Накопительный итог
Есть несколько способ посчитать накопительный итог в Excel. Один из самых простых способов, использовать функцию «СУММ» совместно с постоянными ссылками на ячейки.
Исходные данные
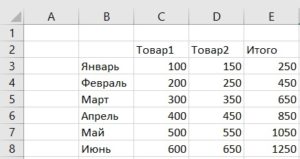
У нас есть таблица, отражающая продажи двух товаров за полгода. Необходимо добавить столбец F в котором будут отражаться итоги продаж как накопительный итог.
Формула
Введем в ячейку F3 следующую формулу — =СУММ($E$3:E3). И растянем ее на следующие ячейки. Так чтобы формула была во всем диапазоне ячеек, от F3 до F8. В результате получим такой результат:
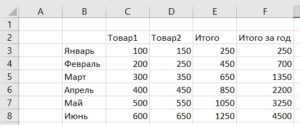
Получили что и хотели, в столбце «Итого за год» у нас отображаются накопительные итоги с начала года.
Логика действия функции очень проста, в первой ячейке ссылка функции «СУММ» указывает не на диапазон, а на одну ячейку Е3. Функция «СУММ» принимает параметром диапазон ячеек, и в случае, когда диапазон состоит из одной ячейки, функция его и воспринимает как диапазон длинной 1 ячейка, фактический просто возвращая результат. После ввода формулы в ячейку F3 мы растягивали ее на следующие ячейки, и для того что бы Excel не сдвигал автоматический ссылку с первой ячейки диапазона, мы указываем ее как статическую. Второй параметр диапазона будет меняться при распространении действия формулы на другие ячейки. Что в результате и приведет к необходимому итогу, мы получим в последнем значении нашего столбца накопительный итог.
Что такое накопительный(промежуточный) итог SQL и как его вычислить?
Расчет промежуточного итога SQL — это очень распространенный шаблон, часто используемый в анализе. В этой статье вы узнаете, что такое промежуточный итог и как написать SQL-запрос для его вычисления.
Что такое промежуточный итог SQL?
В SQL промежуточный итог — это совокупная сумма предыдущих чисел в столбце. Посмотрите на пример ниже, в котором представлен список продаж продуктов в день:
| Дата продажи | Количество проданных продуктов | Накопительный итог |
| 2021-04-10 | 10 | 10 |
| 2021-04-11 | 15 | 25 |
| 2021-04-12 | 5 | 30 |
В первом столбце отображается дата. Во втором столбце показано количество проданных продуктов в этот день. В третьем столбце [Накопительный итог] суммируется общее количество проданных продуктов в этот день.
Например, в первый день (2021-04-10) сотрудник продал 10 продуктов, и общее количество проданных продуктов составило 10. На следующий день (2021-04-11) сотрудник продал 15 продуктов; [Накопительный итог] равен 25 (10 + 15). На третий день (2021-04-12) сотрудник продал пять продуктов, и значение [Накопительный итог] равен 30. Другими словами, [Накопительный итог] — это текущее значение, которое меняется день ото дня. Это общее количество проданных продуктов за день.
Далее мы поговорим о SQL-запросе, который позволяет получить такой итог, и узнаем больше об оконных функциях.
Как вычислить совокупный итог в MSSQL
Если вы хотите вычислить промежуточный итог в MSSQL, вам необходимо знать оконные функции, предоставляемые вашей базой данных. Оконные функции работают с набором строк и возвращают агрегированное значение для каждой строки в наборе результатов.
Синтаксис оконной функции SQL, вычисляющей совокупный итог по строкам, следующий:
| window_function ( column ) OVER ( [ PARTITION BY partition_list ] [ ORDER BY order_list] ) |
Предложение OVER обязательно использовать в оконной функции, но аргументы в этом предложении необязательны.
Пример
В этом примере мы будем вычислять общую текущую сумму проданных продуктов каждый день.
| Дата продажи | Количество проданных продуктов |
| 2021-04-10 | 10 |
| 2021-04-11 | 15 |
| 2021-04-12 | 5 |
Данный запрос выбирает дату продажи для всех пользователей. Нам также нужна сумма всех продуктов за каждый день, начиная с первого заданного дня (2021-04-10):
| Дата продажи | Количество проданных продуктов | Накопительный итог |
| 2021-04-10 | 10 | 10 |
| 2021-04-11 | 15 | 25 |
| 2021-04-12 | 5 | 30 |
Чтобы вычислить промежуточный итог, мы используем SUM()агрегатную функцию и указываем столбец kolvo_product в качестве аргумента; мы хотим получить совокупную сумму проданных продуктов из этого столбца.
