Горизонтальное масштабирование PHP приложений. Часть 1

Итак вы сделали сайт. Всегда интересно и волнительно наблюдать как счетчик посещений медленно, но верно ползет вверх, с каждым днем показывая все лучшие результаты. Но однажды, когда вы этого не ждете, кто-то запостит ссылку на ваш ресурс на каком-нибудь Reddit или Hacker News (или на Хабре — прим. пер.), и ваш сервер ляжет.
Вместо того, что бы получить новых постоянных пользователей, вы останетесь с пустой страницей. В этот момент, ничего не поможет вам восстановить работоспособность сервера, и трафик будет утерян навсегда. Как же избежать таких проблем? В этой статье мы поговорим об оптимизации и масштабировании.
Немного про оптимизацию
Основные советы всем известны: обновитесь до последней версии PHP (в 5.5 теперь встроен OpCache), разберитесь с индексами в базе данных, кэшируйте статику (редко изменяемые страницы, такие как “О нас”, “FAQ” и т.д.).
Также стоит упомянуть об одном особом аспекте оптимизации — обслуживании статического контента не-Apache сервером, таким как, например, Nginx, Настройте Nginx на обработку всего статического контента (*.jpg, *.png, *.mp4, *.html…), а файлы требующие серверной обработки пусть отсылает тяжелому Apache. Это называется reverse proxy.
Масштабирование
Есть два типа масштабирования — вертикальное и горизонтальное.
В моем понимании, сайт является масштабируемым, если он может справляться с трафиком, без изменений в программном обеспечении.
Вертикальное масштабирование.
Представьте себе сервер, обслуживающий веб-приложение. У него 4ГБ RAM, i5 процессор и 1ТБ HDD. Он отлично выполняет свои функции, но, что бы лучше справляться с более высоким трафиком, вы решаете увеличить RAM до 16ГБ, поставить процессор i7, и раскошелиться на SSD диск. Теперь сервер гораздо мощнее, и справляется с высокими нагрузками. Это и есть вертикальное масштабирование.
Горизонтальное масштабирование.
Горизонтальное масштабирование — создание кластера из связанных между собой (часто не очень мощных) серверов, которые вместе обслуживают сайт. В этом случае, используется балансировщик нагрузки (aka load balancer) — машина или программа, основная функция которой — определить на какой сервер послать запрос. Сервера в кластере делят между собой обслуживание приложения, ничего друг о друге не зная, таким образом значительно увеличивая пропускную способность и отказоустойчивость вашего сайта.
Есть два типа балансировщиков — аппаратные и программные. Программный — устанавливается на обычный сервер и принимает весь трафик, передавая его соответствующим обработчикам. Таким балансировщиком может быть, например, Nginx. В разделе “Оптимизация” он перехватывал все запросы на статические файлы, и обслуживал эти запросы сам, не обременяя Apache. Другое популярное ПО для реализации балансировки нагрузки — Squid. Лично я всегда использую именно его, т.к. он предоставляет отличный дружественный интерфейс, для контроля за самыми глубокими аспектами балансировки.
Аппаратный балансировщик — выделенная машина, единственная цель которой — распределять нагрузку. Обычно на этой машине, никакого ПО, кроме разработанного производителем, больше не стоит. Почитать про аппаратные балансировщики нагрузки можно здесь.
Обратите внимание, что эти два метода не являются взаимоисключающими. Вы можете вертикально масштабировать любую машину (aka Ноду) в вашей системе.
В этой статье мы обсуждаем горизонтальное масштабирование, т.к. оно дешевле и эффективнее, хотя и сложнее в реализации.
Постоянное соединение
При масштабировании PHP приложений, возникает несколько непростых проблем. Одна из них — работа с данными сессии пользователя. Ведь если вы залогинились на сайте, а следующий ваш запрос балансировщик отправил на другую машину, то новая машина не будет знать, что вы уже залогинены. В этом случае, вы можете использовать постоянное соединение. Это значит, что балансировщик запоминает на какую ноду отправил запрос пользователя в прошлый раз, и отправляет следующий запрос туда же. Однако, получается, что балансировщик слишком перегружен функциями, кроме обработки сотни тысяч запросов, ему еще и приходится помнить как именно он их обработал, в результате чего, сам балансировщик становится узким местом в системе.
Обмен локальными данными.
Использование БД для хранения сессий
Используя собственный обработчик сессий, мы можем хранить их в БД. База данных может быть на отдельном сервере (или даже кластере). Обычно этот метод отлично работает, но при действительно большом трафике, БД становится узким местом (а при потере БД мы полностью теряем работоспособность), ибо ей приходится обслуживать все сервера, каждый из которых пытается записать или прочитать данные сессии.
