Паук (программа)
Поиско́вый ро́бот («веб-пау́к», краулер) — программа, являющаяся составной частью поисковой системы и предназначенная для обхода страниц Интернета с целью занесения информации о них в базу данных поисковика. По принципу действия паук напоминает обычный браузер. Он анализирует содержимое страницы, сохраняет его в некотором специальном виде на сервере поисковой машины, которой принадлежит, и отправляется по ссылкам на следующие страницы. Владельцы поисковых машин нередко ограничивают глубину проникновения паука внутрь сайта и максимальный размер сканируемого текста, поэтому чересчур большие сайты могут оказаться не полностью проиндексированными поисковой машиной. Кроме обычных пауков, существуют так называемые «дятлы» — роботы, которые «простукивают» проиндексированный сайт, чтобы определить, что он доступен.
Порядок обхода страниц, частота визитов, защита от зацикливания, а также критерии выделения значимой информации определяются поисковыми алгоритмами.
В большинстве случаев переход от одной страницы к другой осуществляется по ссылкам, содержащимся на первой и последующих страницах.
Также многие поисковые системы предоставляют пользователю возможность самостоятельно добавить сайт в очередь для индексирования. Обычно это существенно ускоряет индексирование сайта, а в случаях, когда никакие внешние ссылки не ведут на сайт, вообще оказывается единственной возможностью указать на его существование.
Ограничить индексацию сайта можно с помощью файла
Паук (пасьянс)



«Пау́к» — карточный пасьянс. Является одним из стандартных пасьянсов в Windows.
Содержание
Правила
Для пасьянса требуется 2 колоды карт. Изначально 54 карты равномерно раскладываются в 10 столбцов (то есть получается 4 столбца по 6 карт и 6 по 5), остальные 50 складываются в 5 кучек по 10. В каждом столбце все карты, кроме верхних, закрыты. Разрешается перемещать карты из столбца в столбец. Карты перемещают по следующим правилам:
Если освободилась верхняя закрытая карта какого-либо столбца, то она автоматически открывается. Как только появляется столбец из собранных по порядку карт одной масти, этот столбец убирается в дом. Разрешается в любой момент времени, когда нет пустых столбцов, взять одну из отложенных кучек по 10 карт и раскидать эти карты по одной в каждый столбец. Цель игры — собрать все карты в дом.
Реализации
Сложность
Пасьянс сложнее косынки, но если сравнивать с солитером, то видно, что вероятность выигрыша намного меньше. В сложной игре (Четыре масти) вероятность выигрыша достигает, по крайней мере, 30 %. Активно используя отмену ходов, вероятность выигрыша близка 50 %. Выбирая перспективные варианты первоначальных раскладов вероятность выигрыша существенно превышает 50 %. [источник не указан 565 дней]
См. также
Контакты • DVD Maker • Факсы и сканирование • Internet Explorer • Журнал • Экранная лупа • Media Center • Проигрыватель Windows Media • Программа совместной работы • Центр устройств Windows Mobile • Центр мобильности • Экранный диктор • Paint • Редактор личных символов • Удалённый помощник • Распознавание речи • WordPad • Блокнот • Боковая панель • Звукозапись • Календарь • Калькулятор • Ножницы • Почта • Таблица символов • Исторические: Movie Maker • NetMeeting • Outlook Express • Диспетчер программ • Диспетчер файлов • Фотоальбом
Chess Titans • Mahjong Titans • Purble Place • Пасьянсы (Косынка • Паук • Солитер) • Сапёр • Пинбол • Червы
Autorun.inf • Фоновая интеллектуальная служба передачи • Файловая система стандартного журналирования • Отчёты об ошибках • Планировщик классов мультимедиа • Теневая копия • Планировщик задач • Беспроводная настройка
Active Directory • Службы развёртывания • Служба репликации файлов • DNS • Домены • Перенаправление папок • Hyper-V • IIS • Media Services • MSMQ • Защита доступа к сети (NAP) • Службы печати для UNIX • Удалённое разностное сжатие • Службы удаленной установки • Служба управления правами • Перемещаемые профили пользователей • SharePoint • Диспетчер системных ресурсов • Удаленный рабочий стол • WSUS • Групповая политика • Координатор распределённых транзакций
Поиск под капотом Глава 1. Сетевой паук
Умение искать информацию в Интернете является жизненно необходимым. Когда мы нажимаем на кнопку «искать» в нашей любимой поисковой системе, через доли секунды мы получаем ответ.
