Дерево
Дерево – структура данных, представляющая собой древовидную структуру в виде набора связанных узлов.
Способ представления бинарного дерева: 
Корень дерева расположен на уровне с минимальным значением.
Если элемент не имеет потомков, он называется листом или терминальным узлом дерева.
Остальные элементы – внутренние узлы (узлы ветвления).
Бинарное дерево применяется в тех случаях, когда в каждой точке вычислительного процесса должно быть принято одно из двух возможных решений.
Имеется много задач, которые можно выполнять на дереве.
Распространенная задача — выполнение заданной операции p с каждым элементом дерева. Здесь p рассматривается как параметр более общей задачи посещения всех узлов или задачи обхода дерева.
Если рассматривать задачу как единый последовательный процесс, то отдельные узлы посещаются в определенном порядке и могут считаться расположенными линейно.
Способы обхода дерева
Пусть имеем дерево, где A — корень, B и C — левое и правое поддеревья.

Существует три способа обхода дерева:
Реализация дерева
Узел дерева можно описать как структуру:
При этом обход дерева в префиксной форме будет иметь вид
Обход дерева в инфиксной форме будет иметь вид
Обход дерева в постфиксной форме будет иметь вид
Бинарное (двоичное) дерево поиска – это бинарное дерево, для которого выполняются следующие дополнительные условия (свойства дерева поиска):
Данные в каждом узле должны обладать ключами, на которых определена операция сравнения меньше.
Как правило, информация, представляющая каждый узел, является записью, а не единственным полем данных.
Для составления бинарного дерева поиска рассмотрим функцию добавления узла в дерево.
Добавление узлов в дерево
Удаление поддерева
Пример Написать программу, подсчитывающую частоту встречаемости слов входного потока.
Поскольку список слов заранее не известен, мы не можем предварительно упорядочить его. Неразумно пользоваться линейным поиском каждого полученного слова, чтобы определять, встречалось оно ранее или нет, т.к. в этом случае программа работает слишком медленно.
Один из способов — постоянно поддерживать упорядоченность уже полученных слов, помещая каждое новое слово в такое место, чтобы не нарушалась имеющаяся упорядоченность. Воспользуемся бинарным деревом.
В дереве каждый узел содержит:
Рассмотрим выполнение программы на примере фразы
now is the time for all good men to come to the aid of their party
При этом дерево будет иметь следующий вид 
Результат выполнения 
Структуры данных: бинарные деревья. Часть 1
Интро
Этой статьей я начинаю цикл статей об известных и не очень структурах данных а так же их применении на практике.
В своих статьях я буду приводить примеры кода сразу на двух языках: на Java и на Haskell. Благодаря этому можно будет сравнить императивный и функциональный стили программирования и увидить плюсы и минусы того и другого.
Начать я решил с бинарных деревьев поиска, так как это достаточно базовая, но в то же время интересная штука, у которой к тому же существует большое количество модификаций и вариаций, а так же применений на практике.
Зачем это нужно?
Бинарные деревья поиска обычно применяются для реализации множеств и ассоциативных массивов (например, set и map в с++ или TreeSet и TreeMap в java). Более сложные применения включают в себя ropes (про них я расскажу в одной из следующих статей), различные алгоритмы вычислительной геометрии, в основном в алгоритмах на основе «сканирующей прямой».
В этой статье деревья будут рассмотрены на примере реализации ассоциативного массива. Ассоциативный массив — обобщенный массив, в котором индексы (их обычно называют ключами) могут быть произвольными.
Ну-с, приступим
Двоичное дерево состоит из вершин и связей между ними. Конкретнее, у дерева есть выделенная вершина-корень и у каждой вершины может быть левый и правый сыновья. На словах звучит несколько сложно, но если взглянуть на картинку все становится понятным:

У этого дерева корнем будет вершина A. Видно, что у вершины D отсутствует левый сын, у вершины B — правый, а у вершин G, H, F и I — оба. Вершины без сыновей принято называть листьями.
