В чем разница между параметром и гиперпараметром?
Дата публикации 2017-07-26
Это может сбивать с толку, когда вы начинаете в прикладном машинном обучении.
Есть так много терминов, которые можно использовать, и многие из этих терминов могут не использоваться последовательно. Это особенно верно, если вы пришли из другой области обучения, в которой могут использоваться те же термины, что и машинное обучение, но они используются по-разному.
Например: термины «параметр модели» а также «модельный гиперпараметр«.
Отсутствие четкого определения этих терминов является обычной борьбой для начинающих, особенно тех, которые пришли из области статистики или экономики.
В этом посте мы подробнее рассмотрим эти термины.

Что такое параметр модели?
Параметры являются ключевыми для алгоритмов машинного обучения. Они являются частью модели, которая извлекается из исторических данных обучения.
Часто параметры модели оцениваются с использованием алгоритма оптимизации, который является типом эффективного поиска по возможным значениям параметров.
Имеет ли модель фиксированное или переменное число параметров, определяет, можно ли ее назвать «параметрический» или же «непараметрический«.
Некоторые примеры параметров модели включают в себя:
Что такое модельный гиперпараметр?
Мы не можем знать лучшее значение для гиперпараметра модели в данной задаче. Мы можем использовать практические правила, копировать значения, используемые для других задач, или искать лучшее значение методом проб и ошибок.
Когда алгоритм машинного обучения настроен на конкретную проблему, например, когда вы используете поиск по сетке или случайный поиск, вы настраиваете гиперпараметры модели или порядок, чтобы обнаружить параметры модели, которые приводят к наиболее умелому прогнозы.
Многие модели имеют важные параметры, которые не могут быть непосредственно оценены по данным. Например, в модели классификации K-ближайшего соседа… Этот тип параметра модели называется параметром настройки, поскольку для расчета подходящего значения нет аналитической формулы.
Гиперпараметры модели часто называют параметрами модели, которые могут привести к путанице. Хорошее практическое правило для преодоления этой путаницы заключается в следующем:
Если вам нужно указать параметр модели вручную, то
это, вероятно, гиперпараметр модели.
Некоторые примеры гиперпараметров модели включают в себя:
Дальнейшее чтение
Резюме
В этом посте вы обнаружили четкие определения и разницу между параметрами модели и гиперпараметрами модели.
Таким образом, параметры модели оцениваются на основе данных автоматически, а гиперпараметры модели устанавливаются вручную и используются в процессах для оценки параметров модели.
Гиперпараметры модели часто называют параметрами, потому что они являются частями машинного обучения, которые должны быть установлены вручную и настроены.
Помог ли этот пост разобраться в путанице?
Позвольте мне знать в комментариях ниже.
Существуют ли параметры модели или гиперпараметры, в которых вы все еще не уверены?
Опубликуйте их в комментариях, и я сделаю все возможное, чтобы прояснить ситуацию дальше.
Настройка гиперпараметров
Содержание
Гиперпараметр [ править ]
Гиперпараметр (англ. hyperparameter) — параметр, который не настраивается во время обучения модели. Пример гиперпараметра — шаг градиентного спуска, он задается перед обучением. Пример параметров — веса градиентного спуска, они изменяются и настраиваются во время обучения.
Для подбора гиперпараметров необходимо разделить датасет на три части:
Зачем нам нужен и валидационный, и тестовый набор? Дело в том, что модель может переучиться на валидационном наборе данных. Для выявления переобучения используется тестовый набор данных.
Рассмотрим модель KNeighborsClassifier из библиотеки sklearn. Все “параметры” данной модели (loss, penalty, alpha и т.д), с точки зрения машинного обучения, являются гиперпараметрами, так как задаются до начала обучения.
Поиск по сетке [ править ]
Общая информация [ править ]
Поиск по сетке (англ. Grid search) принимает на вход модель и различные значения гиперпараметров (сетку гиперпараметров). Далее, для каждого возможного сочетания значений гиперпараметров, метод считает ошибку и в конце выбирает сочетание, при котором ошибка минимальна.
Поиск по сетке в Sklearn: использование [ править ]
Пример использования GridSearch из библиотеки scikit-learn:
Поиск по сетке в Sklearn: важные атрибуты [ править ]
Реализация поиска по сетке в библиотеках [ править ]
Случайный поиск по сетке [ править ]
Основная информация [ править ]
Случайный поиск по сетке (англ. Random Grid Search) вместо полного перебора работает с некоторыми, случайным образом выбранными, комбинациями. На основе полученных результатов, происходит сужение области поиска.
Когда случайный поиск по сетке будет гораздо полезнее, чем просто поиск по сетке? В ситуации, когда гиперпараметров много, но сильно влияющих на конечную производительность алгоритма — мало.
Реализация случайного поиска по сетке [ править ]
Последовательная оптимизация по модели [ править ]
Основная информация [ править ]
Последовательная оптимизация по модели (англ. Sequential Model-Based Optimization, SMBO) используются когда оптимизация целевой функции будет стоить очень «дорого». Главная идея SMBO — замена целевой функции «суррогатной» функцией.
На каждом шаге работы SMBO:
Существует четыре ключевые аспекта SMBO:
Методы SMBO отличаются между собой вероятностными моделями и функциями выбора:
Популярные вероятностные модели (суррогатные функции):
Древовидный парзеновский оценщик [ править ]
Основная информация [ править ]
[math]
[math] p(x|y) = \begin
Алгоритм [ править ]
Последовательная конфигурация алгоритма на основе модели [ править ]
Основная информация [ править ]
Последовательная конфигурация алгоритма на основе модели (англ. Sequential Model-based Algorithm Configuration, SMAC) расширяет подходы SMBO:
Понимание гиперпараметров и методов их оптимизации
Дата публикации Jul 3, 2018
В любом алгоритме машинного обучения эти параметры должны быть инициализированы перед обучением модели.
Параметры модели и гиперпараметры
Параметры моделиявляются свойствами данных обучения, которые будут изучаться самостоятельно во время обучения классификатором или другой моделью ML. Например,