Большинство совершенно не задумывается о том, что же происходит «под капотом», а между тем поисковая система — это не только полезный инструмент, но еще и сложный технологический продукт. Современная поисковая система для своей работы использует практически все передовые достижения компьютерной индустрии: большие данные, теорию графов и сетей, анализ текстов на естественном языке, машинное обучение, персонализацию и ранжирование. Понимание того, как работает поисковая система, дает представление об уровне развития технологий, и поэтому разобраться в этом будет полезно любому инженеру.

В нескольких статьях я шаг за шагом расскажу о том, как работает поисковая система, и, кроме того, для иллюстрации я построю свой собственный небольшой поисковый движок, чтобы не быть голословным. Этот поисковый движок будет, конечно же, «учебным», с очень сильным упрощением того, что происходит внутри гугла или яндекса, но, с другой стороны, я не буду упрощать его слишком сильно.
Первый шаг — это сбор данных (или, как его еще называют, краулинг).
Веб — это граф
Та часть Интернета, которая нам интересна, состоит из веб-страниц. Для того чтобы поисковая система смогла найти ту или иную веб-страницу по запросу пользователя, она должна заранее знать, что такая страница существует и на ней содержится информация, релевантная запросу. Пользователь обычно узнает о существовании веб-страницы от поисковой системы. Каким же образом сама поисковая система узнает о существовании веб-страницы? Ведь никто ей не обязан явно сообщать об этом.
К счастью, веб-страницы не существуют сами по себе, они содержат ссылки друг на друга. Поисковый робот может переходить по этим ссылкам и открывать для себя все новые веб-страницы.
На самом деле структура страниц и ссылок между ними описывает структуру данных под названием «граф». Граф по определению состоит из вершин (веб-страниц в нашем случае) и ребер (связей между вершинами, в нашем случае — гиперссылок).
Другими примерами графов являются социальная сеть (люди — вершины, ребра — отношения дружбы), карта дорог (города — вершины, ребра — дороги между городами) и даже все возможные комбинации в шахматах (шахматная комбинация — вершина, ребро между вершинами существует, если из одной позиции в другую можно перейти за один ход).
Графы бывают ориентированными и неориентированными — в зависимости от того, указано ли на ребрах направление. Интернет представляет собой ориентированный граф, так как по гиперссылкам можно переходить только в одну сторону.
Для дальнейшего описания мы будем предполагать, что Интернет представляет собой сильно связный граф, то есть, начав в любой точке Интернета, можно добраться до любой другой точки. Это допущение — очевидно неверное (я могу легко создать новую веб-страницу, на которую не будет ссылок ниоткуда и соответственно до нее нельзя будет добраться), но для задачи проектирования поисковой системы его можно принять: как правило, веб-страницы, на которые нет ссылок, не представляют большого интереса для поиска.
Небольшая часть веб-графа:
Алгоритмы обхода графа: поиск в ширину и в глубину
Поиск в глубину
Существует два классических алгоритма обхода графов. Первый — простой и мощный — алгоритм называется поиск в глубину (Depth-first search, DFS). В его основе лежит рекурсия, и он представляет собой следующую последовательность действий:
Код на Python, имплементирующий данный подход буквально дословно:
Метод поиска в глубину целесообразно применять для того, чтобы обойти веб-страницы на небольшом сайте, однако для обхода всего Интернета он не очень удобен:
В целом обе эти проблемы можно решить, но мы вместо этого воспользуемся другим классическим алгоритмом — поиском в ширину.
Поиск в ширину
Поиск в ширину (breadth-first search, BFS) работает схожим с поиском в глубину образом, однако он обходит вершины графа в порядке удаленности от начальной страницы. Для этого алгоритм использует структуру данных «очередь» — в очереди можно добавлять элементы в конец и забирать из начала.
Понятно, что в очереди сначала окажутся вершины, находящиеся на расстоянии одной ссылки от начальной, потом двух ссылок, потом трех ссылок и т. д., то есть алгоритм поиска в ширину всегда доходит до вершины кратчайшим путем.
Еще один важный момент: очередь и множество «увиденных» вершин в данном случае используют только простые интерфейсы (добавить, взять, проверить на вхождение) и легко могут быть вынесены в отдельный сервер, коммуницирующий с клиентом через эти интерфейсы. Эта особенность дает нам возможность реализовать многопоточный обход графа — мы можем запустить несколько одновременных обработчиков, использующих одну и ту же очередь.
