метамоделей. Наконец, на третьем уровне мы обучаем последнюю метамодель, которая принимает в качестве входных данных прогнозы, возвращаемые М метамоделями предыдущего уровня.
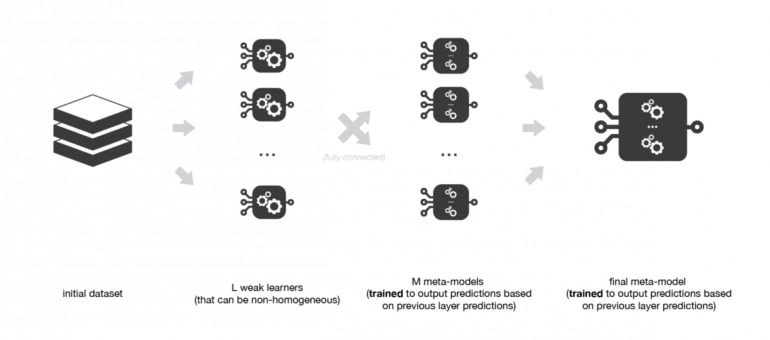 Многоуровневый стекинг предполагает несколько уровней стекинга: некоторые метамодели обучаются на выходных данных, возвращаемых метамоделями более низкого уровня, и так далее. Здесь мы представили 3-х слойную модель стекинга.
Многоуровневый стекинг предполагает несколько уровней стекинга: некоторые метамодели обучаются на выходных данных, возвращаемых метамоделями более низкого уровня, и так далее. Здесь мы представили 3-х слойную модель стекинга.
Итоги
Основные выводы этой статьи следующие:
В этой статье мы дали базовый обзор ансамблевых методов и, в частности, некоторых основных понятий в этой области: бутстрэп, бэггинг, случайный лес, бустинг (adaboost, градиентный бустинг) и стекинг. Среди оставленных в стороне понятий можно упомянуть, например, метод оценки Out-Of-Bag для бэггинга или также очень популярный «XGBoost» (что означает eXtrem Gradient Boosting), который является библиотекой, реализующей методы градиентного бустинга вместе с множеством дополнительных трюков, которые делают обучение намного более эффективным (и пригодным для больших датасетов).
Наконец, мы хотели бы в заключение напомнить, что обучение ансамблей — это объединение некоторых базовых моделей для получения модели ансамбля с лучшими характеристиками. Таким образом, даже если бэггинг, бустинг и стекинг являются наиболее часто используемыми ансамблевыми методами, возможны варианты, которые могут быть разработаны для лучшей адаптации к некоторым конкретным проблемам. В основном это требует двух вещей: полностью понять проблему, с которой мы сталкиваемся и… проявить творческий подход!



