Модели машинного обучения: объясняем пятилетнему ребенку
Продолжаем нашу постоянную рубрику #чтопочитать
Специалисты компании Sociaro подготовили перевод очередной статьи, которая поможет разобраться в том, что такое Машинное обучение.
Если вы новичок в data science, заголовок не был направлен на то, чтобы вас обидеть. Это мой второй пост на тему популярного вопроса на интервью, который звучит примерно так: «объясните мне [вставить техническую тему], как вы бы объяснили пятилетнему ребенку.»
Выходит, достичь уровня понимания пятилетнего ребенка довольно сложно. Так что, хоть эта статья может быть не совсем ясна детсадовцу, она будет понятна тому, кто практически не имеет опыта в data science (и если вы поймете, что это не так, пожалуйста, напишите об этом в комментариях).
Я начну с объяснения понятия машинного обучения, а также его различных типов, а затем перейду к объяснению простых моделей. Я не буду особо вдаваться в математику, но подумываю сделать это в своих будущих статьях. Наслаждайтесь!
Illustration of Machine Learning
Машинное обучение – это когда вы загружаете большое количество данных в компьютерную программу и выбираете модель, которая «подгонит» эти данные так, чтобы компьютер (без вашей помощи) мог придумывать прогнозы. Компьютер строит модели, используя алгоритмы, которые варьируются от простых уравнений (например, уравнение прямой) до очень сложных систем логики/математики, которые позволяют компьютеру сделать самые лучшие прогнозы.
Обучение с учителем — это тип машинного обучения, в котором данные, которые вы засовываете в модель «помечаются». Пометка просто означает, что результат наблюдения (то есть ряд данных) известен. Например, если ваша модель пытается предсказать пойдут ли ваши друзья играть в гольф или нет, у вас могут быть такие переменные, как погода, день недели и так далее. Если ваши данные помечены, то ваша переменная будет иметь значение 1, в том случае если ваши друзья пошли играть в гольф, и значение 0, если они не пошли.
Как вы наверно могли угадать, когда речь идет о помеченных данных, обучение без учителя является противоположностью обучения с учителем. В обучении без учителя, вы не можете знать пошли ваши друзья играть в гольф или нет – только компьютер может найти закономерности с помощью модели, чтобы угадать, что уже произошло или предсказать, что произойдет.
[Требуется присутствие взрослых]
Логистическая регрессия используется для решения проблемы классификации. Это значит, что ваша целевая переменная (та которую вы хотите предсказать) состоит из категорий. Эти категории могут быть да/нет, или что-то вроде числа от 1 до 10, которое обозначает удовлетворенность клиента. Модель логистической регрессии использует уравнение, чтобы создать кривую с вашими данными, а затем использует эту кривую, чтобы спрогнозировать результаты нового наблюдения.
На графике выше, новое наблюдение получило бы в прогнозе 0, потому что оно попадает на левую часть кривой. Если посмотреть на данные, по которым построена кривая, это логично, потому что в области графика «прогнозируемое значение 0» большинство точек по оси y имеют значение 0.
Довольно часто линейная регрессия становится первой моделью машинного обучения, которую люди изучают. Связано это с тем, что ее алгоритм (проще говоря уравнение) достаточно просто понять, используя только одну переменную x – вы просто-напросто рисуете наиболее подходящую линию – концепция, которой учат еще в начальной школе. Наиболее подходящая линия затем используется для прогнозирования новых точек данных (см. иллюстрацию).
Линейная Регрессия чем-то напоминает логистическую регрессию, но используется, когда целевая переменная – непрерывная, а это значит, что она может принимать практически любое числовое значение. На самом деле, любая модель с непрерывной целевой переменной может быть классифицирована как «регрессия». Примером непрерывной переменной может служить цена продажи дома.
Принцип работы опорных векторов заключается в том, что они устанавливают границы между точками данных, где большинство из одного класса падает на одну сторону границы (как пример, в двумерном пространстве это будет линия) и большинство из другого класса падает на другую сторону границы.
