Введение в технологию Translation Memory
База переводов — это база данных, в которой хранятся сегменты текста на исходном языке и их перевод («единицы перевода». Сегменты обычно представляют собой целые предложения, но могут быть короче (например, одно слово в ячейке документа Microsoft Excel) или длиннее (например, целый параграф).
Базы переводов постепенно пополняются по мере перевода: вы начинаете работать с пустой базой, и она увеличивается, предложение за предложением, с течением месяцев и лет. Базу переводов также можно создать на основе существующих ресурсов.
Когда вы работаете, в базе переводов выполняется поиск таких же или похожих сегментов, которые вы уже ранее переводили — это ускоряет вашу работу и позволяет поддерживать единообразие переводов. Новые переведенные сегменты добавляются в базу переводов.
Зачем использовать базу переводов?
Дело не только в концепции «Никогда не придется переводить одно и то же предложение дважды».
Использование базы переводов имеет множество преимуществ.
Представьте, что вы переводите инструкции для стиральной машины. Через год та же самая компания присылает вам на перевод руководство для новой модели. Некоторый текст совпадет полностью, в некоторые части будут внесены незначительные изменения, остальной текст будет новым. Из вашей базы переводов подставятся точные (100%) совпадения, будут найдены похожие сегменты («неточные совпадения»), а оставшиеся сегменты вам необходимо будет перевести с нуля.
Если вы один раз придумаете, как перевести какую-то хитрую фразу, в последующем вы сможете вспомнить свой вариант через базу переводов. Это может быть ваша находка, предпочтение заказчика или устойчивая фраза. Какой бы ни была причина, благодаря базе переводов вы сможете последовательно использовать перевод.
Совпадения на уровне подсегментов в базах переводов доступны в SDL Trados Studio благодаря функции автоматических подсказок. Если вы переводите в тематике программного обеспечения, фраза «Зажмите клавишу Ctrl», например, будет встречаться достаточно часто, но остальная часть предложения может отличаться слишком сильно, чтобы в базе переводов было найдено хорошее неточное совпадение. Функция AutoSuggest 2.0 в SDL Trados Studio предложит эти важные фрагменты по мере ввода текста.
Даже если система не предлагает вам неточные совпадения из базы переводов или автоматические подсказки, вы можете выполнить поиск одного или нескольких слов из исходного текста и увидеть, как вы переводили их ранее. В SDL Trados Studio эта функция известна как поиск-конкорданс. Она похожа на функции глоссария, но в качестве дополнительного преимущества вы видите слова в контексте и знаете, когда и в какой ситуации они были переведены таким образом. Проверьте, как вы переводили трудные слова и фразы в прошлом, запустив автоматический поиск-конкорданс.
Как создать память переводов и использовать ее в проектах?
Translation Memory
Помимо ускорения процесса перевода повторяющихся фрагментов и изменений, внесенных в уже переведенные тексты (например, новых версий программных продуктов или изменений в законодательстве), системы ПП также обеспечивают единообразие перевода терминологии в одинаковых фрагментах, что особенно важно при техническом переводе. С другой стороны, если переводчик регулярно подставляет в свой перевод точные соответствия, извлеченные из баз переводов, без контроля их использования в новом контексте, качество переведенного текста может ухудшиться.
В каждой конкретной системе ПП данные хранятся в своем собственном формате (текстовый формат в Wordfast, база данных Access в Deja Vu), но существует международный стандарт TMX (англ. Translation Memory eXchange format ), который основан на XML и который может генерироваться практически всеми системами ПП. Благодаря этому сделанные переводы можно использовать в разных приложениях, то есть переводчик работающий с OmegaT может использовать ПП, созданную в ТРАДОСе и наоборот.
Большинство систем ПП как минимум поддерживают создание и использование словарей пользователя, создание новых баз данных на основе параллельных текстов (англ. alignment ), а также полуавтоматическое извлечение терминологии из оригинальных и параллельных текстов.
Содержание
Популярные программные системы ПП
В английской википедии есть список, сравнивающий возможности различных систем.
