Метод перекрестной проверки(Cross-validation) с примером реализации
Доброго времени суток! Речь пойдет о задаче классификации. А если быть точнее, то о способе оценить эффективность построенной модели, в частности, о методе перекрестной проверки. Что подразумевается под эффективностью? Конечно же, раз речь идет о классифицирующей модели, то оценивать нужно количество верных ответов.
Чем выше процент правильных ответов, тем больше вероятность, что модель адекватно себя поведет в «полевых условиях» — на реальных данных. Хорошо, когда размер обучающей выборки достаточно велик для того, чтобы выбрать оттуда процентов 30 элементов для тестирования. Но как быть, если данных для обучения очень мало?
На помощь приходит метод перекрестной проверки, в оригинале — Cross-validation.
Суть метода перекрестной проверки
Исходя из названия можно догадаться, что мы будем оперировать доступными ресурсами максимально эффективно, пытаясь их «перекрестить». То есть будем обучать модель на одних и тех же данных, но выкидывая каждый раз по кусочку, который будет использоваться для тестирования полученной модели. Перебрав все «кусочки» и посчитав средний процент отгадывания, мы получим наиболее достоверную оценку модели классификатора.
Всего существует два подхода к выбору размера «кусочка», остановимся на каждом подробнее.
Перекрестная проверка с проходом по одному
Самый простой и действенный метод, выкидываем каждый раз один объект, обучаем модель на остальных и тестируем. Преимущество в том, что используется максимально возможное количество как тестовых, так и обучающих данных, следовательно оценка максимально приближена к реальности.
Но есть существенный недостаток — метод требует больших вычислительных расходов, все таки приходится переобучать модель сколько раз, сколько элементов в обучающей выборке.
X-проходная перекрестная проверка
Этот подход был призван уменьшить вычислительные расходы. Суть в том, что обучающая выборка делится на X сбалансированных частей. Сбалансированность в том смысле, что не должно быть части, в которой какой-то класс сильно доминирует. Затем модель обучается X раз на выборке за исключением одной части. Далее по аналогии с первым методом, считается процент правильных ответов.
Как правило, на практике X = 5, деление на пять частей наиболее подходящий выбор в плане производительности и точности оценки.
Реализация метода перекрестной проверки на PHP
Чтобы не быть голословным, решил в качестве примера привести реализацию метода перекрестной проверки с проходом по одному. Это код из моего недавнего проекта, в нем используется метод опорных векторов из библиотеки PHP-ML. Можно примерно прикинуть, как осуществляется обход элементов обучающей выборки.
Кросс-валидация
Кросс-валидация или скользящий контроль — процедура эмпирического оценивания обобщающей способности алгоритмов. С помощью кросс-валидации эмулируется наличие тестовой выборки, которая не участвует в обучении, но для которой известны правильные ответы.
Содержание
Определения и обозначения [ править ]
Пусть [math] X [/math] — множество признаков, описывающих объекты, а [math] Y [/math] — конечное множество меток.
[math]T^l = <(x_i, y_i)>_
[math]Q[/math] — мера качества,
[math]\mu: (X \times Y)^l \to A, [/math] — алгоритм обучения.
Разновидности кросс-валидации [ править ]
Валидация на отложенных данных (Hold-Out Validation) [ править ]
Обучающая выборка один раз случайным образом разбивается на две части [math] T^l = T^t \cup T^

После чего решается задача оптимизации:
Метод Hold-out применяется в случаях больших датасетов, т.к. требует меньше вычислительных мощностей по сравнению с другими методами кросс-валидации. Недостатком метода является то, что оценка существенно зависит от разбиения, тогда как желательно, чтобы она характеризовала только алгоритм обучения.
Полная кросс-валидация (Complete cross-validation) [ править ]

Здесь число разбиений [math]C_l^
k-fold кросс-валидация [ править ]
Каждая из [math]k[/math] частей единожды используется для тестирования. Как правило, [math]k = 10[/math] (5 в случае малого размера выборки).
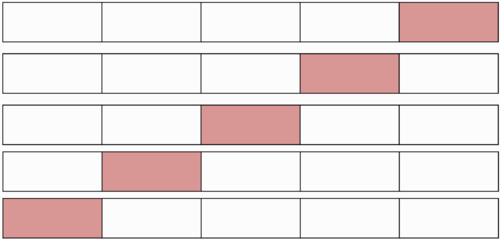
t×k-fold кросс-валидация [ править ]
Кросс-валидация по отдельным объектам (Leave-One-Out) [ править ]
Выборка разбивается на [math]l-1[/math] и 1 объект [math]l[/math] раз.
