Парсер – что это такое простыми словами, как его настроить и пользоваться программой для парсинга сайтов
24 июня 2020 Опубликовано в разделах: Азбука терминов. 86691


Есть приложения, которые позволяют автоматизировать множественные процессы интернет-маркетинга. Они необходимы многим бизнесменам, которые либо хотят использовать сбор информации с конкурирующих веб-источников, либо защитить себя от подобного «воровства» контента. В любом случае, работая с интернет-ресурсом важно знать о парсинге сайта – что это такое (мы расскажем простыми словами) и как настроить и пользоваться парсером данных.
Parsing
Данный механизм действует по заданной программе и сопоставляет определенный набор слов, с тем, что нашлось в интернете. Как поступать с полученной информацией, написано в командной строке, называемой «регулярное выражение». Она состоит из символов и задает правило поиска.
Фактически понятие переводится с английского языка как семантический анализ или разбор. Но термин, применяемый в технологиях создания и наполнения вебсайта, имеет более широкое значение. Это процедура, действие, предполагающее многостороннее исследование страницы, документа, целого раздела на предмет нахождения лексических, грамматических единиц или иных элементов (не только текста, но и видео-, аудио-контента) с последующей систематизацией. Искомые сведения находятся и преобразуются, они подготавливаются для дальнейшей работы с ними. Еще можно сказать, что это быстрая оценка и скорая обработка интернет-ресурса, данных с него. Вручную подобный процесс занял бы много времени, но автоматизация его значительно упрощает.

Таким образом, парсер – это программа для парсинга ключевых слов сайтов. Она настраивается, в нее вводятся параметры поиска и прочие указания, чтобы получить семантическое ядро или анализ карточек товаров для интернет-магазина.
Исходником может быть ваш собственный веб-ресурс (для аналитики и принятия последующих решений), сайт конкурента, страничка из социальных сетей и пр. Полученным результатом можно будет пользоваться в дальнейшем по усмотрению владельца. Приведем понятный пример. По такому принципу работают поисковые системы, когда они анализируют страницы на релевантность, наличие ключевых слов из запроса и соответствие тематике, а затем на основе полученных сведений автоматически формируется выдача.

Законно ли использовать парсинг семантического ядра с сайтов конкурентов
Посмотрим на это с такой стороны. Если ресурс является открытым для пользователей, то вся представленная информация может собираться вручную. А если это доступно, то и применение специального софта для автоматизации процесса не является противозаконной. Опять же при условии, что доступ разрешен всем.

Сквозная аналитика
Это услуга, которая признана дать отчет о результативности интернет-рекламы. То есть с помощью сервиса собираются данные с рекламных площадок, связывает их со сведениями об обращениях и продажах. Анализируя это, можно понять, насколько эффективно было использование того или иного метода продвижения. Таким образом возможно выявить, какие каналы являются затратными, но не приносят достаточно выгодного результата, это помогает оптимизировать бюджет.
Такую услугу постоянной аналитики предлагает компания SEMANTICA в комбинации с комплексным продвижением сайтов. Клиенты этого агентства могут наблюдать за тем, какой результат он получает от того или иного действия, проекта. Все сведения предоставляются в виде отчетов, диаграмм.
Для чего нужен парсинг
Первое с чем сталкивается начинающий руководитель – вокруг много информации, слишком большое ее количество затрудняет возможность оперировать большинством ее массы вручную.
Достоинства применения программ для парсинга каталога товаров с сайта для интернет-магазина
Сравним автоматический режим сбора с ручным, преимущества:
Ограничения: почему бывает сложно парсить
Многие задумываются о том, как защитить сайт от парсинга, потому что не хотят терять уникальность контента. Поэтому используют различные программы, которые запрещают доступ к ресурсу ботам.

Как работает парсинг и какой контент можно парсить своими руками или автоматически
Вам удастся получить любую информацию (текстовую или медийную), которая находится в открытом доступе, например:
Алгоритм работы парсера
Тонкости процесса зависят от задачи, которая забивается в программы, но в остальном действия имеют следующую последовательность, схему:
Способы применения
Парсинг для начинающих начинается с анализа конкурирующих фирм, чтобы сформировать собственную ценовую политику и план продвижения, стратегию интернет-маркетинга. А уже уверенные пользователи одновременно используют парсеры и для изучения конкурентов, и для аудита своего ресурса, для сравнения полученных сведений. Такая работа в тесной связке помогает поддерживать конкурентоспособность на высоком уровне.

Как парсить данные
Можно пойти двумя путями – купить программу, которых представлено большое множество, или создать приложение собственными силами фактически на любом из языков программирования.
Как спарсить цену
Определение ценовой политики – это самая ходовая задача для приложений. Для этого необходимо посмотреть код анализируемого товара и ввести его в программу. Она автоматически подтянет другие позиции, отвечающие запросу. Сэкономить время и повысить эффективность можно, если ограничить круг страничек. Например, так он не будет искать по разделу с информационными статьями. Добавлять стоит категории и сами карточки продукции. Прописываются ссылки на них в карте XML.
Как парсить характеристики товаров
Для этого понадобится вручную определить код у каждого продукта, который вам требуется. Затем можно подвязать полученные сведения с автозаполнением полей в вашем интернет-магазине. Особенно актуально подтягивать описание, когда вы занимаетесь реализацией техники, автомобилей, смартфонов. Часто характерные особенности берутся на сайтах производителей. Они не могут отличаться уникальностью, поэтому поисковики за это не ругаются.

Как спарсить отзывы (с рендерингом)
Процедура аналогичная – копирование кода, а затем его ввод в приложение для парсинга. Но несколько отличаются последующие действия. Обычно комментарии открываются в тот момент, когда пользователь прокручивает страницу вниз, чтобы ознакомиться с ними. И тогда нужно снова залезть в настройки и изменить поле «Рендеринг» на JavaScript. В таком случае программа будет себя вести точно как юзер, прокручивая вниз контент до отзывов.
Как парсить структуру сайта
Это важное занятие, которым также часто занимаются новички. Основная задача – узнать, из каких разделов, подразделов и категорий состоит веб-ресурс, чтобы сделать аналогичные. Структурирование определяется, благодаря изучению breadcrumbs, или хлебных крошек в буквальном переводе. На самом деле термин подразумевает навигационную цепочку, которая выстраивается от начального элемента (корневого файла) до итогового.

Что нужно для этого сделать:
Теперь вы знаете, как сделать парсинг сайта интернет-магазина самостоятельно. Но не всегда удается правильно распорядиться полученной информацией, а также быстро обойти все существующие ограничения на поиск. В таком случае мы рекомендуем обратиться к компании по продвижению вебсайтов. Специалисты агентства SEMANTICA производят анализ конкурентов на начальном этапе работы с проектом, а заказчик получает готовый результат в удобном формате.
30+ парсеров для сбора данных с любого сайта