Стандарты и форматы памяти переводов [4]
См. также
Ссылки
Полезное
Смотреть что такое «Translation Memory» в других словарях:
Translation memory — A translation memory, or TM, is a type of database that stores segments that have been previously translated. A translation memory system stores the words, phrases and paragraphs that have already been translated and aid human translators. The… … Wikipedia
Translation Memory — Ein Übersetzungsspeicher (auch Übersetzungsarchiv; engl. translation memory, abgekürzt TM) ist eine (in der Regel die Haupt )Komponente von Anwendungen zur rechnerunterstützten Übersetzung (Computer aided translation, abgekürzt CAT).… … Deutsch Wikipedia
Translation memory — Память переводов (ПП, англ. translation memory, TM иногда называемая «Накопитель переводов») база данных, содержащая набор ранее переведенных текстов. Одна запись в такой базе данных соответствует сегменту или «единице перевода» (англ.… … Википедия
translation memory — vertimo atmintis statusas T sritis informatika apibrėžtis ↑Duomenų bazė, kurioje laikomi teksto segmentai ir jų vertimai tam, kad vertimus būtų galima panaudoti iš naujo. Teksto segmentas paprastai atitinka pastraipą, sakinį, frazę, rečiau – žodį … Enciklopedinis kompiuterijos žodynas
Translation Memory eXchange — (TMX) ist ein offenes Datenformat, das zum Datenaustausch zwischen verschiedenen Übersetzungsprogrammen (Übersetzungsspeicher, engl. translation memory) dient. Es basiert auf XML und stellt Translation Memory Daten (d. h. vor allem die… … Deutsch Wikipedia
Translation Memory eXchange — TMX (Translation Memory eXchange) is an open XML standard for the exchange of translation memory data created by computer aided translation and localization tools. TMX is developed and maintained by OSCAR [ [http://www.lisa.org/sigs/oscar/ OSCAR] … Wikipedia
Translation Memory eXchange — TMX (Translation Memory eXchange Обмен памятью переводов) открытый формат файлов XML для обмена данными памяти переводов, которые создаются в процессе автоматизированного перевода. Формат TMX разработан и поддерживается группой… … Википедия
Translation Memory eXchange — TMX formatas statusas T sritis informatika apibrėžtis ↑Vertimo atminties ↑XML kalbos pagrindo standartizuotas formatas. Sukurtas 1998 m. Lokalizavimo pramonės standartų asociacijos (LISA) darbo grupės. Pagrindinė formato paskirtis – vertimo… … Enciklopedinis kompiuterijos žodynas
Memory management unit — This 68451 MMU could be used with the Motorola 68010 A memory management unit (MMU), sometimes called paged memory management unit (PMMU), is a computer hardware component responsible for handling accesses to memory requested by the CPU. Its… … Wikipedia
Translation — For other uses, see Translation (disambiguation). Translator redirects here. For other uses, see Translator (disambiguation). Contents 1 Etymology 2 Theory … Wikipedia
Память переводов
Содержание
Описание
Одна запись в такой базе данных соответствует сегменту или «единице перевода» (англ. translation unit ), за которую обычно принимается одно предложение (реже — часть сложносочинённого предложения, либо абзац). Если единица перевода исходного текста в точности совпадает с единицей перевода, хранящейся в базе (точное соответствие, англ. exact match ), она может быть автоматически подставлена в перевод. Новый сегмент может также слегка отличаться от хранящегося в базе (нечёткое соответствие, англ. fuzzy match ). Такой сегмент может быть также подставлен в перевод, но переводчик будет должен внести необходимые изменения.
Помимо ускорения процесса перевода повторяющихся фрагментов и изменений, внесенных в уже переведенные тексты (например, новых версий программных продуктов или изменений в законодательстве), системы ПП также обеспечивают единообразие перевода терминологии в одинаковых фрагментах, что особенно важно при техническом переводе. С другой стороны, если переводчик регулярно подставляет в свой перевод точные соответствия, извлеченные из баз переводов, без контроля их использования в новом контексте, качество переведенного текста может ухудшиться.
