Что такое обезличивание персональных данных, для чего нужно, каковы правила работы с ними?

Обращение с персональными данными как физического, так и юридического лица в Российской Федерации регламентируется законодательством. Такая информация принадлежит владельцу и может обрабатываться только при наличии согласия.
Обезличивание позволяет компании снизить приоритетность информации, обезопасить хозяев за счет сокращения и изменениях ведомостей. В этом материале мы разберемся с тем, что собой представляет обезличивание данных, в каких случаях оно используется и с какой конечной целью.
Что это такое?
Обезличивание персональной информации является составляющей частью обработки материалов. В статье 7 Федерального закона РФ от 27 июля 2006 года «О персональных данных» сообщается, что под обезличиванием ведомостей понимается действие, которое делает невозможным определение принадлежности информации к конкретному лицу. При этом, речь идет только об идентификации физического или юридического лица на основе сообщений, которые подвергаются обезличиванию.
Статья 7 ФЗ №152 от 27 июля 2006 года «О персональных данных». Конфиденциальность персональных данных
Операторы и иные лица, получившие доступ к персональным данным, обязаны не раскрывать третьим лицам и не распространять персональные данные без согласия субъекта персональных данных, если иное не предусмотрено федеральным законом.
Эта же информация может помочь определить, к какому россиянину относятся ведомости, если будут использованы дополнительные источники. Обезличивание проводится как при помощи автоматизированных систем (компьютеров, программ), так и без использования таких средств.
Алгоритм доступен только операторам, имеющим в своем распоряжении информацию личного характера. После обезличивания материалов с оператора снимаются требования по обеспечению максимальной конфиденциальности.
Теперь вы в общих чертах знаете, что это такое – обезличенные данные о клиентах.
Для чего необходимо?
Роскомнадзор определяет обезличивание в качестве способа защиты информации от несанкционированного использования, однако сохранить возможность пользоваться ею дальше. В некоторых случаях операторам необходимо сохранить доступ к ведомостям на длительный срок. Если ликвидировать материалы невозможно, обезличивание станет достойной альтернативой.
Хранение персональных сообщений регулируется законом, требует выполнения мероприятий по обеспечению конфиденциальности. Например, в электронном виде сведения должны храниться в информационных системах, прошедших государственную экспертизу. Переведя данные в разряд обезличенных, оператор может сократить собственные расходы на хранение информации, ведь с этого момента они больше не позволяют определить их владельца.
Пример
Многие из жителей Российской Федерации пользуются интернет-магазинами для совершения быстрых и выгодных покупок. И каждый торговый портал является оператором ПД (персональных данных). Предположим, ресурс хранит сообщения о клиентах в электронном виде.
По каждому покупателю у оператора имеются следующие сведения: ФИО, город проживания, перечень заказанных товаров. Все эти материалы являются личными, дают возможность идентифицировать лицо с большой долей вероятности или способны, в случае неконтролируемого распространения, нанести гражданину – обладателю информации – вред.
Возьмем для примера метод декомпозиции. Он предусматривает разбивку массива информации (ФИО, город проживания и перечень товаров) на несколько частей, которые будут храниться отдельно друг от друга. Все три группы по отдельности не могут стать инструментом для идентификации человека.
Однако при любом способе деперсонализации данных интернет-магазин сохранит возможность оперировать необходимыми материалами, например, использовать информацию для собственных статистических исследований по популярности ресурса в отдельном населенном пункте или востребованности определенного товара.
Правила работы
Такие правила устанавливаются региональными муниципалитетами Российской Федерации на основе уже упомянутого Федерального закона «О персональных данных».
Теперь вы знаете, каковы правила работы с обезличенными данными о клиенте.
При помощи чего возможно?
Так как же обезличить ПД? Основные методы обезличивания информации утверждены в Приказе Роскомнадзора, органа осуществляющего надзор за реализацией государственной политики в сфере массовой коммуникации. В наши дни используются четыре основных метода обезличивания.
Пошаговая инструкция: как осуществить?
Основным нормативным документом при проведении обезличивания информации остается акт «О персональных данных» правительства Российской Федерации. Обезличивание считается вариантом обработки ПД, поэтому при проведении соответствующего действия необходимо выполнять основные требования, которые предъявляются к обработке:
Обработка данных включает в себя следующие составные мероприятия:
Обезличивание данных проводится исключительно для нужд самого оператора, поскольку в процессе этого мероприятия информация теряет важность. Хранить такие ведомости удобно для самого оператора, ведь обезличенные данные даже в случае несанкционированного распространения не смогут нанести вред субъектам. Тем не менее, они остаются персональной информацией, и доступ к ним должен быть ограничен по всем законам России.
Мир без розовых единорогов. Тестирование производительности высоконагруженных систем




Когда необходимо проводить тестирование производительности?
В чем особенности тестирования высоконагруженных систем?
Почему 5 дней обучения по мануалам не сделают из вас тест-инженера?
