Материалы 2-ой Всероссийской конференции «Теория и практика речевых исследований»
В настоящее время применяется множество алгоритмов сжатия речи. Все они могут быть реализованы как аппаратнными, так и программными методами. Условно все алгоритмы можно разделить на три вида: — усовершенствованные виды импульсно-кодовой модуляции (ИКМ, Pulse-Code Modulation PCM); — вокодеры (от англ. Voice и Coder); — липредеры (от англ. Linear и Predictor). Для оценки характера вносимых в речевой сигнал изменений и потерь рассмотрим принципы построения различных методов сжатия.
1. Усовершенствованные виды ИКМ.
Параметры ИКМ при оцифровке речевых сигналов описаны в рекомендациях МККТТ (Международный консультативный комитет по телефонии и телеграфии, CCITT) и, как правило, имеют следующие значения: — частота дискретизации 8000 Гц; — число двоичных разрядов на отсчет 8; — скорость передачи 64000 бит/c.
При этом может быть оцифрован и восстановлен аналоговый сигнал с верхней частотой до 4000 Гц.
Наиболее часто применяются следующие разновидности АДИКМ: — рекомендация G.721 МККТТ (скорость передачи 32 кбит/с); — рекомендация G.722 МККТТ (частота дискретизации 16 000 Гц); — рекомендация G.723 МККТТ (скорость передачи 24 кбит/с); — Creative ADPCM (4, 2,6 или 2 бита на отсчет); — IMA/DVI ADPCM (4, 3 или 2 бита на отсчет); — Microsoft ADPCM.
Рассмотренные выше методы могут вносить незначительные изменения и потери в речевые сигналы (например, сужение динамического диапазона в области высших частот, ограничение крутизны сигнала), которые практически не влияют на аутентичность речи.
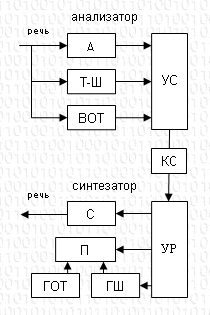
Схема вокодера
Анализатор
Синтезатор
2. Вокодеры.
Вокодеры можно разделить на два класа: — речеэлементные; — параметрические.
Вообще вокодер (от английских слов voice-голос и coder-кодер) представляет собой устройство, которое совершает параметрическое компандирование речевых сигналов.
Компрессия речевых сигналов в кодере осуществляется в анализаторе, который выделяет с речевого сигнала параметры, которые медленно меняются. В декодере при помощи местных источников сигналов, которые управляются принятыми параметрами, синтезируется речевой сигнал.
В декодере, соответственно, по заданным параметрам генерируются основной тон, шум, а затем пропускаются через гребенку полосовых фильтров для восстановления огибающей спектра речевого сигнала.
По принципу определения параметров фильтровой функции различают вокодеры: — полосные (канальные); — формантные; — ортогональне.
В ортогональных вокодерах огибающая мгновенного спектра разлагается на составные части в ряд по выбранной системе ортогональных базисных функций. Рассчитанные коэффициенты этого расписания передаются на приемную сторону. Распространение получили гармонические вокодеры, которые используют расписание в ряд Фуръе. Рассмотренные вокодеры обеспечивают сжатие сигнала до 1200-4800 Бит/с, позволяя восстановить в декодере частоту основного тона с дискретностью в несколько герц и с невысокой точностью огибающую спектра сигнала с периодом изменения 16-40 мс, при этом даже при достаточно высокой разборчивости речи теряются многие индивидуальные особенности диктора.
3. Липредеры
Одним из наиболее эффективных методов анализа и синтеза речевого сигнала является метод линейного предсказания. Метод получил распространение и продолжает совершенствоваться, суть его в том, что для прогноза текущего отсчета речевого сигнала можно использовать линейно взвешенную сумму предшествующих отсчетов, то есть предсказываемый отсчет
Все методы анализа речи предполагают достаточно медленное изменение свойств речевого сигнала во времени. Характеристики голосового тракта можно считать неизменными на интервале 10-20 мс, то есть параметры надо измерять с частотой порядка 1/20 мс = 50 Гц.
Известно несколько разновидностей метода линейного предсказания, а именно: — с возбуждением от импульсов основного тона- LPC (Linear Predictive Coding); — многоимпульсным возбуждением MPELP (Multi Pulse Excidet Linear Predictive) или MPLPC (Multi Pulse Excited LPC); — возбуждением от остатка предвидения RELP (Residual Excited Linear Predictive); — возбуждением от кода СELP (Code Excited Linear Predictive).