Десктопные/облачные, платные/бесплатные, для SEO, для совместных покупок, для наполнения сайтов, для сбора цен… В обилии парсеров можно утонуть.
Мы разложили все по полочкам и собрали самые толковые инструменты парсинга — чтобы вы могли быстро и просто собрать открытую информацию с любого сайта.
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Но если вы хотите собрать персональные данные пользователей и использовать их для email-рассылок или таргетированной рекламы, это уже будет незаконно (эти данные защищены законом о персональных данных).
Десктопные и облачные парсеры
Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
Например, вот англоязычные облачные парсеры:
Из русскоязычных облачных парсеров можно привести такие:
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
Популярные десктопные парсеры:
Виды парсеров по технологии
Браузерные расширения
Для парсинга данных есть много браузерных расширений, которые собирают нужные данные из исходного кода страниц и позволяют сохранять в удобном формате (например, в XML или XLSX).
Парсеры-расширения — хороший вариант, если вам нужно собирать небольшие объемы данных (с одной или парочки страниц). Вот популярные парсеры для Google Chrome:
Надстройки для Excel
Программное обеспечение в виде надстройки для Microsoft Excel. Например, ParserOK. В подобных парсерах используются макросы — результаты парсинга сразу выгружаются в XLS или CSV.
Google Таблицы
С помощью двух несложных формул и Google Таблицы можно собирать любые данные с сайтов бесплатно.
IMPORTXML
Функция использует язык запросов XPath и позволяет парсить данные с XML-фидов, HTML-страниц и других источников.
Вот так выглядит функция:
Функция принимает два значения:
Хорошая новость в том, что вам не обязательно изучать синтаксис XPath-запросов. Чтобы получить XPath-запрос для элемента с данными, нужно открыть инструменты разработчика в браузере, кликнуть правой кнопкой мыши по нужному элементу и выбрать: Копировать → Копировать XPath.
С помощью IMPORTXML можно собирать практически любые данные с html-страниц: заголовки, описания, мета-теги, цены и т.д.
IMPORTHTML
У этой функции меньше возможностей — с ее помощью можно собрать данные из таблиц или списков на странице. Вот пример функции IMPORTHTML:
Она принимает три значения:
Об использовании 16 функций Google Таблиц для целей SEO читайте в нашей статье. Здесь все очень подробно расписано, с примерами по каждой функции.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
Популярные парсеры для СП:
Парсеры цен конкурентов
Инструменты для интернет-магазинов, которые хотят регулярно отслеживать цены конкурентов на аналогичные товары. С помощью таких парсеров вы можете указать ссылки на ресурсы конкурентов, сопоставлять их цены с вашими и корректировать при необходимости.
Вот три таких инструмента:
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
Парсеры для SEO-специалистов
Отдельная категория парсеров — узко- или многофункциональные программы, созданные специально под решение задач SEO-специалистов. Такие парсеры предназначены для упрощения комплексного анализа оптимизации сайта. С их помощью можно:
Пройдемся по нескольким популярным парсерам и рассмотрим их основные возможности и функционал.
Парсер метатегов и заголовков PromoPult
Стоимость: первые 500 запросов — бесплатно. Стоимость последующих запросов зависит от количества: до 1000 — 0,04 руб./запрос; от 10000 — 0,01 руб.
Возможности
С помощью парсера метатегов и заголовков можно собирать заголовки h1-h6, а также содержимое тегов title, description и keywords со своего или чужих сайтов.
Инструмент пригодится при оптимизации своего сайта. С его помощью можно обнаружить:
Также парсер полезен при анализе SEO конкурентов. Вы можете проанализировать, под какие ключевые слова конкуренты оптимизируют страницы своих сайтов, что прописывают в title и description, как формируют заголовки.
Сервис работает «в облаке». Для начала работы необходимо добавить список URL и указать, какие данные нужно спарсить. URL можно добавить вручную, загрузить XLSX-таблицу со списком адресов страниц, или вставить ссылку на карту сайта (sitemap.xml).
Парсер метатегов и заголовков — не единственный инструмент системы PromoPult для парсинга. В SEO-модуле системы можно бесплатно спарсить ключевые слова, по которым добавленный в систему сайт занимает ТОП-50 в Яндексе/Google.
Здесь же на вкладке “Слова ваших конкурентов” вы можете выгрузить ключевые слова конкурентов (до 10 URL за один раз).
Подробно о работе с парсингом ключей в SEO-модуле PromoPult читайте здесь.
Netpeak Spider
Стоимость: от 19$ в месяц, есть 14-дневный пробный период.
Парсер для комплексного анализа сайтов. С Netpeak Spider можно:
Screaming Frog SEO Spider
Стоимость: лицензия на год — 149 фунтов, есть бесплатная версия.
Многофункциональный инструмент для SEO-специалистов, подходит для решения практически любых SEO-задач:
В бесплатной версии доступен ограниченный функционал, а также есть лимиты на количество URL для парсинга (можно парсить всего 500 url). В платной версии таких лимитов нет, а также доступно больше возможностей. Например, можно парсить содержимое любых элементов страниц (цены, описания и т.д.).
ComparseR
Стоимость: 2000 рублей за 1 лицензию. Есть демо-версия с ограничениями.
Еще один десктопный парсер. С его помощью можно:
Анализ сайта от PR-CY
Стоимость: платный сервис, минимальный тариф — 990 рублей в месяц. Есть 7-дневная пробная версия с полным доступом к функционалу.
Онлайн-сервис для SEO-анализа сайтов. Сервис анализирует сайт по подробному списку параметров (70+ пунктов) и формирует отчет, в котором указаны:
Анализ сайта от SE Ranking
Стоимость: платный облачный сервис. Доступно две модели оплаты: ежемесячная подписка или оплата за проверку.
Стоимость минимального тарифа — 7$ в месяц (при оплате годовой подписки).
Возможности:
Xenu’s Link Sleuth
Стоимость: бесплатно.
Десктопный парсер для Windows. Используется для парсинга все url, которые есть на сайте:
Часто применяется для поиска неработающих ссылок на сайте.
A-Parser
Стоимость: платная программа с пожизненной лицензией. Минимальный тарифный план — 119$, максимальный — 279$. Есть демо-версия.
Многофункциональный SEO-комбайн, объединяющий 70+ разных парсеров, заточенных под различные задачи:
Кроме набора готовых инструментов, можно создать собственный парсер с помощью регулярных выражений, языка запросов XPath или Javascript. Есть доступ по API.
Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
Парсинг — что это такое простыми словами. Как работает парсинг и парсеры, и какие типы парсеров бывают (подробный обзор +видео)
Парсинг – что это такое простыми словами? Если коротко, то это сбор информации по разным критериям из интернета, в автоматическом режиме. В процессе работы парсера сравнивается заданный образец и найденная информация, которая в дальнейшем будет структурирована.
В качестве примера можно привести англо-русский словарь. У нас есть исходное слово «parsing». Мы открываем словарь, находим его. И в качестве результата получаем перевод слова «разбор» или «анализ». Ну, а теперь давайте разберем эту тему поподробнее
Содержание статьи:
Парсинг: что это такое простыми словами
Парсинг — это процесс автоматического сбора информации по заданным нами критериям. Для лучшего понимания давайте разберем пример:
Пример того, что такое парсинг:
Представьте, что у нас есть интернет-магазин поставщика, который позволяет работать по схеме дропшиппинга и мы хотим скопировать информацию о товарах из этого магазина, а потом разместить ее на нашем сайте/интернет магазине (под информацией я подразумеваю: название товара, ссылку на товар, цену товара, изображение товара). Как мы можем собрать эту информацию?
Первый вариант сбора — делать все вручную:
То есть, мы вручную проходим по всем страницам сайта с которого хотим собрать информацию и вручную копируем всю эту информацию в таблицу для дальнейшего размещения на нашем сайте. Думаю понятно, что этот способ сбора информации может быть удобен, когда нужно собрать 10-50 товаров. Ну, а что делать, когда информацию нужно собрать о 500-1000 товаров? В этом случае лучше подойдет второй вариант.
Второй вариант — спарсить всю информацию разом:
Мы используем специальную программу или сервис (о них я буду говорить ниже) и в автоматическом режиме скачиваем всю информацию в готовую Excel таблицу. Такой способ подразумевает огромную экономию времени и позволяет не заниматься рутинной работой.
Причем, сбор информации из интернет-магазина я взял лишь для примера. С помощью парсеров можно собирать любую информацию к которой у нас есть доступ.
Грубо говоря парсинг позволяет автоматизировать сбор любой информации по заданным нами критериям. Думаю понятно, что использовать ручной способ сбора информации малоэффективно (особенно в наше время, когда информации слишком много).
Для наглядности хочу сразу показать главные преимущества парсинга:
Если говорить о наличие минусов, то это, разумеется, отсутствие у полученных данных уникальности. Прежде всего, это относится к контенту, мы ведь собираем все из открытых источников и парсер не уникализирует собранную информацию.
Думаю, что с понятием парсинга мы разобрались, теперь давайте разберемся со специальными программами и сервисами для парсинга.
Что такое парсер и как он работает

Парсер – это некое программное обеспечение или алгоритм с определенной последовательностью действий, цель работы которого получить заданную информацию.
Сбор информации происходит в 3 этапа:
Чаще всего парсер — это платная или бесплатная программа или сервис, созданный под ваши требования или выбранный вами для определенных целей. Подобных программ и сервисов очень много. Чаще всего языком написания является Python или PHP.
Но также есть и отдельные программы, которые позволяют писать парсеры. Например я пользуюсь программой ZennoPoster и пишу парсеры в ней — она позволяет собирать парсер как конструктор, но работать он будет по тому же принципу, что и платные/бесплатные сервисы парсинга.
Для примера можете посмотреть это видео в котором я показываю, как я создавал парсер для сбора информации с сервиса spravker.ru.
Чтобы было понятнее, давайте разберем каких типов и видов бывают парсеры:
Не следует забывать о том, что парсинг имеет определенные минусы. Недостатком использования считаются технические сложности, которые парсер может создать. Так, подключения к сайту создают нагрузку на сервер. Каждое подключение программы фиксируется. Если подключаться часто, то сайт может вас заблокировать по IP (но это легко можно обойти с помощью прокси).
Что такое парсинг сайта, программы и примеры их использования

В интернет маркетинге часто необходимо собрать большой объем информации с сайта, не только со своего, но и с сайтов конкурентов, после её проанализировать и применить для каких-либо целей.
В статье постараемся достаточно просто рассказать о термине «парсинг”, его основных нюансах и рассмотрим несколько примеров его полезного применения, как для маркетологов и владельцев бизнеса, так и для SEO специалистов.
Что такое парсинг сайта?
Простыми словами парсинг – это автоматизированный сбор информации с любого сайта, ее анализ, преобразование и выдача в структурированном виде, чаще всего в виде таблицы с набором данных.
Парсер сайта — это любая программа или сервис, которая осуществляет автоматический сбор информации с заданного ресурса.
В статье мы разберем самые популярные программы и сервисы для парсинга сайта.
Зачем парсинг нужен и когда его используют?
Вообще парсинг можно разделить на 2 типа:
На основе полученных данных специалист составляет технические задания для устранения выявленных проблем.
Выше перечислены основные примеры использования парсинга. На самом деле их куда больше и ограничивается только вашей фантазией и некоторыми техническими особенностями.
Как работает парсинг? Алгоритм работы парсера.
Процесс парсинга — это автоматическое извлечение большого массива данных с веб-ресурсов, которое выполняется с помощью специальных скриптов.
Если кратко, то парсер ходит по ссылкам указанного сайта и сканирует код каждой страницы, собирая информацию о ней в Excel-файл либо куда-то еще. Совокупность информации со всех страниц сайта и будет итогом парсинга сайта.
Парсинг работает на основе XPath-запросов, это язык, который обращается к определенному участку кода страницы и извлекает из него заданную критерием информацию.
Алгоритм стандартного парсинга сайта.
Чем парсинг лучше работы человека?
Парсинг сайта – это рутинная и трудоемкая работа. Если вручную извлекать информацию из сайта, в котором всего 10 страниц, не такая сложная задача, то анализ сайта, у которого 50 страниц и больше, уже не покажется такой легкой.
Кроме того нельзя исключать человеческий фактор. Человек может что-то не заметить или не придать значения. В случае с парсером это исключено, главное его правильно настроить.
Если кратко, то парсер позволяет быстро, качественно и структурировано получить необходимую информацию.
Какую информацию можно получить, используя парсер?
У разных парсеров могут быть свои ограничения на парсинг, но по своей сути вы можете спарсить и получить абсолютно любую информацию, которая есть в коде страниц сайта.
Законно ли парсить чужие сайты?
Парсинг данных с сайтов-конкурентов или с агрегаторов не противоречат закону, если:
Если вы сомневаетесь по одному из перечисленных пунктов, перед проведением анализа сайта лучше проконсультироваться с юристом.
Популярные программы для парсинга сайта
Мы выделяем 4 основных инструменты для парсинга сайтов:
Google таблицы (Google Spreadsheet)
Удобный способ для парсинга, если нет необходимости парсить большое количество данных, так как есть лимиты на количество xml запросов в день.
С помощью таблиц Google Spreadsheet можно парсить метаданные, заголовки, наименования товаров, цены, почту и многое другое.
Рассмотрим основные функции
Функция importHTML
Настраивает импорт таблиц и списков на страницах сайта. Прописывается следующим образом:
=IMPORTHTML(“ссылка на страницу”; запрос “table” или “list”; порядковый номер таблицы/списка)
Пример использования
Необходимо выгрузить данные из таблицы со страницы сайта.
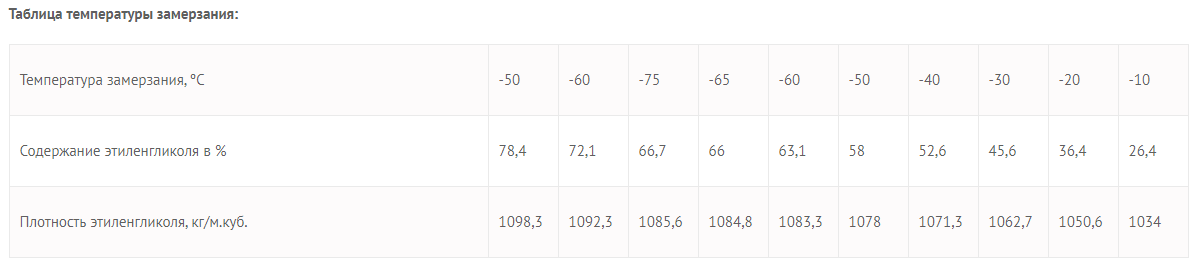