В каждой конкретной системе ПП данные хранятся в своем собственном формате (текстовый формат в Wordfast, база данных Access в Deja Vu), но существует международный стандарт TMX (англ. Translation Memory eXchange format ), который основан на XML и который может генерироваться практически всеми системами ПП. Благодаря этому сделанные переводы можно использовать в разных приложениях, то есть переводчик работающий с OmegaT может использовать ПП, созданную в ТРАДОСе и наоборот.
Большинство систем ПП как минимум поддерживают создание и использование словарей пользователя, создание новых баз данных на основе параллельных текстов (англ. alignment ), а также полуавтоматическое извлечение терминологии из оригинальных и параллельных текстов.
Популярные программные системы ПП
В соответствии с обзорами использования систем ПП к наиболее популярным системам относятся [1] [2] :
В английской Википедии есть список, сравнивающий возможности различных систем.
В чем ее преимущества? А также почему так выгодно использовать TM?
Содержание статьи:

Что такое память переводов?
Память переводов (англ. Translation memory, TM, иногда также называемая «накопитель переводов») – это база данных, содержащая набор ранее переведенных сегментов текста.
Одна запись в базе данных памяти переводов (TM) соответствует сегменту, или «единице перевода» (англ. Translation unit), за которую обычно принимается одно предложение (реже – часть сложносочиненного предложения, абзац, значение в ячейке таблицы или обособленная подпись к рисунку).

Каждый переведенный сегмент попадет в память переводов заказчика. Как только данный сегмент обнаруживается вновь, его перевод подставляется из накопленной памяти переводов автоматически. Переводчику или редактору останется только подтвердить корректность подстановки. Такая подстановка возможна как из переводов, выполненных ранее, так и из той части переводимого документа, работа с которой уже завершена. Это существенно сокращает время и, как итог, стоимость и срок выполнения всего перевода.
Как формируется память переводов (TM)?
Память переводов накапливается с помощью специального программного обеспечения. Это происходит как в процессе перевода, так и путем формирования вручную из пары документов на исходном языке и языке перевода.
В процессе перевода накопление памяти переводов (ТМ) происходит автоматически, каждый переведенный сегмент сохраняется в ТМ, как только переводчик перешел к переводу следующего сегмента. После завершения работы переводчика выполняется редактура, корректура и финальная вычитка, все изменения, внесенные в текст на этих этапах, также попадают в ТМ, либо автоматически (если работа ведется посегментно), либо переносятся вручную в тех случаях, когда работа ведется уже с полной или печатной версией документа.
Чтобы сформировать ТМ из перевода, выполненного ранее, потребуется исходный документ и его перевод на требуемый язык. Наш специалист сегментирует текст и объединит каждый исходный сегмент с его переводом, получив таким образом ТМ. Данная услуга называется «элаймент». Сформированная таким образом память переводов может серьезно сократить расходы на новый перевод, а также позволит сохранить единство терминологии и стиля изложения вашей документации.
Для накопления и последующей работы с памятью переводов наша компания использует программы Trados и Memsorce.
Как работает память переводов?
Получив заказ на перевод, мы выполняем анализ текста, показывающий % совпадений как внутри текста, так и по отношению к накопленной по данному заказчику памяти. Учитывается не только текст, но и скрытые непечатные символы, цифры и знаки препинания. Программа находит совпадающие сегменты текста и предоставляет статистику по словам (подсчитывая количество слов в сегментах). Слова, входящие в состав сегментов, совпадающих на 100%, мы называем «повторения», работа с ними – это только проверка, занимающая существенно меньше времени, чем перевод, и оцениваемая в 25% от тарифа за перевод нового текста. Помимо «повторений», в тексте всегда есть сегменты, совпадающие почти полностью, но все же не на 100%. Например, в предложении, переведенном ранее и присутствующем в ТМ, изменили одно слово или поставили знак препинания, такие предложения считаются «частичными совпадениями». Программа оценивает % совпадающих слов или знаков, что позволяет отделить почти полные совпадения от тех, где процент совпадения совсем низкий (например, совпадает 2 слова из 10). Переводчику проще работать с сегментами, совпадающими на 85–99%. Нужно переводить меньше текста, в связи с чем на слова, входящие в состав таких сегментов, также предоставляется скидка.
