Deep Learning: как это работает? Часть 1
В этой статье вы узнаете
-В чем суть глубокого обучения
-Для чего нужны функции активации
-Какие задачи может решать FCNN
-Каковы недостатки FCNN и с помощью чего с ними бороться
Небольшое вступление
Это начало цикла статей о том, какие задачи есть в DL, сети, архитектуры, принципы работы, как решаются те или иные задачи и почему одно лучше другого.
Какие предварительные навыки для понимания всего нужны? Сказать сложно, но если вы умеете гуглить или правильно задавать вопросы, то, я уверен, мой цикл статей поможет разобраться во многом.
В чем вообще суть глубокого обучения?
Суть в том, чтобы построить некий алгоритм, который принимал бы на вход X и предсказывал Y. Если мы пишем алгоритм Евклида для поиска НОД, то мы просто напишем циклы, условия, присваивания и вот это вот все — мы знаем как построить такой алгоритм. А как построить алгоритм, который на вход принимает изображение и говорит собака там или кошка? Или вовсе ничего? А алгоритм, на вход которого мы подаем текст и хотим узнать — какого он жанра? Вот так просто ручками написать циклы и условия тут не выйдет — тут на помощь и приходят нейронные сети, глубокое обучение и все вот эти модные слова.
Более формально и чуть-чуть о функциях активации
Выражаясь формально, мы хотим построить функцию от функции от функции…от входного параметра X и весов нашей сети W, которая выдавала бы нам некий результат. Тут важно отметить, что мы не можем взять просто много линейных функций, т.к. суперпозиция линейных функций — линейная функция. Тогда любая глубокая сеть аналогична сети с двумя слоями (входом и выходом). Для чего нам нелинейность? Наши параметры, которые мы хотим научиться предсказывать, могут нелинейно зависеть от входных данных. Нелинейность достигается путем использования различных функций активаций на каждом слое.
Fully-connected neural networks(FCNN)
Просто полносвязная нейронная сеть. Выглядит как-то так:
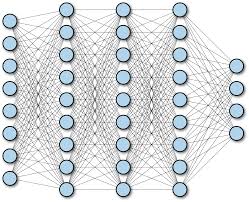
Суть в том, что каждый нейрон одного слоя связан с каждым нейроном следующего и предыдущего (если они есть).
Первый слой — входной. Например, если мы хотим подать изображение 256x256x3 на вход такой сети, то ровно 256x256x3 нейронов во входном слое нам и понадобится (каждый нейрон будет принимать 1 компоненту (R, G или B) пикселя). Если хотим подать рост человека, его вес и еще 23 признака, то понадобится 25 нейронов во входном слое. Кол-во нейронов на выходе — кол-во признаков, которые мы хотим предсказать. Это может быть как 1 признак, так и все 100. В общем случае по выходному слою сети можно почти наверняка сказать — какую задачу она решает.
Каждая связь между нейронами — вес, который тренируется алгоритмом backpropagation, о котором я писал тут.
Какие задачи может решать FCNN
-Задача регрессии. Например, предсказание стоимости магазина по каким-то входным критериям типа страны, города, улицы, проходимости и т.п.
-Задача классификации. Например, классика — MNIST classification.
-Насчет задачи сегментации и обнаружения объектов с помощью FCNN я сказать не возьмусь. Быть может, кто-то поделится в комментариях 🙂
Недостатки FCNN
Искусственный интеллект, машинное обучение и глубокое обучение: в чём разница
Компьютер запросто диагностирует рак, управляет автомобилем и умеет обучаться. Почему же машины пока не захватили власть над человечеством?


Мы пользуемся Google-картами, позволяем сайтам подбирать для нас интересные фильмы и советовать, что купить. И, в общем-то, слышали, что под капотом всех этих умных вещей — искусственный интеллект, машинное обучение и deep learning. Но сможете ли вы с ходу отличить одно от другого? Разбираемся на примерах.
Что такое искусственный интеллект
Искусственный интеллект (англ. artificial intelligence) — это способность компьютера обучаться, принимать решения и выполнять действия, свойственные человеческому интеллекту.
Кроме того, ИИ — это наука на стыке математики, биологии, психологии, кибернетики и ещё кучи всего. Она изучает технологии, которые позволяют человеку писать «интеллектуальные» программы и учить компьютеры решать задачи самостоятельно. Главная задача ИИ — понять, как устроен человеческий интеллект, и смоделировать его.
В области искусственного интеллекта есть подразделы. К ним относятся робототехника, наука о компьютерном зрении, обработка естественного языка и машинное обучение.
Хотите знать, может ли машина мыслить и чувствовать как человек? Приходите на курс «Философия искусственного интеллекта». Здесь вы получите новые знания об ИИ, обсудите актуальные вопросы с преподавателями и однокурсниками и прокачаете навык публичных выступлений.

Пишет про digital и машинное обучение для корпоративных блогов. Топ-автор в категории «Искусственный интеллект» на Medium. Kaggle-эксперт.
Каким бывает искусственный интеллект
Исследователи обычно делят ИИ на три группы:
Слабый ИИ (Weak, или Narrow AI)
Слабый интеллект — тот, что нам уже удалось создать. Такой ИИ способен решать определённую задачу. Зачастую даже лучше, чем человек. Например, как Deep Blue — компьютерная программа, которая обыграла Гарри Каспарова в шахматы ещё в 1996 году. Но такая Deep Blue не умеет делать ничего другого и никогда этому не научится. Слабый ИИ используют в медицине, логистике, банковском деле, бизнесе:
Это несколько примеров, в реальности применений намного больше.
