Отказоустойчивость на уровне инфраструктуры
В инструкции рассматривается как повысить отказоустойчивость клиентского сервиса на физическом уровне.
Отказоустойчивость — свойство сервиса сохранять работоспособность и продолжать выполнение бизнес-задач даже в случае выхода из строя отдельных компонентов IT-инфраструктуры.
Степень отказоустойчивости сервиса зависит от типа выполняемых задач. Необходимость повышения отказоустойчивости появляется, когда ущерб от простоя превышает затраты на обеспечение бесперебойной работы. Например, с помощью сервиса предоставляется непрерывный доступ к важной информации, или сама работа компании напрямую зависит от бесперебойной работы IT-инфраструктуры.
Что обеспечивает Selectel
Selectel обеспечивает отказоустойчивость клиентского сервиса на уровне серверного зала, в котором стоят стойки с серверами. Для этого:
в серверный зал поступают вводы электропитания, зарезервированные на более высоких уровнях (трансформаторные подстанции Selectel; промышленные ИБП включающие АКБ; аварийный источник электроснабжения — ДГУ), далее, к каждой стойке подводится два независимых ввода питания:
для серверов с одним блоком питания в стойки устанавливаются АВР (устройства автоматического ввода резерва), к которым подведены два независимых ввода питания, при отключении одного ввода электричество продолжит поступать по второму; 
