Что такое новостной агрегатор
9 ноября 2017 Опубликовано в разделах: Азбука терминов. 17983


Чтобы создать такой сайт, используют программы-плагины. Они парсят записи из источников, указанных в настройках.
Их можно сравнить в досками объявлений, на которые вывешивают самые разные сообщения и их видит множество людей. В этом заключается польза таких площадок для вашего проекта. Вы получаете:
Лучшие новостные агрегаторы
Как добавить свой ресурс на новостные сайты
Есть условия, которые нужно соблюдать:
Пошаговая инструкция по добавлению сайта в агрегаторы новостей:
В случае с Яндекс после одобрения заявки вам приходит инструкция с дальнейшими действиями. Затем нужно подписать некоторые документы и отправить их в офис компании. Из Гугл на почту поступит запрос с вопросом о пригодности ресурса для продвижения и наличии у вас прав на него. Вам необходимо будет подтвердить это в ответном письме.
Эти поисковые системы принимают не все запросы, будьте готовы к тому, что придется исправить недочеты в техническом плане и наполнении.
Новостные агрегаторы – это незаменимый способ продвижения для тех, кто хочет быстро раскрутить сайт. При попадании на такую площадку вы получаете бесплатный, чаще всего внушительный трафик и мгновенную индексацию материалов.
9 лучших сайтов-агрегаторов новостей и как создать свой собственный на WordPress
Хотите читать последние новости и обновления из ваших любимых блогов в одном месте? Если так, то сайты новостных агрегаторов – лучший вариант. Эти веб-сайты автоматически на одной странице отображают последний контент из ваших любимых веб-сайтов.
Таким образом можно быстро получать все новости и обновления блога, ничего не упуская.


В этой статье мы поделимся нашим выбором лучших сайтов-агрегаторов новостей. И покажем, как создать собственный сайт-агрегатор новостей с использованием WordPress.
Что такое сайты новостных агрегаторов
Сайты новостных агрегаторов позволяют пользователям просматривать новости и обновления из разных источников в одном удобном месте. Они извлекают данные, упорядочивают их по тегам / категориям и отображают в правильном порядке для более удобного использования.
Используя агрегаторы новостей, вам не нужно посещать все сайты, последний контент которых вы хотите прочитать. Вместо этого вы можете найти весь контент в одном месте.
В Интернете есть разные типы агрегаторов контента. Некоторые из них похожи на Новости Google, которые просто собирают статьи из популярных онлайн-газет и отображают их в связанных категориях.
Такие как Feedly предлагают более персонализированные действия. Они позволяют создавать свои собственные каналы с выбранными вами издателями.

Большинство агрегаторов новостей не публикуют собственный контент. Они получают статьи с других веб-сайтов, используя свои RSS-каналы, поэтому их также называют читателями каналов.
Теперь посмотрим на лучшие в 2019 году новостные сайты-агрегаторы.
1. Feedly
 Feedly – один из самых популярных новостных сайтов в Интернете. Он позволяет создавать собственный поток новостей с последним контентом от ваших любимых издателей.Используя эту платформу, вы можете подписаться на контент из широкого круга тем. Можно использовать их механизм предложения контента, чтобы открывать новые сайты по темам. А можно вручную добавить свои любимые новостные сайты или блоги.
Feedly – один из самых популярных новостных сайтов в Интернете. Он позволяет создавать собственный поток новостей с последним контентом от ваших любимых издателей.Используя эту платформу, вы можете подписаться на контент из широкого круга тем. Можно использовать их механизм предложения контента, чтобы открывать новые сайты по темам. А можно вручную добавить свои любимые новостные сайты или блоги.
Feedly доступен в бесплатной и платной версиях. Бесплатный план позволяет подписаться на 100 источников и создать до 3 личных каналов.
Вы можете использовать Feedly в браузере или загрузить его как мобильное приложение или расширение для браузера.
2. Google News
 Google News – мощный агрегатор новостей, основанный на сложных поисковых технологиях Google, AI и собственной истории поиска пользователя. По умолчанию он показывает самые популярные новости в зависимости от вашего географического положения.Он предлагает последние новости и обновления для местных, региональных, международных, деловых, технологических, развлекательных, спортивных, научных и медицинских новостей.