В кодере LPC сигнал возбуждения передается при помощи трех параметров: периода основного тона (Тот) для звуков, которые вокализованы; сигнала тон-шум (характеризующего наличие в данный момент его параметров или тона, или шума) и амплитуды сигнала.
Известно, что кроме ЧОТ основого возбуждения, которое имеет место при смыкании голосовой щели, имеется вторичное возбуждение, которое имеется не только при розмыкании голосовой щели, но и при смыкании.
В многоимпульсном возбуждении сигнал остатка LPC представляется в виде последовательности импульсов с неравномерно распределенными интервалами и с различными амплитудами (приблизительно 8 импульсов за 10 мс).
Информация о положениях и амплитудах импульсов возбуждения вместе с LPC-параметрами в каждом кадре формируется кодером.
Если используется скорость до10 параметров LPC 1,8 кбит/с (36 бит кадров20 мс), то при скоростях передачи 16 и 9,6 кбит/с на передачу параметров сигнала возбуждения отводятся скорости соответственно 14,2 и 7,8 кбит/с. На скорости 16 кбит/с и даже ниже создается высококачественная синтезированная речь. При скоростях 16 и 9,6 кбит/с синтезированная речь отвечает по качеству ИКМ сигналам (с логарифмическим компандированием) со скоростями передачи 56 и 52 кбит/с.
На скорости 4,8 кбит/с на прием передаются параметры LPC и кроскореляционная функция. Автокореляционная функция воспроизводится с параметров LPC, которые принимаются, после чего определяются положения и амплитуды импульсов возбуждения. Качество синтезированной речи при многоимпульсном возбуждении при скорости передачи 4,8 кбит/с заметно выше, чем при одноимпульсном возбуждении при той самой скорости передачи.
Кодер с линейным предсказанием, в котором в качестве сигнала возбуждения может использоваться остаток предсказания, называется RELP кодером. Остаток предсказания пропускается через ФНЧ с частотой среза 800 Гц при передаче на скорости 9,6 кбит/с и 600 Гц на скорости 4,8 кбит/с. В первом случае сигнал остатка дискретизируется с частотой 7,2 кбит/с и с той же частотой передается. Остаток 9,6-7,2 = 2,4 кбит/с используются для передачи коэффициентов предсказания и усиления. Во втором случае, т.е. при скорости передачи 4,8 сигнал остатка дискретизируется на частоте 2,4 кбит/с и с этой же скоростью передается. Остаток 2,4 кбит/с используются так же, как и в первом случае.
В декодере сигнал возбуждения восстанавливается во всей полосе частот. При этом верхняя половина возобновленного спектра возбуждения становится зеркальным отображением нижней половины.
Сигнал остатка для RELP-кодера может формироваться и во время декодирования. Дело в том, что для передачи этого сигнала нужна достаточно высокая скорость, являющаяся неприемлемой для кодеров LPC, скорость передачи каких 2,4 кбит/с, поэтому необходимо создавать сигнал остатка на прием сигнала ЧОТ. Сигнал остатка не обладает амплитудным спектром, а имеет те же самые резонансные области, что и реальный речевой сигнал. Именно поэтому сигнал остатка обладает высокой разборчивостью. Амплитуды формант на выходе синтезирующего фильтра LPC часто бывают меньше амплитуд формант в реальном речевом сигнале. Случается это в результате квантирования параметров LPC.
В линейном предсказателе с возбуждением от кода СELP (Code Excited Linear Predictive) сигнал возбуждения представляется в виде вектора, которому присваивается определенный индекс, т.е. код.
Выбор оптимального вектора осуществляется с большого множества векторов-кандидатов, которые составляют кодовую книгу. Определение размера кодовой книги возбуждения имеет определяющее значение для создания необходимого качества воостановления синтезированного языка.
Метод линейного предсказания с кодовым возбуждением обеспечивает высокое качество речевого сигнала при скоростях передачи 4…16 кбит/с.
По отношению к многоимпульсному методу CELP-метод достигает более высоких показателей восстановления речи при одинаковых скоростях.
В США приняты два федеральных стандарта на применение CELP: — 1015 (LPC-10E, 2400 бит/с); — 1016 (E-CELP, 4800 бит/с). ITU (Международный союз электросвязи, МСЭ) разработал рекомендации: — G.728 на алгоритм LD-CELP (16 кбит/с); — G.729 на алгоритм CS-ACELP (8 кбит/с).