Модель гиперпараметровявляются свойствами, которые управляют всем процессом обучения. Ниже приведены переменные, которые обычно настраиваются перед обучением модели.
Почему гиперпараметры необходимы?
Гиперпараметры важны, потому что они напрямую управляют поведением алгоритма обучения и оказывают существенное влияние на производительность обучаемой модели.
«Хороший выбор гиперпараметров может действительно сделать алгоритм блестящим».
Выбор подходящих гиперпараметров играет решающую роль в успехе нашей архитектуры нейронной сети. Так как это оказывает огромное влияние на усвоенную модель. Например, если скорость обучения слишком низкая, модель пропустит важные шаблоны в данных. Если оно высокое, оно может иметь столкновения.
Выбор хороших гиперпараметров дает два преимущества:
Методы оптимизации гиперпараметров
Процесс поиска наиболее оптимальных гиперпараметров в машинном обучении называется оптимизацией гиперпараметров.
Общие алгоритмы включают в себя:
Grid Search
Поиск по сетке обучает алгоритм для всех комбинаций, используя два набора гиперпараметров (скорость обучения и количество слоев), и измеряет производительность, используя «Перекрестная проверкаТехника. Этот метод проверки дает уверенность в том, что наша обученная модель получила большинство шаблонов из набора данных. Один из лучших методов проверки с помощью «K-Fold Cross Validation”, Которая помогает предоставить достаточные данные для обучения модели и достаточные данные для валидации.

Метод поиска по сетке является более простым алгоритмом, но он страдает, если данные имеют большое размерное пространство, называемоепроклятие размерности,
Случайный поиск
Произвольно выбирает пространство поиска и оценивает наборы из заданного распределения вероятностей. Например, вместо того, чтобы пытаться проверить все 100 000 выборок, мы можем проверить 1000 случайных параметров.