Сильный ИИ (Strong, или General AI)
Как выглядел бы сильный искусственный интеллект, можно увидеть в игре Detroit: Become Human.
Во вселенной Detroit роботы способны учиться, мыслить, чувствовать, осознавать себя и принимать решения. Одним словом, становятся похожи на человека. А в обычной жизни ближе всего к General AI чат-боты и виртуальные ассистенты, которые имитируют человеческое общение. Здесь ключевое слово — имитируют. Siri или Алиса не думают — и неспособны принимать решения в ситуациях, которым их не обучили. Сильный искусственный интеллект пока остаётся мечтой.
Суперинтеллект (Superintelligence)
Мы не только не создали суперинтеллект, но и не имеем пока что ни малейшего представления, как это сделать и можно ли вообще. Это не просто умные машины, а компьютеры, которые во всём превосходят людей. Проще говоря, что-то из области фантастики.
Машинное обучение: как учится ИИ
Машинное обучение (англ. machine learning) — это один из разделов науки об ИИ. Здесь используются алгоритмы для анализа данных, получения выводов или предсказаний в отношении чего-либо. Вместо того чтобы кодировать набор команд вручную, машину обучают и дают ей возможность научиться выполнять поставленную задачу самостоятельно.
Чтобы машина могла принимать решения, необходимы три вещи:
В машинном обучении много разных алгоритмов. Один из самых простых — линейная регрессия. Её применяют, если есть линейная зависимость между переменными. Пример: чем больше сумма заказа, тем больше вы оставите чаевых. По имеющимся данным можно предсказать сумму чаевых в будущем. В общем-то, простая математика.
Есть байесовские алгоритмы. В их основе применение теоремы Байеса и теории вероятности. Эти алгоритмы используют для работы с текстовыми документами — например, для спам-фильтрации. Программе нужно дать наборы данных по категориям «спам» и «не спам». Дальше алгоритм будет самостоятельно оценивать вероятность того, что слова «Бесплатные туры для пенсионеров» и «Закажи маме тур, пожалуйста» относятся к той или иной категории.
А ещё есть нейронные сети, о них вы наверняка слышали. Они относятся к методам глубокого машинного обучения, и об этом чуть подробнее.
Deep learning: глубокое обучение для разных целей
Глубокое обучение — подраздел машинного обучения. Алгоритмам глубокого обучения не нужен учитель, только заранее подготовленные (размеченные) данные.
Самый популярный, но не единственный метод глубокого обучения, — искусственные нейронные сети (ИНС). Они больше всего похожи на то, как устроен человеческий мозг.
Нейронные сети — это набор связанных единиц (нейронов) и нейронных связей (синапсов). Каждое соединение передаёт сигнал от одного нейрона к другому, как в мозге человека. Обычно нейроны и синапсы организованы в слои, чтобы обрабатывать информацию. Первый слой нейросети — это вход, который получает данные. Последний — выход, результат работы. Например, несколько категорий, к одной из которых мы просим отнести то, что было отправлено на вход. И между ними — скрытые слои, которые выполняют преобразование.
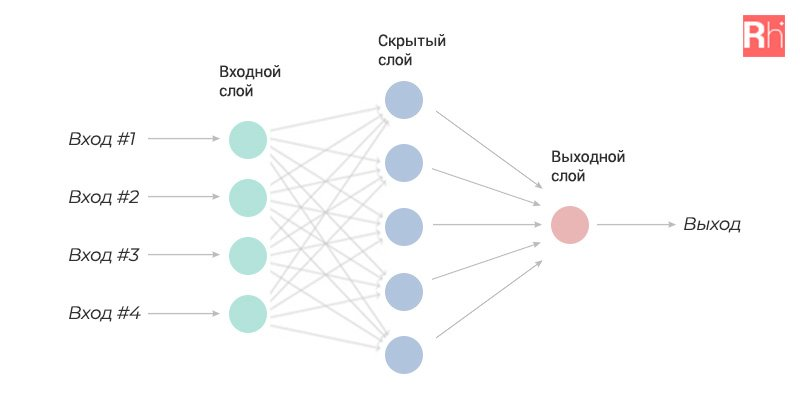
По сути, скрытые слои выполняют какую-то математическую функцию. Мы её не задаём, программа сама учится выводить результат. Можно научить нейросеть классифицировать изображения или находить на изображении нужный объект. Помните, как reCAPTCHA просит найти все изображения грузовиков или светофоров, чтобы доказать, что вы не робот? Нейронная сеть выполняет то же самое, что и наш мозг, — видит знакомые элементы и понимает: «О, кажется, это грузовик!»
А ещё нейросети могут генерировать объекты: музыку, тексты, изображения. Например, компания Botnik скормила нейросети все книги про Гарри Поттера и попросила написать свою. Получился «Гарри Поттер и портрет того, что выглядит как огромная куча пепла». Звучит немного странно, но как минимум с точки зрения грамматики это сочинение имеет смысл.
Сегодня нейронные сети могут применяться практически для любой задачи. Например, при диагностике рака, прогнозировании продаж, идентификации лиц в системах безопасности, машинных переводах, обработке фотографий и музыки.
Чтобы обучить нейросеть, нужны гигантские наборы тщательно отобранных данных. Например, для распознавания сортов огурцов нужно обработать 1,5 млн разных фотографий. Не получится просто слить рандомные картинки или текст из интернета — их нужно подготовить: привести к одному формату и удалить то, что точно не подходит (например, мы классифицируем пиццу, а в наборе данных у нас фото грузовика). На разметку данных — подготовку и систематизацию — уходят тысячи человеко-часов.
