Нормальное распределение (Normal Distribution)

Нормальное распределение (распределением Гаусса или Гаусса — Лапласа) – распространенная разновидность непрерывного распределения вероятностей для случайной величины.
Помните колоколообразную кривую? Вот эту:

Долгое время она служила главным критерием профессиональной оценки сотрудников американских учреждений, и равнодушных не оставляла, ведь от нее зависело, как себя позиционирует человек и его начальство.
Нормальное распределение – это ключевая концепция Статистики (Statistics) и основа Науки о данных (Data Science). При выполнении Разведочного анализа данных (EDA) мы сначала стремимся найти их распределение вероятностей, и наиболее распространенный ее вид – нормальное распределение.
Посмотрите на распределение вероятностей окупить инвестиции в фондовый индекс S&P 500:

Да-да, вероятность «выйти в ноль» выше остальных! Также справедливо утверждение, что вероятность потерять больше как бы тает вместе с отрицательным процентом возврата. Белой непрерывной линией обозначено предсказание кривой нормального распределения. Прочие наблюдения, такие как вес при рождении и показатель IQ, часто следуют нормальному распределению подобным образом.
Еще одна причина, по которой нормальное распределение становится важным для Дата-сайентистов (Data Scientist) – это Центральная предельная теорема (Central Limit Theorem). Эта теорема объясняет магию математики и является основой методов проверки гипотез.
В этой статье мы поймем важность и различные свойства нормального распределения, а изучим, как использовать эти свойства для проверки нормальности наших данных.
Свойства нормального распределения
Кривая стандартного нормального распределения симметрична относительно Среднего арифметического (Mean), Медианы (Median) и Моды (Mode). Более того, также являются нормальным распределением произведение двух нормальных распределений и их сумма. Магия, не правда ли? Существуют и другие, более сложные закономерности, пока обойдемся самыми понятными.
Эмпирическое правило
Вы слышали об эмпирическом правиле? Оно часто используется в статистике и гласит: «68,27% наблюдений случайной Выборки (Sample) лежат в пределах одного Стандартного отклонения (Standard Deviation), 95,45% – в пределах двух, а 99,73 – в пределах трех стандартных отклонений от среднего»:

Это правило позволяет нам идентифицировать Выбросы (Outlier) и очень полезно при Проверке на нормальность (Normality Test).
Стандартное нормальное распределение
Стандартное нормальное распределение – это частный случай нормального распределения, когда среднее значение равно нулю и стандартное отклонение равно единице. Любое нормальное распределение мы можем преобразовать его в стандартное, используя формулу:
Пример. Есть два интерна: Левин и Ричардс. Левин набрал 65 баллов на экзамене по терапии, а Ричардс – 80 баллов на экзамене по кожной венерологии. Верно ли, что Ричардс учился лучше, чем Левин?
Нет, потому что манера поведения людей в терапии отличается от того, как люди проявляют себя в кожной венерологии. Таким образом, прямое сравнение простым сравнением оценок некорректно.
Теперь предположим, что отметки теста по терапии подчиняются нормальному распределению со средним значением 60 и стандартным отклонением 4. С другой стороны, отметки о кожвенерологии подчиняются нормальному распределению со средним значением 79 и стандартным отклонением 2.
Нам нужно будет вычислить Стандартизированную оценку (Z-score) путем стандартизации обоих этих распределений:
Таким образом, Левин набрал 1,25 стандартного отклонения выше среднего, в то время как Ричардс – только 0,5. Следовательно, Левин показал себя лучше:

Асимметричное распределение
Нормальное распределение – это симметрично, что означает, что его «хвосты» слева и справа – зеркальные отображения друг друга. Но это не относится к большинству реальных наборов данных. Как правило, мы будем иметь дело со скошенными асимметричными распределениями.
Визуальная оценка нормальности
Для таких целей принято использовать три вида графиков:
Для оценки нормальности распределения также используют Скошенность (Skewness) и Эксцесс (Kurtosis).
Нормальное распределение и Python
Посмотрим, как выглядит код, визуализирующий распределение и заодно рассчитывающий основные метрики Датасета (Dataset). Для начала импортируем необходимые библиотеки:
Определим функцию, которая пройдется по всем столбцам датасета, рассчитает основные статистические метрики (среднее, минимум, максимум и т.д.):
Построим тройной график:

Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Почему с нормальным распределением не все нормально

Нормальное распределение (распределение Гаусса) всегда играло центральную роль в теории вероятностей, так как возникает очень часто как результат воздействия множества факторов, вклад любого одного из которых ничтожен. Центральная предельная теорема (ЦПТ), находит применение фактически во всех прикладных науках, делая аппарат статистики универсальным. Однако, весьма часты случаи, когда ее применение невозможно, а исследователи пытаются всячески организовать подгонку результатов под гауссиану. Вот про альтернативный подход в случае влияния на распределение множества факторов я сейчас и расскажу.
Краткая история ЦПТ. Еще при живом Ньютоне Абрахам де Муавр доказал теорему о сходимости центрированного и нормированного числа наблюдений события в серии независимых испытаний к нормальному распределению. Весь 19 и начало 20 веков эта теорема послужила ученым образцом для обобщений. Лаплас доказал случай равномерного распределения, Пуассон – локальную теорему для случая с разными вероятностями. Пуанкаре, Лежандр и Гаусс разработали богатую теорию ошибок наблюдений и метод наименьших квадратов, опираясь на сходимость ошибок к нормальному распределению. Чебышев доказал еще более сильную теорему для суммы случайных величин, походу разработав метод моментов. Ляпунов в 1900 году, опираясь на Чебышева и Маркова, доказал ЦПТ в нынешнем виде, но только при существовании моментов третьего порядка. И только в 1934 году Феллер поставил точку, показав, что существование моментов второго порядка, является и необходимым и достаточным условием.
ЦПТ можно сформулировать так: если случайные величины независимы, одинаково распределены и имеют конечную дисперсию отличную от нуля, то суммы (центрированные и нормированные) этих величин сходятся к нормальному закону. Именно в таком виде эту теорему и преподают в вузах и ее так часто используют наблюдатели и исследователи, которые не профессиональны в математике. Что в ней не так? В самом деле, теорема отлично применяется в областях, над которыми работали Гаусс, Пуанкаре, Чебышев и прочие гении 19 века, а именно: теория ошибок наблюдений, статистическая физика, МНК, демографические исследования и может что-то еще. Но ученые, которым не достает оригинальности для открытий, занимаются обобщениями и хотят применить эту теорему ко всему, или просто притащить за уши нормальное распределение, где его просто быть не может. Хотите примеры, они есть у меня.
