Как составить диаграмму Эйлера-Венна
Диаграмма Эйлера-Венна — что из себя представляет, где используется
Диаграмма Эйлера-Венна представляет собой геометрическую схему, предназначенную для представления моделей множеств и схем их взаимосвязей.
Благодаря данной диаграмме, приводят наглядное объяснение разных фактов о множествах. При таком методе универсальное множество представляют в виде прямоугольника, а для изображения подмножества используют круги. Широкое применение диаграммы Эйлера-Венна нашли в таких дисциплинах, как математика, логика, менеджмент, финансы и другие прикладные направления.
Способы отражения отношений между множествами ранее отличались. Джон Венн применял в качестве обозначения множеств замкнутые фигуры, а Эйлер – круги.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
Диаграммы Эйлера-Венна представляют собой важный частный случай кругов, которые изображал Эйлер. На диаграммах представлены все 2 n комбинаций n свойств, что является конечной булевой алгеброй. Если n = 3, на диаграмме, как правило, изображают три круга с центрами, которые расположены в углах равностороннего треугольника, и совпадающими радиусами, ориентировочно равными длине сторон этого многоугольника.
Принципы построения, как изобразить множества
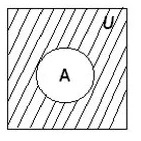
Построить диаграмму Эйлера-Венна – значит, составить большой прямоугольник, представляющий универсальное множество U, и разместить внутри него замкнутые фигуры в качестве обозначения множеств.
В том случае, когда требуется строить на диаграмме не более трех множеств, целесообразно использовать круги. Для изображения свыше четырех множеств применяют эллипсы. Пересечение фигур соответствует максимально общему случаю, согласно условиям задачи, и изображается должным образом на диаграмме.
Если предположить, что диаграмма содержит круг, обозначающий множество А, его центральная часть будет отражать истинность выражения А, а область вне круга – обозначать ложь. Те области, которые соответствуют истинным значениям, заштриховывают, что является отражением логической операции на диаграмме.
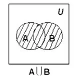
Согласно алгебре логики, конъюнкция множеств А и В соответствует истине в том случае, когда истинны оба эти множества. При этом на диаграмме отмечают участок пересечения множеств.
Применяя диаграммы Эйлера-Венна, доказывают любые алгебраические законы с помощью их графического изображения. Алгоритм построения:
Данные диаграммы являются эффективным методом визуализации операций с множествами. Отдельные множества изображают в виде кругов, а универсальное множество представляют прямоугольником.
Дополнение множества
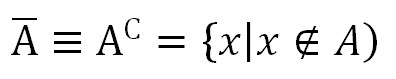
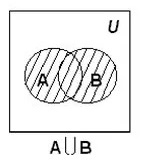
Объединение множеств
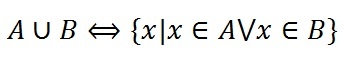
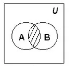
Пересечение множеств
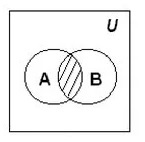
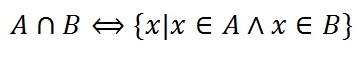
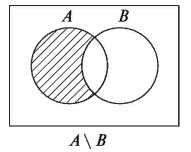
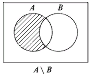
Разность множеств
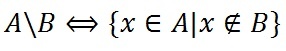
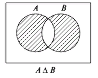
Симметричная разность множеств
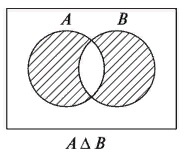
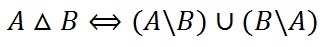
Использование диаграмм Эйлера-Венна для доказательства логических равенств
В качестве доказательства логического равенства подходит способ построения диаграмм Эйлера-Венна. Для примера можно представить доказательства следующего выражения: ¬(АvВ) = ¬А&¬В. Равенство демонстрирует запись закона де Моргана. В первую очередь следует наглядно изобразить левую часть уравнения. Для этого необходимо последовательно заштриховать серым цветом все круги, то есть применить дизъюнкцию. Отобразить инверсию можно с помощью закрашивания черным цветом области вне этих кругов.
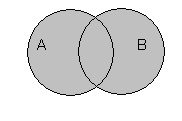
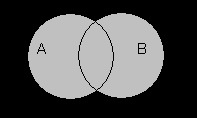
Далее следует визуально представить правую часть выражения. Последовательность действий в этом случае такова: необходимо заштриховать область, в которой отображается инверсия (¬А), с использованием серого цвета и аналогично закрасить область ¬В; отобразить конъюнкцию в виде пересечения этих серых областей. Результат такого наложения будет окрашен черным цветом.