Какие системы можно считать высоконагруженными? Распространенный ответ: с большим количеством одновременно работающих пользователей. Но бывает и так, что пользователей мало, их рост незначителен, а нагрузка на систему постоянно растет. Это происходит за счет увеличения числа существующих интеграционных потоков и их интенсивности. Поэтому правильнее считать высоконагруженными системами те, в которых со временем растут интенсивность нагрузки (количество транзакций в секунду) и количество хранимых и обрабатываемых данных.
Статьи по теме
Поделиться
Высоконагруженная система — это система, цена ошибки производительности которой высока с репутационной и финансовой точек зрения. Поэтому они относятся к классу mission или business critical.
Тестирование производительности высоконагруженных систем должно обеспечивать: высокую интенсивность нагрузки; необходимое количество исторических и тестовых данных.
Мы часто работаем с системами, спроектированными до появления современных паттернов highload-разработки. Архитекторы не закладывали в них возможностей для роста нагрузки, который в итоге произошел. Эти системы работают на пределе своего потенциала и, безусловно, еще больше нуждаются в регулярном нагрузочном тестировании (НТ).
Кому сейчас требуется заказное нагрузочное тестирование? Чаще всего финансовым организациям, ритейлу и операторам сотовой связи. Такие компании могут обеспечить всю необходимую инфраструктуру для проведения тестирования.
Ниже мы поговорим о тестировании на системном и приемочном уровнях. Конечно, выявлять дефекты производительности можно (и даже нужно) раньше, но, чтобы разобраться, как делать это на компонентном и интеграционном уровнях, понадобится отдельный номер журнала.
Для проведения тестирования необходима соответствующая инфраструктура.Предположим, в тестировании задействована промышленная база размером 150 ТБ. Нужно будет найти ресурсы для создания ее копии и тестовый сервер, на котором вы ее восстановите. Причем такая база может иметь кластерную конфигурацию, и тогда речь пойдет уже не об одном, а о нескольких серверах.
На заметку
С точки зрения инфраструктуры тестовый стенд должен включать:
При этом на всех серверах нужно установить те же настройки и патчи, которые используются в промышленной среде.
Тестирование можно провести, даже если у вас нет ресурсов и возможности вовремя их получить. Правда, придется хорошенько подумать об интерпретации результатов, полученных на более слабом железе. Результат не всегда будет точным, поскольку универсальной формулы не существует — все зависит от поведения конкретной системы на конкретном оборудовании.
Все высоконагруженные приложения должны иметь серьезную систему мониторинга. Не менее, а то и более тщательный мониторинг нужно строить и в тестовой среде. Основное правило: не навреди. Система мониторинга не должна существенно влиять на производительность тестируемого приложения.
Система нагрузочного тестирования (скрипты, инструменты генерации нагрузки, эмуляторы) должна создаваться с учетом паттернов highload-разработки. Если SLA на операцию — 30 секунд, а эмулятор при высокой нагрузке отвечает минуту, то дефект в данном случае находится на его стороне.
Кому сейчас требуется заказное нагрузочное тестирование? Финансовым организациям, ритейлу и операторам сотовой связи. Такие компании могут обеспечить всю необходимую инфраструктуру для проведения тестирования.
Для тестирования нужны данные, в идеале — обезличенные. В больших системах это сотни таблиц со сложными связями, сотни терабайт информации.
Безусловно, все обезличивать не надо, но даже обработка 10% данных займет достаточно много времени. Причем обезличивание путем простой замены информации на рандомный набор символов может изменить логику работы системы, и вы начнете тестировать что-то не то. Все эти нюансы необходимо продумывать вместе с бизнесом и разработчиками.
А теперь допустим, что база есть, она обезличена и все хорошо. Предположим, каждый год она растет на один терабайт и это оказывает существенное влияние на производительность. При тестировании данный факт необходимо учесть — наполнить основные таблицы новыми данными. А значит, надо разработать многопоточные sql-скрипты, которые должны сделать это в оптимальные сроки.
Необходима автоматизация процесса тестирования. Без этого для постоянно растущей системы невозможно обеспечить регулярное и быстрое тестирование.
Важно грамотно подобрать команду. Она не обязательно должна быть большой — стенд у вас все равно только один. Что делать 8 инженерам, когда тесты проводят только двое? Команда должна быть оптимальной — такой, чтобы каждый был при деле, но при этом всегда оставалось время на автоматизацию и оптимизацию процессов.
Нужно регулярно проводить ретроспективу, чтобы понять, где в вашем тестировании узкое место и как его устранить.
Уже налаженный процесс тестирования должен развиваться вместе с системой. НТ требует постоянной корректировки и оптимизации.
Мы живем в реальном мире без розовых единорогов. Дефекты все равно будут, но можно минимизировать их количество и снизить критичность.
Встраивание нагрузочного тестирования в жизненный цикл системы — это дорого и сложно. Как же выбрать подходящий момент? Нужно оценить стоимость тестирования и размер финансовых потерь от дефекта производительности системы.
