Как оптимизировать запросы в SQL?
В этой статье хочу рассказать о некоторых приемах, позволяющих значительно ускорить работу с SQL операторами. (Источник: личный опыт)
Вот некоторые из них:
1. Используйте конкретные имена столбцов после оператора select, вместо «*» – это позволит увеличить быстроту отработки запроса и уменьшению сетевого трафика.
2. Сведите к минимуму использование подзапросов.
выглядит значительно хуже на фоне аналогичного запроса:
3. Используйте оператор IN аккуратно, поскольку на практике он имеет низкую производительность и может быть эффективен только при использовании критериев фильтрации в подзапросе.
4. Соединение таблиц в запросе также является критичным: в случае, когда соединение таблиц происходит в правильном порядке, то общее число строк, необходимых к обработке, значительно сократится.
При соединении основной и уточняющей таблиц убедитесь, что первой будет основная таблица, в противном случае вы рискуете получить обработку гораздо большего числа строк, чем необходимо.
5. При соединении таблиц EXIST предпочтительнее distinct (таблицы отношения «один-ко-многим»).
6. Избыточность при работе с SQL – это критичная необходимость, используйте в разделе WHERE как можно больше ограничивающих условий.
Например, если указан
вы сможете вывести результат, где Column_В=425, однако при задании условий
оператор не сможет определить, что Column_A=Column_C.
7. Пишите простые запросы. Больше упрощайте. Оптимизатор может не справиться со слишком сложными операторами. Кроме того, иногда выполнение нескольких простых до невозможности операторов дает лучший результат по сравнению со сложными и позволяет добиться лучшей эффективности.
8. Помните, что одного и того же результата можно добиться разными способами. Например, оператор MINUS выполняется гораздо быстрее, чем запросы с оператором WHERE NOT EXIST. Запрос с данным оператором в самом общем виде выглядит следующим образом:
Этот пример показывает все значения worker_id, которые содержаться в таблице workers, не в таблице orders. Другими словами, если бы значение worker_id одновременно присутствовало в таблицах workers и orders, то значение worker_id не вывелось в результат, поскольку нет конкретики, содержание какой именно таблицы вывести как результат отработки запроса.
9. Оформляйте повторяющиеся коды в пользовательскую процедуру. Это может значительно ускорить работу, уменьшить сетевой трафик.
Таким образом, рассмотренные нами моменты работы с SQL операторами и запросами значительно ускоряют работу с СУБД.
В заключение хочется отметить, что очень важно при работе с SQL – мыслить шире, чем границы поставленной перед вами задачи
Всегда старайтесь оптимизировать запрос, какой бы не была мощной инфраструктура, даже ее производительность может снизиться при выполнении неоптимизированных запросов. Учитывайте все необходимые условия при работе с операторами таким образом, чтобы нагрузка на базу была минимальной.
Оптимизация запросов базы данных на примере B2B сервиса для строителей
Как вырасти в 10 раз под количеству запросов к БД не переезжая на более производительный сервер и сохранить работоспособность системы? Я расскажу, как мы боролись с падением производительности нашей базы данных, как оптимизировали SQL запросы, чтобы обслуживать как можно больше пользователей и не повышать расходы на вычислительные ресурсы.
Я делаю сервис для управления бизнес процессами в строительных компаниях. С нами работает около 3 тысяч компаний. Более 10 тысяч человек каждый день работают с нашей системой по 4-10 часов. Она решает разные задачи планирования, оповещения, предупреждения, валидации… Мы используем PostgreSQL 9.6. В базе данных у нас около 300 таблиц и каждые сутки в нее поступает до 200 млн запросов (10 тысяч различных). В среднем у нас 3-4 тысяч запросов в секунду, в самые активные моменты более 10 тысяч запросов в секунду. Большая часть запросов — OLAP. Добавлений, модификаций и удалений намного меньше, то есть OLTP нагрузка относительно небольшая. Все эти цифры я привел, чтобы вы могли оценить масштаб нашего проекта и понять насколько наш опыт может быть полезен для вас.
Картина первая. Лирическая
Картина вторая. Статистическая
Итак у нас есть около 10 тысяч различных запросов, которые выполняются на нашей БД за сутки. Из этих 10 тысяч есть монстры, которые выполняются по 2-3 млн раз со средним временем выполнения 0.1-0.3 мс и есть запросы со средним временем выполнения 30 секунд, которые вызываются 100 раз в сутки.
Оптимизировать все 10 тысяч запросов не представлялось возможным, поэтому мы решили разобраться с тем, куда направлять усилия, чтобы повышать производительность БД правильно. После нескольких итераций мы стали делить запросы на типы.
TOP запросы
Это самые тяжелые запросы, которые занимают больше всего времени (total time). Это запросы, которые либо очень часто вызываются либо запросы, которые очень долго выполняются (долгие и частые запросы были оптимизированы еще на первых итерациях борьбы за скорость). В итоге суммарно на их исполнение сервер тратит больше всего времени. Причем важно отделять топ запросы по общему времени исполнения и отдельно по IO time. Способы оптимизации таких запросов немного разные.
Обычная практика всех компаний- работать с TOP запросами. Их немного, оптимизация даже одного запроса может освободить 5-10% ресурсов. Однако, по мере “взросления” проекта оптимизация TOP запросов становится все более нетривиальной задачей. Все простые способы уже отработаны, да и самый “тяжелый” запрос отнимает “всего” 3-5% ресурсов. Если TOP запросы в сумме занимают менее 30-40% времени, то скорее всего вы уже приложили усилия, чтобы они работали быстро и пришла пора переходить к оптимизации запросов из следующей группы.
Остается ответить на вопрос сколько верхних запросов включить в эту группу. Я обычно беру не меньше 10, но не больше 20. Стараюсь, чтобы время первого и последнего в TOP группе отличалось не более чем в 10 раз. То есть если время исполнения запросов резко падает с 1 места до 10, то беру TOP-10, если падение более плавное, то увеличиваю размер группы до 15 или 20. 
Середняки (medium)
Это все запросы, которые идут сразу за TOP, за исключением последних 5-10%. Обычно в оптимизации именно этих запросов кроется возможность сильно поднять производительность сервера. Эти запросы могут “весить” до 80%. Но даже если их доля перевалила за 50%, значит пора на них взглянуть более внимательно.
Хвост (tail)
Как было сказано, эти запросы идут в конце и на них уходит 5-10% времени. Про них можно забыть, только если вы не используете автоматические средства анализа запросов, тогда их оптимизация тоже может дешево обойтись.
Как оценить каждую группу?
Я использую SQL запрос, который помогает сделать такую оценку для PostgreSQL (уверен что для многих других СУБД можно написать похожий запрос)
Результат запроса- три столбца, каждый из которых содержит процент времени, который уходит на обработку запросов из этой группы. Внутри запроса есть два числа (в моем случае это 20 и 800), которые отделяет запросы одной группы от другой.
Вот так примерно соотносятся доли запросов на момент начала работ по оптимизации и сейчас.
Из диаграммы видно, что доля TOP запросов резко снизилась, зато выросли “середняки”.
Поначалу в TOP запросы попадали откровенные ляпы. Со временем детские болезни исчезли, доля TOP запросов сокращалась, приходилось прилагать все больше усилий, чтобы ускорить тяжелые запросы.