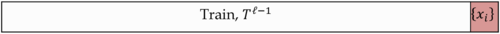
Преимущества LOO в том, что каждый объект ровно один раз участвует в контроле, а длина обучающих подвыборок лишь на единицу меньше длины полной выборки.
Недостатком LOO является большая ресурсоёмкость, так как обучаться приходится [math]L[/math] раз. Некоторые методы обучения позволяют достаточно быстро перенастраивать внутренние параметры алгоритма при замене одного обучающего объекта другим. В этих случаях вычисление LOO удаётся заметно ускорить.
Случайные разбиения (Random subsampling) [ править ]
Выборка разбивается в случайной пропорции. Процедура повторяется несколько раз.
Критерий целостности модели (Model consistency criterion) [ править ]
Не переобученый алгоритм должен показывать одинаковую эффективность на каждой части.

Перекрестная проверка
Дата публикации Aug 16, 2018

Что такое перекрестная проверка?
Перекрестная проверкаэто методы проверки модели для оценки того, как результаты статистического анализа (модели) будут обобщены в независимый набор данных. Он в основном используется в условиях, когда целью является прогнозирование, и каждый хочет оценить, насколько точно прогностическая модель будет работать на практике.
Что такое переоснащение и недостаточное оснащение?
Оптимальная модель хорошо работает как в поезде, так и на испытательном стенде.

Разные стратегии валидации?
Как правило, существуют разные стратегии проверки, основанные на количестве разделений, выполняемых в наборе данных.
Поезд / Тестовый сплит или Удержание: # groups = 2
В этой стратегии мы просто разделяем данные на два набора: обучающий и тестовый набор, чтобы выборка между обучением и тестовым набором не перекрывалась, если они это делают, мы просто не можем доверять нашей модели. Вот почему важно не иметь дублированных выборок в нашем наборе данных. Прежде чем мы сделаем нашу окончательную модель, мы можем переобучить модель на всем наборе данных, не изменяя ни один из гиперпараметров модели.

Реализация на питоне: sklearn.model_selection.train_test_split
K-fold: # groups = k
Поскольку данных для обучения модели никогда не бывает достаточно, удаление ее части для проверки создает проблему недостаточного соответствия. Сокращая данные обучения, мы рискуем потерять важные шаблоны / тренды в наборе данных, что, в свою очередь, увеличивает ошибку, вызванную смещением. Итак, нам нужен метод, который предоставляет достаточно данных для обучения модели, а также оставляет достаточно данных для проверки. K Fold Cross валидация делает именно это.
Это можно рассматривать как повторное удержание, и мы просто усредняем оценки после K различных отклонений. Каждая точка данных попадает в набор проверки ровно один раз и попадает в набор тренировок.к-1раз.Это значительно снижает недостаточную подгонку, так как мы используем большую часть данных для подгонки, а также значительно уменьшает переобучение, так как большая часть данных также используется в проверочном наборе.

Этот метод является хорошим выбором, когда у нас есть минимальное количество данных, и мы получаем достаточно большую разницу в качестве или разные оптимальные параметры между сгибами. Как правило, мы выбираем k = 5 или k = 10, так как эти значения были показаны эмпирически для получения оценок ошибок теста, которые не страдают ни от чрезмерно высокого смещения, ни от высокой дисперсии.
Реализация на питоне: sklearn.model_selection.KFold
Оставьте одно: # groups = len (train)
Это особый случай Kfold, когда K равно числу выборок в нашем наборе данных. Это означает, что каждый раз в каждом наборе данных будет проходить итерация с использованием объекта k-1 в качестве образцов поезда и 1 объекта в качестве тестового набора.

Этот метод может быть полезен, если у нас слишком мало данных и достаточно быстрая модель для переподготовки.
Реализация на питоне: sklearn.model_selection.LeaveOneOut
Дополнительно: стратификация
Обычно, когда мы используем разделение поезда / теста, Kfold перетасовывает данные, пытаясь воспроизвести случайное разделение проверки поезда В этом случае возможно различное распределение цели, которое будет применено к различным сгибам. С помощью стратификации мы достигаем одинакового целевого распределения в разных сгибах, когда разделяем данные.