Недостаток использования алгоритма случайного поиска, однако, это то, что он не использует информацию из предыдущих экспериментов для выбора следующего набора, а также очень трудно предсказать следующий из экспериментов.
Байесовская оптимизация
Настройка гиперпараметра максимизирует производительность модели на наборе проверки. Алгоритмы машинного обучения часто требуют точной настройки гиперпараметров модели. К сожалению, этот тюнинг часто называют ‘черная функцияПотому что это не может быть записано в формулу, поскольку производные функции неизвестны.
Гораздо более привлекательным способом оптимизации и настройки гиперпараметров являютсявключение подхода автоматической настройки моделис помощью байесовского алгоритма оптимизации, Модель, используемая для аппроксимации целевой функции, называетсясуррогатная модель,Популярной суррогатной моделью для байесовской оптимизации является гауссовский процесс (GP), Байесовская оптимизация обычно работает, предполагая, что неизвестная функция была выбрана из гауссовского процесса (GP), и поддерживает апостериорное распределение для этой функции во время наблюдений.
При выполнении байесовской оптимизации необходимо сделать два основных выбора.
Гауссовский процесс
Гауссовский процесс определяет априорное распределение по функциям, которые могут быть преобразованы в апостериорные по функциям, как только мы увидим некоторые данные Гауссовский процесс использует ковариационную матрицу, чтобы обеспечить близкие значения. Ковариационная матрица вместе со среднимμфункция для вывода ожидаемого значенияƒ (х)определяет гауссовский процесс.
1. Гауссовский процесс будет использоваться какпредшествующийдля байесовского вывода
2. Для вычислениязаднийявляется то, что это может быть использовано для прогнозирования невидимых тестовых случаев.


Функция приобретения
Введение данных выборки в пространство поиска осуществляется функциями сбора данных. Это помогает максимизировать функцию сбора данных для определения следующей точки отбора. Популярные функции приобретения
Ожидаемое улучшение (EI)функция кажется популярной. Определяется как
Резюме:
Подбор гиперпараметров ML-модели с помощью HYPEROPT