Чтобы наглядно понять, как текст разделяется на «повторения», «частичные совпадения» и «новые слова», рассмотрим пример из нашей практики.
Мы получили заказ на перевод руководства по эксплуатации автомобиля (документ 2 на рисунке ниже). Ранее мы переводили для этого заказчика руководство на другую модель (документ 1 на рисунке ниже), и теперь, проанализировав текст, получили статистику, содержащую новые слова, повторения и частичные совпадения. На приведенном рисунке красным выделены «повторения», т. е. сегменты, совпавшие на 100% с переведенным ранее текстом (на него указывают стрелки). Переводчик увидит этот текст и подтвердит его подстановку. Зеленым выделены «частичные совпадения». В переводимом документе это предложение отличается на 1 слово (обведено зеленым) из 14, значит, все слова, входящие в состав данного сегмента (предложения), будут считаться «частичными совпадениями». Переводчик увидит, какой перевод был использован ранее и в чем отличие старого и нового текста. Сделанный ранее перевод будет использован при работе с новым текстом как вспомогательный материал.

Таким образом, мы получаем возможность не переводить многократно совпадающий текст, что обеспечивает:
С самого первого заказа каждый переведенный сегмент текста попадает в ТМ заказчика. Так как работа с любым документом включает не только перевод, выполняемый переводчиком, но также редактуру, корректуру и финальную вычитку, все правки, сделанные на каждом этапе проверки, включая корректировки и замечания заказчика, переносятся в ТМ после сдачи финальной версии.
Создаваемая ТМ принадлежит заказчику, предоставляется в универсальном обменном формате TMX и формирует лингвистический капитал заказчика.

Пример расчета стоимости перевода с памятью перевода и без.

Задача: высококачественный перевод с английского на русский язык
Объем документа: 18 000 слов или около 72 условных страниц
Цена за слово: 2,3 рубля
Расчет стоимости услуги с учетом памяти перевода (Translation Memory):
«Память переводчика», или Что такое Translation Memory
Николай Прохоров, Александр Прохоров
Говоря об автоматизированном переводе, обычно подразумевают программы, осуществляющие перевод на основе технологии машинного перевода (Machine Translation). Однако существует и другая технология — Translation Memory, которая хотя и не столь широко известна российским пользователям, но, тем не менее, имеет ряд преимуществ.
Бурное развитие технического прогресса привело к увеличению числа технических устройств, машин и другой сложной техники, без которых жизнь современного человека практически немыслима. Например, объем документации для европейского самолета Airbus исчисляется десятками тысяч страниц. Как показывают данные исследования, проведенного в конце 2004 года ассоциацией LISA 1 (LISA 2004 Translation Memory Survey), 42% опрошенных переводят около 1 млн. слов в год, у 24% компаний — участников опроса ежегодный объем переводов составляет 1-5 млн., 12% переводят от 5 до 10 млн., объем переводов остальных компаний — от 10 до 500 и более миллионов слов в год. В частности, большинство производителей сегодня не ограничиваются своим локальным рынком и активно осваивают региональные рынки. При этом локализация продукции, в том числе перевод описания продукта на местный язык, является одним из обязательных условий для выхода на новый рынок.
В то же время, хотя производители регулярно выпускают новые версии своих продуктов — автомобилей, экскаваторов, компьютеров и мобильных телефонов, программного обеспечения, — далеко не все из них принципиально отличаются от предыдущих моделей. Подчас новая модель телефона представляет собой слегка измененную (или рестайлинговую) предыдущую модель. Новые версии продаются лучше, поэтому производителям приходится регулярно обновлять свои продукты. В результате документация по каждому из таких продуктов зачастую на 70-90% совпадает с той, что была у предыдущей версии.