В целом, для сбалансированного большого набора данных разделение по слоям будет очень похоже на простое случайное (случайное) разделение.
Когда использовать каждый из перечисленных методов?
Если у нас есть достаточно данных, и, вероятно, получатся аналогичные оценки и оптимальные параметры модели для разных разделений, разделение по принципу «поезд / тест» является хорошим вариантом. Если, напротив, оценки и оптимальные параметры различаются для разных расщеплений, мы можем выбрать подход KFold, в то время как если у нас слишком мало данных, мы можем применить опущенный. Стратификация помогает сделать проверку более стабильной и особенно полезна для небольших и несбалансированных наборов данных.
В kFold сколько складок использовать?
По мере увеличения количества сгибов погрешность из-за смещения уменьшается, но увеличивается погрешность из-за дисперсии; вычислительная цена тоже будет расти. Очевидно, вам нужно больше времени для его вычисления и вам потребуется больше памяти.
С меньшим числом сгибов мы уменьшаем ошибку из-за отклонения, но ошибка из-за смещения будет больше. Это также будет в вычислительном отношении дешевле.
Общие рекомендации для большого набора данных, обычно k = 3 или k = 5, являются предпочтительным вариантом, в то время как в небольших наборах данных рекомендуется использовать опцию Leave one out.
Взять домой сообщение
Перекрестная проверкаочень полезный инструмент исследователя данных для оценки эффективности модели, особенно для решения проблемы переоснащения и недостаточного оснащения.Кроме того, полезноопределить гиперпараметры моделив том смысле, что параметры будут приводить к наименьшей ошибке теста.

Спасибо за чтение, и я с нетерпением жду, чтобы услышать ваши вопросы 🙂
Наслаждайтесь!
3.1. Перекрестная проверка: оценка производительности ¶
Изучение параметров функции прогнозирования и тестирование ее на одних и тех же данных является методологической ошибкой: модель, которая будет просто повторять метки образцов, которые она только что увидела, будет иметь идеальную оценку, но пока не сможет предсказать что-либо полезное. невидимые данные. Такая ситуация называется переобучением. Чтобы этого избежать, при проведении (контролируемого) эксперимента с машинным обучением обычно используется часть имеющихся данных в виде набора тестов X_test, y_test. Обратите внимание, что слово «эксперимент» не предназначено для обозначения только академического использования, потому что даже в коммерческих условиях машинное обучение обычно начинается экспериментально. Вот блок-схема типичного рабочего процесса перекрестной проверки при обучении модели. Лучшие параметры могут быть определены методами поиска по сетке.
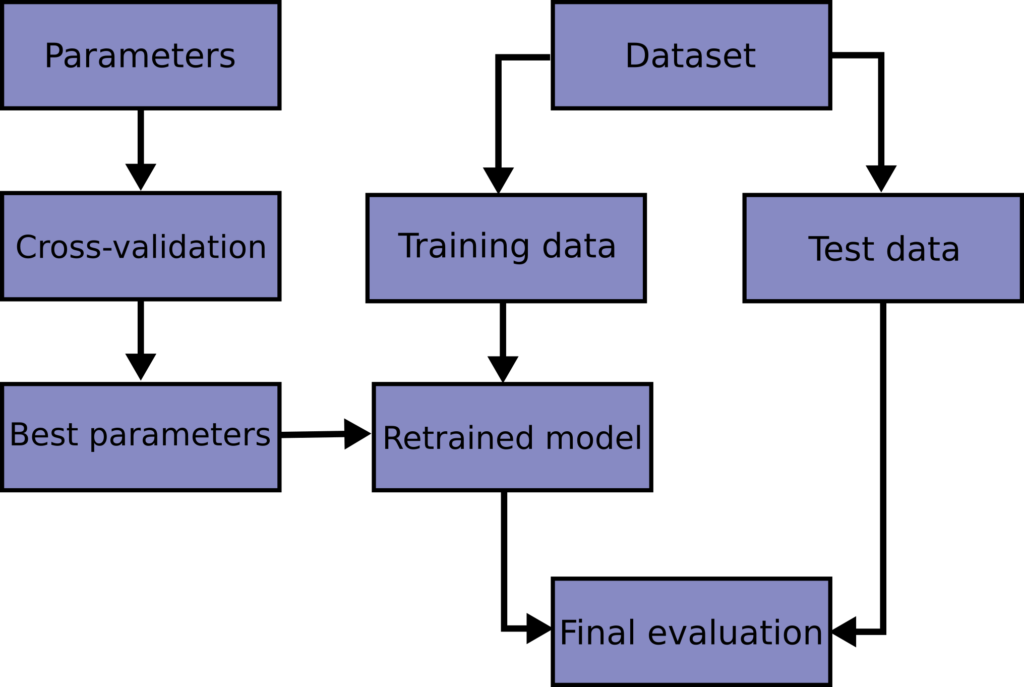
В scikit-learn можно быстро вычислить случайное разбиение на обучающие и тестовые наборы с помощью train_test_split вспомогательной функции. Давайте загрузим набор данных диафрагмы, чтобы он соответствовал линейной машине опорных векторов:
Теперь мы можем быстро выбрать обучающий набор, сохраняя 40% данных для тестирования (оценки) нашего классификатора:
Однако, разбивая доступные данные на три набора, мы резко сокращаем количество выборок, которые можно использовать для обучения модели, а результаты могут зависеть от конкретного случайного выбора для пары наборов (обучение, проверка).