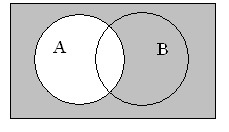
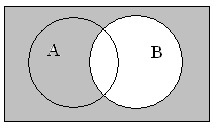
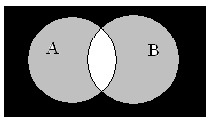
На рисунке видно, что области, в которых отображены левая и правая части уравнения, равны друг другу. Таким образом, закономерность доказана.
Решение задачи поиска информации в Интернет с помощью диаграмм Эйлера-Венна
Изучая тему поиска информации в глобальной сети Интернет, нельзя обойтись без примеров поисковых запросов, в которых использованы логические связки. Как правило, их смысл аналогичен союзам «и», «или» из русского языка. Принцип действия можно понять, если изобразить логические связи с помощью графической схемы или диаграммы Эйлера-Венна.
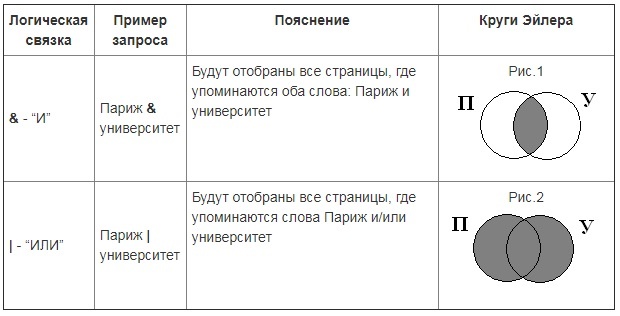
Как логические операции связаны с теорией множеств
Используя диаграммы Эйлера-Венна, принято наглядно демонстрировать связь логических действий и теории множеств. Операции логики можно задать с помощью таблиц истинности. В этом случае следует руководствоваться общим принципом.
На диаграмме в виде области круга под названием А отображают истинность определения А, то есть теоретически круг А обозначает все элементы, которые включены в данное множество. Таким образом, область за пределами круга А будет обозначать ложь соответствующего утверждения.
Понимание, какая область диаграммы отражает логическую операцию, возникает после того, как будут заштрихованы только те области, в которых значения логической операции на наборах А и В соответствуют истине. К примеру, импликация истинна при (00, 01 и 11).
Необходимо заштриховать сначала область за пределами пары пересекающихся кругов в соответствии со значениями А=0, В=0. Затем закрасить область в круге В, которая относится к значениям А=0, В=1, и область, соответствующую и кругу А, и кругу В, то есть участок пересечения, отображающий значения А=1, В=1. Эти три области в комплексе являются графическим представлением логической импликации.
Примеры задач с решением
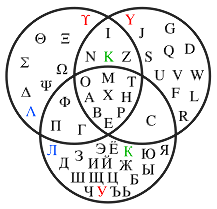
Диаграммы Эйлера-Венна могут содержать три и более круга. Преимуществом данного графического способа представления выражений является его высокая эффективность и наглядность. К примеру, можно изобразить диаграмму пересечений букв из русского, латинского и греческого алфавита:
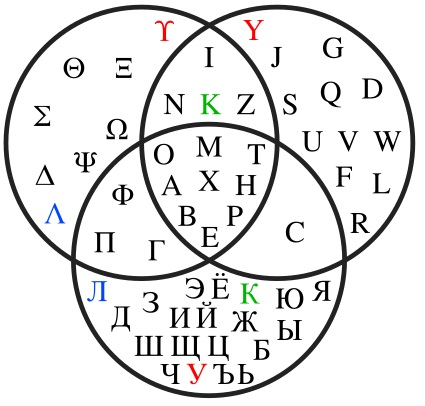
Понять суть методики удобно на практике. Можно решить несколько задач с применением диаграмм Эйлера-Венна.
Задача 1
По условию есть таблица поисковых запросов. В ней представлены страницы по некоторому сегменту. Требуется определить, сколько страниц в тысячах будет отображаться по запросу «Эсминец». Следует отметить, что запросы выполнялись практически в одно время, поэтому набор страниц с искомыми словами не менялся в процессе выполнения запросов.

Решение
Ф – является числом страниц (в тысячах) в соответствии с запросом «Фрегат»;
Э – является числом страниц (в тысячах) в соответствии с запросом «Эсминец»;
Х – представляет собой число страниц (в тысячах) по запросу, в котором присутствует «Фрегат» и отсутствует «Эсминец»;
У – определяет число страниц (в тысячах) по запросу, в котором указано слово «Эсминец» и отсутствует слово «Фрегат».