Инструменты сайта
Основное
Навигация
Информация
Действия
Содержание
Указатель — Разделы — Автор — О проекте
Весь материал настоящего раздела очень «сырой»: я только начал разбираться с тематикой.
Теория звуковых сигналов
Речевой тракт человека
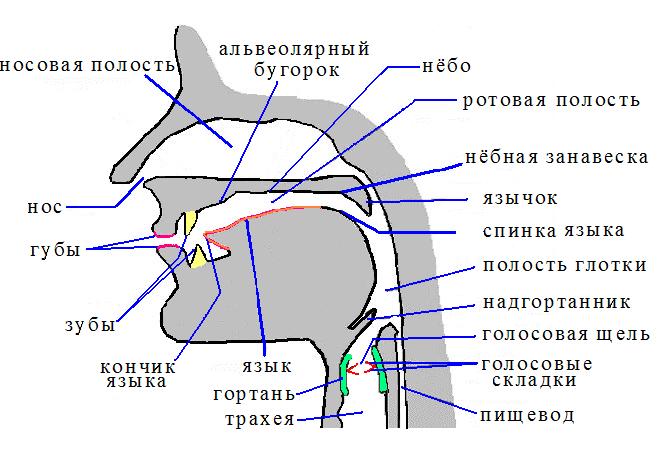
Речь возникает благодаря возбуждению акустической трубы или речевого (вокального) тракта, который с одной стороны ограничен губами, а с другой — голосовой щелью.
Если рассматривать структуру речевого тракта как музыкального инструмента, то он состоит из трех основных частей:
Легкие, действуя как кузнечные меха, создают при выдохе необходимый для звукообразования поток воздуха. Модуляция воздушного потока (за счет вибраций голосовых связок) и создание подглоточного избыточного давления происходит в гортани. Гортань — это клапан, который находится на конце трахеи (узкой трубки, по которой воздух поднимается из легких). Форма гортани имеет большое значение для голоса ее владельца. Так, к примеру, для низких мужских голосов характерна крупная гортань, выступающая на поверхности шеи в виде кадыка. Верхнее отверстие гортани, так называемый вход в гортань образуется подвижным гортанным хрящём — надгортанником. При дыхании гортань свободна, а при глотании свободный край надгортанника наклоняется назад, закрывая отверстие гортани. Во время пения вход в гортань прикрывается надгортанником. Гортань весьма подвижна, в основном, в вертикальной плоскости.
Способы смыкания складок при фонации могут быть разными. Например, если складки смыкаются не полностью, и между ними остается щель, то скорость потока воздуха не падает до нуля и в голосе слышен шум (придыхательный голос, шепот). Наоборот, если складки смыкаются слишком сильно (голос зажатый), это тоже меняет тембр и спектр голоса. Все перечисленный характеристики — основная частота колебания голосовых складок, форма голосовых импульсов, их амплитуда, спектральный состав — играют существенную роль при слуховом восприятии речи. Особую роль играет частота колебаний голосовых складок, она называется частотой основного тона (ОТ).
В речевом потоке частота основного тона субъективно воспринимается как высота голоса, и ее изменение используется для изменения интонации логических ударений, а иногда и смысла слов (например, в китайском языке). Частота основного тона зависит от длины связок, их массы и натяжения. Приближенно эту связь можно представить, как для струны: чем длиннее и тяжелее складки (эти свойства — врожденные), тем более низкий тон имеет голос, чем складки короче и тоньше — тем голос выше.
Таким образом, при образовании звуков речи с помощью процесса фонации (т.е. колебания голосовых связок) формируется вокализованный звуковой сигнал, который затем трансформируется в речевом тракте, где он превращается из «сырого» материала в последовательность речевых акустических сигналов. Движения речевых органов сами по себе не порождают речевого сигнала. Колеблющийся поток воздуха, созданный источником, проходя по речевому тракту, преобразуется. При этом не порождаются новые акустические возмущения, а изменяются характеристики «входного» потока.
В задаче распознавания речи основную роль играют вокализованные звуки; они и рассматриваются ниже.
Речевой тракт с точки зрения общей теории сигналов
Пример. Осциллограмма фразы
Огибающая сигнала
Автор: Пользователь скрыл имя, 29 Января 2011 в 17:37, реферат
Описание работы
Число средств передачи информации непрерывно возрастает. Одним из путей эффективного использования радиочастотного ресурса является сжатие спектра передаваемых сигналов, занимающих значительную долю сигналов.
