Геном человека


Содержание
Особенности
Хромосомы
В геноме присутствует 23 пары хромосом: 22 пары аутосомных хромосом, а также пара половых хромосомы X и Y. У человека мужской пол является гетерогаметным и определяется наличием Y хромосомы. Нормальные диплоидные соматические клетки имеют 46 хромосом.
По результатам проекта Геном человека, количество генов в геноме человека составляет около 28000 генов. Начальная оценка была более чем 100 тысяч генов. В связи с усовершенствованием методов поиска генов (предсказание генов) предполагается дальнейшее уменьшение числа генов.
Число генов человека не намного превосходит число генов у более простых организмов, например, круглого червя Caenorhabditis elegans или мухи Drosophila melanogaster. Так происходит из-за того, что в человеческом геноме широко представлен альтернативный сплайсинг. Альтернативный сплайсинг позволяет получить несколько различных белковых цепочек с одного гена. В результате человеческий протеом оказывается значительно больше протеома рассмотренных организмов. Большинство человеческих генов имеют множественные экзоны, и интроны часто оказываются значительно более длинными, чем граничные экзоны в гене.
Гены неравномерно распределены по хромосомам. Каждая хромосома содержит богатые и бедные генами участки. Эти участки коррелируют с хромосомными бандами (полосы поперёк хромосомы, которые видно в микроскоп) и с CG-богатыми участками. В настоящий момент значимость такого неравномерного распределения генов не вполне изучена.
Кроме кодирующих белок генов человеческий геном содержит тысячи РНК-генов, включая транспортную РНК (tRNA), рибосомную РНК, микро РНК (microRNA) и прочие не кодирующие белок РНК последовательности.
Регуляторные последовательности
В человеческом геноме найдено множество различных последовательностей, отвечающих за регуляцию гена. Под регуляцией понимается контроль экспрессии гена (процесс построения матричной РНК по участку молекулы ДНК). Обычно это короткие последовательности, находящиеся либо рядом с геном, либо внутри гена. Иногда они находятся на значительном расстоянии от гена (энхансеры). Систематизация этих последовательностей, понимание механизмов работы, а также вопросы взаимной регуляции группы генов группой соответствующих ферментов на текущий момент находятся только на начальной стадии изучения. Взаимная регуляция групп генов описывается с помощью сетей регуляции генов. Изучение этих вопросов находится на стыке нескольких дисциплин: прикладной математики, высокопроизводительных вычислений и молекулярной биологии. Знания появляются из сравнений геномов различных организмов и благодаря достижениям в области организации искусственной транскрипции гена в лабораторных условиях.
Прочие объекты в геноме
Представленная классификация не является исчерпывающей. Большая часть объектов вообще не классифицирована мировой научной общественностью на текущий момент.
Соответствующие последовательности, скорее всего, являются эволюционным артефактом. В современной версии генома их функция выключена, и на эти участки генома многие ссылаются как на «мусорную ДНК». Однако существует масса свидетельств, которая говорит о том, что эти объекты обладают некоторой функцией, которая не вполне понятна на текущий момент.
Псевдогены
Вирусы
Около 1 % в геноме человека занимают встроенные гены ретровирусов (эндогенные ретровирусы). Эти гены обычно не приносят пользы хозяину, но существуют и исключения. Так, около 43 млн. лет назад в геном предков обезьян и человека попали ретровирусные гены, служившие для построения оболочки вируса. У человека и обезьян эти гены участвуют в работе плаценты.
Геном человека: полезная книга, или глянцевый журнал?
Автор
Редакторы
Изучение человеческого генома имеет одну конечную цель — оно затевается исключительно ради того, чтобы, взглянув на последовательность ДНК конкретного индивида, можно было бы получить о нем максимум информации. О том, какими болезнями он может заболеть, какие способности в себе развить, и какие опасности его могут поджидать при выборе того или иного жизненного пути. История изучения этого вопроса довольно продолжительна, однако заветная цель приближается к нам далеко не так быстро, как хотелось бы.
История вопроса
Особенности психики человека таковы, что он склонен переоценивать собственные достижения. Эта закономерность очень четко прослеживается в развитии научной мысли. Ученым зачастую кажется, что стоит совершить еще небольшой рывок, как истина откроется во всей красе, а будущим поколениям естествоиспытателей останется лишь стряхивать пыль с приборов. Однако в подавляющем большинстве случаев получается так, что новое открытие порождает больше вопросов, чем дает ответов.
В начале прошлого столетия казалось, что до выяснения природы наследственности рукой подать, ведь были заново открыты законы Менделя, сформулирована Хромосомная теория наследственности Моргана. Согласно представлениям того времени, наследственные факторы — гены — являлись белковыми молекулами, последовательно соединенными между собой в хромосомах. Казалось, что вот-вот эти белки будут выделены из хромосом и все встанет на свои места. При этом, естественно, ни у кого и в мыслях не было, что в генетическом материале организма могут присутствовать элементы, напрямую не определяющие каких-либо его свойств. Была уверенность в том, что каждый ген-белок отвечает за определенную функцию. Однако все оказалось куда сложнее.