В машинном обучении гиперпараметрами называют параметры модели, значения которых устанавливаются перед запуском процесса её обучения. Ими могут быть, как параметры самого алгоритма, например, глубина дерева в random forest, число соседей в knn, веса нейронов в нейронный сетях, так и способы обработки признаков, пропусков и т.д. Они используются для управления процессом обучения, поэтому подбор оптимальных гиперпараметров – очень важный этап в построении ML-моделей, позволяющий повысить точность, а также бороться с переобучением. На сегодняшний день существуют несколько популярных подходов к решению задачи подбора, например:
1. Поиск по решётке. В этом способе значения гиперпараметров задаются вручную, затем выполняется их полный перебор. Популярной реализацией этого метода является Grid Search из sklearn. Несмотря на свою простоту этот метод имеет и серьёзные недостатки:
Очень медленный т.к. надо перебрать все комбинации всех параметров. Притом перебор будет продолжаться даже при заведомо неудачных комбинациях.
Часто в целях экономии времени приходится укрупнять шаг перебора, что может привести к тому, что оптимальное значение параметра не будет найдено. Например, если задан диапазон значений от 100 до 1000 с шагом 100 (примером такого параметра может быть количество деревьев в случайном лесе, или градиентном бустинге), а оптимум находится около 550, то GridSearch его не найдёт.
2. Случайный поиск. Здесь параметры берутся случайным образом из выборки с указанным распределением. В sklearn он этот метод реализован как Randomized Search. В большинстве случаев он быстрее GridSearch, к тому же значения параметров не ограничены сеткой. Однако, даже это не всегда позволяет найти оптимум и не защищает от перебора заведомо неудачных комбинаций.
3. Байесовская оптимизация. Здесь значения гиперпараметров в текущей итерации выбираются с учётом результатов на предыдущем шаге. Основная идея алгоритма заключается в следующем – на каждой итерации подбора находится компромисс между исследованием регионов с самыми удачными из найденных комбинаций гиперпараметров и исследованием регионов с большой неопределённостью (где могут находиться ещё более удачные комбинации). Это позволяет во многих случаях найти лучшие значения параметров модели за меньшее количество времени.
В этой статье приведён обзор hyperopt – популярной python-библиотеки для подбора гиперпарметров. В ней реализовано 3 алгоритма оптимизации: классический Random Search, метод байесовской оптимизации Tree of Parzen Estimators (TPE), и Simulated Annealing – метод имитации отжига. Hyperopt может работать с разными типами гиперпараметров –непрерывными, дискретными, категориальными и т.д, что является важным преимуществом этой библиотеки.
Установить hyperopt очень просто:
В данных есть признаки разных типов, которые, соответственно, требуют и разной обработки. Для этого воспользуемся методом ColumnTransformer из библиотеки sklearn, который позволяет задать свой способ обработки для каждой группы признаков. Для категориальных признаков (тип object) будем использовать методы SimpleImputer (заменяет пропуски, которые обозначены символом «?») и OneHotEncoder (выполняет dummy-кодирование). Числовые признаки (остальные типы) будем масштабировать с помощью StandardScaler. В качестве модели выберем логистическую регрессию.
Сформируем пространство поиска параметров для hyperopt:
Зададим функцию, которую будем оптимизировать. Она принимает на вход гиперпараметры, модель и данные, после чего возвращает точность на кросс-валидации:
Укажем объект для сохранения истории поиска (Trials). Это очень удобно, т.к. можно сохранять, а также прерывать и затем продолжать процесс поиска гиперпараметров. И, наконец, запускаем сам процесс подбора с помощью функции fmin. Укажем в качестве алгоритма поиска tpe.suggest – байесовскую оптимизацию. Для Random Search нужно указать tpe.rand.suggest.
Выведем результаты в pandas DataFrame с помощью специальной функции и визуализируем:

На графике видно, что Hyperopt почти не исследовал районы, где получались низкие значения roc auc, а сосредоточился на районе с наибольшими значениями этой метрики.
Таким образом, hyperopt – мощный инструмент для настройки модели, которым легко и удобно пользоваться. Дополнительные материалы можно найти в репозитории (для нескольких моделей), а также в 1, 2, 3, 4.
Гиперпараметры: как перестать беспокоиться и начать их оптимизировать
«Подбор гиперпараметров». Если у вас в голове при произнесении этой фразы прокатились несколько панических атак и непроизвольно задергался глаз, а, возможно, и рука в инстинктивном желании перевернуть стол с криками «Да ну его, этот ваш дата сайнс» (нецензурную брань оставим за скобками), значит вы, как и я, хоть раз пытались обучить наивный байес мало-мальски тяжелую модель на большом объеме данных.

Размер батча, learning rate, размер того слоя, размер сего слоя, вероятность dropout-a. Страшно? Уже представляете часы (дни) ожидания? А это я еще про количество голов у трансформеров не говорил…