Для этого в формулу помещаем URL страницы, добавляем тег «table» и порядковый номер — 1.
Вот что получается:
Вставляем формулу в таблицу и смотрим результат:

Для выгрузки второй таблицы в формуле заменяем 1 на 2.
Вставляем формулу в таблицу и смотрим результат:
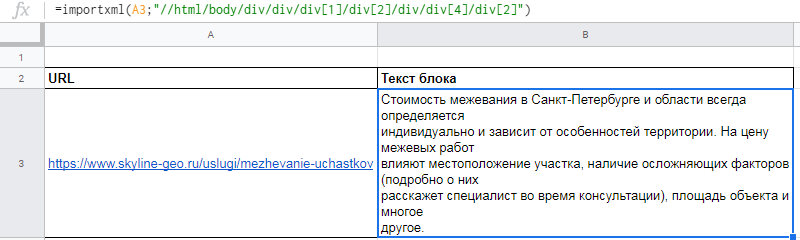
Функция importXML
Импортирует данные из документов в форматах HTML, XML, CSV, CSV, TSV, RSS, ATOM XML.
Функция имеет более широкий спектр опций, чем предыдущая. С её помощью со страниц и документов можно собирать информацию практически любого вида.
Работа с этой функцией предусматривает использование языка запросов XPath.
Формула:
=IMPORTXML(“ссылка”; “//XPath запрос”)
Пример использования
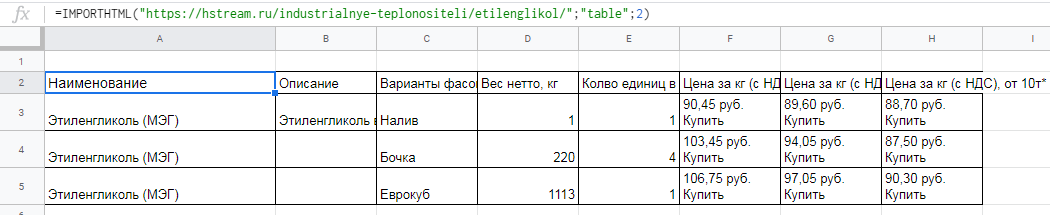
Вытягиваем title, description и заголовок h1.
В первом случае в формуле просто прописываем //title:
В формулу можно также добавлять названия ячеек, в которых содержатся нужные данные.
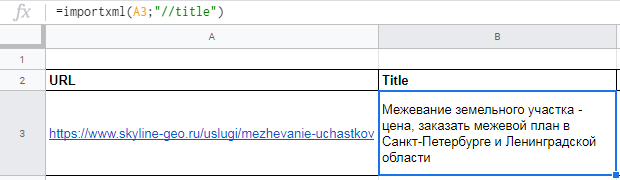
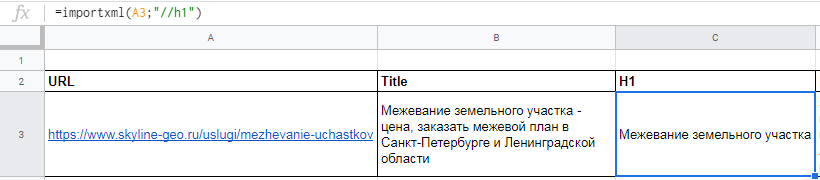
Для заголовка h1 похожая формула
С парсингом description немного другая история, а именно прописать его XPath запросом. Он будет выглядеть так:

В случае с другими любыми данными XPath можно скопировать прямо из кода страницы. Делается это просто:
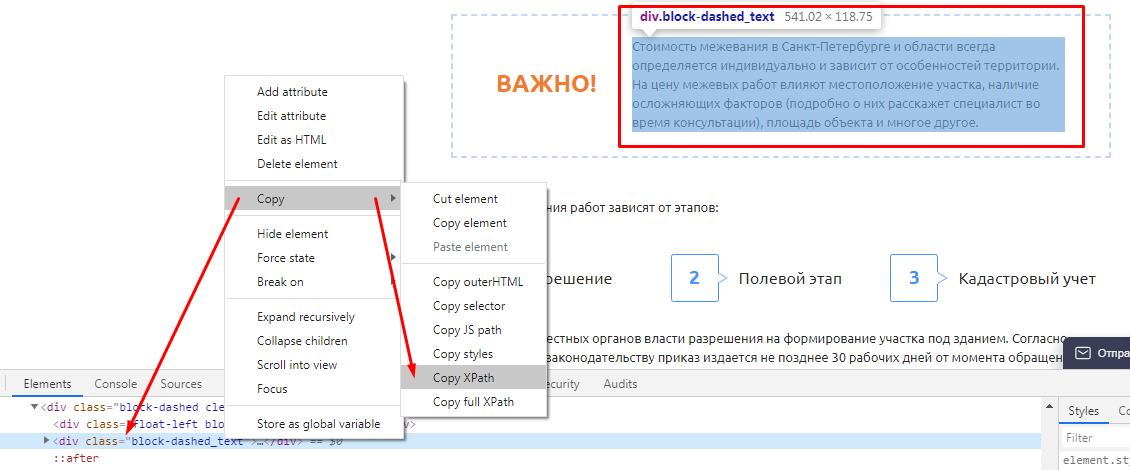
Вот как это будет выглядеть после всех манипуляций
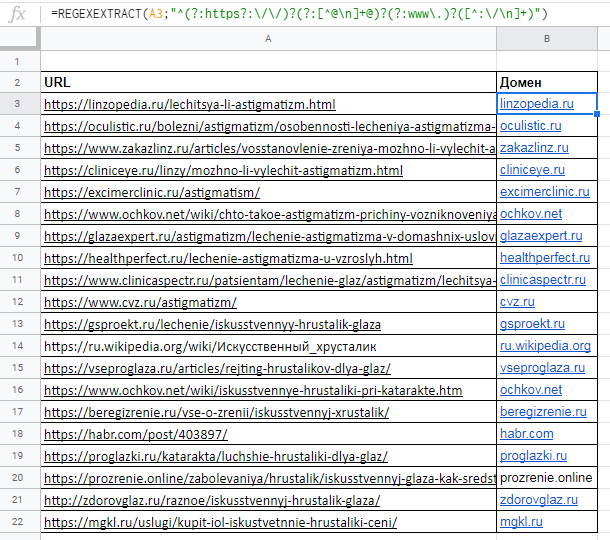
Функция REGEXEXTRACT
С её помощью можно извлекать любую часть текста, которая соответствует регулярному выражению.
Конечно для использования данной функции необходимы знания построения регулярных выражений,
Пример использования
Нужно отделить домены от страниц. Это можно сделать с помощью выражения:
Подробнее о функциях таблиц можно почитать в справке Google.
NetPeak Spider

Десктопный инструмент для регулярного SEO-аудита, быстрого поиска ошибок, системного анализа и парсинга сайтов.
Бесплатный период 14 дней, есть варианты платных лицензий на месяц и более.
Данная программа подойдет как новичкам, так и опытным SEO-специалистам. У неё интуитивно понятный интерфейс, она самостоятельно находит и кластеризует ошибки, найденные на сайте, помечает их разными цветами в зависимости от степени критичности.
Возможности Netpeak Spider:
ComparseR

ComparseR – специализированная программа, предназначенная для глубокого изучения индексации сайта.
У демо-версии ComparseR есть 2 ограничения:
Данный парсер примечателен тем, что он заточен на сравнение того, что есть на вашем сайте и тем, что индексируется в поисковых системах.
То есть вы легко найдете страницы, которые не индексируются поисковыми системами, или наоборот, страницы-сироты (страницы, на которые нет ссылок на сайте), о которых вы даже не подозревали.
Стоит отметить, что данный парсер полностью на русском и не так требователен к мощностям компьютера, как другие аналоги.
Screaming Frog SEO Spider