Способ работы также заключается в том, что машина стремится найти границу с наибольшим пределом. Предел определяется расстоянием между границей и ближайшими точками каждого класса (см. иллюстрацию). Новые точки данных затем строятся и помещаются в определенный класс, в зависимости от того, на какую сторону границы они попадают.
Я объясняю эту модель на примере классификации, но вы также можете ее использовать для регрессии!
Про это я уже рассказывала в предыдущей статья, вы можете найти ее здесь (Деревья Решений и Случайные Леса ближе к концу):
[Читайте с осторожностью]
Теперь мы готовы перейти к машинному обучению без учителя. Напомню, это значит, что наш датасет не помеченный, так что мы не знаем результаты наших наблюдений.
Когда вы используете K кластеризацию, вы должны начать с предположения, что в вашем датасете присутствует K кластеров. Поскольку вы не знаете, сколько групп на самом деле в ваших данных, вы должны попробовать различные значения K и с помощью визуализации и метрик понять, какое значение K подходит. Метод K средних лучше всего работает с круговыми кластерами одинаковых размеров.
Этот алгоритм сначала выбирает лучшие точки данных K, чтобы сформировать центр каждого K кластера. Затем, он повторяет 2 следующих шага для каждой точки:
1. Присваивает точку данных ближайшему центру кластера
2. Создает новый центр, взяв среднее значение всех точек данных из этого кластера
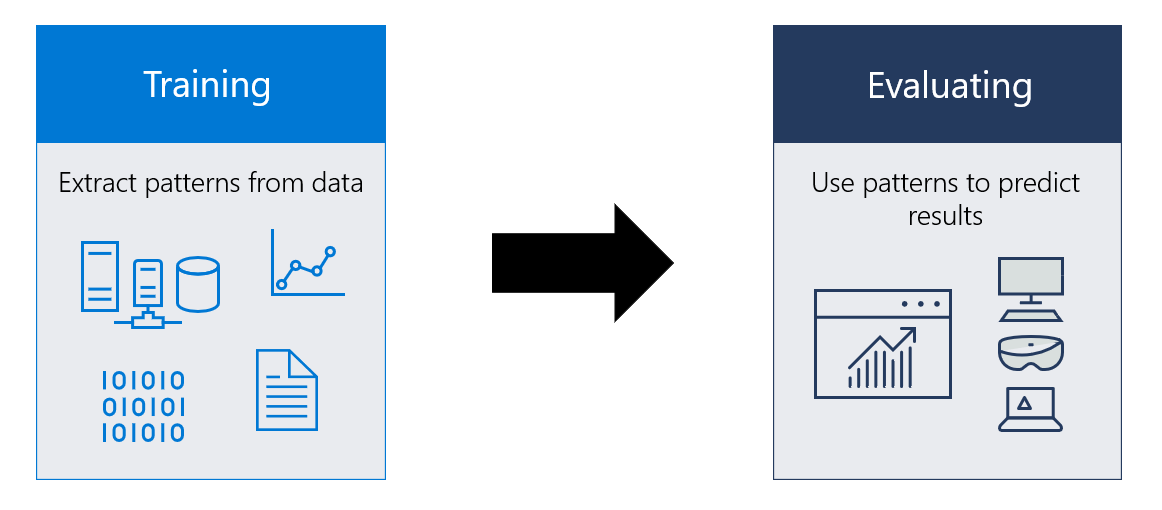
Что такое модель машинного обучения?
Моделью машинного обучения называется файл, который обучен распознаванию определенных типов закономерностей. Вы обучаете модель на основе набора данных, предоставляя ей алгоритм, который она может использовать для анализа и обучения на основе этих данных.
Завершив обучение модели, вы сможете применить ее для принятия решений и выполнения прогнозов по данным, которые ранее не встречались. Предположим, вам нужно создать приложение для распознавания эмоций пользователя по его выражению лица. Вы можете обучить модель по набору изображений лиц, каждое из которых отмечено тегом определенной эмоции, а затем применить эту модель в приложении для распознавания эмоций пользователя. Примером такого приложения служит Emoji8.
Когда использовать Машинное обучение
Продуманные сценарии машинного обучения обычно имеют следующие общие свойства:
Windows Machine Learning использует для своих моделей формат ONNX (Open Neural Network Exchange). Вы можете скачать предварительно обученную модель или обучить собственную. Дополнительные сведения о получении моделей ONNX для Windows ML см. в этой статье.