для серверов с двумя блоками питания их подключение выполняется в два независимых блока розеток; 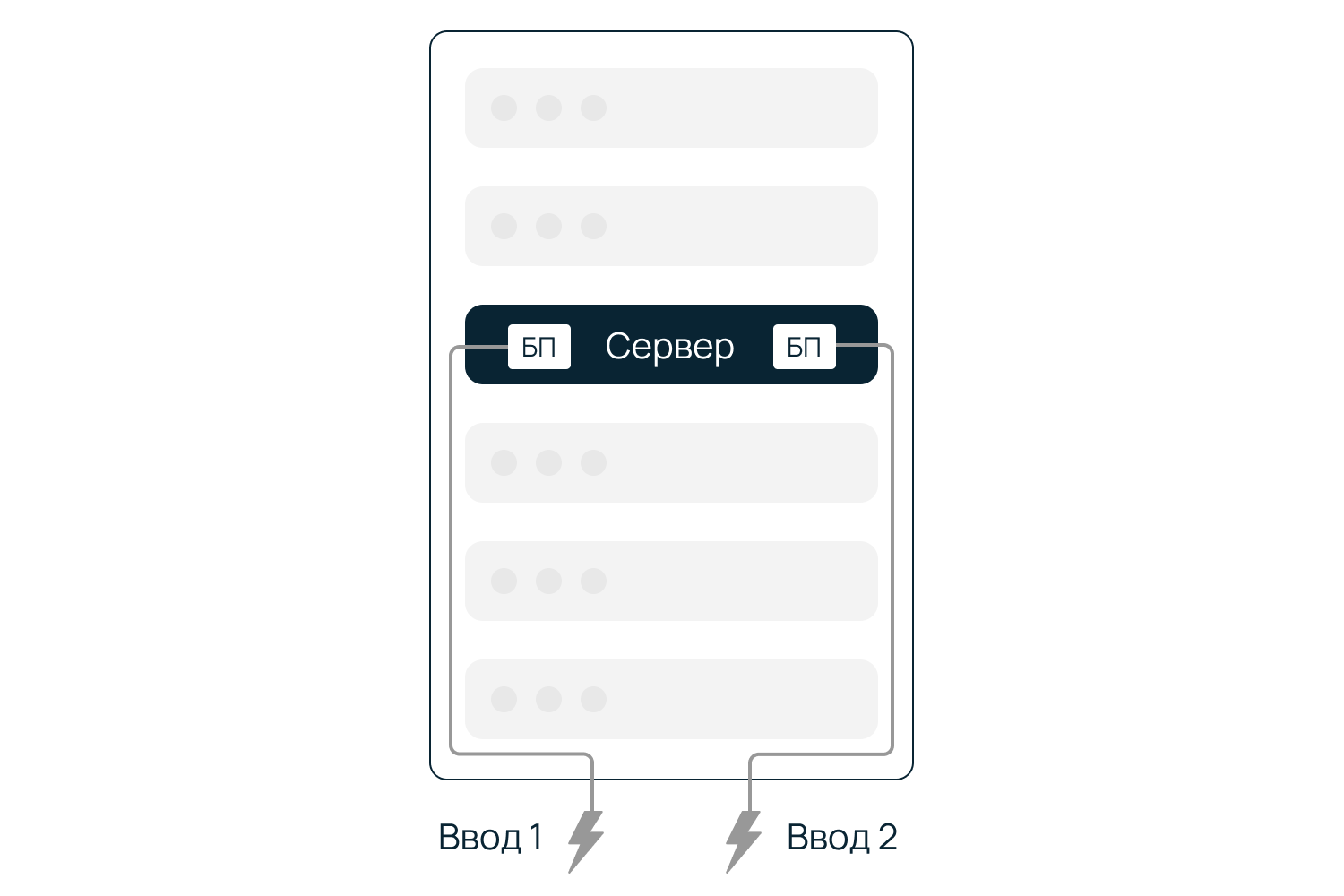
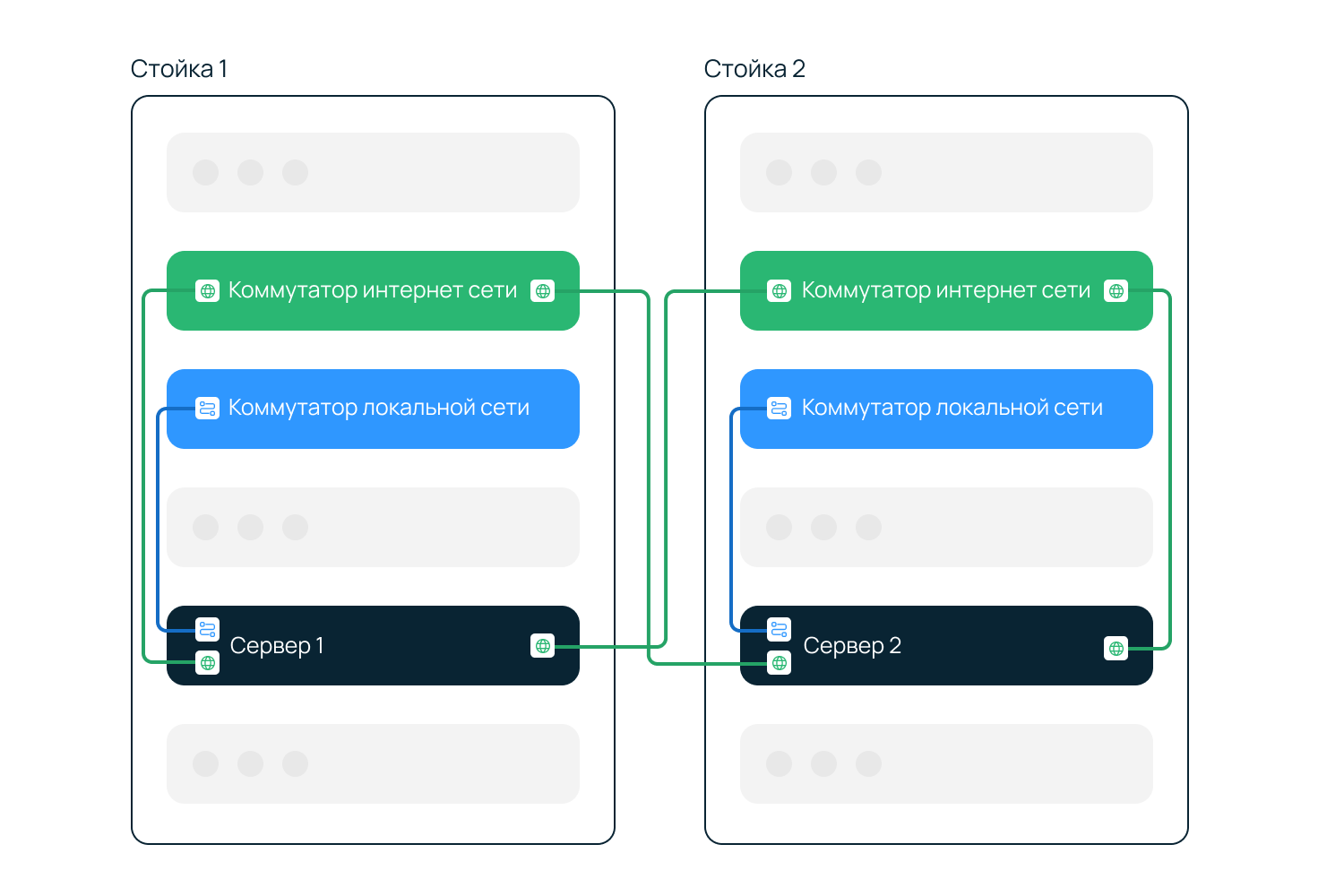
резервируется доступ к локальной и интернет-сети на уровне коммутатора агрегации (и выше), а также:
для серверов готовой конфигурации в каждой стойке устанавливаются коммутаторы доступа для локальной сети и интернет-коммутаторы; 
для серверов линейки Chipcore подключение к локальной сети отсутствует, в каждой стойке устанавливаются только интернет-коммутаторы; 
для серверов произвольной конфигурации резервирование подключения к нужной сети (локальной или интернет) определяется клиентом;
если есть техническая возможность, при заказе двух и более серверов они располагаются в разных стойках. Примечание: Просмотреть текущее расположение серверов и отправить запрос на перенос сервера в другую стойку можно в панели управления, раздел Серверы и оборудование ⟶ Серверы, вкладка Расположение серверов. Подробнее в инструкции Расположение по стойкам.
Повышение отказоустойчивости сервиса
Повысить отказоустойчивость клиентского сервиса на физическом уровне можно снижением количества вероятных точек отказа. При построении IT-инфраструктуры вероятными точками отказа могут стать:
Отказоустойчивость на уровне стойки
Для снижения количества вероятных точек отказа на уровне стойки можно:
Отказоустойчивость клиентского сервиса, состоящего из нескольких серверов