Когда нужно проводить тестирование производительности
На самом деле всегда. Но встраивание НТ в жизненный цикл любой системы — это дорого и сложно. Как тогда выбрать подходящий момент? Достаточно оценить стоимость тестирования и размер финансовых потерь от дефекта производительности системы. Например, он может привести к потере данных, длительному простою или увеличению времени отклика приложения. А вдруг система окажется не способна к восстановлению после падения? А если речь идет о финансовых транзакциях?
Когда стоимость НТ значительно меньше возможных потерь, его обязательно стоит проводить. При этом если задача срочная, а у вас не хватает экспертизы или специалистов, логично заказать его на стороне.
На заметку
Какая экспертиза нужна тестировщику производительности высоконагруженных систем?
Нужны навыки:
Также необходимо: разбираться в конкретных областях бизнеса, владеть специфическими знаниями и инструментами нагрузочного тестирования. Важную роль играют и soft skills: усидчивость, умение работать в команде — короче говоря, классический «джентльменский набор».
Нагрузочное тестирование на аутсорсинге
Аутсорсинг — отличный вариант, если вам не хватает экспертизы. Также он подойдет, если тестирование нужно для выполнения конкретной задачи. Например, заменить серверы, сменить версию СУБД или перейти на другое решение (привет импортозамещению). Такие задачи возникают редко и не всегда решаются стандартным способом — синтетическими тестами. А нанимать в штат людей с нужными компетенциями ради их решения бессмысленно.
Недавно к нам пришел запрос на НТ автоматизированной системы от крупного банка с офисами по России и Европе, входящего в топ-50. Речь шла о системе для работы с претензиями клиентов в отношении транзакций по картам на устройствах самообслуживания. БД на тот момент составляла более 20 ТБ данных. Раньше разработкой занимались подрядчики, а потом банк забрал эту задачу себе. При этом была утрачена экспертиза в части тестирования системы и частично по ее работе.
Требовалось оценить производительность решения перед внедрением в продуктив очередного релиза, восстановить экспертизу и обучить сотрудников заказчика.
Предполагалось, что ранее разработанные средства НТ для системы работоспособны и актуальны. Но при попытке запуска скриптов мы наткнулись на ошибки, дающие ложноположительные результаты. К тому же система серьезно изменилась с момента последнего тестирования. В итоге мы полностью переписали средства НТ, составили подробную инструкцию и провели очное обучение штатных специалистов банка. Как показала практика, в отсутствие автора, инструкций или хотя бы странички в Confluence, а также комментариев в коде скрипты проще написать заново.
Кроме того, тестируемое решение предполагало интеграцию с БД четырех автоматизированных систем (АС), откуда в офлайн-режиме должны были загружаться данные. Нам нужно было эмулировать БД этих АС. Для эмуляции создавались таблицы, которые нужно было наполнять данными (более 100 млн записей). При этом для успешного проведения каждой операции важно было соблюдать и правила наполнения таблиц внутри одной АС, и правила связи данных между АС. Поскольку экспертиза по системе у заказчика была частично утеряна, вместо необходимых инструкций у нас был единственный документ из ста с лишним страниц. Для решения задачи мы привлекли Oracle DBA, который смог быстро разработать скрипты создания и наполнения таблиц с учетом всех изложенных в документе правил. Мы подобрали оптимальное количество потоков для наполнения БД и разработали инструкции по использованию скриптов для заказчика.
В ходе тестирования мы столкнулись с неожиданной проблемой. Каждый раз после перезапуска стенда (а значит, после каждого теста) в коде системы изменялись ID компонентов пользовательского интерфейса. Всему виной технология JSF, где ID могут быть фиксированными, а могут назначаться заново. По умолчанию использовался второй вариант. Из-за этого приходилось каждый раз выполнять отладку всего набора UI-скриптов. Для устранения этой проблемы мы вместе с разработчиками приняли решение зафиксировать ID в коде системы.
Проект оказался интересным и с управленческой точки зрения. Сроки поджимали, а количество непредвиденных сложностей росло по мере погружения в проект. Чтобы снизить риски и их последствия, мы плотно работали с заказчиком — помогали ему наращивать экспертизу в части эксплуатации системы и оперативно исправлять дефекты производительности.
В итоге все тесты были выполнены вовремя, а трудозатраты не превышены. Мы исправили все дефекты производительности, и релиз был внедрен в промышленную среду.
Аутсорсинг нагрузочного тестирования — отличный вариант, если вам не хватает экспертизы. Также он подойдет, если тестирование нужно для выполнения конкретной задачи. Например, заменить серверы или сменить версию СУБД.
Фишки аутстаффинга
В последние годы на рынке заказного тестирования набирает популярность новая парадигма — иметь хорошую внутреннюю экспертизу, а при увеличении объема работ дополнительно привлекать подрядчиков. Другими словами — использовать аутстаффинг. Вот несколько фишек, с помощью которых мы как генеральный подрядчик делаем эту модель действительно эффективной для заказчика.