Содержание
1. Введение. 2. Обработка сигналов. 3. Нахождение огибающей сигнала. 4. Применение огибающей. 5. Заключение. 6. Список использованных источников.
Работа содержит 1 файл
Определение огибающей.doc
Министерство образования Российской Федерации
НОВОСИБИРСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Автор работы Кузьмин А.В. __________
Научный руководитель Куликов А.И. __________
Новосибирск 2009 г.
Содержание:
1. Введение.
Число средств передачи информации непрерывно возрастает. Одним из путей эффективного использования радиочастотного ресурса является сжатие спектра передаваемых сигналов, занимающих значительную долю сигналов.
Несмотря на то, что проблема компандирования (сжатие – восстановление спектра речевых сигналов при их обработке на основе математической модели модуляционной теории) спектра речевых сигналов (РС) на сегодняшний день достаточно успешно решается средствами статистической теории, поиск решений данной проблемы на базе альтернативных теоретических представлений не только не потерял своей актуальности, но и приобрел еще большую остроту с развитием телекоммуникационных технологий, что объясняется ограниченными возможностями известных методов при возрастающей потребности.
Разработка новых эффективных способов компандирования спектра РС является актуальной, прежде всего, для систем радиосвязи, в том числе специализированных систем подвижной радиосвязи. Также это актуально для систем записи и хранения больших массивов речевой информации.
Также одной из важнейших задач систем радиомониторинга является
определение факта присутствия одного или нескольких сигналов в
анализируемой полосе частот. При этом определяются различные временные
характеристики огибающей сигнала.
2.Обработка сигналов.
Основой исследования сигналов является спектральный анализ. Понятие спектрального анализа является довольно широким. Оно применимо к рассмотрению любых функций в виде обобщенного ряда Фурье. При анализе сигналов обычно используется преобразование или ряд Фурье, позволяющие перевести анализ в частотную область. Сигнал рассматривается как бесконечная или конечная совокупность гармонических составляющих.
Спектральный анализ непериодических сигналов основан на использовании преобразования Фурье. Прямое и обратное преобразования Фурье устанавливают взаимно однозначное соответствие между сигналом (временной функцией, описывающей сигнал s(t)) и его спектральной плотностью :
Функция в общем случае является комплексной
Модуль спектральной плотности сигнала описывает распределение амплитуд гармонических составляющих по частоте, называется амплитудным спектром. Аргумент дает распределение фазы по частоте, называется фазовым спектром сигнала.
Формирование огибающей сигнала во времени является наиболее эффективным способом выделения модулирующей компоненты в тех случаях, когда спектральный состав модулирующей и несущей компонент различен и не пересекается в частотной области, т.е. частотная область несущей много выше частотной области модулирующей компоненты.
Поэтому применение огибающей сигнала нашло широкое применение в различных сферах деятельности.
На первых этапах развития вибрационной диагностики спектральный анализ огибающей вибрации использовался для определения частот и амплитуд гармонических составляющих, имеющих близкие частоты, не позволяющие разделить эти составляющие в спектре сигнала вибрации из-за ограниченной разрешающей способности анализаторов.
С появлением цифровых спектральных анализаторов, обладающих высокой разрешающей способностью по частоте, диагносты стали отказываться от анализа спектров огибающей тех мультипликативных компонент вибрации, в которых обе компоненты являются строго периодическими. На практике такой вид анализа еще иногда используется при диагностике подшипников качения насосов и других потокосоздающих машин, с целью обнаружения модуляции наиболее сильных составляющих вибрации на гармониках частоты вращения рабочего колеса более низкими модулирующими частотами, например частотой вращения сепаратора. Основанием является то, что в низкочастотной вибрации машин подобного типа присутствуют значительные случайные компоненты, затрудняющие обнаружение в спектре слабых боковых составляющих у вибрации на частоте вращения ротора.
Также на сегодняшний день очень остро стоит проблема сжатия спектра РС. Обоснована необходимость продолжения развития модуляционной теории звуковых сигналов, изучающей свойства натуральных акустических сигналов. Обоснована необходимость сжатия спектра речевых сигналов для повышения эффективности использования частотного ресурса каналов передачи речи. Показано развитие и современное состояние решения проблемы компандирования спектра РС с целью их трансляции по каналам связи. Приведены зависимости качества речи от степени компрессии спектра РС наиболее популярными современными методами.