Коэффициент интеллекта IQ. Изначально подразумевает, что интеллект людей распределен нормально. Проводят тест, который заранее составлен таким образом, при котором не учитываются незаурядные способности, а учитываются по-отдельности с одинаковыми долевыми факторами: логическое мышление, мысленное проектирование, вычислительные способности, абстрактное мышление и что-то еще. Способность решать задачи, недоступные большинству, или прохождение теста за сверхбыстрое время никак не учитывается, а прохождение теста ранее, увеличивает результат (но не интеллект) в дальнейшем. А потом филистеры и полагают, что «никто в два раза умнее их быть не может», «давайте у умников отнимем и поделим».
Второй пример: изменения финансовых показателей. Исследования изменения курса акций, котировок валют, товарных опционов требует применения аппарата математической статистики, а особенно тут важно не ошибиться с видом распределения. Показательный пример: в 1997 году нобелевская премия по экономике была выплачена за предложение модели Блэка — Шоулза, основанной на предположении нормальности распределения прироста фондовых показателей (так называемый белый шум). При этом авторы явно заявили, что данная модель нуждается в уточнении, но всё, на что решилось большинство дальнейших исследователей – просто добавить к нормальному распределению распределение Пуассона. Здесь, очевидно, будут неточности при исследовании длинных временных рядов, так как распределение Пуассона слишком хорошо удовлетворяет ЦПТ, и уже при 20 слагаемых неотличимо от нормального распределения. Гляньте на картинку снизу (а она из очень серьезного экономического журнала), на ней видно, что, несмотря на достаточно большое количество наблюдений и очевидные перекосы, делается предположение о нормальности распределения.
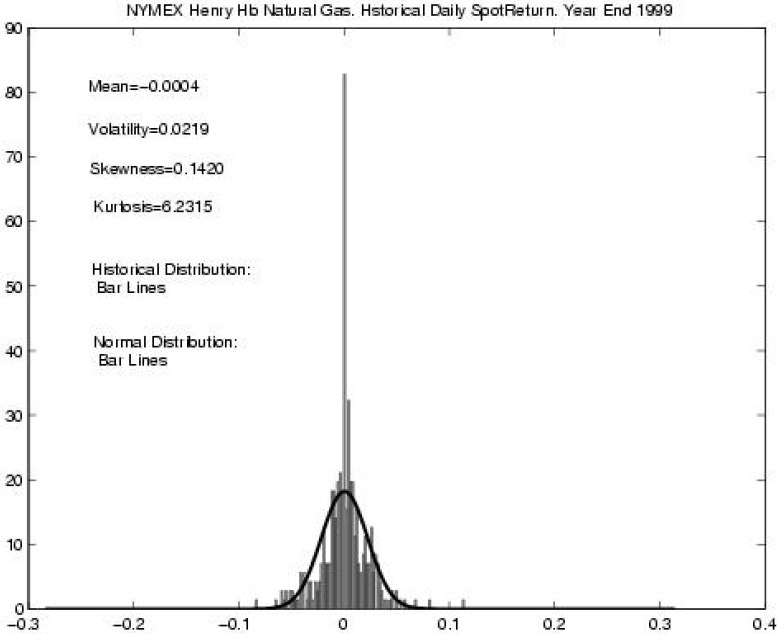
Весьма очевидно, что нормальными не будет распределения заработной платы среди населения города, размеров файлов на диске, населения городов и стран.
Общее у распределений из этих примеров – наличие так называемого «тяжелого хвоста», то есть значений, далеко лежащих от среднего, и заметной асимметрии, как правило, правой. Рассмотрим, какими еще, кроме нормального могли бы быть такие распределения. Начнем с упоминаемого ранее Пуассона: у него есть хвост, но мы же хотим, чтобы закон повторялся для совокупности групп, в каждой из которых он наблюдается (считать размер файлов по предприятию, зарплату по нескольким городам) или масштабировался (произвольно увеличивать или уменьшать интервал модели Блэка — Шоулза), как показывают наблюдения, хвосты и асимметрия не исчезают, а вот распределение Пуассона, по ЦПТ, должно стать нормальным. По этим же соображениям не подойдут распределения Эрланга, бета, логонормальное, и все другие, имеющие дисперсию. Осталось только отсечь распределение Парето, а вот оно не подходит в связи с совпадением моды с минимальным значением, что почти не встречается при анализе выборочных данных.
Распределения, обладающее необходимыми свойствами, существуют и носят название устойчивых распределений. Их история также весьма интересна, а основная теорема была доказана через год после работы Феллера, в 1935 году, совместными усилиями французского математика Поля Леви и советского математика А.Я. Хинчина. ЦПТ была обобщена, из нее было убрано условие существования дисперсии. В отличие от нормального, ни плотность ни функция распределения у устойчивых случайных величин не выражаются (за редким исключением, о котором ниже), все что о них известно, это характеристическая функция (обратное преобразование Фурье плотности распределения, но для понимания сути это можно и не знать).
Итак, теорема: если случайные величины независимы, одинаково распределены, то суммы этих величин сходятся к устойчивому закону.
Теперь определение. Случайная величина X будет устойчивой тогда и только тогда, когда логарифм ее характеристической функции  представим в виде:
представим в виде:
где .
В самом деле, ничего сильно сложного здесь нет, просто надо объяснить смысл четырех параметров. Параметры сигма и мю – обычные масштаб и смещение, как и в нормальном распределении, мю будет равно математическому ожиданию, если оно есть, а оно есть, когда альфа больше одного. Параметр бета – асимметрия, при его равенстве нулю, распределение симметрично. А вот альфа это характеристический параметр, обозначает какого порядка моменты у величины существуют, чем он ближе к двум, тем больше распределение похоже на нормальное, при равенстве двум распределение становиться нормальным, и только в этом случае у него существуют моменты больших порядков, также в случае нормального распределения, асимметрия вырождается. В случае, когда альфа равна единице, а бета нулю, получается распределение Коши, а в случае, когда альфа равна половине, а бета единице – распределение Леви, в других случаях не существует представления в квадратурах для плотности распределения таких величин.
В 20 веке была разработана богатая теория устойчивых величин и процессов (получивших название процессов Леви), показана их связь с дробными интегралами, введены различные способы параметризации и моделирования, несколькими способами были оценены параметры и показана состоятельность и устойчивость оценок. Посмотрите на картинку, на ней смоделированная траектория процесса Леви с увеличенным в 15 раз фрагментом.
Именно занимаясь такими процессами и их приложением в финансах, Бенуа Мандельброт придумал фракталы. Однако не везде было так хорошо. Вторая половина 20 века прошла под повальным трендом прикладных и кибернетических наук, а это означало кризис чистой математики, все хотели производить, но не хотели думать, гуманитарии со своей публицистикой оккупировали математические сферы. Пример: книга «Пятьдесят занимательных вероятностных задач с решениями» американца Мостеллера, задача №11:

Авторское решение этой задачи, это просто поражение здравого смысла:

Такая же ситуация и с 25 задачей, где даются ТРИ противоречащих ответа.