Вот список самых часто используемых приемов, которые помогали нам ускорять TOP запросы:
Тогда мы обратили внимание на вторую группу запросов- группу середняков. В ней намного больше запросов и казалось, что на анализ всей группы уйдет очень много времени. Однако большинство запросов оказались очень просты для оптимизации, а многие проблемы повторялись десятки раз в разнличных вариациях. Вот примеры некоторых типовых оптимизаций, который мы применяли к десяткам похожих запросов и каждая группа оптимизированных запросов разгружала БД на 3-5%.
Например, вместо запроса для выборки всех водителей по большой таблице доставок (DELIVERY)
сделали запрос по сравнительно небольшой таблице PERSON
Каждый конкретный запрос удавалось ускорить порой в 3-1000 раз. Несмотря на впечатляющие показатели, поначалу нам казалось, что нет смысла в оптимизации запроса, который выполняется 10 мс, входит в 3-ю сотню самых тяжелых запросов и в общем времени нагрузки на БД занимает сотые доли процента. Но применяя один и тот же рецепт к группе однотипных запросов мы отыгрывали по несколько процентов. Чтобы не тратить время на ручной просмотр всех сотен запросов мы написали несколько простых скриптов, которые с помощью регулярных выражений находили однотипные запросы. В итоге автоматический поиск групп запросов позволил нам еще больше улучшить нашу производительность, затратив скромные усилия.
В итоге мы уже три года работаем на одном и том же железе. Среднесуточная нагрузка около 30%, в пиках доходит до 70%. Количество запросов как и количество пользователей выросло примерно в 10 раз. И все это благодаря постоянному мониторингу этих самых групп запросов TOP-MEDIUM. Как только какой-то новый запрос появляется в группе TOP, мы его тут же анализируем и пытаемся ускорить. Группу MEDIUM мы раз в неделю просматриваем с помощью скриптов анализа запросов. Если попадаются новые запросы, которые мы уже знаем как оптимизировать, то мы их быстро меняем. Иногда находим новые способы оптимизации, которые можно применить сразу к нескольким запросам.
По нашим прогнозам текущий сервер выдержит увеличение количества пользователей еще в 3-5 раз. Правда у нас есть еще один козырь в рукаве- мы до сих пор не перевели SELECT- запросы на зеркало, как рекомендуется делать. Но мы этого не делаем осознанно, так как хотим сначала до конца исчерпать возможности «умной» оптимизации, прежде чем включать «тяжелую артиллерию».
Критический взгляд на проделанную работу может подсказать использовать вертикальное масштабирование. Купить более мощный сервер, вместо того, чтобы тратить время специалистов. Сервер может стоить не так дорого, тем более что лимиты вертикального масштабирования у нас еще не исчерпаны. Однако в 10 раз выросло лишь количество запросов. За несколько лет, увеличился функционал системы и сейчас разновидностей запросов стало больше. Тот функционал, который был, за счет кеширования выполняется меньшим количеством запросов, к тому же более эффективных запросов. Значит можно смело умножить еще на 5, чтобы получить реальный коэффициент ускорения. Итак по самым скромным подсчетам можно сказать, что ускорение составило 50 и более раз. Вертикально раскачать сервер в 50 раз обошлось бы дороже. Особенно учитывая, что однажды проведенная оптимизация работает все время, а счет за арендованный сервер приходит каждый месяц.
Оптимизация SQL запросов или розыск опасных преступников
Кейс компании Appbooster
Полагаю, практически каждый проект, использующий Ruby on Rails и Postgres в качестве основного вооружения на бэкенде находится в перманентной борьбе между скоростью разработки, читаемостью/поддерживаемостью кода и скоростью работы проекта в продакшене. Я расскажу о своем опыте балансирования между этими тремя китами в кейсе, где на входе страдали читаемость и скорость работы, а на выходе получилось сделать то, что до меня безуспешно пытались сделать несколько талантливых инженеров.
Полностью вся история займёт несколько частей. Это первая, где я расскажу о том что такое PMDSC для оптимизации SQL-запросов, поделюсь полезными инструментами измерения эффективности запросов в postgres и напомню об одной полезной старой шпаргалке, которая до сих пор актуальна.
Сейчас, спустя какое-то время, “задним умом” я понимаю, что на входе в этот кейс совершенно не ожидал что у меня всё получится. Поэтому этот пост будет полезен скорее для смелых и не самых опытных разработчиков, чем для супер-сеньоров видавших рельсы с голым SQL.
Вводные данные
Мы в Appbooster занимаемся продвижением мобильных приложений. Чтобы легко выдвигать и проверять гипотезы мы разрабатываем несколько своих приложений. Бэкенд большинства из них это Rails API и Postgresql.
Герой этой публикации разрабатывается с конца 2013 года – тогда только-только вышел rails 4.1.0.beta1. С тех пор проект вырос в полноценно нагруженное веб-приложение, которое крутится на нескольких серверах в Amazon EC2 c отдельным инстансом базы данных в Amazon RDS (db.t3.xlarge с 4 vCPU и 16 GB RAM). Пиковые нагрузки доходят до 25k RPM, средняя нагрузка днём 8-10k RPM.
С инстанса базы данных, точнее с её кредитного баланса и началась эта история.
Как работает инстанс Postgres типа “t” в Амазон RDS: если ваша база данных работает со средним потреблением процессорного времени ниже определенного значения, то у вас на счету накапливаются кредиты, которые инстанс может тратить на потребление процессора в часы высокой нагрузки – это позволяет не переплачивать за серверные мощности и справляться с высокой нагрузкой. Более подробно о том за что и сколько платят, используя AWS можно прочитать в статье нашего CTO.
В один прекрасный день, я написал в ежедневном саммари о том, что очень устал тушить периодически возникающие в разных местах проекта “пожары”. Если так будет продолжаться, то бизнес задачам будет уделять время выгоревший разработчик. В тот же день я подошел к главному менеджеру проектов, объяснил расклад и попросил время на расследование причин периодических пожаров и ремонт. Получив добро, я начал собирать данные из разных систем мониторинга.
Мы используем Newrelic для отслеживания общего времени отклика за сутки. Картина выглядела так:
Желтым на графике выделена часть времени ответа, которую занимает Postgres. Как видно, иногда время ответа доходило до 1000 ms и большую часть времени именно база данных размышляла над ответом. Значит надо смотреть что происходит с SQL запросами.
PMDSC – простая и понятная практика для любой скучной работы оптимизации SQL запросов
Play it!
Measure it!
Draw it!
Suppose it!
Check it!
Play it!
Пожалуй, самая важная часть всей практики. Когда кто-то произносит фразу «Оптимизация SQL запросов» – это скорее вызывает приступ зевоты и скуку у абсолютного большинства людей. Когда ты произносишь «Детективное расследование и розыск опасных злодеев» – это сильнее вовлекает и настраивает тебя самого на нужный лад. Поэтому важно войти в игру. Мне понравилось играть в детектива. Я представлял себе что проблемы с базой данных либо опасные преступники, либо редкие болезни. А себя представлял в роли Шерлока Холмса, Лейтенанта Коломбо или Доктора Хауса. Выбирай героя на свой вкус и вперед!
Measure It!
Для анализа статистики запросов, я установил PgHero. Это очень удобный способ читать данные из расширения pg_stat_statements для Postgres. Заходим в /queries и смотрим на статистику всех запросов за последние сутки. Сортировка запросов по умолчанию по колонке Total Time – доля общего времени которое база данных обрабатывает запрос – ценный источник в поиске подозреваемых. Average Time – сколько в среднем запрос выполняется. Calls – сколько запросов было за выбранное время. PgHero считает медленными запросы, которые выполнялись более 100 раз за сутки и занимали в среднем более 20 миллисекунд. Список медленных запросов на первой странице, сразу после списка дублирующихся индексов.