Каждой вершине X можно сопоставить свое дерево, состоящее из вершины, ее сыновей, сыновей ее сыновей, и т.д. Такое дерево называют поддеревом с корнем X. Левым и правым поддеревьями X называют поддеревья с корнями соответственно в левом и правом сыновьях X. Заметим, что такие поддеревья могут оказаться пустыми, если у X нет соответствующего сына.
Данные в дереве хранятся в его вершинах. В программах вершины дерева обычно представляют структурой, хранящей данные и две ссылки на левого и правого сына. Отсутствующие вершины обозначают null или специальным конструктором Leaf:
Как видно из примеров, мы требуем от ключей, чтобы их можно было сравнивать между собой ( Ord a в haskell и T1 implements Comparable в java). Все это не спроста — для того, чтобы дерево было полезным данные должны храниться в нем по каким-то правилам.
Какие же это правила? Все просто: если в вершине X хранится ключ x, то в левом (правом) поддереве должны храниться только ключи меньшие (соответственно большие) чем x. Проиллюстрируем:
Что же нам дает такое упорядочевание? То, что мы легко можем отыскать требуемый ключ x в дереве! Просто сравним x со значением в корне. Если они равны, то мы нашли требуемое. Если же x меньше (больше), то он может оказаться только в левом (соответственно правом) поддереве. Пусть например мы ищем в дереве число 17:
Функция, получающая значение по ключу:
Добавление в дерево
Теперь попробуем сделать операцию добавления новой пары ключ/значение (a,b). Для этого будем спускаться по дереву как в функции get, пока не найдем вершину с таким же ключем, либо не дойдем до отсутсвующего сына. Если мы нашли вершину с таким же ключем, то просто меняем соответствующее значение. В противно случае легко понять что именно в это место следует вставить новую вершину, чтобы не нарушить порядок. Рассмотрим вставку ключа 42 в дерево на прошлом рисунке:
Лирическое отступление о плюсах и минусах функционального подхода
Если внимательно рассмотреть примеры на обоих языках, можно увидеть некоторое различие в поведении функциональной и императивной реализаций: если на java мы просто модифицируем данные и ссылки в имеющихся вершинах, то версия на haskell создает новые вершины вдоль всего пути, пройденного рекурсией. Это связано с тем, что в чисто функциональных языках нельзя делать разрушающие присваивания. Ясно, что это ухудшает производительность и увеличивает потребляемую память. С другой стороны, у такого подхода есть и положительные стороны: отсутствие побочных эффектов сильно облегчает понимание того, как функционирует программа. Более подробно об этом можно прочитать в практически любом учебнике или вводной статье про функциональное программирование.
В этой же статье я хочу обратить внимание на другое следствие функционального подхода: даже после добавления в дерево нового элемента старая версия останется доступной! За счет этого эффекта работают ropes, в том числе и в реализации на императивных языках, позволяя реализовывать строки с асимптотически более быстрыми операциями, чем при традиционном подходе. Про ropes я расскажу в одной из следующих статей.
Вернемся к нашим баранам
Теперь мы подобрались к самой сложной операции в этой статье — удалению ключа x из дерева. Для начала мы, как и раньше, найдем нашу вершину в дереве. Теперь возникает два случая. Случай 1 (удаляем число 5):
Видно, что у удаляемой вершины нет правого сына. Тогда мы можем убрать ее и вместо нее вставить левое поддерево, не нарушая упорядоченность:
Если же правый сын есть, налицо случай 2 (удаляем снова вершину 5, но из немного другого дерева):
Тут так просто не получится — у левого сына может уже быть правый сын. Поступим по-другому: найдем в правом поддереве минимум. Ясно, что его можно найти если начать в правом сыне и идти до упора влево. Т.к у найденного минимума нет левого сына, можно вырезать его по аналогии со случаем 1 и вставить его вместо удалеемой вершины. Из-за того что он был минимальным в правом поддереве, свойство упорядоченности не нарушится:
На десерт, пара функций, которые я использовал для тестирования:
Чем же все это полезно?