Особенности программы:
В бесплатной версии доступна обработка до 500 запросов.
На первый взгляд интерфейс данной программы для парсинга сайтов может показаться сложным и непонятным, особенно из-за отсутствия русского языка.
Не смотря на это, сама программа является великолепным инструментом с множеством возможностей.
Всю необходимую информацию можно узнать из подробного мануала по адресу https://www.screamingfrog.co.uk/seo-spider/user-guide/.
Примеры глубокого парсинга сайта — парсинг с конкретной целью
Пример 1 — Поиск страниц по наличию/отсутствию определенного элемента в коде страниц
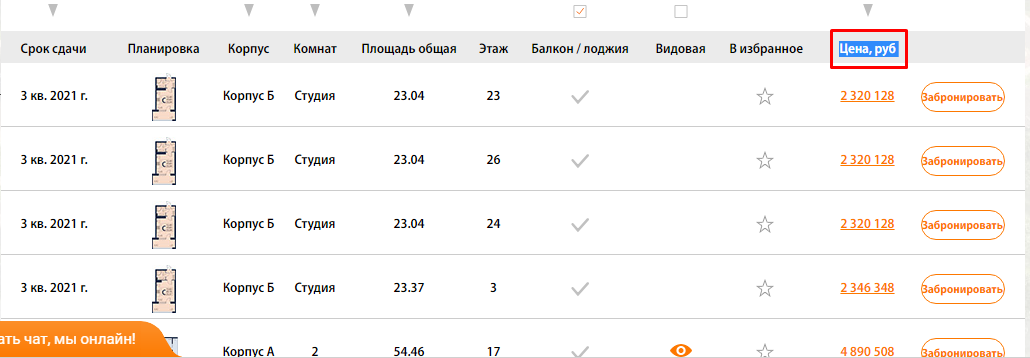
Задача: — Спарсить страницы, где не выводится столбец с ценой квартиры.
Как быстро найти такие страницы на сайте с помощью Screaming Frog SEO Spider?
Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, который есть на всех искомых страницах.
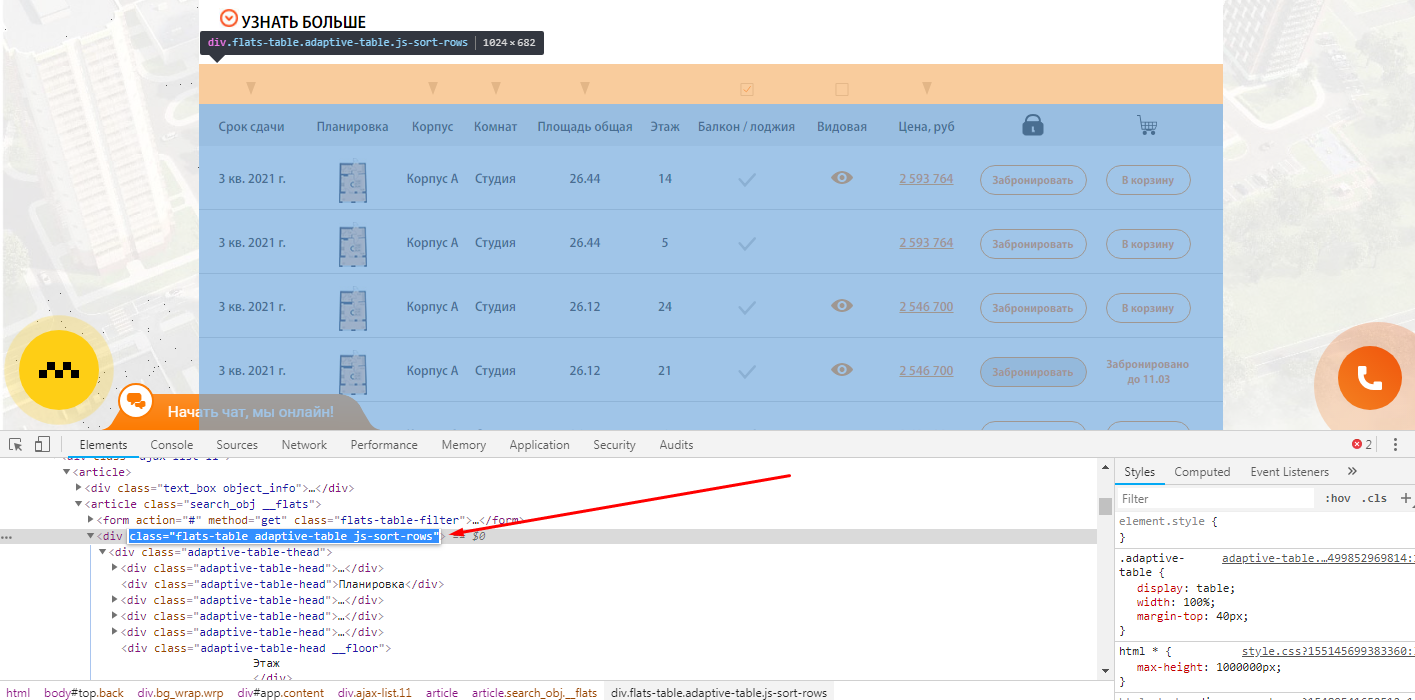
Чтобы было более понятна задача из примера, мы ищем страницы, блок которых выглядит вот так:
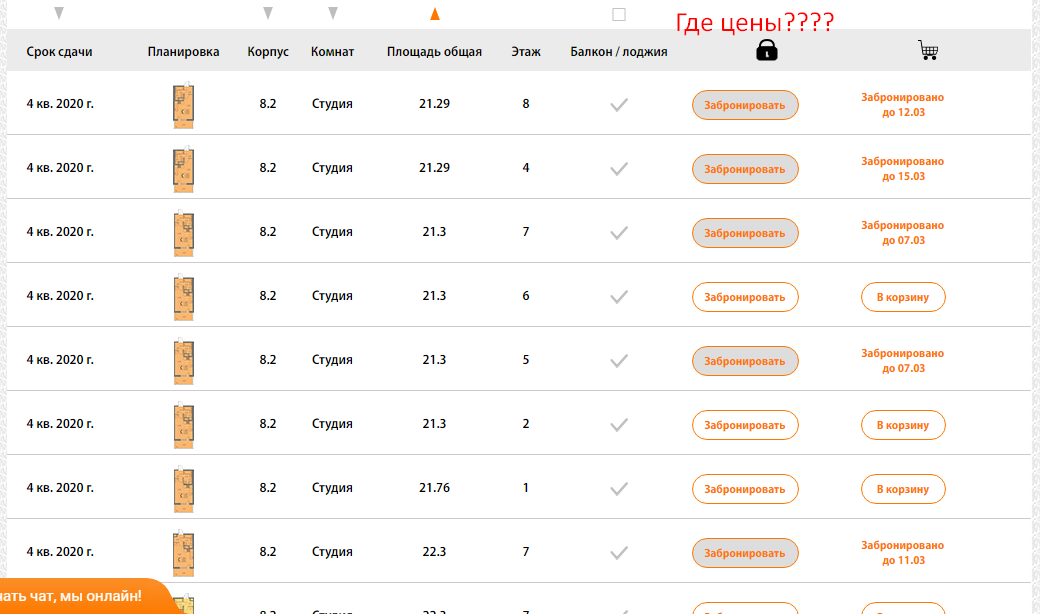
Тут же ищите элемент, который отсутствует на искомых страницах, но присутствует на нормальных страницах.
В нашем случае это столбец цен, и мы просто ищем страницы, где отсутствует столбец с таким названием (предварительно проверив, нет ли где в коде закомменченного подобного столбца)
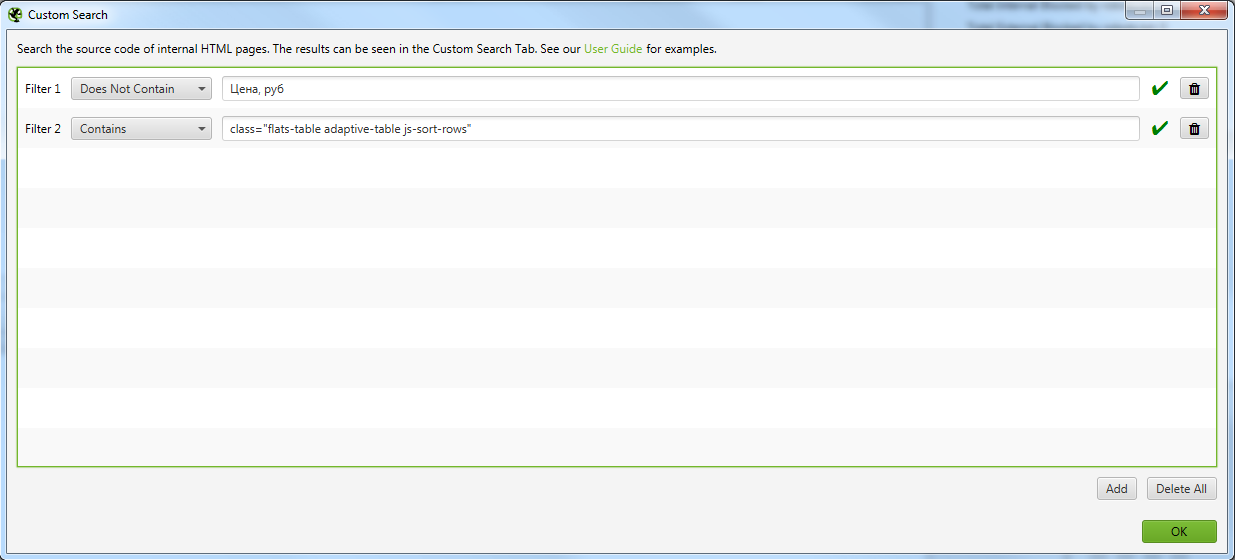
Выгружаем Custom 1 и Custom 2.
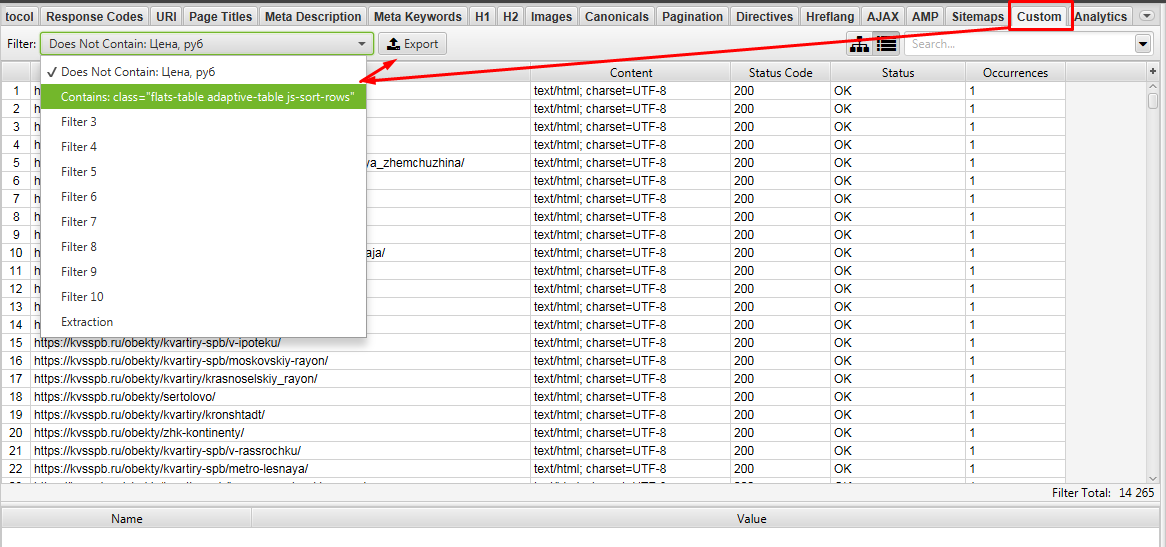
Далее в Excel ищем урлы которые совпадают между файлами Custom 1 и Custom 2. Для этого объединяем 2 файла в 1 таблицу Excel и с помощью «Повторяющихся значений» (предварительно нужно выделить проверяемый столбец).
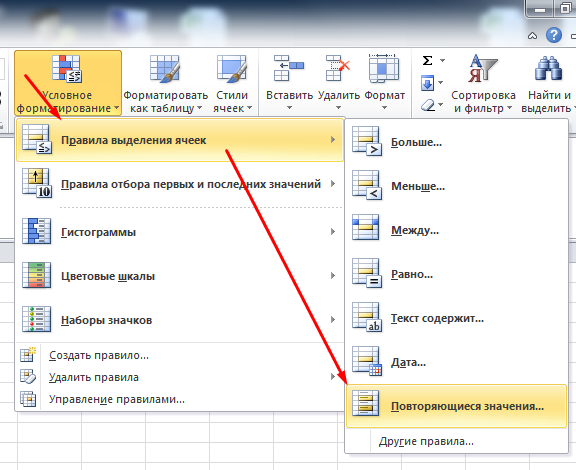
Фильтруем по красному цвету и получаем список урлов, где есть блок с выводом квартир, но нет столбца с ценами)!