Чтобы создать новую нейросеть, требуется задать алгоритм, прогнать через него все данные, протестировать и неоднократно оптимизировать. Это сложно и долго. Поэтому иногда проще воспользоваться более простыми алгоритмами — например, регрессией.
Подведём итоги
Искусственный интеллект — одновременно и наука, которая помогает создавать «умные» машины, и способность компьютера обучаться и принимать решения.
Машинное обучение — одна из областей искусственного интеллекта. МО использует алгоритмы для анализа данных и получения выводов.
А глубокое обучение — лишь один из методов машинного обучения, в рамках которого компьютер учится без учителя подспудно, с помощью данных.
Если чувствуете, что вас привлекает проектирование машинного интеллекта, продолжить образование можно на нашем курсе. Вы научитесь писать алгоритмы, собирать и сортировать данные и получите престижную профессию Data Scientist — специалист по машинному обучению.
Первичное, обычно регулярное, обследование тех, у кого нет клинических симптомов. Проводится с целью ранней диагностики заболевания.
До покупки Google, Waymo cars была самостоятельной компанией по производству самопилотируемых автомобилей.
Умный облачный помощник для устройств Apple.
Виртуальный голосовой помощник, созданный компанией «Яндекс».
Одна из основных теорем элементарной теории вероятностей. Позволяет переставить причину и следствие: по известному факту события вычислить вероятность того, что оно было вызвано этой причиной.
Глубокое обучение (Deep Learning): краткий туториал
Первым шагом к пониманию того, как работает глубокое обучение, является понимание различий между несколькими важными терминами.
Нейронная сеть (искусственная нейронная сеть) — это попытка воспроизведения работы человеческого мозга на компьютере при помощи слоев нейронов.
Искусственный интеллект — способность машины или программы находить решения при помощи вычислений.
Во время первых исследований в области ИИ ученые пытались воспроизвести человеческий интеллект для решения конкретных задач — например, игры с человеком. Было введено большое количество правил, которым должен следовать компьютер. На основе этих правил компьютер принимал решения в согласии с конкретным списком возможных действий.
Машинное обучение — это попытка научить компьютеры самостоятельно обучаться на большом количестве данных вместо жестко постулированных правил.
Машинное обучение позволяет компьютерам самостоятельно обучаться. Это возможно благодаря вычислительной мощности современных компьютеров, которые могут легко обрабатывать большие наборы данных.
Контролируемое и неконтролируемое обучение
Контролируемое обучение (обучение с учителем, supervised learning) подразумевает использование помеченных наборов данных, содержащих входные данные и ожидаемые выходные результаты. Когда вы обучаете нейронную сеть с помощью контролируемого обучения, вы подаете как входные данные, так и ожидаемые выходные результаты.
Если результат, генерируемый нейронной сетью, неверен, она скорректирует свои вычисления. Это итерационный процесс, оканчивающийся тогда, когда сеть перестает совершать ошибки.
Примером задачи с контролируемым обучением является предсказание погоды. Нейросеть учится делать прогноз погоды с использованием исторических данных. Обучающие данные включают в себя входные данные (давление, влажность, скорость ветра) и выходные результаты (температура).
Неконтролируемое обучение (обучение без учителя, unsupervised learning) — это машинное обучение с использованием наборов данных без определенной структуры.
Когда вы обучаете нейросеть неконтролируемо, она самостоятельно проводит логическую классификацию данных. Примером задачи с неконтролируемым обучением является предсказание поведения посетителей интернет-магазинов. В этом случае сеть не обучается на размеченных даннх. Вместо этого она самостоятельно классифицирует входные данные и отвечает на вопрос, какие пользователи чаще всего покупают различные товары.
Глубокое обучение
Теперь вы подготовлены к изучению того, что такое глубокое обучение и как оно работает.
Глубокое обучение — это метод машинного обучения. Глубокое обучение позволяет обучать модель предсказывать результат по набору входных данных. Для обучения сети можно использовать как контролируемое, так и неконтролируемое обучение.
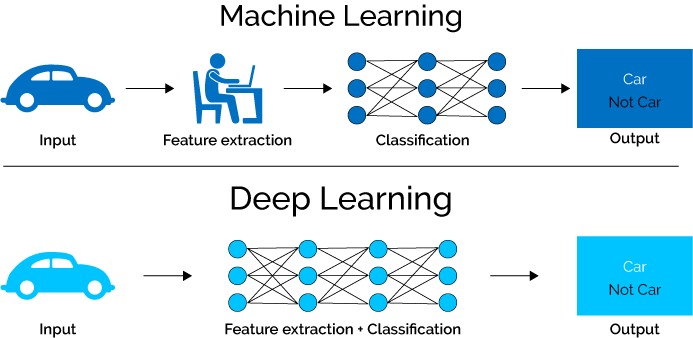 Разница между машинным и глубоким обучением
Разница между машинным и глубоким обучением
Рассмотрим, как работает глубокое обучение, на примере сервиса по оценке стоимости авиабилета. Мы будем обучать его контролируемым образом.