Диаграмма для каждого поискового запроса будет иметь следующий вид:

Исходя из информации по диаграммам, получим:
Х+900+У = Ф+У = 2100+У = 3400
Э = 900+У = 900+1300= 2200
Ответ: по запросу «Эсминец» будет найдено 2200 страниц
Задача 2
Класс состоит из 36 учеников. Дети ходят на занятия в рамках математического, физического, химического кружка. Факультатив по математике посещают 18 учащихся, по физике – 14, по химии – 10. Также известно, что 2 ученика ходят на все три кружка, 8 – на математику и физику, 5 – на математику и химию, 3 – на физику и химию. Необходимо определить количество учеников, которые не посещают ни одного кружка.
Решение
Решить данную задачу можно с помощью удобного и наглядного метода в виде кругов Эйлера. Наибольшим кругом следует обозначить множество всех учащихся класса. Внутри этой окружности необходимо изобразить пересекающиеся множества в виде учащихся на факультативе по математике (М), физике (Ф), химии (Х).
МФХ – является множеством учеников, каждый из которых ходит на занятия во все три кружка;
МФ¬Х – определяет множество учащихся, которые посещают факультативы по математике и физике, но не ходят на занятия по химии.
¬М¬ФХ – представляет собой множество людей, каждый из которых посещает химический факультатив, но отказался от дополнительных занятий по физике и математике.
По аналогичному принципу можно ввести множества: ¬МФХ, М¬ФХ, М¬Ф¬Х, ¬МФ¬Х, ¬М¬Ф¬Х.
Согласно условиям задачи, пара учеников записаны во все три кружка. Поэтому в область МФХ требуется вписать число 2. Исходя из того, что 8 учащихся посещают факультативы по математике и физике, а из них двое школьников ходят во все кружки, то в области МФ¬Х следует отметить 6 человек (8-2). Аналогичным способом можно определить число учеников в остальных множествах:

Далее требуется определить сумму учеников по всем областям:
Таким образом, всего 28 учащихся посещают факультативные занятия.
Ответ: 8 учеников из класса не посещают ни одного кружка.
Задача 3
Когда закончились зимние каникулы, преподаватель поинтересовался у учеников, кто из них посещал театр, кино или цирк. Всего в классе 36 человек. По полученной информации, два ребенка не были ни в кино, ни в театре, ни в цирке. Кино посетили 25 школьников, театр – 11, цирк – 17. И в кино, и в театр сходили 6 человек, и в кино, и в цирк – 10, и в театр, и в цирк – 4. Необходимо посчитать, какое количество учащихся из класса посетили и кино, и театр, и цирк.
Решение
Предположим, что х представляет собой число учеников, которые посетили и кино, и театр, и цирк. В таком случае, можно изобразить диаграмму и определить число школьников для каждой области:
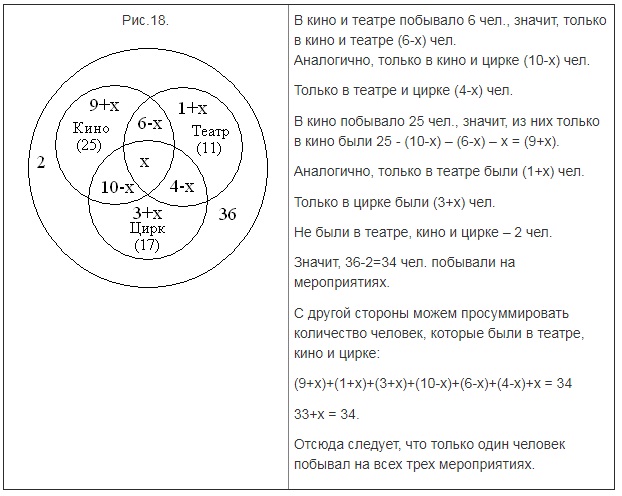
Ответ: 1 ученик побывал и в кино, и в театре, и в цирке.
Диаграммы Эйлера-Венна (помните, что это?) и доказательство законов де Моргана для множеств
Подписывайтесь на канал в Яндекс. Дзен или на канал в телеграмм «Математика не для всех», чтобы не пропустить интересующие Вас материалы.

Внимание: важная информация перед прочтением!
Если Вы новичок в теории множеств, ознакомьтесь, пожалуйста, со следующими материалами канала:
Перейдем к делу: в теории множеств у нас осталось совсем немного белых пятен, которые необходимо закрыть. Сегодня поговорим об удобном и наглядном представлении операций над множествами: диаграммами Эйлера-Венна, а также рассмотрим, как через них доказываются два ключевых закона логики — законы де Моргана. Поехали!