Для снижения количества вероятных точек отказа клиентского сервиса, размещенного на нескольких серверах, можно:
Отказоустойчивый кластер для балансировки нагрузки
Поговорим о горизонтальном масштабировании. Допустим, ваш проект вырос до размеров, когда один сервер не справляется с нагрузкой, а возможностей для вертикального роста ресурсов уже нет.
В этом случае дальнейшее развитие инфраструктуры проекта обычно происходит за счет увеличения числа однотипных серверов с распределением нагрузки между ними. Такой подход не только позволяет решить проблему с ресурсами, но и добавляет надежности проекту — при выходе из строя одного или нескольких компонентов его работоспособность в целом не будет нарушена.
Большую роль в этой схеме играет балансировщик — система, которая занимается распределением запросов/трафика. На этапе ее проектирования важно предусмотреть следующие ключевые требования:
Фактически, это описание кластера, узлами которого являются серверы-балансеры.
В этой статье мы хотим поделиться рецептом подобного кластера, простого и неприхотливого к ресурсам, концепцию которого успешно применяем в собственной инфраструктуре для балансировки запросов к серверам нашей панели управления, внутреннему DNS серверу, кластеру Galera и разнообразными микросервисам.
Договоримся о терминах:
— Серверы, входящие в состав кластера, будем называть узлами или балансерами.
— Конечными серверами будем называть хосты, на которые проксируется трафик через кластер.