Распределенная файловая система
Возможно вы думаете о том, что неплохо бы было настроить сетевую файловую систему, куда все сервера смогли бы писать данные сессии. Не делайте этого! Это очень медленный подход, приводящий к порче, а то и потере данных. Если же, по какой-то причине, вы все-таки решили использовать этот метод, рекомендую вам GlusterFS
Memcached
Чем больше у вас машин, тем больше вы можете отвести в этот пул памяти. Вам не обязательно объединять всю память машин в пул, но вы можете, и вы можете пожертвовать в пул произвольное количество памяти с каждой машины. Так что, есть возможность оставить большую часть памяти для обычного использования, и выделить кусок для кэша, что позволит кэшировать не только сессии, но другую подходящую информацию. Memcached — отличное и широко распространенное решение.
Для использования этого подхода, нужно немного подредактировать php.ini
Redis кластер
Redis — NoSQL хранилище данных. Хранит базу в оперативной памяти. В отличие от memcached поддерживает постоянное хранение данных, и более сложные типы данных. Redis не поддерживает кластеризацию, так что использовать его для горизонтального масштабирования несколько затруднительно, однако, это временно, и уже вышла альфа версия кластерного решения.
Другие решения
ZSCM неплохая альтернатива от Zend, но требует Zend Server на каждой ноде.
Если вас интересуют другие NoSQL хранилища и системы кэширования — попробуйте Scache, Cassandra или Couchbase.
Итого
Как видите, горизонтальное масштабирование PHP приложений не такое уж простое дело. Существует много трудностей, большинство решений не взаимозаменяемые, так что приходится выбирать одно, и придерживаться его до конца, ведь когда трафик зашкаливает — уже нет возможности плавно перейти на что-то другое.
Надеюсь этот небольшой гайд поможет вам выбрать подход к масштабированию для вашего проекта.
Во второй части статьи мы поговорим о масштабировании базы данных.
Вертикальное и горизонтальное масштабирование, scaling для web
Для примера можно рассмотреть сервера баз данных. Для больших приложений это всегда самый нагруженный компонент системы.
Возможности для масштабирования для серверов баз данных определяются применяемыми программными решениями: чаще всего это реляционные базы данных (MySQL, Postgresql) или NoSQL (MongoDB, Cassandra и др).
Горизонтальное масштабирование для серверов баз данных при больших нагрузках значительно дешевле
Веб-проект обычно начинают на одном сервере, ресурсы которого при росте заканчиваются. В такой ситуации возможны 2 варианта:
MySQL является самой популярной RDBMS и, как и любая из них, требует для работы под нагрузкой много серверных ресурсов. Масштабирование возможно, в основном, вверх. Есть шардинг (для его настройки требуется вносить изменения в код) и репликация, которая может быть сложной в поддержке.
Вертикальное масштабирование 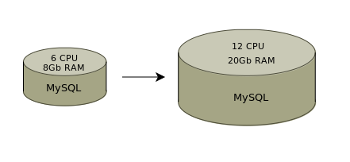
NoSQL масштабируется легко и второй вариант с, например, MongoDB будет значительно выгоднее материально, при этом не потребует трудозатратных настроек и поддержки получившегося решения. Шардинг осуществляется автоматически.
Таким образом с MySQL нужен будет сервер с большим количеством CPU и оперативной памяти, такие сервера имеют значительную стоимость.
Горизонтальное масштабирование
С MongoDB можно добавить еще один средний сервер и полученное решение будет стабильно работать давая дополнительно отказоустойчивость. 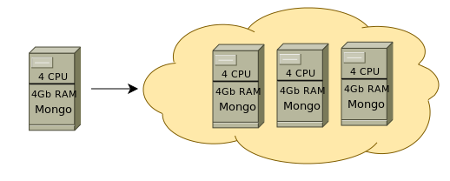
Scale-out или горизонтальное масштабирование является закономерным этапом развития инфраструктуры. Любой сервер имеет ограничения и когда они достигнуты или когда стоимость более мощного сервера оказывается неоправданно высокой добавляются новые машины. Нагрузка распределяется между ними. Также это дает отказоустойчивость.
Добавлять средние сервера и настраивать кластеры нужно начинать когда возможности для увеличения ресурсов одной машины исчерпаны или когда приобретение сервера мощнее оказывается невыгодно
Приведенный пример с реляционными базами данных и NoSQL является ситуацией, которая имеет место чаще всего. Масштабируются также фронтэнд и бэкенд сервера.
