Компьютерные сети
You are here
Неблокирующие коммутаторы
Как уже отмечалось, высокая производительность является одним из главных достоинств коммутаторов. С понятием производительности тесно связано понятие неблокирующего коммутатора.
Наши партнеры:
— Возможно эта информация Вас заинтересует:
— Посмотрите интересные ссылочки вот тут:
Коммутатор называют неблокирующим, если он может передавать кадры через свои порты с той же скоростью, с которой они на них поступают.
Когда говорят, что коммутатор может поддерживать устойчивый неблокирующий режим работы, то имеют в виду, что коммутатор передает кадры со скоростью их поступления в течение произвольного промежутка времени. Для поддержания подобного режима нужно таким образом распределить потоки кадров по выходным портам, чтобы, во-первых, порты справлялись с нагрузкой, во-вторых, коммутатор мог всегда в среднем передать на выходы столько кадров, сколько их поступило на входы. Если же входной поток кадров (просуммированный по всем портам) в среднем будет превышать выходной поток кадров (также просуммированный по всем портам), то кадры будут накапливаться в буферной памяти коммутатора и при переполнении просто отбрасываться.
В этом соотношении под производительностью коммутатора в целом понимается его способность продвигать определенное количество кадров, принимаемых от приемников всех его портов, на передатчики всех его портов.
В суммарной производительности портов каждый проходящий кадр учитывается дважды, как входящий и как выходящий, а так как в устойчивом режиме входной трафик равен выходному, то минимально достаточная производительность коммутатора для поддержки неблокирующего режима равна половине суммарной производительности портов. Если порт, например, стандарта Ethernet со скоростью 10 Мбит/с работает в полудуплексном режиме, т о производительность порта Сpt равна 10 Мбит/с, а если в дуплексном — 20 Мбит/с.
Иногд а говорят, что коммутатор поддерживает мгновенный неблокирующий режим. Это означает, что он может принимать и обрабатывать кадры от всех своих портов на максимальной скорости протокола независимо от того, обеспечиваются ли условия устойчивого равновесия между входным и выходным трафиком. Правда, обработка некоторых кадров при этом может быть неполной — при занятости выходного порта кадр помещается в буфер коммутатора.
Способы, которыми обеспечивается способность коммутатора поддерживать неблокирующий режим, могут быть разными. Необходимым требованием является умение процессора порта обрабатывать потоки кадров с максимальной для физического уровня этого порта скоростью. В главе 12 мы подсчитали, что максимальная производительность порта Ethernet стандарта 10 Мбит/с равна 14 880 кадров в секунду. Это означает, что процессоры портов Ethernet стандарта 10 Мбит/с неблокирующего коммутатора должны поддерживать продвижение кадров со скоростью 14 880 кадров в секунду.
Однако только адекватной производительности процессоров портов недостаточно для того, чтобы коммутатор был неблокирующим. Необходимо, чтобы достаточной производительностью обладали все элементы архитектуры коммутатора, включая центральный процессор, общую память, шины, соединяющие отдельные модули между собой, саму архитектуру коммутатора (наиболее распространенные архитектуры коммутаторов мы рассмотрим позже). В принципе, задача создания неблокирующего коммутатора аналогична задаче создания высокопроизводительного компьютера — в обоих случаях она решается комплексно: за счет соответствующей архитектуры объединения модулей в едином устройстве и адекватной производительности каждого отдельного модуля устройства.
Что такое неблокирующий коммутатор
Как уже отмечалось, высокая производительность является одним из главных достоинств коммутаторов. С понятием производительности тесно связано понятие неблокирующего коммутатора.

Когда говорят, что коммутатор может поддерживать устойчивый неблокирующий режим работы, то имеют в виду, что коммутатор передает кадры со скоростью их поступления в течение произвольного промежутка времени. Для поддержания подобного режима нужно таким образом распределить потоки кадров по выходным портам, чтобы, во-первых, порты справлялись с нагрузкой, во-вторых, коммутатор мог всегда в среднем передать на выходы столько кадров, сколько их поступило на входы. Если же входной поток кадров (просуммированный по всем портам) в среднем будет превышать выходной поток кадров (также просуммированный по всем портам), то кадры будут накапливаться в буферной памяти коммутатора и при переполнении просто отбрасываться.