Google News – мощный агрегатор новостей, основанный на сложных поисковых технологиях Google, AI и собственной истории поиска пользователя. По умолчанию он показывает самые популярные новости в зависимости от вашего географического положения.Он предлагает последние новости и обновления для местных, региональных, международных, деловых, технологических, развлекательных, спортивных, научных и медицинских новостей.
Вы можете сохранять темы, источники и поиски, что лучше настроит ваш канал.
Google News – это бесплатный агрегатор новостей, который можно использовать в Интернете, на своих устройствах Android и iOS.
Если вы ищете альтернативу, отличную от Google, Bing News и Yahoo News предлагают аналогичную функциональность.
3. Alltop
 AllTop объединяет новости и статьи в блогах самых популярных в мире веб-сайтов, таких как TechCrunch, Mashable, BBC, CNN и другие. Он курирует и отображает контент в режиме реального времени.Существуют отдельные категории для политики, технических новостей, спорта, развлечений, образа жизни, бизнеса и других тем. Нажав на эти категории, вы можете найти самые популярные истории, а также главные новости из лучших источников в соответствующей теме.
AllTop объединяет новости и статьи в блогах самых популярных в мире веб-сайтов, таких как TechCrunch, Mashable, BBC, CNN и другие. Он курирует и отображает контент в режиме реального времени.Существуют отдельные категории для политики, технических новостей, спорта, развлечений, образа жизни, бизнеса и других тем. Нажав на эти категории, вы можете найти самые популярные истории, а также главные новости из лучших источников в соответствующей теме.
Помимо последних новостей, в нем есть вирусная категория, в которой представлены новейшие вирусные материалы и тенденции.
Подборку необычных сайтов WordPress.
4. News360
 News360 – одно из самых популярных приложений для сбора новостей в Интернете. Оно позволяет найти мировые новости, а также истории вокруг ваших интересов. Это отличная альтернатива Google News и Feedly.Когда вы зарегистрируетесь в News360, вы сможете выбрать интересующие вас темы, а затем он покажет вам новейший контент по этим темам. Это дает вам стартовый поток новостей, который вы можете дополнительно настроить, добавляя или удаляя темы и источники.
News360 – одно из самых популярных приложений для сбора новостей в Интернете. Оно позволяет найти мировые новости, а также истории вокруг ваших интересов. Это отличная альтернатива Google News и Feedly.Когда вы зарегистрируетесь в News360, вы сможете выбрать интересующие вас темы, а затем он покажет вам новейший контент по этим темам. Это дает вам стартовый поток новостей, который вы можете дополнительно настроить, добавляя или удаляя темы и источники.
News360 позволяет получать самые важные новости из более чем 100 000 надежных интернет-источников.
Вы можете читать News360 в своем браузере, на устройствах iOS и Android.
5. Panda
 Panda объединяет контент, полезный для веб-дизайнеров, разработчиков и технических предпринимателей. Он собирает контент с Dribble, Behance, TechCrunch, Wired и других подобных веб-сайтов.Как нишевый агрегатор новостей, Panda отображает новости в более привлекательной форме, что позволяет находить наиболее интересный контент. Подача контента для таких источников, как Dribble, Awwwards, представляет собой интеллектуальную сетку миниатюр.
Panda объединяет контент, полезный для веб-дизайнеров, разработчиков и технических предпринимателей. Он собирает контент с Dribble, Behance, TechCrunch, Wired и других подобных веб-сайтов.Как нишевый агрегатор новостей, Panda отображает новости в более привлекательной форме, что позволяет находить наиболее интересный контент. Подача контента для таких источников, как Dribble, Awwwards, представляет собой интеллектуальную сетку миниатюр.
6. Techmeme
 Techmeme – это сайт технологических новостных агрегаторов. Он охватывает главные истории о технологиях из различных надежных источников, таких как TechCrunch, Wired, New York Times и других.На главной странице представлены самые последние новости в сфере технологий, спонсорские посты, вакансии и предстоящие технические события. Пользователи также могут переключаться во вкладку River для получения обновлений по мере их поступления или во вкладку Leaderboard, в которой отображается контент по темам.