— Виртуальным IP будем называть адрес, “плавающий” между всеми узлами, и на который должны указывать имена сервисов в DNS.
Что потребуется:
— Для настройки кластера потребуется как минимум два сервера (или вирт.машины) с двумя сетевыми интерфейсами на каждом.
— Первый интерфейс будет использоваться для связи с внешним миром. Здесь будут настроены реальный и виртуальный IP адреса.
— Второй интерфейс будет использоваться под служебный трафик, для общения узлов друг с другом. Здесь будет настроен адрес из приватной (“серой”) сети 172.16.0.0/24.
Вторые интерфейсы каждого из узлов должны находиться в одном сегменте сети.
Используемые технологии:
VRRP, Virtual Router Redundancy Protocol — в контексте этой статьи, реализация «плавающего» между узлами кластера виртуального IP адреса. В один момент времени такой адрес может быть поднят на каком-то одном узле, именуемом MASTER. Второй узел называется BACKUP. Оба узла постоянно обмениваются специальными heartbeat сообщениями. Получение или неполучение таких сообщений в рамках заданных промежутков дает основания для переназначения виртуального IP на “живой” сервер. Более подробно о протоколе можно прочитать здесь.
LVS, Linux Virtual Server — механизм балансировки на транспортном/сеансовом уровне, встроенный в ядро Linux в виде модуля IPVS. Хорошее описание возможностей LVS можно найти здесь и здесь.
Суть работы сводится к указанию того, что есть определенная пара “IP + порт” и она является виртуальным сервером. Для этой пары назначаются адреса реальных серверов, ответственных за обработку запросов, задается алгоритм балансировки, а также режим перенаправления запросов.
В нашей системе мы будем использовать Nginx как промежуточное звено между LVS и конечными серверами, на которые нужно проксировать трафик. Nginx будет присутствовать на каждом узле.
Для настроек VRRP и взаимодействия с IPVS будем использовать демон Keepalived, написанный в рамках проекта Linux Virtual Server.
КОНЦЕПЦИЯ
Система будет представлять собой связку из двух независимых друг от друга равнозначных узлов-балансеров, объединенных в кластер средствами технологии LVS и протокола VRRP.
Точкой входа для трафика будет являться виртуальный IP адрес, поднятый либо на одном, либо на втором узле.
Поступающие запросы LVS перенаправляет к одному из запущенных экземпляров Nginx — локальному или на соседнем узле. Такой подход позволяет равномерно размазывать запросы между всеми узлами кластера, т.е. более оптимально использовать ресурсы каждого балансера.

Работа Nginx заключается в проксировании запросов на конечные сервера. Начиная с версии 1.9.13 доступны функции проксирования на уровне транспортных протоколов tcp и udp.
Каждый vhost/stream будет настроен принимать запросы как через служебный интерфейс с соседнего балансера так и поступающие на виртуальный IP. Причем даже в том случае, если виртуальный IP адрес физически не поднят на данном балансере (Keepalived назначил серверу роль BACKUP).
Таким образом, схема хождения трафика в зависимости от состояния балансера (MASTER или BACKUP) выглядит так:
РЕАЛИЗАЦИЯ:
В качестве операционной системы будем использовать Debian Jessie с подключенными backports репозиториями.
Установим на каждый узел-балансер пакеты с необходимым для работы кластера ПО и сделаем несколько общесистемных настроек:
На интерфейсе eth1 настроим адреса из серой сети 172.16.0.0/24 :
Виртуальный IP адрес прописывать на интерфейсе eth0 не нужно. Это сделает Keepalived.
В файл /etc/sysctl.d/local.conf добавим следующие директивы:
Первая включает возможность слушать IP, которые не подняты локально (это нужно для работы Nginx). Вторая включает автоматическую защиту от DDoS на уровне балансировщика IPVS (при нехватке памяти под таблицу сессий начнётся автоматическое вычищение некоторых записей). Третья увеличивает размер conntrack таблицы.