Начало работы
Вы можете начать работу с Windows Machine Learning, пройдя один из наших учебников или сразу перейдя к примерам Windows Machine Learning.
Используйте следующие ресурсы для получения справки по машинному обучению в Windows:
Введение в машинное обучение
1.1 Введение
Благодаря машинному обучению программист не обязан писать инструкции, учитывающие все возможные проблемы и содержащие все решения. Вместо этого в компьютер (или отдельную программу) закладывают алгоритм самостоятельного нахождения решений путём комплексного использования статистических данных, из которых выводятся закономерности и на основе которых делаются прогнозы.
Технология машинного обучения на основе анализа данных берёт начало в 1950 году, когда начали разрабатывать первые программы для игры в шашки. За прошедшие десятилетий общий принцип не изменился. Зато благодаря взрывному росту вычислительных мощностей компьютеров многократно усложнились закономерности и прогнозы, создаваемые ими, и расширился круг проблем и задач, решаемых с использованием машинного обучения.
Чтобы запустить процесс машинного обучение, для начала необходимо загрузить в компьютер Датасет(некоторое количество исходных данных), на которых алгоритм будет учиться обрабатывать запросы. Например, могут быть фотографии собак и котов, на которых уже есть метки, обозначающие к кому они относятся. После процесса обучения, программа уже сама сможет распознавать собак и котов на новых изображениях без содержания меток. Процесс обучения продолжается и после выданных прогнозов, чем больше данных мы проанализировали программой, тем более точно она распознает нужные изображения.
Благодаря машинному обучению компьютеры учатся распознавать на фотографиях и рисунках не только лица, но и пейзажи, предметы, текст и цифры. Что касается текста, то и здесь не обойтись без машинного обучения: функция проверки грамматики сейчас присутствует в любом текстовом редакторе и даже в телефонах. Причем учитывается не только написание слов, но и контекст, оттенки смысла и другие тонкие лингвистические аспекты. Более того, уже существует программное обеспечение, способное без участия человека писать новостные статьи (на тему экономики и, к примеру, спорта).
1.2 Типы задач машинного обучения
Все задачи, решаемые с помощью ML, относятся к одной из следующих категорий.
1)Задача регрессии – прогноз на основе выборки объектов с различными признаками. На выходе должно получиться вещественное число (2, 35, 76.454 и др.), к примеру цена квартиры, стоимость ценной бумаги по прошествии полугода, ожидаемый доход магазина на следующий месяц, качество вина при слепом тестировании.
2)Задача классификации – получение категориального ответа на основе набора признаков. Имеет конечное количество ответов (как правило, в формате «да» или «нет»): есть ли на фотографии кот, является ли изображение человеческим лицом, болен ли пациент раком.
3)Задача кластеризации – распределение данных на группы: разделение всех клиентов мобильного оператора по уровню платёжеспособности, отнесение космических объектов к той или иной категории (планета, звёзда, чёрная дыра и т. п.).
4)Задача уменьшения размерности – сведение большого числа признаков к меньшему (обычно 2–3) для удобства их последующей визуализации (например, сжатие данных).
5)Задача выявления аномалий – отделение аномалий от стандартных случаев. На первый взгляд она совпадает с задачей классификации, но есть одно существенное отличие: аномалии – явление редкое, и обучающих примеров, на которых можно натаскать машинно обучающуюся модель на выявление таких объектов, либо исчезающе мало, либо просто нет, поэтому методы классификации здесь не работают. На практике такой задачей является, например, выявление мошеннических действий с банковскими картами.
1.3 Основные виды машинного обучения
Основная масса задач, решаемых при помощи методов машинного обучения, относится к двум разным видам: обучение с учителем (supervised learning) либо без него (unsupervised learning). Однако этим учителем вовсе не обязательно является сам программист, который стоит над компьютером и контролирует каждое действие в программе. «Учитель» в терминах машинного обучения – это само вмешательство человека в процесс обработки информации. В обоих видах обучения машине предоставляются исходные данные, которые ей предстоит проанализировать и найти закономерности. Различие лишь в том, что при обучении с учителем есть ряд гипотез, которые необходимо опровергнуть или подтвердить. Эту разницу легко понять на примерах.