Следующим шагом будет использование предложения OVER. В нашем примере это условие имеет один аргумент: ORDER BY c_date. Строки результирующего набора сортируются в соответствии с этим столбцом ( c_date).
Для каждого значения в столбце c_date вычисляется общая сумма значений предыдущего столбца (т. е. сумма проданных продуктов до даты в текущей строке) и к ней добавляется текущее значение (т. е. продукты, проданные в день текущей строки). Общая сумма отображается в новом столбце, который мы назвали total_product.
На первом этапе (Дата продажи 2021-04-10) у нас 10 проданных продуктов. Сумма продуктов, проданных в этот день, та же — 10. На следующем шаге мы прибавляем к этой общей сумме (10) количество проданных продуктов на текущую дату (2021-04-11) — 15; это дает нам промежуточную сумму 25. В последней строке набора результатов (для последней даты продажи, 2021-04-12) промежуточная сумма равна 30.
Благодаря оконным функциям SQL легко найти кумулятивное общее количество проданных продуктов за заданный период времени. Например, в период с 10 апреля по 12 апреля 2021 года общее количество проданных продуктов равно 30.
Накопительные итоги стр. 1
В предположении некоторой упорядоченности строк накопительный итог для каждой строки представляет собой сумму значений некоторого числового столбца для этой строки и всех строк, расположенных выше данной.
Другими словами, накопительный итог для первой строки в упорядоченном наборе будет равен значению в этой строке. Для любой другой строки накопительный итог будет равен сумме значения в этой строке и накопительного итога в предыдущей строке.
Рассмотрим, например, такую задачу.
Для пункта 2 по таблице Outcome_o получить на каждый день суммарный расход за этот день и все предыдущие дни.
Вот запрос, который выводит информацию о расходах на пункте 2 в порядке возрастания даты
|
Фактически, чтобы решить задачу нам нужно добавить еще один столбец, содержащий накопительный итог (run_tot). В соответствии с темой, этот столбец будет представлять собой коррелирующий подзапрос, в котором для ТОГО ЖЕ пункта, что и у ТЕКУЩЕЙ строки включающего запроса, и для всех дат, меньших либо равных дате ТЕКУЩЕЙ строки включающего запроса, будет подсчитываться сумма значений столбца out:
|
Собственно, использование пункта 2 продиктовано желанием уменьшить результирующую выборку. Чтобы получить накопительные итоги для каждого из пунктов, имеющихся в таблице Outcome_o, достаточно закомментировать строку
Ну а чтобы получить «сквозной» накопительный итог для всей таблицы нужно, видимо, убрать условие на равенство пунктов:
Однако при этом мы получим один и тот же накопительный итог для разных пунктов, работавших в один и тот же день. Вот подобный фрагмент из результирующей выборки,
|
Но это не проблема, если понять, что же мы хотим в итоге получить. Если нас интересует накопление расхода по дням, то нужно из выборки вообще исключить пункт и суммировать расходы по дням:
Нарастающий итог в SQL
Нарастающий (накопительный) итог долго считался одним из вызовов SQL. Что удивительно, даже после появления оконных функций он продолжает быть пугалом (во всяком случае, для новичков). Сегодня мы рассмотрим механику 10 самых интересных решений этой задачи – от оконных функций до весьма специфических хаков.
В электронных таблицах вроде Excel нарастающий итог вычисляется очень просто: результат в первой записи совпадает с её значением:

… а затем мы суммируем текущее значение и предыдущий итог.


Появление в таблице двух и более групп несколько усложняет задачу: теперь мы считаем несколько итогов (для каждой группы отдельно). Впрочем, и здесь решение лежит на поверхности: необходимо каждый раз проверять, к какой группе принадлежит текущая запись. Click and drag, и работа выполнена:
Как можно заметить, подсчёт нарастающего итога связан с двумя неизменными составляющими:
(а) сортировкой данных по дате и
(б) обращением к предыдущей строке.
Но что SQL? Очень долго в нём не было нужного функционала. Необходимый инструмент – оконные функции – впервые появился только стандарте SQL:2003. К этому моменту они уже были в Oracle (версия 8i). А вот реализация в других СУБД задержалась на 5-10 лет: SQL Server 2012, MySQL 8.0.2 (2018 год), MariaDB 10.2.0 (2017 год), PostgreSQL 8.4 (2009 год), DB2 9 для z/OS (2007 год), и даже SQLite 3.25 (2018 год).