Во-первых, к середине 40-х годов XX века, благодаря опытам Эйвери, Маклеода и Маккарти становится понятно, что функции хранения и передачи наследственной информации могут выполнять вовсе не белки. Внимание ученых начинает концентрироваться на изучении ДНК — полимерной молекулы, состоящей из дезоксирибонуклеотидов. К тому моменту было хорошо известно, что ДНК входит в состав хромосом, однако полагали, что эта молекула выполняет структурные функции, являясь своего рода хромосомным каркасом. Окончательно обосновали ключевую роль ДНК в наследственности Альфред Херши и Марта Чейз, только в начале 50-х годов показав, что бактериофаги способны размножаться без собственных белков — в инфицируемой ими бактериальной клетке оказывается и реплицируется только молекула ДНК.
Структуру ДНК впервые описывают Джеймс Уотсон и Френсис Крик в своей работе 1953 года [1]. В последующие 20 лет накапливаются знания о природе генетического кода (М. Ниренберг и Дж. Маттеи), работе генов и регуляторных элементов (Ф. Жакоб и Ж. Моно), тонкой структуре гена (С. Бензер), об укладке ДНК на нуклеосомах (А. Корнберг). Также становится понятно, что в геномах организмов содержатся не только уникальные последовательности структурных генов — в них присутствует огромное количество часто повторяющихся и вовсе не кодирующих белки последовательностей.
Своя и чужая ДНК
В середине прошлого века тезис о том, что генетический материал организма содержит исключительно структуры, необходимые для формирования фенотипических признаков, было странно подвергать сомнению. Любую особенность организма пытались объяснить с позиций целесообразности, и поэтому считалось, что лишних и нефункциональных структур быть просто не должно.
Опыты, подтверждающие наличие в геноме «лишнего» материала, довольно любопытны. Первые указания на такую особенность были получены при изучении кинетики реассоциации геномной ДНК. Дело в том, что последовательности ДНК с разной скоростью восстанавливаются после денатурации. Если последовательность содержит много повторов, она восстанавливается быстрее, а если последовательность ДНК уникальна — времени на ее ренатурацию требуется больше. В ходе проведения экспериментов по реассоциации геномных ДНК эукариот было выяснено, что очень большая часть генома приходится на разного рода быстро ренатурирующие повторы, сателлиты и прочую «бесполезную» ДНК (кстати, термин “junk DNA” был введен еще Френсисом Криком). Еще сравнительно недавно бытовало мнение, что такого рода «мусорные последовательности» необходимы для того, чтобы защищать полезную ДНК от мутаций, как бы вызывая огонь на себя. В самом деле, если мутациям подвергается некодирующий участок ДНК, то это, скорее всего, не отразится негативно на фенотипе особи. Однако, как выяснилось впоследствии, роль такой ДНК в геноме нельзя ограничить только этим. Дальнейшее изучение вопроса показало, что повторяющаяся и некодирующая фракция ДНК в геноме чрезвычайно разнообразна по своей структуре. Помимо повторов, выполняющих чисто технические функции связывания с белками ядерного матрикса или компонентами центромеры, обнаруживаются и такие участки генома, которые напрямую не влияют на морфологию организма и на выполнение им тех или иных функций. Исследование того, откуда эти участки взялись и почему они есть во всех организмах, представляло интерес.

Рисунок 1. Барбара МакКлинток.
Примерно одновременно с работами по изучению роли ДНК в наследственности подвергается первой критике хромосомная теория Моргана в хрестоматийном ее понимании. Это связано с тем, что Барбара МакКлинток обнаруживает генетические элементы, которые, по ее мнению, способны менять свою локализацию на хромосоме [2]. Эти революционные исследования поначалу не находят понимания, поскольку противоречат принятому тогда постулату о том, что каждый ген имеет свой постоянный хромосомный локус. Сама МакКлинток даже получает обидное прозвище crazy Barbara (сумасшедшая Барбара). Однако позднее выясняется, что подобные мобильные генетические элементы присутствуют у всех живых организмов (стоит также упомянуть, что МакКлинток спустя 30 лет после своего открытия удостаивается Нобелевской премии в области физиологии и медицины [3]).
У животных, а конкретно, у дрозофилы, мобильные элементы впервые обнаруживают в лабораториях Хогнесса в США и Георгиева в СССР. Причем очень быстро становится ясно, что таких элементов огромное множество, в геномах они представлены очень широко, а по своим структурным и функциональным особенностям могут отличаться очень сильно. Изучение структуры различных классов мобильных элементов генома (МГЭ) приводит ученых к выводу об их родстве с вирусами. Жизненные циклы вирусов и многих МГЭ очень похожи, да и белки, кодируемые их генами, выполняют одни и те же функции, что отчетливо указывает на общность происхождения этих примитивных живых систем.