Два фактора — большой объем требующих перевода документов и их высокая повторяемость — послужили стимулом к созданию технологии Translation Memory (сокращенно именуется TM, общепринятый русский перевод этого термина отсутствует). Суть технологии TM можно образно передать одной фразой: «Не переводить один и тот же текст дважды». Иначе говоря, Translation Memory используется для повторного использования ранее сделанных переводов. Это позволяет серьезно сократить время на подготовку перевода, особенно при работе с текстами, имеющими высокую степень повторяемости.
Технологию Translation Memory часто путают с машинным переводом (Machine Translation), которая, безусловно, тоже полезна и интересна, но ее описание не является целью настоящей статьи. Использование технологии ТМ повышает скорость перевода за счет уменьшения объема механической работы. Однако важно отметить, что TM не выполняет перевод за переводчика, а является мощным инструментом для сокращения затрат при переводе повторяющихся текстов.
Технология ТМ работает по принципу накопления результатов перевода: в процессе перевода в базе ТМ сохраняются исходный текст и его перевод. Для облегчения обработки информации и сравнения различных документов система Translation Memory разбивает весь текст на отдельные кусочки, которые называются сегментами. Такими сегментами чаще всего являются предложения, но могут быть приняты и другие правила сегментации. При загрузке нового текста система TM осуществляет сегментирование и сравнивает сегменты исходного текста с уже имеющимися в подключенной базе переводов. Если системе удается найти полностью или частично совпадающий сегмент, то его перевод отображается с указанием совпадения в процентах. Сегменты, которые отличаются от сохраненного текста, выделяются подсветкой. Таким образом, переводчику остается только перевести новые сегменты и отредактировать частично совпадающие.
Как правило, задается порог совпадений на уровне не ниже 75%, так как если установить меньший процент совпадений, то увеличатся затраты на редактирование текста. Каждое изменение или новый перевод сохраняются в ТМ, так что нет необходимости переводить одно и то же дважды!
Важно также постоянно пополнять базу Translation Memory, сохраняя в базе (или в базах, если перевод выполняется по различным тематикам) пары сегментов «исходный текст — правильный перевод». Это позволит значительно сократить время, необходимое для перевода сходных текстов. Помимо снижения трудоемкости перевода система TМ позволяет выдержать единство терминологии и стиля во всей документации.
Использование технологии ТМ обеспечивает переводчику следующие преимущества:
Отдельно отметим, что в западных странах, где технология Translation Memory давно уже стала де-факто обязательным инструментом переводчика, средства, потраченные на создание базы переводов, рассматриваются не как затраты, а, скорее, как инвестиции в стабильную и качественную работу, что увеличивает не только прибыль, но и стоимость самой компании.
Рынок систем Тranslation Мemory
Бесспорным лидером на рынке систем Translation Memory являются программы SDL-TRADOS. Летом 2005 года произошло объединение двух крупнейших разработчиков систем ТМ — компаний SDL и TRADOS (программные продукты под торговой маркой TRADOS хорошо известны многим пользователям), и теперь они выпускают совместный продукт, который является законодателем стандартов в области Translation Memory.
Новая система SDL-TRADOS имеет расширенные (настраиваемые пользователем) функциональные возможности нечеткого соответствия (поиск по совпадениям в базе переводов), а также инструментарий для проверки качества переводимых документов. Программа осуществляет проверку орфографии и защищает содержимое блоков памяти с помощью технологии шифрования.
Система поддерживает такие форматы, как Word DOC и RTF, online help RTF, PowerPoint, FrameMaker, FrameMaker +SGML, FrameBuilder, Interleaf, QuickSilver, Ventura, QuarkXPress, PageMaker, SGML/HTML/XML, включая HTML Help, RC (Windows Resource), Bookmaster (DCF) и Troff. Помимо системы SDL-TRADOS, на IT-рынке имеются и другие системы ТМ. Особенно широко представлены французские производители.