Машинное обучение с учителем
Предположим, в нашем распоряжении оказались сведения о десяти тысячах московских квартир: площадь, этаж, район, наличие или отсутствие парковки у дома, расстояние от метро, цена квартиры и т. п. Нам необходимо создать модель, предсказывающую рыночную стоимость квартиры по её параметрам. Это идеальный пример машинного обучения с учителем: у нас есть исходные данные (количество квартир и их свойства, которые называются признаками) и готовый ответ по каждой из квартир – её стоимость. Программе предстоит решить задачу регрессии.
Ещё пример из практики: подтвердить или опровергнуть наличие рака у пациента, зная все его медицинские показатели. Выяснить, является ли входящее письмо спамом, проанализировав его текст. Это всё задачи на классификацию.
Машинное обучение без учителя
В случае обучения без учителя, когда готовых «правильных ответов» системе не предоставлено, всё обстоит ещё интереснее. Например, у нас есть информация о весе и росте какого-то количества людей, и эти данные нужно распределить по трём группам, для каждой из которых предстоит пошить рубашки подходящих размеров. Это задача кластеризации. В этом случае предстоит разделить все данные на 3 кластера (но, как правило, такого строгого и единственно возможного деления нет).
Если взять другую ситуацию, когда каждый из объектов в выборке обладает сотней различных признаков, то основной трудностью будет графическое отображение такой выборки. Поэтому количество признаков уменьшают до двух или трёх, и становится возможным визуализировать их на плоскости или в 3D. Это – задача уменьшения размерности.
1.4 Основные алгоритмы моделей машинного обучения
1. Дерево принятия решений
Это метод поддержки принятия решений, основанный на использовании древовидного графа: модели принятия решений, которая учитывает их потенциальные последствия (с расчётом вероятности наступления того или иного события), эффективность, ресурсозатратность.
Для бизнес-процессов это дерево складывается из минимального числа вопросов, предполагающих однозначный ответ — «да» или «нет». Последовательно дав ответы на все эти вопросы, мы приходим к правильному выбору. Методологические преимущества дерева принятия решений – в том, что оно структурирует и систематизирует проблему, а итоговое решение принимается на основе логических выводов.
2. Наивная байесовская классификация
Наивные байесовские классификаторы относятся к семейству простых вероятностных классификаторов и берут начало из теоремы Байеса, которая применительно к данному случаю рассматривает функции как независимые (это называется строгим, или наивным, предположением). На практике используется в следующих областях машинного обучения:
Всем, кто хоть немного изучал статистику, знакомо понятие линейной регрессии. К вариантам её реализации относятся и наименьшие квадраты. Обычно с помощью линейной регрессии решают задачи по подгонке прямой, которая проходит через множество точек. Вот как это делается с помощью метода наименьших квадратов: провести прямую, измерить расстояние от неё до каждой из точек (точки и линию соединяют вертикальными отрезками), получившуюся сумму перенести наверх. В результате та кривая, в которой сумма расстояний будет наименьшей, и есть искомая (эта линия пройдёт через точки с нормально распределённым отклонением от истинного значения).
Линейная функция обычно используется при подборе данных для машинного обучения, а метод наименьших квадратов – для сведения к минимуму погрешностей путем создания метрики ошибок.
4. Логистическая регрессия
Логистическая регрессия – это способ определения зависимости между переменными, одна из которых категориально зависима, а другие независимы. Для этого применяется логистическая функция (аккумулятивное логистическое распределение). Практическое значение логистической регрессии заключается в том, что она является мощным статистическим методом предсказания событий, который включает в себя одну или несколько независимых переменных. Это востребовано в следующих ситуациях:
Это целый набор алгоритмов, необходимых для решения задач на классификацию и регрессионный анализ. Исходя из того что объект, находящийся в N-мерном пространстве, относится к одному из двух классов, метод опорных векторов строит гиперплоскость с мерностью (N – 1), чтобы все объекты оказались в одной из двух групп. На бумаге это можно изобразить так: есть точки двух разных видов, и их можно линейно разделить. Кроме сепарации точек, данный метод генерирует гиперплоскость таким образом, чтобы она была максимально удалена от самой близкой точки каждой группы.