В /etc/modules включаем загрузку модуля IPVS при старте системы:
Параметр conn_tab_bits определяет размер таблицы с соединениями. Его значение является степенью двойки. Максимально допустимое значение — 20.
Кстати, если модуль не будет загружен до старта Keepalived, последний начинает сегфолтиться.
Теперь перезагрузим оба узла-балансера. Так мы убедимся, что при старте вся конфигурация корректно поднимется.
Общие настройки выполнены. Дальнейшие действия будем выполнять в контексте двух задач:
Вводные данные:
Начнем с конфигурации Nginx.
Добавим описание секции stream в /etc/nginx/nginx.conf :
И создадим соответствующий каталог:
Настройки для веб-серверов добавим в файл /etc/nginx/sites-enabled/web_servers.conf
Настройки для DNS-серверов добавим в файл /etc/nginx/stream-enabled/dns_servers.conf
Далее остается сконфигурировать Keepalived (VRRP + LVS). Это немного сложнее, поскольку нам потребуется написать специальный скрипт, который будет запускаться при переходе узла-балансера между состояниями MASTER/BACKUP.
При переходе в состояние MASTER, скрипт удаляет это правило.
Настройки LVS для группы веб-серверов:
Настройки LVS для группы DNS-серверов:
В завершении перезагрузим конфигурацию Nginx и Keepalived:
ТЕСТИРОВАНИЕ:
Посмотрим как балансировщик распределяет запросы к конечным серверам. Для этого на каждом из веб-серверов создадим index.php с каким-нибудь простым содержимым:
И сделаем несколько запросов по http к виртуальному IP 192.168.0.100 :
Если в процессе выполнения этого цикла посмотреть на статистику работы LVS (на MASTER узле), то мы можем увидеть следующую картину:
Здесь видно как происходит распределение запросов между узлами кластера: есть два активных соединения, которые обрабатываются в данный момент и 6 уже обработанных соединений.
Статистику по все соединениям, проходящим через LVS, можно посмотреть так:
Здесь, соответственно, видим то же самое: 2 активных и 6 неактивный соединений.
ПОСЛЕСЛОВИЕ:
Предложенная нами конфигурация может послужить отправным пунктом для проектирования частного решения под конкретный проект со своими требованиями и особенностями.
Если у вас возникли вопросы по статье или что-то показалось спорным — пожалуйста, оставляйте свои комментарии, будем рады обсудить.
Как мы обеспечиваем отказоустойчивость работы инфраструктуры наших клиентов
Добрый день, уважаемые Хабраюзеры.
В данном посте я хотел бы рассказать подробнее о том, как мы обеспечиваем отказоустойчивость работы инфраструктуры наших клиентов.
Для примера взят стандартный офис (ПК, IP-телефония, WiFi) с разбивкой на подсистемы: ClientCloud, ClientLan, ClientPhone, ClientWiFi
Подсистема ClientLan предназначена для организации доступа ПК к другим подсистемам.
Подсистема ClientPhone предназначена для организации доступа IP-телефонов к подсистеме ClientCloud (IP-АТС).
Подсистема ClientWiFi предназначена для организации гостевого доступа мобильного оборудования (ноутбуки, коммуникаторы, планшетные компьютеры) к сети Интернет.
Доступ с подсистемы ClientWiFi ко всем подсистемам (ClientCloud, ClientLan, ClientPhone) запрещен настройками коммутатора.


В целях отказоустойчивости связи оборудования с подсистемой облака клиента предусматриваются две линии связи – основная (канал L2) и резервная (VPN через Интернет). Оборудование, расположенное на узле ЛВС в целях обеспечения бесперебойной работы сети подключается к источнику бесперебойного питания. Для создания отказоустойчивой системы коммутаторы объединяются в стек – Stacking Switch.