— это самостоятельное приложение с систематизированным меню. Система может создавать базы ТМ, а также базы данных терминологии и подключать словари. Процесс перевода осуществляется в специальной оболочке Project, куда при ее создании прикрепляется файл, который необходимо перевести, и подключаются дополнительные настройки: база ТМ, словари и др. Текст переводится в специальной таблице, где напротив каждой графы его оригинала нужно заполнить вариант перевода. К преимуществам также относится дополнительная функция для перевода файлов различных форматов, которая позволяет сохранить исходное форматирование файла.
Другая система ТМ — Wordfast (www.wordfast.net) — разработана профессиональным французским переводчиком Ивом Чамполлионом и предназначена для перевода информации путем накопления переводов непосредственно в текстовом редакторе Word. Программа не сегментирует текст в виде таблицы, а выделяет цветом одно предложение за другим непосредственно в тексте и вставляет дополнительные скобки для варианта перевода.
Помимо поддержки форматов Word, система может переводить документы Excel и PowerPoint. При переводе можно использовать и базы ТМ других программ: Trados версий 2, 3 и 5, документы формата TMX и базы программы IBM Translation Manager. Кроме того, система может работать без лицензии с базами перевода объемом до 110 Кбайт.
ТМ в России
Помимо иностранных компаний, разработкой систем класса Тranslation Мemory занимается российская компания ПРОМТ — всемирно известный разработчик систем машинного перевода (Machine Translation).
Разработка продукта PROMT Translation Suite 7.0 — это дебют компании ПРОМТ в области применения технологии Translation Memory. Уникальность продукта заключается в интеграции сразу двух технологий перевода: Translation Memory и Machine Translation. Помимо работы с базой ТМ в виде самостоятельного приложения путем создания специального документа «Проект», система PROMT Translation Suite 7.0 самостоятельно переводит те сегменты текста, которые отсутствуют в базе ТМ.
Для облегчения работы с незнакомым текстом в продукте также имеется интегрированный электронный словарь, который позволяет оперативно просмотреть варианты перевода слова (рис. 1).
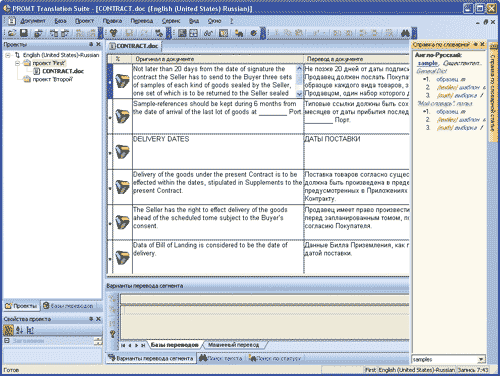
Рис. 1. Окно программы PROMT Translation Suite с развернутой панелью справки по словарной статье
Основные достоинства PROMT Translation Suite:
Как настроить систему Тranslation Memory
Процесс перевода с помощью системы Translation Memory можно условно разделить на следующие этапы:
Для упрощения изложения в рамках данной статьи мы сознательно не рассматриваем этапы извлечения текста из исходного документа и последующей верстки переведенного текста в случае перевода документов в таких форматах, как XML, PDF и др.
Рассмотрим возможности настройки системы Translation Memory на примере уже упоминавшейся нами программы PROMT Translation Suite.
Правила сегментации текста
Одна из основных задач во время настройки системы — правильное сегментирование текста. Успех поиска совпадающих сегментов в базе зависит от того, насколько правильно заданы правила сегментации текста (рис. 2).
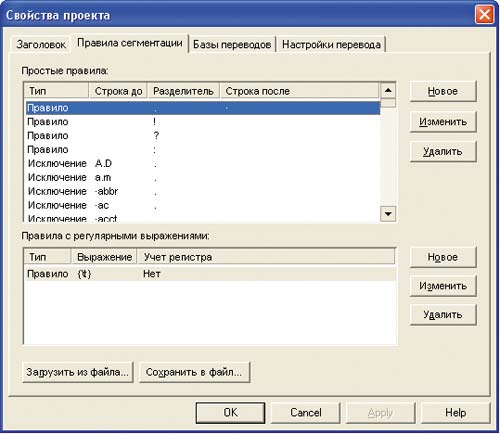
Существует два типа условий сегментации:
В системе можно задать две группы правил сегментации: простые правила и правила с регулярными выражениями.