Мы хотим, чтобы наш сервис предсказывал цену на авиабилет по следующим входным данным:
Нейронные сети глубокого обучения
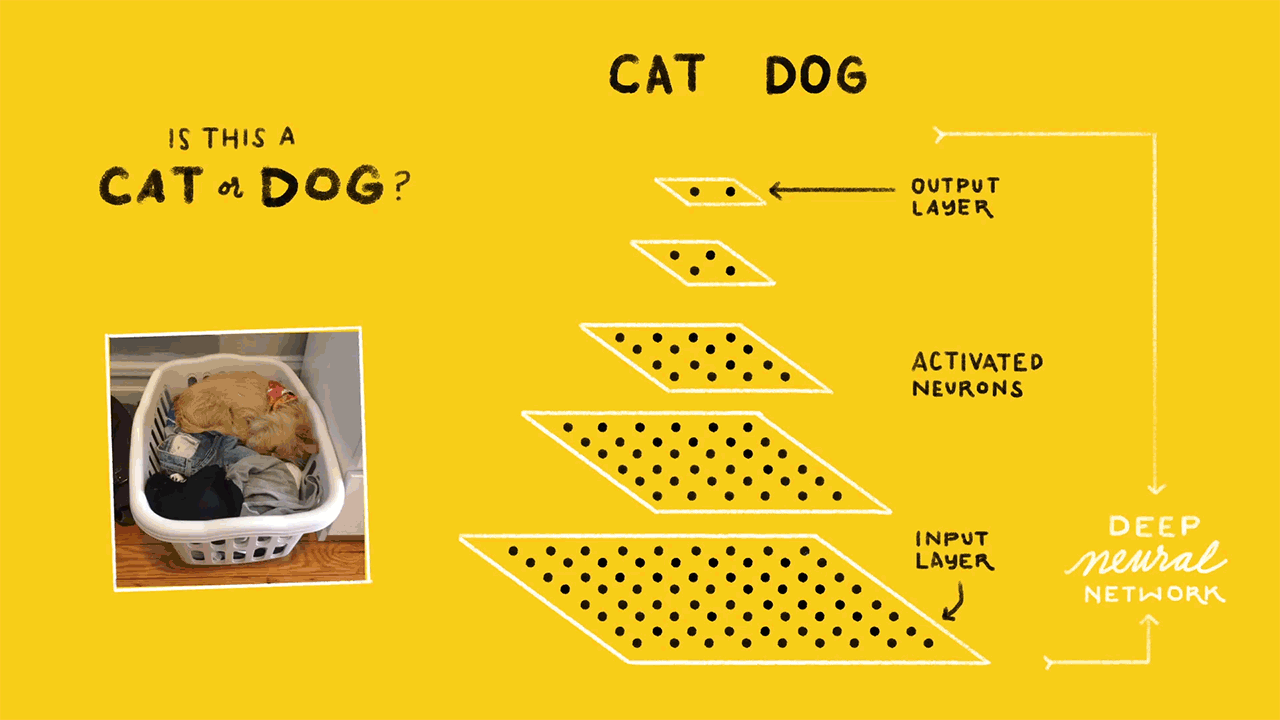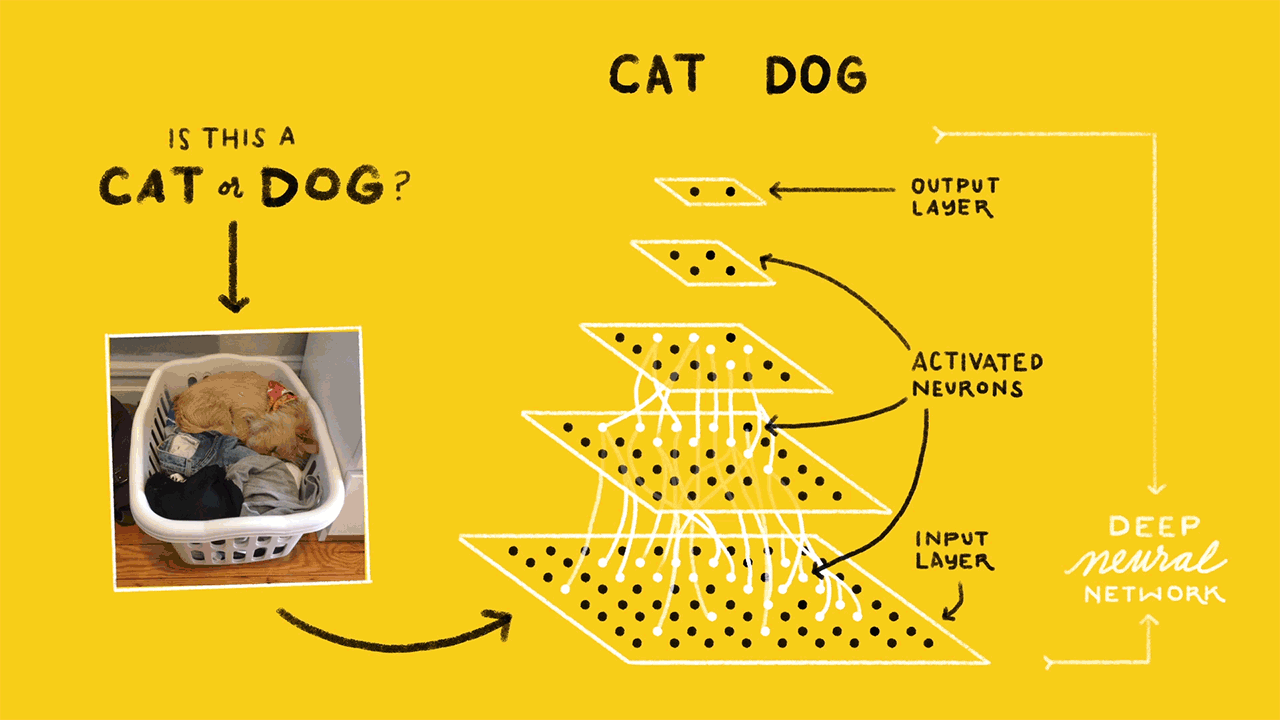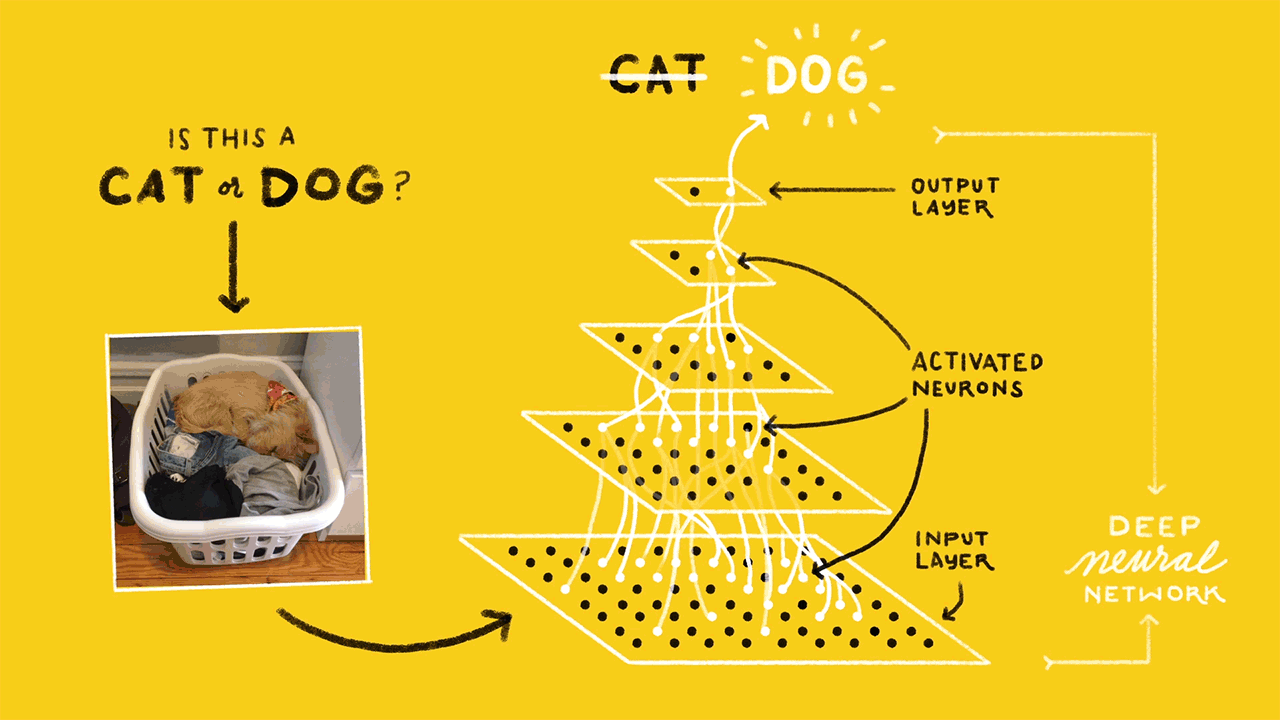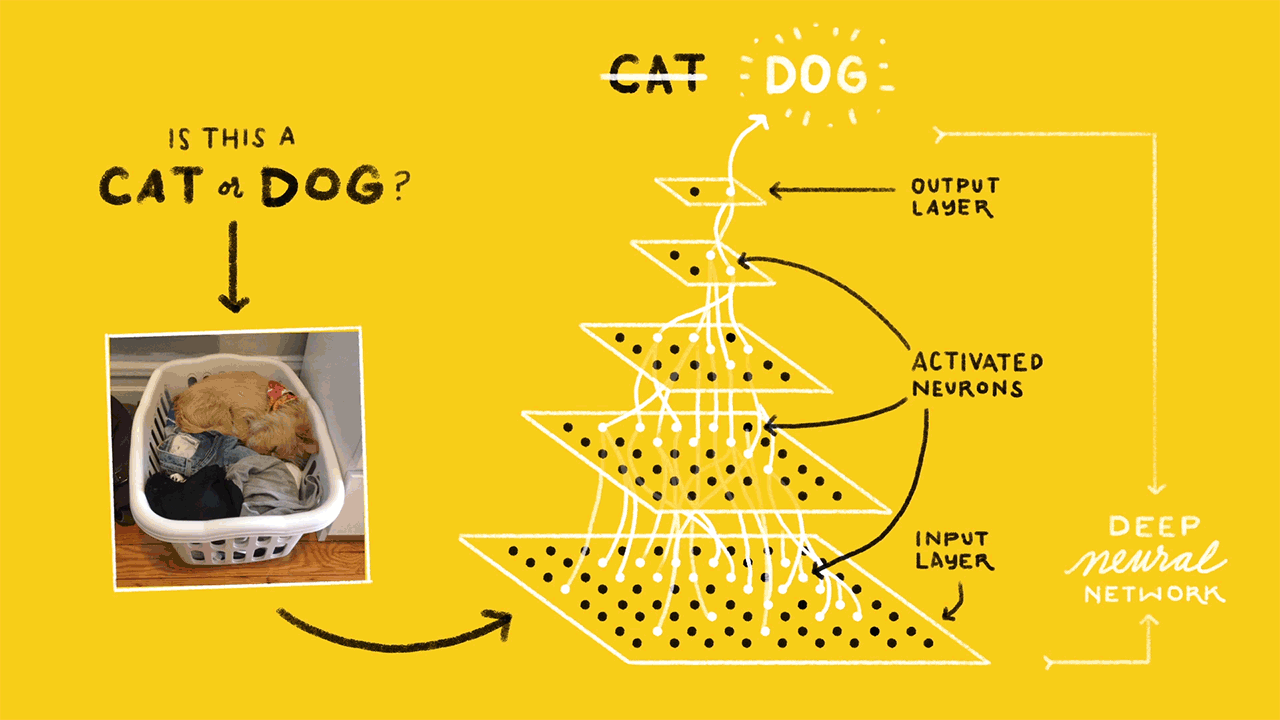
Давайте заглянем внутрь нашей модели. Как и у животных, искусственная нейронная сеть содержит взаимосвязанные нейроны. На диаграмме они представлены кругами:
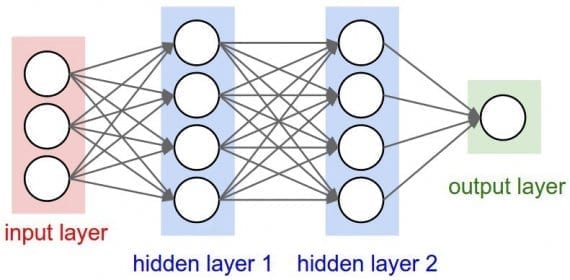 Глубокая нейронная сеть (с двумя скрытыми слоями)
Глубокая нейронная сеть (с двумя скрытыми слоями)
Нейроны сгруппированы в три различных типа слоев:
Входной слой принимает входные данные. В нашем случае имеется четыре нейрона на входном слое: аэропорт вылета, аэропорт назначения, дата вылета и авиакомпания. Входной уровень передает эти данные в первый скрытый слой.