У читателя возможно возникает вопрос, зачем нужны такие сложности, если можно просто хранить список пар [(ключ, значение)]. Ответ прост — операции с деревом работают быстрее. При реализации списком все функции требуют O(n) действий, где n — размер структуры. (Запись O(f(n)) грубо говоря означает «пропорционально f(n)», более корректное описание и подробности можно почитать тут). Операции с деревом же работают за O(h), где h — максимальная глубина дерева (глубина — расстояние от корня до вершины). В оптимальном случае, когда глубина всех листьев одинакова, в дереве будет n=2^h вершин. Значит, сложность операций в деревьях, близких к оптимуму будет O(log(n)). К сожалению, в худшем случае дерево может выродится и сложность операций будет как у списка, например в таком дереве (получится, если вставлять числа 1..n по порядку):
К счастью, существуют способы реализовать дерево так, чтобы оптимальная глубина дерева сохранялась при любой последовательности операций. Такие деревья называют сбалансированными. К ним например относятся красно-черные деревья, AVL-деревья, splay-деревья, и т.д.
Анонс следующих серий
В следующей статье я сделаю небольшой обзор различных сбалансированных деревьев, их плюсы и минусы. В следующих статьях я расскажу о каком-нибудь (возможно нескольких) более подробно и с реализацией. После этого я расскажу о реализации ropes и других возможных расширениях и применениях сбалансированных деревьев.
Оставайтесь на связи!
Полезные ссылки
Исходники примеров целиком:
Также очень советую почитать книгу Кормен Т., Лейзерсон Ч., Ривест Р.: «Алгоритмы: построение и анализ», которая является прекрасным учебником по алгоритмам и структурам данных
Алгоритмы и структуры данных для начинающих: двоичное дерево поиска
Авторизуйтесь
Алгоритмы и структуры данных для начинающих: двоичное дерево поиска
До сих пор мы рассматривали структуры данных, данные в которых располагаются линейно. В связном списке — от первого узла к единственному последнему. В динамическом массиве — в виде непрерывного блока.
В этой части мы рассмотрим совершенно новую структуру данных — дерево. А точнее, двоичное (бинарное) дерево поиска (binary search tree). Бинарное дерево поиска имеет структуру дерева, но элементы в нем расположены по определенным правилам.
10–12 декабря, Онлайн, Беcплатно
Для начала мы рассмотрим обычное дерево.
Деревья
Дерево — это структура, в которой у каждого узла может быть ноль или более подузлов — «детей». Например, дерево может выглядеть так:

Это дерево показывает структуру компании. Узлы представляют людей или подразделения, линии — связи и отношения. Дерево — это самый эффективный способ представления и хранения такой информации.
Дерево на картинке выше очень простое. Оно отражает только отношение родства категорий, но не накладывает никаких ограничений на свою структуру. У генерального директора может быть как один непосредственный подчиненный, так и несколько или ни одного. На рисунке отдел продаж находится левее отдела маркетинга, но порядок на самом деле не имеет значения. Единственное ограничение дерева — каждый узел может иметь не более одного родителя. Самый верхний узел (совет директоров, в нашем случае) родителя не имеет. Этот узел называется «корневым», или «корнем».
Вопросы о деревьях задают даже на собеседовании в Apple.
Двоичное дерево поиска
Двоичное дерево поиска похоже на дерево из примера выше, но строится по определенным правилам:
Давайте посмотрим на дерево, построенное по этим правилам:
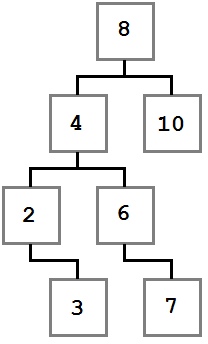
Двоичное дерево поиска
Обратите внимание, как указанные ограничения влияют на структуру дерева. Каждое значение слева от корня (8) меньше восьми, каждое значение справа — больше либо равно корню. Это правило применимо к любому узлу дерева.