Решением этой проблемы является процедура перекрестной проверки (cross-validation сокращенно CV). Набор тестов по-прежнему должен храниться для окончательной оценки, но набор для проверки больше не нужен при выполнении резюме. В базовом подходе, называемом k- кратным CV, обучающая выборка разбивается на k меньших наборов (другие подходы описаны ниже, но обычно следуют тем же принципам). Для каждой из k «фолдов» выполняется следующая процедура :
Показатель производительности, сообщаемый k- фолд перекрестной проверкой, тогда является средним из значений, вычисленных в цикле. Этот подход может быть дорогостоящим в вычислительном отношении, но не тратит слишком много данных (как в случае фиксации произвольного набора проверки), что является основным преимуществом в таких задачах, как обратный вывод, когда количество выборок очень мало.
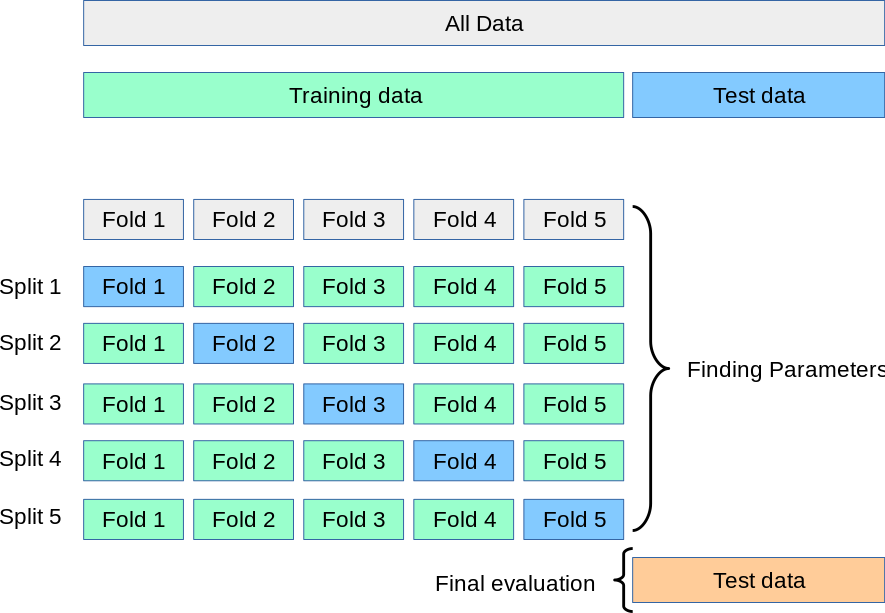
3.1.1. Вычисление метрик с перекрестной проверкой
Самый простой способ использовать перекрестную проверку — вызвать cross_val_score вспомогательную функцию для оценщика и набора данных.