Берём первый в списке и смотрим детали запроса, тут же можно посмотреть его explain analyze. Eсли planning time сильно меньше execution time, значит с этим запросом что-то не так и мы концентрируем внимание на этом подозреваемом.
В PgHero есть свой способ визуализации, но мне больше понравилось использовать explain.depesz.com копируя туда данные из explain analyze.
Один из подозреваемых запросов использует Index Scan. На визуализации видно что этот индекс не эффективен и является слабым местом – выделено красным. Отлично! Мы изучили следы подозреваемого и нашли важную улику! Правосудие неизбежно!
Draw it!
Нарисуем множество данных которые используются в проблемной части запроса. Будет полезно сравнить с тем какие данные покрывает индекс.
Немного контекста. Мы тестировали один из способов удержания аудитории в приложении – что-то вроде лотереи, в которой можно выиграть немного внутренней валюты. Делаешь ставку, загадываешь число от 0 до 100 и забираешь весь банк, если твое число оказалось ближе всех к тому что получил генератор случайных чисел. Мы назвали это “Арена”, а розыгрыши назвали “Битвами”.
В базе данных на момент расследования около пятисот тысяч записей о битвах. В проблемной части запроса мы ищем битвы в которых ставка не превышает баланс пользователя и статус битвы – жду игроков. Видим что пересечение множеств (выделено оранжевым) совсем маленькое количество записей.
Индекс, используемый в подозреваемой части запроса покрывает все созданные битвы по полю created_at. Запрос пробегает по 505330 записям из которых выбирает 40, а 505290 отсеивает. Выглядит очень расточительно.
Suppose it!
Выдвигаем гипотезу. Что поможет базе данных найти сорок записей из пятисот тысяч? Попробуем сделать индекс который покрывает поле ставка, только для битв со статусом “жду игроков” – паршиал индекс.
Паршиал индекс – существует только для тех записей, которые подходят под условие: поле статус равно “жду_игроков” и индексирует поле ставка – ровно то что в условии запроса. Очень выгодно использовать именно этот индекс: он занимает всего 40 килобайт и не покрывает те битвы которые уже сыграны и не нужны нам для получения выборки. Для сравнения – индекс index_arena_battles_on_created_at, который использовался подозреваемым занимает около 40 Мб, а таблица с битвами около 70 Мб. Этот индекс можно смело удалить, если его не используют другие запросы.
Check it!
Выкатываем миграцию с новым индексом в продакшен и наблюдаем за тем как изменился отклик эндпоинта с битвами.
На графике видно во сколько мы выкатили миграцию. Вечером 6 декабря время отклика уменьшилось примерно в 10 раз с
50ms. Подозреваемый в суде получил статус заключенного и теперь сидит в тюрьме. Отлично!
Prison Break
Спустя несколько дней мы поняли что рано радовались. Похоже, заключенный нашел сообщников, разработал и осуществил план побега.
Утром 11 декабря планировщик запросов postgres решил что использовать свежий паршиал индекс, ему больше не выгодно и стал снова использовать старый.
Мы снова на этапе Suppose it! Собираем дифференциальный диагноз, в духе доктора Хауса:
Давай вместе пройдемся по этому SQL. Выбираем все поля битвы из таблицы битв статус которых равен “жду игроков” и ставка меньше или равна некоему числу. Пока все понятно. Следующее слагаемое условия выглядит жутко.
Мы ищем не существующий результат подзапроса. Достань первое поле из таблицы участий в битвах, где идентификатор битвы совпадает и профиль участника принадлежит нашему игроку. Попробую нарисовать множество описанное в подзапросе.
Сложно осмыслить, но в итоге этим подзапросом мы пробовали исключить те битвы в которых игрок уже участвует. Смотрим общий explain запроса и видим Planning time: 0.180 ms, Execution time: 12.119 ms. Мы нашли сообщника!
Настало время моей любимой шпаргалки, которая гуляет по интернетам с 2008 года. Вот она:
Да! Как только в запросе встречается что-то, что должно исключить какое-то количество записей на основе данных из другой таблицы, в памяти должен всплыть этот мем с бородой и кудрями.
На самом деле вот что нам нужно:
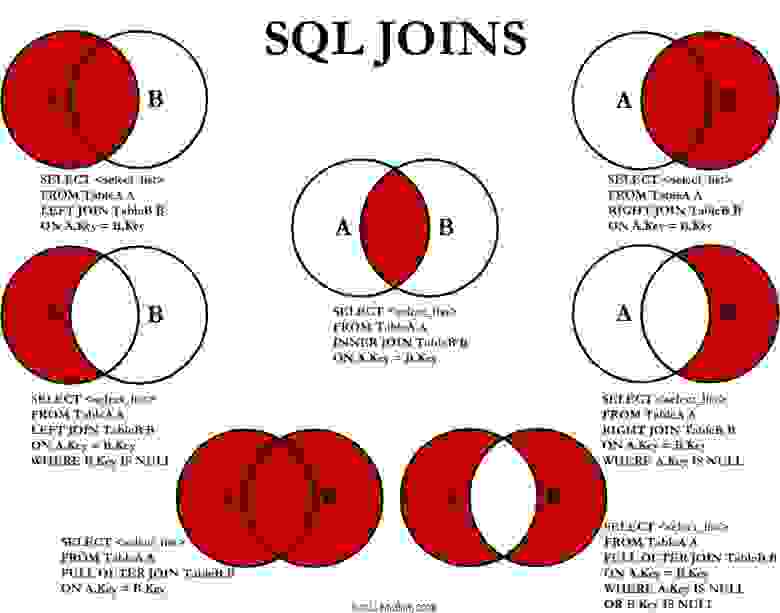
Сохрани себе эту картинку, а еще лучше распечатай и повесь в нескольких местах в офисе.
Переписываем подзапрос на LEFT JOIN WHERE B.key IS NULL, получаем:
Исправленный запрос бежит сразу по двум таблицам. Мы присоединили “слева” таблицу с записями участий в битвах пользователя и добавили условие что идентификатор участия не существует. Смотрим explain analyze полученного запроса: Planning time: 0.185 ms, Execution time: 0.337 ms. Отлично! Теперь планировщик запросов не будет сомневаться что ему стоит использовать паршиал индекс, а будет использовать самый быстрый вариант. Сбежавший заключенный и его сообщник приговорены на пожизненное заключение в заведении строгого режима. Сбежать им будет сложнее.
Оптимизация сложных запросов MySQL
Введение
MySQL — весьма противоречивый продукт. С одной стороны, он имеет несравненное преимущество в скорости перед другими базами данных на простейших операциях/запросах. С другой стороны, он имеет настолько неразвитый (если не сказать недоразвитый) оптимизатор, что на сложных запросах проигрывает вчистую.
Прежде всего хотелось бы ограничить круг рассматриваемых проблем оптимизации «широкими» и большими таблицами. Скажем до 10m записей и размером до 20Gb, с большим количеством изменяемых запросов к ним. Если в вашей в таблице много миллионов записей, каждая размером по 100 байт, и пять несложных возможных запросов к ней — это статья не для Вас. NB: Рассматривается движок MySQL innodb/percona — в дальнейшем просто MySQL.