Масштабирование нагрузки web-приложений
Оптимизация
Масштабирование
И так, допустим, что оптимизация уже проведена, но приложение всё равно не справляется с нагрузкой. В таком случае решением проблемы, очевидно, может послужить разнесение его по нескольким хостам, с целью увеличения общей производительности приложения за счёт увеличения доступных ресурсов. Такой подход имеет официальное название – «масштабирование» (scale) приложения. Точнее говоря, под «масштабируемостью» (scalability) называется возможность системы увеличивать свою производительность при увеличении количества выделяемых ей ресурсов. Различают два способа масштабирования: вертикальное и горизонтальное. Вертикальное масштабирование подразумевает увеличение производительности приложения при добавлении ресурсов (процессора, памяти, диска) в рамках одного узла (хоста). Горизонтальное масштабирование характерно для распределённых приложений и подразумевает рост производительности приложения при добавлении ещё одного узла (хоста).
Понятно, что самым простым способом будет простое обновление железа (процессора, памяти, диска) – то есть вертикальное масштабирование. Кроме того, этот подход не требует никаких доработок приложения. Однако, вертикальное масштабирование очень быстро достигает своего предела, после чего разработчику и администратору ничего не остаётся кроме как перейти к горизонтальному масштабированию приложения.
Архитектура приложения
Большинство web-приложений априори являются распределёнными, так как в их архитектуре можно выделить минимум три слоя: web-сервер, бизнес-логика (приложение), данные (БД, статика).

Каждый их этих слоёв может быть масштабирован. Поэтому если в вашей системе приложение и БД живут на одном хосте – первым шагом, несомненно, должно стать разнесение их по разным хостам.
Узкое место
Обычно всё зависит от архитектуры приложения, но наиболее вероятными кандидатами на «узкое место» в общем случае являются БД и код. Если ваше приложение работает с большим объёмом пользовательских данных, то «узким местом», соответственно, скорее всего будет хранение статики.
Масштабирование БД
Как уже говорилось выше, зачастую узким местом в современных приложениях является БД. Проблемы с ней делятся, как правило, на два класса: производительность и необходимость хранения большого количества данных.
Снизить нагрузку на БД можно разнеся её на несколько хостов. При этом остро встаёт проблема синхронизации между ними, решить которую можно путём реализации схемы master/slave с синхронной или асинхронной репликацией. В случае с PostgreSQL реализовать синхронную репликацию можно с помощью Slony-I, асинхронную – PgPool-II или WAL (9.0). Решить проблему разделения запросов чтения и записи, а так же балансировки нагрузку между имеющимися slave’ами, можно с помощью настройки специального слоя доступа к БД (PgPool-II).
Проблему хранения большого объёма данных в случае использования реляционных СУБД можно решить с помощью механизма партицирования (“partitioning” в PostgreSQL), либо разворачивая БД на распределённых ФС типа Hadoop DFS.
Однако, для хранения больших объёмов данных лучшим решением будет «шардинг» (sharding) данных, который является встроенным преимуществом большинства NoSQL БД (например, MongoDB).
Кроме того, NoSQL БД в общем работают быстрее своих SQL-братьев за счёт отсутствия overhead’а на разбор/оптимизацию запроса, проверки целостности структуры данных и т.д. Тема сравнения реляционных и NoSQL БД так же довольно обширна и заслуживает отдельной статьи.
Отдельно стоит отметить опыт Facebook, который используют MySQL без JOIN-выборок. Такая стратегия позволяет им значительно легче масштабировать БД, перенося при этом нагрузку с БД на код, который, как будет описано ниже, масштабируется проще БД.
Масштабирование кода
Сложности с масштабированием кода зависят от того, сколько разделяемых ресурсов необходимо хостам для работы вашего приложения. Будут ли это только сессии, или потребуется общий кеш и файлы? В любом случае первым делом нужно запустить копии приложения на нескольких хостах с одинаковым окружением.
Далее необходимо настроить балансировку нагрузки/запросов между этими хостами. Сделать это можно как на уровне TCP (haproxy), так и на HTTP (nginx) или DNS.
Следующим шагом нужно сделать так, что бы файлы статики, cache и сессии web-приложения были доступны на каждом хосте. Для сессий можно использовать сервер, работающий по сети (например, memcached). В качестве сервера кеша вполне разумно использовать тот же memcached, но, естественно, на другом хосте.
Файлы статики можно смонтировать с некого общего файлового хранилища по NFS/CIFS или использовать распределённую ФС (HDFS, GlusterFS, Ceph).
Так же можно хранить файлы в БД (например, Mongo GridFS), решая тем самым проблемы доступности и масштабируемости (с учётом того, что для NoSQL БД проблема масштабируемости решена за счёт шардинга).
Отдельно стоит отметить проблему деплоймента на несколько хостов. Как сделать так, что бы пользователь, нажимая «Обновить», не видел разные версии приложения? Самым простым решением, на мой взгляд, будет исключение из конфига балансировщика нагрузки (web-сервера) не обновлённых хостов, и последовательного их включения по мере обновления. Так же можно привязать пользователей к конкретным хостам по cookie или IP. Если же обновление требует значимых изменений в БД, проще всего, вообще временно закрыть проект.