Сжатие спектра РС возможно за счет уменьшения их статистической и психоакустической избыточностей. В современных системах радиотелефонии с целью сжатия спектра речевых сигналов наиболее широкое применение нашли гибридные вокодеры, уменьшающие как психоакустическую, так и статистическую избыточности. Достаточно низкое качество получаемой речи при сравнительно невысокой степени сжатия ее спектра современными методами обосновывает необходимость поиска новых путей эффективного решения данной проблемы на базе альтернативных теоретических представлений.
3.Нахождение огибающей сигнала.
При математическом анализе огибающей сигнала очень часто вместо вещественных сигналов с целью упрощения математического аппарата преобразования данных удобно использовать эквивалентное комплексное представление сигналов.
В общем случае, произвольный динамический сигнал s(t), заданный на определенном участке временной оси (как конечном, так и бесконечном) имеет комплексную двустороннюю спектральную плотность S(ω). При раздельном обратном преобразовании Фурье реальной и мнимой части спектра S(ω) сигнал s(t) разделяется на четную и нечетную составляющие, которые являются двусторонними относительно t = 0, и суммирование которых полностью восстанавливает исходный сигнал. На рис. 2 приведен пример сигнала (А), его комплексного спектра (В) и получения четной и нечетной части сигнала из реальной и мнимой части спектра (С).
Рис. 3.1. Сигнал, спектральная плотность сигнала, четная и нечетная составляющие.
s(t) = S(ω)·exp(jωt) dω + S(ω)·exp(jωt)dω (3.1)
Информация в комплексном спектре сигнала является избыточной. В силу комплексной сопряженности полную информацию о сигнале s(t) содержит как левая (отрицательные частоты), так и правая (положительные частоты) часть спектра S(ω). Аналитическим сигналом, отображающим вещественный сигнал s(t), называют второй интеграл выражения (3.1), нормированный на π, т.е. обратное преобразование Фурье спектра сигнала s(t) только по положительным частотам:
Дуальность свойств преобразования Фурье определяет, что аналитический сигнал zs(t), полученный из односторонней спектральной функции, всегда является комплексным и может быть представлен в виде:
Аналогичное преобразование первого интеграла выражения (3.1) дает сигнал zs*(t), комплексно сопряженный с сигналом z(t):
что наглядно видно на рис. 3.2 при восстановлении сигналов по односторонним частям спектра, приведенного на рис. 2-В.
Рис. 3.2. Сигналы z(t) и z*(t).
По рисунку 3.2 можно видеть, что при сложении функций zs(t) и zs*(t) мнимые части функций взаимно компенсируются, а вещественные части, с учетом нормировки только на π, а не на 2π, как в (3.1), в сумме дают полный исходный сигнал s(t):
= (1/2π) S(ω) cos ωt dt = s(t).
Отсюда следует, что реальная часть аналитического сигнала zs(t) равна самому сигналу s(t).
Для выявления характера мнимой части сигнала zs(t) выполним перевод всех членов функции (3.2′) в спектральную область с раздельным представлением по положительным и отрицательным частотам (индексами – и +) реальных и мнимых частей спектра:
где индексами A’ и B’ обозначены функции преобразования Im(z(t)). В этом выражении функции в левой части спектра (по отрицательным частотам) должны взаимно компенсировать друг друга согласно определению аналитического сигнала (3.2), т.е.:
Отсюда, с учетом четности вещественных A’—(ω) и нечетности мнимых B’—(ω) функций спектра, следуют также равенства:
где индексом обозначен сигнал, аналитически сопряженный с сигналом s(t), hb(t) – оператор Гильберта.
Таким образом, квадратурное дополнение сигнала s(t) представляет собой свертку сигнала s(t) с оператором 1/(πt) и может быть выполнено линейной системой с постоянными параметрами:
ПЕРВИЧНЫЙ РЕЧЕВОЙ СИГНАЛ.
Речь с физической точки зрения состоит из последовательности звуков с паузами между их группами. При нормальном темпе речи паузы появляются между отрывками фраз, так как при этом слова произносятся слитно (хотя слух, как правило, воспринимает слова по отдельности). При замедленном темпе речи, например, при диктовке, паузы могут делаться между словами и даже их частями. Предлоги, союзы звучат всегда слитно с последующим словом.