Но вернемся к устойчивым распределениям. В оставшейся части статьи я попытаюсь показать, что не должно возникать дополнительных сложностей при работе с ними. А именно, существуют численные и статистические методы, позволяющие оценивать параметры, вычислять функцию распределения и моделировать оные, то есть работать так же, как и с любым другим распределением.
Моделирование устойчивых случайных величин. Так как все познается в сравнении, то напомню сначала наиболее удобный, с точки зрения вычислений, метод генерирования нормальной величины (метод Бокса – Мюллера): если – базовые случайные величины (равномерно распределены на [0, 1) и независимы), то по соотношению
получится стандартная нормальная величина.
Теперь зададим заранее альфу и бету, пусть V и W, независимые случайные величины: V равномерно распределена на , W экспоненциально распределена с параметром 1, определим и , тогда по соотношению:
получим устойчивую случайную величину, для которой мю равна нулю, а сигма единице. Это так называемая стандартная устойчивая величина, которую для общего случая (при альфа не равном единице), просто достаточно помножить на масштаб и прибавить смещение. Да, соотношение сложнее, но оно все равно достаточно простое, чтобы его использовать даже в электронных таблицах (Ссылка). На рисунках снизу показаны траектории моделирования модели Блэка — Шоулза сперва для нормального, а затем для устойчивого процесса.
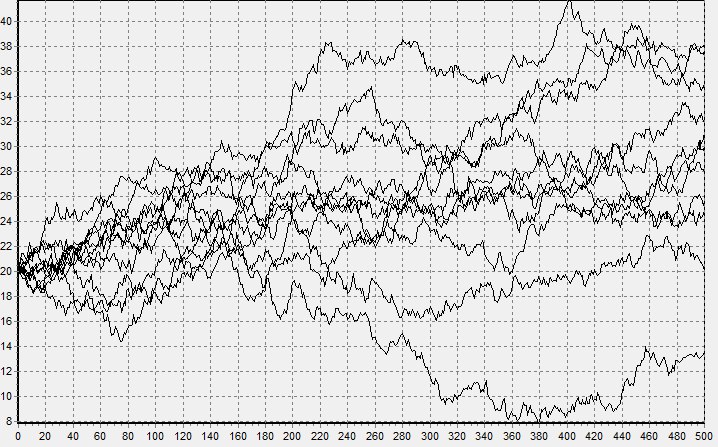
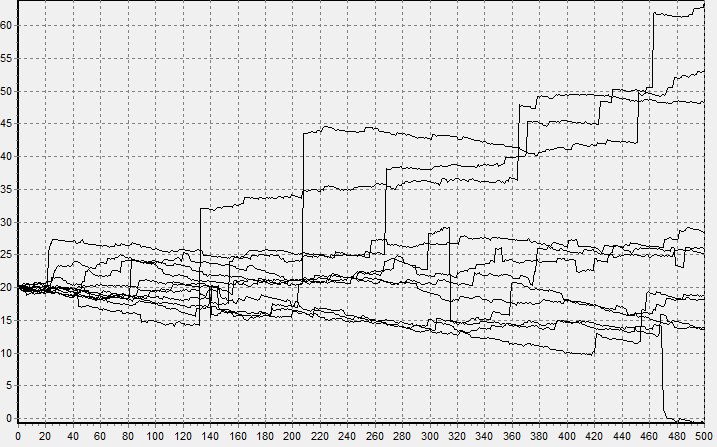
Можете поверить, график изменения цен на биржах больше похож на второй.
Оценка параметров устойчивого распределения. Так как вставлять формулы на хабре достаточно сложно, я просто оставлю ссылку на статью, где подробно разбираются всевозможные методы для оценки параметров, или на мою статью на русском языке, где приводятся только два метода. Также можно найти замечательную книгу, в которой собрана вся теория по устойчивым случайным величинам и их приложениям (Zolotarev V., Uchaikin V. Stable Distributions and their Applications. VSP. M.: 1999.), или ее чисто научный русский вариант (Золотарев В.М. Устойчивые одномерные распределения. – М.: Наука, Главная редакция физико-математической литературы, 1983. – 304 с.). В этих книгах также присутствуют методы для вычисления плотности и функции распределения.
В качестве заключения могу лишь порекомендовать, при анализе статистических данных, когда наблюдается асимметрия или значения, сильно превосходящие ожидаемые, спрашивать самих себя: «правильно ли выбран закон распределения?» и «а все ли с нормальным распределением нормально?».
Нормальный закон распределения вероятностей
Без преувеличения его можно назвать философским законом. Наблюдая за различными объектами и процессами окружающего мира, мы часто сталкиваемся с тем, что чего-то бывает мало, и что бывает норма: 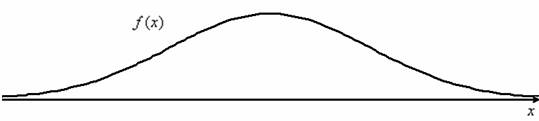
Перед вами принципиальный вид функции плотности нормального распределения вероятностей, и я приветствую вас на этом интереснейшем уроке.
Какие можно привести примеры? Их просто тьма. Это, например, рост, вес людей (и не только), их физическая сила, умственные способности и т.д. Существует «основная масса» (по тому или иному признаку) и существуют отклонения в обе стороны.
Это различные характеристики неодушевленных объектов (те же размеры, вес). Это случайная продолжительность процессов, например, время забега стометровки или превращения смолы в янтарь. Из физики вспомнились молекулы воздуха: среди них есть медленные, есть быстрые, но большинство двигаются со «стандартными» скоростями.
Более того, даже дискретные распределения бывают близкИ к нормальному, и в конце урока мы раскроем важный секрет «нормальности». Но прежде, математика, математика, математика, которая в древности не зря считалась философией!
Непрерывная случайная величина 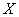 , распределённая по нормальному закону, имеет функцию плотности
, распределённая по нормальному закону, имеет функцию плотности 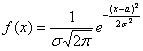 (не пугаемся) и однозначно определяется параметрами
(не пугаемся) и однозначно определяется параметрами 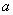 и
и 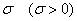 .
.
Данная функция получила фамилию некоронованного короля математики, и я не могу удержаться, чтобы не запостить: 
Одну из таких купюр мне довелось лично держать в руках, и ещё будучи школьником я внимательно изучил функцию Гаусса. Педантичные немцы отобразили все её особенности (на картинке видно плохо), и мы с толком, с расстановкой приступаем к их немцев изучению.