В следующем примере показано, как оценить точность машины вектора поддержки линейного ядра в наборе данных радужной оболочки путем разделения данных, подбора модели и вычисления оценки 5 раз подряд (с разными разбиениями каждый раз):
Таким образом, средний балл и стандартное отклонение выражаются следующим образом:
По умолчанию оценка, вычисляемая на каждой итерации CV, является score методом оценщика. Это можно изменить, используя параметр оценки:
Также можно использовать другие стратегии перекрестной проверки, передав вместо этого итератор перекрестной проверки, например:
Другой вариант — использовать итерируемые разбиения с получением (train, test) как массивы индексов, например:
Преобразование данных с сохраненными данными
Подобно тому, как важно протестировать предсказатель на данных, полученных в результате обучения, предварительная обработка (например, стандартизация, выбор функций и т. Д.) И аналогичные преобразования данных аналогичным образом должны быть изучены из обучающего набора и применены к удерживаемым данным для прогнозирования. :
A Pipeline упрощает составление оценщиков, обеспечивая такое поведение при перекрестной проверке:
3.1.1.1. Функция cross_validate и оценка нескольких показателей
В cross_validate функции отличается от cross_val_score двух способов:
Для оценки единственной метрики, где параметром скоринга является строка, вызываемая или None, ключи будут: [‘test_score’, ‘fit_time’, ‘score_time’]
А для оценки нескольких показателей возвращаемое значение — это dict со следующими ключами: [‘test_ ‘, ‘test_ ‘, ‘test_ ‘, ‘fit_time’, ‘score_time’]
Множественные показатели могут быть указаны в виде списка, кортежа или набора заранее определенных имен счетчиков:
Или как dict сопоставление имени счетчика с предопределенной или настраиваемой функцией оценки:
Вот пример cross_validate использования одной метрики:
3.1.1.2. Получение прогнозов путем перекрестной проверки
Замечание о неправильном использовании cross_val_predict. Результат cross_val_predict может отличаться от полученного при использовании, cross_val_score поскольку элементы сгруппированы по-разному. Функция cross_val_score берет среднее значение по сверткам перекрестной проверки, тогда как cross_val_predict просто возвращает метки (или вероятности) из нескольких различных моделей без различия. Таким образом, cross_val_predict не является подходящей мерой ошибки обобщения.
Доступные итераторы перекрестной проверки представлены в следующем разделе.
3.1.2. Итераторы перекрестной проверки
В следующих разделах перечислены утилиты для создания индексов, которые можно использовать для создания разбиений наборов данных в соответствии с различными стратегиями перекрестной проверки.
3.1.2.1. Итераторы перекрестной проверки для данных
Предполагая, что некоторые данные являются независимыми и идентично распределенными (Independent and Identically Distributed — i.i.d.), предполагается, что все выборки происходят из одного и того же генерирующего процесса и что генеративный процесс не имеет памяти о сгенерированных ранее выборках.
В таких случаях можно использовать следующие кросс-валидаторы.
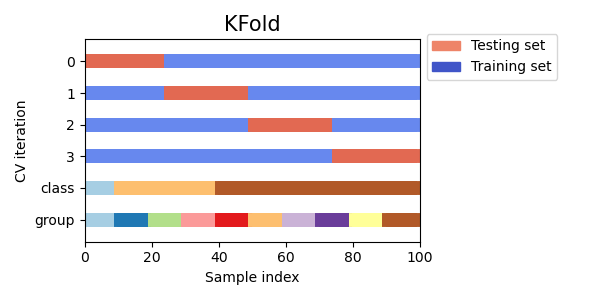
3.1.2.1.1. K-фолд
Пример 2-фолдовой перекрестной проверки на наборе данных с 4 образцами:
Вот визуализация поведения перекрестной проверки. Обратите внимание, на KFold не влияют классы или группы.
3.1.2.1.2. Повторяющийся K-Fold
RepeatedKFold повторяет K-Fold n раз. Его можно использовать, когда нужно выполнить KFold n раз, производя разные разбиения в каждом повторении.
Пример 2-кратного K-Fold повторяется 2 раза:
Аналогичным образом, RepeatedStratifiedKFold повторяет стратифицированный K-Fold n раз с различной рандомизацией в каждом повторении.