Диаграммы Эйлера-Венна
1. Дополнение множества.
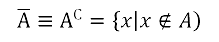
2. Объединение множеств.
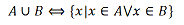
3. Пересечение множеств.
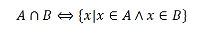
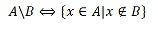
5. Симметричная разность множеств
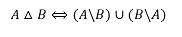
На диаграммах Эйлера-Венна могут быть три и более окружностей. Очевидным их преимуществом является наглядность: например, вот так выглядит диаграмма пересечений букв русского, латинского и греческого алфавита.
Законы де Моргана
Несмотря на простоту, законы де Моргана применяются в физике, электротехнике и информатике. С их помощью оптимизируются схемы посредством замены одних логических элементов другими (кстати, вот канал моего товарища — на нём он неторопливо и вдумчиво рассказывает о современных технологиях, начиная с транзисторной логики и заканчивая прикладными приложениями). Эти законы пришли в теорию множеств из математической логики и изначально под А и B понимались не множества, а утверждения.
Суть первого закон де Моргана такова:
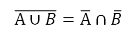
То есть: дополнение объединения множеств равно пересечению отдельных дополнений этих множеств (напомню, что когда говорим об операции дополнения множества А, подразумеваем разность UA, где U — универсум (универсальное множество). Докажем первый закон де Моргана с помощью диаграмм Эйлера-Венна.

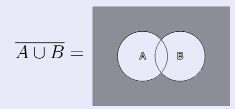
Закончили с левой частью закона, перейдем к правой:
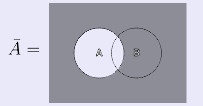
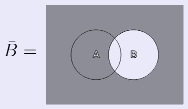
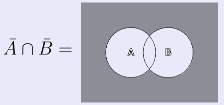
Таким образом, мы пришли к одинаковым диаграммам двумя разными путями, т.е. доказали справедливость первого закона де Моргана. Второй закон де Моргана выглядит обратным первому:
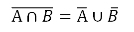
То есть: дополнение пересечения множеств равно объединению отдельных дополнений этих множеств. Доказательство второго закона идентично первому: оставлю его любопытному читателю.
ПОДПИСЫВАЙТЕСЬ! Этим Вы максимально мотивируете меня на создание интересного и познавательного контента. Ведь, если математика не для всех, то не значит, что она не для Вас конкретно! В теории множеств осталось рассмотреть только функционал отображения множеств, и пойдем дальше к изучению топологии.
Курс «Введение в математическую топологию»
Список материалов для начинающего математика:
Электронная библиотека
Диаграммы Эйлера-Венна – геометрические представления множеств. Построение диаграммы заключается в изображении большого прямоугольника, представляющего универсальное множество U, а внутри его – кругов (или каких-нибудь других замкнутых фигур), представляющих множества. Фигуры должны пересекаться в наиболее общем случае, требуемом в задаче, и должны быть соответствующим образом обозначены. Точки, лежащие внутри различных областей диаграммы, могут рассматриваться как элементы соответствующих множеств. Имея построенную диаграмму, можно заштриховать определенные области для обозначения вновь образованных множеств.
Операции над множествами рассматриваются для получения новых множеств из уже существующих.
Определение. Объединением множеств А и В называется множество, состоящее из всех тех элементов, которые принадлежат хотя бы одному из множеств А, В (рис. 1):
Рис. 1.1. Диаграмма Эйлера-Венна для объединения
Определение. Пересечением множеств А и В называется множество, состоящее из всех тех и только тех элементов, которые принадлежат одновременно как множеству А, так и множеству В (рис. 2):
Рис. 1.2. Диаграмма Эйлера-Венна для пересечения
Определение. Разностью множеств А и В называется множество всех тех и только тех элементов А, которые не содержатся в В (рис. 3):
Рис. 1.3. Диаграмма Эйлера-Венна для разности
Определение. Симметрической разностью множеств А и В называется множество элементов этих множеств, которые принадлежат либо только множеству А, либо только множеству В (рис. 4):
Рис. 1.4. Диаграмма Эйлера-Венна для симметрической разности
Определение. Абсолютным дополнением множества А называется множество всех тех элементов, которые не принадлежат множеству А (рис. 5):
Рис. 1.5. Диаграмма Эйлера-Венна для абсолютного дополнения
Пример 5. С помощью диаграмм Эйлера – Венна проиллюстрируем справедливость соотношения (рис. 6).
Рис. 1.6. Доказательство справедливости соотношения для примера 5
Убедились, что в обоих случаях получаем равные множества. Следовательно, исходное соотношение справедливо.