Начнём с того, что для функции 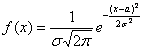 выполнены свойства плотности вероятностей , а именно
выполнены свойства плотности вероятностей , а именно 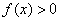 (почему?) и
(почему?) и 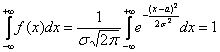 , откуда следует, что нормально распределённая случайная величина достоверно примет одно из действительных значений. Теоретически – какое угодно, практически – узнаем позже.
, откуда следует, что нормально распределённая случайная величина достоверно примет одно из действительных значений. Теоретически – какое угодно, практически – узнаем позже.
Любопытно отметить, что сам по себе неопределённый интеграл 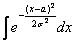 является неберущимся, однако указанный выше несобственный интеграл сходится и равен
является неберущимся, однако указанный выше несобственный интеграл сходится и равен 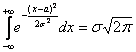 . Вычисления для простейшего случая
. Вычисления для простейшего случая 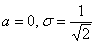 можно найти здесь, все же остальные варианты сводятся к нему с помощью линейной замены
можно найти здесь, все же остальные варианты сводятся к нему с помощью линейной замены 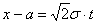 .
.
Следующие замечательные факты я тоже приведу без доказательства:
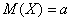 – то есть, математическое ожидание нормально распределённой случайной величины в точности равно «а», а среднее квадратическое отклонение в точности равно «сигме»:
– то есть, математическое ожидание нормально распределённой случайной величины в точности равно «а», а среднее квадратическое отклонение в точности равно «сигме»: 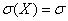 .
.
Эти значения выводятся с помощью общих формул математического ожидания и дисперсии, и желающие / нуждающиеся могут ознакомиться с подробными выкладками в учебной литературе, и совсем здОрово, если вам удастся провести их самостоятельно.
Ну а мы переходим к насущным практическим вопросам. Практики сегодня будет много, и она будет интересна не только «чайникам», но и более подготовленным читателям:
Нормально распределённая случайная величина задана параметрами 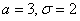 . Записать её функцию плотности и построить график.
. Записать её функцию плотности и построить график.
Несмотря на кажущуюся простоту задания, в нём существует немало тонкостей.
Первый момент касается обозначений. Они стандартные, и никаких вольностей: математическое ожидание обозначают буквой 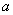 (реже
(реже 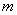 или
или 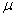 («мю»)), а стандартное отклонение – буквой
(«мю»)), а стандартное отклонение – буквой 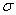 . Кстати, обратите внимание на формулировку: в условии ничего не сказано о сущности параметров «а» и «сигма», и несведущий человек может только догадываться, что это такое.
. Кстати, обратите внимание на формулировку: в условии ничего не сказано о сущности параметров «а» и «сигма», и несведущий человек может только догадываться, что это такое.
Решение начнём шаблонной фразой: функция плотности нормально распределённой случайной величины имеет вид 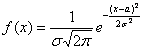 . В данном случае
. В данном случае 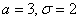 и:
и: 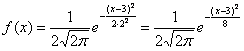
Первая, более лёгкая часть задачи выполнена. Теперь график. Вот на нём-то, на моей памяти, студентов «заворачивали» десятки раз, причём, многих неоднократно. По той причине, что график  обладает несколькими принципиальными особенностями, которые нужно обязательно отобразить на чертеже.
обладает несколькими принципиальными особенностями, которые нужно обязательно отобразить на чертеже.
Сначала полная картина, затем комментарии: 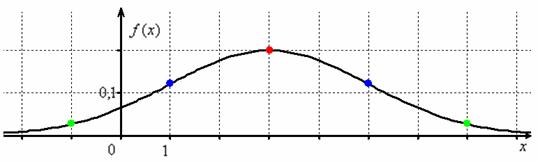
Строим декартову систему координат. При выполнении чертежа от руки во многих случаях оптимален следующий масштаб:
по оси абсцисс: 2 тетрадные клетки = 1 ед.;
по оси ординат: 2 тетрадные клетки = 0,1 ед., при этом саму ось следует расположить из тех соображений, что в точке 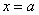 функция достигает максимума, и вертикальная прямая
функция достигает максимума, и вертикальная прямая 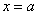 (на чертеже отсутствует) является линией симметрии графика.
(на чертеже отсутствует) является линией симметрии графика.
И логично, что в первую очередь удобно найти максимум функции. В данном примере он находится в точке 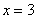 :
: 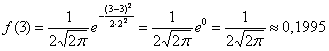
Отмечаем вершину графика (красная точка).
Далее вычислим значения функции при 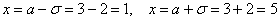 , а точнее только одно из них – в силу симметрии графика они равны:
, а точнее только одно из них – в силу симметрии графика они равны: 
Отмечаем синим цветом.
Внимание! 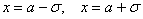 – это точки перегиба нормальной кривой. На интервале
– это точки перегиба нормальной кривой. На интервале 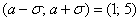 график является выпуклым, а на крайних интервалах – вогнутым.
график является выпуклым, а на крайних интервалах – вогнутым.
Далее отклоняемся от центра ещё на одно стандартное отклонение 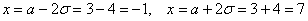 и рассчитываем высоту:
и рассчитываем высоту: 
Отмечаем точки на чертеже (зелёный цвет) и видим, что этого вполне достаточно.
На завершающем этапе аккуратно чертим график, и особо аккуратно отражаем его выпуклость / вогнутость! Ну и, наверное, вы давно поняли, что ось абсцисс – это горизонтальная асимптота, и «залезать» за неё категорически нельзя!
При электронном оформлении решения график легко построить в Экселе, и неожиданно для самого себя я даже записал короткий видеоролик на эту тему. Но сначала поговорим о том, как меняется форма нормальной кривой в зависимости от значений 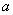 и
и 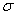 .
.
При увеличении или уменьшении «а» (при неизменном «сигма») график сохраняет свою форму и перемещается вправо / влево соответственно. Так, например, при 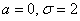 функция принимает вид
функция принимает вид 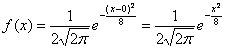 и наш график «переезжает» на 3 единицы влево – ровнехонько в начало координат:
и наш график «переезжает» на 3 единицы влево – ровнехонько в начало координат: 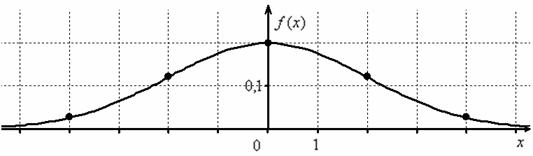
Нормально распределённая величина с нулевым математическим ожиданием получила вполне естественное название – центрированная; её функция плотности 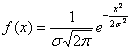 – чётная, и график симметричен относительно оси ординат.
– чётная, и график симметричен относительно оси ординат.