Масштабирование ФС
При необходимости хранения большого объёма статики можно выделить две проблемы: нехватка места и скорость доступа к данным. Как уже было написано выше, проблему с нехваткой места можно решить как минимум тремя путями: распределённая ФС, хранение данных в БД с поддержкой шардинга и организация шардинга «вручную» на уровне кода.
При этом стоит понимать, что раздача статики тоже не самая простая задача, когда речь идёт о высоких нагрузках. Поэтому в вполне резонно иметь множество серверов предназначенных для раздачи статики. При этом, если мы имеем общее хранилище данных (распределённая ФС или БД), при сохранении файла мы можем сохранять его имя без учёта хоста, а имя хоста подставлять случайным образом при формировании страницы (случайным образом балансирую нагрузку между web-серверами, раздающими статику). В случае, когда шардинг реализуется вручную (то есть, за выбор хоста, на который будут залиты данные, отвечает логика в коде), информация о хосте заливки должна либо вычисляться на основе самого файла, либо генерироваться на основании третьих данных (информация о пользователе, количестве места на дисках-хранилищах) и сохраняться вместе с именем файла в БД.
Мониторинг
Понятно, что большая и сложная система требует постоянного мониторинга. Решение, на мой взгляд, тут стандартное – zabbix, который следит за нагрузкой/работой узлов системы и monit для демонов для подстраховки.
Горизонтальное масштабирование PHP-приложений
Постоянно растущее количество посетителей сайта – всегда большое достижение для разработчиков и администраторов. Конечно, за исключением тех ситуаций, когда трафик увеличивается настолько, что выводит из строя веб-сервер или другое ПО. Постоянные перебои работы сайта всегда очень дорого обходятся компании.
Однако это поправимо. И если сейчас вы подумали о масштабировании – вы на правильном пути.
В двух словах, масштабируемость – это способность системы обрабатывать большой объем трафика и приспособляться к его росту, сохраняя при этом необходимый UX. Существует два метода масштабирования:
Что такое горизонтальное масштабирование?
Проще говоря, кластер – это группа серверов. Балансировщик нагрузки – это сервер, распределяющий рабочую нагрузку между серверами в кластере. В любой момент в существующий кластер можно добавить веб-сервер для обработки большего объёма трафика. В этом и есть суть горизонтального масштабирования.
Балансировщик нагрузки отвечает только за то, какой сервер из кластера будет обрабатывать полученный запрос. в основном, он работает как обратный прокси-сервер.
Горизонтальное масштабирование – несомненно, более надёжный метод увеличения производительности приложения, однако оно сложнее в настройке, чем вертикальное масштабирование. Главная и самая сложная задача в этом случае – постоянно поддерживать все ноды приложения обновленными и синхронизированными. Предположим, пользователь А отправляет запрос сайту mydomain.com, после чего балансировщик передаёт запрос на сервер 1. Тогда запрос пользователя Б будет обрабатываться сервером 2.
Что произойдёт, если пользователь А внесёт изменения в приложение (например, выгрузит какой-нибудь файл или обновит содержимое БД)? Как передать это изменение остальным серверам кластера?
Ответ на эти и другие вопросы можно найти в этой статье.
Разделение серверов
Подготовка системы к масштабированию требует разделения серверов; при этом очень важно, чтобы серверы с меньшим объёмом ресурсов имели меньше обязанностей, чем более объёмные серверы. Кроме того, разделение приложения на такие «части» позволит быстро определить его критические элементы.
Предположим, у вас есть PHP-приложение, позволяющее проходить аутентификацию и выкладывать фотографии. Приложение основано на стеке LAMP. Фотографии сохраняются на диске, а ссылки на них – в базе данных. Задача здесь заключается в поддержке синхронизации между несколькими серверами приложений, которые совместно используют эти данные (загруженные файлы и сессии пользователя).
Для масштабирования этого приложения нужно разделить веб-сервер и сервер БД. Таким образом в кластере появятся ноды, которые совместно используют сервер БД. Это увеличит производительность приложения, снизив нагрузку на веб-сервер.
В дальнейшем можно настроить балансировку нагрузки; об этом можно прочесть в руководстве «Балансировка нагрузки MySQL при помощи HAProxy»
Сессионная согласованность
Разделив веб-сервер и базу данных, нужно сосредоточиться на обработке пользовательских сессий.
Реляционные базы данных и сетевые файловые системы
Данные сессий часто хранят в реляционных базах данных (таких как MySQL), потому что это такие базы легко настроить.