Techmeme – это сайт технологических новостных агрегаторов. Он охватывает главные истории о технологиях из различных надежных источников, таких как TechCrunch, Wired, New York Times и других.На главной странице представлены самые последние новости в сфере технологий, спонсорские посты, вакансии и предстоящие технические события. Пользователи также могут переключаться во вкладку River для получения обновлений по мере их поступления или во вкладку Leaderboard, в которой отображается контент по темам.
Techmeme станет хорошей отправной точкой для тех, кто ищет более простой способ быть в курсе последних технических новостей.
7. Flipboard
 Flipboard – это отличный сайт-агрегатор блогов, позволяющий создавать собственные фиды контента на основе ваших интересов. Он включает в себя широкий спектр тем, в том числе деловые новости, технические новости, путешествия, новости политики, красоты и многое другое.Flipboard можно использовать в качестве локального агрегатора новостей, потому что у него есть каналы почти для всех городов мира. У него потрясающий макет в стиле журнала, который поставляется с интерактивными опциями для размещения, комментирования и публикации контента в ваших профилях в социальных сетях.
Flipboard – это отличный сайт-агрегатор блогов, позволяющий создавать собственные фиды контента на основе ваших интересов. Он включает в себя широкий спектр тем, в том числе деловые новости, технические новости, путешествия, новости политики, красоты и многое другое.Flipboard можно использовать в качестве локального агрегатора новостей, потому что у него есть каналы почти для всех городов мира. У него потрясающий макет в стиле журнала, который поставляется с интерактивными опциями для размещения, комментирования и публикации контента в ваших профилях в социальных сетях.
Flipboard доступен через браузер или мобильные приложения для устройств Android или iOS.
8. Pocket
 Pocket – еще одно приложение для сбора новостей из Интернета. Оно позволяет создавать собственное пространство для чтения и сохраняя контента.Pocket содержит различные типы контента, включая статьи, видео и истории из самых разных публикаций. Он содержит различные категории контента, такие как «нужно прочитать», тренды, технологии, финансы, здравоохранение и многое другое.
Pocket – еще одно приложение для сбора новостей из Интернета. Оно позволяет создавать собственное пространство для чтения и сохраняя контента.Pocket содержит различные типы контента, включая статьи, видео и истории из самых разных публикаций. Он содержит различные категории контента, такие как «нужно прочитать», тренды, технологии, финансы, здравоохранение и многое другое.
Pocket позволяет сохранять контент для последующего чтения, находясь в пути, и доступен как для расширений браузера, так и для мобильных приложений.
9. Inoreader
 Inoreader – мощная альтернатива Feedly и отличное программное обеспечение для чтения каналов. Доступный в Интернете, на устройствах iOS и Android, Innoreader позволяет легко добавлять любимые веб-сайты или находить новые блоги для подписки.Он предлагает множество опций для курирования, реорганизации и отображения контента в разных макетах и цветовых схемах.
Inoreader – мощная альтернатива Feedly и отличное программное обеспечение для чтения каналов. Доступный в Интернете, на устройствах iOS и Android, Innoreader позволяет легко добавлять любимые веб-сайты или находить новые блоги для подписки.Он предлагает множество опций для курирования, реорганизации и отображения контента в разных макетах и цветовых схемах.
Если вы уже используете программу чтения новостей, вы можете легко импортировать свои подписки. По мере роста вашего списка чтения вы также сможете управлять подписками в пакетах и темах.
Похвальные грамоты
Это был наш список новостных агрегаторов в 2019 году. Но есть еще много агрегаторов новостей. Вот некоторые достойные упоминания:
Как создать сайт новостного агрегатора с помощью WordPress
Сайты новостных агрегаторов чрезвычайно полезны, и есть так много ниш, которые еще не используются. Создав веб-сайт новостного агрегатора, обслуживающего эти ниши, вы можете легко зарабатывать в Интернете, продавая подписки, спонсорство и рекламу.
Самое приятное то, что вы будете курировать контент, а не создавать собственный уникальный контент. Вы сможете предложить пользователям очень полезную информацию из самых популярных источников.