Robots.txt
Прежде чем описать собственно имплементацию, хотелось бы отметить, что хорошо ведущий себя краулер учитывает запреты, установленные владельцем веб-сайта в файле robots.txt. Вот, например, содержимое robots.txt для сайта lenta.ru:
Видно, что тут определены некоторые разделы сайта, которые запрещено посещать роботам яндекса, гугла и всем остальным. Для того чтобы учитывать содержимое robots.txt в языке python, можно воспользоваться реализацией фильтра, входящего в стандартную библиотеку:
Имплементация
Итак, мы хотим обойти Интернет и сохранить его для последующей обработки.
Конечно, в демонстрационных целях обойти и сохранить весь Интернет не выйдет — это стоило бы ОЧЕНЬ дорого, но разрабатывать код мы будем с оглядкой на то, что потенциально его можно было бы масштабировать до размеров всего Интернета.
Это означает, что работать мы должны на большом количестве серверов одновременно и сохранять результат в какое-то хранилище, из которого его можно будет легко обработать.
В качестве основы для работы своего решения я выбрал Amazon Web Services, так как там можно легко поднять определенное количество машин, обработать результат и сохранить его в распределенное хранилище Amazon S3. Похожие решения есть, например, у google, microsoft и у яндекса.

Архитектура разработанного решения
Центральным элементом в моей схеме сбора данных является сервер очереди, хранящий очередь URL, подлежащих скачиванию и обработке, а также множество URL, которые наши обработчики уже «видели». В моей имплементации это они основаны на простейших структурах данных Queue и set языка python.
В реальной продакшн-системе, скорее всего, вместо них стоило бы использовать какое-нибудь существующее решение для очередей (например, kafka) и для распределенного хранения множеств (например, подошли бы решения класса in-memory key-value баз данных типа aerospike). Это позволило бы достичь полной горизонтальной масштабируемости, но в целом нагрузка на сервер очереди оказывается не очень большой, поэтому в таком масштабировании в моем маленьком демо-проекте смысла нет.
Рабочие серверы периодически забирают новую группу URL для скачивания (забираем сразу помногу, чтобы не создавать лишнюю нагрузку на очередь), скачивают веб-страницу, сохраняют ее на s3 и добавляют новые найденные URL в очередь на скачивание.
Для того чтобы снизить нагрузку на добавление URL, добавление тоже происходит группами (добавляю сразу все новые URL, найденные на веб-странице). Еще я периодически синхронизирую множество «увиденных» URL с рабочими серверами, чтобы осуществлять предварительную фильтрацию уже добавленных страниц на стороне рабочей ноды.
Скачанные веб-страницы я сохраняю на распределенном облачном хранилище (S3) — это будет удобно впоследствии для распределенной обработки.
Очередь периодически отправляет статистику по количеству добавленных и обработанных запросов в сервер статистики. Статистику отправляем суммарно и в отдельности для каждой рабочей ноды — это необходимо для того, чтобы было понятно, что скачивание происходит в штатном режиме. Читать логи каждой отдельной рабочей машины невозможно, поэтому следить за поведением будем на графиках. В качестве решения для мониторинга скачивания я выбрал graphite.
Запуск краулера
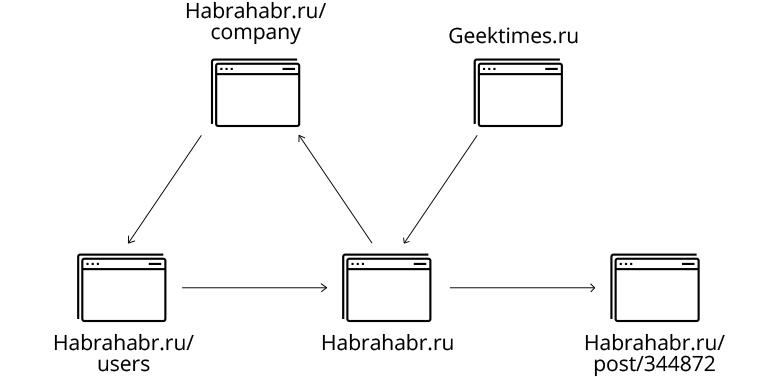
Как я уже писал, для того чтобы скачать весь Интернет, нужно огромное количество ресурсов, поэтому я ограничился только маленькой его частью — а именно сайтами habrahabr.ru и geektimes.ru. Впрочем, ограничение это довольно условное, и расширение его на другие сайты — просто вопрос количества доступного железа. Для запуска я реализовал простенькие скрипты, которые поднимают новый кластер в облаке amazon, копируют туда исходный код и запускают соответствующий сервис:
Код скрипта deploy.py, содержащего все вызываемые функции
Использование в качестве инструмента статистики graphite позволяет рисовать красивые графики:
Красный график — найденные URL, зеленый — скачанные, синий — URL в очереди. За все время скачано 5.5 миллионов страниц.