Экология генома: молекулярные паразиты и эндосимбионты
До 80-х — 90-х годов прошлого столетия тезис о том, что внутри человеческого генома могут находиться последовательности, собственно к человеку не имеющие никакого отношения, звучал бы дико. Однако сейчас мы сталкиваемся с тем, что геномы едва ли не всех эукариот кишат молекулярными паразитами! Известно, что подавляющее большинство вирусов могут встраивать свои ДНК в геном организма, который они заражают. При этом задача вируса очевидна — это размножение. Однако этой цели вирусы могут добиваться разными способами. С одной стороны, логично сразу же после встраивания начать синтезировать свои собственные белки, реплицировать свой генетический материал, а потом выходить из одной клетки организма и начинать заражать другие. В этой ситуации возникает небольшая проблема: клетка-хозяин погибает, а вслед за одной клеткой может погибнуть и весь организм, не дав возможности вирусу заразить другие организмы. Вступает в силу один из законов экологии: паразит, губящий своего хозяина, губит и себя самого. Поэтому возникает принципиально иная стратегия поведения молекулярных паразитов. После интеграции в геном многие вирусы начинают вести себя так, будто являются его неотъемлемой частью. Они не начинают активно копировать свой генетический материал, а остаются в сайте интеграции в виде так называемого провируса. Такой подход позволяет вирусам копировать информацию своего генома вместе с репликацией генома организма-хозяина, передаваясь по наследству потомкам этого хозяина. Британский генетик Джон Брукфилд (John F. Brookfield) в своих обзорах последних лет обосновывает введенный недавно термин «экология генома» [4], рассматривая в том числе и геном человека, как среду обитания всевозможных эндогенных ретровирусов, транспозонов и коротких сателлитных последовательностей. Причем между организмом-хозяином и такими сожителями ведется борьба по всем законам экосистем: паразит стремится размножиться, причиняя минимум беспокойства хозяину, а хозяин стремится либо паразита нейтрализовать, либо заставить работать на себя. При этом случаи мутуалистических отношений (сожительства с обоюдной пользой) между чужеродными последовательностями и геномом не редки. Одним из красивых примеров такого симбиоза является участие белковых продуктов эндогенных ретровирусов человека в процессе образования ткани плаценты. К тому же, широко известно, что относительно безопасные «одомашненные» вирусы могут препятствовать проникновению в клетки агрессивных вирусов извне.
Разумеется, помимо пользы от мобильных генетических элементов можно вполне ожидать и проблем. В частности, они могут провоцировать хромосомные аберрации, вызывать своими перемещениями мутации и изменения в активности генов, приводить к дестабилизации структуры всего генома. Взаимодействие между МГЭ и хозяйским геномом могут приводить к самым разнообразным и любопытным последствиям: от возникновения наследственных заболеваний до провоцирования процессов видообразования и образования новых генов.
Запутанная молекулярная инструкция
Проект «Геном человека» стартовал в начале девяностых и к настоящему времени завершен. Первые данные о составе нашего генома были опубликованы еще в 2001 году [5]. Тогда стало ясно, что на долю структурных генов (генов, содержащих информацию о строении белков или РНК) приходится около 5% всего генома (а ведь еще совсем недавно считалось, что кроме них в генетическом материале клетки быть ничего не должно). Самих же генов всего порядка 25–30 тысяч, что совсем не так много, как считалось. На долю же всевозможных мобильных последовательностей отводится целых 45% геномной ДНК! Остальное представлено повторами, поломанными неактивными генами и прочими техническими последовательностями. Причем все это невероятное разнообразие молекулярных текстов из поколения в поколение взаимодействует друг с другом, перестраивается, меняется местами и чуть ли не противоречит друг другу. Выяснить, как вся эта биоинформатическая каша из отдельных слов, написанных четырьмя молекулярными буквами-нуклеотидами, определяет внешний вид, характер и прочие особенности человека, — это задача, на решение которой уйдет еще очень много времени.
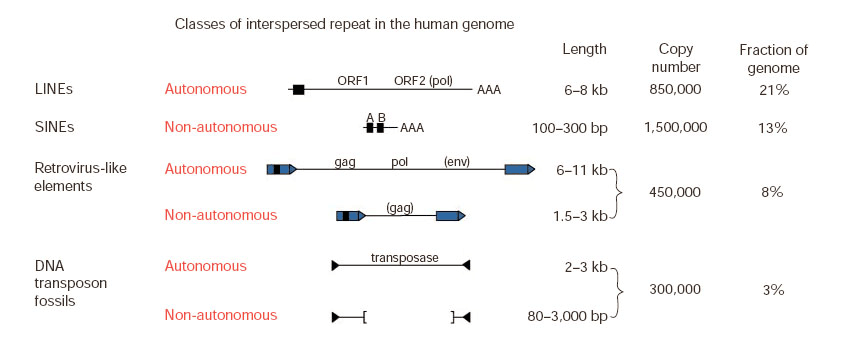
Рисунок 2. Классы повторов в геноме человека.
LINE — Long interspersed nuclear repeats. Одни из самых древних элементов. Содержат ген обратной транскриптазы и способны вносить разрывы в геномную ДНК при транспозиции. Часто образуют несовершенные копии.