В случае изменения «сигмы» (при постоянном «а»), график «остаётся на месте», но меняет форму. При увеличении 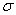 он становится более низким и вытянутым, словно осьминог, растягивающий щупальца. И, наоборот, при уменьшении
он становится более низким и вытянутым, словно осьминог, растягивающий щупальца. И, наоборот, при уменьшении 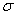 график становится более узким и высоким – получается «удивлённый осьминог». Так, при уменьшении «сигмы» в два раза:
график становится более узким и высоким – получается «удивлённый осьминог». Так, при уменьшении «сигмы» в два раза: 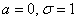 предыдущий график сужается и вытягивается вверх в два раза:
предыдущий график сужается и вытягивается вверх в два раза: 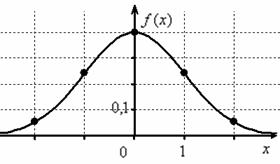
Всё в полном соответствии с геометрическими преобразованиями графиков.
Нормальное распределёние с единичным значением «сигма» называется нормированным, а если оно ещё и центрировано (наш случай), то такое распределение называют стандартным. Оно имеет ещё более простую функцию плотности, которая уже встречалась в локальной теореме Лапласа: 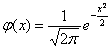 . Стандартное распределение нашло широкое применение на практике, и очень скоро мы окончательно поймём его предназначение.
. Стандартное распределение нашло широкое применение на практике, и очень скоро мы окончательно поймём его предназначение.
Ну а теперь смотрим кино:
Да, совершенно верно – как-то незаслуженно у нас осталась в тени функция распределения вероятностей. Вспоминаем её определение:
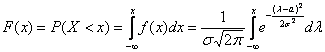 – вероятность того, что случайная величина
– вероятность того, что случайная величина 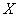 примет значение, МЕНЬШЕЕ, чем переменная
примет значение, МЕНЬШЕЕ, чем переменная 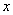 , которая «пробегает» все действительные значения до «плюс» бесконечности.
, которая «пробегает» все действительные значения до «плюс» бесконечности.
Внутри интеграла обычно используют другую букву, чтобы не возникало «накладок» с обозначениями, ибо здесь каждому значению 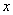 ставится в соответствие несобственный интеграл
ставится в соответствие несобственный интеграл 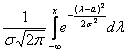 , который равен некоторому числу из интервала
, который равен некоторому числу из интервала 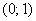 .
.
Почти все значения 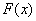 не поддаются точному расчету, но как мы только что видели, с современными вычислительными мощностями с этим нет никаких трудностей. Так, для функции
не поддаются точному расчету, но как мы только что видели, с современными вычислительными мощностями с этим нет никаких трудностей. Так, для функции 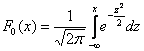 стандартного распределения
стандартного распределения  соответствующая экселевская функция вообще содержит один аргумент:
соответствующая экселевская функция вообще содержит один аргумент:
Раз, два – и готово:
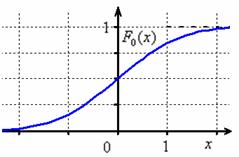
На чертеже хорошо видно выполнение всех свойств функции распределения, и из технических нюансов здесь следует обратить внимание на горизонтальные асимптоты и точку перегиба 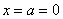 .
.
Теперь вспомним одну из ключевых задач темы, а именно выясним, как найти 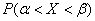 – вероятность того, что нормальная случайная величина
– вероятность того, что нормальная случайная величина 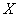 примет значение из интервала
примет значение из интервала 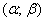 . Геометрически эта вероятность равна площади между нормальной кривой и осью абсцисс на соответствующем участке:
. Геометрически эта вероятность равна площади между нормальной кривой и осью абсцисс на соответствующем участке: 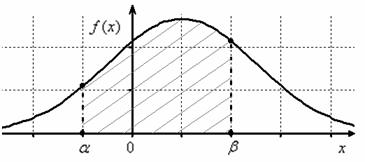
но каждый раз вымучивать приближенное значение  неразумно, и поэтому здесь рациональнее использовать «лёгкую» формулу:
неразумно, и поэтому здесь рациональнее использовать «лёгкую» формулу: 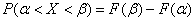 .
.
! Вспоминаем также, что 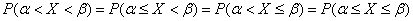
Тут можно снова задействовать Эксель, но есть пара весомых «но»: во-первых, он не всегда под рукой, а во-вторых, «готовые» значения 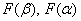 , скорее всего, вызовут вопросы у преподавателя. Почему?
, скорее всего, вызовут вопросы у преподавателя. Почему?
Об этом я неоднократно рассказывал ранее: в своё время (и ещё не очень давно) роскошью был обычный калькулятор, и в учебной литературе до сих пор сохранился «ручной» способ решения рассматриваемой задачи. Его суть состоит в том, чтобы стандартизировать значения «альфа» и «бета», то есть свести решение к стандартному распределению:
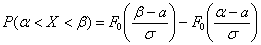
Примечание: функцию 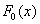 легко получить из общего случая
легко получить из общего случая 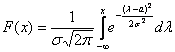 с помощью линейной замены
с помощью линейной замены 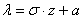 . Тогда
. Тогда 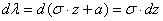 и:
и: 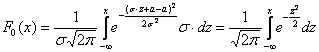
и из проведённой замены как раз следует формула 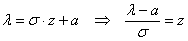 перехода от значений
перехода от значений 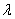 произвольного распределения – к соответствующим значениям
произвольного распределения – к соответствующим значениям 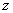 стандартного распределения.
стандартного распределения.
Зачем это нужно? Дело в том, что значения 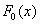 скрупулезно подсчитаны нашими предками и сведены в специальную таблицу, которая есть во многих книгах по терверу. Но ещё чаще встречается таблица значений
скрупулезно подсчитаны нашими предками и сведены в специальную таблицу, которая есть во многих книгах по терверу. Но ещё чаще встречается таблица значений 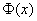 , с которой мы уже имели дело в интегральной теореме Лапласа:
, с которой мы уже имели дело в интегральной теореме Лапласа:
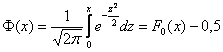
В силу очевидной нечётности функции Лапласа (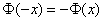 ), в таблице представлены её значения только для положительных «икс», и по причине симметрии нормального распределения этого оказывается достаточно. Итак, вероятность того, что нормальная случайная величина
), в таблице представлены её значения только для положительных «икс», и по причине симметрии нормального распределения этого оказывается достаточно. Итак, вероятность того, что нормальная случайная величина 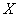 с параметрами
с параметрами 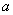 и
и 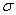 примет значение из интервала
примет значение из интервала 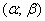 , можно вычислить по формуле:
, можно вычислить по формуле:
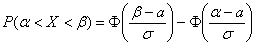 , где
, где 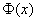 – функция Лапласа.
– функция Лапласа.
Таким образом, наша задача становится чуть ли не устной! Порой, здесь хмыкают и говорят, что метод устарел. Может быть…, но парадокс состоит в том, что «устаревший метод» очень быстро приводит к результату! И ещё в этом заключена большая мудрость – если вдруг пропадёт электричество или восстанут машины, то у человечества останется возможность заглянуть в бумажные таблицы и спасти мир =)
Из пункта  ведётся стрельба из орудия вдоль прямой
ведётся стрельба из орудия вдоль прямой 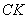 . Предполагается, что дальность полёта распределена нормально с математическим ожиданием 1000 м и средним квадратическим отклонением 5 м. Определить (в процентах) сколько снарядов упадёт с перелётом от 5 до 70м.