Один и тот же звук речи разные люди произносят по-разному. Произношение звуков речи зависит от ударения, соседних звуков и т. п. Но при всем многообразии в их произношении они являются физическими реализациями (произнесением) ограниченного числа обобщенных звуков речи, называемых фонемами. Фонема — это то, что человек хочет произнести, а звук речи — это то, что человек фактически произносит. Фонема по отношению к звуку речи играет ту же роль, что и образцовая буква по отношению к ее рукописной форме в конкретном написании.
B русском языке насчитываются 41 основная и 3 неясно звучащих фонемы: 6 гласных (а, о, у, э, и, ы), 1 полугласная (й) и 34 согласных. Гласные буквы я, ю, ё, е (соответствуют или составным фонемам: йа, йу, йо, йэ, или служат для смягчения предыдущей согласной. Согласных фонем больше, чем согласных букв, так как род согласных букв соответствует двум фонемам: мягкой и твердой. Только твердых фонем 3 (ш, ж, ц), только мягких—1 (ч). Остальные l6 существуют в обоих видах: твердом и мягком.
Если связки тонкие и сильно напряжены, то период получается коротким и частота основного тона — высокой; для толстых, слабонапряженных связок частота основного тона низкая. Эта частота для всех голосов лежит в пределах от 70 до 450 Гц. При произнесении речи она непрерывно изменяется в соответствии с ударением и подчеркиванием звуков и слов, а также для проявления эмоций (вопрос, восклицание, удивление и т. д.). Изменение частоты основного тона называют интонацией. У каждого человека свой диапазон изменения частоты основного тона (обычно он бывает немногим более октавы) и своя интонация. Последняя имеет большое значение для узнаваемости говорящего. Основной тон, интонация, устный «почерк» и тембр (окраска) голоса могут служить для опознавания человека. При этом степень достоверности опознавания выше, чем по отпечаткам пальцев. Это свойство используют в разработанной в последнее время аппаратуре, срабатывающей только от определенных голосов.
Импульсы основного тона имеют пилообразную форму, и поэтому при их периодическом повторении получается дискретный спектр с большим числом гармоник (до 40), частоты которых кратны частоте основного тона. Огибающая спектра основного тона имеет спад в сторону высоких частот с крутизной около 6 дБ/окт. Например, для мужского голоса уровень гармоник на частоте 3000 Гц ниже уровня на 100 Гц примерно на 30 дБ.
Звуки речи делят на звонкие и глухие. Звонкие звуки образуются с участием голосовых связок, в этом случае находящихся в напряжении. Под напором воздуха, идущего из легких, они периодически раздвигаются, в результате чего создается прерывистый поток воздуха. Импульсы потока воздуха, создаваемые голосовыми связками с достаточной точностью, могут считаться периодическими. Соответствующий период повторения импульсов называют периодом основного тона голоса То. Обратную величину fo=1\T называют частотой основного тона.
При произнесении глухих звуков голосовые связки находятся в расслабленном состоянии и поток воздуха из легких свободно проходит в полость рта. Встречая на своем пути различные преграды в виде языка, зубов, губ, он образует завихрения, создающие шум со сплошным спектром.
При произнесении звуков речи язык, губы, зубы, нижняя челюсть, голосовые связки должны находиться для каждой фонемы в строго определенном положении или движении. Эти движения называют артикуляциейорганов речи. При этом в речеобразующем тракте создаются определенные для данной фонемы резонансные полости, а для слитного звучания фонем в речи — и определенные переходы от одной формы тракта к другой.
Через речевой тракт при произнесении звуков проходят или тональный импульсный сигнал, или шумовой, или тот и другой вместе. Речевой тракт представляет собой сложный акустический фильтр с рядом резонансов, создаваемых полостями рта, носа и носоглотки, т. е. с помощью артикуляционных органов речи. Вследствие этого тональный или шумовой спектры с монотонной огибающей превращаются в спектры с рядом максимумов и минимумов.
Максимально в отдельных звуках замечено до 6 усиленных частотных областей. Однако далеко не все они являются формантами. Некоторые из них никакого значения для распознавания звуков не имеют, хотя и несут в себе довольно значительную энергию.
Формантными являются одна или две частотные области. Исключение из передачи любой из этих областей вызывает искажение передаваемого звука, т. е. либо превращение его в другой звук, либо вообще потерю им признаков звука человеческой речи. рукописной форме в конкретном написании.
Максимумы спектра называют формантами, а нулевые значения — антиформантами. Огибающая спектра для каждой фонемы имеет индивидуальную и вполне определенную форму (рис. 3.3). При произнесении речи спектр ее непрерывно изменяется, в результате чего образуются формантные переходы. Частотный диапазон речи находится в пределах 70 — 7000 Гц.