3.1.2.1.3. Оставьте один вне (LOO)
Пример Leave-2-Out в наборе данных с 4 образцами:
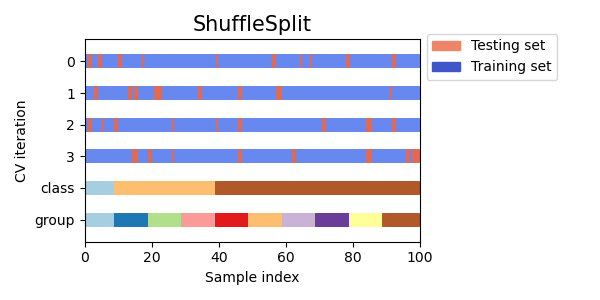
3.1.2.1.5. Перекрестная проверка случайных перестановок, известная как Shuffle & Split
Итератор ShuffleSplit будет генерировать, определенные пользователем, число независимых обученые / тестовые наборы данных разделений. Образцы сначала перемешиваются, а затем разделяются на пару наборов для обучения и тестов.
Можно контролировать случайность для воспроизводимости результатов путем явного заполнения random_state генератора псевдослучайных чисел.
Вот пример использования:
Вот визуализация поведения перекрестной проверки. Обратите внимание, на ShuffleSplit это не влияют классы или группы.
Таким образом ShuffleSplit это хорошая альтернатива KFold перекрестной проверке, которая позволяет более точно контролировать количество итераций и долю выборок на каждой стороне разделения обучения / тест.
3.1.2.2. Итераторы перекрестной проверки со стратификацией на основе меток классов.
Некоторые проблемы классификации могут демонстрировать большой дисбаланс в распределении целевых классов: например, отрицательных образцов может быть в несколько раз больше, чем положительных. В таких случаях рекомендуется использовать стратифицированную выборку, как это реализовано в, StratifiedKFold и StratifiedShuffleSplit гарантировать, что относительная частота классов приблизительно сохраняется в каждой последовательности и валидации.
3.1.2.2.1. Стратифицированный k-фолд
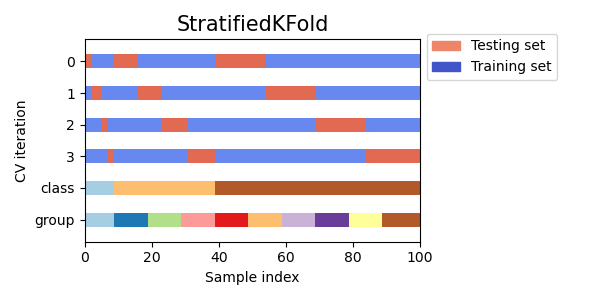
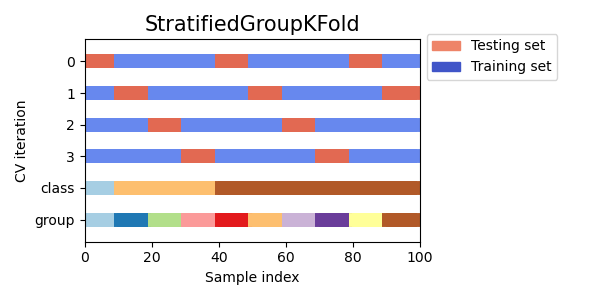
StratifiedKFold представляет собой разновидность k-фолдовой кратности, которая возвращает стратифицированные фолды: каждый набор содержит примерно такой же процент выборок каждого целевого класса, что и полный набор.
Мы видим, что StratifiedKFold соотношение классов (примерно 1/10) сохраняется как в обучающем, так и в тестовом наборе данных.
Вот визуализация поведения перекрестной проверки.
RepeatedStratifiedKFold может использоваться для повторения стратифицированного K-фолдов n раз с различной рандомизацией в каждом повторении.
3.1.2.2.2. Стратифицированное перемешивание в случайном порядке
Вот визуализация поведения перекрестной проверки.
3.1.2.3. Итераторы перекрестной проверки для сгруппированных данных.
Предположение iid нарушается, если основной процесс генерации дает группы зависимых выборок.
Такая группировка данных зависит от предметной области. В качестве примера можно привести медицинские данные, собранные у нескольких пациентов, с множеством образцов, взятых у каждого пациента. И такие данные, вероятно, будут зависеть от отдельной группы. В нашем примере идентификатор пациента для каждого образца будет идентификатором его группы.
В этом случае мы хотели бы знать, хорошо ли модель, обученная на конкретном наборе групп, обобщается на невидимые группы. Чтобы измерить это, нам нужно убедиться, что все выборки в фолдовой проверке взяты из групп, которые вообще не представлены в парной обучающей выборке.