Скрытые слои выполняют математические вычисления со входными данными. Одна из задач при создании нейронных сетей — определение количества скрытых слоев и нейронов на каждом слое.
Слово «глубина» в термине «глубокое обучение» означает наличие более чем одного скрытого слоя.
Выходной слой выдает результат. В нашем случае это прогноз цены на билет.
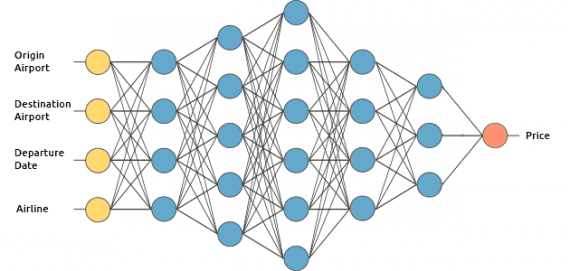
Итак, как же вычисляется цена? Здесь вступает в силу магия глубокого обучения. Нейроны связаны между собой с определенным весом. Вес определяет важность элемента входных данных. Исходные веса задаются случайным образом.
При прогнозировании цены на билет дата вылета является одним из наиболее важных факторов. Следовательно, связи нейрона времени вылета будут иметь большой вес.
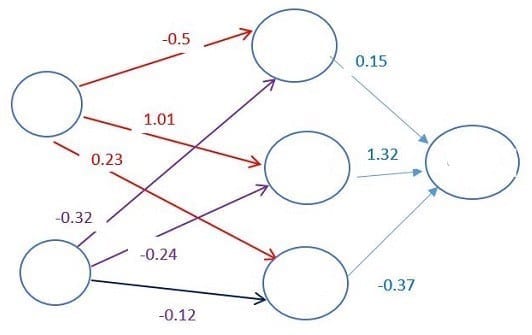
Каждый нейрон имеет функцию активации. Ее смысл трудно понять без привлечения математических рассуждений. Одной из ее целей является «стандартизация» данных на выходе из нейрона.
После того, как набор входных данных прошел через все слои нейронной сети, функция активации возвращает выходные результаты через выходной уровень.
Обучение глубокой сети
Обучение нейросети — самая сложная часть глубокого обучения. Почему?
Для оценки стоимости билета нужно найти исторические данные о ценах на билеты. Из-за большого количества возможных комбинаций аэропортов и дат вылета нам нужен очень большой список цен на билеты.
Для обучения сети нужно подать в нее подготовленные данные и сравнить сгенерированные ей выходные результаты с результатами из нашего тестового набора данных. Поскольку сеть еще не обучена, результаты будут неверными.
После пропуска всех данных можно определить функцию, которая будет показывать нам, насколько результаты работы алгоритма отличаются от реальных данных. Эта функция называется функцией потерь.
В идеале мы хотим, чтобы функция потерь была равна нулю. В этом случае выходные результаты работы сети полностью совпадают с результатами тестового набора данных.
Как уменьшить значение функции потерь?
Нужно менять веса между нейронами. Можно делать это случайным образом до тех пор, пока функция потерь не станет равной нулю, но это не очень эффективно.
Вместо этого мы будем использовать метод градиентного спуска. Градиентный спуск — это метод, который позволяет найти минимум функции. В нашем случае мы ищем минимум функции потерь.
Суть метода состоит в небольшом изменении весов после каждой итерации. Вычисляя производную (или градиент) функции потерь при определенном наборе весов, можно определить, в каком направлении находится минимум.
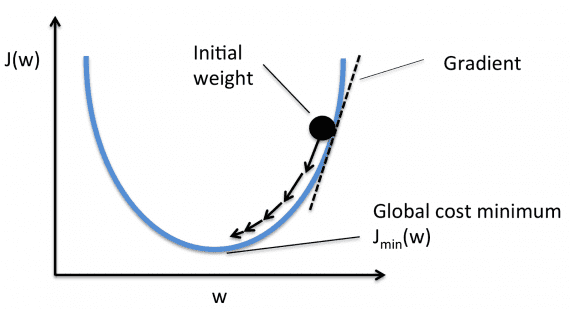
Для минимизации функции потерь нужно многократно перебирать данные. Именно поэтому нам требуется большая вычислительная мощность. Уточнение весов с помощью градиентного спуска выполняется автоматически. В этом и состоит магия глубокого обучения!
После обучения можно использовать разработанный нами сервис для прогнозирования цен на авиабилеты.