Короче говоря, подбор гиперпараметров – это всегда боль любого датасаентолога. При этом известно, что пренебрежение этой процедурой может привести к большой потере в качестве или в производительности при решении любой задачи анализа данных, а в случае если вы предлагаете какой-то инновационный подход, то к построению слабого бейзлайна (this).
Процедуры RandomSearch и GridSearch известны нам всем из любого начального курса по машинному обучению. Однако немногие знают, или, по крайней мере, немногие используют при решении своих задач более изощренные методы оптимизации гиперпараметров. Мне давно было интересно разобраться, как работают подобные методы и действительно ли они дают существенный выигрыш во времени по сравнению с классикой. В данной статье я быстренько пройдусь по вышеупомянутым GridSearch и RandomSearch, постараюсь привести интуитивное объяснение, как работают байесовские алгоритмы оптимизации гиперпараметров, а также протестирую несколько существующих фреймворков (hyperopt, scikit-optimize, optuna) на одной из задач NLP.
Постановка задачи
Для начала стоит отметить, что алгоритмы оптимизации гиперпараметров работают с моделью, как с черным ящиком (с оракулом, если вам ближе язык оптимизации): им неважно, как работает модель, важно только значение функционала качества модели, обученной с рассматриваемыми гиперпараметрами. Поставим задачу более формально, описав её ДНК (Дано, Найти, Критерий (здравствуйте, Константин Вячеславович)).
Пространство гиперпараметров  где
где  – пространство
– пространство  -го параметра. Данные
-го параметра. Данные  .
.
Найти

где  измеряет функцию потерь модели
измеряет функцию потерь модели  , обученной при гиперпараметрах
, обученной при гиперпараметрах  на
на  и провалидированной на
и провалидированной на  [1].
[1].
Критерий
GridSearch, RandomSearch
Собственно, смысл этих подходов описан в их названии. «GridSearch» дословно обозначает «поиск по сетке», то есть «тупой экспоненциальный перебор всех узлов сетки параметров». Для RandomSearch всё слегка хитрее: он не просто перебирает все узлы сетки, а семплирует очередную точку на каждом шаге оптимизации.
Думаю, многие видели подобную картинку в доказательство превосходства RandomSearch. Поиск по сетке слишком завязан на координатах, которые вы ему подаете на вход. Случайный поиск же менее зависим от человека и вполне может попасть в точку пространства, которая ближе к оптимуму (конечно, если эти точки распределены не категориально [спойлер: в наших экспериментах они распределены категориально]).
Bayesian optimization
По сути, байесовский подход – это модификация случайного поиска. Подумайте сами: как бы вы могли улучшить RandomSearch? Очевидно, что хочется чаще семплировать в окрестности тех точек, которые дают больший прирост в качестве. Собственно, так же подумали и байесиане байесологи свидетели Байеса исследователи байесовской статистики и байесовской оптимизации. Был предложен подход, основанный на идее, что для выбора лучшей области пространства гиперпараметров следует учитывать историю уже рассмотренных точек, в которых были обучены модели и получены значения целевой функции. Данный метод оптимизации гиперпараметров получил название SMBO (Sequential Model-Based Optimization).
Sequential Model-Based Optimization (SMBO)
Источник изображения: [3]
SMBO включает в себя два ключевых ингредиента: вероятностная суррогатная модель (surrogate model) (  в приведенном выше алгоритме) и функция выбора (acquisition function) следующей точки (
в приведенном выше алгоритме) и функция выбора (acquisition function) следующей точки (  в приведенном выше алгоритме). На каждой итерации суррогатная модель обучается по всем полученным ранее выходам целевой функции. Таким образом, мы стараемся получить более дешевую аппроксимацию целевой функции. Далее функция выбора, используя предсказательное распределение суррогатной модели, оценивает «пользу» различных следующих точек, балансируя между использованием уже имеющейся информации и «разведыванием» новой области пространства (exploration vs exploitation). [1]
в приведенном выше алгоритме). На каждой итерации суррогатная модель обучается по всем полученным ранее выходам целевой функции. Таким образом, мы стараемся получить более дешевую аппроксимацию целевой функции. Далее функция выбора, используя предсказательное распределение суррогатной модели, оценивает «пользу» различных следующих точек, балансируя между использованием уже имеющейся информации и «разведыванием» новой области пространства (exploration vs exploitation). [1]
Источник изображения: [1]
Если проводить аналогию с обычной задачей машинного обучения, то функция выбора – это функция качества для мета-алгоритма SMBO, а суррогатная модель – это модель, которую мы получаем на выходе этого мета-алгоритма. Примерами функции выбора могут служить Expected Improvement, Probability of Improvement и т.п. Здесь и далее будет использоваться Expected Improvement, если не оговорено иное:

•  – некоторый порог значения функционала качества,
– некоторый порог значения функционала качества,
•  – суррогатная вероятностная модель получения
– суррогатная вероятностная модель получения  при выбранных гиперпараметрах и истории
при выбранных гиперпараметрах и истории  . [2]
. [2]
Таким образом, после некоторого количества итераций SMBO мы получаем какую-то аппроксимацию  нашей целевой функции . При этом, значения стоит получить гораздо дешевле, чем значения
нашей целевой функции . При этом, значения стоит получить гораздо дешевле, чем значения  .
.
Если говорить о суррогатных моделях, одними из наиболее популярных являются гауссовские процессы (Gaussian Processes (GP)) и парзеновские деревья (Tree-Structured Parzen Estimators (TPE)).

Согласен, остановимся на этом чуть подробнее.
Gaussian Processes
При использовании гауссовских процессов целевая функция аппроксимируется в виде апостериорного распределения значений при выбранных параметрах и известной истории (). В качестве априорного распределения выбирается нормальное с константным матожиданием и изменяемой функцией ковариации:  .
.
Tree Parzen Estimators
В отличие от GP, которые напрямую моделируют  , данная стратегия моделирует
, данная стратегия моделирует  и
и  . Для этого априорные вероятности распределения каждого из гиперпараметров заменяются на их непараметрические аналоги. При этом, подобные замены позволяют использовать все имеющиеся точки пространства, моделируя сразу несколько распределений:
. Для этого априорные вероятности распределения каждого из гиперпараметров заменяются на их непараметрические аналоги. При этом, подобные замены позволяют использовать все имеющиеся точки пространства, моделируя сразу несколько распределений:

Стоит заметить, что в GP все точки из области  y^*$» data-tex=»inline»/> просто отбрасывались при использовании апостериорной вероятности в EI.
y^*$» data-tex=»inline»/> просто отбрасывались при использовании апостериорной вероятности в EI.
Алгоритм выбирает как некоторый  -квантиль среди всех полученных (в отличие от гауссовских процессов, где обычно выбирается как наименьшее значение лосса (функционала качества) из всей истории). В итоге можно показать [3], что
-квантиль среди всех полученных (в отличие от гауссовских процессов, где обычно выбирается как наименьшее значение лосса (функционала качества) из всей истории). В итоге можно показать [3], что