Однако это решение не самое надёжное, потому что в таком случае увеличивается нагрузка. Сервер должен вносить в БД каждую операцию чтения и записи для каждого отдельного запроса, и в случае резкого увеличения трафика база данных, как правило, отказывает раньше других компонентов.
Сетевые файловые системы – ещё один простой способ хранения данных; при этом не требуется вносить изменения в базу исходных текстов, однако сетевые системы очень медленно обрабатывают I/O операции, а это может оказать негативное влияние на производительность приложения.
Липкие сессии
Липкие сессии реализуются на балансировщике нагрузки и не требуют никаких изменений в нодах приложения. Это наиболее удобный метод обработки пользовательских сессий. Балансировщик нагрузки будет постоянно направлять пользователя на один и тот же сервер, что устраняет необходимость распространять данные о сессии между остальными нодами кластера.
Однако это решение тоже имеет один серьёзный недостаток. Теперь балансировщик не только распределяет нагрузку, у него появляется дополнительная задача. Это может повлиять на его производительность и привести к сбою.
Серверы Memcached и Redis
Также можно настроить один или несколько дополнительных серверов для обработки сессий. Это самый надёжный способ решения проблем, связанных с обработкой сессий.
Memcached и Redis – это чрезвычайно быстрые хранилища «ключ-значение», которые позволяют обрабатывать сессии PHP. Установив один из этих серверов, нужно открыть к ним доступ для остальных серверов кластера, после чего кластер сможет использовать этот сервер в качестве обработчика сессий. Также для этой настройки необходимо установить специальное расширение PHP и изменить параметры php.ini.
Более подробную информацию можно получить в официальной документации и руководстве PHP.
Согласованность файлов
На данном этапе нужно найти средство для поддержки согласованности загруженных файлов, поскольку они могут храниться на любом из нодов кластера.
Эту проблему можно решить несколькими способами. К примеру, можно использовать GlusterFS, инструмент, который создаёт хранилище для совместного использования, дублирующее весь загруженный контент.
Также можно внедрить объектное хранение; это может быть BLOB-хранилище или облачное хранилище. Однако такое решение внесёт множество изменений в базу исходного кода.
Балансировка нагрузки
Стандартным средством для балансировки нагрузки является открытый балансировщик HAProxy. Его используют проекты с очень большой нагрузкой (например, Twitter, Instagram, Imgur). Подробнее об установке и использовании этого инструмента можно узнать в руководстве «Балансировка нагрузки HTTP с помощью HAProxy на сервере Ubuntu».
Заключительные действия
Горизонтальное масштабирование приложения сначала кажется очень сложным и запутанным решением, однако оно помогает устранить серьёзные проблемы с трафиком. Главное – научиться работать с балансировщиком нагрузки, чтобы понимать, какие из компонентов требуют дополнительной настройки.
Масштабирование и производительность приложения очень тесно связаны между собой. Конечно, масштабирование нужно далеко не всем приложениям и сайтам. Однако лучше подумать об этом заранее, желательно ещё на стадии разработки приложения.
Вертикальное и горизонтальное масштабирование систем

В последнее время нередки утверждения, что серверы среднего и старшего класса активно заменяются на группы серверов начального уровня, объединенные в стойки или кластеры. Однако некоторые эксперты с этим не согласны. Так, по данным Dataquest, доля моделей ценой от 500 тыс. долл. и выше (к ним относятся средние и старшие серверы SMP) в общем объеме продаж серверов с 2000 до 2002 г. выросла с 38 до 52%.
Эта тенденция сложилась в результате выделения в центрах обработки данных разных уровней вычислений (рис. 1). Уровень 1, или фронтальный уровень, постепенно переходит на модель горизонтального масштабирования небольших серверов, а на уровне 3 (уровне баз данных) преобладают серверы с вертикальным масштабированием. Уровень 2 (уровень приложений) становится областью, где сосуществуют вертикальная и горизонтальная архитектуры.
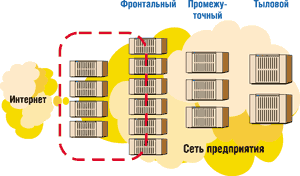 | Рис. 1. Уровни вычислений в центрах обработки данных. |
Вертикальная и горизонтальная архитектуры
При альтернативном, горизонтальном масштабировании системы соединяются через сеть или объединяются в кластер. Для межсоединений обычно используются стандартные сетевые технологии, такие, как Fast Ethernet, Gigabit Ethernet (GBE) и Scalable Coherent Interconnect (SCI), дающие меньшую пропускную способность и большее запаздывание по сравнению с вертикальными системами. Ресурсы в этом случае распределяются между узлами, обычно содержащими от одного до четырех процессоров; каждый узел имеет собственный процессор и память и может иметь собственную подсистему ввода-вывода или использовать ее совместно с другими узлами. На каждом узле работает отдельная копия ОС. Ресурсы расширяются за счет добавления узлов, но не добавления ресурсов в узел. Память в горизонтальных системах распределена, т. е. у каждого узла есть собственная память, к которой напрямую обращаются его процессоры и подсистема ввода-вывода. Доступ к этим ресурсам с другого узла происходит намного медленнее, чем с узла, где они расположены. Кроме того, при горизонтальной архитектуре отсутствует согласованный доступ узлов к памяти, а используемые приложения потребляют относительно немного ресурсов, поэтому они «умещаются» на одном узле и им не нужен согласованный доступ. Если же приложению потребуется несколько узлов, то оно само должно обеспечить согласованный доступ к памяти.