Срочно?
Закажи у профессионала, через форму заявки
8 (800) 100-77-13 с 7.00 до 22.00
Как построить диаграмму Венна с 50 кругами? Визуализация множеств и история моего Python-проекта с открытым кодом
Всем привет, меня зовут Фёдор Индукаев, я работаю аналитиком в Яндекс.Маршрутизации. Сегодня хочу рассказать вам про задачу визуализации пересекающихся множеств и про пакет для Python с открытым кодом, созданный мной для её решения. В процессе мы узнаем, чем различаются диаграммы Венна и Эйлера, познакомимся с сервисом распределения заказов и по касательной заденем такую область науки, как биоинформатика. Двигаться будем от простого к более сложному. Поехали!

О чём речь и зачем это нужно?
Почти каждому, кто занимался разведочным анализом данных, хотя бы раз приходилось искать ответ на вопросы такого типа:
Все перечисленные вопросы можно свести к одной и той же формулировке. Она звучит так: даны несколько конечных множеств, возможно, пересекающихся между собой, и надо оценить их взаимное расположение — то есть понять, как именно они пересекаются.
Речь пойдёт о визуализациях и программных инструментах, помогающих решать эту задачу.
Диаграммы Венна
Такие рисунки с двумя или тремя кругами, думаю, знакомы каждому и не требуют объяснения:
Особенность диаграммы Венна в том, что она статична. Фигуры на ней равновелики и расположены симметрично. На рисунке изображаются все возможные пересечения, даже если большинство из них на самом деле пусты. Такие диаграммы подходят, чтобы проиллюстрировать абстрактные понятия или множества, точные размеры которых неизвестны либо неважны. Основная информация тут содержится не в графике, а в подписях.
 Именно такими их замыслил Джон Венн, английский математик и философ. В своей статье 1880 года он предложил диаграммы для графического отображения логических высказываний. К примеру, высказывание «любой Х — это Y либо Z» даёт диаграмму справа (иллюстрация взята из оригинальной статьи). Чёрным закрашена область, не удовлетворяющая высказыванию: те Х, которые не являются ни Y, ни Z. Основной посыл статьи именно в том, что статические рисунки без варьирования формы и расположения фигур лучше подходят для целей логики, чем динамические диаграммы Эйлера, о которых речь пойдёт ниже.
Именно такими их замыслил Джон Венн, английский математик и философ. В своей статье 1880 года он предложил диаграммы для графического отображения логических высказываний. К примеру, высказывание «любой Х — это Y либо Z» даёт диаграмму справа (иллюстрация взята из оригинальной статьи). Чёрным закрашена область, не удовлетворяющая высказыванию: те Х, которые не являются ни Y, ни Z. Основной посыл статьи именно в том, что статические рисунки без варьирования формы и расположения фигур лучше подходят для целей логики, чем динамические диаграммы Эйлера, о которых речь пойдёт ниже.
Ясно, что в анализе данных сфера применения диаграмм Венна ограничена. Они дают только качественную информацию, но не количественную и не отражают ни размер, ни даже пустоту пересечений. Если вас это не останавливает, в вашем распоряжении пакет venn, который строит такие диаграммы для  множеств. Для каждого
множеств. Для каждого  там есть одна-две типовые картинки, и различаться будут только подписи:
там есть одна-две типовые картинки, и различаться будут только подписи:
Если же мы хотим что-то более динамически зависящее от данных, стоит обратить внимание на другой подход: диаграммы Эйлера.
Диаграммы Эйлера
В отличие от диаграмм Венна, форма и положение фигур на плоскости здесь подобраны так, чтобы показать взаимоотношения множеств или понятий. Если какое-то пересечение пусто, то фигуры тоже по возможности не перекрывают друг друга, как на рисунке о растениях и животных.
Обратите внимание, что рисунок про вопрос на лекции отличается от остальных двух. На нём важно не только положение фигур, но и размеры пересечений — в них и заключен весь юмор.
Эту идею можно использовать и для нашей задачи. Возьмём два-три множества и нарисуем круги с площадями, пропорциональными размерам этих множеств. А затем постараемся расположить круги на плоскости таким образом, чтобы площади перекрытия также были пропорциональны размерам пересечений.
Именно это делает (несмотря на своё название) пакет matplotlib-venn:
Изобразить два множества с точным соблюдением всех пропорций легко. Но уже на трёх метод может давать сбой. Пусть, например, одно из трёх множеств — в точности пересечение остальных двух:
Рисунок выглядит неважно, появилась странная область с цифрой 0. Но удивляться тут нечему, ведь пересечение двух кругов изобразить в виде круга никак не получится.