SINE — Short interspersed nuclear repeats. Короткие последовательности, содержащие промотор полимеразы III. Их транспозиции происходят за счет белков, кодируемых генами LINE-элементов.
LTR (long terminal repeat) retrotransposons — группа элементов, по своей организации больше всего напоминающая вирусы (если точнее — ретровирусы). Считается, что часть ретротранспозонов произошла от вирусов, когда-то проникнувших в геном. Некоторые LTR-элементы сохраняют возможность покидать клетку-хозяина и инфицировать другие клетки. Включают от одного до нескольких генов.
DNA transposons — мобильные элементы, не требующие стадии образования РНК-копии для транспозиций. Кодируют фермент транспозазу, необходимую для перемещения.
Разумеется, значение проекта «Геном человека» сложно переоценить. Уже сейчас сделано множество интереснейших работ, которые были бы невозможны без прочтения последовательности человеческой ДНК. Однако каких-то 5–10 лет назад казалось, что секвенирование генома решит сразу все проблемы биологической науки, а заодно и медицины. В прессе было очень модно обсуждать прочтение «книги жизни», в которой содержится подробная инструкция о том, как собрать человеческий организм. Вроде бы оставалось лишь последовательно вникнуть в смысл каждой главы. И вдруг столь значительная книга, страницы которой так мечтали пролистать ученые конца XX века, на поверку оказывается зачитанным глянцевым журналом, пестрящим рекламой, вырезанными страницами, частными объявлениями с грамматическими ошибками и чьими-то заметками на полях. Найти что-то полезное в таком молекулярном издании довольно сложно, однако ученым не просто предстоит отделить в нем ценную информацию от бессмыслицы, но также понять алгоритм того, как полезные отрывки сочетаются и дополняют друг друга, реализуясь в целостной картине человеческого организма. И это не самая простая головоломка.
Геном человека: как это было и как это будет
Геном человека: как это было и как это будет
Около трёх миллиардов пар нуклеотидных остатков составляют наш геном — совокупность всех молекул ДНК в клетке человека
Авторы
Редакторы
Это было семь лет назад — 26-го июня 2000 года. На совместной пресс-конференции с участием президента США и премьер-министра Великобритании представители двух исследовательских групп — International Human Genome Sequencing Consortium (IHGSC) и Celera Genomics — объявили о том, что работы по расшифровке генома человека, начавшиеся ещё в 70-х годах, успешно завершены, и черновой его вариант составлен. Начался новый эпизод развития человечества — постгеномная эра.
Что может дать нам расшифровка генома, и стоят ли потраченные средства и усилия достигнутого результата? Фрэнсис Коллинз (Francis S. Collins), руководитель американской программы «Геном человека», в 2000 году дал следующий прогноз развития медицины и биологии в постгеномную эру:
Как видно из прогноза, геномная информация в недалеком будущем может стать основой лечения и профилактики множества болезней. Без информации о своих генах (а она умещается на стандарный DVD-диск) человек в будущем сможет вылечить разве что насморк у какого-нибудь целителя в джунглях. Это кажется фантастикой? Но когда-то такой же фантастикой была поголовная вакцинация от оспы или интернет (заметьте, в 70-х его еще не существовало)! В будущем генетический код ребенка будут выдавать родителям в роддоме. Теоретически, при наличии такого диска, лечение и предотвращение любых недугов отдельно взятого человека станет сущим пустяком. Профессиональный врач сможет в предельно сжатые сроки поставить диагноз, назначить эффективное лечение, и даже определить вероятность появления разных болезней в будущем. К примеру, современные генетические тесты уже позволяют точно определить степень предрасположенности женщины к раку груди. Почти наверняка, лет через 40–50 ни один уважающий себя врач без генетического кода не захочет «лечить вслепую» — подобно тому, как сегодня хирургия не может обойтись без рентгеновского снимка.
Давайте зададимся вопросом — а достоверно ли сказанное, или, может быть, в действительности всё будет наоборот? Смогут ли люди наконец победить все болезни и придут ли они ко всеобщему счастью? Увы. Начнем с того, что Земля маленькая, и счастья на всех не хватит. По правде сказать, его не хватит даже для половины населения развивающихся стран. «Счастье» предназначено в основном для государств, развитых в плане науки, в частности — наук биологических. Например методика, с помощью которой можно «прочесть» генетический код любого человека, уже давно запатентована. Это отлично отработанная автоматизированная технология — правда, дорогостоящая и очень тонкая. Хочешь, покупай лицензию, а хочешь — придумывай новую методику. Только вот денег на подобную разработку хватит далеко не у всех стран! В итоге ряд государств будет обладать медициной, существенно опережающей уровень остального мира. Естественно, в слаборазвитых странах Красным Крестом будут строиться благотворительные больницы, госпитали и геномные центры. И постепенно это приведет к тому, что генетическая информация пациентов развивающихся стран (которых большинство), сосредоточится у двух-трех держав, финансирующих эту благотворительность. Что можно сделать, имея такую информацию — даже представить трудно. Может, и ничего страшного. Однако возможен и другой исход. Битва за приоритет, сопровождавшая секвенирование генома, наглядно подтверждает важность доступности генетической информации. Давайте кратко вспомним некоторые факты из истории программы «Геном человека».