В этом соотношении под производительностью коммутатора в целом понимается его способность продвигать определенное количество кадров, принимаемых от приемников всех его портов, на передатчики всех его портов.
В суммарной производительности портов каждый проходящий кадр учитывается дважды, как входящий и как выходящий, а так как в устойчивом режиме входной трафик равен выходному, то минимально достаточная производительность коммутатора для поддержки неблокирующего режима равна половине суммарной производительности портов. Если порт, например, стандарта Ethernet со скоростью 10 Мбит/с работает в полудуплексном режиме, то производительность порта Cpi равна 10 Мбит/с, а если в дуплексном — 20 Мбит/с.
Иногда говорят, что коммутатор поддерживает мгновенный неблокирующий режим. Это означает, что он может принимать и обрабатывать кадры от всех своих портов на максимальной скорости протокола независимо от того, обеспечиваются ли условия устойчивого
равновесия между входным и выходным трафиком. Правда, обработка некоторых кадров при этом может быть неполной — при занятости выходного порта кадр помещается в буфер коммутатора.
Для поддержки мгновенного неблокирующего режима коммутатор должен обладать большей собственной производительностью, а именно она должна быть равна суммарной производительности его портов: С* =
Приведенные соотношения справедливы для портов с любыми скоростями, то есть портов стандартов Ethernet со скоростью 10 Мбит/с, Fast Ethernet, Gigabit Ethernet и 10G Ethernet.
Способы, которыми обеспечивается способность коммутатора поддерживать неблокирующий режим, могут быть разными. Необходимым требованием является умение процессора порта обрабатывать потоки кадров с максимальной для физического уровня этого порта скоростью. В главе 12 мы подсчитали, что максимальная производительность порта Ethernet стандарта 10 Мбит/с равна 14 880 кадров в секунду. Это означает, что процессоры портов Ethernet стандарта 10 Мбит/с неблокирующего коммутатора должны поддерживать продвижение кадров со скоростью 14 880 кадров в секунду.
Однако только адекватной производительности процессоров портов недостаточно для того, чтобы коммутатор был неблокирующим. Необходимо, чтобы достаточной производительностью обладали все элементы архитектуры коммутатора, включая центральный процессор, общую память, шины, соединяющие отдельные модули между собой, саму архитектуру коммутатора (наиболее распространенные архитектуры коммутаторов мы рассмотрим позже). В принципе, задача создания неблокирующего коммутатора аналогична задаче создания высокопроизводительного компьютера — в обоих случаях она решается комплексно: за счет соответствующей архитектуры объединения модулей в едином устройстве и адекватной производительности каждого отдельного модуля устройства.
Борьба с перегрузками
Даже в том случае, когда коммутатор является неблокирующим, нет гарантии того, что он во всех случаях справится с потоком кадров, направляемых на его порты. Неблокирующие коммутаторы тоже могут испытывать перегрузки и терять кадры из-за переполнения внутренних буферов.
Причина перегрузок обычно кроется не в том, что коммутатору не хватает производительности для обслуживания потоков кадров, а в ограниченной пропускной способности отдельного выходного порта, которая определяется параметрами протокола. Другим словами, какой бы производительностью коммутатор не обладал, всегда найдется такое распределение потоков кадров, которое приведет к перегрузке коммутатора из-за ограниченной производительности выходного порта коммутатора.
Возникновение таких перегрузок является платой за отказ от применения алгоритма доступа к разделяемой среде, так как в дуплексном режиме работы портов теряется контроль за потоками кадров/направляемых конечными узлами в сеть. В полудуплексном режиме, свойственном технологиям с разделяемой средой, поток кадров регулировался самим методом доступа к разделяемой среде. При переходе на дуплексный режим узлу разрешается отправлять кадры в коммутатор всегда, когда это ему нужно, поэтому в данном режиме коммутаторы сети могут сталкиваться с перегрузками, не имея при этом никаких средств «притормаживания» потока кадров.