Учитывая это, давайте представим, как можно построить такое дерево. Поскольку вначале дерево было пустым, первое добавленное значение — восьмерка — стало его корнем.
Рассмотрим подробнее первые шаги.
В первую очередь добавляется 8. Это значение становится корнем дерева. Затем мы добавляем 4. Поскольку 4 меньше 8, мы кладем ее в левого ребенка, согласно правилу 2. Поскольку у узла с восьмеркой нет детей слева, 4 становится единственным левым ребенком.
После этого мы добавляем 2. 2 меньше 8, поэтому идем налево. Так как слева уже есть значение, сравниваем его со вставляемым. 2 меньше 4, а у четверки нет детей слева, поэтому 2 становится левым ребенком 4.
Затем мы добавляем тройку. Она идет левее 8 и 4. Но так как 3 больше, чем 2, она становится правым ребенком 2, согласно третьему правилу.
Последовательное сравнение вставляемого значения с потенциальным родителем продолжается до тех пор, пока не будет найдено место для вставки, и повторяется для каждого вставляемого значения до тех пор, пока не будет построено все дерево целиком.
Класс BinaryTreeNode
Класс BinaryTreeNode представляет один узел двоичного дерева. Он содержит ссылки на левое и правое поддеревья (если поддерева нет, ссылка имеет значение null ), данные узла и метод IComparable.CompareTo для сравнения узлов. Он пригодится для определения, в какое поддерево должен идти данный узел. Как видите, класс BinaryTreeNode очень простой:
Класс BinaryTree
Кроме того, в классе есть ссылка на корневой узел дерева и поле с общим количеством узлов.
Метод Add
Добавление узла не представляет особой сложности. Оно становится еще проще, если решать эту задачу рекурсивно. Есть всего два случая, которые надо учесть:
Если дерево пустое, мы просто создаем новый узел и добавляем его в дерево. Во втором случае мы сравниваем переданное значение со значением в узле, начиная от корня. Если добавляемое значение меньше значения рассматриваемого узла, повторяем ту же процедуру для левого поддерева. В противном случае — для правого.
Метод Remove
Удаление узла из дерева — одна из тех операций, которые кажутся простыми, но на самом деле таят в себе немало подводных камней.
В целом, алгоритм удаления элемента выглядит так:
Первый шаг достаточно простой. Мы рассмотрим поиск узла в методе Contains ниже. После того, как мы нашли узел, который необходимо удалить, у нас возможны три случая.
Случай 1: У удаляемого узла нет правого ребенка.
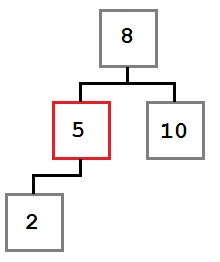
В этом случае мы просто перемещаем левого ребенка (при его наличии) на место удаляемого узла. В результате дерево будет выглядеть так:
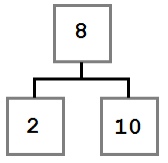
Случай 2: У удаляемого узла есть только правый ребенок, у которого, в свою очередь нет левого ребенка.
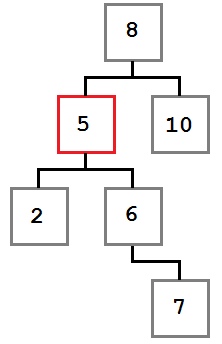
В этом случае нам надо переместить правого ребенка удаляемого узла (6) на его место. После удаления дерево будет выглядеть так:
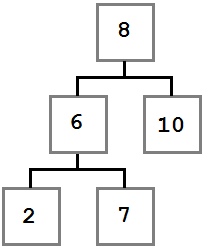
Случай 3: У удаляемого узла есть первый ребенок, у которого есть левый ребенок.