Противники расшифровки генома считали поставленную задачу нереальной, ведь ДНК человека в десятки тысяч раз длиннее молекул ДНК вирусов или плазмид. Главный аргумент против был: «проект потребует миллиарды долларов, которых недосчитаются другие области науки, поэтому геномный проект затормозит развитие науки в целом. А если все-таки деньги найдутся и геном человека будет расшифрован, то полученная в результате информация не оправдает затрат. » Однако Джеймс Уотсон, один из первооткрывателей структуры ДНК и идеолог программы тотального прочтения генетической информации, остроумно парировал: «лучше не поймать большую рыбу, чем не поймать маленькую» [1], [2]. Аргумент учёного был услышан — проблему генома вынесли на обсуждение в конгресс США, и в итоге была принята национальная программа «Геном человека».
В американском городе Бетесда, что недалеко от Вашингтона, находится один из координационных центров HUGO (HUman Genome Organization). Центр координирует научную работу по теме «Геном человека» в шести странах — Германии, Англии, Франции, Японии, Китае и США. В работу включились учёные из многих стран мира, объединенные в три команды: две межгосударственные — американская Human Genome Project и британская из Wellcome Trust Sanger Institute — и частная корпорация из штата Мериленд, включившаяся в игру чуть позже, — Celera Genomics. Кстати, это пожалуй первый случай в биологии, когда на таком высоком уровне частная фирма соревновалась с межгосударственными организациями.
Борьба происходила с использованием колоссальных средств и возможностей. Как отмечали некоторое время назад российские эксперты, Celera стояла на плечах у программы «Геном Человека», то есть использовала то, что уже было сделано в рамках глобального проекта. Действительно, Celera Genomics подключилась к программе не сначала, а когда проект уже шёл полным ходом. Однако специалисты из Celera усовершенствовали алгоритм секвенирования. Кроме того, по их заказу был построен суперкомпьютер, который позволял складывать выявляемые «кирпичики» ДНК в результирующую последовательность быстрее и точнее. Конечно, все это не давало компании Celera безоговорочного преимущества, однако считаться с ней как с полноправным участником гонки заставило.
Появление Celera Genomics резко повысило напряженность — те, кто был занят в государственных программах, почувствовали жёсткую конкуренцию. Кроме того, после создания компании остро встал вопрос об эффективности использования государственных капиталовложений. Во главе Celera стал профессор Крейг Вентер (Craig Venter) [3], который имел огромный опыт научной работы по государственной программе «Геном человека». Именно он и заявил, что все публичные программы малоэффективны и что в его фирме геном секвенируют быстрее и дешевле. А тут появился ещё один фактор — спохватились крупные фармацевтические компании. Дело в том, что если вся информация о геноме окажется в открытом доступе, они лишатся интеллектуальной собственности, и нечего будет патентовать. Озабоченные этим, они вложили миллиарды долларов в Celera Genomics (с которой, вероятно, было проще договориться). Это еще более укрепило её позиции. В ответ на это коллективам межгосударственного консорциума срочно пришлось повышать эффективность работ по расшифровке генома. Сначала работа шла несогласованно, но потом были достигнуты определенные формы сосуществования — и гонка начала наращивать темп.
Финал был красивым — конкурирующие организации по взаимной договоренности одновременно объявили о завершении работ по расшифровке генома человека [4], [5]. Произошло это, как мы уже писали — 26 июня 2000 года. Но разница во времени между Америкой и Англией вывела на первое место США.

Рисунок 1. «Гонка за генóм», в которой участвовали межгосударственная и частная компании, формально завершилась «ничьей»: обе группы исследователей опубликовали свои достижения практически одновременно. Руководитель частной компании Celera Genomics Крейг Вентер опубликовал свою работу в журнале Science в соавторстве с
270 учёными, работавшими под его началом [5]. Работа, выполненная международным консорциумом по секвенированию человеческого генома (IHGSC), опубликована в журнале Nature, и полный список авторов насчитывает около 2800 человек, работавших в почти трёх десятках центров по всему миру [4].
Исследования в сумме продлились 15 лет. Создание первого «чернового» варианта генома человека обошлось в 300 миллионов долларов. Однако на все исследования по этой теме, включая сравнительные анализы и решение ряда этических проблем, было выделено в сумме около трех миллиардов долларов. Celera Genomics вложила примерно столько же, правда, она истратила их всего за шесть лет. Цена колоссальная, но эта сумма ничтожна в сравнении с той выгодой, которую получит страна-разработчик от ожидаемой вскоре окончательной победы над десятками серьезных заболеваний. В начале октября 2002 года в интервью «Ассошиэйтед пресс» президент Celera Genomics Крейг Вентер заявил, что одна из его некоммерческих организаций планирует заняться изготовлением компакт-дисков, содержащих максимум информации о ДНК клиента. Предварительная стоимость такого заказа — более 700 тысяч долларов. А одному из первооткрывателей структуры ДНК — доктору Джеймсу Уотсону — уже в этом году были подарены два DVD-диска с его геномом общей стоимостью 1 млн. долларов [6], — как видим, цены падают. Так, вице-президент фирмы 454 Life Sciences Майкл Эгхолм (Michael Egholm) сообщил, что в скором времени компания сможет довести цену расшифровки до 100 тыс. долларов.