Помимо одного большого SMP-сервера, к вертикальной архитектуре относятся также кластеры больших SMP-серверов, используемые для одного крупномасштабного приложения.
Таблица 1. Особенности вертикальной и горизонтальной архитектур
| Параметр | Вертикальные системы | Горизонтальные системы |
| Память | Большая совместно используемая | Небольшая выделенная |
| Потоки | Много взаимозависимых потоков | Много независимых потоков |
| Межсоединения | Сильносвязанные внутренние | Слабосвязанные внешние |
| RAS | Мощные RAS одиночной системы | Мощные RAS с использованием репликации |
| Центральные процессоры | Много стандартных | Много стандартных |
| ОС | Одна копия ОС на множество центральных процессоров | Несколько копий ОС (по одной копии на 1-4 процессора) |
| Компоновка | В одном шкафу | Размещение большого числа серверов в стойке |
| Плотность размещения | Высокая плотность размещения процессоров на единицу площади пола | Высокая плотность размещения процессоров на единицу площади пола |
| Оборудование | Стандартное и специально разработанное | Стандартное |
| Масштабирование | В пределах корпуса одного сервера | В масштабе нескольких серверов |
| Расширение | Путем установки в сервер дополнительных компонентов | Путем добавления новых узлов |
| Архитектура | 64-разрядная | 32- и 64-разрядная |
Таблица 2. Типы приложений для вертикальной и горизонтальной архитектур
Факторы, влияющие на производительность
Все крупные центры обработки данных представляют собой параллельные компьютеры. Здесь даже кластеры можно рассматривать как особый тип параллельных систем. Для получения высокой производительности требуется сбалансированная система с мощными процессорами, работающими на высокой скорости межсоединениями и подсистемой ввода-вывода, масштабируемой ОС, оптимизированными приложениями и совершенными функциями RAS.
Процессоры и системные межсоединения
Процессоры, безусловно, существенный компонент, но они только отчасти определяют общую производительность системы. Более важно обеспечить работу процессоров с максимальной загрузкой. У мощного процессора, загруженного лишь на 50%, производительность будет хуже, чем у более медленного процессора, который загружен на 80%.
Системные межсоединения также используются для перемещения адресов данных, что необходимо для поддержки согласованного обращения к кэш-памяти. Если системное межсоединение слишком медленно передает адреса данных, то процессор опять-таки будет простаивать в ожидании данных, поскольку для доступа к ним ему нужно знать их адрес. Быстрые межсоединения обеспечивают высокую пропускную способность и низкое запаздывание (малое время, проходящее от момента запроса на данные до начала передачи данных).
Ввод и вывод
Быстрый ввод-вывод необходим для того, чтобы межсоединение могло быстро получить данные с диска и из сети и передать их процессорам. Узкое место в подсистеме ввода-вывода может отрицательно сказаться на работе даже самых быстрых межсоединений и процессоров.
Операционная система
Даже лучшее оборудование оказывается неэффективным, если ОС недостаточно масштабируема. Для горизонтальных систем масштабируемость ОС не столь важна, потому что в отдельном узле или с отдельной копией ОС работает не более четырех процессоров.
Доступность системы
Вообще говоря, доступность системы во многом зависит от типа архитектуры. В больших SMP-системах функции RAS встроены в систему и дополнены переключением при отказах для двух-четырех узлов. В горизонтальных системах RAS отдельных узлов хуже, но улучшение этих функций достигается многократной репликацией узлов.
Оптимизированные приложения
Приложения необходимо оптимизировать для архитектуры вычислительной системы. Легче всего писать и оптимизировать приложения для SMP-систем. Основные коммерческие приложения оптимизированы именно для SMP-систем и даже разрабатывались на них, поэтому SMP доминируют на рынке систем среднего класса и high-end последние десять лет.