. Предполагается, что дальность полёта распределена нормально с математическим ожиданием 1000 м и средним квадратическим отклонением 5 м. Определить (в процентах) сколько снарядов упадёт с перелётом от 5 до 70м.
Решение: в задаче рассматривается нормально распределённая случайная величина 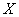 – дальность полёта снаряда, и по условию
– дальность полёта снаряда, и по условию 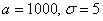 .
.
Если в нашем распоряжении есть таблица значений функции 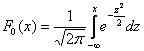 , то используем формулу
, то используем формулу 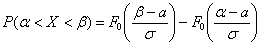 :
: 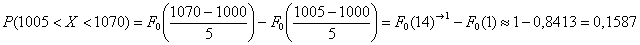
Для самопроверки можно задействовать экселевскую функцию =НОРМСТРАСП(z) или напрямую «забить» 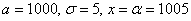 и затем
и затем 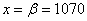 в Пункт 9 расчётного макета.
в Пункт 9 расчётного макета.
Если же в нашем распоряжении есть таблица значений функции Лапласа 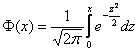 , то решаем через неё:
, то решаем через неё: 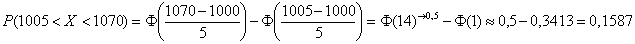
Дробные значения традиционно округляем до 4 знаков после запятой, как это сделано в типовой таблице. И для контроля есть Пункт 5 макета.
Напоминаю, что 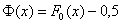 , и во избежание путаницы всегда контролируйте, таблица КАКОЙ функции перед вашими глазами.
, и во избежание путаницы всегда контролируйте, таблица КАКОЙ функции перед вашими глазами.
Ответ требуется дать в процентах, поэтому рассчитанную вероятность нужно умножить на 100 и снабдить результат содержательным комментарием:
– с перелётом от 5 до 70 м упадёт примерно 15,87% снарядов
Диаметр подшипников, изготовленных на заводе, представляет собой случайную величину, распределенную нормально с математическим ожиданием 1,5 см и средним квадратическим отклонением 0,04 см. Найти вероятность того, что размер наугад взятого подшипника колеблется от 1,4 до 1,6 см.
В образце решения и далее я буду использовать функцию Лапласа, как самый распространённый вариант. Кстати, обратите внимание, что согласно формулировке, здесь можно включить концы интервала в рассмотрение. Впрочем, это не критично.
И уже в этом примере нам встретился особый случай – когда интервал 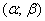 симметричен относительно математического ожидания. В такой ситуации его можно записать в виде
симметричен относительно математического ожидания. В такой ситуации его можно записать в виде 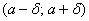 и, пользуясь нечётностью функции Лапласа, упростить рабочую формулу:
и, пользуясь нечётностью функции Лапласа, упростить рабочую формулу:
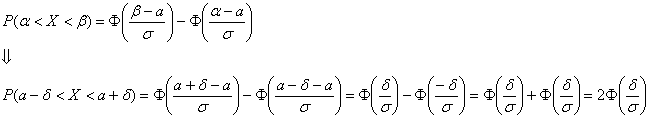
Параметр «дельта» называют отклонением от математического ожидания, и двойное неравенство можно «упаковывать» с помощью модуля:
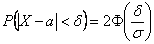 – вероятность того, что значение случайной величины
– вероятность того, что значение случайной величины 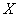 отклонится от математического ожидания менее чем на
отклонится от математического ожидания менее чем на 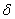 .
.
Хорошо то решение, которое умещается в одну строчку:)
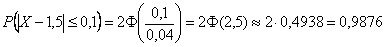 – вероятность того, что диаметр наугад взятого подшипника отличается от 1,5 см не более чем на 0,1 см.
– вероятность того, что диаметр наугад взятого подшипника отличается от 1,5 см не более чем на 0,1 см.
Результат этой задачи получился близким к единице, но хотелось бы ещё бОльшей надежности – а именно, узнать границы, в которых находится диаметр почти всех подшипников. Существует ли какой-нибудь критерий на этот счёт? Существует! На поставленный вопрос отвечает так называемое
правило «трех сигм»
Его суть состоит в том, что практически достоверным является тот факт, что нормально распределённая случайная величина 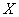 примет значение из промежутка
примет значение из промежутка 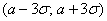 .
.
И в самом деле, вероятность отклонения от матожидания менее чем на 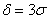 составляет:
составляет:
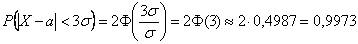 или 99,73%
или 99,73%
В «пересчёте на подшипники» – это 9973 штуки с диаметром от 1,38 до 1,62 см и всего лишь 27 «некондиционных» экземпляров.
В практических исследованиях правило «трёх сигм» обычно применяют в обратном направлении: если статистически установлено, что почти все значения исследуемой случайной величины укладываются в интервал длиной 6 стандартных отклонений, то появляются веские основания полагать, что эта величина распределена по нормальному закону. Проверка осуществляется с помощью теории статистических гипотез.
Продолжаем решать суровые советские задачи:
Случайная величина 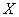 ошибки взвешивания распределена по нормальному закону с нулевым математическим ожиданием и стандартным отклонением 3 грамма. Найти вероятность того, что очередное взвешивание будет проведено с ошибкой, не превышающей по модулю 5 грамм.
ошибки взвешивания распределена по нормальному закону с нулевым математическим ожиданием и стандартным отклонением 3 грамма. Найти вероятность того, что очередное взвешивание будет проведено с ошибкой, не превышающей по модулю 5 грамм.
Решение очень простое. По условию, 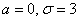 и сразу заметим, что при очередном взвешивании (чего-то или кого-то) мы почти 100% получим результат с точностью до 9 грамм. Но в задаче фигурирует более узкое отклонение
и сразу заметим, что при очередном взвешивании (чего-то или кого-то) мы почти 100% получим результат с точностью до 9 грамм. Но в задаче фигурирует более узкое отклонение 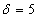 и по формуле
и по формуле 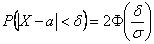 :
:
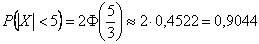 – вероятность того, что очередное взвешивание будет проведено с ошибкой, не превышающей 5 грамм.
– вероятность того, что очередное взвешивание будет проведено с ошибкой, не превышающей 5 грамм.