Количество скрауленных страниц в минуту в разбивке по рабочим нодам. Графики не прерываются, краулинг идет в штатном режиме.
Результаты
Скачивание habrahabr и geektimes у меня заняло три дня.
Можно было бы скачать гораздо быстрее, увеличив количество экземпляров воркеров на каждой рабочей машине, а также увеличив количество воркеров, но тогда нагрузка на сам хабр была бы очень большой — зачем создавать проблемы любимому сайту?
В процессе работы я добавил пару фильтров в краулер, начав фильтровать некоторые явно мусорные страницы, нерелевантные для разработки поискового движка.
Разработанный краулер, хоть и является демонстрационным, но в целом масштабируется и может применяться для сбора больших объемов данных с большого количества сайтов одновременно (хотя, возможно, в продакшне есть смысл ориентироваться на существующие решения для краулинга, такие как heritrix. Реальный продакшн-краулер также должен запускаться периодически, а не разово, и реализовывать много дополнительного функционала, которым я пока пренебрег.
В следующей статье цикла я построю индекс по скачанным веб-страницам при помощи технологий больших данных и спроектирую простейший движок собственно поиска по скачанным страницам.
Поисковой паук (краулер): виды и функции
Поисковый паук (другие наименования — робот, веб-паук, краулер) — программа поисковой системы, сканирующая веб-ресурсы для отражения сведений о них в базе данных.
С какой целью создают поисковых пауков?
Приведём элементарный пример. Представим себе Иванова Валерия, который регулярно посещает сайт http://it-ebooks.info/, где ежедневно публикуются новые электронные книги. Заходя на ресурс, Валерий выполняет заданную последовательность действий:
1) открывает главную страницу;
2) заходит в раздел «Последние загруженные произведения»;
3) оценивает новинки из списка;
4) при появлении интересных заголовков, проходит по ссылкам;
5) читает аннотацию и, если она интересна, скачивает файл.
Указанные действия отнимают у Валерия 10 минут. Однако, если тратить на поиск 10 минут в день, в месяц это уже 5 часов. Вместо этого к задаче можно привлечь программу, отслеживающую новинки по расписанию. По механизму действия она будет представлять собой простейшего веб-паука, заточенного под выполнение определенных функций. Без краулеров не выживет никакая поисковая система, будь то лидеры Google и «Яндекс» или предприимчивые стартапы. Боты перемещаются по сайтам, отыскивая сырье для поисковой системы. При этом чем с большей отдачей трудится паук, тем актуальнее результаты выдачи (рис. 1).
.jpg/200px-%D0%A1%D0%BA%D1%80%D0%B8%D0%BD%D1%88%D0%BE%D1%82_1_(24).jpg)
.jpg/200px-%D0%A1%D0%BA%D1%80%D0%B8%D0%BD%D1%88%D0%BE%D1%82_2_(17).jpg)
.jpg/200px-%D0%A1%D0%BA%D1%80%D0%B8%D0%BD%D1%88%D0%BE%D1%82_3_(13).jpg)
В зависимости от поисковой системы, функции, которые мы перечислим ниже, могут выполнять один или несколько роботов.
1. Сканирование контента сайта. Функция краулера первого порядка — обнаружение вновь созданных страниц и сбор размещенной текстовой информации.
2. Считывание графики. Если поисковая система подразумевает поиск графических файлов, для этой цели может быть введен отдельный веб-паук.
3. Сканирование зеркал. Робот находит идентичные по содержанию, но разные по адресу, ресурсы. «Работник», наделенный такими должностными полномочиями, есть у «Яндекса».
Содержание
Виды поисковый роботов
У поисковых систем есть несколько пауков, каждый из которых поддерживает выполнение запрограммированных функций (рис. 2).