Таким образом, если входной трафик неравномерно распределяется между выходными портами, легко представить ситуацию, когда на какой-либо выходной порт коммутатора будет направляться трафик с суммарной средней интенсивностью большей, чем протокольный максимум. На рис. 13.13 показана как раз такая ситуация, когда на порт 3 коммутатора Ethernet направляется от портов 1, 2,4 и 6 поток кадров размером в 64 байт с суммарной интенсивностью в 22 100 кадров в секунду. Вспомним, что максимальная скорость в кадрах в секунду для сегмента Ethernet составляет 14 880. Естественно, что когда кадры поступают в буфер порта со скоростью 22 100 кадров в секунду, а уходят со скоростью 14 880 кадров в секунду, то внутренний буфер выходного порта начинает неуклонно заполняться необработанными кадрами.
 Рис. 13.13. Переполнение буфера порта из-за несбалансированности трафика
Рис. 13.13. Переполнение буфера порта из-за несбалансированности трафика
Неблокирующие коммутаторы




![]()
![]()
Коммутаторы
Особенности коммутаторов
При появлении в конце 80-х начале 90-х годов быстрых протоколов, производительных персональных компьютеров, мультимедийной информации, разделении сети на большое количество сегментов классические мосты перестали справляться с работой. Обслуживание потоков кадров между теперь уже несколькими портами с помощью одного процессорного блока требовало значительного повышения быстродействия процессора, а это довольно дорогостоящее решение.
Более эффективным оказалось решение, которое и «породило» коммутаторы: для обслуживания потока, поступающего на каждый порт, в устройство ставился отдельный специализированный процессор, который реализовывал алгоритм моста. По сути, коммутатор – это мультипроцессорный мост, способный параллельно продвигать кадры сразу между всеми парами своих портов. Но если при добавлении процессорных блоков компьютер не перестали называть компьютером, а добавили только прилагательное «мультипроцессорный», то с мультипроцессорными мостами произошла метаморфоза – они превратились в коммутаторы. Этому способствовал способ связи между отдельными процессорами коммутатора – они связывались коммутационной матрицей, похожей на матрицы мультипроцессорных компьютеров, связывающие процессоры с блоками памяти.
Со временем коммутаторы вытеснили из локальных сетей классические однопроцессорные мосты. Основная причина этого – существенно более высокая производительность, с которой коммутаторы передают кадры между сегментами сети. Если мосты могли даже замедлять работу сети, то коммутаторы всегда выпускаются с процессорами портов, которые могут передавать кадры с той максимальной скоростью, на которую рассчитан протокол. Добавление к этому возможности параллельной передачи кадров между портами предопределило судьбу мостов и коммутаторов.
Производительность коммутаторов на несколько порядков выше, чем мостов – коммутаторы могут передавать до нескольких миллионов кадров в секунду, в то время как мосты обычно обрабатывают 3-5 тысяч кадров в секунду.
За время своего существования уже без конкурентов-мостов коммутаторы вобрали в себя многие дополнительные функции, которые появлялись в результате естественного развития сетевых технологий. К этим функциям относятся, например, поддержка виртуальных сетей (VLAN), приоритезация трафика, использование магистрального порта по умолчанию и т.п.
Технология коммутации сегментов Ethernet была предложена небольшой компанией Kalpana в 1990 году в ответ на растущие потребности в повышении пропускной способности связей высокопроизводительных серверов с сегментами рабочих станций. У коммутатора компании Kalpana при свободном в момент приема кадра состоянии выходного порта задержка между получением первого байта кадра и появлением этого же байта на выходе порта адреса назначения составляла всего 40 мкс, что было гораздо меньше задержки кадра при его передаче мостом.
Структурная схема коммутатора EtherSwitch, предложенного фирмой Kalpana, представлена на рис. 15.9.
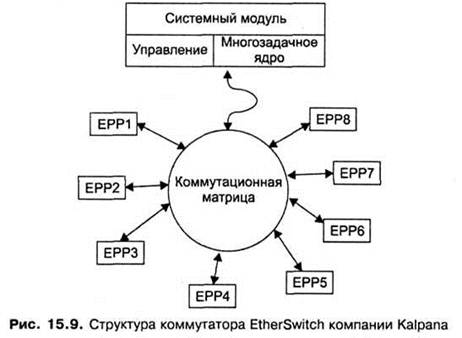
Каждый из 8 портов 10Base-T обслуживается одним процессором пакетов Ethernet(Ethernet Packet Processor, EPP). Кроме того, коммутатор имеет системный модуль, который координирует работу всех процессоров ЕРР, в частности ведет общую адресную таблицу коммутатора. Для передачи кадров между портами используется коммутационная матрица.Она функционирует по принципу коммутации каналов, соединяя порты коммутатора. Для 8 портов матрица может одновременно обеспечить 8 внутренних каналов при полудуплексном режиме работы портов и 16 – при дуплексном, когда передатчик иприемник каждого порта работают независимо друг от друга.