Большинство запросов не являются очень сложными. Поэтому очень важно знать как построить индекс для использования нужным запросом и/или модифицировать запрос таким образом, чтобы он использовал уже имеющиеся индексы. Мы рассмотрим работу оптимизатора для выбора индекса обычных запросов (select_type=simple), без джойнов, подзапросов и объединений.
Отбросим простейшие случаи для очень небольших таблиц, для которых оптимизатор зачастую использует type=all (полный просмотр) вне зависимости от наличия индексов — к примеру, классификатор с 40-ка записями. MySQL имеет алгоритм использования нескольких индексов (index merge), но работает этот алгоритм не очень часто, и только без order by. Единственный разумный способ пытаться использовать index merge — случаи выборки по разным столбцам с OR.
Еще одно отступление: подразумевается что читатель уже знаком с explain. Часто сам запрос немного модифицируется оптимизатором, поэтому для того, чтобы понять, почему использовался или нет тот или иной индекс, следует вызвать а затем который и покажет измененный оптимизатором запрос.
Покрывающий индекс — от толстых таблиц к индексам
Итак задача: пусть у нас есть довольно простой запрос, который выполняется довольно часто, но для такого частого вызова относительно медленно. Рассмотрим стратегию приведения нашего запроса к using index, как к наиболее быстрому выбору.
Следует указать на разницу в кешировании запросов в разных базах. Если PostgreSQL/Oracle кешируют планы запросов (как бы prepare for some timeout), то MySQL просто кеширует СТРОКУ запроса (включая значение параметров) и сохраняет результат запроса. То есть если последовательно селектировать несколько раз — то, если DDD не содержит изменяющихся функций, и таблица AAA не изменилась (в смысле используемой изоляции), результат будет взят прямо из кеша. Довольно спорное улучшение.
Что такое оптимизация запросов
Матиас Ярке, Юрген Кох
Оригинал: Matthias Jarke, Jurgen Koch. Query Optimization in Database Systems. Computing Surveys, Vol. 16, No. 2, June 1984
Оригинал можно посмотреть здесь
Предисловие переводчика
На протяжении последних тридцати лет эти факторы привлекают к данному направлению внимание сотен исследователей, опубликовавших тысячи статей, многие из которых доступны и/или интересны только профессионалам. Но некоторое знакомство с методами оптимизации запросов полезно гораздо более широкой аудитории: проектировщикам и администраторам систем баз данных, разработчикам приложений баз данных и даже пользователям этих приложений. Такое знакомство обеспечивают обзоры методов оптимизации. До сих пор русскоязычным читателям были доступны моя обзорная статья и перевод более современной обзорной статьи Сураджита Чаудхари.
Мне кажется, что для полноты картины очень полезно познакомится с еще более ранней статьей Ярке и Коха, перевод которой мы и предлагаем вашему вниманию. Перечитывая эту статью, я обнаружил в ней достоинства, которыми, к сожалению, не обладают более поздние обзоры: последовательность и систематичность. Авторы пытаются (и преуспевают в этом) представить последовательную картину процесса оптимизации запроса. В свое время меня раздражало то, что они ведут свое изложение не прямо в контексте языка SQL, а используют более абстрактное представление запросов на языке реляционного исчисления. Однако сейчас мне понятно, что этот подход позволил авторам отвлечься от не слишком существенных технических трудностей оптимизации, специфичных для языка SQL, и сосредоточиться на более фундаментальных методах оптимизации.
Для справедливости следует заметить, что в 1984 г. было гораздо проще написать фундаментальный обзор методов оптимизации, чем в настоящее время. За прошедшие 20 лет было разработано множество методов, существенной части которых нельзя отказать в фудаментальности. Поэтому в наше время очень трудно выбрать стиль изложения, позволяющий описать текущее состояние данного направления исследований в такой же последовательной и логичной манере, что я Ярке и Коха. Тем более рекомендую прочитать русский вариант этой замечательной статьи, которая лично на меня оказала очень серьезное влияние.
Содержание
Эффективные методы обработки непредвиденных запросов являются решающей предпосылкой успеха обобщенных систем управления базами данных. Предлагалось множество подходов к совершенствованию эффективности алгоритмов вычисления запросов: основанные на логике и семантические преобразования, быстрые реализации основных операций, комбинаторные и эвристические алгоритмы генерации возможных путей доступа и выбора между ними.
Эти методы представляются в каркасе общей процедуры вычисления запроса использованием для представления запросов реляционного исчисления. Кроме того, затрагиваются аспекты нестандартной оптимизации запросов, такие как вычисление запросов более высокого уровня, оптимизация запросов в распределенных базах данных и использование машин баз данных. Однако основное внимание уделяется оптимизации запросов в централизованных системах баз данных.
ВВЕДЕНИЕ
Системы управления базами данных (СУБД) стали стандартным инструментом экранирования пользователя компьютера от деталей управления вторичной памятью. СУБД разрабатываются для повышения производительности труда прикладных программистов и облегчения доступа к данным неискушенных в комьютерах конечных пользователей.
Вторая область интересов затрагивает безопасную и эффективную реализацию СУБД. Комьютеризоаванные данные становятся центральным ресурсом большинства организаций. Это должно учитываться в каждой реализации, предназначенной для производственного использования, путем гаранирования безопасности данных в случаях параллельного доступа [Bernstein and Goodman 1981c], восстановления [Verhofstad 1978] и реорганизации [Sockut and Goldberg 1979]. Одно из основных критических замечаний ко многим ранним СУБД относилось к отсутствию эффективности при обработке предлагаемых ими мощных операций, в особенности, доступа к данным на основе их содержимого через запросы. Оптимизация запросов предназначена для решения этой проблемы путем интеграции большого числа методов и стратегий, простирающихся от логических преобразований запросов до оптимизации путей доступа и хранения данных на уровне файловых систем.
Традиционно в каждом из этих подходов использовался отдельный язык. Вероятно, это является одной из причин, по которым до сих пор не представлен исчерпывающий обзор методов оптимизации запросов. Целью этой статьи является представление методов оптимизации запросов в общем каркасе реляционного исчисления. Показано, что реляционной исчисление технически эквивалентно представлению реляционной алгебры [Codd 1972; Klug 1982a] и поддается расширениям для реализации сетевых СУБД [Dayal and Goodman 1982]. Более того, многие популярные языки запросов, такие как SQL [Astrahan and Chamberlin 1975] и QUEL [Stonebraker et al. 1976], легко отображаются в реляционное исчисление.
Пользовательская оптимизация. Общая стоимость информационной системы составляется из стоимости СУБД и стоимости усилий пользователей для работы с системой. Граница между этими двумя областями состоит из функциональных возможностей и удобства использования языка запросов [Vassiliou and Jarke 1984], и наиболее важной характеристикой является время отклика системы. Если предположить, язык запросов обладает заданными функциональными возможностями, а минимизация времени отклика является целью системы выполнения запросов, то оптимизация запросов может считаться отдельно трактуемой подпроблемой пользовательской оптимизации.
Структуры файлов. Алгоритм оптимизации запросов должен производить выбор между множеством путей доступа для выполнения запроса. Внутренние детали реализации таких путей доступа и вывод соответствующих оценочных форму (см., например, Teorey and Fry [1982]) находятся за пределами этой статьи.
Статья состоит из шести разделов, расположенных в соответствии с подходом «сверху-вниз». В разд. 1 мы представляем глобальный каркас для оптимизации запросов. В разд. 2 мы сравниваем четыре метода представления запросов с точки зрения их пригодности для оптимизации. В разд. 3 мы используем один из этих методов, реляционное исчисление, для представления преобразований, основанных на логике, включая развивающиеся методы семантической оптимизации.