Сами проводим первичное интервью с кандидатом. Только если он нас полностью устраивает, мы включаем его в работу с заказчиком. Кандидат попадает к нам в штат: мы учим его, вместе выходим из конфликтных ситуаций, решаем вопросы, касающиеся развития, ищем для него следующий проект у другого заказчика.
Ходим на собеседования к заказчику вместе с кандидатами. Поскольку у нас за плечами большой опыт и в нагрузочном тестировании, и в подборе персонала, мы умеем задавать правильные вопросы заказчику и выявлять ключевые компетенции из всего перечисленного в описании вакансии. Это помогает понять, каких именно людей надо искать для заказчика.
Не просто выполняем задачи заказчика, а находим узкие места в процессах и предлагаем варианты их оптимизации. Безусловно, у заказчика всегда есть свой ответственный эксперт, но взгляд на уже устоявшийся процесс со стороны всегда полезен. Успешная автоматизация процессов и применение современных технологий позволяют сократить время на подготовку и проведение тестирования до 90%.
Проводим стажировки под конкретные проекты. Обсуждаем и корректируем программу обучения в зависимости от особенностей заказчика, его пожеланий в отношении знаний и умений стажеров. Это не два дня обучения MF LoadRunner. Понятно, что можно обучиться работе с любым инструментом по мануалам за неделю совершенно бесплатно, но это не сделает из вас инженера по нагрузочному тестированию. Мы обучаем теории тестирования производительности, основам объектно-ориентированного программирования, DML- и DDL-командам в SQL. Рассказываем о мониторинге, брокерах сообщений. Результаты выполнения итогового задания обсуждаем с заказчиком и решаем, на какой проект можно привлечь конкретного стажера.
Обеспечиваем стабильный состав команды. Люди реже уходят оттуда, где о них заботятся.
За хорошего инженера нужно платить. Конечно, всегда есть озвученный выше вариант «5 дней обучения по мануалам — и инженер готов». Дешево и сердито. Только даст ли это ожидаемый заказчиком результат?
Расследование: как обезличенные данные становятся персональными и продаются на сторону
Неделю назад мне в очередной раз позвонили и предложили купить какой-то новый автомобиль в салоне, где я точно никогда не бывал. На простой вопрос о том, откуда звонивший взял мой номер телефона и мои имя и отчество, последовал прямой ответ — мы выбрали ваш номер случайным образом из номерной емкости. В это объяснение я не поверил, и решил поинтересоваться тем, как устроен рынок данных и понять, кто может сливать информацию о пользователях и как легко и виртуозно интернет-монополисты обходят стороной закон «О персональных данных» (№152-ФЗ).
Читайте под катом о том, кто монетизирует мои данные и как они попадают в руки компаний, услугами которых я никогда не пользовался — банков, страховых компаний, медицинских центров, застройщиков и прочих организаций с надоедливыми рекламными звонками. И да, это лонгрид, всё как вы любите.
Весну и начало лета 2020 года наша прекрасная страна провела на самоизоляции. Помимо очевидного роста финансовой нагрузки на бизнес, необходимости людям носить повсюду маски и вынужденно работать из дома, этот временной период наглядно показал, насколько легко и просто некоторые участники рынка обращаются с персональными данными россиян.
Предыстория
К написанию этой статьи меня подтолкнуло интервью Тиграна Оганесовича Худаверяна в СМИ (TheBell, Roem) о работе сервиса Яндекса по оценке индекса самоизоляции.
Напомню кратко в чем суть: практически одновременно с объявлением режима «как бы нерабочих дней по всей стране», интернет-гигант Яндекс стал регулярно рапортовать о соблюдении мер по самоизоляции гражданами. Чиновники и СМИ ежедневно обращались к этим данным. И хотя сейчас эта тема плавно уходит на второй план, но вопросы к первоисточнику таких данных никуда не делись.
Поскольку Яндекс и ранее был замешан в скажем так вольготном отношении к пользователям — вспомним хотя бы историю слежки через приложения — то разумно предположить, что данные о текущем местоположении граждан при самоизоляции собирались с помощью мобильных приложений с геолокацией. Да и сам по себе метод слежки через умные гаджеты — очевидный. В столице, например, вообще была вопиющая история — несмотря на обилие нарушений действующего законодательства, ДИТ Москвы заставлял людей подписывать кабальный договор с другим подобным «товарищем майором».