Узел ЛВС на Объекте включает в себя:
-активное оборудование уровня коммутации ЛВС;
-пассивное оборудование кроссирования портов;
-пассивное оборудование для организации размещения патч-кордов;
-пассивное оборудование для монтажа
Подключение объекта к сети производится при помощи двух независимых каналов связи – L2 (основной канал) и VPN через интернет (резервный). Логическая схема представлена на рисунке. Для обеспечения наибольшей отказоустойчивости операторы L2 и оператор сети интернет различны, либо используется независимое (различное) активное оборудование оператора. Доступ к сети интернет для ПК, принтеров, IP-телефонов, сети устройств Wi-Fi и других устройств происходит посредством данного подключения к сети интернет.

При пропадании основного канала L2 происходит переключение таблицы маршрутизации на коммутаторе третьего уровня, и трафик начинает проходить через резервный канал – VPN-канал. Данное переключение происходит посредством динамического протокола маршрутизации RIP версии 2.
При потере канала с доступом в интернет, основной канал остается в работе. Пропадает возможность поднятия резервного VPN-канала, а так же доступ в сеть интернет для пользователей ПК и устройств Wi-Fi сети.
Организация VPN канала происходит посредством существующего подключения к сети интернет через оператора связи. Защищенный VPN организуется посредством аппаратной реализации, используя оборудование Cisco ASA5505, задействовав технологии Site-to-site, IPsec.
Схема отказоустойчивости коммутаторов
Коммутаторы, расположенные в серверной стойке, для обеспечения отказоустойчивости объединяются в стек StackingSwitch. Это достигается перекрестным соединением портов стекирования таким образом, что при выходе из строя любого коммутатора, оставшиеся будут друг для друга доступны по альтернативному пути. Соединения внешней сети L2 и канала VPN подключаются в разные коммутаторы, для сохранения подключения к сети при выходе из строя коммутатора. Переключение прохождения трафика происходит полностью в автоматическом режиме.

Коммутаторы доступа обслуживают следующие подсистемы: ClientLan, ClientPhone и ClientWiFi. Подключение персональных компьютеров осуществляется на коммутаторы Switch1 (Extreme Summit X440-48t) и Switch2 (Extreme Summit X440-48t). IP-телефоны, используя технологию PoE, коммутируются на Switch3 и Switch4 (Extreme Summit X440-48p). Подсистема ClientWiFi на данных коммутаторах присутствует логически и подключается через контроллер Wi-Fi на порт коммутатора Switch3.
Для каждой подсистемы выделен свой VLAN и своя подсеть. Каждая подсистема имеет свой список доступа к другим подсетям (подсистемам).
При отказе одного из коммутаторов произойдет потеря связи только у ПК, непосредственно подключенных к данному коммутатору, не повлияв на работоспособность остальных. При выходе из строя коммутатора Switch1 (или канала L2) связь с подсистемой ClientCloud останется по каналу VPN. При отказе коммутатора Switch2 будет использоваться основной канал L2. При выходе из строя коммутатора Switch3 часть телефонов отключится, однако, кроссировкой предусмотрено, что в одном кабинете телефоны кроссируются на разные коммутаторы Switch3 и Switch4, и поэтому кабинет без связи не останется, т.е. часть телефонов будут работать.
После замены вышедшего коммутатора и ввода его в стек, к нему применяется единая стековая конфигурация. На случай выхода из строя коммутаторов или портов, к которым подключены магистрали, в стеке предусмотрены порты-партнеры, которые позволят, вручную переключив магистральный кабель, возобновить работу именно через необходимый канал.
Схема подключения подсистем к коммутаторам
Таким образом схема подключения клиента строиться так, что каждая подсистема выделена в свой VLAN и свою подсеть, что гарантирует защиту от негативного влияния одной сети на другую (вирус, большая нагрузка) и обеспечивает контроль доступа по сетям.