Глубинное обучение: возможности, перспективы и немного истории
Последние несколько лет словосочетание «глубинное обучение» всплывает в СМИ слишком часто. Различные журналы вроде KDnuggets и DigitalTrends стараются не упустить новости из этой сферы и рассказать о популярных фреймворках и библиотеках.
Даже популярные издания вроде The NY Times и Forbes стремятся регулярно писать о том, чем заняты ученые и разработчики из области deep learning. И интерес к глубинному обучению до сих пор не угасает. Сегодня мы расскажем о том, на что способно глубинное обучение сейчас, и по какому сценарию оно будет развиваться в будущем.

Пара слов про глубинное обучение, нейронные сети и ИИ
Чем отличается алгоритм глубинного обучения от обычной нейронной сети? По словам Патрика Холла, ведущего исследователя данных в компании SAS, самое очевидное отличие: в нейронной сети, используемой в глубинном обучении, больше скрытых слоев. Эти слои находятся между первым, или входным, и последним, выходным, слоем нейронов. При этом совсем не обязательно связывать все нейроны на разных уровнях между собой.
Разграничение глубинного обучения и искусственного интеллекта не такое однозначное. Например, профессор Вашингтонского университета Педро Домингос соглашается с мнением, что глубинное обучение выступает гипонимом по отношению к термину «машинное обучение», которое в свою очередь является гипонимом по отношению к искусственному интеллекту. Домингос говорит, что на практике области их применения пересекаются достаточно редко.
Однако существует и другое мнение. Хуго Ларочелле, профессор Шербрукского университета, уверен, что данные концепты почти никак не связаны между собой. Хуго замечает, что ИИ фокусируется на цели, а глубинное обучение — на определенной технологии или методологии, необходимой для машинного обучения. Поэтому здесь и далее, говоря о достижениях в области ИИ (таких, как AlphaGo, например) будем иметь в виду, что подобные разработки используют алгоритмы глубинного обучения — но наряду и с другими разработками из области ИИ в целом и машинного обучения в частности [как справедливо отмечает Педро Домингос].
От «глубокой нейронной сети» до глубинного обучения
Глубокие нейронные сети появились достаточно давно, еще в 1980-е. Так почему же глубинное обучение начало активно развиваться только в 21 веке? Репрезентации в нейронной сети создаются в слоях, поэтому было логично предположить, что больше слоев позволит сети лучше обучаться. Но большую роль играет метод обучения сети. Раньше для глубинного обучения использовались те же алгоритмы, что и для обучения искусственных нейронных сетей — метод обратного шифрования. Такой метод мог эффективно обучать только последние слои сети, в результате чего процесс был чрезвычайно длительным, а скрытые слои глубинной нейронной сети, фактически, не «работали».
Только в 2006 году три независимых группы ученых смогли разработать способы преодоления трудностей. Джеффри Хинтон смог провести предобучение сети при помощи машины Больцмана, обучая каждый слой отдельно. Для решения проблем распознавания изображений Яном ЛеКаном было предложено использование сверточной нейронной сети, состоящей из сверточных слоев и слоев подвыборки. Каскадный автокодировщик, разработанный Иошуа Бенджио, также позволил задействовать все слои в глубокой нейронной сети.
Проекты, которые «видят» и «слышат»
Сегодня глубинное обучение используется в совершенно разных сферах, но, пожалуй больше всего примеров использования лежит в области обработки изображений. Функция распознавания лиц существует уже давно, но, как говорится, нет предела совершенству. Разработчики сервиса OpenFace уверены, что проблема еще не решена, ведь точность распознавания можно повысить. И это не просто слова, OpenFace умеет различать даже похожих внешне людей. Подробно о работе программы уже писали в этой статье. Глубинное обучение поможет и при работе с черно-белыми файлами, автоматической колоризацией которых занимается приложение Colornet.
Кроме того, глубокие сети теперь способны распознавать и человеческие эмоции. А вместе с возможностью отследить использование логотипа компании на фотографиях и анализом сопроводительного текста мы получаем мощный маркетинговый инструмент. Похожие сервисы разрабатывает, например, IBM. Инструмент позволяет оценить авторов текстов при поиске блогеров для сотрудничества и рекламы.
Программа NeuralTalk умеет описывать изображения при помощи нескольких предложений. В базу программы загружается набор изображений и 5 предложений, описывающих каждое из них. На стадии обучения алгоритм учится прогнозировать предложения на основе ключевого слова, используя предыдущий контекст. А на стадии прогнозирования нейронная сеть Джордана уже создает предложения, описывающие картинки.
Сегодня существует много приложений, которые могут решать разные задачи в работе с аудио. Например, приложение Magenta, разработанное командой Google, умеет создавать музыку. Но большая часть приложений направлена на распознавание речи. Интернет-сервис Google Voice умеет транскрибировать голосовую почту и имеет функции управления СМС, при этом для обучения глубоких сетей исследователями использовались существующие голосовые сообщения.
Проекты в «разговорном жанре»
По мнению таких ученых, как Ноам Хомски, невозможно научить компьютер полностью понимать речь и вести осознанный диалог, потому что даже механизм человеческой речи изучен не до конца. Попытки научить машины говорить начались еще в 1968 году, когда Терри Виноград создал программу SHRDLU. Она умела распознавать части речи, описывать предметы, отвечать на вопросы, даже обладала небольшой памятью. Но попытки расширить словарный запас машины привели к тому, что стало невозможно контролировать применение правил.