И хотя в своем интервью управляющий директор Яндекса заявляет:
«Мы ни в чем из этого не участвуем. Признаюсь, для нас это больное место, потому что нас постоянно подозревают, что мы в этой слежке участвуем. Но у нас внутри компании есть свой принцип: ни в коем случае, даже в сложной ситуации, не нарушать принципы, которыми «Яндекс» руководствуется со дня основания»
— веры в это нет никакой. Журналисты не задали самый главный вопрос – а на основе каких данных, Яндекс формировал свой «конфиденциальный» рейтинг? Это важно, ведь свободном доступе ответа нет — интернет-гигант просто не раскрывает свою методологию:

Разумно предположить, что под термином «данные об использовании различных приложений и сервисов Яндекса» имеется ввиду именно мониторинг перемещений граждан. Вот только вряд ли кто-то из нас с вами давал прямое согласие на такую слежку.
Как устроен рынок данных
В 90-х продавали базы данных на рыночных развалах с компакт-дисками. В наше время получить список нужных контактов можно еще быстрее — даже ехать никуда не надо.
Очевидные, но нелегальные способы
Чужие данные можно поискать в соцсетях, или в специальных телеграм-каналах, названия пабликов я приводить не буду, уверен, вы и сами их найдете при желании.

Некоторые более продвинутые граждане поступают немного иначе — они размещают на своих сайтах договор-оферту, из которой следует, что данные собираются из публичных источников и даже приводят отсылки на статьи закона, которые как бы разрешают им это делать:

Нюанс только в том, что в документах на сайте «Авито» сказано, что самостоятельно парсить базу контактов интернет-площадки avito.ru прямо запрещено правилами.
Подобным образом продавцы баз в интернете собирают информацию изо всех возможных источников. Все эти методы, будем говорить прямо, незаконны, так как нарушают положения закона «О персональных данных» (№152-ФЗ). Уверен на 100%, что ни один здравомыслящий человек из вот таких баз данных не давал своего согласия на публичное распространение подобными компаниями информации о себе через интернет.
Man-in-the-middle attack
Способ слива информации через сотрудников предприятий, имеющих доступ к базе клиентов тоже очевиден. Не будем уделять слишком много внимания этому аспекту.
Единственный способ борьбы с такими людьми — контроль доступа, грамотное проектирование базы контактов и применение механизмов борьбы со фродом, которые разрабатывают сотрудники информационной безопасности. Последние, к слову, регулярно ловят «продавцов» и передают их правоохранителям.
Завуалированные способы сбора данных
Интернет-компании, скажем прямо, совсем обнаглели и придумали новую методику свободного обращения с данными пользователей. Сегодня все крупнейшие игроки этого рынка собирают про нас, бедных пользователей, такое досье, что им позавидуют Джеймс Бонд, Рихард Зорге, Мата Хари и Остин Пауэрс вместе взятые. Причем, никто из пользователей и не уполномачивал интернет-компании собирать такую фактуру.
У всех на слуху история с американскими выборами, в которых победу республиканцев обеспечил таргетинг рекламы на пользователей Google и Facebook. Причем, эти компании делились данными со сторонней организацией Сambridge Analytics, которая и формировала «целевую аудиторию» рекламных объявлений. Сбором данных промышляют и в Китае — популярная ныне соцсеть тоже недавно прославилась использованием нелегальных методов слежки, которые запрещены даже правилами Google.
Должен сказать, что российский Яндекс внимательно следит за действиями иностранных коллег, и применяет схожие методы — компания прячется за ширмой «обезличенных данных», которая, как показал мой личный опыт непрограммиста, при должной сноровке расшифровывается даже сидя дома на диване.
В декабре прошлого года на РБК появилась интересная статья, в которой рассказывалось про совместный проект Яндекса и Бюро Кредитных Историй (БКИ) по передаче данных о пользовательском поведении в сети. По задумке авторов этого решения, банки смогут получать дополнительную информацию по нужным им персонам от Яндекса, обладая при этом лишь адресом электронной почты и номером мобильного телефона клиента.
Неназванный в статье источник сообщил, что Яндекс получает данные в хэшированном виде, после чего внутренние алгоритмы определяют некую оценку для конкретного человека, и именно эта оценка и возвращается в БКИ. Все это выглядит довольно складно, однако есть нюанс — в статье приводится мнение управляющего партнера УК «Право и бизнес» Александра Пахомова, который также как и я считает, что при выполнении этой процедуры обезличенные данные вновь становятся персональными:
Как обезличенные данные становятся персональными
Попробуем разобраться в том, что происходит «под капотом» у этого сервиса. Сразу скажу, что мне сделать это сложно, так как я часто наслаждаюсь грациозностью великой и прекрасной России, а не провожу рабочие дни на митингах в переговорках современного московского офиса Яндекса. Поэтому, призываю вас поделиться информацией и подправить меня, если я ошибаюсь или в чем-то не прав.
Шаг 1. Хэширование данных
Начнем с изучения того, что именно сам Яндекс вкладывает в понятие «зашифрованные», «хэшированные» или «обезличенные» данные. И поможет нам в этом публичный сервис Яндекс.Аудитория.