При поступлении кадра в какой-либо порт соответствующий процессор ЕРР буферизует несколько первых байтов кадра, чтобы прочитать адрес назначения. После получения адреса назначения процессор сразу же приступает к обработке кадра, не дожидаясь прихода остальных его байтов.
1. Процессор ЕРР просматривает свой кэш адресной таблицы, и если не находит там нужного адреса, обращается к системному модулю, который работает в многозадачном режиме, параллельно обслуживая запросы всех процессоров ЕРР. Системный модуль производит просмотр общей адресной таблицы и возвращает процессору найденную строку, которую тот буферизует в своем кэше для последующего использования.

2. Если адрес назначения найден в адресной таблице и кадр нужно отфильтровать, процессор просто прекращает записывать в буфер байты кадра, очищает буфер и ждет поступления нового кадра.
3. Если же адрес найден и кадр нужно передать на другой порт, процессор, продолжая прием кадра в буфер, обращается к коммутационной матрице, пытаясь установить в ней путь, связывающий его порт с портом, через который идет маршрут к адресу назначения.
4. Коммутационная матрица может это сделать только в том случае, когда порт адреса назначения в этот момент свободен, то есть не соединен с другим портом данного коммутатора.
5. Если же порт занят, то, как и в любом устройстве с коммутацией каналов, матрица в соединении отказывает. В этом случае кадр полностью буферизуется процессором входного порта, после чего процессор ожидает освобождения выходного порта и образования коммутационной матрицей нужного пути.
6. После того как нужный путь установлен, в него направляются буферизованные байты кадра, которые принимаются процессором выходного порта. Как только процессор выходного порта получает доступ к подключенному к нему сегменту Ethernet по алгоритму CSMA/CD, байты кадра сразу же начинают передаваться в сеть. Процессор входного порта постоянно хранит несколько байтов принимаемого кадра в своем буфере, что позволяет ему независимо и асинхронно принимать и передавать байты кадра (рис. 15.10).
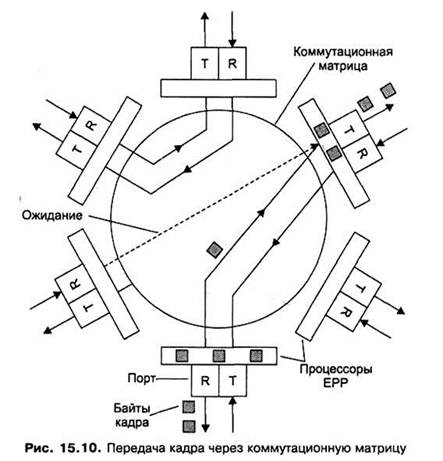
Описанный выше способ передачи кадра без его полной буферизации получил название коммутации «на лету» (on-the-fly), или «напролет»(cut-through). Этот способ представляет собой, по сути, конвейерную обработку кадра, когда частично совмещаются во времени несколько этапов его передачи.
1. Прием первых байтов кадра процессором входного порта, включая прием байтов адреса назначения.
2. Поиск адреса назначения в адресной таблице коммутатора (в кэше процессора или в общей таблице системного модуля).
3. Коммутация матрицы.
4. Прием остальных байтов кадра процессором входного порта.
5. Прием байтов кадра (включая первые) процессором выходного порта через коммутационную матрицу.
6. Получение доступа к среде процессором выходного порта.
7. Передача байтов кадра процессором выходного порта в сеть.
На рис. 15.11 подставлены два режима обработки кадра: режим коммутации «на лету» с частичным совмещением во времени нескольких этапов, и режим полной буферизации кадра с последовательным выполнением всех этапов. (Заметим, что этапы 2 и 3 совместить во времени нельзя, так как без знания номера выходного порта операция коммутации матрицы не имеет смысла.)