Из формулы можно увидеть, что для максимизации EI необходимо с высокой вероятностью брать точки из  и с низкой – из
и с низкой – из  . Подобный компромисс как раз решает проблему «exploration vs. exploitation».
. Подобный компромисс как раз решает проблему «exploration vs. exploitation».
В статье [3], где был впервые представлен TPE, приводилось его сравнение с GP, где TPE показал себя сильно лучше.
Эксперименты
Постановка эксперимента
Данные
Для эксперимента решено было взять задачу sentiment-analysis на датасете Large Movie Reviews Dataset. Датасет представляет собой сбалансированную выборку отрицательных и положительных отзывов о фильмах с imdb. В данном эксперименте нашей целью стояло не получение SOTA (state-of-the-art)-качества на конкретной задаче, а сравнение существующих фреймворков для оптимизации гиперпараметров с точки зрения конечного качества, удобства и скорости работы. Поэтому для преобразования слов в векторные представления мы взяли базовые предобученные 300-мерные fasttext эмбеддинги для английского языка, для 16 миллиардов токенов. При этом токенизация производилась простым TweetTokenizer из nltk без какой-либо дополнительной предобработки слов.
Модель и обучение
Мы выбрали модель на основе LSTM из pytorch со следующими конфигурируемыми гиперпараметрами:
Помимо этого, я также изменял
Изначально еще хотелось покрутить dropout, но для уменьшения мощности пространства гиперпараметров решено было зафиксировать его на значении 0.5. Как уже говорилось, в данной статье мы не гнались за SOTA-качеством. Поэтому распределение каждого из параметров было решено сделать категориальным с одинаковыми вероятностями (проще говоря, представить в виде сетки) для еще большего уменьшения мощности пространства. Вся сетка гиперпараметров выглядит следующим образом:
Чтобы не переобучать все модели для каждого отдельного оптимизатора (а каждый оптимизатор может еще и несколько раз оказываться в одинаковых точках пространства), было решено разбить эксперимент на 3 этапа:
На первом этапе во время обучения кешируется куча всего, в том числе качество модели на валидационной и тестовой выборках и время обучения/теста модели. Обучение происходит в течение 20 эпох.
На втором этапе при попадании в очередную точку пространства мы просто подгружаем уже имеющееся у нас accuracy на валидации, учитывая потраченное на обучение время. Стоит отметить, что часто возникает ситуация, что оптимизатор приходит несколько раз в одну и ту же точку пространства. В таких случаях мы полагаем, что модель бы у нас уже была обучена, и не учитываем время обучения повторно.
На третьем этапе мы получаем уже закешированное качество конечной модели на тесте, учитывая время, потраченное на тест во время 1 этапа.
Рассмотренные фреймворки
В качестве бейзлайнов для сравнения я взял, собственно RandomSearch и GridSearch, написав их оптимизаторы собственноручно (см. github).
Для сравнения всех методов было решено отслеживать:
Помимо этого, я приведу плюсы и минусы каждого из фреймворков, выявленные мной в процессе экспериментирования с каждым из них, именно с точки зрения удобства, не качества решения задачи.
hyperopt
Судя по тому, что работа над фреймворком ведется аж с 2013 года при практически полном отсутствии документации, развивается он не слишком бойко (а, возможно, вообще доживает свой век). Также на сайте документации есть любопытная фраза: «Hyperopt has been designed to accommodate Bayesian optimization algorithms based on Gaussian processes and regression trees, but these are not currently implemented«, то бишь изначально запланированные алгоритмы так и не были реализованы. Также в документации есть про распараллеливание с помощью MongoDB, Apache Spark, но подробно в это не вникал.
Еще при инициализации пространства можно создавать «условные параметры», позволяя это пространства представлять в виде дерева: в зависимости от того, по какой ветви дерева пойдет алгоритм, на выходе будут разные виды гиперпараметров. Так можно, к примеру, перебирать не только гиперпараметры к конкретному классификатору, но и рассматривать разные классификаторы. В зависимости от выбранного классификатора будут перебираться разные группы гиперпараметров.
scikit-optimize
Из байесовских подходов есть только GP, но также реализованы методы на основе решающих деревьев. Хорошая документация (в стиле старшего брата scikit-learn), также есть несколько разобранных примеров и много примеров от других энтузиастов в интернете.
optuna
Наиболее молодой из представленных здесь фреймворков: статью о нем опубликовали в 2019 году. Хорошая документация. Помимо байесовских алгоритмов, есть возможность прунинга пространства гиперпараметров (удаления плохих точек из рассмотрения). По умолчанию удаляет точки, в которых модель дает качество ниже медианы из уже рассмотренных.
Результаты
Как видно, почти все оптимизаторы приходят в одну и ту же точку, в которой accuracy на валидации является максимальным (GridSearch иначе и не мог). При этом лучшее время показывает optuna: он более чем в 3 раза быстрее полного перебора и более, чем в 1.5 раза быстрее, чем hyperopt, несмотря на то, что в обоих случаях используется TPE и EI.
Стоит прокомментировать, почему я включил scikit-optimize дважды. Я экспериментировал со всеми функциями выбора. EIps и PIps, видимо, еще не реализованы ввиду вылетающего exception. Все остальные функции, кроме LCB, приходят в одинаковую точку, в которой качество на тесте выше, а качество на валидации ниже, чем у LCB. Тут следует напомнить, что наш оптимизатор работает с моделью как с черным ящиком. Цель оптимизатора заключается в нахождении точки пространства гиперпараметров, в которой соответствующая модель даст наибольшее качество именно на валидации. Поэтому то, что большинство функций выбора приводят алгоритм в точку пространства, где качество на тесте выше, является, скорее, результатом переобучения нейросети и ошибки оптимизатора scikit-optimize. Функция gp_hedge была выбрана как показавшая наилучшее время среди остальных, приходящих в ту же точку.
Дальше приведу несколько графиков. Под skopt подразумевается scikit-optimize (LCB), если что.