Таким способом на сайте можно быстро найти и выгрузить выборку необходимых страниц для различных задач.
Пример 2 — Парсим содержимое заданного элемента на странице с помощью CSSPath
Давайте разбираться, как такое сделать
Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, текст которого нам нужно выгружать.
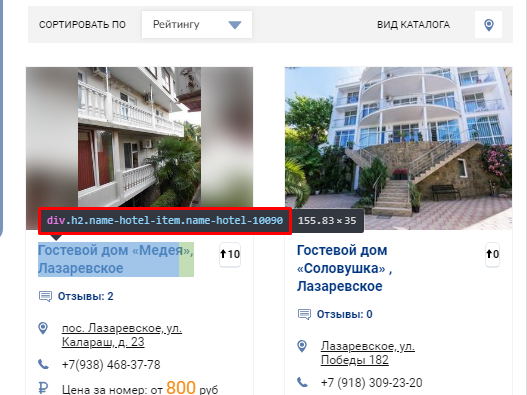
Выглядит это так
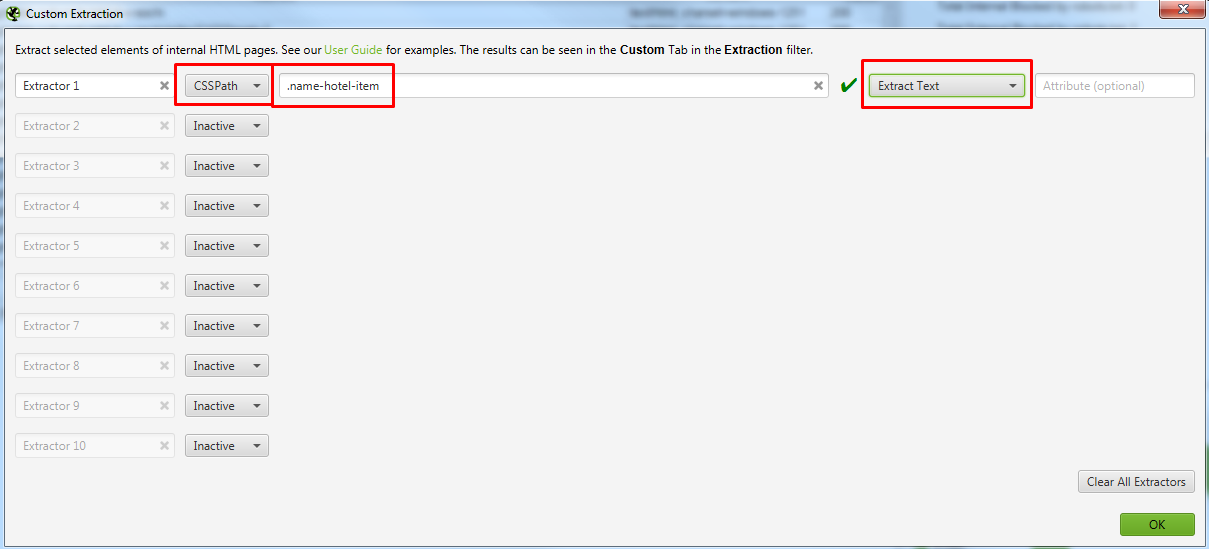
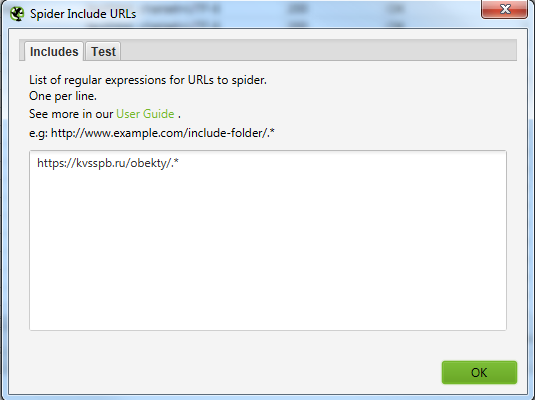
Для того, чтобы не парсить весь сайт целиком, вы можете ограничить область поиска с помощью указания конкретного раздела, который нужно парсить.
Указываем сюда разделы, в которых содержатся все нужные страницы.
Выглядит это вот так для обоих случаев.
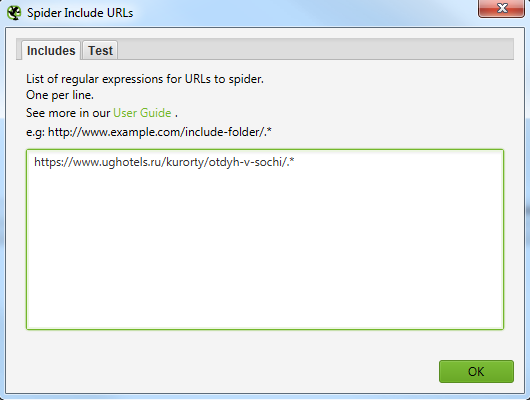
Далее парсим сайт, вбив в строку свой урл. В нашем случае это https://www.ughotels.ru/kurorty/otdyh-v-sochi.
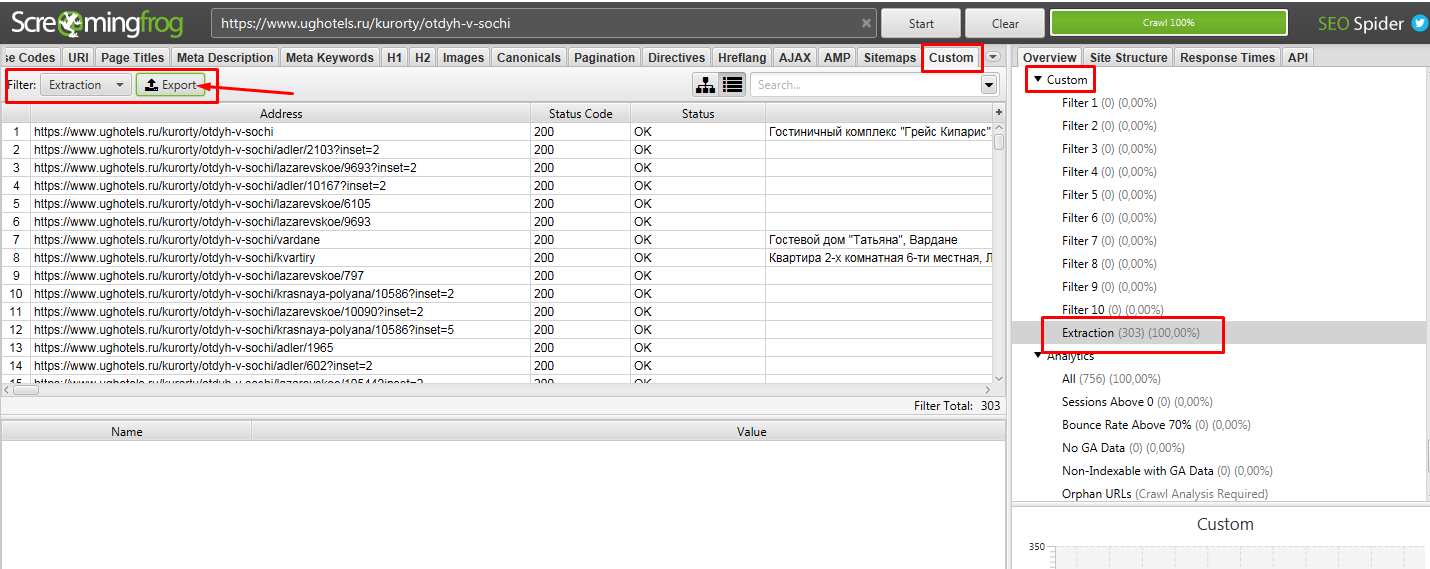
Теперь в Excel чистим файл от пустых данных, так как не на всех страницах есть подобные блоки, поэтому данных нет.
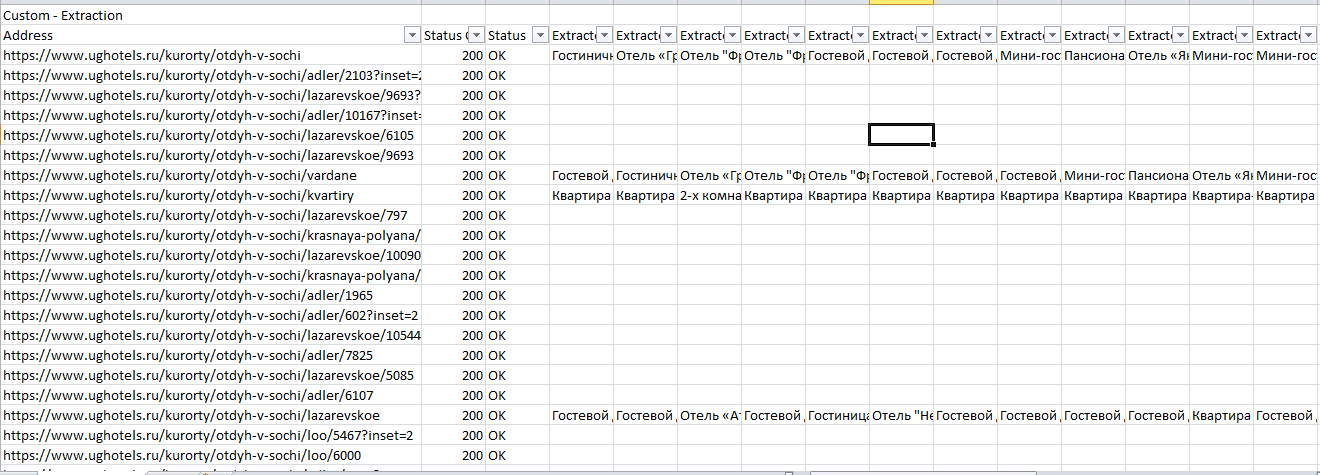
После фильтрации мы рекомендуем для удобства сделать транспонирование таблички на второй вкладке, так ее станет удобнее читать.
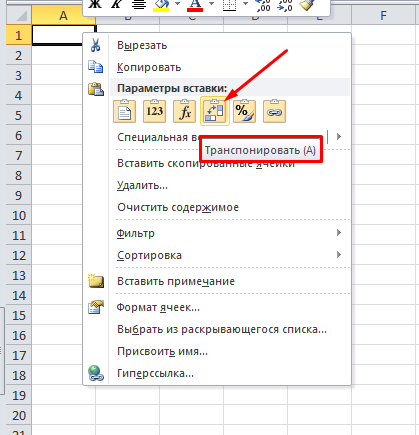
Для этого выделяем табличку, копируем и на новой вкладке нажимаем
Получаем итоговый файл: 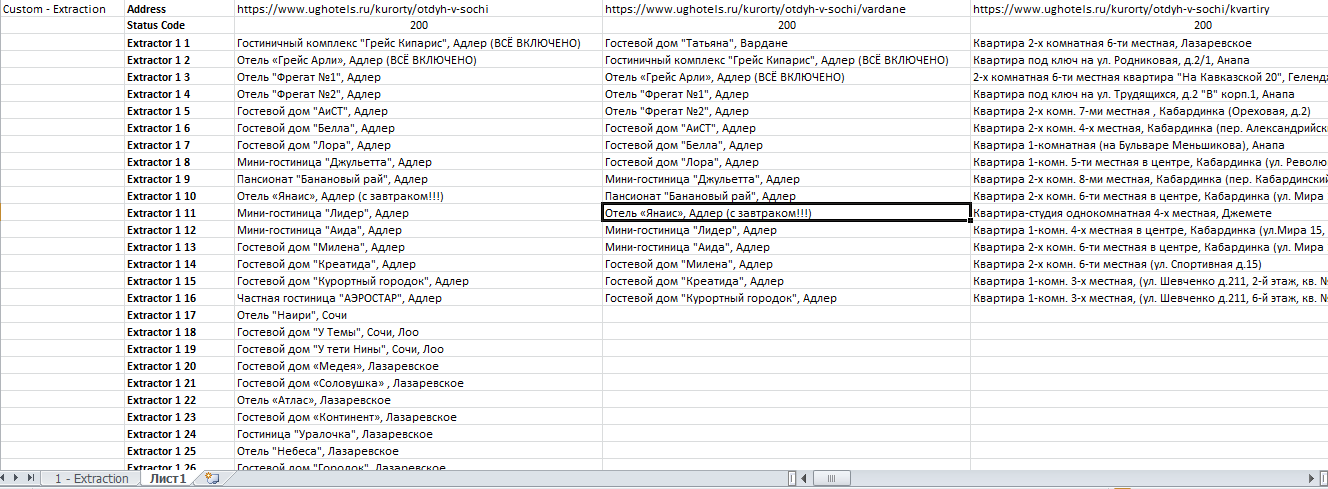
Пример 3 — Извлекаем содержимое нужных нам элементов сайта с помощью запросов XPath
Задача: Допустим, мы хотим спарсить нестандартные, необходимые только нам данные и получить на выходе таблицу с нужными нам столбцами — URL, Title, Description, h1, h2 и текст из конца страниц листингов товаров (например, https://www.funarena.ru/catalog/maty/). Таким образом, решаем сразу 2 задачи:
Сначала немного теории, знание которой позволит решить эту и многие другие задачи.
Технический парсинг сайта и сбор определенных данных со страницы с помощью запросов XPath