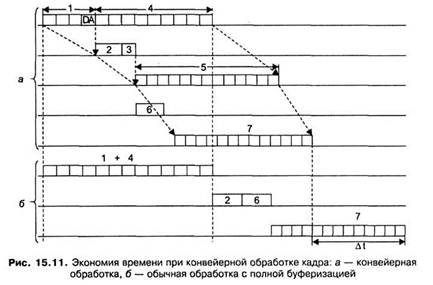
Как показывает схема, экономия от конвейеризации получается ощутимой.
Однако главной причиной повышения производительности сети при использовании коммутатора является параллельная обработка нескольких кадров.
Этот эффект иллюстрирует рис. 15.12, на котором показана идеальная в отношении производительности ситуация, когда четыре порта из восьми передают данные с максимальной для протокола Ethernet скоростью 10 Мбит/с. Причем они передают эти данные на остальные четыре порта коммутатора не конфликтуя – потоки данных между узлами сети распределились так, что для каждого принимающего кадры порта есть свой выходной порт.
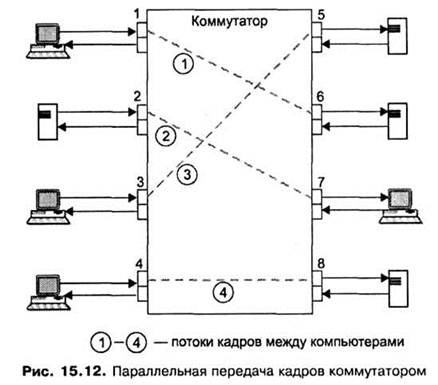
Если коммутатор успевает обрабатывать входной трафик при максимальной интенсивности поступления кадров на входные порты, то общая производительность коммутатора в приведенном примере составит 4 х 10 = 40Мбит/с, а при обобщении примера для N портов – (N/2) х 10 Мбит/с. В таком случае говорят, что коммутаторпредоставляет каждой станции или сегменту, подключенным к его портам, выделенную пропускную способность протокола.
Естественно, что в сети не всегда складывается описанная ситуация. Если двум станциям, например станциям, подключенным к портам 3 и 4, одновременно нужно записывать данные на один и тот же сервер, подключенный к порту 8, то коммутатор не сможет выделить каждой станции по 10 Мбит/с, так как порт 8 не может передавать данные со скоростью 20 Мбит/с. Кадры станций будут ожидать во внутренних очередях входных портов 3 и 4, когда освободится порт 8 для передачи очередного кадра. Очевидно, хорошим решением для такого распределения потоков данных было бы подключение сервера к более высокоскоростному порту, например Fast Ethernet.
Неблокирующие коммутаторы
Коммутатор называют неблокирующим, если он может передавать кадры через свои порты стой же скоростью, с которой они на них поступают.
Когда говорят, что коммутатор может поддерживать устойчивый неблокирующий режим работы коммутатора, то имеют в виду, что коммутатор передает кадры со скоростью их поступления в течение произвольного промежутка времени. Для обеспечения подобного режима нужно таким образом распределить потоки кадров по выходным портам, чтобы: во-первых, порты справлялись с нагрузкой, во-вторых, коммутатор мог всегда в среднем передать на выходы столько кадров, сколько их поступило на входы. Если же входной ноток кадров (просуммированный по всем портам) в среднем будет превышать выходной поток кадров (также просуммированный по всем портам), то кадры будут накапливаться в буферной памяти коммутатора, и при переполнении – просто отбрасываться.
Основы коммутации
Архитектура коммутаторов
Одним из основных компонентов всего коммутационного оборудования является коммутирующая матрица (switch fabric). Коммутирующая матрица представляет собой чипсет, соединяющий множество входов с множеством выходов на основе фундаментальных технологий и принципов коммутации. Коммутирующая матрица выполняет три функции:
Производительность коммутирующей матрицы (switch capacity) определяется как общая полоса пропускания ( bandwidth ), обеспечивающая коммутацию без отбрасывания пакетов трафика любого типа (одноадресного, многоадресного, широковещательного).