Обзор вариантов реализации отказоустойчивых кластеров: Stratus, VMware, VMmanager Cloud

Есть разновидности бизнеса, где перерывы в предоставлении сервиса недопустимы. Например, если у сотового оператора из-за поломки сервера остановится биллинговая система, абоненты останутся без связи. От осознания возможных последствий этого события возникает резонное желание подстраховаться.
Мы расскажем какие есть способы защиты от сбоев серверов и какие архитектуры используют при внедрении VMmanager Cloud: продукта, который предназначен для создания кластера высокой доступности.
Предисловие
В области защиты от сбоев на кластерах терминология в Интернете различается от сайта к сайту. Для того чтобы избежать путаницы, мы обозначим термины и определения, которые будут использоваться в этой статье.
На первый взгляд самый привлекательный вариант для бизнеса тот, когда в случае сбоя обслуживание пользователей не прерывается, то есть кластер непрерывной доступности. Без КНД никак не обойтись как минимум в задачах уже упомянутого биллинга абонентов и при автоматизации непрерывных производственных процессов. Однако наряду с положительными чертами такого подхода есть и “подводные камни”. О них следующий раздел статьи.
Continuous availability / непрерывная доступность
Бесперебойное обслуживание клиента возможно только в случае наличия в любой момент времени точной копии сервера (физического или виртуального), на котором запущен сервис. Если создавать копию уже после отказа оборудования, то на это потребуется время, а значит, будет перебой в предоставлении услуги. Кроме этого, после поломки невозможно будет получить содержимое оперативной памяти с проблемной машины, а значит находившаяся там информация будет потеряна.
Для реализации CA существует два способа: аппаратный и программный. Расскажем о каждом из них чуть подробнее.
Программный способ.
На момент написания статьи самый популярный инструмент для развёртывания кластера непрерывной доступности — vSphere от VMware. Технология обеспечения Continuous Availability в этом продукте имеет название “Fault Tolerance”.
В отличие от аппаратного способа данный вариант имеет ограничения в использовании. Перечислим основные:
Мы не стали расписывать конкретные конфигурации нод: состав комплектующих в серверах всегда зависит от задач кластера. Сетевое оборудование описывать также смысла не имеет: во всех случаях набор будет одинаковым. Поэтому в данной статье мы решили считать только то, что точно будет различаться: стоимость лицензий.
Стоит упомянуть и о тех продуктах, разработка которых остановилась.
Есть Remus на базе Xen, бесплатное решение с открытым исходным кодом. Проект использует технологию микроснэпшотов. К сожалению, документация давно не обновлялась; например, установка описана для Ubuntu 12.10, поддержка которой прекращена в 2014 году. И как ни странно, даже Гугл не нашёл ни одной компании, применившей Remus в своей деятельности.
Предпринимались попытки доработки QEMU с целью добавить возможность создания continuous availability кластера. На момент написания статьи существует два таких проекта.
Первый — Kemari, продукт с открытым исходным кодом, которым руководит Yoshiaki Tamura. Предполагается использовать механизмы живой миграции QEMU. Однако тот факт, что последний коммит был сделан в феврале 2011 года говорит о том, что скорее всего разработка зашла в тупик и не возобновится.
Второй — Micro Checkpointing, основанный Michael Hines, тоже open source. К сожалению, уже год в репозитории нет никакой активности. Похоже, что ситуация сложилась аналогично проекту Kemari.
Таким образом, реализации continuous availability на базе виртуализации KVM в данный момент нет.
Итак, практика показывает, что несмотря на преимущества систем непрерывной доступности, есть немало трудностей при внедрении и эксплуатации таких решений. Однако существуют ситуации, когда отказоустойчивость требуется, но нет жёстких требований к непрерывности сервиса. В таких случаях можно применить кластеры высокой доступности, КВД.
High availability / высокая доступность
В контексте КВД отказоустойчивость обеспечивается за счёт автоматического определения отказа оборудования и последующего запуска сервиса на исправном узле кластера.