Простые правила задают условия, определяющие последовательность символов, которые надо или не надо считать границей сегмента. К простым правилам относится строка до разделителя (возможна пустая или определенная последовательность символов), символ разделителя (всегда один!) и строка после разделителя.
Правила с регулярными выражениями существуют для создания более гибких условий сегментации, что также отнюдь не лишне. Если должным образом не задать такие условия, то, например, предложение «Команда выиграла матч со счетом 3:1» может быть неправильно сегментировано. В данном случае необходимо задать исключение (то есть символ, который система не будет считать границей сегмента) в виде строки до разделителя с помощью регулярного выражения « \d+ » (обозначает любое количество цифр), символа разделителя «:» и строки после разделителя с помощью регулярного выражения « \d+ » (любое количество цифр). В этом случае система не обратит внимание на двоеточие между цифрами.
Работа с непереведенными сегментами
В процессе перевода система анализирует текст, находит полностью или частично совпадающие предложения в базе ТМ и подставляет их в текст перевода. В каждом сегменте сбоку указывается процент совпадений, нижний предел которого можно устанавливать самостоятельно, задавая настройки перед переводом.
Как уже упоминалось, система PROMT Translation Suite позволяет переводить сегменты, отсутствующие в базе переводов, с помощью технологии машинного перевода (Machine Translation). Это значительно сокращает время работы над переводом, поскольку править уже готовый перевод легче, чем переводить заново. Для настройки машинного перевода можно использовать стандартный набор функций: создание и пополнение собственных словарей, резервирование слов, применение препроцессоров и ряд других (более подробно читайте о них в статье «Настройка — залог качественного перевода» в этом спецвыпуске).
Нельзя также забывать о необходимости постоянного пополнения баз ТМ для сокращения затрат на перевод в дальнейшем. Для того чтобы добавить корректно переведенные сегменты в базу, щелкните правой клавишей мыши по выделенному сегменту и выберите команду Добавить выделенные сегменты в базу (или нажмите соответствующую кнопку на панели инструментов). Сохранение новых сегментов перевода в базе не только повышает эффективность работы с системой, но и экономит время при переводе последующих текстов.
Кроме того, следует пользоваться командой контекстного меню Завершить перевод сегментов после окончания редактирования сегментов. В этом случае можно избежать случайного внесения изменений в уже отредактированный сегмент.
Импорт баз переводов
Одна из наиболее полезных опций системы PROMT Translation Suite — возможность импорта баз переводов (во внутреннем формате программы (*.pts) и баз переводов ассоциированной памяти PROMT (*.apd)), а также сегментов из файлов (во внутреннем формате *.pts и в формате TMX Level 1 (*.tmx)). Используя эту возможность системы, можно избавить себя от составления базы переводов с нуля в том случае, если база ТМ по необходимой тематике уже создана, например, другими сотрудниками компании.
Особое внимание следует уделить возможности импорта сегментов файлов TMX.
В заключение отметим, что технология Translation Memory является мощным инструментом для решения проблемы эффективного перевода повторяющихся текстов. В этом обзоре мы не только рассказали о сути технологии TM, но и описали представленные на рынке системы. В частности, российским пользователям можно порекомендовать обратить внимание на систему PROMT Translation Suite, разработанную российской компанией ПРОМТ.
Важным преимуществом системы PROMT Translation Suite, по сравнению с зарубежными аналогами, является наличие интегрированной технологии машинного перевода. Это позволяет значительно ускорить создание собственных баз Translation Memory и повысить эффективность работы с системой.
Постоянное пополнение баз переводов новыми сегментами сведет к минимуму работу переводчика вручную при переводе текстов схожей тематики.