Ответ: 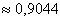
Прорешанная задача принципиально отличается от вроде бы похожего Примера 3 урока о равномерном распределении. Там была погрешность округления результатов измерений, здесь же речь идёт о случайной погрешности самих измерений. Такие погрешности возникают в связи с техническими характеристиками самого прибора (диапазон допустимых ошибок, как правило, указывают в его паспорте), а также по вине экспериментатора – когда мы, например, «на глазок» снимаем показания со стрелки тех же весов.
Помимо прочих, существуют ещё так называемые систематические ошибки измерения. Это уже неслучайные ошибки, которые возникают по причине некорректной настройки или эксплуатации прибора. Так, например, неотрегулированные напольные весы могут стабильно «прибавлять» килограмм, а продавец систематически обвешивать покупателей. Или не систематически ведь можно обсчитать. Однако, в любом случае, случайной такая ошибка не будет, и её матожидание отлично от нуля.
…срочно разрабатываю курс по подготовке продавцов =)
Самостоятельно решаем обратную задачу:
Диаметр валика – случайная нормально распределенная случайная величина, среднее квадратическое отклонение ее равно 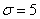 мм. Найти длину интервала, симметричного относительно математического ожидания, в который с вероятностью
мм. Найти длину интервала, симметричного относительно математического ожидания, в который с вероятностью 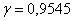 попадет длина диаметра валика.
попадет длина диаметра валика.
Пункт 5* расчётного макета в помощь. Обратите внимание, что здесь не известно математическое ожидание, но это нисколько не мешает решить поставленную задачу.
И экзаменационное задание, которое я настоятельно рекомендую для закрепления материала:
Нормально распределенная случайная величина 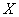 задана своими параметрами
задана своими параметрами 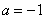 (математическое ожидание) и
(математическое ожидание) и 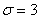 (среднее квадратическое отклонение). Требуется:
(среднее квадратическое отклонение). Требуется:
а) записать плотность вероятности и схематически изобразить ее график;
б) найти вероятность того, что 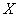 примет значение из интервала
примет значение из интервала 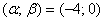 ;
;
в) найти вероятность того, что 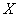 отклонится по модулю от
отклонится по модулю от 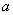 не более чем на
не более чем на 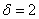 ;
;
г) применяя правило «трех сигм», найти значения случайной величины 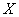 .
.
Такие задачи предлагаются повсеместно, и за годы практики мне их довелось решить сотни и сотни штук. Обязательно попрактикуйтесь в ручном построении чертежа и использовании бумажных таблиц 😉
Ну а я разберу пример повышенной сложности:
Плотность распределения вероятностей случайной величины 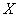 имеет вид
имеет вид 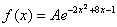 . Найти
. Найти 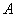 , математическое ожидание
, математическое ожидание 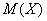 , дисперсию
, дисперсию 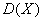 , функцию распределения
, функцию распределения 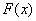 , построить графики плотности и функции распределения, найти
, построить графики плотности и функции распределения, найти 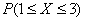 .
.
Решение: прежде всего, обратим внимание, что в условии ничего не сказано о характере случайной величины. Само по себе присутствие экспоненты ещё ничего не значит: это может оказаться, например, показательное или вообще произвольное непрерывное распределение. И поэтому «нормальность» распределения ещё нужно обосновать:
Так как функция 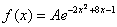 определена при любом действительном значении
определена при любом действительном значении 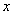 , и её можно привести к виду
, и её можно привести к виду 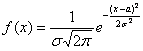 , то случайная величина
, то случайная величина 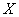 распределена по нормальному закону.
распределена по нормальному закону.
Приводим. Для этого выделяем полный квадрат и организуем трёхэтажную дробь: 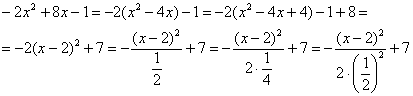
Обязательно выполняем проверку, возвращая показатель в исходный вид: 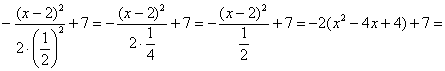
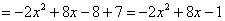 , что мы и хотели увидеть.
, что мы и хотели увидеть.
Таким образом:
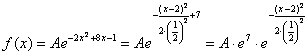 – по правилу действий со степенями «отщипываем»
– по правилу действий со степенями «отщипываем» 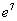 . И здесь можно сразу записать очевидные числовые характеристики:
. И здесь можно сразу записать очевидные числовые характеристики: 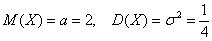
Теперь найдём значение параметра 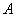 . Поскольку множитель нормального распределения имеет вид
. Поскольку множитель нормального распределения имеет вид 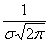 и
и 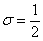 , то:
, то: 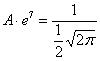 , откуда выражаем
, откуда выражаем 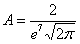 и подставляем в нашу функцию:
и подставляем в нашу функцию: 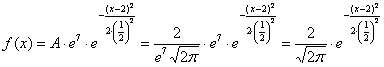 , после чего ещё раз пробежимся по записи глазами и убедимся, что полученная функция имеет вид
, после чего ещё раз пробежимся по записи глазами и убедимся, что полученная функция имеет вид 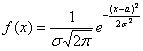 .
.
Построим график плотности: 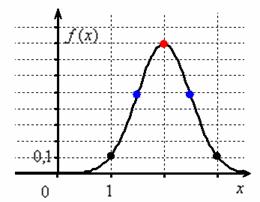
и график функции распределения 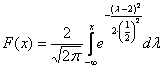 :
: 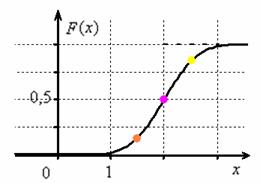
Если под рукой нет Экселя и даже обычного калькулятора, то последний график легко строится вручную! В точке 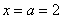 функция распределения принимает значение
функция распределения принимает значение 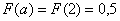 и здесь находится перегиб графика (малиновая точка) Кроме того, для более или менее приличного чертежа желательно найти ещё хотя бы пару точек. Берём традиционное значение
и здесь находится перегиб графика (малиновая точка) Кроме того, для более или менее приличного чертежа желательно найти ещё хотя бы пару точек. Берём традиционное значение 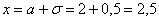 и стандартизируем его по формуле
и стандартизируем его по формуле 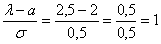 . Далее с помощью таблицы значений функции Лапласа находим:
. Далее с помощью таблицы значений функции Лапласа находим: 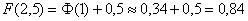 – жёлтая точка на чертеже. С симметричной оранжевой точкой никаких проблем:
– жёлтая точка на чертеже. С симметричной оранжевой точкой никаких проблем: 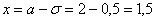 и:
и: 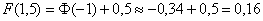 .
.
После чего аккуратно проводим интегральную кривую, не забывая о перегибе и двух горизонтальных асимптотах.
Да, и ещё нужно вычислить:
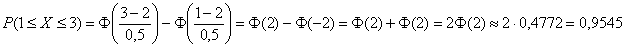 – вероятность того, что случайная величина
– вероятность того, что случайная величина 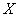 примет значение из данного отрезка.