А вот ещё более удручающий пример: два множества и их симметрическая разность (объединение минус пересечение):
Получилось что-то совсем странное: обратите внимание, сколько тут нулей!
Первый пример ещё можно спасти, если взять вместо кругов прямоугольники (пересечение прямоугольников — тоже прямоугольник), а для второго нужны как минимум невыпуклые фигуры. Ну а больше трёх множеств данный пакет не поддерживает в принципе.
Других общедоступных инструментов для Python, развивающих подход Эйлера — Венна, я не знаю, и дальше пойдёт уже история моих собственных экспериментов. Но прежде чем продолжить, сделаю небольшое отступление, чтобы объяснить, зачем я вообще взялся за задачу визуализации множеств.
Пару слов об API построения оптимальных маршрутов
Как я говорил, наш отдел делает Яндекс.Маршрутизацию. Один из наших сервисов помогает интернет-магазинам, службам доставки и любым компаниям, чей бизнес включает логистику, строить оптимальные маршруты для транспорта.
Клиенты взаимодействуют с сервисом, отправляя запросы к API. Каждый запрос содержит список заказов (точек доставки) с координатами, интервалами доставки и т.д., а также список машин, которыми нужно развезти заказы. Наш алгоритм переваривает все эти данные и выдаёт оптимальные маршруты с учётом пробок, вместимости машин и много чего ещё.
У нас сотни, а не миллионы клиентов, как у популярных B2C-сервисов Яндекса. Поэтому нам особенно важно счастье каждого клиента, к тому же есть возможность уделять ему больше внимания и глубже погружаться в его задачи. Для этого, в частности, полезно иметь инструменты, помогающие понять, какие запросы нам присылает клиент.
Приведу пример. Допустим, за один день от компании «Ромашка» пришло 24 запроса. Это может означать, что:
Упрощаем задачу: от кругов к полосам
Какое-то время я пользовался пакетом matplotlib-venn, но ограничение в «два с половиной» множества, конечно, расстраивало. Размышляя над разными подходами к задаче, я решил попробовать перейти от кругов и вообще двумерных примитивов к одномерным — горизонтальным полосам. Пересечения тогда можно изображать наложением по вертикали вот таким образом:
Линейные размеры воспринимаются глазом лучше, чем площади, для построения не нужна сложная тригонометрия, а разнесение множеств по оси Y делает график менее перегруженным. К тому же наш первый неудачный пример (два множества и их пересечение в качестве третьего) улучшается сам собой:
Проблема с симметрической разностью пока ещё никуда не делась. Но мы поступим с ней, как Александр Македонский с гордиевым узлом: разрешим, если надо, разрубать одно из множеств на две части:
Красное множество изображено двумя полосами вместо одной, но ничего страшного в этом нет. Обе находятся на одной и той же высоте и имеют один цвет, так что их единство визуально хорошо считывается.
Нетрудно убедиться, что таким способом можно с точным соблюдением пропорций изобразить любые три множества. Тем самым задачу для равного 2 или 3 можно считать решённой.
Ещё один плюс такого подхода в том, что его легко применить к любому числу множеств, что мы и сделаем совсем скоро. Всё, что для этого нужно, — разрешить не один, а произвольное число разрывов в строках. Но сперва — немного простой комбинаторики.
Немного арифметики
Посмотрим на диаграмму Венна с тремя кругами и посчитаем, на сколько областей круги разбивают друг друга:
Каждая область определяется тем, лежит она внутри или снаружи каждого из трёх кругов, ну а внешняя область — лишняя. Итого получаем  . Другие расположения трёх кругов могут давать меньшее количество областей вплоть до 1, когда все круги совпадают.
. Другие расположения трёх кругов могут давать меньшее количество областей вплоть до 1, когда все круги совпадают.
Перенося это рассуждение с кругов на множества, получим, что любые множеств разбивают друг друга не более чем на  таких элементарных частей. Важно, что каждая из этих частей либо целиком входит, либо целиком не входит в любое из данных множеств. В наших новых диаграммах столбцы — это и есть такие элементарные части.
таких элементарных частей. Важно, что каждая из этих частей либо целиком входит, либо целиком не входит в любое из данных множеств. В наших новых диаграммах столбцы — это и есть такие элементарные части.
Больше множеств!
Итак, мы хотим обобщить вот такие схемы на случай  3$» data-tex=»inline»/>:
3$» data-tex=»inline»/>:
Для множеств у нас получается сетка с строками и  столбцами, как мы только что подсчитали. Остаётся пройтись по каждой строке и закрасить ячейки, соответствующие входящим в данное множество элементарным частям.