Из его описания следует, что сервис позволяет рекламодателям достучаться до своих клиентов. Причем, чтобы добиться этой цели потребуется всего лишь сообщить Яндексу некие идентификаторы клиентов — номера телефонов или адреса электронной почты. Эти данные можно сгрузить в явном виде, например, в виде текстового или табличного файла. А можно — также и в обезличенном виде. Для этого применяется алгоритм хэширования MD5.
Далее сервис работает следующим образом: Яндекс вычисляет конкретного пользователя, зная его персональные данные, и показывает ему таргетированные рекламные сообщения на различных сервисах и порталах Яндекса.
Алгоритм MD5 представляет собой 128-битный алгоритм хеширования. Это значит, что он вычисляет 128-битный хеш для произвольного набора данных, поступающих на его вход.
Детальное описание алгоритма можно найти на Хабре. Нам важно знать, что он был разработан и предназначался для создания и проверки отпечатков сообщений произвольной длины — например, пользовательских паролей или контактов.
Алгоритм MD5 создали в далеком 1991 году, и до 1993 он точно считался криптостойким. Именно тогда исследователи Берт ден Боер и Антон Боссиларис предположили, что в алгоритме возможны псевдоколлизии. Дальше было проведено несколько научных работ на эту тему, которые показали возможность «взлома» MD5. Практическая же реализация была продемонстрирована в 2008 году.
Шаг 2. Расшифровка MD5-хэшей
Технически, взлом MD5 может быть осуществлен одним из четырех способов:
Возьмем, например, любой телефонный номер. Мы точно знаем, что в нем может быть фиксированное число символов, и мы точно знаем, что все эти символы — цифры от нуля до 9. Предположим, что число символов в телефонном номере не превышает 11.
Знание этих критериев позволит быстро получить искомую таблицу с помощью специального программного обеспечения. Типичное содержание такого файла будет выглядеть примерно так:
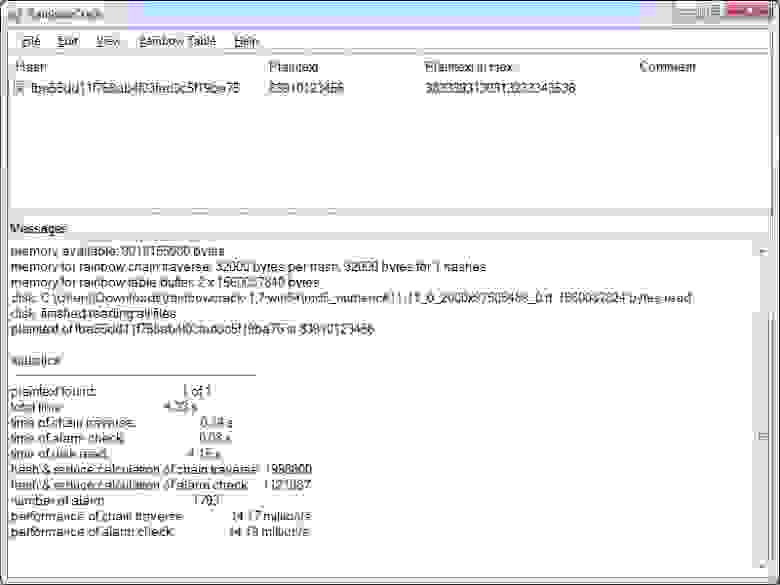
Далее, вам потребуется взять в качестве референсного значения какой-нибудь условный телефонный номер. Возьмем для примера абстрактный номер 83910123456. Его MD5 хэш будет выглядеть так — fba55dd11f758ab4f03fad3c5f19ba75.
Подставляем этот хэш в софт, указываем расположение таблицы… пара секунд, и вуаля — видим исходный телефонный номер в поле Plaintext!
С адресами электронной почты, как вы уже догадались, дело обстоит ровно так же. Единственная лишь разница в том, что для определения имени почты используется больше данных — в набор символов должны входить буквы, цифры, средства пунктуации и спецсимволы.
В приведённом примере я сознательно не использую «соль» — понятно, что подсоливание хэшей усложняет их взлом. Но об этом немного позже.
Шаг 3. Сопоставление данных
Нет ни малейших сомнений в том, что Яндекс хранит данные в зашифрованном виде. Условно говоря, у поисковика есть профиль каждого зарегистрированного пользователя, где помимо прочего указаны адреса его электронной почты и номер телефона. Такие данные легко хэшируются и, при необходимости (как мы уже убедились выше) — дехешируются.
Далее, получив от рекламодателей в любом виде список контактов, Яндексу не составляет труда сопоставить их со своей внутренней базой, которая содержит эти же идентификаторы. Говоря проще, Яндекс делает кросс-матчинг идентификатора из профиля своего пользователя на соответствие запрашиваемым данным рекламодателя. Это и позволяет таргетированно показывать рекламу конкретному пользователю при заходе на страницу того или иного сервиса Яндекса.