Звонкие звуки речи, особенно гласные, имеют высокий уровень интенсивности, глухие — низкий. В процессе произнесения речи ее громкость непрерывно изменя-
ется, особенно резко при взрывных звуках речи. Динамический диапазон уровней звуков речи находится в пределах 35—45 дБ. Гласные звуки имеют в среднем длительность около 0,15 с, согласные —около 0,08 с, звук «п» — около 30 мс. Большая длительность гласных звуков необходима для перестройки артикуляционных органов, так как иначе язык будет «заплетаться».
Звуки речи неодинаково информативны. Так, гласные звуки содержат меньшую информацию о смысле речи, чем глухие. Поэтому разборчивость речи снижается при действии шумов, в первую очередь из-за маскировки глухих звуков.
Известно, что для передачи одного и того же сообщения по телеграфу и по речевому тракту требуется различная пропускная способность тракта: для телеграфного сообщения не более 100 бит/с, а для речевого — около 100 000 бит/с (полоса равна 7000 Гц, динамический диапазон 42 дБ, т. е. требуется семизначный код, откуда имеем: 2х7000х7 = 98000 бит/с), т. е. в 1000 раз большая. Может показаться, что речевой сигнал имеет огромную избыточность. Это неверно и вот почему.
.В результате спектральной модуляции изменяется соотношение между частотными составляющими несущей, т. е. изменяется форма огибающей ее спектра (появляются форманты и антиформанты). Почти вся информация о звуках речи заключается в этой спектральной огибающей и ее временном изменении. Эти изменения происходят медленно( в темпе произнесения звуков), поэтому передача сведений об огибающей и ее изменении не требует пропускной способности тракта более 100 бит/с. Но для передачи широкополосной несущей с ее широким динамическим диапазоном требуется очень большая пропускная способность. Кроме того, речевой сигнал при образовании в речевом тракте приобретает много информации, не относящейся к смыслу передаваемой речи (например, фазовую информацию). Эта информация называется сопутствующей. Для ее передачи также расходуется пропускная способность тракта. Из этого следует, что избыточность речевого сигнала лишь немного превышает избыточность телеграфного сигнала с таким же сообщением: речевой сигнал отличается от телеграфного лишь информацией об эмоциях и личности говорящего.
Поэтому для передачи смысла достаточно передавать сведения о форме огибающей спектра речи, а также об изменении основного тона речи и переходов тон-шума. Эти сигналы идут от речевого центра мозга.
— Частично информация о звуках речи заключена в переходах от тонального спектра к шумовому и обратно (т. е. в переходах от звонких звуков к глухим и обратно), а информация о сигнале — еще и в интонации. По фонетической теории информация заключается только в скорости изменения спектральных уровней.
— Речевой сигнал можно уподобить водоему, в котором находится рыба. Водоем может иметь большой объем, а полезной информации (рыбы) в нем может быть немного.
ВТОРИЧНЫЙ СИГНАЛ.
Вторичный сигнал должен точно воспроизводить первичный, но это не всегда требуется, так как слух человека может и не заметить их несоответствие. К тому же на практике точное соответствие их часто невозможно или очень трудно осуществить. При художественном вещании, телевидении и звукозаписи надо стремиться к этому соответствию в пределах, при которых слуховое ощущение, создающееся у слушателя, было бы близко к тому ощущению, которое он получает, находясь в месте исполнения данной программы при условии достаточно хороших акустических условий в этом месте. Для информационных программ вещания и телефонной связи этого соответствия добиваются в первую очередь для получения полной понятности речи, а затем для достаточно высокого качества звучания. Только в этом случае необходимо стремиться к более точному соответствию вторичного сигнала первичному, В обоих случаях существенную роль играют экономические соображения.
Нарушение точности передачи, замечаемое слухом, бывает самого разнообразного вида. Рассмотрим основные из них: потерю акустической перспективы, смещение уровней, ограничение динамического и частотного Диапазона сигнала, помехи, искажения.
Смещение уровней. Поскольку по тракту передачи сигналов не передается информация об абсолютных уровнях звучания первичного сигнала, то слушатель (а при массовом слушании — оператор на приемном конце) по своему усмотрению устанавливает уровень вторичного сигнала. При этом не всегда можно восстановить нужный уровень первичного сигнала из-за недостаточной мощности аппаратуры на приемном конце, а также из-за условий слушания (например, в квартирах с плохой звукоизоляцией).