1. Оконные функции
Оконные функции – вероятно, самый простой способ. В базовом случае (таблица без групп) мы рассматриваем данные, отсортированные по дате:
… но нас интересуют только строки до текущей:
В конечном итоге, нам нужна сумма с этими параметрами:
А полный запрос будет выглядеть так:
В случае нарастающего итога по группам (поле grp ) нам требуется только одна небольшая правка. Теперь мы рассматриваем данные как разделённые на «окна» по признаку группы:
Чтобы учесть это разделение необходимо использовать ключевое слово partition by :
И, соответственно, считать сумму по этим окнам:
Тогда весь запрос преобразуется таким образом:
Производительность оконных функций будет зависеть от специфики вашей СУБД (и её версии!), размеров таблицы, и наличия индексов. Но в большинстве случаев этот метод будет самым эффективным. Тем не менее, оконные функции недоступны в старых версиях СУБД (которые ещё в ходу). Кроме того, их нет в таких СУБД как Microsoft Access и SAP/Sybase ASE. Если необходимо вендоро-независимое решение, следует обратить внимание на альтернативы.
2. Подзапрос
Как было сказано выше, оконные функции были очень поздно введены в основных СУБД. Эта задержка не должна удивлять: в реляционной теории данные не упорядочены. Куда больше духу реляционной теории соответствует решение через подзапрос.
Такой подзапрос должен считать сумму значений с датой до текущей (и включая текущую):  .
.
Что в коде выглядит так:
Чуть более эффективным будет решение, в котором подзапрос считает итог до текущей даты (но не включая её), а затем суммирует его со значением в строке:
В случае нарастающего итога по нескольким группам нам необходимо использовать коррелированный подзапрос:
Условие g.grp = t2.grp проверяет строки на вхождение в группу (что, в принципе, сходно с работой partition by grp в оконных функциях).
3. Внутреннее соединение
Поскольку подзапросы и джойны взаимозаменяемы, мы легко можем заменить одно на другое. Для этого необходимо использовать Self Join, соединив два экземпляра одной и той же таблицы:
Точно также можно сделать для случая с разными группами grp :
4. Декартово произведение
Раз уж мы заменили подзапрос на join, то почему бы не попробовать декартово произведение? Это решение потребует только минимальных правок:
Или для случая с группами:
Перечисленные решения (подзапрос, inner join, cartesian join) соответсвуют SQL-92 и SQL:1999, а потому будут доступны практически в любой СУБД. Основная проблема всех этих решений в низкой производительности. Это не велика беда, если мы материализуем таблицу с результатом (но ведь всё равно хочется большей скорости!). Дальнейшие методы куда более эффективны (с поправкой на уже указанные специфику конкретных СУБД и их версий, размер таблицы, индексы).
5. Рекурсивный запрос
Один из более специфических подходов – это рекурсивный запрос в common table expression. Для этого нам необходим «якорь» – запрос, возвращающий самую первую строку:
Часть кода, добавляющая один день, не универсальна. Например, это r.dt = dateadd(day, 1, cte.dt) для SQL Server, r.dt = cte.dt + 1 для Oracle, и т.д.
Совместив «якорь» и основной запрос, мы получим окончательный результат:
Решение для случая с группами будет ненамного сложнее:
6. Рекурсивный запрос с функцией row_number()
Итак, для рекурсивного запроса с row_number() нам понадобится два СТЕ. В первом мы только нумеруем строки:
… и если номер строки уже есть в таблице, то можно без него обойтись. В следующем запросе обращаемся уже к cte1 :
А целиком запрос выглядит так:
… или для случая с группами:
7. Оператор CROSS APPLY / LATERAL
Один из самых экзотических способов расчёта нарастающего итога – это использование оператора CROSS APPLY (SQL Server, Oracle) или эквивалентного ему LATERAL (MySQL, PostgreSQL). Эти операторы появились довольно поздно (например, в Oracle только с версии 12c). А в некоторых СУБД (например, MariaDB) их и вовсе нет. Поэтому это решение представляет чисто эстетический интерес.
Функционально использование CROSS APPLY или LATERAL идентично подзапросу: мы присоединяем к основному запросу результат вычисления:
… что целиком выглядит так:
Похожим будет и решение для случая с группами:
Итого: мы рассмотрели основные платформо-независимые решения. Но остаются решения, специфичные для конкретных СУБД! Поскольку здесь возможно очень много вариантов, остановимся на нескольких наиболее интересных.