После преобразования запрос должен быть отображен в последовательность операций, возвращающих требуемые данные. В разд. 4 мы анализируем реализацию таких операций в низкоуровневой системе хранения данных и путей доступа. В разд. 5 мы представляем оптимизационные процедуры для интеграции этих операций в глобально оптимальный план доступа.
1. ПРОБЛЕМА ОПТИМИЗАЦИИ ЗАПРОСОВ
Точная оптимизация процедур вычисления запросов является, вообще говоря, вычислительно трудной, и еще больше мешает отсутствие точной статистической информации о базе данных. В алгоритмах вычисления запросов приходится в большой степени полагаться на эвристики. Тем не менее, в статье будет использоваться термин «оптимизация запросов» для обозначения стратегий, направленных на повышение эффективности процедур вычисления запросов. В этом разделе мы формулируем цели оптимизации запросов и представляем общую процедуру, разработанную для структуризации процесса поиска решения.
1.1 Запросы
Запросы используются в нескольких окружениях. Наиболее очевидно приложение, в котором поступают непосредственные запросы конечного пользователя, нуждающегося в информации о структуре или содержимом базы данных. Если потребности пользователей ограничены набором стандартных запросов, они могут оптимизироваться вручную путем программирования соответствующих процедур поиска и ограничения пользовательского ввода форматом меню. Однако, если требуется задавать непредвиденные запросы с использованием языка запросов общего назначения, становится необходимой система автоматической оптимизации запросов.
Второе применение запросов происходит в транзакциях, которые изменяют хранимые данные на основе их текущих значений (например, «повысить зарплату всем доцентам на 10%»). Наконец, выражения, подобные запросам, могут использоваться внутри СУБД, например, для проверки прав доступа [Griffiths and Wade 1976], поддержки ограничений целостности [Stonebraker 1975] и корректной синхронизации параллельного доступа [Reimer 1983].
1.2 Цели оптимизации
Чтобы допустить справедливое сравнение эффективности, функциональные возможности сравниваемых систем выполнения запросов должны быть сходными. Требование «реляционной полноты», придуманное Коддом [Codd 1972], (сравните с разд. 2.1) стало квазистандартом. Методы, обозреваемые в данной статье, представляются как вклады в реализацию запросов на реляционно полном языке с минимальной стоимостью выполнения или временем отклика. Запросы более высокого уровня сложности [Chandra and Harel 1982a] рассматриваются в разд. 6.1. Общая стоимость, подлежащая минимизации, складывается из следующих компонентов:
Стоимость коммуникаций: Стоимость передачи данных из места, в котором они хранятся, в места, где выполняются вычисления и представляются результаты. Эта стоимость состоит из стоимости коммуникационного канала, которая обычно связана с временем, в течение которого канал открыт, и стоимостью задержек в обработке, вызваемых передачей. Последний компонент, более важный для оптимизации запросов, часто полагается линейной функцией от объема передаваемых данных.
Стоимость доступа к вторичной памяти: Стоимость (или время) загрузки страниц данных из вторичной памяти в основную память. На эту стоимость влияет выбираемых данных (главным образом, размер промежуточных результатов), кластеризация данных на физических страницах, размер доступного буферного пространства и скорость используемых устройств.
Стоимость хранения: Стоимость занятия вторичной памяти и буферов основной памяти. Стоимость хранения уместна только в том случае, когда память становится узким местом системы, и размер требуемой памяти может изменяться от запроса к запросу.
Стоимость вычислений: Стоимость (или время) использования ЦП.
На структуру алгоритмов оптимизации запросов влияют соотношения между этими компонентами стоимости. В территориально распределенной СУБД с относительно медленными коммуникационными каналами преобладает стоимость коммуникацонных задержек, а другие факторы существенны только для локальной подоптимизации. В централизованных системах доминирует время доступа к вторичной памяти, хотя для сложных запросов достаточно высокой может быть и стоимость ЦП [Gotlieb 1975]. В локально распределенных СУБД все факторы имеют близкие веса, что приводит к очень сложным оценочным функциям и процедурам оптимизации.
Поскольку эта статья в основном посвящена централизованным базам данных, стоимость коммуникаций не принимается во внимание, потому что в таких системах комуникационные требования не зависят от стратегии выполнения запросов. Для оптимизации одиночных запросов стоимость хранения также считается не первостепенно важной. Эти расходы учитываются только при одновременной оптмизации нескольких запросов.
Остаются стоимость доступа ко вторичной памяти (обычно измеряемая числом обращения к страницам) и стоимость использования ЦП (часто измеряемая числом сравнений, которые требуется произвести). В основе большинства методов, разработанных для сокращения этой стоимости, лежит ряд общих идей: (1) избегать дублирования усилий; (2) использовать стандартизованные компоненты; (3) заглядывать вперед, чтобы избегать лишних операций; (4) выбирать наиболее дешевые способы выполнения элементарных операций; (5) выстраивать их последовательность оптимальным образом. Следующий простой пример показывает, что можно ожидать от оптимизации запросов.
Рассмотрим реляционную схему базы данных, описывающей служащих, предлагающих компьютерные лекции отделам географически распределенной организации:
Ключевые атрибуты подчеркнуты; заданная комбинация значений ключевых атрибутов уникально идентифицирует элемент отношения. Предположим, что пользователя интересуют «названия отделов, расположенных в Нью-Йорке и предлагающих курсы по управлению базами данных».
Имеется много возможных стратегий разрешения этого запроса, три из которых сравниваются по отношению к следующим предположениям относительно реальных значений данных. Заметим, что детальные данные, используемые в приводимых ниже вычислениях, обычно недоступны оптимизатору запросов, а должны оцениваться.
Имеется 100 отделов, 5 из которых размещаются в Нью-Йорке. В физическом блоке может поместиться 5 записей об отделах или 50 значений dname.
Имеется 500 курсов, 20 из которых посвящены управлению базами данных. В физическом блоке помещается 10 записей.
Первая представленная здесь стратегия следует прямому подходу трансляции выражения реляционного исчисления в операции алгебры [Codd 1972]. Вместе с каждым шагом стратегии приводится число обращений ко вторичной памяти, требующихся для чтения (r) и записи (w).
Исключительно высокая стоимость этой стратегии происходит из того факта, что она генерирует промежуточный результат, очень небольшая часть которого действительно существенна для дальнейшей обработки. Эффективность может быть существенно повышена путем рассмотрения только тех комбинаций элементов разных отношений, которые имеют одинаковые значения общих атрибутов. Путем использования существующих порядков сортировки, такие комбинации могут формироваться «слиянием» участвующих отношений. Эта операция называется «соединением».
Итого: Приблизительно 6000 обращений.
Стоимость ответа на запрос можно еще более сократить путем выполнения ограничений на основе значений как можно раньше и уменьшения за счет этого расходов на сортировку и слияние промежуточных результатов.
Итого: 277 обращений
Таким образом, было достигнуто сокращение стоимости приблизительно в 700 раз. Для больших баз данных и более сложных запросов более совершенные методы могут привести к еще большим сокращениям.