Смещение уровней приводит к изменению соотношения между громкостями низкочастотных и среднечастотных составляющих первичного и вторичного сигналов, так как смещение среднего уровня вторичного сигнала вверх по отношению к среднему уровню первичного приводит к субъективному повышению громкости низкочастотных составляющих, смещение вниз — к их ослаблению.
Ограничение динамического диапазона. Поскольку динамический диапазон канала ограничен снизу шумами, а сверху — перегрузкой и нелинейностью отдельных звеньев канала передачи, то во избежание искажений его сжимают в начале тракта (во всяком случае до звена, в котором скорее всего может ограничиться или исказиться сигнал). Этот дефект может быть частично исправлен путем расширения динамического диапазона сигнала на конце тракта, что не всегда возможно, так как на приемном конце может быть неизвестно, насколько был сжат этот диапазон. Кроме того, попытка расширить диапазон (применением экспандеров) усложняет аппаратуру.
Ограничение частотного диапазона. Поскольку тракт передачи акустических сигналов не пропускает весь их частотный диапазон, говорят об ограничении частотного диапазона.
Помехи. При передаче на сигнал накладываются различного рода помехи, в том числе шумы электрического и акустического происхождения. Последние имеются как в месте нахождения первичного источника, звука, так и в месте нахождения слушателя.
Искажения. По сути дела все перечисленные несоответствия первичного и вторичного сигналов являются искажениями в широком смысле этого понятия. Но обычно под этим термином понимают более узкий тип искажений. К ним относятся линейные, нелинейные, параметрические и переходные (временные) искажения.
ШУМЫ И ПОМЕХИ
Помехи по своему характеру и происхождению разделяются на фон, шум и различного характера внешние наводки. Влияние шумов и помех сводится к маскировке вторичного акустического сигнала независимо от их происхождения (акустического или электрического). Шумы сдвигают порог слышимости, который не зависит от времени, если шумы относятся к «гладким», т. е. имеют пик-фактор, не превышающий 6 дБ. К этим шумам относятся различные флуктуационные шумы, например шумы; дробового эффекта, речевые шумы от нескольких голосов, звучащих одновременно. Импульсные шумы создают порог слышимости, изменяющийся во времени в зависимости от пик-фактора шума и длительности импульсов. Из-за наличия постоянной времени у слуха ощущение кратковременных импульсов получается сглаженным: происходит выравнивание временной зависимости порога слышимости. Импульсные шумы не только маскируют полезный сигнал, но и искажают его, создавая комбинационные частоты шума и сигнала. Получается нечто похожее на взаимную модуляцию сигнала и шума.
Спектр шумов электрического происхождения, как; правило, близкий к равномерному, а акустического происхождения — ближе к речевому. Поэтому частотная зависимость порога слышимости для первых имеет тенденцию роста к высоким частотам, так как ширина критических полосок растет с увеличением частоты. Для речевых шумов порог слышимости почти не зависит от частоты.
Индустриальные, атмосферные и станционные помехи, кроме тональных, могут быть отнесены и к импульсным, и к гладким, с равномерным или низкочастотным спектром. Кроме этих помех, приходится иногда считаться с помехами от самомаскировки речи, т. е. с маскировкой слабых звуков, следующих за громкими.
Фон проявляется обычно в виде прослушиваемого низкого однотонного гудения с частотой 50 или 100 Гц. Причина фона может быть двоякой: чаще всего это плохая фильтрация переменной составляющей напряжения, выпрямленного в источнике питания и используемого для питания транзисторов или электронных ламп усилителей. Но могут проявиться и внешние наводки, т.е. возбуждения в самом усилителе или в присоединенных к нему проводах и линиях колебаний, появляющиеся за счет электромагнитной связи этих цепей с посторонними источниками электрических и магнитных полей (например, трансформаторов, силовых электрических кабелей, театральных софитов и т.п. Таким же путем, т.е. путем электромагнитных наводок на токоведущие цепи канала передачи звукового сигнала, могут проникнуть в канал и, так называемые, «внятные» помехи, например, посторонние программы близко расположенных мощных радиовещательных станций и т.п. Для борьбы с наводками любого характера следует тщательно защищать, применяя экранировку, те цепи, по которым протекают слабые токи ( например, микрофонные провода).
Борьба с акустическими шумами ведется путем устранения (или ослабления) действия источников шума, а также путем повышения звукоизоляции помещений. Учет их действия на прием речевого сигнала делается при расчете и измерении разборчивости речи.