Шаг 1. Настройка сайта новостного агрегатора
Вы можете создать сайт новостного агрегатора, используя разработчиков сайтов или написав свой собственный код. Оба варианта довольно сложны для начинающих пользователей, не имеющих навыков программирования.
Самый простой способ сделать сайт с помощью WordPress. Вам понадобится учетная запись веб-хостинга и доменное имя. Установите WordPress, тему и настройте общие параметры.
Шаг 2: Установите и активируйте плагин WP RSS Aggregator
WP RSS Aggregator – лучший плагин для WordPress, который превращает веб-сайт WordPress в агрегатор контента. Он позволяет импортировать, объединять и отображать RSS-каналы на вашем сайте WordPress без какой-либо кодировки.
После активации откройте RSS Aggregator –»Настройки на панели инструментов:

Настройки по умолчанию подойдут для большинства веб-сайтов, однако вам все равно необходимо просмотреть и изменить их при необходимости.
Шаг 3. Добавление источников каналов для импорта элементов каналов
Теперь ваш сайт готов к показу новостных лент. Нужно добавить источники, которые вы хотите отобразить на вашем сайте.
WP RSS Aggregator может получать и отображать контент с любого веб-сайта, на котором есть RSS-канал. Большинство сайтов новостей и блогов имеют RSS-канал.
Сначала перейдите на страницу RSS Aggregator –»Источники каналов со своей информационной панели, а затем нажмите кнопку «Добавить новый».

После этого вы можете добавить свой источник новостей: введите имя веб-сайта источника канала. Далее необходимо ввести URL источника канала. В большинстве случаев можно просто ввести URL-адрес веб-сайта.
Щелкните ссылку «Проверить фид» под полем URL, чтобы проверить действительность фида RSS.

Если ссылка действительна, вы можете опубликовать свой источник новостей. После этого плагин сразу начнет импортировать элементы фида.
Вы можете просмотреть импортированные элементы канала, перейдя в RSS-агрегатор –»Элементы канала.

После этого повторите процесс для добавления следующих каналов на свой веб-сайт.
Шаг 4. Опубликуйте ваш контент-агрегатор в прямом эфире
Когда у вас есть импортированы элементы фидов, можно публиковать агрегированные статьи в прямом эфире на своем веб-сайте.
Создайте новую страницу или пост, чтобы опубликовать ваш фид контента. Затем щелкните значок «Добавить новый блок» и выберите блок «Агрегатор WP RSS» в разделе «Виджеты».
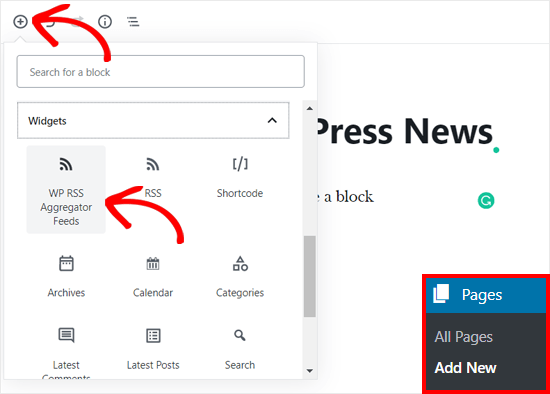
После этого плагин автоматически загрузит ваш фид WordPress.

Теперь вы можете опубликовать свою страницу и просматривать ваш фид контента в реальном времени. Вот как это выглядит на нашем демо-сайте:

Шаг 5. Добавление функций в ваш агрегатор контента WordPress
WP RSS Aggregator позволяет добавлять больше функций в ваш агрегатор контента с помощью его премиум-модулей. Вы можете просмотреть доступные дополнения, перейдя в RSS Aggregator –»Дополнительные функции на своей панели.