Пауки «Яндекс»
Пауки Google
Вежливые пауки — как научить роботов правилам поведения
Вежливыми называют краулеров, которые действуют, придерживаясь существующих правил поведения на сайте. Эти правила пишут вебмастеры, размещая их в файле robots.txt (рис. 3). Пауки, которые попадают на сайт, на начальном этапе изучают информацию в указанном файле, где перечислены страницы, содержание которых не подлежит разглашению (регистрационные данные пользователей, административные сведения). Получив указания, паук приступает к индексации сайта, либо покидает его.
В robots.txt прописывают:
User-Agent: Twitterbot Allow: /images
Расшифруем эти данные:
Вежливый робот всегда представляется и указывает в заголовке запроса реквизиты, которые дают возможность вебмастеру связаться с владельцем. Для чего вводятся ограничения? Владельцы ресурсов заинтересованы в привлечении реальных пользователей и не желают, чтобы программы строили на их контенте свой бизнес. Для этих целей сайты часто настраивают на обслуживание браузерных HTTP-запросов и лишь за тем — запросов от программ.
Пауки в интернете: вас подслушивают
Пауков в интернете пруд пруди, они обходят Интернет с целью сбора и агрегирования информации и даже. следят за всем тем, что Вы отправляете и получаете из интернета. Для чего это делается? Тема очень просторная, я не буду на ней останавливаться, я хочу лишь показать Вам парочку живых примеров (их Вы сами можете проверить экспериментальным путем) для иллюстрации.
Файл ловушка для ботов
Файл «ловушка» будет выглядеть следующим образом (простой php-код):
Загружаем этот php файл к себе на хостинг, и делаем секретную ссылку (чтобы никто по ней не мог перейти, кроме жертвы), типа /jcii549dskj.php
Ловим ботов в типичных ситуациях
Под «типичными ситуациями» я подразумеваю перечень интернет-узлов, которыми каждый из нас пользуется ежедневно в интернете: почта, социальные сети, поиск. Разумеется, их перечень и вариации могут быть разнообразными. Я покажу примеры некоторых из них, проверить остальные (интересующие Вас), Вы сможете самостоятельно.
Почтовые сервисы (Gmail и Яндекс)
Я написал письмо, как с этих почтовых сервисов (имеется ввиду Gmail и Яндекс), так и на ящики, находящиеся на них! В письме я поместил ссылку-ловушку! К своему удивлению, лог-файл оказался пустой. Никто не перешел по ссылке в письме. Я долго пребывал в недоумении и на всякий случай прождал целые сутки, подозревая, что рано или поздно боты поинтересуются содержимым ссылки, что свидетельствовало бы об индексации содержимого писем. Напрасно, по ссылке никто из них не перешел. Впрочем, это не отрицает возможности индексации самих писем, это лишь свидетельство того, что ссылками в письме никто не поинтересовался.
Социальные сети
С социальными сетями совершенно иная ситуация. Здесь люди контактируют, общение внутри таких сетей давно заменили мессенджеров. Поэтому нет ничего удивительного в положительных результатах теста. В эксперименте участвовали: Вконтакте, Фейсбук и Одноклассники.
Ссылка-ловушка отправлялась личным сообщением друзьям. Обратите внимание на слово «личным», которое подразумевает не публичность, тайну.
Бот Вконтакте перешел по ссылке в сообщении в первую же секунду:
Бот Фейсбук перешел по ссылке уже в тот момент, когда ссылка была лишь вставлена из буфера обмена в окно сообщения (само сообщение еще не было отправлено):
Боты в социальных сетях переходят сразу же по ссылках для создания превью страницы, а также для информирования пользователя о вредоносных ссылках. И кто знает, для чего еще?
Поисковые системы
SEO-оптимизаторов всегда интересовал этот вопрос: переходят ли боты по ссылке, если ее искать в поиске?
В ходе эксперимента удалось выяснить, что ни Google, ни Яндекс, не переходят по ссылке, если ее ввести в поисковую строку поисковика!
Мессенджеры
В Skype бот переходит сразу же после отправки сообщения:
ICQ (он же Аська), под покровительством Mail.Ru Group, теряющий в настоящее время аудиторию семимильными шагами, переходы ботов не обнаружены (почему-то).
P.S. Путем нехитрого эксперимента, мы убедились, что в некоторых местах, отправляемая нами информация через интернет перехватывается, даже если речь идет о «личной» переписке.
Специализируюсь на безопасности сайтов: защищаю сайты от атак и взломов, занимаюсь лечением вирусов на сайтах и профилактикой.
Наверняка у Вас есть вопросы, просьбы или пожелания. Не стесняйтесь спросить, я отвечаю всегда быстро.