1.3 Нисходящий подход к оптимизации запросов
Потребность в работающих системах инициировала разработку полномасштабных процедур вычисления запросов, что повлияло на общность решений и заставило заниматься оптимизацией запросов в единообразной и эвристической манере [Astrahan and Chamberlin 1975; Makinouchi et al. 1981; Niebuhr et al. 1976; Palermo 1972; Schenk and Pinkert 1977; Wong and Youssefi 1976]. Поскольку часто это не позволяло достичь конкурентноспособной эффектвности систем, современной тенденцией представляется нисходящий подход, который обеспечивает возможность включения в общие процедуры большего знания о возможностях оптимизации в частных случаях. В то же время, сами общие алгоритмы усиливаются комбинаторными процедурами минимизации стоимости для выбора между стратегиями.
В этой статье мы придерживаемся нисходящего подхода, применяя общую процедуру вычисления, служащую каркасом для конкретных методов, разработанных при исследовании оптимизации запросов:
Шаг 1. Найти внутреннее представление запросов, в которое могут легко отображаться запросы пользователей, оставляющее системе все необходимые степени свободы для оптимизации выполнения запросов.
Шаг 2. Применить логические преобразования к представлению запроса, которые (1) стандартизируют запрос, (2) упрощают запрос, чтобы избежать дублирования усилий, (3) улучшают запрос для упрощения его выполнения и создания возможности применения процедур частных случаев.
Шаг 3. Отобразить преобразованный запросв в возможную последовательность элементарных операций, для которых известна хорошая реализация и соответсвующие оценки стоимости. В результате этого шага появляется набор возможных «планов доступа».
Шаг 4. Вычислить общую стоимость каждого плана доступа, выбрать наиболее дешевый план и выполнить его.
Первые два шага этой процедуры являются в большой степени независимыми и поэтому часто могут быть выполнены во время компиляции. Качество шагов 3 и 4, т.е. изобилие генерируемых планов доступа и оптимальность алгоритма выбора сильно зависит от знания значений в базе данных.
Последствия от зависимости от данных являются двоякими. Во-первых, если база данных изменчива, то шаги 3 и 4 могут быть выполнены только во время выполнения. Это означает, что возможный выигрыш в эффективности должен соотноситься со стоимостью самой оптимизации. Во-вторых, в метабазе данных (например, расширяемом справочнике данных) должна поддерживаться общая нформация о структуре базе данных, равно как и статистическая информация о содержимом базы данных. Как и во многих схожих операционных исследовательских проблемах (например, в управлении запасами) стоимость получения и поддержки этой добавочной информации должна сопоставляться с ее качеством.
2. ПРЕДСТАВЛЕНИЕ ЗАПРОСОВ
Запросы могут представляться в ряде форм. В контексте оптимизации запросов уместное представление запросов должно удовлетворять следующим требованиям: Оно должно быть достаточно мощным для выражения большого класса запросов и должно обеспечивать правильно построенный базис для преобразования запросов. В этом разделе мы представляем четыре разные формы представления запросов, каждая из которых используется в ряде походов к оптимизации запросов.
2.1 Реляционное исчисление
Выражение выборки специфицирует содержимое отношения, происходящего в результате выполнения запроса, средствами предикатов первого порядка (т.е. обобщенных булевских выражений, возможно, содержащих кванторы существования и всеобщности). В целевом списке определяются свободные переменные, встречающиеся в предикате, и специфицируется структура результирующего отношения. В Примере 2.1 демонстрируется представление реляционного исчисления с использованием синтаксиса языка программирования баз данных Pascal/R [Schmidt 1977].
Пример 2.1. Имена профессоров, опубликовавших какую-либо статью в 1981 г.
В целевом списке, т.е. подвыражении, предшествующем двоеточию, область определения (свободной) переменной e ограничивается элементами отношения «employees». Поэтому отношение «employees» называется отношением области определения (range relation) переменной e. Спецификация атрибута цели » » показывает, что в результате запроса останутся только имена служащих.
Кроме логической операции AND, в предикатах могут использоваться и операции OR и NOT. Предикаты реляционного исчисления полностью определяются следующими рекурсивными правилами:
Реляционное исчисление было введено в [Codd 1972] как мерило реляционной мощности. Форма представления называется реляционно полной, если в ней допускается определение результата любого запроса, определяемого выражением реляционного исчисления. Ясно, что реляционная полнота должна рассматриваться как минимальное требование в отношении выразительной мощности. Часто приводимым примером концептуально простого запроса, выходящим за пределы реляционной полноты, является запрос «найти имена служащих, отчитывающихся перед менеджером Смитом на любом уровне», предусматривающий, что в одном отношении моделируется иерархия служащий (через атрибуты name и manager) [Pirotte 1979]. Кроме того, запросы в сегодняшних приложениях часто содержат агрегации, которые неаозможно выразить в чистом реляционном исчислении. Однако реляционное исчисление довольно легко расширяется агрегатными функциями [Klug 1982b; Maier and Warren 1981].
2.2 Реляционная алгебра
Операция ограничения, примененная к отношению «rel», конструирует горизонтальное подмножество в соответствии с безкванторным предикатом, содержащим только одноместные термы или «внутриотношенческие» двуместные термы (сравнения между атрибутами одного элемента отошения):
Операция проекции служит для конструирования вертикального подмножества отношения «rel» путем выбора набора указанных атрибутов A и удаления кортежей-дубликатов из этих атрибутов:
Операция соединения позволяет соединять два отношения «rel1» и «rel2» в одно отношение, атрибуты которого являются объединением атрибутов «rel1» и «rel2«:
Допускаемые в соединениях операции сравнения «op» являются такими же, как в двуместных термах реляционного исчисления. Если «op» является операцией сравнения на равенство, в результате «естественного» соединения опускается A или B.
Операция деления является алгебраическим двойником квантора всеобщности. Она определяется следующим образом:
В Примере 2.2 представляется запрос Примера 2.1 в терминах реляционной алгебры.
Пример 2.2. Имена профессоров, опубликовавших какую-либо статью в 1981 г.
В противоположность выражению реляционного исчисления, которое описывает отношение, проиходящее из запроса, в терминах его свойств, выражение релционной алебры определяет алгоритм конструирования результирующего отношения. Выражение исчисления кажется лучшей стартовой точкой для оптимизации запросов, поскольку оно обеспечивает оптимизатор только базовыми свойствами запроса; возможности оптимизации могут быть скрыты в конкретной последовательности операций алгебры. Однако в отношении реляционной полноты реляционная алгебра, по меньшей мере, настолько же полна, как и реляционное исчисление. В [Codd 1972] показано, что любое выражение реляционного исчисления можно отрранслировать в эквивалентное выражение алгебры. Аналогичный результат для выражений алгебры и исчисления, расширенных агрегатыми функциями доказан Клугом [Klug 1982a].
2.3 Графы запросов
В объектных графах узлы представляют объекы, такие как переменные (отношений) и константы. Дуги описывают предикаты, которым эти объекты должны удовлетворять [Bernstein and Chiu 1981; Palermo 1972; Youssefi and Wong 1979]. Объектные графы содержат свойства результатов запросов и поэтому тесно связаны с реляционным исчислением. Графы операций описывают управляемые операциями потоки данных путем представления операций как узлов, связанных дугами, указывающими направление движения данных. В [Smith and Chang [1975]; Yao [1979] графы операций использовались для представления выражений алгебры. На рис. 1 и рис. 2 приведены примеры объектного графа и графа операций соответственно.