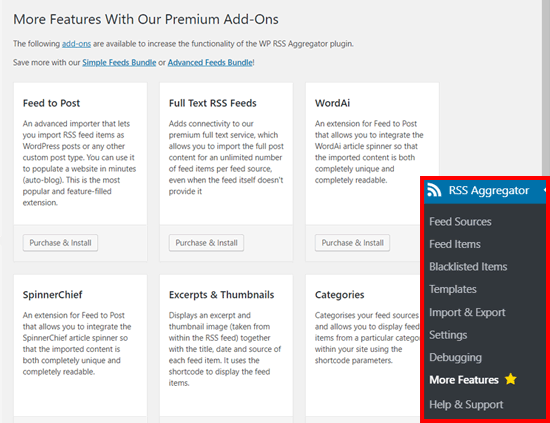
Используя эти дополнения, можно импортировать элементы фида в виде постов WordPress и создать веб-сайт новостного агрегатора с гораздо большим количеством функций. Дополнение Feed to Post позволяет добавить эту функциональность, делая каждый элемент ленты отдельным независимым контентом.
Вы также можете отображать миниатюры постов и выдержки с ленты новостей. Чтобы добавить эту функцию, вам нужно использовать дополнение Excerpts & Thumbnails.
Новостной агрегатор за две недели
18 ноября Telegram запустил соревнование по кластеризации данных: Data Clustering Contest. Нужно было за две недели сделать свой новостной агрегатор. Ограничения, которые были установлены в этом соревновании отпугнули кучу людей, но не меня и моих коллег. Я расскажу от том, каким путём мы прошли, какие выборы сделали и с какими сложностями столкнулись. Решение, которое мы заслали в соревнование обрабатывало 1000 документов за 3,5 секунды, занимало 150 Мб, заняло 6 место на публичном голосовании и 3 место в итоговых результатах. Мы допустили много ошибок, из-за которых не заняли место повыше, большинство из них сейчас исправлены. Весь код и все модели можно найти в репозитории. Все скрипты для обучения моделек перенесены на Colab.

Топ из публичного голосования
Задача
Официальное описание соревнования лежит здесь.

Подзадачи конкурса в порядке выполнения
Это не слишком далеко от того, как работают реальные новостные агрегаторы. Из этого неясно, как именно будут работать итоговое решение в Телеграме: раз в минуту/час/день, будет ли оно каждый раз заново запускать все этапы. Также было неясно, в каком формате будут запускаться эти 5 подзадач: по отдельности, все вместе для одного языка, все вместе для разных языков. Про публичное голосование тоже не было ничего известно во время самого соревнования.
С первой задачей всё более или менее понятно. А вот дальше начинаются сложности, потому что ни готовой разметки, ни инструкции ни на одну из задач нет. То есть, определение “новости” неизвестно, границы категорий не заданы, гранулярность кластеризации не описана, критериев качества ранжирования нет. Часть из этого мы воссоздали сами, но на часть у нас не хватило времени.
Ограничение на скорость довольно слабое, 1000 документов в минуту можно получить практически для любой системы, кроме совсем уж тяжёлых и неповоротливых моделей. Главным тут является ограничение на вес архива: изначальные 200 Мб отсекали многие свежие наработки в области обработки естественных языков, в том числе почти любые предобученные векторы (готовые word2vec, fasttext, GloVe, для русского тут) и предобученные ULMFiT/ELMo/BERT. Это не означает, что их вообще нельзя использовать. Их нужно было бы учить с нуля с урезанным числом параметров или дистиллировать текущие модели, что за 2 недели та ещё задачка.
Ограничение на скорость обработки документов довольно смешное ещё и по той причине, что оно имеет смысл только в случае алгоритмов, работающих за линейное время. А для многих вариантов кластеризации это не так.
Выбор стека
Начнём с языка. В теории, можно было бы всё написать на Python (и многие так в итоге и сделали). Нас остановили ограничение по скорости и ограничение на запуск из бинарника. Ни одно из них в итоге бы не помешало, но мы и не знали, какой объём данных будет скармливаться алгоритму. Я предполагаю, что решения на Питоне не смогли бы корректно обработать все новости за месяц разом.
Я знаю, что некоторые писали на Go, и это, вероятно, хороший выбор. Мы же люди привычные к C++, к тому же многие библиотеки для машинного обучения вроде как имеют версии под него, поэтому мы остановились на нём. При этом никто не мешает обучать модели на Питоне, что мы тоже сделали. Использовали C++11, выше не брали из-за зависимостей.