Однозначная идентификация пользователей
Ни о каком обезличенном обмене данными при работе по такой схеме и речи идти не может. Все стороны однозначно идентифицируют конкретного пользователя в процессе оказания услуг. С кредитными бюро, судя по комментариям и описанию, применяется ровно эта же схема. И по всей видимости, на стороне Яндекса используется решение, подозрительно похожее на платформу Крипта.
Однако Яндекс публично никогда не заявлял о возможности сопоставления таких профилей с номерами мобильных телефонов или e-mail своих пользователей. Но, как нам стало известно из материалов СМИ, Яндекс именно это и делает как минимум при работе с Объединенным Кредитным Бюро.
Почему об этом честно не сказать своим клиентам, ведь все и так лежит на поверхности? Вместо этого спикеры Яндекса стыдливо говорят об отсутствии “личной информации» и приводят прочие выдуманные термины, которые отсутствуют в законодательстве РФ и позволяют обойти некоторые вопросы оборота и защиты данных граждан.
Немного практики: Яндекс, я нашел у тебя нарушение 152-ФЗ!
Солит ли Яндекс хэши? Я не могу однозначно ответить на этот вопрос, в конце концов, я не работаю в этой компании и не знаю внутренней кухни. Однако я могу сделать два допущения:
Обратите внимание на вопросительный знак у чекбокса «Хэшированные данные». Давайте перейдем в сам сервис и подведем указатель мыши к этому вопросу.

Видим три хэша: a31259d185ad013e0a663437c60b5d0, 78ee6d68f49d2c90397d9fbffc3814d1 и 702e8494aeb560dff987e623e71bccf8. Причем, в первом явно чего-то не хватает: там всего 31 символ, а должно быть 32! Поэтому, этот хэш отбросим сразу.
Расшифровать вторые два хэша через ранее созданную радужную таблицу я тоже не смог. Но решил попробовать пройтись по ним брутфорсом. Для этого мне потребовалось перенастроить майнинг-ферму из 6 видеокарт класса GeForce GTX1060 с добычи эфира на работу с программой hashcat.

Я указал программе поиск по маске из 11 цифр (см на верхнюю стрелку на скриншоте). В результате, моя вполне обычная ферма произвела дехэширование номера телефона в одном из хэшей всего за 22 секунды. Просто представьте, с какой скоростью можно брутфорсить хэши на мощностях Яндекса!
Теперь давайте определим кому принадлежит этот номер, просто пробьем его через мобильное приложение Numbuster:

Теперь идем в поисковик, и за считанные мгновения получаем всю нужную нам информацию:
Шах и мат, Яндекс, благодаря открытой информации с твоего же сайта, я только что в пару кликов мышью узнал, кто именно делал твой сервис! Надо ли говорить, что такое же действие может легко повторить любой из тех, кто сейчас читает эту статью? За что же вы так с Ярославом-то поступили?
Какие данные могут быть в профиле каждого пользователя
Для использования сервисов Яндекса необходимо указать номер мобильного телефона и электронной почты. Через свои приложения и сервисы Яндекс знает обо мне практически все: от сайтов, которые я посещаю (где стоит Яндекс.Метрика, а таковых в Рунете более 54%), до номера телефона, который я указываю в приложениях. Ему известны мои маршруты из супераппа Яндекс.Go, мои заболевания, предпочтения в музыке. Яндекс знает, в какие театры я хожу, какие фильмы смотрю, какие товары покупаю в магазине и какую еду заказываю.
Эта информация, как утверждают в компании, «используется, в основном, для собственных нужд и размещения таргетированной рекламы за счет знаний о клиентских предпочтениях». Ключевое здесь – «в основном». Раньше считалось, что Яндекс – инновационная компания, которая предоставляет пользователям бесплатные сервисы и зарабатывает на рекламе в Интернете. Но как мы знаем из СМИ, теперь Яндекс как минимум продает данные через Бюро Кредитных Историй — работу самого механизма трансфера данных я покажу чуть ниже. Разумно предположить, что желающих купить у интернет-гиганта информацию о пользователях в привязке к номерам телефонов и адресам электронной почты, будет довольно много.
Другими словами — теперь банки, страховые и юридические компании, медицинские центры, застройщики могут получить номер человека, который заходил на определенный сайт или искал определенный товар, и звонить ему в своих рекламных целях. Или отказать в выдаче страховки или банковского кредита.
Кому Бюро Кредитных Историй продает данные
Не требуется быть особым аналитиком, чтобы понять, что БКИ консолидирует данные о конкретных людях не только для банков. На сайте той структуры, с которой работает Яндекс, можно увидеть, что кроме банковского скоринга клиентам также доступны и другие сервисы:
Сервис «Триггеры Бюро»
В Банки и Страховые компании передается информация о ваших действиях в триггерном режиме:
Обратите внимание на логику работы этого сервиса — вы ставите на мониторинг номера телефонов ваших клиентов, и как только они делают какое-либо действие, которое вас интересует, вы получаете об этом уведомление. При этом данные о конкретных действиях клиента не передаются. Просто факт целевого действия – подача или оформление полиса автострахования, заказ такси и прочее.