Широкая известность и масштабное финансирование — палка о двух концах. С одной стороны, за счет неограниченных средств работа продвигается легко и быстро. Но с другой стороны, результат исследований должен получиться таким, каким его заказывают. К началу 2001 года в геноме человека со стопроцентной достоверностью было идентифицировано больее 20 тыс. генов. Эта цифра оказалось в три раза меньше, чем было предсказано всего за два года до этого. Вторая команда исследователей из Национального института геномных исследований США во главе с Френсисом Коллинсом независимым способом получила те же результаты — между 20 и 25 тыс. генов в геноме каждой человеческой клетки. Однако неопределенность в окончательные оценки внесли два других международных совместных научных проекта. Доктор Вильям Хезелтайн (руководитель фирмы Human Genome Studies) настаивал, что в их банке содержится информация о 140 тыс. генов. И этой информацией он не собирается пока делиться с мировой общественностью. Его фирма вложила деньги в патенты и собирается зарабатывать на полученной информации, поскольку она относится к генам широко распространенных болезней человека. Другая группа заявила о 120 тыс. идентифицированных генов человека и также настаивала, что именно эта цифра отражает общее число генов человека.
Тут необходимо уточнить, что эти исследователи занимались расшифровкой последовательности ДНК не самого генома, а ДНК-копий информационных (называемых также матричными) РНК (иРНК или мРНК). Другими словами, исследовался не весь геном, а только та его часть, что перекодируется клеткой в мРНК и направляет синтез белков. Поскольку один ген может служить матрицей для производства нескольких различных видов мРНК (что определяется многими факторами: тип клетки, стадия развития организма и т. д.), то и суммарное число всех различных последовательностей мРНК (а это именно то, что запатентовала Human Genome Studies) будет значительно бóльшим. Скорее всего, использовать это число для оценки количества генов в геноме просто некорректно.
Очевидно, что наспех «приватизированная» генетическая информация будет в ближайшие годы тщательно проверяться, пока точное число генов станет, наконец, общепринятым. Но настораживает тот факт, что в процессе «познания» патентуется вообще все, что только можно запатентовать. Тут даже не шкура не убитого медведя, а вообще все, что находилось в берлоге, было поделено! Кстати, на сегодня дебаты сбавили обороты, и геном человека официально насчитывает только 21667 генов (версия NCBI 35, датированная октябрём 2005 года). Следует отметить, что пока большая часть информации всё-таки остаётся общедоступной. Сейчас существуют базы данных, в которых аккумулирована информация о структуре генома не только человека, но и геномов многих других организмов (например, EnsEMBL). Однако попытки получить исключительные права на использование каких-либо генов или последовательностей в коммерческих целях всегда были, есть сейчас и будут предприниматься впредь.
На сегодня основные цели структурной части программы уже в основном выполнены — геном человека почти полностью прочитан. Первый, «черновой» вариант последовательности, опубликованный в начале 2001 года [4], был далек от совершенства. В нём отсутствовало приблизительно 30% последовательности генома в целом, из них около 10% последовательности так называемого эухроматина — богатых генами и активно экспрессирующихся участков хромосом. Согласно последним подсчётам, эухроматин составляет примерно 93,5% от всего генома [7]. Оставшиеся же 6,5% приходятся на гетерохроматин — эти участки хромосом бедны генами и содержат большое количество повторов, которые представляют серьезные трудности для ученых, пытающихся прочесть их последовательность [8]. Более того, считается, что ДНК в гетерохроматине находится в неактивном состоянии и не экспрессируется. (Этим можно объяснить такое «невнимание» ученых к оставшимся «малым» процентам человеческого генома.) Но даже имевшиеся на 2001 год «черновые» варианты эухроматиновых последовательностей содержали большое количество разрывов, ошибок и неверно соединенных и ориентированных фрагментов. Нисколько не умаляя значения для науки и ее приложений появление этого «черновика», стоит однако отметить, что использование этой предварительной информации в крупномасштабных экспериментах по анализу генома в целом (например, при исследовании эволюции генов или общей организации генома) выявило множество неточностей и артефактов. Поэтому дальнейшая и не менее кропотливая работа, «последние вершки», была абсолютно необходима.

Рисунок 2. Слева: Автоматизированная линия подготовки образцов ДНК для секвенирования в Центре Геномных исследований института Уайтхеда. Справа: Лаборатория в Сэнгеровском институте, заполненная автоматами для высокопроизводительной расшифровки последовательностей ДНК.