Как уже говорилось выше, SEO-специалисты используют технический парсинг сайта в основном для поиска “классических” тех. ошибок. У парсеров даже есть специальные алгоритмы, которые сразу помечают и классифицируют ошибки по типам, облегчая работу SEO специалиста.
Но бывают ситуации, когда с сайта необходимо извлечь содержимое конкретного класса или тега. Для этого на помощь приходит язык запросов XPath. С помощью него можно извлечь с сайта только нужную информацию, записать ее в удобный вид и затем работать с ней.
Ниже приведем примеры некоторых вариантов запросов XPath, которые могут быть вам полезны.
Данные взяты из официальной справки. Там вы сможете увидеть больше примеров.
По умолчанию парсер Screaming Frog SEO Spider собирает только h1 и h2, но если вы хотите собрать h3, то XPath запрос будет выглядеть так:
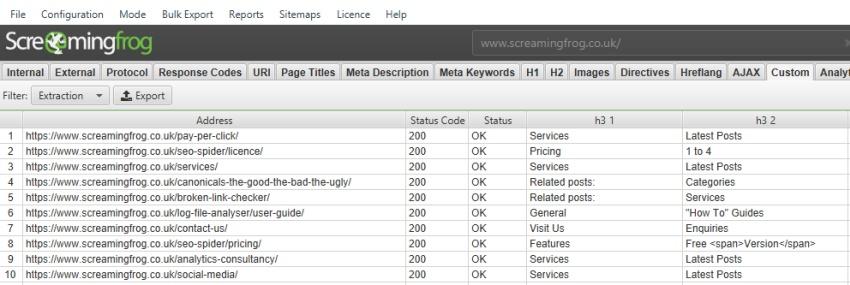
Если вы хотите спарсить только 1-й h3, то XPath запрос будет таким:
/descendant::h3[1]
Чтобы собрать первые 10 h3 на странице, XPath запрос будет:
/descendant::h3[position() >= 0 and position() Теперь вернемся к изначальной задаче
В предыдущем примере мы показали, как парсить с помощью CSSPath, принцип похож, но у него есть свои особенности.
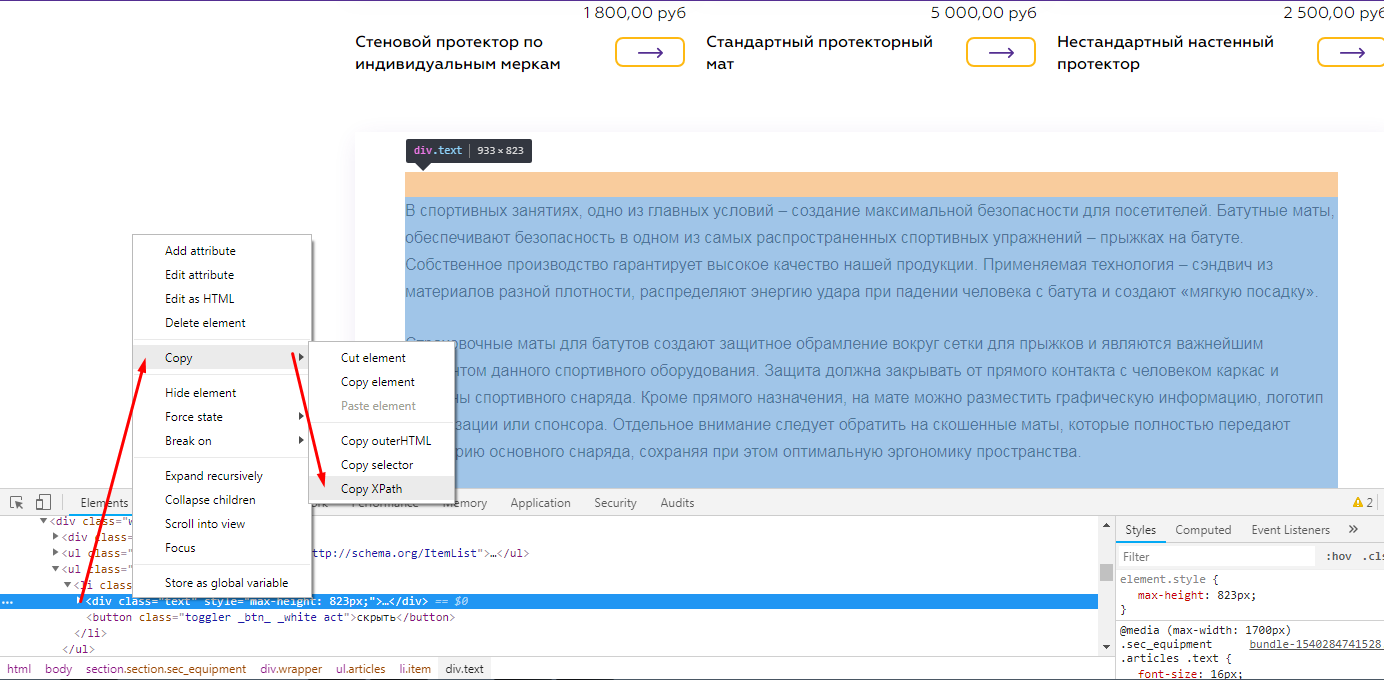
При таком копировании мы получили /html/body/section/div[2]/ul[2]/li/div
Для элементарного понимания, таким образом в коде зашифрована вложенность того места, где расположен текст. И мы получается будем проверять на страницах, есть ли текст по этой вложенности.
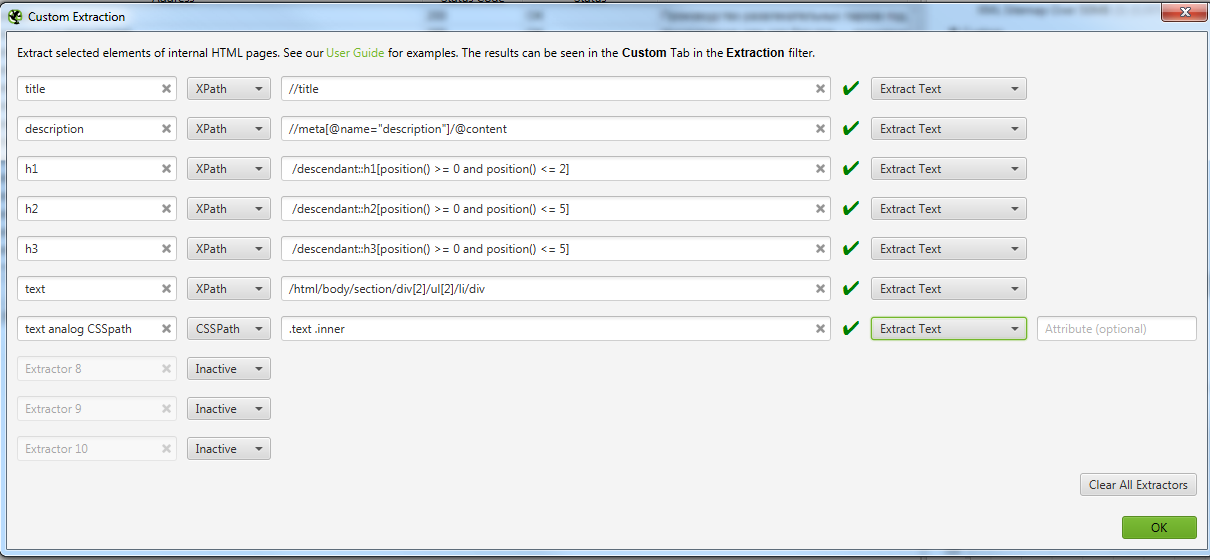
На скрине мы оставили вариант парсинга того же текста, но уже с помощью CSSPath, чтобы показать, что практически все можно спарсить 2-мя способами, но у Xpath все же больше возможностей.
Получаем Excel с нужными нам данными.
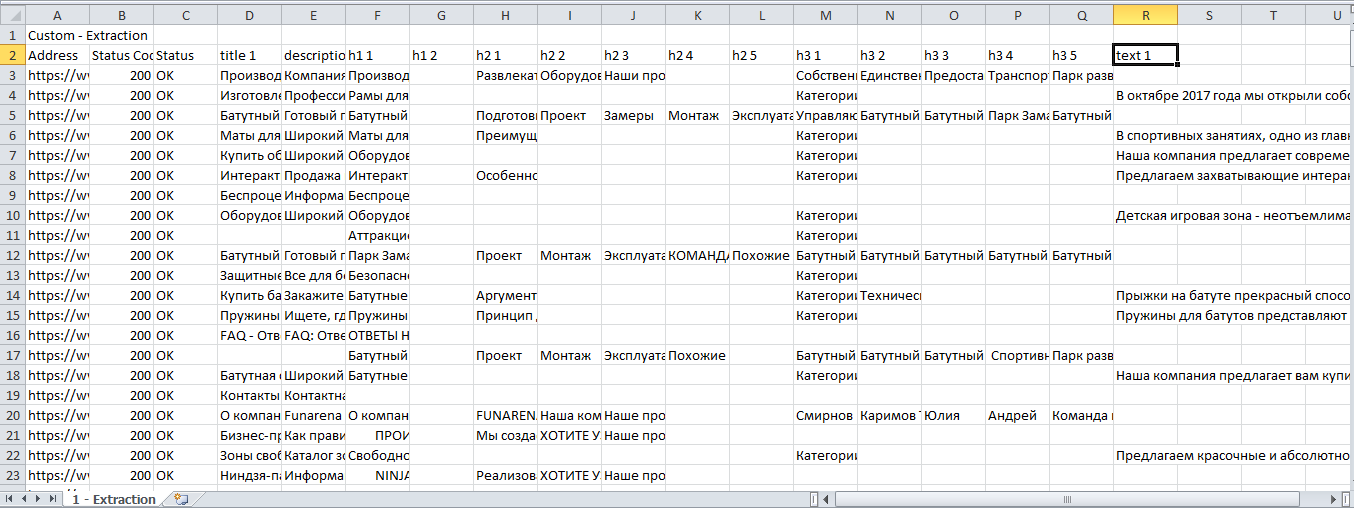
После фильтрации удобно сделать транспонирование полученных данных.