примет значение из данного отрезка.
Ответ: 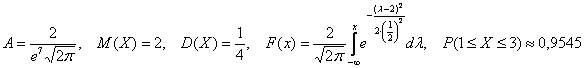
Но этим, конечно, всё дело не ограничивается! Дополнительные примеры, причём довольно творческие, можно найти в тематической pdf-книжке.
И в заключение урока обещанный секрет:
понятие о центральной предельной теореме
которую также называют теоремой Ляпунова. Её суть состоит в том, что если случайная величина 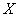 является суммой очень большого числа взаимно независимых случайных величин
является суммой очень большого числа взаимно независимых случайных величин 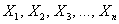 , влияние каждой из которых на всю сумму ничтожно мало, то
, влияние каждой из которых на всю сумму ничтожно мало, то 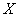 имеет распределение, близкое к нормальному.
имеет распределение, близкое к нормальному.
В окружающем мире условие теоремы Ляпунова выполняется очень часто, и поэтому нормальное распределение (близкое к нему) и встречается буквально на каждом шагу.
Так, например, молекул воздуха очень и очень много, и каждая из них своим движением оказывает ничтожно малое влияние на всю совокупность. Поэтому скорость молекул воздуха распределена нормально.
Большая популяция некоторых особей. Каждая из них (или подавляющее большинство) оказывает несущественное влияние на жизнь всей популяции, следовательно, длина их лапок тоже распределена по нормальному закону.
Теперь вернёмся к знакомой задаче, где проводится 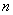 независимых испытаний, в каждом из которых некое событие
независимых испытаний, в каждом из которых некое событие 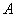 может появиться с постоянной вероятностью
может появиться с постоянной вероятностью 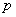 . Эти испытания можно считать попарно независимым случайными величинами
. Эти испытания можно считать попарно независимым случайными величинами 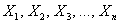 , и при достаточно большом значении «эн» биномиальное распределение случайной величины
, и при достаточно большом значении «эн» биномиальное распределение случайной величины 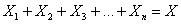 – числа появлений события
– числа появлений события 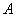 в
в 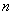 испытаниях – очень близко к нормальному.
испытаниях – очень близко к нормальному.
Уже при 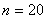 и
и 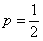 в многоугольнике биномиального распределения хорошо просматривается нормальная кривая:
в многоугольнике биномиального распределения хорошо просматривается нормальная кривая: 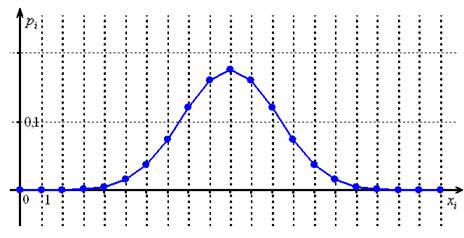
И чем больше  , тем ближе будет сходство. Вероятность
, тем ближе будет сходство. Вероятность  может быть и другой, но не слишком малой.
может быть и другой, но не слишком малой.
Именно этот факт мы и использовали в теоремах Лапласа – когда приближали биномиальные вероятности соответствующими значениями функций нормального распределения.
Вот такие вот пироги.
Необычайно интересной, и я бы даже сказал «сочной» получилась эта статья, что бывает далеко не всегда, но всегда вдохновляет на новое творчество! Надеюсь, вам тоже понравилось, и вы освоили весь материал «на одном дыхании».
Пример 3. Решение: т.к. случайная величина  (диаметр подшипника) распределена нормально, то используем формулу
(диаметр подшипника) распределена нормально, то используем формулу 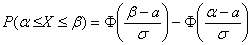 , где
, где 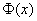 – функция Лапласа. В данном случае:
– функция Лапласа. В данном случае: 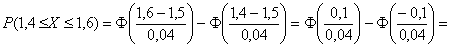
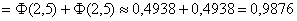 – вероятность того, что диаметр наугад взятого подшипника будет находиться в пределах от 1,4 до 1,6 см.
– вероятность того, что диаметр наугад взятого подшипника будет находиться в пределах от 1,4 до 1,6 см.
Ответ: 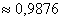
Пример 5. Решение: используем формулу: 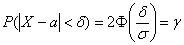 .
.
В данной задаче 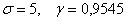 , таким образом:
, таким образом: 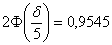
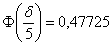
откуда находим:
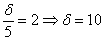
Длина искомого интервала составляет 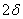
Ответ: 20 мм
Пример 6. Решение: функция плотности нормально распределённой случайной величины имеет вид 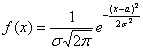 , где
, где 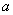 – математическое ожидание,
– математическое ожидание, 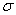 – стандартное отклонение. В данном случае
– стандартное отклонение. В данном случае 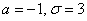 , следовательно:
, следовательно: 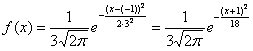
Выполним чертёж: 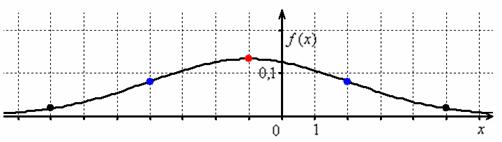
! Примечание: несмотря на то, что условие допускает схематическое построение графика, на чертеже обязательно отображаем все его принципиальные особенности, в частности, на забываем о перегибах в точках 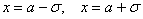 .
.
б) Используем формулу 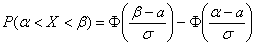 , где
, где 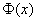 – функция Лапласа.
– функция Лапласа.
В данной задаче 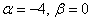 :
: 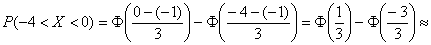
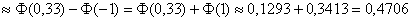 – вероятность того, что случайная величина
– вероятность того, что случайная величина 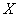 примет значение из данного интервала.
примет значение из данного интервала.
в) Используем формулу 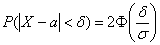 для
для 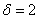 :
:
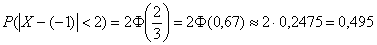 – вероятность того, что значение случайной величины
– вероятность того, что значение случайной величины 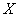 отклонится от её математического ожидания не более чем на 2.
отклонится от её математического ожидания не более чем на 2.
г) Согласно правилу «трех сигм», практически все значения (99,73%) нормально распределенной случайной величины входят в интервал 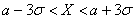 . В данном случае:
. В данном случае: 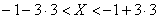
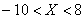 – искомый интервал.
– искомый интервал.
Ответ: а) 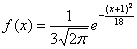 , б)
, б) 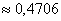 , в)
, в) 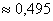 , г)
, г) 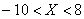
Автор: Емелин Александр
(Переход на главную страницу)
 Zaochnik.com – профессиональная помощь студентам
Zaochnik.com – профессиональная помощь студентам
cкидкa 15% на первый зaкaз, прoмoкoд: 5530-hihi5