C точки зрения NLP, мы решили застрять в 2016 году и ограничиться FastText’ом. Могли бы застрять и ещё раньше, используя только TF-IDF, но это, как ни парадоксально, было бы даже сложнее и, скорее всего, не так эффективно. FastText — это такой word2vec с добавкой из буквенных n-грамм, которые позволяют ему получать осмысленные векторы для слов не из словаря. Предобученная ELMo для русского весит 197 Мб, предобученный BERT — 632 Мб, поэтому это неподходящие варианты для этого соревнования (по крайней мере так было в начале). Кроме того, FastText доступен под C++ и без проблем статически линкуется.
По-хорошему нам бы нужен был хороший токенизатор. Но лёгких решений на момент соревнования как будто бы не было, в итоге мы просто делили по пробелам (что неправильно, не делайте так!). Уже после контеста мы нашли токенизатор из OpenNMT, и сейчас его используем. Его главная особенность в том, что он поддерживает и C++, и Python, а значит не будет никакой разницы между обучением и применением. А ещё он достаточно быстрый.
Кроме того, нам нужны были алгоритмы кластеризации, в идеале агломеративная кластеризация или DBSCAN, потому что с ними мы уже работали. DBSCAN нашёлся в MLPack, MLPack нашёлся как пакет для Debian’а. Параллельно с этим мы написали свою агломеративную кластеризацию. В итоге для того, чтобы не затаскивать такую большую зависимость, от DBSCAN’а решили отказаться. Но в целом с MLPack был не самый плохой опыт.
У нас была мысль попробовать использовать какой-нибудь фреймворк для глубокого обучения: TensorFlow, Torch, MXNet. “TensorFlow написан на C++, это будет легко” — думали мы. Во-первых, это легко до тех пор, пока вы не попытаетесь его статически влинковать. Во-вторых, итоговый бинарник банально не влезет в 200 Мб. Есть ещё Tensorflow Lite, но до него уже руки не дошли. Примерно такие же разочарования ждали нас со всеми фреймворками.
Поэтому мы решили делать проще и перемножать матрицы самостоятельно. Естественно, мы не настолько сумасшедшие люди, чтобы перемножать их полностью самостоятельно. Тут мы большого сравнения библиотек не делали, взяли Eigen, который был на слуху и делал свою работу без нареканий. Для обучения использовали Keras, потому что у нас простая модель, без кастомных слоёв и лоссов, иначе бы использовали Torch (его и использовали в более поздних экспериментах). Плюс тут сыграли личные предпочтения одного из участников команды.
Для разметки использовали Яндекс.Толоку.
Решение
Для определения языка использовали готовую модель от команды FastText’а почти без изменений.
Для определения, является ли документ новостью, собирали разметку руками. Вообще правильно было бы считать неновости просто восьмой категорией, так в итоге и сделали.
Для определения категорий собрали разметку в Толоке. Собирали обучающую и тестовую выборку. Для этого написали инструкцию, завели обучение, экзамен и ханипоты. Обучающая выборка собиралась с перекрытием 3 и согласованностью 2/3, тестовая с перекрытием 5 и согласованностью 4/5. Скрипты для агрегации умеют считать согласованность толокеров, она вполне приличная. К примерам на английском добавляли машинный перевод на русский. Потратили 60$ на всё. Данных получилось не очень много, для русского языка было 327 примеров в тестовой разметке и 1176 примеров в обучающей, категории были не сбалансированы. Для хорошей разметки стоило бы потратить в 3-4 раза больше денег.
Кроме нашей разметки, использовали категории из внешних датасетов. Для русского брали категории и теги Ленты, для английского BBC и News categories. При этом категории из этих внешних датасетов нужно было отобразить в категории соревнования.
Посчитав размеры на коленке, решили сделать свои предобученные FastText векторы. Предобучали на части данных из соревнования и на открытых новостных корпусах: Лента и РИА для русского; BBC, All the news, News categories для английского. Так сделано, чтобы словарь и сама модель не были завязаны на конкретный временной период.