столбцами, как мы только что подсчитали. Остаётся пройтись по каждой строке и закрасить ячейки, соответствующие входящим в данное множество элементарным частям.
Для иллюстрации возьмём модельный пример с пятью множествами:
Действуя, как описано выше, получаем вот такой рисунок:
Читается он плохо: в строках слишком много разрывов, все множества порублены в капусту. Но раз нам не нравятся разрывы, то почему бы прямо не поставить задачу — минимизировать их? Ведь порядок столбцов несущественен, ничто не мешает нам переставлять их, как захочется. Приходим к такой задаче: найти перестановку столбцов данной матрицы из нулей и единиц с минимальным числом разрывов между единицами в строках.
Как мне подсказали уже позже, это практически задача коммивояжера в метрике Хэмминга, она NP-полная. Если столбцов получилось немного (скажем, не более 12), то найти нужную перестановку можно полным перебором, а иначе надо прибегать к тем или иным эвристикам.
Применим несложный жадный алгоритм. Назовём похожестью двух столбцов число позиций, на которых значения в этих столбцах совпадают. Возьмём два самых похожих столбца, поставим их вместе. Далее будем жадно наращивать последовательность в обе стороны от этой пары. Среди оставшихся столбцов найдём тот, который наиболее похож на один из этих двух, приставим — и так далее с остальными столбцами.
Вот рисунки до и после применения алгоритма:
Стало гораздо лучше. Именно на этой стадии я почувствовал, что выходит что-то полезное. Поэкспериментировав, я заметил, что алгоритм склонен залипать в локальных минимумах. Это удалось неплохо полечить с помощью простой рандомизации: немного зашумляем значения похожести столбцов, прогоняем алгоритм, повторяем 1000 раз, выбираем лучшее из 1000 решений.
Получился уже вполне рабочий инструмент, но в него можно добавить ещё немного полезной информации. Я сделал два дополнительных графика: на правом выведены размеры исходных множеств, а верхний для каждого пересечения показывает, во сколько из наших множеств оно входит. По сути, это ни что иное, как суммы нашей бинарной матрицы по строкам (справа) и по столбцам (вверху):
Ещё я добавил опцию упорядочивания самих множеств (т. е. строк) по тому же принципу, что и столбцов: с минимизацией числа разрывов. В итоге похожие множества группируются:
Применение в работе
Естественно, первым делом я стал применять новый инструмент для той задачи, для которой его и создавал: исследовать запросы клиентов к нашему API. Результаты меня порадовали. Вот так, например, выглядел рабочий день одного из клиентов. Каждая строка — запрос к API (множество ID входящих в него заказов), а подписи в середине — время отправки запросов:
Весь день как на ладони. В 10:49 логист клиента с интервалом 23 секунды послал два одинаковых запроса со 129 заказами. С 11:25 до 15:53 было три запроса с другим набором из 152 заказов. В 16:43 пришёл третий уникальный запрос со 114 заказами. К решению этого запроса логист затем применил четыре ручные правки (это можно делать через наш UI).
А так выглядит идеальный день: все независимые задачи решены по одному разу, никаких правок или подбора параметров не потребовалось:
А вот пример от клиента, отправляющего запросы каждые 15–30 минут, чтобы учесть заказы, поступающие в реальном времени:
Даже на 50 множествах алгоритм хорошо выявил структуру, скрытую в данных. Видно, как старые заказы по мере исполнения убирались из запросов и замещались новыми.
Словом, закрыть созданным инструментом свою рабочую потребность мне вполне удалось.
Banana for scale (not really)
Пока я изучал существующие подходы, мне несколько раз попадался на глаза рисунок из журнала Nature, где сравниваются геномы банана и пяти других растений:
Обратите внимание, как соотносятся размеры областей с 13 и 149 элементами (указаны стрелками): вторая в несколько раз меньше. Так что ни о какой пропорциональности тут нет и речи.
Мне, конечно, захотелось попробовать силы и на таких данных, но результат меня не порадовал:
График выглядит неряшливо. Причина в том, что, во-первых, почти все пересечения (62 из 63 возможных) непусты, а во-вторых, их размеры различаются на три порядка. В результате числовым аннотациям становится очень тесно.
Чтобы мой инструмент был удобен и для таких данных, я добавил несколько параметров. Один позволяет частично выровнять ширины столбцов, другой прячет аннотации, если ширина столбца меньше заданной величины.
Такой вариант читается уже вполне неплохо, но ради этого пришлось пожертвовать точной пропорциональностью размеров.