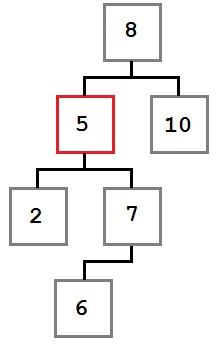
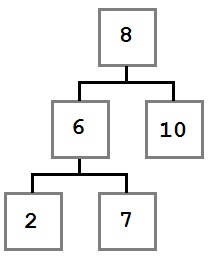
В этом случае место удаляемого узла занимает крайний левый ребенок правого ребенка удаляемого узла.
Давайте посмотрим, почему это так. Мы знаем о поддереве, начинающемся с удаляемого узла следующее:
Мы дожны поместить на место удаляемого узел со значением, меньшим или равным любому узлу справа от него. Для этого нам необходимо найти наименьшее значение в правом поддереве. Поэтому мы берем крайний левый узел правого поддерева.
После удаления узла дерево будет выглядеть так:
Теперь, когда мы знаем, как удалять узлы, посмотрим на код, который реализует этот алгоритм.
Отметим, что метод FindWithParent (см. метод Contains ) возвращает найденный узел и его родителя, поскольку мы должны заменить левого или правого ребенка родителя удаляемого узла.
Мы, конечно, можем избежать этого, если будем хранить ссылку на родителя в каждом узле, но это увеличит расход памяти и сложность всех алгоритмов, несмотря на то, что ссылка на родительский узел используется только в одном.
Метод Contains
Метод Count
Метод Clear
Обход деревьев
Обходы дерева — это семейство алгоритмов, которые позволяют обработать каждый узел в определенном порядке. Для всех алгоритмов обхода ниже в качестве примера будет использоваться следующее дерево:
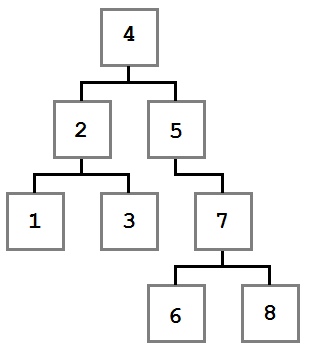
Пример дерева для обхода
Также, кроме описания поведения и алгоритмической сложности метода будет указываться порядок значений, полученный при обходе.
Метод Preorder (или префиксный обход)
При префиксном обходе алгоритм получает значение текущего узла перед тем, как перейти сначала в левое поддерево, а затем в правое. Начиная от корня, сначала мы получим значение 4. Затем таким же образом обходятся левый ребенок и его дети, затем правый ребенок и все его дети.
Префиксный обход обычно применяется для копирования дерева с сохранением его структуры.
Метод Postorder (или постфиксный обход)
При постфиксном обходе мы посещаем левое поддерево, правое поддерево, а потом, после обхода всех детей, переходим к самому узлу.
Постфиксный обход часто используется для полного удаления дерева, так как в некоторых языках программирования необходимо убирать из памяти все узлы явно, или для удаления поддерева. Поскольку корень в данном случае обрабатывается последним, мы, таким образом, уменьшаем работу, необходимую для удаления узлов.
Метод Inorder (или инфиксный обход)
Инфиксный обход используется тогда, когда нам надо обойти дерево в порядке, соответствующем значениям узлов. В примере выше в дереве находятся числовые значения, поэтому мы обходим их от самого маленького до самого большого. То есть от левых поддеревьев к правым через корень.
В примере ниже показаны два способа инфиксного обхода. Первый — рекурсивный. Он выполняет указанное действие с каждым узлом. Второй использует стек и возвращает итератор для непосредственного перебора.
Метод GetEnumerator
Продолжение следует
На этом мы заканчивает пятую часть руководства по алгоритмам и структурам данных. В следующей статье мы рассмотрим множества (Set).
B-tree
Введение
Деревья представляют собой структуры данных, в которых реализованы операции над динамическими множествами. Из таких операций хотелось бы выделить — поиск элемента, поиск минимального (максимального) элемента, вставка, удаление, переход к родителю, переход к ребенку. Таким образом, дерево может использоваться и как обыкновенный словарь, и как очередь с приоритетами.