Размер приложений
Например, в случае горизонтальной архитектуры (или архитектуры с распределенной памятью) четыре процессорных узла (каждый с отдельным ОЗУ и выделенной либо используемой совместно подсистемой ввода-вывода) могут использовать сетевое межсоединение, например, Gigabit Ethernet. В этой вычислительной среде выполняются рабочие нагрузки трех типов. Самая маленькая нагрузка помещается на одном узле, но по мере ее увеличения для выполнения требуется уже несколько узлов. Как утверждают специалисты, при выполнении одной задачи на нескольких узлах производительность значительно ухудшается из-за медленных межузловых межсоединений. Небольшие нагрузки, которым не нужно обмениваться данными между собой, прекрасно сочетаются с горизонтальной архитектурой, но при выполнении в ней крупномасштабных нагрузок возникают проблемы.
Часто возникает вопрос о целесообразности размещения на больших SMP малых нагрузок. Хотя в техническом плане это возможно, с экономической точки зрения такой подход себя не оправдывает. Для больших SMP стоимость приобретения в расчете на один процессор выше, чем для маленьких систем. Поэтому если приложение может работать на небольшом узле (или нескольких небольших узлах) и это не создает серьезных проблем с управлением, для его развертывания лучше подходит горизонтальное масштабирование. Но если приложение слишком велико и не может выполняться на небольшом узле (или нескольких таких узлах), то крупный SMP-сервер будет оптимальным вариантом с точки зрения как производительности, так и системного администрирования.
Производительность на уровне базы данных
При обсуждении масштабируемости фирмы-производители используют ряд специальных терминов. Так, рост производительности (Speedup) для SMP определяется как отношение скоростей выполнения приложения на нескольких процессорах и на одном. Линейный рост производительности (Linear speedup) означает, например, что на 40 процессорах приложение работает в 40 раз (40x) быстрее, чем на одном. Рост производительности не зависит от числа процессоров, т. е. для конфигурации из 24 процессоров он будет таким же, как для 48 процессоров. Рост производительности кластера (Cluster speedup) отличается только тем, что при его расчете берется число узлов, а не процессоров. Как и рост производительности SMP, рост производительности кластера остается постоянным для разного числа узлов.
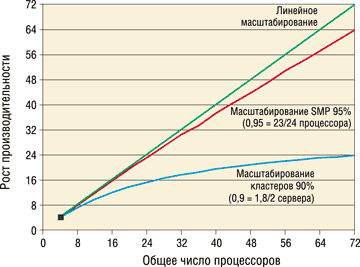 | Рис. 2. Показатели масштабируемости. |
Опубликованные результаты эталонных тестов показывают, например, что у Oracle9i RAC (Real Application Cluster) рост производительности составляет 1,8 и эффективность масштабирования равна 90%. Такая эффективность масштабируемости может показаться достаточно высокой, но на самом деле масштабируемость 90% для четырех узлов оказывается неэффективной, если сравнить ее с результатами больших SMP-серверов.
Производительность на уровне приложений
Считается, что серверы приложений не требуется распределять по нескольким узлам. Несколько копий прикладного ПО можно распределить по разным физическим серверам разной мощности или по динамическим доменам больших серверов.
Число процессоров, требуемых для уровня приложений, будет примерно одинаково независимо от архитектуры компьютеров. Затраты на приобретение оборудования и ПО для горизонтальной архитектуры будут меньше, поскольку стоимость в расчете на один процессор в этом случае меньше. В большинстве случаев горизонтальные системы способны обеспечить производительность, необходимую для выполнения соглашения об уровне сервиса. Затраты, связанные с приобретением лицензий на ПО, для обеих архитектур примерно одинаковы.
В то же время расходы на управление и обслуживание инфраструктуры у горизонтальной архитектуры могут оказаться более высокими. При развертывании на горизонтальных системах используются многочисленные копии ОС и ПО серверов приложений. Затраты же на поддержание инфраструктуры обычно растут пропорционально числу копий ОС и приложений. Кроме того, для горизонтальной архитектуры резервное копирование и восстановление после аварий становится децентрализованным, и управлять сетевой инфраструктурой сложнее.
Стоимость системного администрирования с трудом поддается измерениям. Обычно модели для сравнения горизонтального и вертикального развертывания прикладных серверов показывают, что управление меньшим числом более мощных серверов (вертикальных серверов) обходится дешевле, чем управление множеством небольших серверов. В целом при выборе типа архитектуры для развертывания уровня приложений ИТ-менеджеры должны детально проанализировать стоимость приобретения оборудования.
Влияние архитектуры на доступность
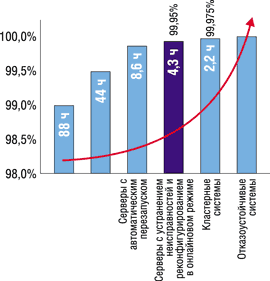 | Рис. 3. Доступность и продолжительность простоев для разных типов систем. |
По мере роста требований к доступности растет и стоимость решения. Менеджеры центров обработки данных должны определить, какое сочетание стоимости, сложности и доступности наилучшим образом соответствует требованиям к уровню сервиса. Центры обработки данных, которым нужна доступность примерно 99,95%, могут развернуть одиночный SMP-сервер с такими функциями RAS, как полное резервирование аппаратуры и обслуживание в онлайновом режиме.