8. Оператор MODEL (Oracle)
Оператор MODEL в Oracle даёт одно из самых элегантных решений. В начале статьи мы рассмотрели общую формулу нарастающего итога:
MODEL позволяет реализовать эту формулу буквально один к одному! Для этого мы сначала заполняем поле total значениями текущей строки
Функция cv() здесь отвечает за значение текущей строки. А весь запрос будет выглядеть так:
9. Курсор (SQL Server)
Нарастающий итог – один из немногих случаев, когда курсор в SQL Server не только полезен, но и предпочтителен другим решениям (как минимум до версии 2012, где появились оконные функции).
Реализация через курсор довольно тривиальна. Сначала необходимо создать временную таблицу и заполнить её датами и значениями из основной:
Затем задаём локальные переменные, через которые будет происходить обновление:
После этого обновляем временную таблицу через курсор:
И, наконец, получем нужный результат:
10. Обновление через локальную переменную (SQL Server)
Обновление через локальную переменную в SQL Server основано на недокументированном поведении, поэтому его нельзя считать надёжным. Тем не менее, это едва ли не самое быстрое решение, и этим оно интересно.
Создадим две переменные: одну для нарастающих итогов и табличную переменную:
Сначала заполним @tv данным из основной таблицы
Затем табличную переменную @tv обновим, используя @VarTotal :
… после чего получим окончательный результат:
Резюме: мы рассмотрели топ 10 способов расчёта нарастающего итога в SQL. Как можно заметить, даже без оконных функций эта задача вполне решаема, причём механику решения нельзя назвать сложной.
Накопительный итог VS Данные по дням
Варианты форматов данных
Как правило, данные, которые можно получить из источников, отдаются в одном из двух возможных форматов. В качестве примера данных в этой статье будут использоваться показы роликов на ютуб.
Проблема
Очень редко, когда данные можно получить сразу в двух форматах, при этом смотреть данные в обоих вариантах иногда бывает очень полезно.
Решение
Ниже мы рассмотрим варианты преобразования формата данных от одного к другому и какие могут возникать проблемы при этом.
Часть 1. Разбиваем накопительный итог по дням
Мы будем исходить из следующего утверждения — если на сегодня у ролика 90 показов, а вчера было 59, то за сегодня прибавился 31 показ.
Метод 1.1. Power Query. Кастомный столбец
Чтобы узнать сколько было показов на конкретную дату, нужно отнять из текущего показателя показов количество показов на предыдущую дату. Если после сортировки по дате по убыванию нужное нам число показов находится в строчке ниже, то самым простым способом будет создать индексный столбец, а затем кастомный столбец:
В данном случае:
Source («Источник» в русской версии) — техническое слово, указывающее на вашу текущую таблицу
[Index] — столбец с индексом
[views] — столбец с показами
Всё это оформлено в структуру try otherwise, чтобы для строчки в которой нет предыдущего значения показов (самой последней) вместо ошибки получить количество показов на текущую дату.
Что делать, если строчки относятся не к одному ролику, а к несколькими, а также просто другие подходы к решению этой задачи мы рассмотрим ниже.
Метод 1.2. Power Query. Таблица-дубликат с предыдущими значениями
Вторым вариантом, чтобы узнать сколько было показов в предыдущий день будет взять нашу таблицу, сделать дубликат и сделать смещение. После чего можно объединить ее с основной таблицей.
Пошаговая инструкция:
Шаг 1. Создаем дубликат таблицы (именно дубликат, а не ссылку, поскольку в дальнейшем мы будем присоединять это таблицу к основной и при использовании ссылки у нас получится циклическая зависимость)
Шаг 2. Делаем смещение даты
1) Преобразуем дату в числовой формат
2) Добавляем единицу
3) Преобразуем число обратно в дату
Шаг 3. Присоединяем таблицу с предыдущими значениями к основной по полю даты.
Шаг 4. Создаем кастомный столбец, где вычитаем из текущего количество показов, данные за предыдущий день
Шаг 5. Профит!
Метод 1.3. Power Query. Используем календарь (заполнение пробелов)
Вышеописанный метод будет работать в идеальных условиях, когда в наших данных нет разрывов, а так бывает далеко не всегда, если у вас не хватает данных за какой-то день, то их можно восстановить. Для этого есть разные методы, в данном случае мы просто будем исходить из того, что если данных нет, то прирост в этот день был равен 0. А следовательно, будем брать ближайшее предыдущее непустое значение.