Завершение расшифровки заняло еще несколько лет и привело почти что к удвоению стоимости всего проекта. Однако уже в 2004 г. было объявлено, что эухроматин прочитан на 99% с общей точностью одна ошибка на 100 000 пар оснований. Количество разрывов уменьшилось в 400 раз. Аккуратность и полнота прочтения стала достаточной для эффективного поиска генов, отвечающих за то или иное наследственное заболевание (например, диабет или рак груди). Практически это означает, что исследователям больше не надо заниматься трудоемким подтверждением последовательностей генов, с которыми они работают, так как можно полностью положиться на определенную и доступную каждому последовательность всего генома.
Таким образом, изначальный план проекта был значительно перевыполнен. Помогло ли это нам в понимании того, как устроен и работает наш геном? Безусловно. Авторы статьи в Nature, в которой был опубликован «окончательный» (на 2004 год) вариант генома [7], провели с его использованием несколько анализов, которые были бы абсолютно бессмысленны, имей они на руках только «черновую» последовательность. Оказалось, что более тысячи генов «родились» совсем недавно (по эволюционным меркам, конечно) — в процессе удвоения исходного гена и последующего независимого развития дочернего гена и гена-родителя. А чуть меньше сорока генов недавно «умерли», накопив мутации, сделавшие их совершенно неактивными. Другая статья, вышедшая в том же номере журнала Nature, прямо указывает на недостатки метода, использованного учеными из Celera [9]. Следствием этих недостатков стали пропуски многочисленных повторов в прочитанных последовательностях ДНК и, как результат, недооценённая длина и сложность всего генома. Чтобы не повторять подобных ошибок в будущем, авторы статьи предложили использовать гибридную стратегию — комбинацию высокоэффективного подхода, использовавшегося учеными из Celera, и сравнительно медленного и трудоемкого, но и более надежного метода, применявшегося исследователями из IHGSC.
Куда дальше будет направлено беспрецедентное исследование «Геном человека»? Кое-что об этом можно сказать уже сейчас. Основанный в сентябре 2003 года международный консорциум ENCODE (ENCyclopaedia Of DNA Elements) поставил своей целью обнаружение и изучение «управляющих элементов» (последовательностей) в геноме человека. Действительно, ведь 3 млрд. пар оснований (а именно такова длина генома человека) содержат всего лишь 22 тыс. генов, разбросанных в этом океане ДНК непонятным для нас образом. Что управляет их экспрессией? Зачем нам такой избыток ДНК? Действительно ли он является балластом, или же все-таки проявляет себя, обладая какими-то неизвестными функциями [10]?
Для начала, в качестве пилотного проекта, ученые из ENCODE «пристально вгляделись» в последовательность, составляющую 1% от генома человека (30 млн. пар оснований), используя новейшее оборудование для исследований в молекулярной биологии. Результаты были опубликованы в апреле нынешнего года в Nature [11]. Оказалось, что бóльшая часть генома человека (в том числе участки, считавшиеся ранее «молчащими») служит матрицей для производства различных РНК, многие из которых не являются информационными, поскольку не кодируют белков. Многие из этих «некодирующих» РНК перекрываются с «классическими» генами (участками ДНК, кодирующими белки). Неожиданным результатом было и то, как регуляторные участки ДНК были расположены относительно генов, экспрессией которых они управляли. Последовательности многих из этих участков мало изменялись в процессе эволюции, в то время как другие участки, считавшиеся важными для управления клеткой, мутировали и изменялись в процессе эволюции с неожиданно высокой скоростью [10]. Все эти находки поставили большое количество новых вопросов, ответы на которые можно получить лишь в дальнейших исследованиях.
Другая задача, решение которой станет делом недалекого будущего, — определение последовательности оставшихся «малых» процентов генома, составляющих гетерохроматин, т. е. бедных генами и богатых повторами участков ДНК, необходимых для удвоения хромосом в процессе деления клетки. Наличие повторов делает задачу расшифровки этих последовательностей неразрешимой для существующих подходов, и, следовательно, требует изобретения новых методов. Поэтому не удивляйтесь, когда году в 2010 выйдет очередная статья, объявляющая об «окончании» расшифровки генома человека — в ней будет рассказано о том, как был «взломан» гетерохроматин.