Пример 4 — Как спарсить цены и названия товаров с Интернет магазина конкурента
Задача: Спарсить товары и взять со страницы название товара и цену.

Начнем с того, что ограничим область парсинга до каталога, так как ссылки на все товары ресурса лежат в папке /catalog/. Но нас интересуют именно карточки товаров, а они лежат в папке /product/ и поэтому их тоже нужно парсить, так как информацию мы будем собирать именно с них.
https://okumashop.ru/catalog/.* ← Это страницы на которых расположены ссылки на товары.
https://okumashop.ru/product/.* ← Это страницы товаров, с которых мы будем получать информацию.
Для реализации задуманного мы воспользуемся уже известными нам методами извлечения данных с помощью CSSPath и XPath запросов.
Заходим на любую страницу товара, нажимаем F12 и через кнопку исследования элемента смотрим какой класс у названия товара.
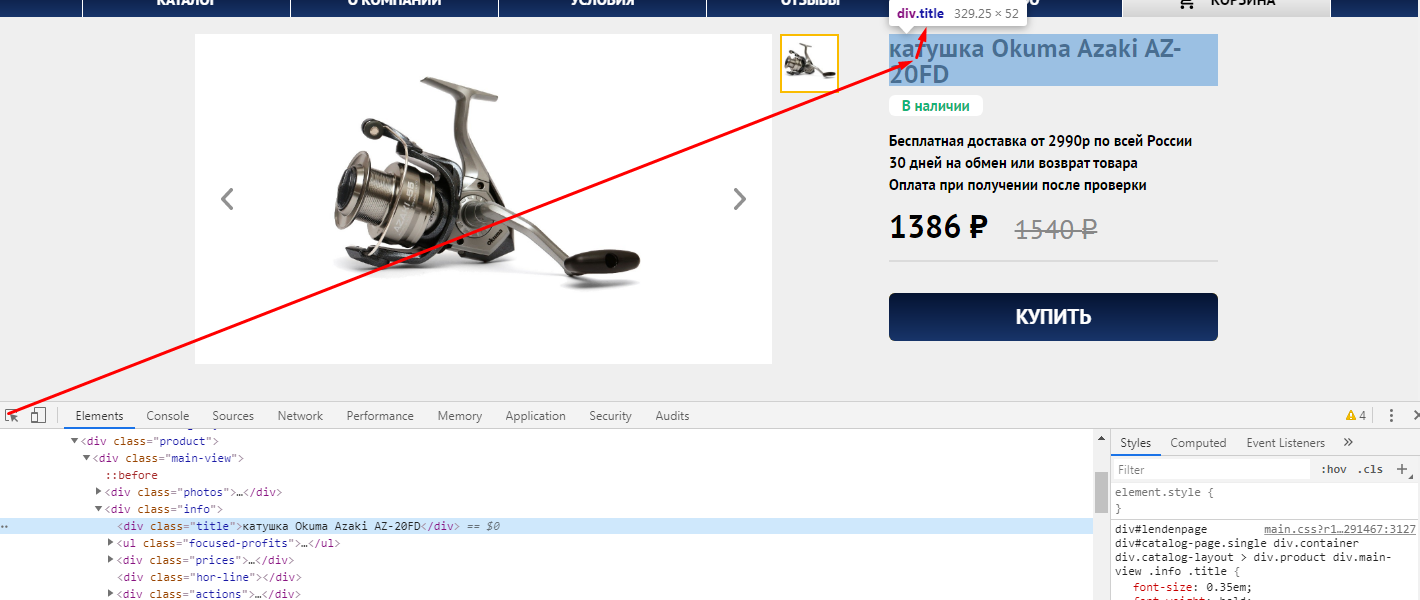
Иногда этого знания достаточно, чтобы получить нужные данные, но всегда стоит проверить, есть ли еще на сайте элементы, размеченные как
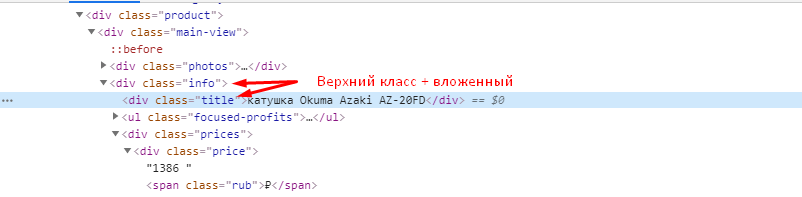
Цену можно получить, как с помощью CSSPath, так и с помощью Xpath.
Если хотим получить цену через XPath, то также через исследование элемента копируем путь XPath.
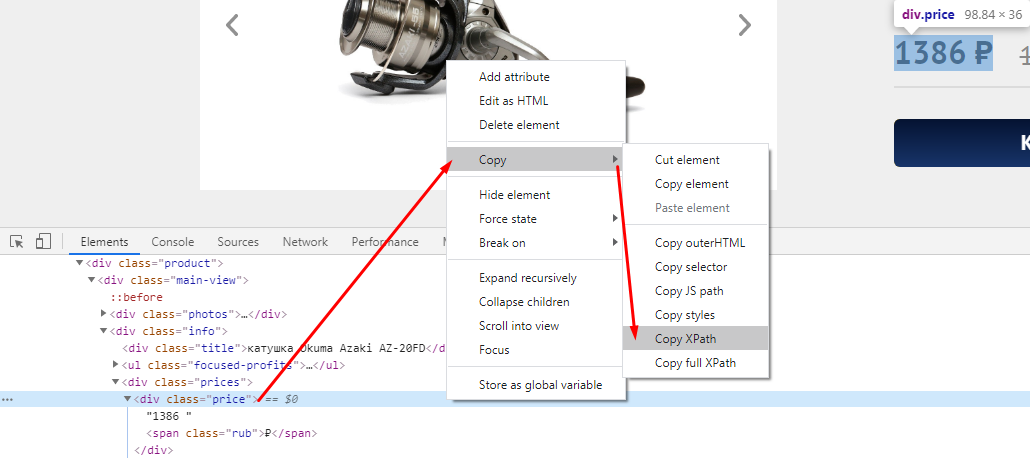
Получаем вот такой код //*[@id=»catalog-page»]/div/div/div/div[1]/div[2]/div[2]/div[1]
Идем в Configuration → Custom → Extraction и записываем все что мы выявили. Важно выбирать Extract Text, чтобы получать именно текст искомого элемента, а не сам код.
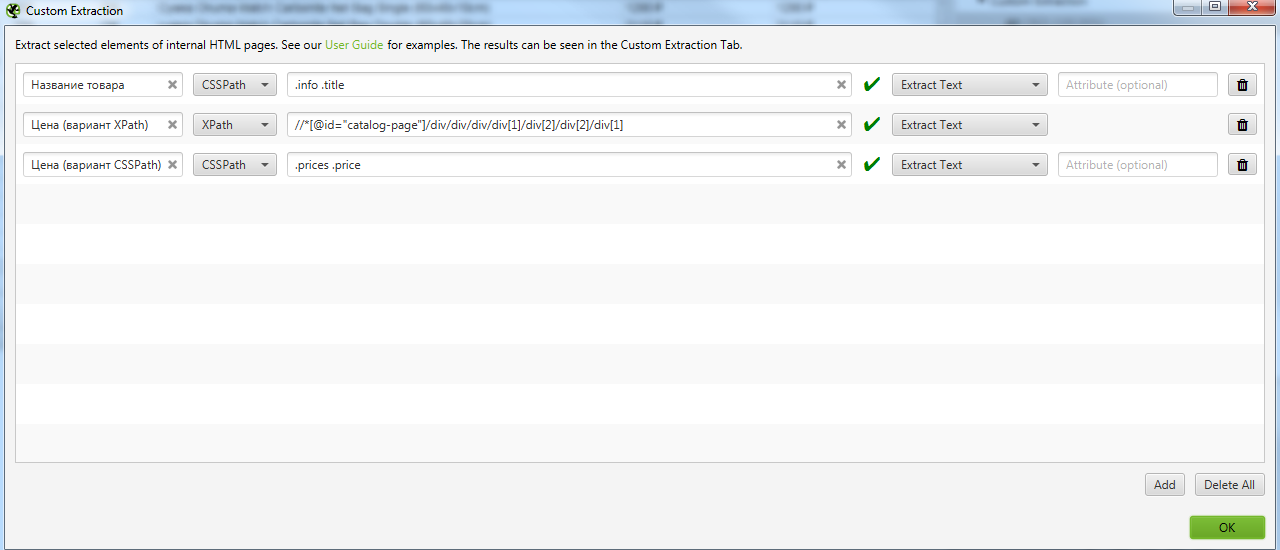
После парсим сайт. То, что мы хотели получить находится в разделе Custom Extraction. Подробнее на скрине.
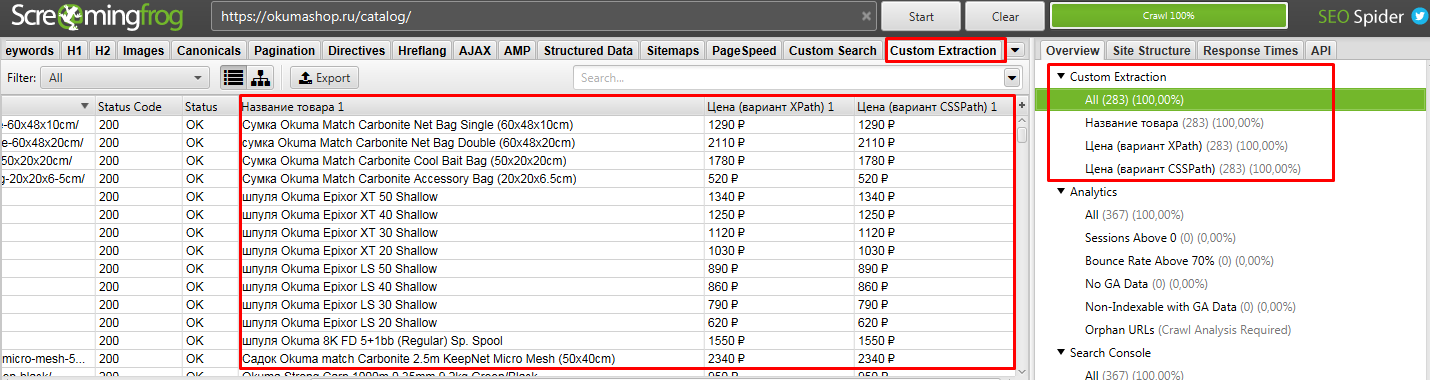
Выгружаем полученные данные.
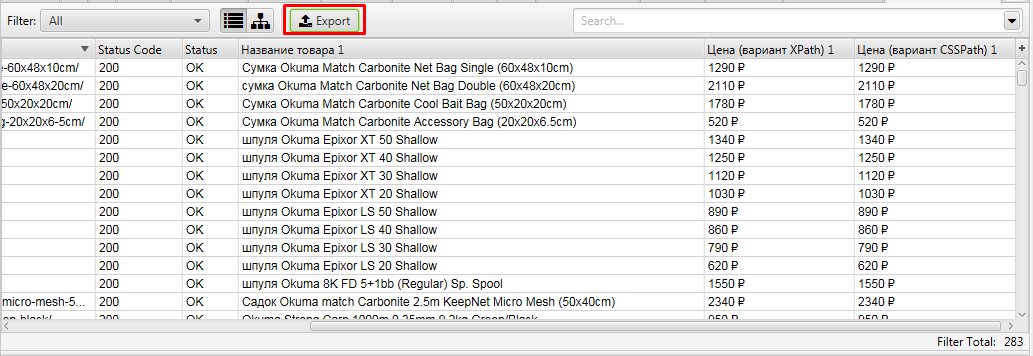
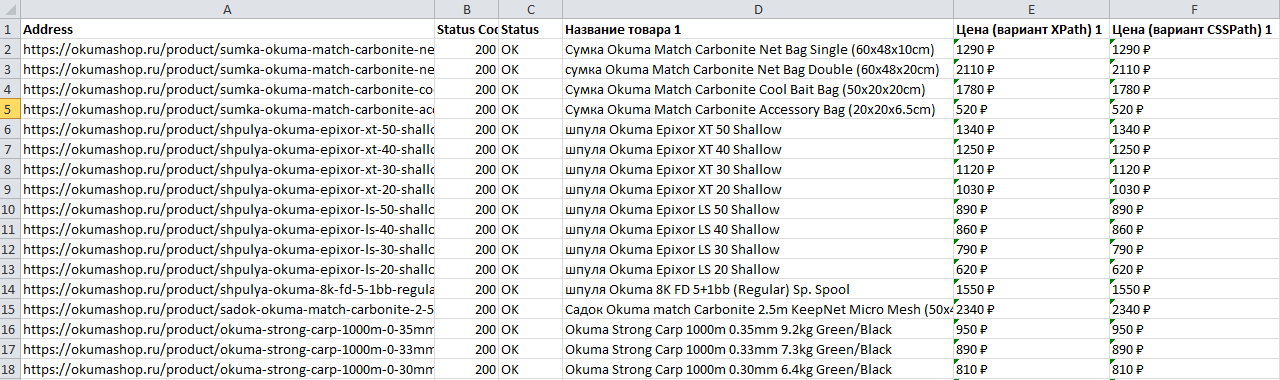
Получаем файл, где есть все необходимое, что мы искали — URL, Название и цена товара
Пример 5 — Поиск страниц-сирот на сайте (Orphan Pages)
Задача: — Поиск страниц, на которые нет ссылок на сайте, то есть им не передается внутренний вес.
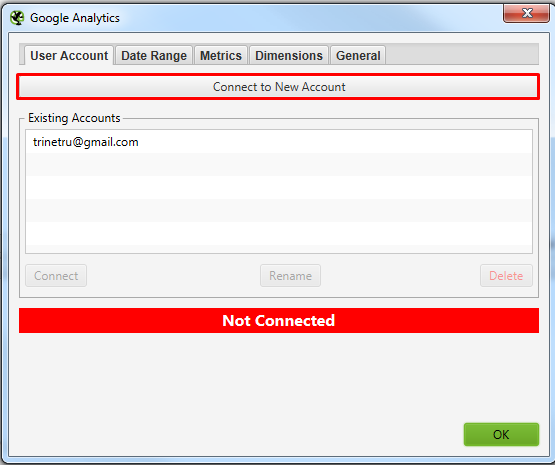
Для решения задачи нам потребуется предварительно подключить к Screaming frog SEO spider Google Search Console. Для этого у вас должны быть подтверждены права на сайт через GSC.
Screaming frog SEO spider в итоге спарсит ваш сайт и сравнит найденные страницы с данными GSC. В отчете мы получим страницы, которые она не обнаружила на сайте, но нашла в Search Console.
Давайте разбираться, как такое сделать.
Подключаемся к Google Search Console. Просто нажимаете кнопку, откроется браузер, где нужно выбрать аккаунт и нажать кнопку “Разрешить”.
В окошках, указанных выше нужно найти свой сайт, который вы хотите спарсить. С GSC все просто там можно вбить домен. А вот с GA не всегда все просто, нужно знать название аккаунта клиента. Возможно потребуется вручную залезть в GA и посмотреть там, как он называется.
Выбрали, нажали ок. Все готово к чуду.
Теперь можно приступать к парсингу сайта.
Тут ничего нового. Если нужно спарсить конкретный поддомен, то в Include его добавляем и парсим как обычно.
Если по завершению парсинга у вас нет надписи “API 100%”
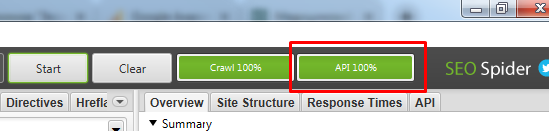