SVM и его модификации помогают решать такие сложные задачи машинного обучения, как сплайсинг ДНК, определение пола человека по фотографии, вывод рекламных баннеров на сайты.
Он базируется на алгоритмах машинного обучения, генерирующих множество классификаторов и разделяющих все объекты из вновь поступающих данных на основе их усреднения или итогов голосования. Изначально метод ансамблей был частным случаем байесовского усреднения, но затем усложнился и оброс дополнительными алгоритмами:
Кластеризация заключается в распределении множества объектов по категориям так, чтобы в каждой категории – кластере – оказались наиболее схожие между собой элементы.
Кластеризировать объекты можно по разным алгоритмам. Чаще всего используют следующие:
8. Метод главных компонент (PCA)
Метод главных компонент, или PCA, представляет собой статистическую операцию по ортогональному преобразованию, которая имеет своей целью перевод наблюдений за переменными, которые могут быть как-то взаимосвязаны между собой, в набор главных компонент – значений, которые линейно не коррелированы.
Практические задачи, в которых применяется PCA, – визуализация и большинство процедур сжатия, упрощения, минимизации данных для того, чтобы облегчить процесс обучения. Однако метод главных компонент не годится для ситуаций, когда исходные данные слабо упорядочены (то есть все компоненты метода характеризуются высокой дисперсией). Так что его применимость определяется тем, насколько хорошо изучена и описана предметная область.
9. Сингулярное разложение
В линейной алгебре сингулярное разложение, или SVD, определяется как разложение прямоугольной матрицы, состоящей из комплексных или вещественных чисел. Так, матрицу M размерностью [m*n] можно разложить таким образом, что M = UΣV, где U и V будут унитарными матрицами, а Σ – диагональной.
Одним из частных случаев сингулярного разложения является метод главных компонент. Самые первые технологии компьютерного зрения разрабатывались на основе SVD и PCA и работали следующим образом: вначале лица (или другие паттерны, которые предстояло найти) представляли в виде суммы базисных компонент, затем уменьшали их размерность, после чего производили их сопоставление с изображениями из выборки. Современные алгоритмы сингулярного разложения в машинном обучении, конечно, значительно сложнее и изощрённее, чем их предшественники, но суть их в целом нем изменилась.
10. Анализ независимых компонент (ICA)
Это один из статистических методов, который выявляет скрытые факторы, оказывающие влияние на случайные величины, сигналы и пр. ICA формирует порождающую модель для баз многофакторных данных. Переменные в модели содержат некоторые скрытые переменные, причем нет никакой информации о правилах их смешивания. Эти скрытые переменные являются независимыми компонентами выборки и считаются негауссовскими сигналами.
В отличие от анализа главных компонент, который связан с данным методом, анализ независимых компонент более эффективен, особенно в тех случаях, когда классические подходы оказываются бессильны. Он обнаруживает скрытые причины явлений и благодаря этому нашёл широкое применение в самых различных областях – от астрономии и медицины до распознавания речи, автоматического тестирования и анализа динамики финансовых показателей.
1.5 Примеры применения в реальной жизни
Пример 1. Диагностика заболеваний
Пациенты в данном случае являются объектами, а признаками – все наблюдающиеся у них симптомы, анамнез, результаты анализов, уже предпринятые лечебные меры (фактически вся история болезни, формализованная и разбитая на отдельные критерии). Некоторые признаки – пол, наличие или отсутствие головной боли, кашля, сыпи и иные – рассматриваются как бинарные. Оценка тяжести состояния (крайне тяжёлое, средней тяжести и др.) является порядковым признаком, а многие другие – количественными: объём лекарственного препарата, уровень гемоглобина в крови, показатели артериального давления и пульса, возраст, вес. Собрав информацию о состоянии пациента, содержащую много таких признаков, можно загрузить её в компьютер и с помощью программы, способной к машинному обучению, решить следующие задачи:
Пример 2. Поиск мест залегания полезных ископаемых
В роли признаков здесь выступают сведения, добытые при помощи геологической разведки: наличие на территории местности каких-либо пород (и это будет признаком бинарного типа), их физические и химические свойства (которые раскладываются на ряд количественных и качественных признаков).