Если простои в несколько минут недопустимы для центра обработки данных, то решением может стать система типа «активный-активный», где приложение развертывается на двух или нескольких узлах: если один из них выйдет из строя, то остальные продолжат выполнение приложения. В результате перебой будет очень коротким (некоторые клиенты сообщают, что он продолжается менее 1 мин), иногда пользователь может даже не заметить отказа узла.
Вертикальные серверы обеспечивают высокую доступность за счет встраивания многих функций RAS в отдельный сервер для сокращения до минимума запланированных и незапланированных простоев. В горизонтальных серверах функции, обеспечивающие высокий уровень RAS, реализуются не на уровне отдельного сервера, а за счет дублирования и размещения нескольких серверов. Из-за разной реализации функций RAS и межсоединений горизонтальные серверы обычно дешевле в расчете на один процессор.
Для трехуровневой архитектуры хорошим примером горизонтальной высокой доступности служит развертывание Web-серверов. Можно развернуть много небольших серверов, на каждом из которых будет установлена отдельная копия ПО Web-сервера. Если один Web-сервер выйдет из строя, его транзакции перераспределяются между остальными работоспособными серверами. В случае серверов приложений они могут размещаться как на горизонтальных, так и на вертикальных серверах, и высокая доступность реализуется с помощью дублирования. Независимо от того, развертывается ли несколько крупных SMP-серверов или много небольших, дублирование остается основным способом обеспечения высокого RAS на уровне приложений.
Однако для уровня баз данных ситуация меняется. Базы данных сохраняют состояние и по своей природе требуют в большинстве случаев разделения данных и возможности доступа к ним со всех процессоров/узлов. Это означает, что для высокой доступности с помощью дублирования нужно использовать такое ПО кластеризации, как Sun Cluster или Oracle9i RAC (для очень высокой доступности).
Выводы
Как у вертикальной, так и у горизонтальной архитектуры есть своя ниша в сегодняшнем центре обработки данных. Хотя сегодня основное внимание сосредоточено на таких новых технологиях, как модульные серверы и параллельные базы данных, на рынке сохраняется высокий спрос на серверы среднего класса и класса high-end.
Для фронтального уровня горизонтальные серверы обычно предоставляют оптимальное решение с точки зрения производительности, совокупной стоимости приобретения и доступности. Для уровня приложений можно эффективно использовать как вертикальную, так и горизонтальную архитектуру. Для уровня баз данных оптимальным решением будет использование вертикальных серверов, независимо от требуемого уровня доступности.
Другие статьи из раздела
 Chloride
Chloride
Демонстрация Chloride Trinergy
Впервые в России компания Chloride Rus провела демонстрацию системы бесперебойного электропитания Chloride Trinergy®, а также ИБП Chloride 80-NET™, NXC и NX для своих партнеров и заказчиков.
 NEC Нева Коммуникационные Системы
NEC Нева Коммуникационные Системы
Завершена реорганизация двух дочерних предприятий NEC Corporation в России
С 1 декабря 2010 года Генеральным директором ЗАО «NEC Нева Коммуникационные Системы» назначен Раймонд Армес, занимавший ранее пост Президента Shyam …
 компания «Гротек»
компания «Гротек»
С 17 по 19 ноября 2010 в Москве, в КВЦ «Сокольники», состоялась VII Международная выставка InfoSecurity Russia. StorageExpo. Documation’2010.
Новейшие решения защиты информации, хранения данных и документооборота и защиты персональных данных представили 104 организации. 4 019 руководителей …
 МФУ Panasonic DP-MB545RU с возможностью печати в формате А3
МФУ Panasonic DP-MB545RU с возможностью печати в формате А3
Хотите повысить эффективность работы в офисе? Вам поможет новое МФУ #Panasonic DP-MB545RU. Устройство осуществляет
 Adaptec by PMC
Adaptec by PMC
RAID-контроллеры Adaptec Series 5Z с безбатарейной защитой кэша
Опытные сетевые администраторы знают, что задействование в работе кэш-памяти RAID-контроллера дает серьезные преимущества в производительности …
 Chloride
Chloride
Трехфазный ИБП Chloride от 200 до 1200 кВт: Trinergy
Trinergy — новое решение на рынке ИБП, впервые с динамическим режимом работы, масштабируемостью до 9.6 МВт и КПД до 99%. Уникальное сочетание …