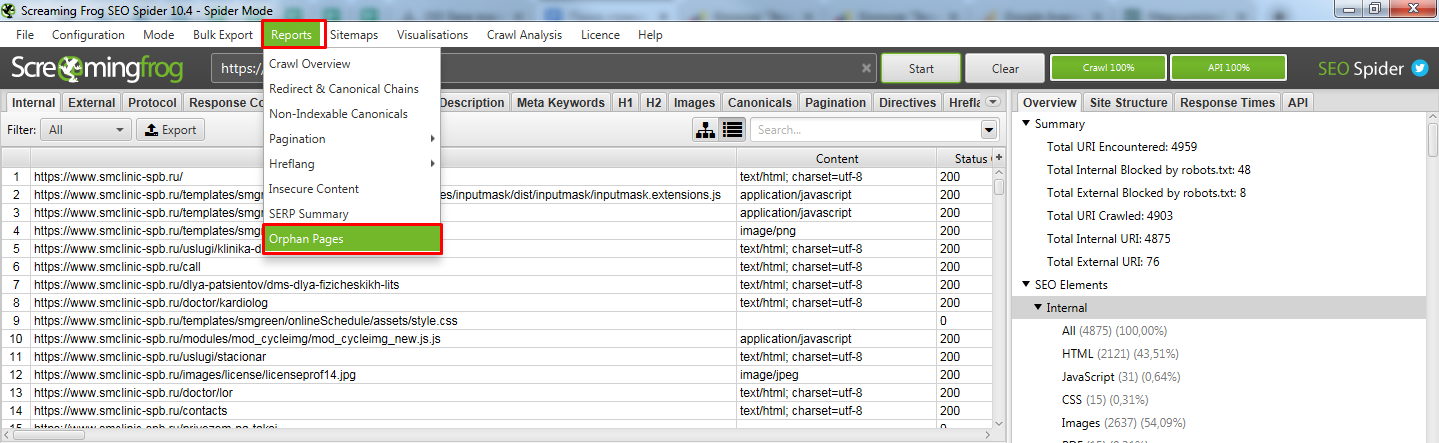
Открываем получившийся отчет. Получили список страниц, которые известны Гуглу, но Screaming frog SEO spider не обнаружил ссылок на них на самом сайте.
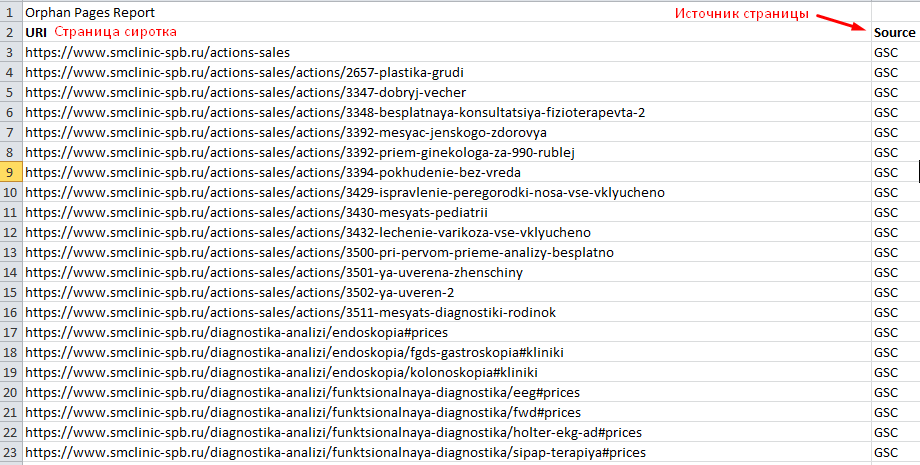
Возможно тут будет много лишних страниц (которые отдают 301 или 404 код ответа), поэтому рекомендуем прогнать весь этот список еще раз, используя метод List.
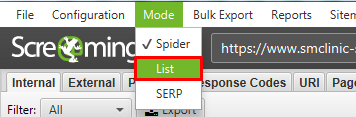
После парсинга всех найденных страниц, выгружаем список страниц, которые отдают 200 код. Таким образом вы получаете реальный список страниц-сирот с которыми нужно работать.
На такие страницы нужно разместить ссылки на сайте, если в них есть необходимость, либо удаляем страницы или настраиваем 301 редирект на существующие похожие страницы.
Вывод
Парсеры помогают очень быстро решить множество задач не только технического характера (поиска ошибок), но и массу бизнес задач, таких как, собрать структуру сайта конкурента, спарсить цены и названия товаров и и другие полезные данные.