где 1 Умножение на 2 для дуплексного режима работы  — количество портов,
— количество портов,  — максимальная производительность протокола, поддерживаемого i-м портом коммутатора.
— максимальная производительность протокола, поддерживаемого i-м портом коммутатора.
Например, производительность коммутатора с 24 портами 10/100 Мбит/с и 2 портами 1 Гбит/с вычисляется следующим образом:
Коммутатор обеспечивает портам равноправный доступ к матрице, если в системе не установлено преимущество одних портов над другими.
* Умножение на 2 для дуплексного режима работы.
В настоящее время существует много типов архитектур коммутирующих матриц. Выбор архитектуры матрицы во многом определяется ролью коммутатора в сети и количеством трафика, которое ему придется обрабатывать. В действительности, матрица обычно реализуется на основе комбинации двух или более базовых архитектур. Рассмотрим самые распространенные типы архитектур коммутирующих матриц.
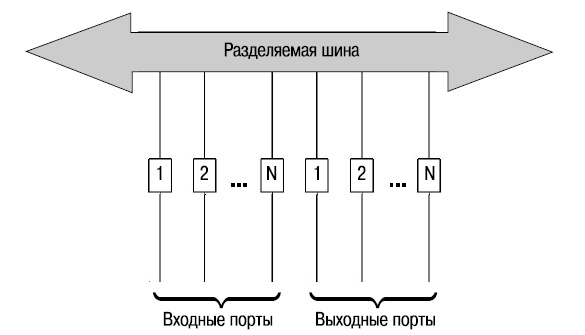
Архитектура с разделяемой шиной
Архитектура с разделяемой шиной (Shared Bus), как следует из ее названия, использует в качестве разделяемой среды шину, которая обеспечивает связь подключенных к ней устройств ввода-вывода (портов). Шина используется в режиме разделения времени, т.е. в каждый момент времени только одному источнику разрешено передавать по ней данные. Управление доступом к шине осуществляется через централизованный арбитр, который предоставляет источнику право передавать данные.
Применительно к системам с разделяемой шиной под термином «неблокирующая» понимается то, что сумма скоростей портов матрицы меньше, чем скорость шины. Т.е. производительность системы ограничена производительностью шины. Даже если общая полоса пропускания ниже производительности шины, количество и производительность устройств ввода-вывода ограничены производительностью централизованного арбитра.
Архитектура с разделяемой памятью
Улучшения архитектуры с разделяемой шиной привели к появлению высокопроизводительной архитектуры с разделяемой памятью (Shared Memory). Архитектура с разделяемой памятью обычно основана на использовании быстрой памяти RAM большой емкости в качестве общего буфера коммутационной системы, предназначенного для хранения входящих пакетов перед их передачей. Память обычно организуется в виде множества выходных очередей, ассоциирующихся с одним из устройств ввода-вывода или портом. Для обеспечения неблокирующей работы полоса пропускания памяти для операции «запись» и операции «чтение» должна быть равна максимальной суммарной полосе пропускания всех входных портов.

Одним из преимуществ использования общего буфера для хранения пакетов является то, что он позволяет минимизировать количество выходных буферов, требуемых для поддержания скорости потери пакетов на низком уровне. С помощью централизованного буфера можно воспользоваться преимуществами статического разделения буферной памяти. При высокой скорости трафика на одном из портов он может захватить большее буферное пространство, если общий буферный пул не занят полностью.
Архитектура с разделяемой памятью обладает рядом недостатков. Так как пакеты записываются и считываются из памяти одновременно, она должна обладать суммарной пропускной способностью портов, т.е. операции записи и чтения из памяти должны выполняться в N (количество портов) раз выше скорости работы портов. Т.к. доступ к памяти физически ограничен, необходимость ускорения работы в N раз ограничивает масштабируемость архитектуры. Более того, контроллер памяти должен обрабатывать пакеты с той же скоростью, что и память. Такая задача может быть трудно выполнимой в случае управления множеством классов приоритетов и сложными операциями планирования. Коммутаторы с разделяемой памятью обладают единой точкой отказа, поскольку добавление еще одного общего буфера является сложным и дорогим. В результате этого в чистом виде архитектура с разделяемой памятью используется для построения коммутаторов с небольшим количеством портов.