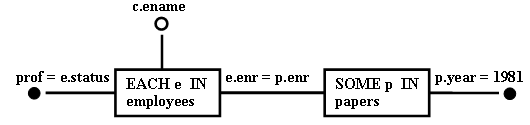
Рис. 1. Объектный граф, представляющий запрос из примера
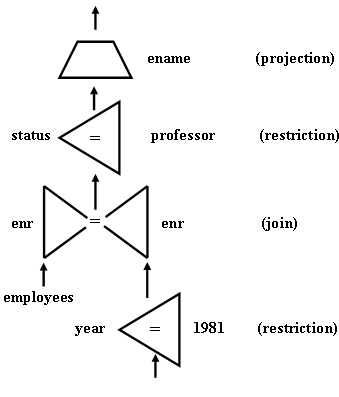
Рис. 2. Граф операций, представляющий запрос из примера
У графов запросов имеется много привлекательных свойств. Визуальное представление запроса способствует более простому пониманию его структурных характеристик. Кроме того, в теории графов имеется много результатов, полезных для автоматического анализа графов, например, обнаружение циклов и свойства древовидности. Наконец, важным достоинством графов запросов является то, что их легко расширять дополнительной информацией. Например, расширение графов деталями физической организации данных предложено в [Rosenthal and Reiner 1982].
2.4 Табло
Табло представлют собой специализированные матрицы, столбцы которых соответствуют атрибутам соответствующей схемы базы данных. Первая строка матрицы, сводка (summary), служит тем же целям, что целевой список выражения реляционного исчисления. Остальные строки описывают предикат. Символы, появляющиеся в табло, являются выделенными (distinguished) переменными (соответствующими свободным переменным), невыделенными (nondistinguished) переменными (соответствующими переменным под знаком квантора существования), константами, пробелами и тэгами (указывающими отношения областей определения).
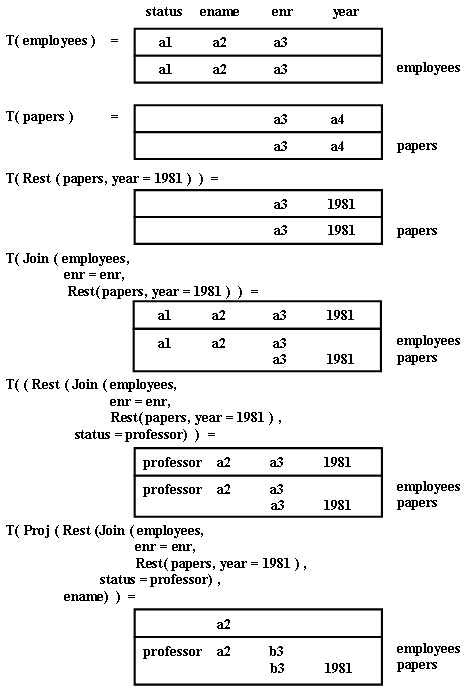
Рис. 3. Пошаговое конструирование табло T, представляющего запрос из Примера 2.1
Выражения, содержащие дизъюнкцию (объединение множеств) и отрицание (вычитание множеств) могут представляться наборами табло [Sagiv and Yannakakis 1980]. В [Klug 1983] и Johnson and Klug 1983] набора табло используются для представления общих конъюгктивных запросов. Конкретная значимость табло в отношении оптимизации запросов обсуждается в разд. 3.2.
3. ПРЕОБРАЗОВАНИЕ ЗАПРОСОВ
3.1 Стандартизация
Говорят, что представление запроса с использованием реляционного исчисления находится в предваренной нормальной форме (prenex normal form), если его выражение выборки имеет вид
находится в дизъюнктивной нормальной форме, а матрица, состоящая из конъюнкции дизъюнктов, такая как
находится в конъюнктивной нормальной форме
Предваренная нормальная форма с нормальными формами матрицы приводит к двум нормальным формам выражений реляционного исчисления: дизъюнктивной предваренной нормальной форме (disjunctive prenex normal form, DPNF) и конъюнктивной предваренной нормальной форме (conjunctive prenex normal form, СPNF). Использование DPNF мотивируется целью раздельной оптимизации и выполнения независимых компонентов запросов [Bernstein et al. 1981]. CPNF оказалась полезной для декомпозиции запросов [Wong and Youssefi 1976] и для зависящего от данных улучшения запроса (например, проверка в первую очередь наиболее ограничительного дизъюнта).
Запросы в CPNF могут подвергаться дальнейшему преобразованию к не содержащей кванторов форме, популярной в приложениях доказательства теорем искусственного интеллекта, к так называемой клаузальной форме (clausal form) [Nilsson 1982]. Языки баз данных, основанные на логике, такие как Prolog [Kowalski 1981], основываются на клаузальной форме. Поскольку клаузальная форма редко используется при оптимизации запросов (в качестве исключений см. Grant and Minker [1981], Jarke et al. [1984] и Warren [1981]) здесь мы опускаем подробности.
Преобразование произвольного выражения реляционного исчисления к предваренной нормальной форме состоит в перемещении кванторов по термам (справа налево). Перемещение кванторов управляется правилами преобразований, представленными в таб. 1. Нормализация матрицы может достигаться с применением правил ДеМоргана, правил дистрибутивности и правила двойного отрицания (см. таб. 2).

Таб. 1. Правила преобразований для выражений с кванторами

Таб. 2. Правила преобразований для общих выражений
Различия для случаев пустых и непустых отношений областей определения в правилах Q2 и Q3 таб. 1 возникают из-за изменчивости отношений во времени и многосортности реляционного исчисления [Jarke and Schmidt 1982]. Выражение реляционного исчисления может быть преобразовано к односортному исчислению путем введения области определения, такой как (r IN rel), как еще одного типа атомарного предиката:
Применение правил Q2a и Q3a при перемещение квантора из терма вызвало бы поэтому неверный результат в случае пустого отношения области определения. Из этого следует, что при нормализации произвольного выражения реляционного исчисления во время компиляции необходимо сохранять информацию об исходных определениях областей определения переменных, чтобы при необходимости во время выполнения можно было произвести модификации в соответствии с правилами Q2b и Q3b.
3.2 Упрощение
Избыточное выражение выражение может быть упрощено путем применения правил преобразования M4a-M4j, в которых учитывется идемпотентность (см. таб. 2). Применение этих правил усложняется тем фактом, что идемпотентность может встретиться на любом уровне выражения по причине наличия общих подвыражений, т.е. подвыражений, которые могут встретиться более одного раза в выражении, представляющем запрос. Поэтому, чтобы упростить, например, выражение
посредством правил M4d и M4g, сначала нужно распознать эквивалентность подвыражений
Алгоритмы приводятся в [Downey et al. 1980 и Hall 1974, 1976]. Распознавание общих подвыражений и применение правил идемпотентности должно выполняться скорее совместно, чем последовательно, поскольку при упрощении выражения на основе правил идемпотентности могут появиться новые общие подвыражения, которые, в свою очередь, являются предметом упрощения. Выражения, связанные с пустыми отношениями, также можно упрощать. Правила преобразований для их упрощения приводятся в таб. 3. (Заметим, что эти правила можно применять только во время выполнения.)
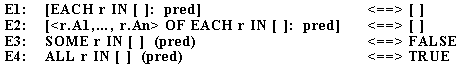
Таб. 3. Правила преобразований для выражений с пустыми отношениями
Термы, как они определены в разд. 2.1, в реляционном исчислении служат атомарными предикатами. Однако эти термы могут быть упрощены или удалены, если явно учитывается семантика операций сравнения. Важным приложением является так называемое распространение констант, в котором используются законы транзитивности, такие как
позволяющее сократить в запросе число двуместных термов. В алгоритмах минимизации числа строк в табло (см. разд. 2.4) систематически используются такие правила упрощения для конъюнктивных запросов [Aho et al. 1979a; Sagiv 1981, 1983]. Поскольку число строк в табло больше числа соединений (двуместных соединительных термов) в выражении, минимизация числа строк соответствует исключению избыточных соединений.