В КВД не выполняется синхронизация запущенных на нодах процессов и не всегда выполняется синхронизация локальных дисков машин. Стало быть, использующиеся узлами носители должны быть на отдельном независимом хранилище, например, на сетевом хранилище данных. Причина очевидна: в случае отказа ноды пропадёт связь с ней, а значит, не будет возможности получить доступ к информации на её накопителе. Естественно, что СХД тоже должно быть отказоустойчивым, иначе КВД не получится по определению.
Таким образом, кластер высокой доступности делится на два подкластера:
VMmanager Cloud
Наше решение VMmanager Cloud использует виртуализацию QEMU-KVM. Мы сделали выбор в пользу этой технологии, поскольку она активно разрабатывается и поддерживается, а также позволяет установить любую операционную систему на виртуальную машину. В качестве инструмента для выявления отказов в кластере используется Corosync. Если выходит из строя один из серверов, VMmanager поочерёдно распределяет работавшие на нём виртуальные машины по оставшимся нодам.
В упрощённой форме алгоритм такой:
Практика показывает, что лучше выделить одну или несколько нод под аварийные ситуации и не развёртывать на них ВМ в период штатной работы. Такой подход исключает ситуацию, когда на “живых” нодах в кластере не хватает ресурсов, чтобы разместить все виртуальные машины с “умершей”. В случае с одним запасным сервером схема резервирования носит название “N+1”.
Рассмотрим по каким схемам пользователи VMmanager Cloud реализовывали кластеры высокой доступности.
FirstByte
Компания FirstByte начала предоставлять облачный хостинг в феврале 2016 года. Изначально кластер работал под управлением OpenStack. Однако отсутствие доступных специалистов по этой системе (как по наличию так и по цене) побудило к поиску другого решения. К новому инструменту для управления КВД предъявлялись следующие требования:
Отличительные черты кластера:
Данная конфигурация подходит для хостинга сайтов с высокой посещаемостью, для размещения игровых серверов и баз данных с нагрузкой от средней до высокой.
FirstVDS
Компания FirstVDS предоставляет услуги отказоустойчивого хостинга, запуск продукта состоялся в сентябре 2015 года.
К использованию VMmanager Cloud компания пришла из следующих соображений:
В случае общего отказа Infiniband-сети связь между хранилищем дисков ВМ и вычислительными серверами выполняется через Ethernet-сеть, которая развёрнута на оборудовании Juniper. “Подхват” происходит автоматически.
Благодаря высокой скорости взаимодействия с хранилищем такой кластер подходит для размещения сайтов со сверхвысокой посещаемостью, видеохостинга с потоковым воспроизведением контента, а также для выполнения операций с большими объёмами данных.
Эпилог
Подведём итог статьи. Если каждая секунда простоя сервиса приносит значительные убытки — не обойтись без кластера непрерывной доступности.
Однако если обстоятельства позволяют подождать 5 минут пока виртуальные машины разворачиваются на резервной ноде, можно взглянуть в сторону КВД. Это даст экономию в стоимости лицензий и оборудования.
Кроме этого не можем не напомнить, что единственное средство повышения отказоустойчивости — избыточность. Обеспечив резервирование серверов, не забудьте зарезервировать линии и оборудование передачи данных, каналы доступа в Интернет, электропитание. Всё что только можно зарезервировать — резервируйте. Такие меры исключают единую точку отказа, тонкое место, из-за неисправности в котором прекращает работать вся система. Приняв все вышеописанные меры, вы получите отказоустойчивый кластер, который действительно трудно вывести из строя.
Если вы решили, что для ваших задач больше подходит схема высокой доступности и выбрали VMmanager Cloud как инструмент для её реализации, к вашим услугам инструкция по установке и документация, которая поможет подробно ознакомиться с системой. Желаем вам бесперебойной работы!
P. S. Если у вас в организации есть аппаратные CA-серверы — напишите, пожалуйста, в комментариях кто вы и для чего вы их используете. Нам действительно интересно услышать для каких проектов использование такого оборудование экономически целесообразно 🙂