Удобно, правда? Особенно с точки зрения объяснения позиции «данные о клиентах не передаются и обрабатываются в Яндексе»? Ведь информацию о действии в виде захода на конкретный web-сайт, можно сообщить, просто передав захэшированный мобильный номер, без каких-либо данных о посещении сайта. А хэш, о чем я говорил выше, можно элементарно сопоставить с хэшами базы пользователей. Можно даже, для упрощения, взять базу всех возможных комбинаций мобильных номеров в России — она доступна на сайте Федерального агентства связи.
Опять получается, что «зашифрованные», «хэшированные», «обезличенные» данные в терминах Яндекса таковыми не очень-то и являются. И уж точно описанная Яндексом схема не мешает продавать эти данные в рамках рассмотренных сервисов кредитных бюро, которые как раз и могут быть тем самым источником спам-звонков на мой телефон.
Страховые компании, получив доступ к данным из картографических сервисов Яндекса и его шедеврального супераппа Яндекс.Go, могут определять:
Законом о GDPR воспользовались журналисты издания Meduza, которые из Литвы запросили данные по одному из своих сотрудников.
В статье Meduza говорится, что журналист получил от сотрудников Яндекса архив, в котором помимо прочего был файл со всей историей перемещений. Информация отслеживалась в тот момент, когда приложение было запущено на смартфоне, в том числе в фоновом режиме. Журналист это называет «историей запуска приложения «Карт» на айфоне с точными координатами, где это происходило» (файл traffic_sessions.csv).
Интересно, что гражданам РФ такая информация компанией Яндекс не предоставляется. Более того, до сего момента Яндекса даже не представил сервис, который позволил бы понять, кто и когда запрашивал накопленные данные о пользователе. Такой сервис есть даже у Facebook — и сам пользователь может запросить и просмотреть всю информацию о себе.
Какую персональную информацию точно собирает Яндекс?
Обратимся к правовым документам на сайте Яндекса. Из пункта 4 мы узнаем, что интернет-гигант может собирать следующие категории персональной информации пользователей во время использования сайтов и сервисов Яндекса:
С какой целью Яндекс собирает все эти данные?
Ответ на этот вопрос можно найти в том же документе, внимательно смотрим пункт №5. Помимо понятных целей, таких как:
предоставление пользователям результатов поиска по поисковым запросам;
соблюдения установленных законодательством обязательств;
чтобы лучше понимать, как пользователи взаимодействуют с сайтами и сервисами,
Яндекс отдельно отмечает, что сбор персональных данных необходим для того, чтобы чтобы предлагать вам другие продукты и сервисы Яндекса или других компаний, которые, по нашему мнению, могут Вас заинтересовать (подпункт пункт «с» пункта 5).
Однако закон «О персональных данных» (№152-ФЗ) категоричен: статья 15 гласит, что «обработка персональных данных в целях продвижения товаров, работ, услуг на рынке путем осуществления прямых контактов с потенциальным потребителем допускается только при условии предварительного согласия субъекта персональных данных». На стороне пользователей контролирующие органы – ФАС, Роспотребнадзор и Роскомнадзор.
При этом интернет-гигант свободно передает другим компаниям базы данных с якобы обезличенными персональными идентификаторами, которые по мнению интернет-гиганта перестали быть персональными данными. И Яндекс обеспечил себе это право «делиться» за счет малозаметной строчки во внушительном тексте собственной политики конфиденциальности.
Вместо заключения
Законно ли всё это? Ведь я не давал права Яндексу разглашать информацию обо мне кому-либо. Знакомые юристы говорят, интернет-данные и интернет идентификаторы – это «серое» поле нашего законодательства и привлечь Яндекс к ответственности за продажу таких данных о вас невозможно.
И насколько справедливо, что Яндекс зарабатывает на моих данных, не объясняя мне как именно это происходит и за счет чего формируется этот заработок, ведь это уже давно не только пресловутая реклама утюгов, которая после поиска «утюга» догоняет тебя еще 2 недели на всех сайтах. Это и прямое влияние на качество моей жизни и доступность социальных сервисов и услуг – таких как кредитование, страховки, медицинская помощь.
Согласитесь, оценка меня как заемщика или страхователя на основе информации о моем поведении в интернете, которая к тому же происходит «в темную» и опирается только на завуалированные термины и оферты, скрытые в подвалах – выглядит абсолютно неэтично и непрозрачно. Это очень напрягает.
Несмотря на GDPR и ужесточение законов по использованию персональных данных граждан в России, интернет-гигант продолжает монетизировать информацию о нас и абсолютно открыто следит за всеми нашими действиями через свои сервисы. Пусть даже и прикрываясь социально важной темой информирования населения и властей о соблюдении режима изоляции, как в случае с коронавирусом. Возникает разумный вопрос – а кто ещё использует наши данные помимо Яндекса и его коммерческих клиентов?