Основные операции в деревьях выполняются за время пропорциональное его высоте. Сбалансированные деревья минимизируют свою высоту (к примеру, высота бинарного сбалансированного дерева с n узлами равна log n). Большинство знакомо с такими сбалансированными деревьями, как «красно-черное дерево», «AVL-дерево», «Декартово дерево», поэтому не будем углубляться.
В чем же проблема этих стандартных деревьев поиска? Рассмотрим огромную базу данных, представленную в виде одного из упомянутых деревьев. Очевидно, что мы не можем хранить всё это дерево в оперативной памяти => в ней храним лишь часть информации, остальное же хранится на стороннем носителе (допустим, на жестком диске, скорость доступа к которому гораздо медленнее). Такие деревья как красно-черное или Декартово будут требовать от нас log n обращений к стороннему носителю. При больших n это очень много. Как раз эту проблему и призваны решить B-деревья!
B-деревья также представляют собой сбалансированные деревья, поэтому время выполнения стандартных операций в них пропорционально высоте. Но, в отличие от остальных деревьев, они созданы специально для эффективной работы с дисковой памятью (в предыдущем примере – сторонним носителем), а точнее — они минимизируют обращения типа ввода-вывода.
Структура
При построении B-дерева применяется фактор t, который называется минимальной степенью. Каждый узел, кроме корневого, должен иметь, как минимум t – 1, и не более 2t – 1 ключей. Обозначается n[x] – количество ключей в узле x.
Все листья B-дерева должны быть расположены на одной высоте, которая и является высотой дерева. Высота B-дерева с n ≥ 1 узлами и минимальной степенью t ≥ 2 не превышает logt(n+1). Это очень важное утверждение (почему – мы поймем чуть позже)!
h ≤ logt((n+1)/2) — логарифм по основанию t.
Операции, выполнимые с B-деревом
Как упоминалось выше, в B-дереве выполняются все стандартные операции по поиску, вставке, удалению и т.д.
Поиск
Операция поиска выполняется за время O(t logt n), где t – минимальная степень. Важно здесь, что дисковых операций мы совершаем всего лишь O(logt n)!
Добавление
В отличие от поиска, операция добавления существенно сложнее, чем в бинарном дереве, так как просто создать новый лист и вставить туда ключ нельзя, поскольку будут нарушаться свойства B-дерева. Также вставить ключ в уже заполненный лист невозможно => необходима операция разбиения узла на 2. Если лист был заполнен, то в нем находилось 2t-1 ключей => разбиваем на 2 по t-1, а средний элемент (для которого t-1 первых ключей меньше его, а t-1 последних больше) перемещается в родительский узел. Соответственно, если родительский узел также был заполнен – то нам опять приходится разбивать. И так далее до корня (если разбивается корень – то появляется новый корень и глубина дерева увеличивается). Как и в случае обычных бинарных деревьев, вставка осуществляется за один проход от корня к листу. На каждой итерации (в поисках позиции для нового ключа – от корня к листу) мы разбиваем все заполненные узлы, через которые проходим (в том числе лист). Таким образом, если в результате для вставки потребуется разбить какой-то узел – мы уверены в том, что его родитель не заполнен!
На рисунке ниже проиллюстрировано то же дерево, что и в поиске (t=3). Только теперь добавляем ключ «15». В поисках позиции для нового ключа мы натыкаемся на заполненный узел (7, 9, 11, 13, 16). Следуя алгоритму, разбиваем его – при этом «11» переходит в родительский узел, а исходный разбивается на 2. Далее ключ «15» вставляется во второй «отколовшийся» узел. Все свойства B-дерева сохраняются!
Операция добавления происходит также за время O(t logt n). Важно опять же, что дисковых операций мы выполняем всего лишь O(h), где h – высота дерева.