Конечно, сейчас в нашем распоряжении имеется лишь некий «усредненный» вариант человеческого генома. Образно говоря — мы сегодня имеем лишь самое общее описание конструкции автомобиля: мотор, ходовая часть, колёса, руль, сиденья, краска, обивка, бензин с маслом и т. д. Ближайшее рассмотрение полученного результата свидетельствует о том, что впереди — годы работ по уточнению наших знаний по каждому конкретному геному. Программа «Геном человека» не прекратила свое существование, она лишь меняет ориентацию: от структурной геномики осуществляется переход к геномике функциональной, предназначенной установить, как управляются и работают гены. Более того, все люди на уровне генов отличаются так же, как одни и те же модели автомобилей отличаются различными вариантами исполнения одних и тех же агрегатов. Не только отдельные основания в последовательностях генов двух разных людей могут отличаться, но и количество копий крупных фрагментов ДНК, порой включающих в себя несколько генов, может сильно варьировать. А это означает, что на передний план выходят работы по детальному сравнению геномов, скажем, представителей различных человеческих популяций, этнических групп, и даже здоровых и больных людей. Современные технологии позволяют быстро и точно проводить такие сравнительные анализы, а ведь еще лет десять назад об этом никто и не мечтал. Изучением структурных вариаций человеческого генома занимается очередное международное научное объединение. В США и Европе значительные средства выделяются на финансирование биоинформатики — молодой науки, возникшей на стыке информатики, математики и биологии, без которой никак не разобраться в безграничном океане информации, накопленном в современной биологии. Биоинформационные методы помогут нам ответить на многие интереснейшие вопросы — «как происходила эволюция человека?», «какие гены определяют те или иные особенности человеческого организма?», «какие гены ответственны за предрасположенность к болезням?» Знаете, как говорят англичане: “This is the end of the beginning” — «Это конец начала». Вот именно эта фраза точно отражает нынешнюю ситуацию [12]. Начинается самое главное и — я совершенно уверен — самое интересное: накопление результатов, их сравнение и дальнейший анализ.
«. Сегодня мы выпускаем в свет первое издание „Книги жизни“ с нашими инструкциями, — сказал в эфире телеканала «Россия» Фрэнсис Коллинз. — Мы будем обращаться к нему десятки, сотни лет. И уже скоро люди зададутся вопросом, как они могли обходиться без этой информации».
Другую точку зрения можно проиллюстрировать, процитировав академика Кордюма В. А.:
«. Надежды же на то, что новая информация о функциях генома будет полностью открытой, чисто символические. Можно прогнозировать, что возникнут (на базе уже имеющихся) гигантские центры, которые смогут все данные соединить в одно связное целое, некую электронную версию Человека и реализовывать её практически — в гены, белки, клетки, ткани, органы и что угодно ещё. Но во что? Угодное кому? Для чего? В процессе работ по программе „геном человека“ стремительно совершенствовались методы и аппаратура для определения первичной последовательности ДНК. В крупнейших центрах это превратилось в некое подобие заводской деятельности. Но даже на уровне лабораторных индивидуальных приборов (вернее их комплексов) уже создано столь совершенное оборудование, что оно способно определить за три месяца такую по объему последовательность ДНК, которая равна всему геному человека. Не удивительно, что возникла (и тут же начала стремительно реализоваться) идея определения геномов индивидуальных людей. Безусловно, это очень интересно — сравнить отличия разных индивидуумов на уровне их первоосновы. Польза от такого сравнения тоже несомненная. Можно будет установить, у кого имеются какие нарушения в геноме, прогнозировать их последствия и устранить то, что может привести к болезням. Здоровье будет гарантированным, да и жизнь продлится весьма существенно. Это с одной стороны. С другой же стороны всё совсем не очевидно. Получить и проанализировать всю наследственность индивидуума означает получение полного, исчерпывающего биологического досье на него. Оно, при желании того, кто его знает, позволит столь же исчерпывающе делать с человеком всё что угодно. По уже известной цепочке: клетка — молекулярная машина; человек состоит из клеток; клетка во всех своих проявлениях и во всём диапазоне возможных ответов, записана в геноме; с геномом можно ограниченно уже и сегодня манипулировать, а в обозримом будущем вообще манипулировать практически как угодно. »
Однако, наверное, пугаться таких мрачных прогнозов еще рано (хотя знать о них, безусловно, нужно). Для их осуществления надо полностью перестраивать многие социальные и культурные традиции. Очень хорошо по этому поводу сказал в интервью доктор биологических наук Михаил Гельфанд, и. о. заместителя директора Института проблем передачи информации РАН: «. если у вас есть, предположим, один из пяти генов, предопределяющих развитие шизофрении, то что может случиться, если эта информация — ваш геном — попала в руки вашего потенциального работодателя, который ничего в геномике не понимает! (и как следствие — вас на работу могут не принять, посчитав это рискованным; и это не смотря на то, что шизофрении у вас нет и не будет — прим. автора.) Другой аспект: с появлением индивидуализированной медицины, основанной на геномике, полностью изменится страховая медицина. Ведь одно дело — предусматривать риски неизвестные, а другое дело — совершенно определенные. Если честно, то все западное общество в целом, не только российское, к геномной революции сейчас не готово. » [13].
Действительно, чтобы разумно пользоваться новой информацией, надо ее понимать. А для того чтобы понять геном — не просто прочитать, этого далеко не достаточно, — нам потребуются десятилетия. Слишком уж сложная картина вырисовывается, и чтобы осознать её, нам надо будет поменять многие стереотипы. Поэтому на самом деле расшифровка генома ещё продолжается и будет продолжаться. И будем ли мы стоять в стороне или станем, наконец, активными участниками этой гонки — зависит от нас.