Как оказалось, обратив внимание на сферу биоинформатики, я не прогадал. Я отправил пост о своём инструменте на Reddit в r/visualization, r/datascience и r/bioinformatics, именно в последнем его приняли лучше всего, отзывы были прямо-таки восторженные.
Превращение в продукт
В итоге я понял, что получился неплохой инструмент, который может быть полезен многим. Поэтому родилась идея превратить его в полноценный пакет с открытым исходным кодом. Конечно, нужно было согласие руководителей, но ребята не только не возражали, но и поддержали меня, за что им большое спасибо.
Работая в основном по выходным, я начал понемногу приводить код в товарный вид, писать тесты и разбираться с системой пакетов в Python. Это мой первый проект такого рода, поэтому всё заняло несколько месяцев.
Придумать хорошее название тоже оказалось непростой задачей, и справился я с ней плоховато. Выбранное имя (supervenn) нельзя назвать удачным, ведь вся соль диаграмм Венна в их статичности, я же, напротив, стремился точно показывать реальные размеры. Но когда я это осознал, проект уже вышел в свет и менять название было поздно.
Аналоги
Конечно, я не первый использовал этот подход к визуализации множеств: идея, в общем-то, лежит на поверхности. В открытом доступе есть два похожих веб-приложения: RainBio и Linear Diagram Generator, второе использует в точности тот же принцип, что и у меня. (Авторы вдобавок написали статью на 40 страниц, где экспериментально сравнили, что лучше воспринимается — горизонтальные или вертикальные линии, тонкие или толстые и т. п. Мне даже показалось, что для них первичной была именно статья, а сам инструмент — лишь дополнение к ней.)
Чтобы сравнить эти два приложения с моим пакетом, снова используем пример со словами. Можете сами решить, какой вариант более удобочитаем и информативен.
RainBio
Linear Diagram Generator
supervenn
Другие подходы
Нельзя не упомянуть проект UpSet, существующий в виде веб-приложения и пакетов для R и Python. Базовый принцип можно понять, посмотрев на отображение данных о геноме банана. График обрезан справа, показаны только 30 пересечений из 62:
Интересно, что если использовать supervenn с сортировкой столбцов по ширине и сделать столбцы одинаковыми с помощью параметра выравнивания ширин, то получится почти то же самое, хотя это и не сразу заметно. Не хватает лишь вертикальных линий с размерами пересечений, вместо них только цифры внизу графика:
Уже при написании этого текста я попробовал воспользоваться Python-версией UpSet, но обнаружил, что пакет не обновлялся с 2016 года, в документации никак не описан формат входных данных, а тестовый пример падает с ошибкой. Веб-версия исправна, в ней много полезных вспомогательных функций, но работать с ней довольно тяжело из-за сложного способа ввода данных.
Наконец, в сети доступен интересный обзор методов визуализации множеств. Далеко не все из них реализованы в виде программных инструментов. Вот несколько картинок для привлечения внимания:
Особенно меня заинтересовал метод Bubble Sets (нижний ряд), позволяющий изображать небольшие множества поверх заданного расположения элементов на плоскости. Это может быть удобно, например, когда элементы привязаны к оси времени (а) или к карте (b). Пока что этот метод реализован только на Java и JavaScript (ссылки есть на странице авторов), и было бы здорово, если бы кто-нибудь взялся портировать его на Python.
Я отправил письма с кратким описанием проекта авторам UpSet и обзора и получил хорошие отзывы. Двое из них даже обещали включить supervenn в свои лекции по визуализации множеств.
Заключение
Если вы захотите воспользоваться пакетом, он доступен на GitHub и в PyPI: pip install supervenn. Я буду благодарен за любые замечания о коде и использовании пакета, за идеи и критику. Особенно буду рад прочитать рекомендации, как улучшить алгоритм перестановки столбцов для больших , и советы, как писать тесты для функций построения графиков.
Спасибо за внимание!
Ссылки
2. J.-B. Lamy and R. Tsopra. RainBio: Proportional visualization of large sets in biology. IEEE Transactions on Visualization and Computer Graphics, doi: 10.1109/TVCG.2019.2921544.
3. Peter Rodgers, Gem Stapleton and Peter Chapman. Visualizing Sets with Linear Diagrams. ACM Transactions on Computer Human Interaction 22(6) pp. 27:1-27:39 September 2015. doi:10.1145/2810012.
6. Christopher Collins, Gerald Penn and Sheelagh Carpendale. Bubble Sets: Revealing Set Relations with Isocontours over Existing Visualizations. IEEE Trans. on Visualization and Computer Graphics (Proc. of the IEEE Conf. on Information Visualization), vol. 15, iss. 6, pp. 1009−1016, 2009.