Для обучающей выборки берутся 2 вида прецедентов: районы, где точно присутствуют месторождения полезных ископаемых, и районы с похожими характеристиками, где эти ископаемые не были обнаружены. Но добыча редких полезных ископаемых имеет свою специфику: во многих случаях количество признаков значительно превышает число объектов, и методы традиционной статистики плохо подходят для таких ситуаций. Поэтому при машинном обучении акцент делается на обнаружение закономерностей в уже собранном массиве данных. Для этого определяются небольшие и наиболее информативные совокупности признаков, которые максимально показательны для ответа на вопрос исследования – есть в указанной местности то или иное ископаемое или нет. Можно провести аналогию с медициной: у месторождений тоже можно выявить свои синдромы. Ценность применения машинного обучения в этой области заключается в том, что полученные результаты не только носят практический характер, но и представляют серьёзный научный интерес для геологов и геофизиков.
Пример 3. Оценка надёжности и платёжеспособности кандидатов на получение кредитов
С этой задачей ежедневно сталкиваются все банки, занимающиеся выдачей кредитов. Необходимость в автоматизации этого процесса назрела давно, ещё в 1960–1970-е годы, когда в США и других странах начался бум кредитных карт.
Лица, запрашивающие у банка заём, – это объекты, а вот признаки будут отличаться в зависимости от того, физическое это лицо или юридическое. Признаковое описание частного лица, претендующего на кредит, формируется на основе данных анкеты, которую оно заполняет. Затем анкета дополняется некоторыми другими сведениями о потенциальном клиенте, которые банк получает по своим каналам. Часть из них относятся к бинарным признакам (пол, наличие телефонного номера), другие — к порядковым (образование, должность), большинство же являются количественными (величина займа, общая сумма задолженностей по другим банкам, возраст, количество членов семьи, доход, трудовой стаж) или номинальными (имя, название фирмы-работодателя, профессия, адрес).
Для машинного обучения составляется выборка, в которую входят кредитополучатели, чья кредитная история известна. Все заёмщики делятся на классы, в простейшем случае их 2 – «хорошие» заёмщики и «плохие», и положительное решение о выдаче кредита принимается только в пользу «хороших».
Более сложный алгоритм машинного обучения, называемый кредитным скорингом, предусматривает начисление каждому заёмщику условных баллов за каждый признак, и решение о предоставлении кредита будет зависеть от суммы набранных баллов. Во время машинного обучения системы кредитного скоринга вначале назначают некоторое количество баллов каждому признаку, а затем определяют условия выдачи займа (срок, процентную ставку и остальные параметры, которые отражаются в кредитном договоре). Но существует также и другой алгоритм обучения системы – на основе прецедентов.
Все модели машинного обучения за 5 минут
Mar 6, 2020 · 5 min read


Фундаментальная сегментация моделей машинного обучения
Все модели машинного обучения разделяются на обучение с учителем (supervised) и без учителя (unsupervised). В первую категорию входят регрессионная и классификационная модели. Рассмотрим значения этих терминов и входящие в эти категории модели.
Обучение с учителем
Представляет собой изучение функции, которая преобразует входные данные в выходные на основе примеров пар ввода-вывода.
Например, из набора данных с двумя переменными: возраст (входные данные) и рост (выходные данные), можно реализовать модель обучения для прогнозирования роста человека на основе его возраста.

Пример обучения с учителем
Повторюсь, обучение с учителем подразделяется на две подкатегории: регрессия и классификация.
Регрессия
В регре с сионных моделях вывод является непрерывным. Ниже приведены некоторые из наиболее распространенных типов регрессионных моделей.
Линейная регрессия

Пример линейной регрессии
Задача линейной регрессии заключается в нахождении линии, которая наилучшим образом соответствует данным. Расширения линейной регрессии включают множественную линейную регрессию (например, поиск наиболее подходящей плоскости) и полиномиальную регрессию (например, поиск наиболее подходящей кривой).