Для этого нам понадобится календарь, который будет покрывать весь интересующий интервал, при этом в нём не должно быть разрывов. Способов создания календаря очень много, в качестве примера можно использовать тот, что написан ниже.
Пошаговая инструкция:
Шаг 1. Сортируем по убыванию дат нашу таблицу (календарь также должен быть отсортирован по убыванию)
Шаг 2. Присоединяем календарь к основной таблице по дате (нужно использовать правое соединение, чтобы были добавлены все даты из календаря и появились пробелы в показах)
Шаг 3. Удаляем старый столбец с датой (теперь даты из календаря будут нашими датами)
Шаг 4. Используем заполнение вниз на столбце с показами
Шаг 5. Удаляем пустые значения показов (если ваш календарь содержит больше дат чем нужно, то у вас такие записи точно появятся)
Шаг 6. Повторяем действия из метода 1.2
Метод 1.4. Power Query. Используем ключ
К сожалению, в некоторых случаях метод 1.3 также не является панацеей. К примеру, если вам не нужна куча лишних записей, которые не несут в себе ценности. Или у вас огромный объем данных и добавление большого количества пустых строк может сильно усложнить работу системы.
В этом случае, использование календаря нежелательно и нам нужно найти предыдущее значение, зная что статистики по некоторым дням может не хватать.
На самом деле задача решается аналогично методу 1.2, но только соединять таблицу с предыдущими значениями мы будем не по дате, а по ключу.
Пошаговая инструкция:
Шаг 1. Сортируем по возрастанию даты
Шаг 2. Создаем дубликат основной таблицы
Шаг 3. Добавляем столбец-индекс для основной таблицы (начинаем с 0)
Шаг 4. Добавляем столбец-индекс для таблицы дубликата (начинаем с 1)
Шаг 5. Присоединяем к основной таблице таблицу-дубликат по столбцам-индексам (используем левое соединение)
Шаг 6. Заменяем null на 0 в значениях показов из таблицы-дубликата
Шаг 7. Создаем кастомный столбец, где вычитаем из текущего количество показов, данные за предыдущий день (из таблицы-дубликата)
Шаг 8. Профит!
Что делать, если роликов несколько?
Если в ваших данных есть информация не по одному, а по нескольким роликам, вам необходимо:
1) присоединять данные за предыдущий период, не только по ключу (или дате), а также и по идентификатору ролика;
2) при осуществлении сортировки, необходимо в начале производить сортировку по идентификатору ролика, а потом уже по дате.
Метод 1.5. DAX. Считаем простую меру
Помимо разнообразных способов посчитать изменение данных за сутки с помощью Power Query, естественно, также есть способ посчитать тоже самое с помощью DAX. Мы рассмотрим самый простой способ — создание меры для данных без пропусков и когда все данные относятся к одному ролику.
Часть 2. Собираем накопительный итог из статистики по дням
В данном случае, наоборот, нам предстоит просуммировать статистику показов по всем предыдущим дням, чтобы получить количество показов на конкретную дату.
Метод 2.1. DAX. Считаем меру
Наиболее простым способом в данном случае будет использовать меру:
Метод 2.2. Power Query. Кастомный столбец
Если отсортировать данные по возрастанию даты и добавить столбец с индексом, то можно создать пользовательский столбец таким образом:
Обратите внимание, столбец с индексом при такой формуле должен начинаться с 1. А также, необходимо использовать #»AddedIndex»[views], а не просто [views]. Поскольку в первом случае это список, а во втором значение из столбца [views]. #»AddedIndex» — в данном случае это название последнего шага до создания пользовательского столбца.
Часть 3. Делаем переключение между двумя форматами
После того, как мы получили данные в двух форматах, логично сделать возможность выбора формата выбора.
Для этого нам потребуется вспомогательная табличка ListMode:
| Mode | Index |
| Total | 1 |
| Delta | 2 |
Таблица. ListMode
Дальше нам нужно создать следующую мультимеру (про них подробнее можно почитать здесь):
И создать соответствующий фильтр на основе поле ListMode[Mode] с помощью которого мы будем переключаться между двумя режимами. Сразу рекомендуется разрешить выбор только одного значения в настройках фильтра.
Далее остается только вывести данную меру на визуализацию.