Как видно, все алгоритмы на первых итерациях ведут себя приблизительно одинаково. Поэтому рассмотрим изменение качества после 5 итерации.
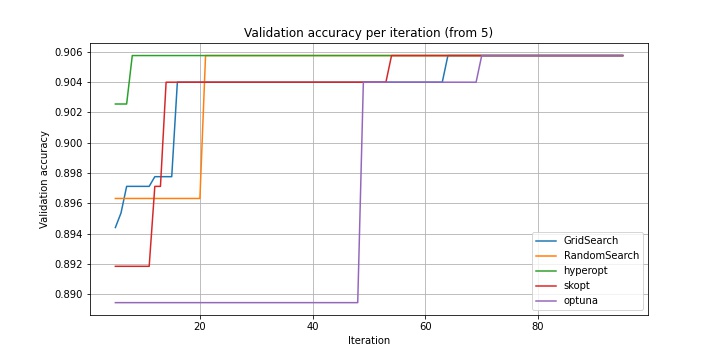
Как можно увидеть, hyperopt одним из первых достигает наилучшей точки пространства. Однако посмотрим еще на зависимость общего времени, потраченного на обучение моделей от итерации.
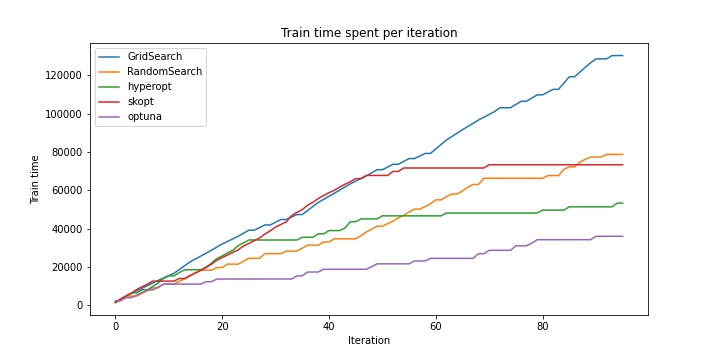
Как видно из таблицы и из приведенного графика, hyperopt сильно проигрывает optuna по времени. Сначала я грешил на прунинг, но без него результат оказался идентичным. Судя по всему, TPE в hyperopt больше «разведывает» неизвестную область пространства, в связи с чем чаще натыкается на неизвестные ранее точки, следовательно, тратит больше времени на обучение. Думаю, можно подкрутить параметры как optuna в сторону exploration, так и hyperopt в сторону exploitation, но из коробки они работают так.
Выводы
Ситуация по результатам эксперимента несколько спорная, хотя перевес явно в сторону optuna. Также, по моим субъективным ощущениям, этот фреймворк явно выигрывает у hyperopt. Но посмотрим на них в сравнении.
Почему optuna?
Почему hyperopt?
Заключение
Надеюсь, мне удалось более-менее простым языком объяснить принцип работы оптимизаторов гиперпараметров. А если и не удалось, то я хотя бы разобрал несколько фреймворков. Код доступен на github.