Но сегодня с помощью глубинного обучения Google в лице разработчика Куока Ле шагнул далеко вперед. Его разработки умеют отвечать на письма в Gmail и даже помогают специалистам технической поддержки Google. А программа Cleverbot обучалась на диалогах из 18 900 фильмов. Поэтому она может отвечать на вопросы даже о смысле жизни. Так, бот считает, что смысл жизни заключается в служении добру. Однако ученые вновь столкнулись с тем, что искусственный интеллект лишь имитирует понимание и не имеет представления о реальности. Программа воспринимает речь лишь как сочетание определенных символов.
Обучение машин языку может помочь и в переводе. Google давно занимается улучшением качества перевода в своем сервисе. Но насколько можно приблизить машинный перевод к идеалу, если и человек не всегда может правильно понимать смысл высказывания? Рэй Курцвейл предлагает для решения этой задачи графически представить семантическое значение слов в языке. Процесс достаточно трудоемкий: в специальный каталог Knowledge Graph, созданный в Google, ученые загрузили данные о почти 700 миллионах тем, мест, людей, между которыми было проведено почти миллиард различных связей. Все это направлено на улучшение качества перевода и восприятие искусственным интеллектом языка.
Сама идея о представлении языка графическими и/или математическими методами не нова. Еще в 80-е перед учеными стояла задача представить язык в формате, с которым могла бы работать нейронная сеть. В итоге был предложен вариант представления слов в виде математических векторов, что позволяло точно определить смысловую близость разных слов (например, в векторном пространстве слова «лодка» и «вода» должны быть близки друг к другу). На этих исследованиях и базируются сегодняшние разработки Google, которые современные исследователи называют уже не «векторами отдельных слов», а «векторами идей».
Глубинное обучение и здравоохранение
Сегодня глубинное обучение проникает даже в сферу здравоохранения и помогает следить за состоянием пациентов не хуже врачей. Например, медицинский центр Дармут-Хичкок в США использует специализированный сервис Microsoft ImagineCare, что позволяет врачам уловить едва заметные перемены в состоянии пациентов. Алгоритмы получают данные об изменениях веса, контролируют давление пациентов и могут даже распознавать эмоциональное состояние на основе анализа телефонных разговоров.
Глубинное обучение применяется и в фармацевтике. Сегодня для лечения разных видов рака используется молекулярно-таргетная терапия. Но для создания эффективного и безопасного лекарства необходимо идентифицировать активные молекулы, которые бы воздействовали только на заданную мишень, позволяя избежать побочных эффектов. Поиск таких молекул может выполняться с использованием глубинного обучения (описание проекта, проведенного совместно учеными из университетов Австрии, Бельгии и R&D-отдела компании Johnson&Johnson есть в этом научном материале).
Есть ли у алгоритма интуиция?
Насколько на самом деле «глубоко» глубинное обучение? Ответ на это вопрос могут дать разработчики AlphaGo. Этот алгоритм не умеет говорить, не умеет распознавать эмоции. Но он способен обыграть любого в настольную игру. На первый взгляд тут нет ничего особенного. Уже почти 20 лет назад компьютер, разработанный IBM, впервые обыграл в шахматы человека. Но AlphaGo – совсем другое дело. Настольная игра Го появилась в Древнем Китае. Начало чем-то похоже на шахматы – противники играют на доске в клетку, черные фигуры против белых. Но на этом сходства заканчиваются, потому что фигуры являются небольшими камушками, а цель игры – окружить камушек противника своими.
Но главное отличие в том, что не существует каких-либо заранее известных выигрышных комбинаций, в го невозможно думать на несколько ходов вперед. Машину нельзя запрограммировать на победу, потому что невозможно выстроить победную стратегию заранее. Здесь и вступает в игру глубинное обучение. Вместо программирования определенных ходов, AlphaGo проанализировала сотни тысяч сыгранных партий и сыграла миллион партий сама с собой. Искусственный интеллект может обучаться на практике и выполнять сложные задания, приобретая то, что человек назвал бы «интуитивным пониманием выигрышной стратегии».
Машины не захватят мир
Несмотря на ошеломляющие успехи AlphaGo, искусственный интеллект еще далек от порабощения человеческой расы. Машины научились своеобразному «интуитивному мышлению», обработке огромного массива данных, но, по словам Фей-Фей Ли, руководителя Стэнфордской лаборатории искусственного интеллекта, абстрактное и творческое мышление им недоступно.
Несмотря на определенный прогресс в распознавании изображений, компьютер может перепутать дорожный знак с холодильником. Вместе со своими коллегами Ли составляет базу изображений с их подробным описанием и большим количеством тегов, которые позволят компьютеру получить больше информации о реальных объектах.
По словам Ли, такой подход – обучение на основе фото и подробного его описания – похож на то, как учатся дети, ассоциируя слова с объектами, отношениями и действиями. Конечно, эта аналогия довольно грубая – ребенку для понимания взаимосвязей объектов реального мира не нужно дотошно описывать каждый предмет и его окружение.
Профессор Джош Тененбаум, изучающий когнитивистику в MIT, отмечает, что, алгоритм познания мира и обучения у компьютера сильно отличается от процесса познания у человека; несмотря на свой размер, искусственные нейронные сети не могут сравниться с устройством биологических сетей. Так, способность говорить формируется в человеке очень рано и базируется на визуальном восприятии мира, владении опорно-двигательным аппаратом. Тененбаум уверен, что научить машины полноценному мышлению без подражания человеческой речи и психологической составляющей не представляется возможным.
Фей-Фей Ли согласна с этим мнением. По словам ученой, современный уровень работы с искусственным интеллектом не позволит приблизить его к человеческому – как минимум за счет наличия у людей эмоционального и социального интеллекта. Поэтому захват мира машинами стоит отложить как минимум еще на пару десятилетий.