Для этого можно использовать следующие разделители перекрестной проверки. Идентификатор группировки для образцов указывается через groups параметр.
3.1.2.3.1. Группа K фолд
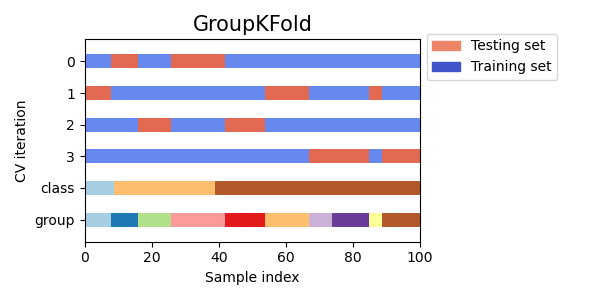
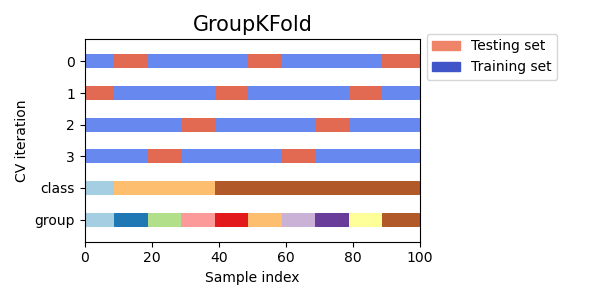
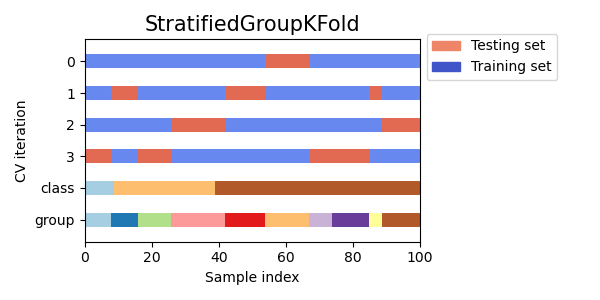
GroupKFold представляет собой вариант k-фолдовое увеличение, которое гарантирует, что одна и та же группа не будет представлена как в тестовой, так и в обучающей выборке. Например, если данные получены от разных субъектов с несколькими выборками по каждому субъекту, и если модель достаточно гибкая, чтобы учиться на личностно-специфических особенностях, ее нельзя будет обобщить на новые темы. GroupKFold п озволяет обнаруживать такого рода ситуации переобучения.
Представьте, что у вас есть три предмета, каждому из которых соответствует номер от 1 до 3:
Каждый предмет проходит разные этапы тестирования, и один и тот же предмет никогда не проходит и в тестировании, и в обучении. Обратите внимание, что складки не имеют точно такого же размера из-за несбалансированности данных.
Вот визуализация поведения перекрестной проверки.
3.1.2.3.2. Оставьте одну группу вне (Leave One Group Out)
LeaveOneGroupOut представляет собой схему перекрестной проверки, в которой образцы хранятся в соответствии с массивом целочисленных групп, предоставленным третьей стороной. Эту групповую информацию можно использовать для кодирования произвольных предопределенных фолдов перекрестной проверки, зависящих от домена.
Таким образом, каждый обучающий набор состоит из всех выборок, кроме тех, которые относятся к определенной группе.
Например, в случаях нескольких экспериментов, LeaveOneGroupOut может использоваться для создания перекрестной проверки на основе различных экспериментов: мы создаем обучающий набор, используя образцы всех экспериментов, кроме одного:
Другое распространенное применение — использование информации о времени: например, группы могут быть годом сбора образцов и, таким образом, допускать перекрестную проверку на разбиение по времени.
3.1.2.3.3. Оставьте P групп вне (Leave P Groups Out)
Пример выхода из группы 2 из 2:
3.1.2.3.4. Групповой случайный сплит
Вот пример использования:
Вот визуализация поведения перекрестной проверки.
3.1.2.4. Предопределенные Fold-Splits / Validation-Sets
Для некоторых наборов данных уже существует предварительно определенное разделение данных на фолды обучения и теста или на несколько фолдов перекрестной проверки. С PredefinedSplit помощью этих фолдов можно использовать, например, при поиске гиперпараметров.