Дерево решений
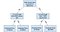
Изображение из Kaggle
Дерево решений — популярная модель, используемая в исследовании операций, стратегическом планировании и машинном обучении. Каждый прямоугольник выше называется узлом. Чем больше узлов, тем более точным будет дерево решений. Последние узлы, в которых принимается решение, называются листьями дерева. Деревья решений интуитивны и просты в создании, однако не предоставляют точные результаты.
Случайный лес
Случайный лес — это техника ансамбля методов, основанная на деревьях решений. Случайные леса включают создание нескольких деревьев решений с использованием первоначальных наборов данных и случайный выбор поднабора переменных на каждом этапе. Затем модель выбирает моду (значение, которое встречается чаще других) из всех прогнозов каждого дерева решений. Какой в этом смысл? Модель “победы большинства” снижает риск ошибки отдельного дерева.

Например, у нас есть одно дерево решений (третье), которое предсказывает 0. Однако если полагаться на моду всех 4 деревьев, прогнозируемое значение будет равно 1. В этом заключается преимущество случайных лесов.
Нейронная сеть

Визуальное представление нейронной сети
Нейронная сеть — это многослойная модель, устроенная по системе человеческого мозга. Как и нейроны в нашем мозге, круги выше представляют узлы. Синим обозначен слой входных данных, черным — скрытые слои, а зеленым — слой выходных данных. Каждый узел в скрытых слоях представляет функцию, через которую проходят входные данные, приводящие к выходу в зеленых кругах.
Классификация
В классификационных моделях вывод является дискретным. Ниже приведены некоторые из наиболее распространенных типов классификационных моделей.
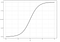
Логистическая регрессия
Логистическая регрессия аналогична линейной регрессии, но используется для моделирования вероятности ограниченного числа результатов, обычно двух. Логистическое уравнение создается таким образом, что выходные значения могут находиться только между 0 и 1:
Метод опорных векторов
Метод опорных векторов — это классификационный метод обучения с учителем, довольно сложный, но достаточно интуитивный на базовом уровне.
Предположим, что существует два класса данных. Метод опорных векторов находит гиперплоскость или границу между двумя классами данных, которая максимизирует разницу между двумя классами. Есть множество плоскостей, которые могут разделить два класса, но только одна из них максимизирует разницу или расстояние между классами.

Наивный Байес
Наивный Байес — еще один популярный классификатор, используемый в науке о данных. Его идея лежит в основе теоремы Байеса:

Несмотря на ряд нереалистичных предположений, сделанных в отношении наивного Байеса (отсюда и название “наивный”), он не только доказал свою эффективность в большинстве случаев, но и относительно прост в построении.
Обучение без учителя

В отличие от обучения с учителем, обучение без учителя используется для того, чтобы сделать выводы и найти шаблоны из входных данных без отсылок на помеченные результаты. Два основных метода, используемых в обучении без учителя, включают кластеризацию и снижение размерности.
Кластеризация

Кластеризация — это техника обучения без учителя, которая включает в себя группирование или кластеризацию точек данных. Чаще всего она используется для сегментации потребителей, выявления мошенничества и классификации документов.
Распространенные методы кластеризации включают кластеризацию с помощью k-средних, иерархическую кластеризацию, сдвиг среднего значения и кластеризацию на основе плотности. У каждого из них есть свой способ поиска кластеров, однако все они предназначены для достижения одного результата.
Понижение размерности
Снижение размерности — это процесс уменьшения числа рассматриваемых случайных переменных путем получения набора главных переменных. Проще говоря, это процесс уменьшения размера набора признаков (уменьшение количества признаков). Большинство методов снижения размерности могут быть классифицированы как отбор или извлечение признаков.
Популярный метод понижения размерности называется методом главных компонент (PCA). Он представляет собой проецирование многомерных данных (например, 3 измерения) в меньшее пространство (например, 2 измерения). Это приводит к уменьшению размерности данных (2 измерения вместо 3) при сохранении всех исходных переменных в модели.