Удаление
Удаление ключа из B-дерева еще более громоздкий и сложный процесс, чем вставка. Это связано с тем, что удаление из внутреннего узла требует перестройки дерева в целом. Аналогично вставке необходимо проверять, что мы сохраняем свойства B-дерева, только в данном случае нужно отслеживать, когда ключей t-1 (то есть, если из этого узла удалить ключ – то узел не сможет существовать). Рассмотрим алгоритм удаления:
1)Если удаление происходит из листа, то необходимо проверить, сколько ключей находится в нем. Если больше t-1, то просто удаляем и больше ничего делать не нужно. Иначе, если существует соседний лист (находящийся рядом с ним и имеющий такого же родителя), который содержит больше t-1 ключа, то выберем ключ из этого соседа, который является разделителем между оставшимися ключами узла-соседа и исходного узла (то есть не больше всех из одной группы и не меньше всех из другой). Пусть это ключ k1. Выберем ключ k2 из узла-родителя, который является разделителем исходного узла и его соседа, который мы выбрали ранее. Удалим из исходного узла нужный ключ (который необходимо было удалить), спустим k2 в этот узел, а вместо k2 в узле-родителе поставим k1. Чтобы было понятнее ниже представлен рисунок (рис.1), где удаляется ключ «9». Если же все соседи нашего узла имеют по t-1 ключу. То мы объединяем его с каким-либо соседом, удаляем нужный ключ. И тот ключ из узла-родителя, который был разделителем для этих двух «бывших» соседей, переместим в наш новообразовавшийся узел (очевидно, он будет в нем медианой).
Рис. 1.
2)Теперь рассмотрим удаление из внутреннего узла x ключа k. Если дочерний узел, предшествующий ключу k содержит больше t-1 ключа, то находим k1 – предшественника k в поддереве этого узла. Удаляем его (рекурсивно запускаем наш алгоритм). Заменяем k в исходном узле на k1. Проделываем аналогичную работу, если дочерний узел, следующий за ключом k, имеет больше t-1 ключа. Если оба (следующий и предшествующий дочерние узлы) имеют по t-1 ключу, то объединяем этих детей, переносим в них k, а далее удаляем k из нового узла (рекурсивно запускаем наш алгоритм). Если сливаются 2 последних потомка корня – то они становятся корнем, а предыдущий корень освобождается. Ниже представлен рисунок (рис.2), где из корня удаляется «11» (случай, когда у следующего узла больше t-1 ребенка).
Рис.2.
Операция удаления происходит за такое же время, что и вставка O(t logt n). Да и дисковых операций требуется всего лишь O(h), где h – высота дерева.
Итак, мы убедились в том, что B-дерево является быстрой структурой данных (наряду с такими, как красно-черное, АВЛ). И еще одно важное свойство, которое мы получили, рассмотрев стандартные операции, – автоматическое поддержание свойства сбалансированности – заметим, что мы нигде не балансируем его специально.
Базы Данных
Проанализировав, вместе со скоростью выполнения, количество проведенных операций с дисковой памятью, мы можем сказать, что B-дерево несомненно является более выгодной структурой данных для случаев, когда мы имеем большой объем информации.
Очевидно, увеличивая t (минимальную степень), мы увеличиваем ветвление нашего дерева, а следовательно уменьшаем высоту! Какое же t выбрать? — Выбираем согласно размеру оперативной памяти, доступной нам (т.е. сколько ключей мы можем единовременно просматривать). Обычно это число находится в пределах от 50 до 2000. Разберёмся, что же дает нам ветвистость дерева на стандартном примере, который используется во всех статьях про B-tree. Пусть у нас есть миллиард ключей, и t=1001. Тогда нам потребуется всего лишь 3 дисковые операции для поиска любого ключа! При этом учитываем, что корень мы можем хранить постоянно. Теперь видно, на сколько это мало!
Также, мы читаем не отдельные данные с разных мест, а целыми блоками. Перемещая узел дерева в оперативную память, мы перемещаем выделенный блок последовательной памяти, поэтому эта операция достаточно быстро работает.
Соответственно, мы имеем минимальную нагрузку на сервер, и при этом малое время ожидания. Эти и другие описанные преимущества позволили B-деревьям стать основой для индексов, базирующихся на деревьях в СУБД.