3.1.2.5. Использование итераторов перекрестной проверки для разделения обучения и тестирования
Вышеупомянутые групповые функции перекрестной проверки также могут быть полезны для разделения набора данных на подмножества обучения и тестирования. Обратите внимание, что вспомогательная функция train_test_split является оболочкой ShuffleSplit и, таким образом, допускает только стратифицированное разбиение (с использованием меток классов) и не может учитывать группы.
Чтобы выполнить разделение поезда и теста, используйте индексы для подмножеств поезда и теста, полученные на выходе генератора split() методом разделителя перекрестной проверки. Например:
3.1.2.6. Перекрестная проверка данных временных рядов
3.1.2.6.1. Разделение временных рядов
TimeSeriesSplit это вариант k-фолд возврата, который возвращается первымk складывается как набор поездов и ($k+1$)-я фолдов в качестве тестового набора. Обратите внимание, что в отличие от стандартных методов перекрестной проверки, последовательные обучающие наборы являются надмножествами предшествующих. Кроме того, он добавляет все лишние данные в первый обучающий раздел, который всегда используется для обучения модели.
Этот класс можно использовать для перекрестной проверки выборок данных временных рядов, которые наблюдаются через фиксированные интервалы времени.
Пример перекрестной проверки 3-сегментных временных рядов на наборе данных с 6 выборками:
Вот визуализация поведения перекрестной проверки.
3.1.3. Замечание о перемешивании
Если порядок данных не является произвольным (например, выборки с одной и той же меткой класса являются смежными), сначала перетасовка данных может быть существенной для получения значимого результата перекрестной проверки. Однако может быть и обратное, если образцы не распределены независимо и одинаково. Например, если образцы соответствуют новостным статьям и упорядочены по времени публикации, то перетасовка данных, скорее всего, приведет к переобучению модели и завышенной оценке валидации: она будет проверена на образцах, которые искусственно похожи (близкие вовремя) к обучающим выборкам.
3.1.4. Перекрестная проверка и выбор модели
3.1.5. Результат теста на перестановку (Permutation test score)
permutation_test_score предлагает другой способ оценки производительности классификаторов. Он обеспечивает p-значение на основе перестановок, которое показывает, насколько вероятно, что наблюдаемая производительность классификатора будет получена случайно. Нулевая гипотеза в этом тесте заключается в том, что классификатор не может использовать какую-либо статистическую зависимость между функциями и метками, чтобы делать правильные прогнозы на основе оставленных данных. permutation_test_score генерирует нулевое распределение, вычисляя n_permutations различные перестановки данных. В каждой перестановке метки случайным образом перемешиваются, тем самым удаляя любую зависимость между функциями и метками. Выходное значение p — это доля перестановок, для которых средняя оценка перекрестной проверки, полученная моделью, лучше, чем оценка перекрестной проверки, полученная моделью с использованием исходных данных. Для надежных результатов n_permutations обычно должно быть больше 100 и составлять cv от 3 до 10 фолдов.
Низкое значение p свидетельствует о том, что набор данных содержит реальную зависимость между функциями и метками, и классификатор смог использовать это для получения хороших результатов. Высокое значение p могло быть связано с отсутствием зависимости между функциями и метками (нет разницы в значениях функций между классами) или потому, что классификатор не смог использовать зависимость в данных. В последнем случае использование более подходящего классификатора, способного использовать структуру данных, приведет к низкому значению p (p-value).
Перекрестная проверка предоставляет информацию о том, насколько хорошо классификатор обобщает, в частности, о диапазоне ожидаемых ошибок классификатора. Однако классификатор, обученный на многомерном наборе данных без структуры, может работать лучше, чем ожидалось при перекрестной проверке, просто случайно. Обычно это может происходить с небольшими наборами данных, содержащими менее нескольких сотен образцов. permutation_test_score предоставляет информацию о том, нашел ли классификатор реальную структуру классов, и может помочь в оценке производительности классификатора.
Важно отметить, что этот тест показал низкие p-значения, даже если в данных есть только слабая структура, потому что в соответствующих переставленных наборах данных нет абсолютно никакой структуры. Таким образом, этот тест может показать, только когда модель надежно превосходит случайное предположение.
Наконец, permutation_test_score вычисляется методом грубой силы и полностью соответствует (n_permutations + 1) * n_cv моделям. Следовательно, его можно обрабатывать только с небольшими наборами данных, для которых подгонка отдельной модели выполняется очень быстро.