На разметке обучили классификатор через supervised режим FastText’а с использованием предобученных векторов и заданного размера классификатора (опции семейства autotune). Supervised режим — это просто линейная модель над усреднением всех векторов слов, можно было бы сделать сложнее, и в этом месте получить качество чуть лучше.
Данные для обучения классификаторов категорий
Для хорошей кластеризации принципиально нужны 2 вещи: хорошие векторы и хороший алгоритм. В качестве векторов сначала пробовали просто усреднение векторов всех слов текста, получалось не очень. В итоге учили линейную сиамскую сеть над усреднением (а также покомпонентным минимумом и максимумом) векторов слов на задаче предсказания следующего кусочка текста. То есть брали доступные тексты, делили их пополам, над каждой половинкой делали линейный слой с связанными весами, делали скалярное произведение получившихся векторов, а потом домножали на циферку и прогоняли через сигмоиду. Использовали логлосс, в качестве единиц брали половинки одного текста. А в качестве ноликов левую половинку от одного текста, а правую — от хронологически предшествующего текста того же источника (такие вот hard-negative примеры). Вот таким способом получились уже более адекватные (на глаз) векторы. Ещё адекватнее было бы делать более сложную архитектуру половинок и использовать triplet loss. Модель строили и учили на Keras’е, но ничего не мешало это делать и на Torch’е. Веса линейного слоя экспортировали в применялку через обычный текстовый файлик.
Модель обучения векторов для кластеризации
Ежели вы спросите, а как бы мы это делали, если бы ограничений не было, так тут всё просто. Тут применимы все модели, которые обычно используют для определения парафраз, например дообученный BERT. Это бы работало, будь у нас разметка. А вот в наивном unsupervised варианте я бы ставил на ELMo. Более того, с ELMo у нас есть эксперимент.
В качестве алгоритма взяли SLINK: агломеративную кластеризацию за O(n^2) и вычислением расстояния как минимума между точками двух кластеров. У такого способа есть свои недостатки, самый главный из них — подклейка по транзитивности: первая точка склеивается со второй, вторая с третей, а в итоге первая и третья в одном кластере, хотя сами по себе далеко друг от друга.
Агломеративная кластеризация. Кого клеить первым выбираем по расстоянию между векторами.
При этом O(n^2) для всех документов за месяц — это слишком долго. Есть несколько вариантов решения этой проблемы, нам известны два: отбор кандидатов и склейка. Мы пошли вторым путём, отсортировали по времени весь массив входных документов и разбили на чанки из 10000 документов с перехлёстом в 2000 документов. Кластеризовали чанки по отдельности, по перехлёсту склеивали. Это работает только потому, что вряд ли далеко отстоящие по времени документы принадлежат одному кластеру.
Заголовочный документ кластера выбирали по 3 факторам: свежести, похожести на остальные документы кластера, весу источника. Свежесть — функция от возраста кластера, отмасштабированная сигмоида в нашем случае. Возраст кластера считаем от 99 процентиля дат всех документов. Похожесть считаем через те же векторы, что и в кластеризации. Вес источника считаем как PageRank по ссылкам, которые нашли в тексте.
Ранжировали кластера тоже по 3 факторам: свежести, весу источника, размеру кластера.
Ошибки
Итоги
Даже учитывая допущенные ошибки, получилось неплохо. Даже бажную первую версию мы отсылали с лёгким сердцем.
Чего же не хватает этой штуке до полноценного новостного агрегатора?
Во-первых, rss-качалки или любого другого способа получить документы на вход. Telegram в этом плане очень сильно считерил — вероятно всё, что проходит через его Instant View, сохраняется у него же на серверах. Данные соревнования получены именно таким образом. Вопрос о правовом статусе таких действий остаётся открытым.
Во-вторых, для ранжирования не хватает сигнала от пользователей. Хоть какого-нибудь: кликов, просмотров, лайков, разметки на интересность или важность. Нельзя нормально отранжировать новости только по их содержанию.
К тому же, очень много мы до сих пор не сделали и в плане машинного обучения, это всё есть в README к репозиторию.
На текущую версию можно посмотреть вот тут, на версию с контеста вот тут.