Сагив и Яннакакис [Sagiv and Yannakakis 1980] расширяют методы табло для обеспечения возможности упрощения выражений, содержащих дизъюнкты. Однако обобщение методов для всех выражений реляционно полного языка все еще остается открытой проблемой.
Заключительная возможность упрощения возникает в тех случаях, когда удается показать, что один или несколько конъюнктов матрицы стандартизованного запроса никогда не удовлетворяются [Eswaran et al. 1976; Klug 1983; Munz et al. 1979; Ozsoyoglu and Yu 1980]. Для примера рассмотрим выражение
3.3 Улучшение
Простейшими преобазованиями, рассматриваемыми в этом разделе, являются объединение последовательности проекций в одну проекцию и объединение последовательности ограничений в одно ограничение [Hall 1976; Smith and Chang 1975]. Соответствующими правилами преобразования являются следующие:
Объединение внутриотношенческих операций обеспечивает два преимущества. Во-первых, избегается повторяющееся чтение одного и того же отношения, и, во-вторых, существующие пути доступа могут использоваться для объединенной операции, а не только для первой операции последовательности.
Целью ряда улучшающих преобразований является минимизация размера конструируемых, сохраняемых и считываемых промежуточных результатов. Важная эвристика перемещает селективные операции, такие как ограничение и проекция, выше контруктивных операций, таких как соединение и декартово произведение, чтобы выполнять селективные операции как можно раньше [Smith and Chang 1975]. В контексте реляционного исчисления разбор некоторой последовательности вычислений может быть представлен вложенным выражением. Вычисление вложенного выражения начинается с вычисления наиболее внутреннего вложенного выражения, за которым следует непосредственно окружающее его выражение и т.д., пока не будет достигнуто наиболее внешнее выражение. Вложенное выражение, подразумевающее раннее вычисление одноместных термов (ограничений) приведено в Примере 3.1.
Пример 3.1. Вложенное выражение, эквивалентное выражению из Примера 2.1.
Ранее вычисление селективных операций представляет частный случай отсоединения запроса (query detachment), введенного Вонгом и Юссефи [Wong and Youssefi 1976]. Подвыражение, которое перекрывается с оставшейся частью запроса по одной переменной, отсоединяется и образует внутреннюю вложенность. Отсоединение выполняется рекурсивно на каждом уровне вложенности до тех пор, пока выражение не перестанет сокращаться. Эксперименты, описанные Юссефи и Вонгом [Wong and Youssefi 1979], показали, что это очень сильная эвристика. В Примере 3.2 демонстрируется отсоединение подвыражения сложного выражения.
Пример 3.2. Отделы, предлагающие лекции, проводимые профессорами, которые живут в том же городе, в котором находится отдел, и каждый из которых опубликовал какую-либо статью в 1981 г.
Вот эквивалентное выражение, произведенное путем отсоединения запроса:
Объектный граф, представляющий запрос, показан на рис. 4.
Заметим, что результирующее вложенное выражение является неразделимым [Goodman and Shmueli 1980]; т.е. его нельзя разделить на два подвыражения, перекрывающихся по одной переменной. Другими словами, вложенное выражение содержит цикл (см. рис. 4).
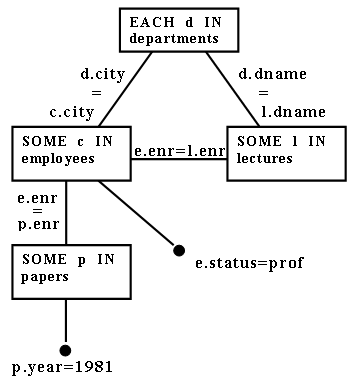
Рис 4. Объектный граф для Примера 3.2
Важность различения циклических и ациклических (древовидных) выражения для обработки запросов подробнее обсуждается в разд. 4.3. Пока мы лишь заметим, что бывают циклы, которые можно преобразовать к эквивалентным ациклическим графам. В число таких циклов входят те, которые (1) вводятся по транзитивности [Bernstein and Chiu 1981; Yu and Ozsoyoglu 1979], (2) содержат некоторые комбинации дуг, соотвествующих соединительным термам с условием сравнения на неравенство [Bernstein and Goodman 1981b; Ozsoyoglu and Yu 1980], (3) являются «замкнутыми» посредством переменных, связанных квантором всеобщности [Jarke and Koch 1983] и (4) содержат переменные, которые можно подвергнуть декомпозиции с использованием функциональных зависимостей [Kambayashi and Yoshikawa 1983].
Понятия расширенных выражений областей определения (extended range expressions) [Jarke and Schmidt 1982] и вложенных областей определения (range nesting) [Jarke and Koch 1983] обеспечивают обобщение отсоединения запросов, поскольку в них учитываются выражения с кванторами всеобщности. Отношения базы данных, задающие область определения кортежной переменной замещаются выражениями исчисления в соответствии со следующими правилами преобразований:
Заметим, что особенно полезно правило преобразования A5 для переменных, связанных квантором всеобщности, поскольку при сокращении числа конъюнктов на внешнем уровне вложенности можно ожидать существенного уменьшения размеров промежуточных результатов.
В представленных до сих пор улучшающих преобразованиях используется информация из трех источников: общие правила преобразования и эвристики, управляющие их применением, знание сруктур реляционных данных и сам запрос. Пока не рассмотрены два других источника знаний: ограничения целостности, которые во многих базах данных дополняют структурное определение схемы и реальные данных в базе данных.
Предположим, например, что ограничение целостости говорит: «Мы принимаем на работу только профессоров, которые публикуют, по крайней мере, одну статью в год». В этом случае вычисление запроса из Примера 2.1 (в котором спрашиваются имена профессоров со статьями в 1981 г.) становится тривиальным, а вычисление запроса из Примера 3.2 существенно упрощается.
Добавление ограничения целостности к выражению выборки может также изменить структуру запроса, делая его более приспособленным для обработки. Нассмотрим ограничение: «Мы принимаем на работу только местных профессоров». В этом случае терм «d.city = e.city» в примере 3.2 можно опустить. В объектном графе оставшегося запроса больше не содержится цикл.
Успех семантической обработки запросов сильно зависит от разработки эффективных эвристик для выбора между многими преобразованиями, делающими возможным добавление к запросу любой комбинации ограничений целостности. В [King 1981] и [Xu 1983] для принятия этого решения для специального класса реляционных баз данных используются правила в духе искусственного интеллекта.
Яо [Yao 1979] указывает, что существуют случаи, в которых оптимальное преобразование является зависимым от данных. Представленные выше эвристики могут быть не всегда оптимальными, особенно в тех случаях, когда некоторые пути доступа поддерживаются структурами физического хранения. Одним из последствий такой зависимости от данных является то, что средства преобразования запросов должны поддерживаться не только во время компиляции, но и во время выполнения. Кроме того, если эвристики не приносят удовлетворительных результатов, требуется одновременная оптимизация на физическом и логическом уровнях. Однако, прежде чем обратиться к таким интегрированным подходам, необходимо описать физическое выполнение компонентов запросов.



